python爬虫 - 爬取微博热搜数据
文章目录
- python爬虫 -爬取微博热搜数据
- 1. 第一步:安装requests库和BeautifulSoup库
- 2. 第二步:获取爬虫所需的header和cookie
- 3. 第三步:获取网页
- 4. 第四步:解析网页
- 5. 第五步:分析得到的信息,简化地址
- 6. 第六步:爬取内容,清洗数据
- 7. 爬取微博热搜的代码实例以及结果展示
python爬虫 -爬取微博热搜数据
python爬虫六部曲:
-
第一步:安装requests库和BeautifulSoup库
-
第二步:获取爬虫所需的header和cookie
-
第三步:获取网页
-
第四步:解析网页
-
第五步:分析得到的信息,简化地址:
-
第六步:爬取内容,清洗数据
1. 第一步:安装requests库和BeautifulSoup库
在程序中引用两个库的书写是这样的:
import requests
from bs4 import BeautifulSoup
以pycharm为例,在pycharm上安装这两个库的方法。在菜单【文件】–>【设置】->【项目】–>【Python解释器】中,在所选框中,点击软件包上的+号就可以进行查询插件安装了。有过编译器插件安装的hxd估计会比较好入手。具体情况就如下图所示。
2. 第二步:获取爬虫所需的header和cookie
以爬取微博热搜的爬虫程序为例。获取header和cookie是一个爬虫程序必须的,它直接决定了爬虫程序能不能准确的找到网页位置进行爬取。
- 首先进入微博热搜的页面,按下F12,就会出现网页的js语言设计部分,找到网页上的Network部分。如下图所示:
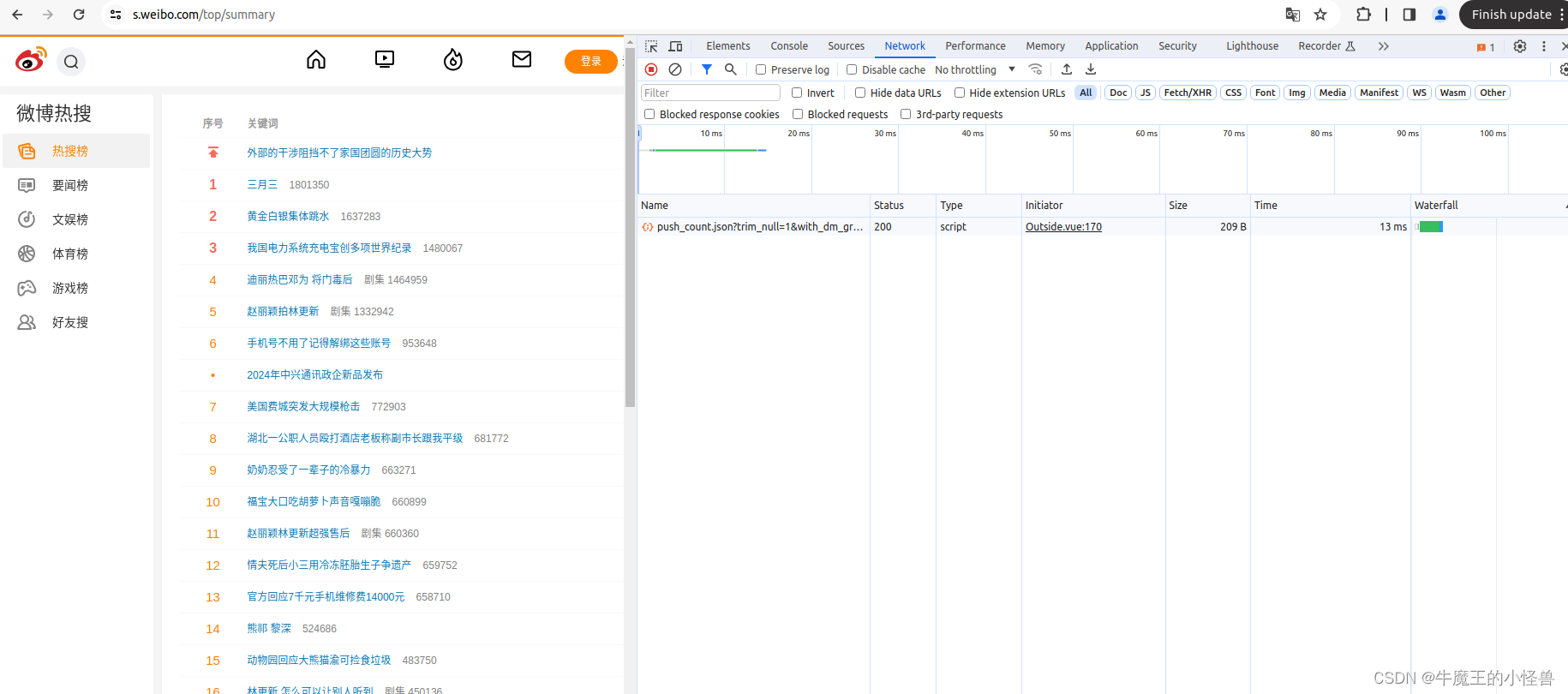
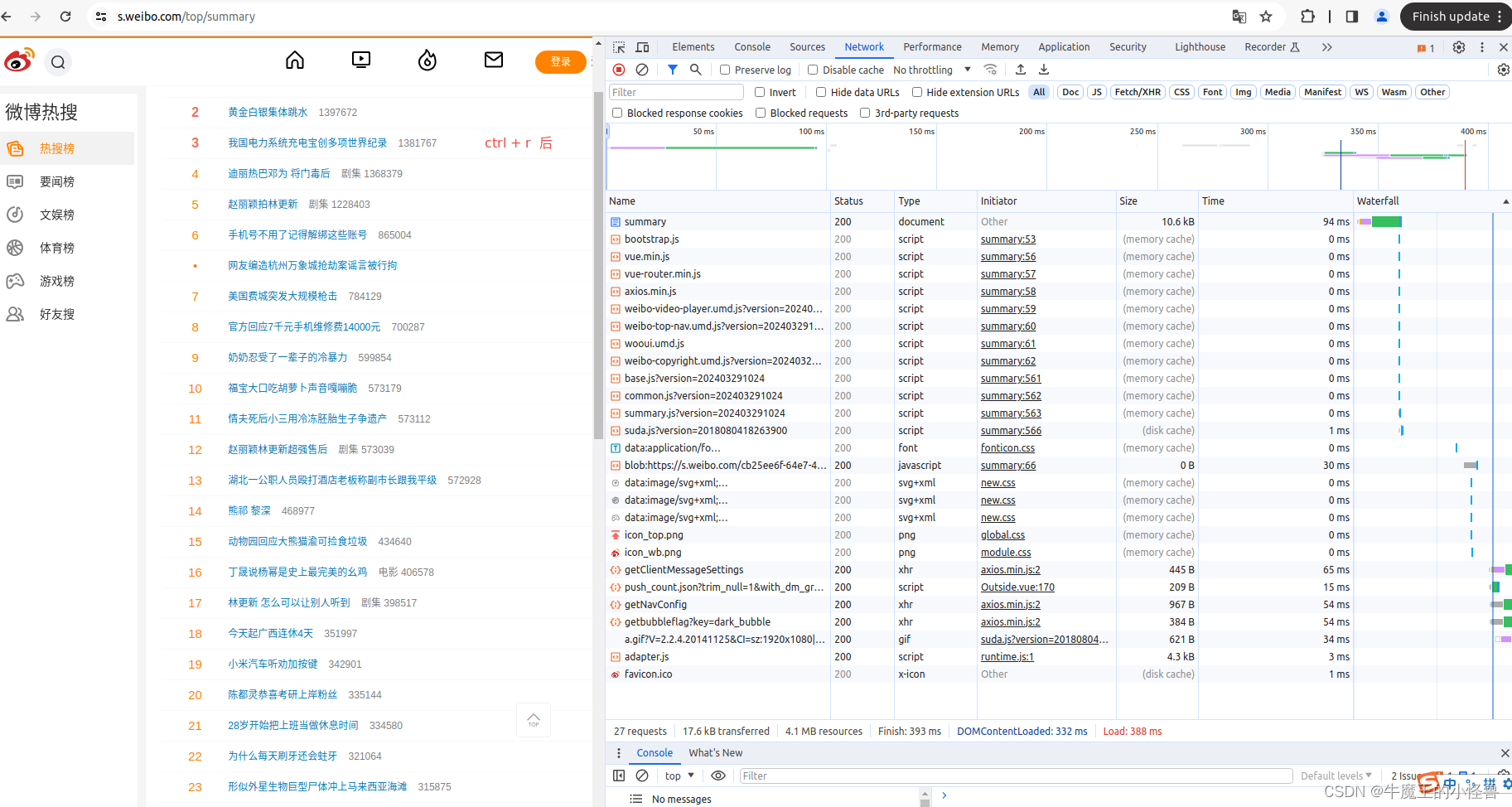
- 然后按下ctrl+R刷新页面,此时法线右边 NetWork 部分出现很多信息。
(如果进入后就有所需要的信息,就不用刷新了),当然刷新了也没啥问题。
-
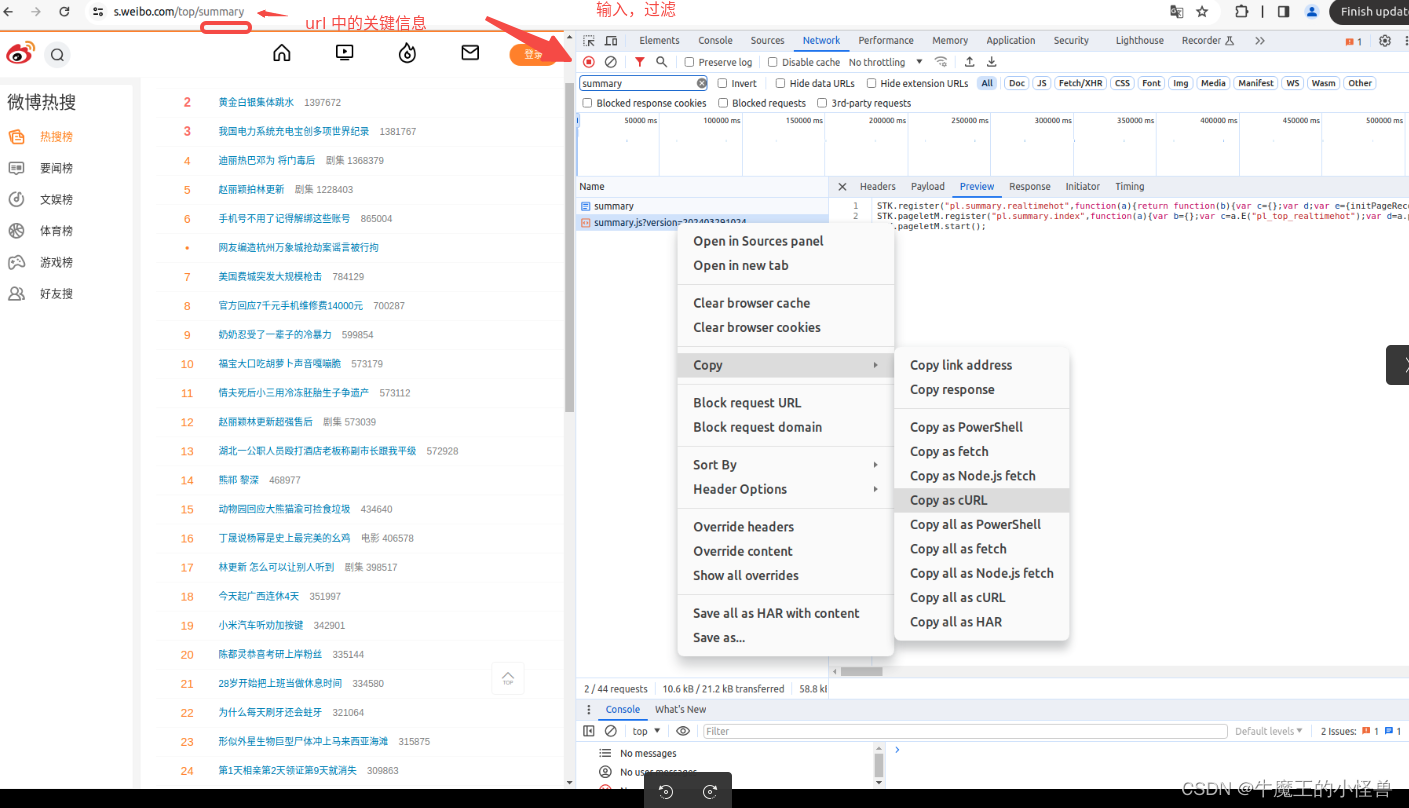
过滤网络信息,并拷贝其 cURL 信息 ,
在 Network --> Filter 中,依据网址(https://s.weibo.com/top/summary)中的关键信息进行过滤,如: summary。 然后,我们浏览Name这部分,找到我们想要爬取的文件(网络信息),鼠标右键,选择copy,复制下网页的URL。过滤后,有效信息会少很多,如下所示。选中所需的条目,右键 --> Copy --> Copy as cURL
