大模型日报|今日必读的10篇大模型论文

大家好,今日必读的大模型论文来啦!
1.谷歌推出新型 Transformer 架构:反馈注意力就是工作记忆
虽然 Transformer 给深度学习带来了革命性的变化,但二次注意复杂性阻碍了其处理无限长输入的能力。
谷歌研究团队提出了一种新型 Transformer 架构“反馈注意力记忆”(Feedback Attention Memory,FAM),其利用反馈环路使网络能够关注自身的潜在表征。这种设计促进了 Transformer 工作记忆的出现,使其能够处理无限长的序列。TransformerFAM 不需要额外的权重,因此可以与预训练模型无缝集成。
实验表明,TransformerFAM 显著提高了 Transformer 在各种模型大小(1B、8B 和 24B)的长上下文任务中的性能。
论文链接:
https://arxiv.org/abs/2404.09173
2.高通新研究:提高多模态大型语言模型的推理速度
多模态大型语言模型(MLLMs)的推理速度很慢,这是因为其大型语言模型骨干存在内存带宽瓶颈,并且会自动回归生成 toekn。
高通研究团队探讨了如何应用推测解码来提高 MLLM(特别是 LLaVA 7B 模型)的推理效率。研究表明,纯语言模型可以作为使用 LLaVA 7B 进行推测解码的良好草稿模型,从而绕过草稿模型中图像 token 及其相关处理组件的需要。在三个不同任务中进行的实验表明,推测解码可以实现高达 2.37 倍的内存加速。
论文链接:
https://arxiv.org/abs/2404.08856
3.确保 LLM 对齐和安全的 18 个基本挑战
来自剑桥大学的研究团队及其合作者确定了在确保大型语言模型(LLMs)的一致性和安全性方面的 18 个基本挑战。这些挑战被分为三个不同的类别:对 LLMs 的科学理解,开发和部署方法,以及社会技术挑战。他们根据已确定的挑战,提出了 200 多个具体的研究问题。
论文链接:
https://arxiv.org/abs/2404.09932
4.Ctrl-Adapter:使多样的控制适应任意扩散模型的高效和通用的框架
ControlNets 被广泛用于在不同条件下的图像生成中添加空间控制,如深度图、canny 边缘和人体姿态。
然而,在利用预训练图像 ControlNets 进行受控视频生成时,依然存在一些挑战。首先,由于特征空间的不匹配,预训练的 ControlNet 不能直接插入到新的骨干模型中,且为新骨干训练 ControlNet 的成本很高。其次,不同帧的 ControlNet 特征可能不能有效地处理时间一致性问题。
为此,北卡罗来纳大学教堂山分校团队提出了一个高效、通用的框架——Ctrl-Adapter,其可以通过适应预训练的 ControlNets (并改善视频的时间对齐),为任何图像、视频扩散模型添加不同的控件。Ctrl-Adapter 提供多种功能,包括图像控制、视频控制、具有稀疏帧的视频控制、多条件控制、兼容不同的骨干、适应未见过的控制条件和视频编辑。在 Ctrl-Adapter 中,训练适配器层,将预训练的控制网络特征融合到不同的图像、视频扩散模型,同时冻结 ControlNet 和扩散模型的参数。Ctrl-Adapter 由时间模块和空间模块组成,可以有效地处理视频的时间一致性。他们还提出潜在跳跃和逆时间步采样,用于鲁棒自适应和稀疏控制。
此外,Ctrl-Adapter 还能通过简单地取 ControlNet 输出的(加权)平均值来实现多种条件下的控制。凭借各种图像、视频扩散骨干(SDXL、Hotshot-XL、I2VGen-XL 和 SVD), Ctrl-Adapter 在图像控制方面与 ControlNet 不相上下,并在视频控制方面超过所有基线(在 DAVIS 2017 数据集上实现 SOTA 精度),而且计算成本显著降低(少于 10 GPU 小时)。
论文链接:
https://arxiv.org/abs/2404.09967
项目地址:
https://ctrl-adapter.github.io/
5.Tango 2:通过直接偏好优化调整基于扩散的文生视频模型
生成式多模态内容在许多内容创作领域日益流行,因为它有可能让艺术家和媒体人员通过快速将他们的想法带到生活中来创建预制作模型。根据文字提示生成音频,是在音乐和电影行业中这类流程的一个重要方面。
目前,许多基于文生视频的扩散模型专注于在大量提示音频对数据集上训练日益复杂的扩散模型。然而,这些模型并没有明确地关注概念或事件的存在,以及它们在输出音频中与输入提示相关的时间顺序。
来自新加坡科技设计大学的研究团队及其合作者假设关注的是音频生成的这些方面如何在数据有限的情况下提高音频生成的性能。他们使用现有的文本到音频模型 Tango,综合创建了一个偏好数据集,其中每个提示都有一个赢家的音频输出和一些输家的音频输出,供扩散模型学习。从理论上讲,输家的输出可能缺少提示中的一些概念或顺序不正确。
他们在偏好数据集上使用 diffusion-DPO 损失对公开可用的 Tango 文生视频模型进行了微调,并表明它在自动和手动评估指标方面优于 Tango 和 AudioLDM2 的音频输出。
论文链接:
https://arxiv.org/abs/2404.09956
GitHub 地址:
https://github.com/declare-lab/tango
6.Video2Game:将真实世界场景视频转换为现实和交互式游戏环境
创建高质量的交互式虚拟环境,如游戏和模拟器,通常涉及复杂和昂贵的人工建模过程。
来自伊利诺伊大学香槟分校、上海交通大学和康奈尔大学的研究团队提出了一种自动将真实世界场景视频转换为现实和交互式游戏环境的新方法——Video2Game。该系统的有三个核心组件:(1)神经辐射场(NeRF)模块,有效捕捉场景的几何形状和视觉外观(2)一个网格模块,从 NeRF 中提取知识,以更快地渲染(3)物理模块,对物体之间的相互作用和物理动力学进行建模。
通过遵循精心设计的管道,人们可以构建现实世界的可交互和可操作的数字副本。在室内和大规模室外场景上对该系统进行了基准测试证明,该方法不仅可以实时产生高度逼真的渲染,还可以在上面构建交互式游戏。
论文链接:
https://arxiv.org/abs/2404.09833
GitHub 地址:
https://video2game.github.io/
7.北大、快手提出 UNIAA:让多模态大模型更懂人类审美
作为昂贵的专家评估的替代方案,图像美学评估(IAA)是计算机视觉领域的一项重要任务。然而,传统的 IAA 方法通常局限于单一的数据源或任务,限制了其通用性。
为了更好地符合人类的审美,来自北京大学和快手的研究团队提出了一个统一的多模态图像美学评估(UNIAA)框架,包括一个名为 UNIAA-LLaVA 的多模态大型语言模型(MLLM)和一个名为 UNIAA-Bench 的综合基准。他们为 IAA 选择了具有视觉感知和语言能力的 MLLMs,并建立了一种将现有数据集转换为统一的高质量视觉指令微调数据的低成本范式,并以此为基础训练 UNIAA-LLaVA。为了进一步评估 MLLMs 的 IAA 能力,他们构建了由感知、描述和评估 3 个审美层次组成的 UNIAA-Bench。
通过大量实验,验证了 UNIAA 的有效性和合理性。与现有的 MLLMs 相比,UNIAA-LLaVA 在 UNIAA-Bench的所有级别上都实现了有竞争力的性能。该模型在审美感知方面的表现优于 GPT-4V,甚至接近人类(junior-level),MLLMs在 IAA 中有很大的潜力,但仍有很大的改进空间。
论文链接:
https://arxiv.org/abs/2404.09619
8.综述:替代 Transformer 的状态空间模型