- 利用工具 Convert curl commands to code https://curlconverter.com/python/ 进行转换
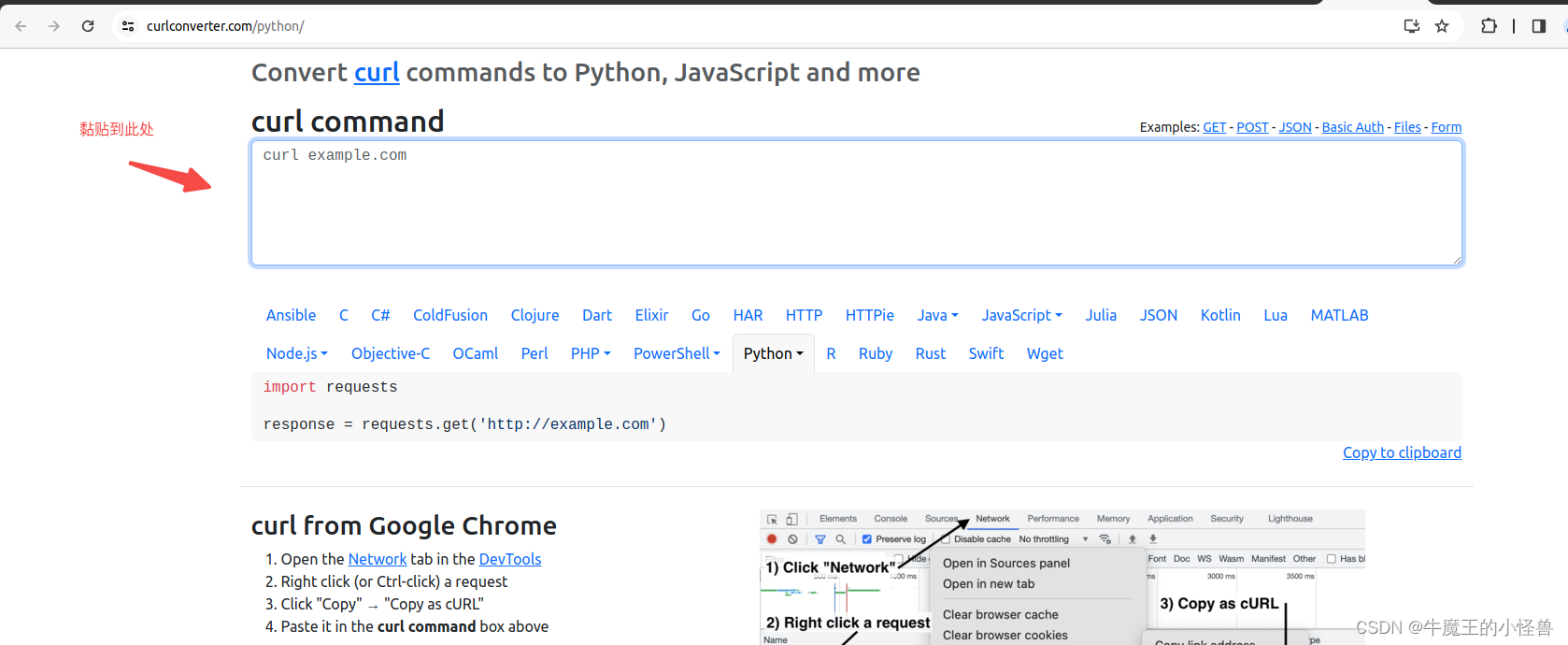
转换后信息如下图所示,选择【Copy to clipboard】,并黏贴到Pycharm开发环境中即可直接使用:
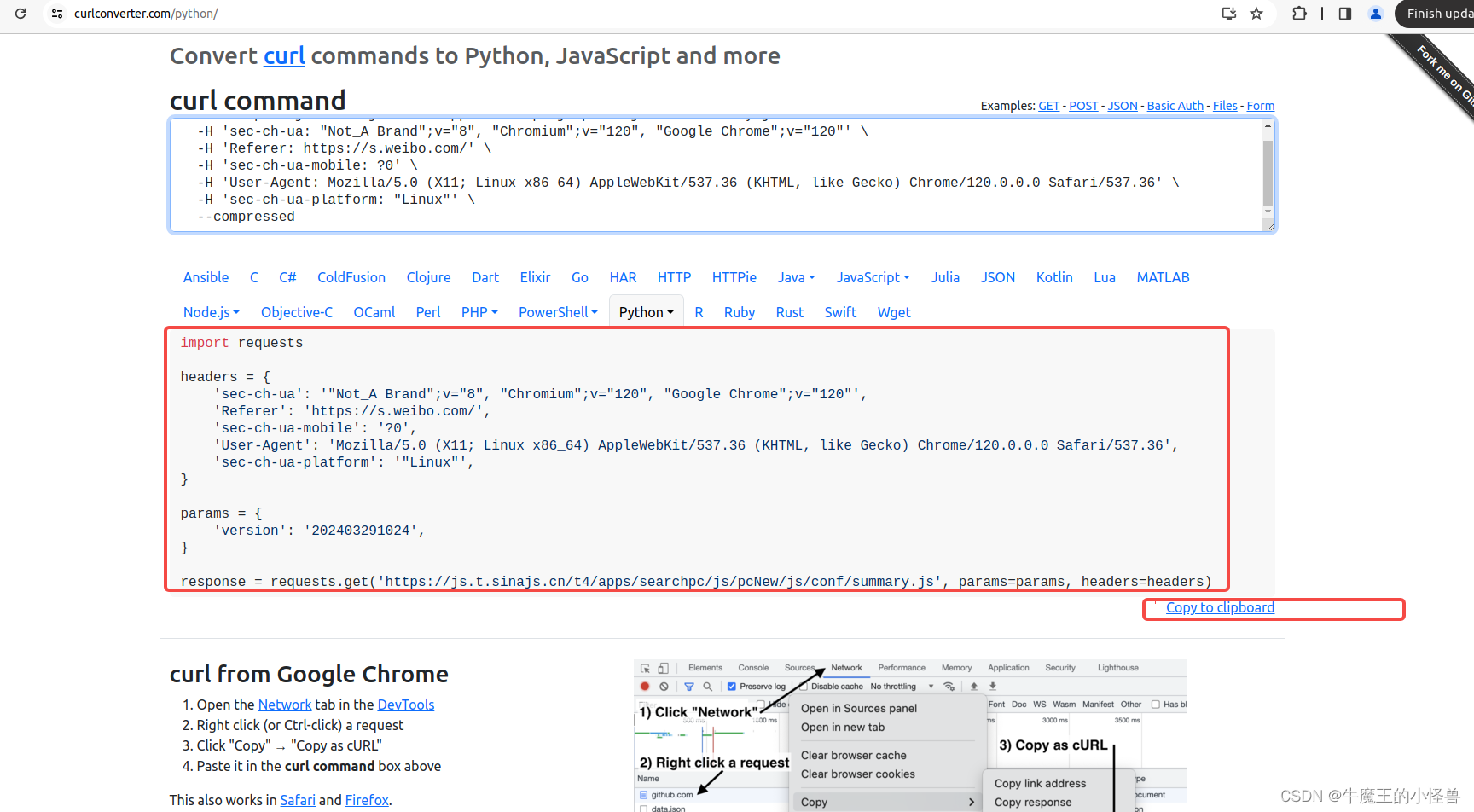
拷贝到 pycharm 中,可直接作为源代码使用:
3. 第三步:获取网页
通过requests.get() 即可获取网页内容:
response = requests.get('https://s.weibo.com/top/summary', cookies=cookies, headers=headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
print(f'soup value= {soup}')4. 第四步:解析网页
这个时候,我们需要回到网页: 【按下F12】–> 【找到网页的Elements部分 --> 【选中左上角的小框带箭头的标志】,进入【内容选择模式】,如下图,当点击(或鼠标移动到)对应网页内容时,这个时候网页就会自动在右边显示出你获取网页部分对应的代码。


在找到想要爬取的页面部分的网页内容后,在响应条目(如:“赵丽颖拍林更新”)上右键,退出【内容选择模式】。
然后将鼠标放置于 【Element】中对应的代码上,右键 -> copy --> selector。就如图所示。


5. 第五步:分析得到的信息,简化地址
黏贴到文本文件中信息如下:
#pl_top_realtimehot > table > tbody > tr:nth-child(6) > td.td-02
同理再黏贴:
#pl_top_realtimehot > table > tbody > tr:nth-child(8) > td.td-02 > a
其实刚才复制的selector就相当于网页上对应部分存放的地址。由于我们需要的是网页上的一类信息,所以我们需要对获取的地址进行分析,提取。
当然,就用那个地址也是可行的,就是只能获取到你选择的网页上的那部分内容。
可以发现几个地址有很多相同的地方,唯一不同的地方就是tr部分。由于tr是网页标签,后面的部分就是其补充的部分,也就是子类选择器。可以推断出,该类信息,就是存储在tr的子类中,我们直接对tr进行信息提取,就可以获取到该部分对应的所有信息。所以提炼后的地址为:
#pl_top_realtimehot > table > tbody > tr > td.td-02 > a
这个过程对js类语言有一定了解的hxd估计会更好处理。不过没有js类语言基础也没关系,主要步骤就是,保留相同的部分就行,慢慢的试,总会对的。
6. 第六步:爬取内容,清洗数据
这一步完成后,我们就可以直接爬取数据了。用一个标签存储上面提炼出的像地址一样的东西。标签就会拉取到我们想获得的网页内容。
# 爬取内容
content = "#pl_top_realtimehot > table > tbody > tr > td.td-02 > a"
之后我们就要soup和text过滤掉不必要的信息,比如js类语言,排除这类语言对于信息受众阅读的干扰。这样我们就成功的将信息,爬取下来了。
# 清洗数据
a = soup.select(content)将数据存储到文件夹中,所以会有wirte带来的写的操作。想把数据保存在哪里,或者想怎么用,就看读者自己了。
# 数据存储
fo = open("./weibo_down.txt", 'a', encoding="utf-8")
for i in range(0, len(a)):a[i] = a[i].textfo.write(a[i] + '\n')fo.close()
7. 爬取微博热搜的代码实例以及结果展示
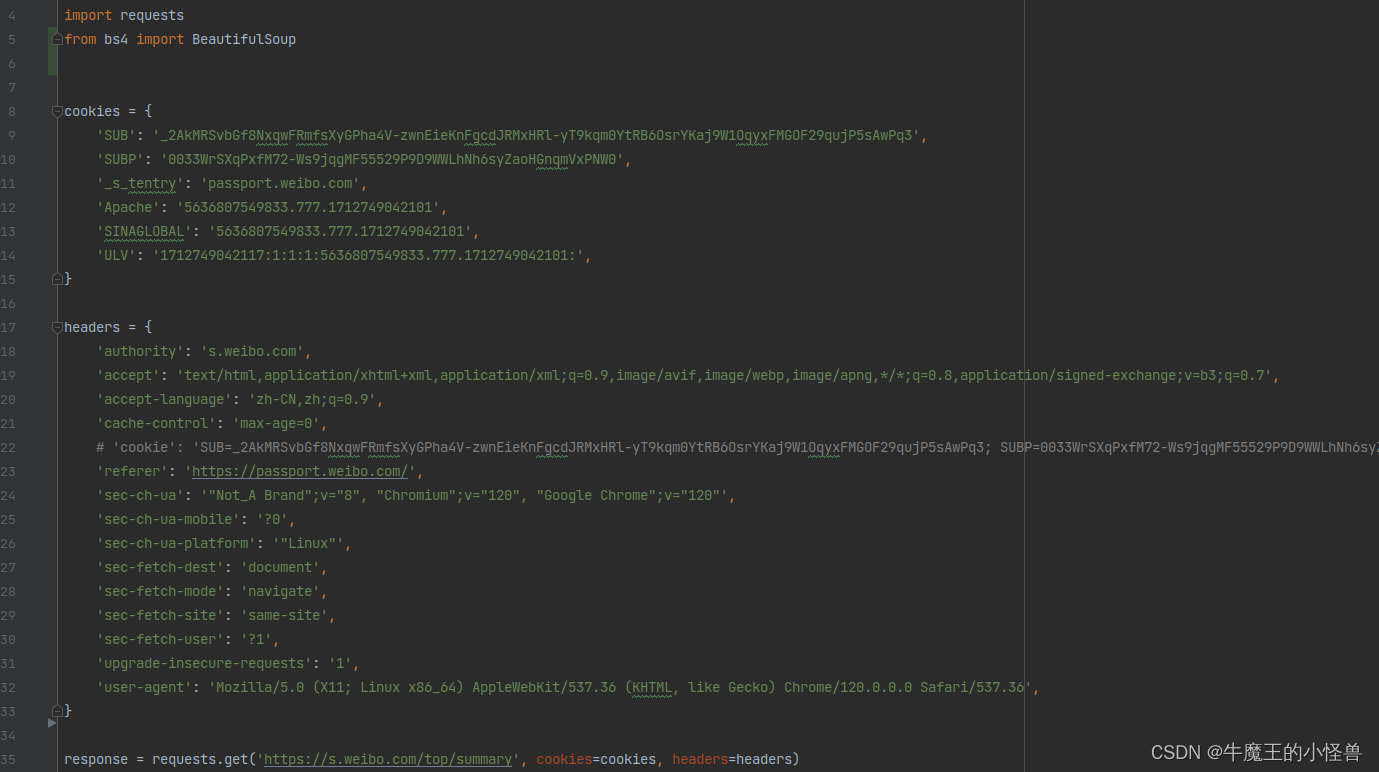
import osimport requests
from bs4 import BeautifulSoupcookies = {'SUB': '_2AkMRSvbGf8NxqwFRmfsXyGPha4V-zwnEieKnFgcdJRMxHRl-yT9kqm0YtRB6OsrYKaj9W1OqyxFMGOF29qujP5sAwPq3','SUBP': '0033WrSXqPxfM72-Ws9jqgMF55529P9D9WWLhNh6syZaoHGnqmVxPNW0','_s_tentry': 'passport.weibo.com','Apache': '5636807549833.777.1712749042101','SINAGLOBAL': '5636807549833.777.1712749042101','ULV': '1712749042117:1:1:1:5636807549833.777.1712749042101:',
}headers = {'authority': 's.weibo.com','accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','accept-language': 'zh-CN,zh;q=0.9','cache-control': 'max-age=0',# 'cookie': 'SUB=_2AkMRSvbGf8NxqwFRmfsXyGPha4V-zwnEieKnFgcdJRMxHRl-yT9kqm0YtRB6OsrYKaj9W1OqyxFMGOF29qujP5sAwPq3; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WWLhNh6syZaoHGnqmVxPNW0; _s_tentry=passport.weibo.com; Apache=5636807549833.777.1712749042101; SINAGLOBAL=5636807549833.777.1712749042101; ULV=1712749042117:1:1:1:5636807549833.777.1712749042101:','referer': 'https://passport.weibo.com/','sec-ch-ua': '"Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Linux"','sec-fetch-dest': 'document','sec-fetch-mode': 'navigate','sec-fetch-site': 'same-site','sec-fetch-user': '?1','upgrade-insecure-requests': '1','user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
}response = requests.get('https://s.weibo.com/top/summary', cookies=cookies, headers=headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
print(f'soup value= {soup}')# 爬取内容
content = "#pl_top_realtimehot > table > tbody > tr > td.td-02 > a"# 清洗数据
a = soup.select(content)# 数据存储
fo = open("./weibo_down.txt", 'a', encoding="utf-8")
for i in range(0, len(a)):a[i] = a[i].textfo.write(a[i] + '\n')fo.close()
相关文章:
python爬虫 - 爬取微博热搜数据
文章目录 python爬虫 -爬取微博热搜数据1. 第一步:安装requests库和BeautifulSoup库2. 第二步:获取爬虫所需的header和cookie3. 第三步:获取网页4. 第四步:解析网页5. 第五步:分析得到的信息,简化地址6. 第…...