近来,状态空间模型(State Space Model,SSM)作为一种可能替代基于自注意力的 Transformer 的方法,受到了越来越多的关注。在这项工作中,来自安徽大学、哈尔滨工业大学和北京大学的研究团队,首先对这些工作进行了全面的综述,并进行了实验比较和分析,从而更好地展示 SSM 的特点和优势。
具体而言,他们首先对 SSM 的原理进行了详细描述,从而帮助读者快速捕捉 SSM 的主要思想;然后,对现有的 SSM 及其各种应用进行综述,包括自然语言处理、计算机视觉、图、多模态多媒体、点云/事件流、时间序列数据等领域。此外,他们还对这些模型进行了统计上的比较和分析,希望能帮助读者了解不同结构在各种任务上的有效性。然后,他们提出了该方向可能的研究方向,从而更好地推动 SSM 理论模型和应用的发展。
论文链接:
https://arxiv.org/abs/2404.09516
GitHub 地址:
https://github.com/Event-AHU/Mamba_State_Space_Model_Paper_List
9.Melodist:实现包含人声和伴奏的可控文生歌曲模型
歌曲是歌声和伴奏的结合,然而,现有的工作主要集中在歌唱声音合成和音乐生成上,很少有人关注歌曲合成。
来自浙江大学的研究团队提出了一项名为“文本到歌曲合成”(text-to-song synthesis)的新任务,其中包含人声和伴奏的生成,他们开发的 Melodist 是一种两阶段文本到歌曲方法,包括歌唱语音合成 (SVS)和人声到伴奏合成 (V2A)。Melodist 利用三塔对比预训练来学习更有效的文本表示,用于可控的 V2A 合成。
为了缓解数据的稀缺性问题,他们构建了一个从音乐网站中挖掘出的中文歌曲数据集。在他们的数据集上的评估结果表明,Melodist 可以合成具有相当质量和风格一致性的歌曲。
论文链接:
https://arxiv.org/abs/2404.09313
项目地址:
https://text2songmelodist.github.io/Sample/
10.Megalodon:具有无限文本长度的高效 LLM 预训练和推理
Transformers 的二次方复杂性和较弱的长度外推能力限制了其扩展至长序列的能力,虽然存在线性注意和状态空间模型等二次方以下的解决方案,但根据经验,它们在预训练效率和下游任务准确性方面都不如 Transformers。
来自南加利福尼亚大学、Meta、卡内基梅隆大学和加利福尼亚大学圣地亚哥分校的研究团队提出了一种用于高效序列建模,并且其上下文长度不受限制的神经架构 Megalodon。Megalodon 继承了 Mega 的指数移动平均线架构,为提高其能力和稳定性,还进一步提出了多种技术组件,包括复杂指数移动平均法(CEMA)、时间步归一化层、归一化关注机制和带两跳残差配置的预归一化。在与 Llama2 的可控正面比较中,Megalodon 在 70亿个参数和2万亿训练 Tokens 的规模上取得了比 transformer 更好的效率。Megalodon 的训练损失为1.70,降落在美洲驼 2-7B (1.75) 和 13B (1.67) 之间。
论文链接:
https://arxiv.org/abs/2404.08801
GitHub 地址:
https://github.com/XuezheMax/megalodon
相关文章:
大模型日报|今日必读的10篇大模型论文
大家好,今日必读的大模型论文来啦! 1.谷歌推出新型 Transformer 架构:反馈注意力就是工作记忆 虽然 Transformer 给深度学习带来了革命性的变化,但二次注意复杂性阻碍了其处理无限长输入的能力。 谷歌研究团队提出了一种新型 T…...
深度学习 Lecture 8 决策树
一、决策树模型(Decision Tree Model) 椭圆形代表决策节点(decison nodes),矩形节点代表叶节点(leaf nodes),方向上的值代表属性的值, 构建决策树的学习过程: 第一步:决定在根节点…...