Pytorch-张量形状操作
😆😆😆感谢大家的观看😆😆 🌹 reshape 函数 transpose 和 permute 函数 view 和 contigous 函数 squeeze 和 unsqueeze 函数 在搭建网络模型时,掌握对张量形状的操作是非常重要的ÿ…...
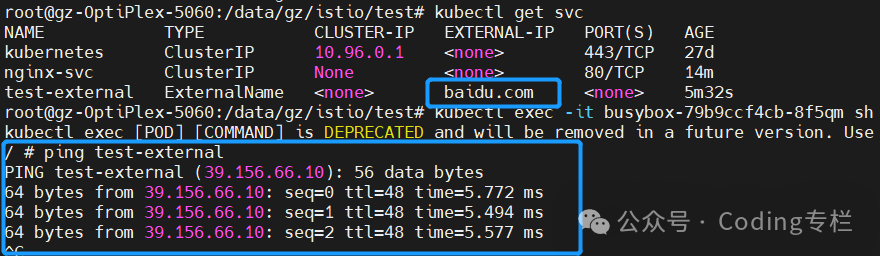
k8s的service为什么不能ping通?——所有的service都不能ping通吗
点击阅读原文 前提:kube-proxy使用iptables模式 Q service能不能ping通? A: 不能,因为k8s的service禁止了icmp协议 B: 不能,因为clusterIP是一个虚拟IP,只是用于配置netfilter规则,不会实际绑定设备&…...