打包 docker 容器镜像到另一台电脑
# 提交容器为镜像 <container_id> 容器id my_migration_image 镜像名称 docker commit <container_id> my_migration_image # 保存镜像为tar文件 docker save my_migration_image > my_migration_image.tar 在另一台电脑上导入上面的镜像,请…...

贪心算法--购买股票
给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。 在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。 返回 你能获得的 最大 利润 。 示例 1&a…...
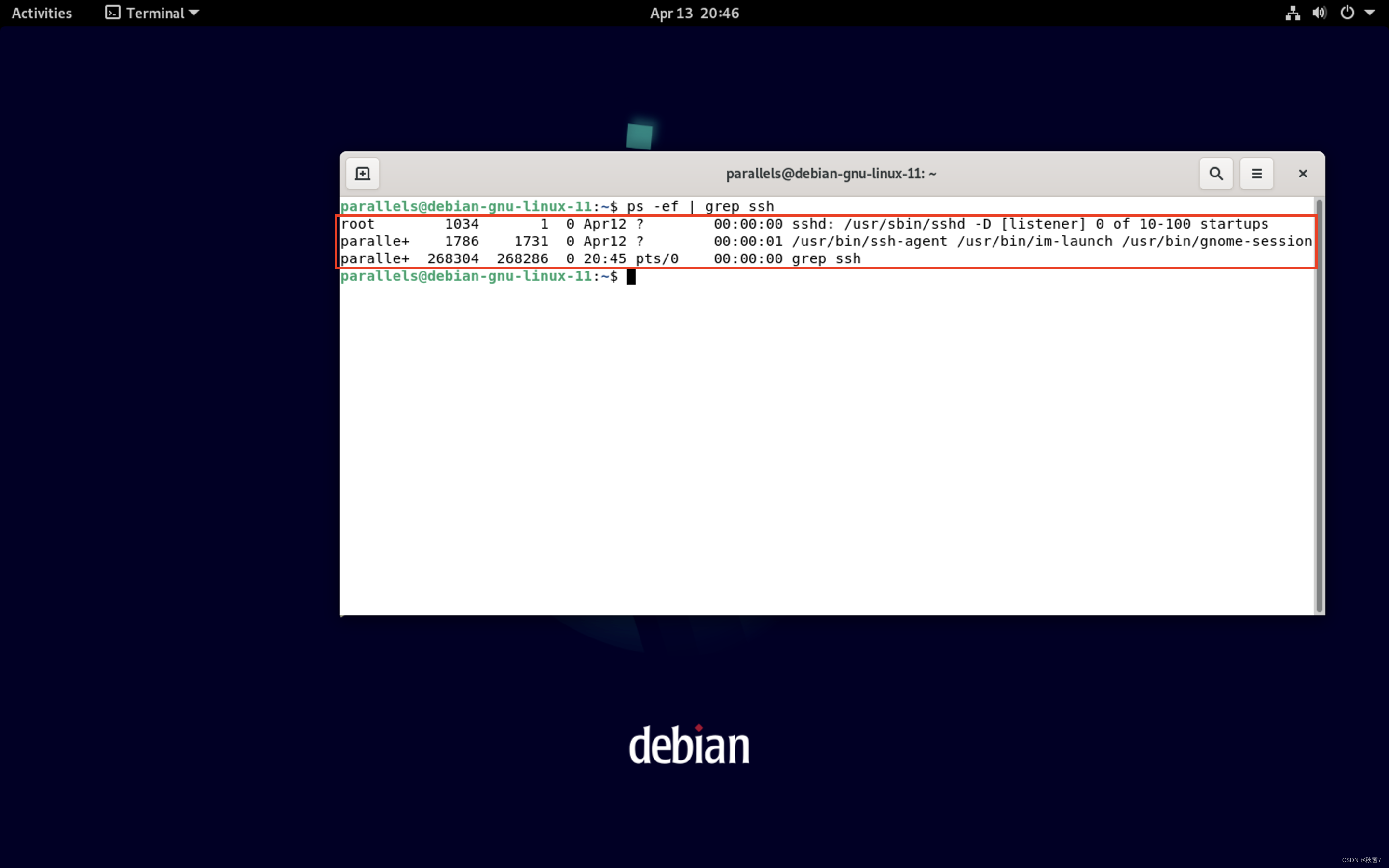
在Mac主机上连接Linux虚拟机
前言 最近醉心于研究Linux,于是在PD上安装了一个Debian Linux虚拟机,用来练练手。但是每次在mac和Linux之间切换很是麻烦,有没有一种方法,可以在mac终端直接连接我的虚拟机,这样在mac终端上就可以直接操控我的Linux虚…...

前端如何单独做虚拟奖金池?
公司业务需求要做一个虚拟奖金池,具体是需求是,不需要后端数据支持,但是又需要不同用户看到的奖金池数据每次变动都是一致的,并且要在给定的最小最大值中变动。 一开始看需求,因为需要所有登录/未登录,不同…...

前端md5校验文件
前端获取文件的md5值,与文件一同传到后端,后端同样对md5值进行校验。如果相同,则文件未被损坏(其实这种方式优点类似于tcp、ip的差错校验,好像token也是这种方式) 项目准备 前端并不可能手写一个算法来实…...
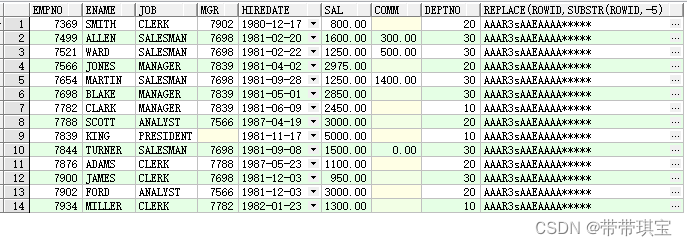
总结SQL相对常用的几个字符函数
目录 字符的截取 substr() trim()、ltrim()、rtrim() 字符串的拼接 ||、 字符的大小写转换 upper(column_name):大写 lower(column_name):小写 字符替换 replace() 搜索字符 instr(column_name, substring_to_find,start,n_appearence) charindex(substring_to_fi…...

云计算笔记
RAID的组合方式 RAID0:多个硬盘同时工作,可提供性能,无冗余机制 RAID1:数据保存多份,提供冗余机制,性能受到影响 RAID3:存在数据盘和单独校验盘,数据写入 至数据盘后需要运算且将…...

网络安全学习路线-超详细
零基础小白,到就业!入门到入土的网安学习路线! 在各大平台搜的网安学习路线都太粗略了。。。。看不下去了! 建议的学习顺序: 一、网络安全学习普法(心里有个数,要进去坐几年!&#x…...