[Linux] 权限控制命令 chmod、chown和chgrp
文章目录 chmodchownchgrp chmod 在Linux系统中,root用户可以使用chmod命令来修改文件的权限,并且root用户也可以授权普通用户来执行chmod命令。要将权限授予普通用户修改一个文件的权限,可以使用以下步骤: 使用root用户登录到L…...

RNN知识体系构筑:详尽阐述其理论基础、技术架构及其在处理序列数据挑战中的创新应用
一、为什么需要RNN 尽管神经网络被视为一种强大且理论上能够近似任何连续函数的模型,尤其当训练数据充足时,它们能够在输入空间中的某个点( x )映射到输出空间的特定值( y ),然而,这并不能完全解释为何在众多应用场景中ÿ…...
)
LeetCode 1702.修改后的最大二进制字符串:脑筋急转弯(构造,贪心)
【LetMeFly】1702.修改后的最大二进制字符串:脑筋急转弯(构造,贪心) 力扣题目链接:https://leetcode.cn/problems/maximum-binary-string-after-change/ 给你一个二进制字符串 binary ,它仅有 0 或者 1 组…...
图片像素轻松缩放自如,支持批量将多张jpg图片像素放大,高效掌握图片的像素
在这个数字化时代,图片已经成为我们生活中不可或缺的一部分。然而,你是否曾遇到过需要放大图片像素却担心失去细节和质量的问题?现在,一款全新的图片缩放工具诞生了,它能够让你轻松将多张JPG图片像素放大,同…...
FILE类与IO流
目录 File类的实例化与常用方法 File类的理解 文件路径的表示方式: API的使用 IO流概述与流的分类 I/O流中的是Input/Output的缩写 IO流的分类(不同角度) Java程序中的IO流涉及40多个,但实际上都是由4个抽象类衍生出来的。 F…...
基于java+springboot+vue实现的智慧党建系统(文末源码+Lw+ppt)23-58
摘 要 当今社会进入了科技进步、经济社会快速发展的新时代。国际信息和学术交流也不断加强,计算机技术对经济社会发展和人民生活改善的影响也日益突出,人类的生存和思考方式也产生了变化。传统智慧党建管理采取了人工的管理方法,但这种管…...

HiveSQL基础Day03
回顾总结 hive表的类型 :内部表和外部表 删除内部表会删除表的所有数据 删除外部表只会删除表的元数据,hdfs上的行数据会保留 表的分区和分桶 本质都是对表数据的拆分存储 分区的方式 是通过创建不同的目录来拆分数据 ,根据数据本身的内容最为…...

houdini 学习过程
1.基础界面操作了解 当初通过 朱峰上的界面 工具栏操作入门的,现在B站上应该也比较多 houdini pdf早期的 2.节点操作 B站视频 教程 3.vex B站捷佳 4.BILIBILI ENTAGMA CGWIKI YOUTUBE 5.节点功能的深入,属性了解,或其它节点扩充 常用&…...
Angular学习第四天--问题记录及父子组件问题
问题一、 拉取完项目,使用npm install命令的时候遇到的。 解决办法: 在查找网上五花八门的解决方案之后,发现都不能解决。 我的解决办法是: 1. 把package-lock.json给删掉; 2. 把package.json中公司自己库的包给删除掉…...
如何拿捏2024年的B端设计?(附工具推荐)
伴随着2019年前的互联网人口红利时代结束,科技行业的基本面发生了巨大的变化,以普通消费者为目标的C端需求大幅萎缩,面向企业的B端需求成为行业热点。 在2024年的今天,设计师应该如何理解B端设计的实质,并真正驾驭B端产…...

【蓝桥杯】2024年第15届真题题目
试题 A: 握手问题 本题总分: 5 分 【问题描述】 小蓝组织了一场算法交流会议,总共有 50 人参加了本次会议。在会议上, 大家进行了握手交流。按照惯例他们每个人都要与除自己以外的其他所有人进 行一次握手(且仅有一次&a…...
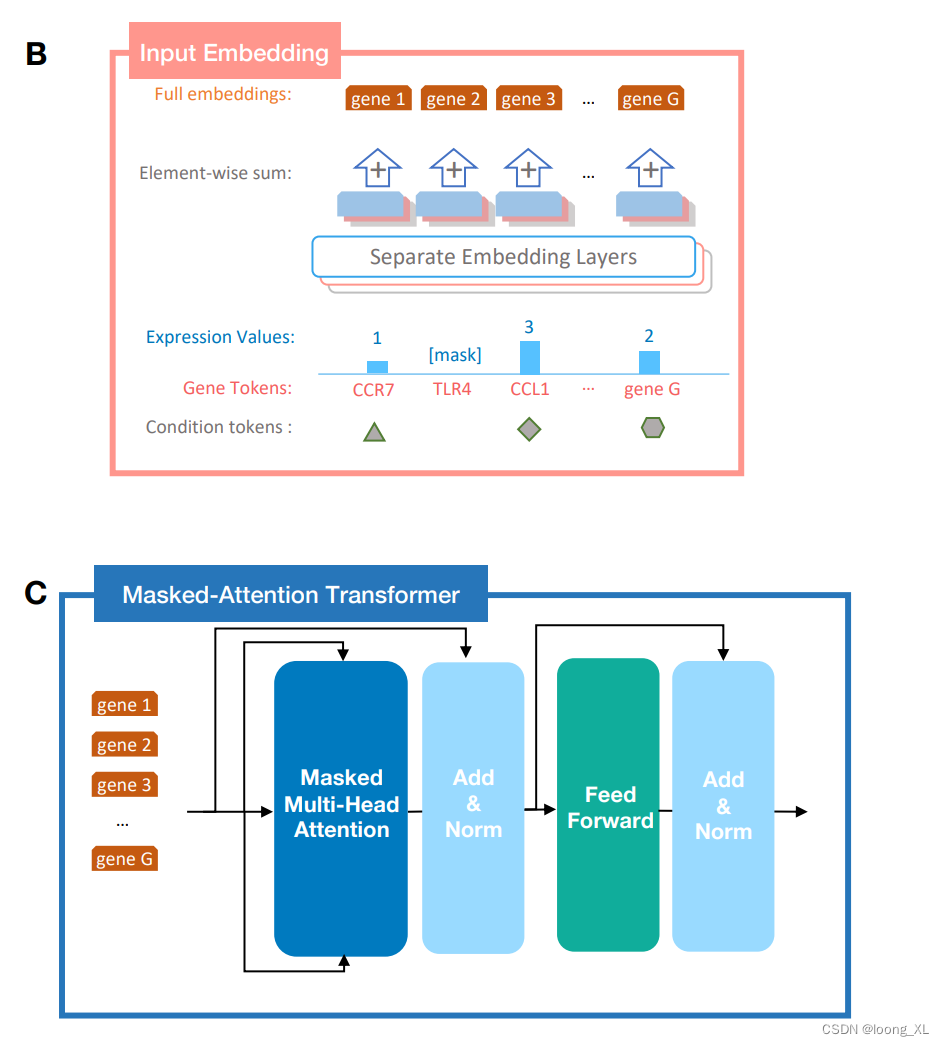
LLM生成模型在生物单细胞single cell的应用:scGPT
参考: https://github.com/bowang-lab/scGPT https://www.youtube.com/watch?vXhwYlgEeQAs 相关算法: 主要是把单细胞测序出来的基因表达量的拼接起来构建成的序列,这里不是用的基因的ATCG,是直接用的基因名称 训练数据&#x…...