【多模态检索】Coarse-to-Fine Visual Representation
快手文本视频多模态检索论文 论文:Towards Efficient and Effective Text-to-Video Retrieval with Coarse-to-Fine Visual Representation Learning 链接:https://arxiv.org/abs/2401.00701 摘要 近些年,基于CLIP的text-to-video检索方法…...
VRRP——虚拟路由冗余协议
什么是VRRP 虚拟路由冗余协议VRRP(Virtual Router Redundancy Protocol)是一种用于提高网络可靠性的容错协议。 通过VRRP,可以在主机的下一跳设备出现故障时,及时将业务切换到备份设备,从而保障网络通信的连续性和可…...
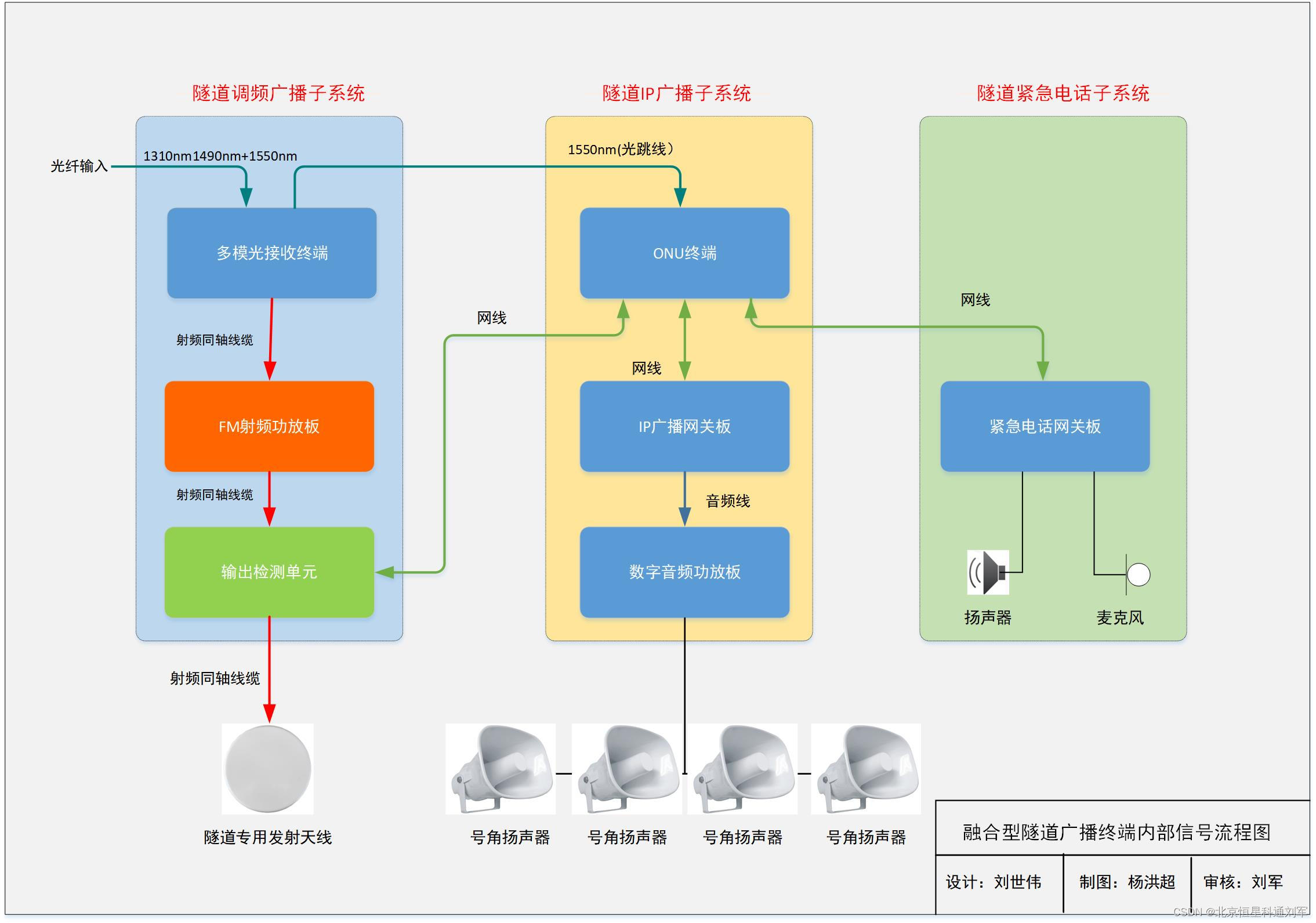
隧道应急广播应该如何搭建?
隧道应急广播系统的搭建需遵循以下关键步骤,确保在紧急情况下能够迅速、准确地传达信息,保障人员安全: 1. 需求分析与规划设计: 明确目标:确定广播系统覆盖范围(如隧道全长、出入口、避难所等关键位置&…...
OpenHarmony实战开发-Worker子线程中解压文件。
介绍 本示例介绍在Worker 子线程使用ohos.zlib 提供的zlib.decompressfile接口对沙箱目录中的压缩文件进行解压操作,解压成功后将解压路径返回主线程,获取解压文件列表。 效果图预览 使用说明 1.点击解压按钮,解压test.zip文件,…...
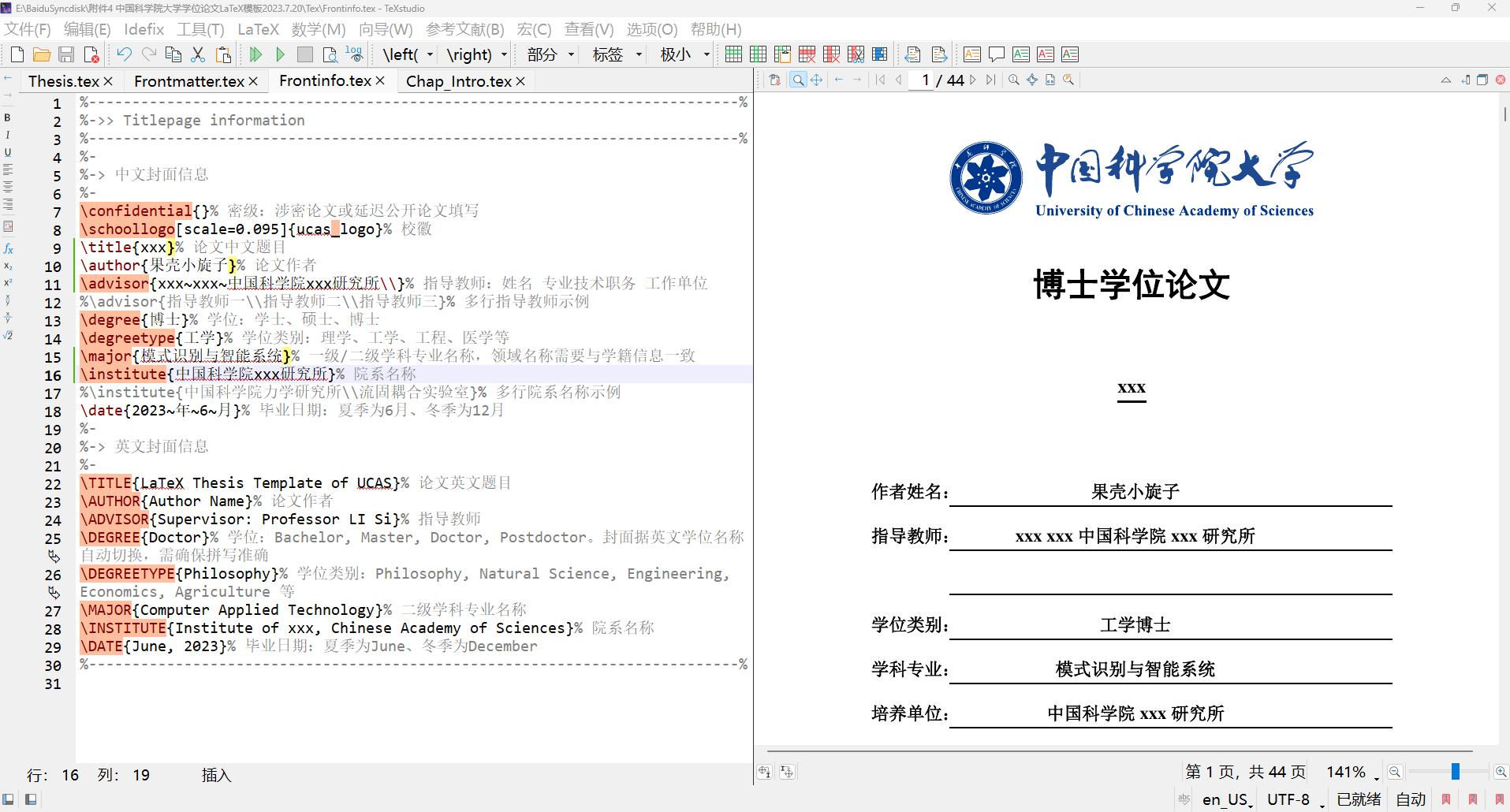
中国科学院大学学位论文LaTeX模版
Word排版太麻烦了,公式也不好敲,推荐用LaTeX模版,全自动 官方模版下载位置:国科大sep系统 → \rightarrow → 培养指导 → \rightarrow → 论文 → \rightarrow → 论文格式检测 → \rightarrow → 撰写模板下载百度云&#…...
秘塔和Kimi AI在资料查询和学习中的使用对比
一、引言 最近老猿在网上查资料时,基本上都使用Kimi AI进行查询,发现其查询资料后总结到位,知识点的准确度较高。今天早上收到一个消息,说新推出的秘塔AI比Kimi更新进,老猿利用在学习的《统计知识学习》简单对比试用了…...