力扣15题. 三数之和
题目: 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复…...

项目经理好还是产品经理好?入行必读!
在现代项目管理领域,产品经理Product Manager和项目经理Project Manager,两者虽都是PM,但两者在实际操作中却有着显著的区别,在各自的领域中承担着不同的岗位职责和工作。 项目经理跟产品经理两个证都挺受市场欢迎的,…...
Elastic安装后 postman对elasticsearch进行测试
一、创建索引和mapping //id 字段自增id //good_sn 商品SKU //good_name 商品名称 //good_introduction 商品简介 //good_descript 商品详情 PUT http://IP:9200/shop { "mappings":{ "good":{ "properties":{ …...

JPA (Java Persistence API)
一、Jpa的介绍 JPA ,是一套Sun公司Java官方制定的ORM 规范。 ORM,即 对象关系映射 (Object Relational Mapping),是一种程序技术,用于 在关系数据库和业务实体对象之间做映射 。ORM 框架的存在,…...

实战要求下,如何做好资产安全信息管理
文章目录 一、资产安全信息管理的重要性二、资产安全信息管理的痛点三、如何做好资产安全信息管理1、提升资产安全信息自动化、集约化管理能力,做到资产全过程管理2、做好资产的安全风险识别3、做好互联网暴露面的测绘与管空4、做好资产安全信息的动态稽核管理 “摸…...

NetApp FAS FC SAN存储替换实战:从HP MSA到ONTAP的平滑迁移
1. 项目背景与环境摸底 这次遇到的存储替换项目挺典型的——客户原先用的是HP MSA系列SAN存储,现在要升级到NetApp FAS2750全闪存阵列。现场环境是标准的VMware虚拟化平台,通过FC协议连接存储。说实话,第一次看到旧存储配置时我就发现几个隐患…...

使用Node.js在虚拟机后端服务中集成Taotoken多模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Node.js在虚拟机后端服务中集成Taotoken多模型调用 在虚拟机环境中部署Node.js后端服务时,直接对接多个大模型厂商…...

在Google Cloud上构建OpenAI兼容API网关:无缝对接Vertex AI模型
1. 项目概述:在Google Cloud上搭建你自己的OpenAI兼容API网关 如果你正在寻找一种方法,能够让你手头那些原本为OpenAI ChatGPT设计的应用,无缝对接上Google Cloud Vertex AI的强大模型,比如Gemini Pro、PaLM 2或者Codeyÿ…...
)
玩转OurBMC第二十六期:OpenBMC固件远程更新原理与实践(下)
栏目介绍:“玩转OurBMC” 是OurBMC社区开创的知识分享类栏目,主要聚焦于社区和BMC全栈技术相关基础知识的分享,全方位涵盖了从理论原理到实践操作的知识传递。OurBMC社区将通过 “玩转OurBMC” 栏目,帮助开发者们深入了解到社区文…...

告别混乱!用Cadence Allegro SPB17.4从DXF文件创建PCB封装的完整清洁流程
告别混乱!用Cadence Allegro SPB17.4从DXF文件创建PCB封装的完整清洁流程 在PCB设计领域,从机械图纸(DXF)快速创建精确的封装是工程师常面临的挑战。许多设计师都经历过这样的困扰:导入DXF后,封装在3D预览中…...

GraphQL在后端开发中的应用与优势
在现代后端开发领域,GraphQL作为一种新兴的API查询语言,正迅速改变着开发者构建和交互数据的方式。与传统的RESTful API相比,GraphQL提供了一种更灵活、高效的数据获取机制,使前端能够精准地请求所需数据,避免了过度获…...

Axure中文汉化终极指南:3分钟搞定英文界面,让原型设计更顺手
Axure中文汉化终极指南:3分钟搞定英文界面,让原型设计更顺手 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn …...

从MATLAB到FPGA:高效生成三种波形COE文件的实战指南
1. COE文件格式解析与FPGA应用场景 COE文件是Xilinx FPGA设计中用于初始化Block RAM(BRAM)的标准文件格式。我第一次接触这种文件时,发现它其实就是一个带有特定格式要求的文本文件,但正是这种简单的结构,让它成为MATL…...

【DeepSeek安全防护权威指南】:20年攻防专家亲授Prompt注入3大高危场景与7层防御体系
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Prompt注入防护的演进与现状 随着 DeepSeek 系列大模型在企业级场景中的深度部署,Prompt 注入攻击已从理论威胁演变为高频真实风险。早期防护策略依赖于简单的关键词过滤和长度截断…...

从网线到数据包:手把手拆解以太网帧,搞懂GMAC接口到底在忙啥
从网线到数据包:手把手拆解以太网帧,搞懂GMAC接口到底在忙啥 当我们在浏览器输入一个网址,敲下回车键的瞬间,数据便开始了一场奇妙的旅程。这场旅程的起点,往往是一根不起眼的网线,而GMAC接口则是这场旅程中…...