apk反编译
APK文件可以通过多个工具反编译,以便查看包含在其中的Java源文件。但是,需要注意的是,通常通过反编译得到的不是原始的Java源代码,而是反编译后的代码,这意味着它可能已经被转换成了类似于原始Java代码的形式ÿ…...

修改百度百科的词条的方法
百度百科作为国内最大的百科全书网站之一,是广大网民获取各类知识的重要途径之一。所以,如何修改百度百科的词条成为了很多人关心的话题。本文将介绍修改百度百科的方法,并提供一些技巧和注意事项。 注册百度账号 首先,进入百度百…...

更改ip地址的几种方式有哪些
在数字化时代,IP地址作为网络设备的标识,对于我们在网络世界中的活动至关重要。然而,出于多种原因,如保护隐私、访问特定网站或进行网络测试,我们可能需要更改IP地址。虎观代理将详细介绍IP地址的更改方法与步骤&#…...
Flink学习(六)-容错处理
前言 Flink 是通过状态快照实现容错处理 一、State Backends 由 Flink 管理的 keyed state 是一种分片的键/值存储,每个 keyed state 的工作副本都保存在负责该键的 taskmanager 本地中。 一种基于 RocksDB 内嵌 key/value 存储将其工作状态保存在磁盘上&#x…...

对比使用Taotoken前后,个人开发者的月度AI调用成本变化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比使用Taotoken前后,个人开发者的月度AI调用成本变化 在原型开发与日常编码辅助中,频繁调用大模型API已成…...

LeetCode 岛屿数量题解
LeetCode 岛屿数量题解 题目描述 给定一个二维网格地图 1(陆地)和 0(水),计算岛屿的数量。 示例: 输入:grid [ ["1","1","1","1","0"], …...

基于官方API的WhatsApp AI助手集成:规避封号风险与实战部署指南
1. 项目概述:为你的AI助手开通一个安全的WhatsApp专线 如果你正在使用OpenClaw构建自己的AI助手,并且希望它能通过WhatsApp与用户自然交流,那么你很可能已经研究过各种方案了。市面上常见的方案,比如基于 whatsapp-web.js 或 …...

从一次内部渗透测试说起:我是如何利用SSRF漏洞,通过Gopher协议拿下Redis的
渗透测试实战:SSRF漏洞到Redis未授权访问的完整攻击链剖析 在一次常规的企业内部渗透测试中,我发现了一个看似普通的SSRF漏洞,却意外打开了通往内网核心系统的大门。这个故事不是教科书式的漏洞复现,而是一个真实攻击者视角下的完…...

技术突破开源方案:img2latex-mathpix实现公式图像转LaTeX代码的本地化部署
技术突破开源方案:img2latex-mathpix实现公式图像转LaTeX代码的本地化部署 【免费下载链接】img2latex-mathpix Mathpix has changed their billing policy and no longer has free monthly API requests. This repo is now archived and will not receive any upda…...

一图定胜负|虎贲等考 AI 科研绘图:零代码画出期刊级学术图,让论文颜值与专业度双在线
据 Nature 统计,超 90% 的审稿人先看图表,65% 的初审意见直接来自图表质量,一张规范、清晰、专业的学术图,直接影响论文录用与答辩评分。可现实是:Origin、Visio 难学难精通,PPT 做图粗糙不规范,…...
)
别再只会addItem了!QT QComboBox的5个高级用法与实战场景(含完整代码)
别再只会addItem了!QT QComboBox的5个高级用法与实战场景(含完整代码) 在QT开发中,QComboBox可能是最容易被低估的控件之一。很多开发者仅仅把它当作一个简单的下拉选择框,用addItem()填充几个静态选项就草草了事。但实…...

基于Claude API的智能代理框架:从架构设计到实战应用
1. 项目概述:一个面向Claude API的智能代理框架最近在折腾AI应用开发,特别是围绕Anthropic的Claude模型构建自动化工作流时,发现了一个挺有意思的开源项目——CLAUDGENCY。这个项目由开发者Aviralx77创建,本质上是一个专门为Claud…...
:ELK日志采集实战,集中分析接口异常、慢请求和用户上传问题)
Pytorch图像去噪实战(七十三):ELK日志采集实战,集中分析接口异常、慢请求和用户上传问题
Pytorch图像去噪实战(七十三):ELK日志采集实战,集中分析接口异常、慢请求和用户上传问题 一、问题场景:日志散落在各个容器里,排查问题非常痛苦 图像去噪服务上线后,日志会越来越多: FastAPI访问日志 模型推理日志 Nginx访问日志 Worker任务日志 Celery错误日志 GPU异…...

NHSE:5分钟掌握动物森友会存档编辑,打造你的完美岛屿
NHSE:5分钟掌握动物森友会存档编辑,打造你的完美岛屿 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 你是否曾经为了收集某个稀有家具而花费数周时间?是否因为地…...