【大语言模型】应用:10分钟实现搜索引擎
本文利用20Newsgroup这个数据集作为Corpus(语料库),用户可以通过搜索关键字来进行查询关联度最高的News,实现对文本的搜索引擎:
1. 导入数据集
from sklearn.datasets import fetch_20newsgroupsnewsgroups = fetch_20newsgroups()print(f'Number of documents: {len(newsgroups.data)}')
print(f'Sample document:\n{newsgroups.data[0]}')2. 向量化单词
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer()
count.fit(newsgroups.data)
show_vocabulary(count)print(f'Size of vocabulary: {len(count.get_feature_names_out())}')def show_vocabulary(vectorizer):words = vectorizer.get_feature_names_out()print(f'Vocabulary size: {len(words)} words')# we can print ~10 words per linefor l in np.array_split(words, math.ceil(len(words) / 10)):print(''.join([f'{x:<15}' for x in l]))3. 搜索引擎
#将语料库进行转化
corpus_bow = count.transform(newsgroups.data)#提供用户输入,对输入内容进行转化为BoW - Bag of word
query = input("Type your query: ")
query_bow = count.transform([query])from sklearn.metrics.pairwise import cosine_similarity#比较输入内容与语料库中的相似度
similarity_matrix = cosine_similarity(corpus_bow, query_bow)
print(f'Similarity Matrix Shape: {similarity_matrix.shape}')![]()
得到Similarity_matrix一共有N行,表示语料库中的文档数。还有一列,代表相似度系数。
第K行的相似度系数,代表用户输入的文本与语料库中第K个文档的相似程度。
我们对相似度矩阵进行排序:
similarities = pd.Series(similarity_matrix[:, 0])
similarities.head(10)那么和用户输入最相关的文档就是第一个了!
print('Best document:')
print(newsgroups.data[top_10.index[0]])结论:本文利用Cosine_similarity比较文档的相似度,从语料库找出最佳匹配的文档。
如果对单词的向量化,BoW概念有问题可以看下我的另一篇文章。
CSDN
下面一篇文章我会具体分析Cosine_similarity的原理,敬请关注!
相关文章:
【大语言模型】应用:10分钟实现搜索引擎
本文利用20Newsgroup这个数据集作为Corpus(语料库),用户可以通过搜索关键字来进行查询关联度最高的News,实现对文本的搜索引擎: 1. 导入数据集 from sklearn.datasets import fetch_20newsgroupsnewsgroups fetch_20newsgroups()print(fNu…...

UT单元测试
Tips:在使用时一定要注意版本适配性问题 一、Mockito 1.1 Mock的使用 Mock 的中文译为仿制的,模拟的,虚假的。对于测试框架来说,即构造出一个模拟/虚假的对象,使我们的测试能顺利进行下去。 Mock 测试就是在测试过程…...
leetcode-合并两个有序链表
目录 题目 图解 方法一 方法二 代码(解析在注释中) 方法一 编辑方法二 题目 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 示例 1: 输入:l1 [1,2,4], l2 [1,3,4] 输出:[1,1…...
006Node.js cnpm的安装
百度搜索 cnpm,进入npmmirror 镜像站https://npmmirror.com/ cmd窗口输入 npm install -g cnpm --registryhttps://registry.npmmirror.com...

web server apache tomcat11-01-官方文档入门介绍
前言 整理这个官方翻译的系列,原因是网上大部分的 tomcat 版本比较旧,此版本为 v11 最新的版本。 开源项目 同时也为从零手写实现 tomcat 提供一些基础和特性的思路。 minicat 别称【嗅虎】心有猛虎,轻嗅蔷薇。 系列文章 web server apac…...

java的总结
由于最近已经开始做项目了,所以对java的基础知识的学习都是一个离散化的状态没有一个很系统的学习,都是哪里不会就去学哪里。 先来讲一下前后端的区别吧 在我的理解前端就是:客户端在前端进行点击输入数据,前端将这些数据整合起来…...
解决npm run dev跑项目,发现node版本不匹配,怎么跑起来?【已解决】
首先问题点就是我们npm run dev 运行项目的时候发现出错,跑不起来,类型下面这种 这里的出错的原因在于我们的node版本跟项目的版本不匹配 解决办法 我这里的问题是我的版本是node14的,然后项目需要node20的,执行下面的就可以正…...
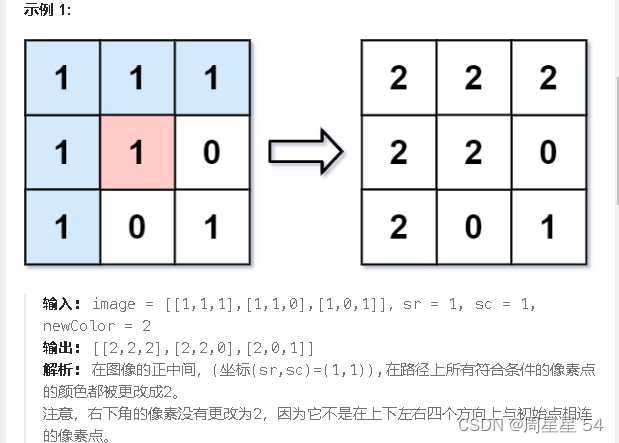
flood_fill 算法|图形渲染
flood fill 算法常常用来找极大连通子图,这是必须掌握的基本算法之一! 图形渲染 算法原理 我们可以利用DFS遍历数组把首个数组的值记为color,然后上下左右四个方向遍历二维数组数组如果其他方块的值不等于color 或者越界就剪枝 return 代码…...
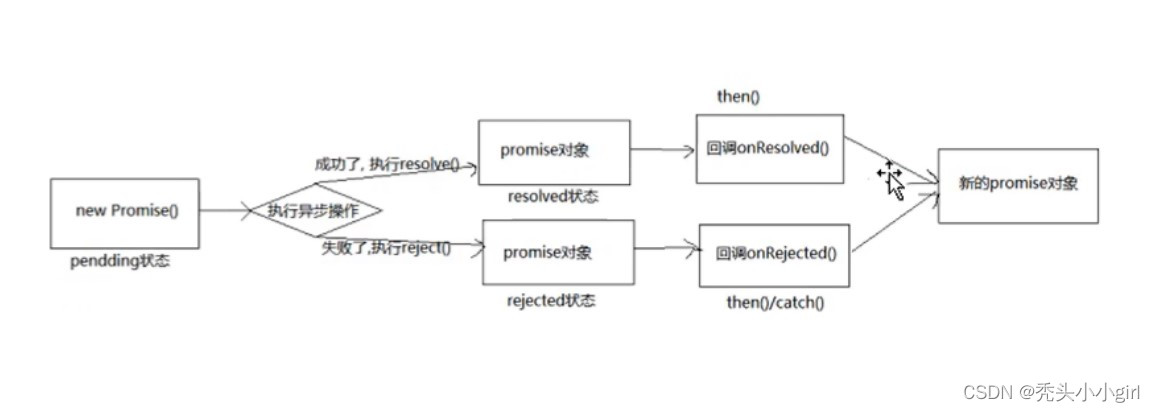
Promise简单概述
一. Promise是什么? 理解 1.抽象表达: Promise是一门新的技术(ES6规范) Promise是JS中进行异步编程的新解决方案(旧方案是单纯使用回调函数) 异步编程:包括fs文件操作,数据库操作(Mysql),AJAX,定时器 2.具…...
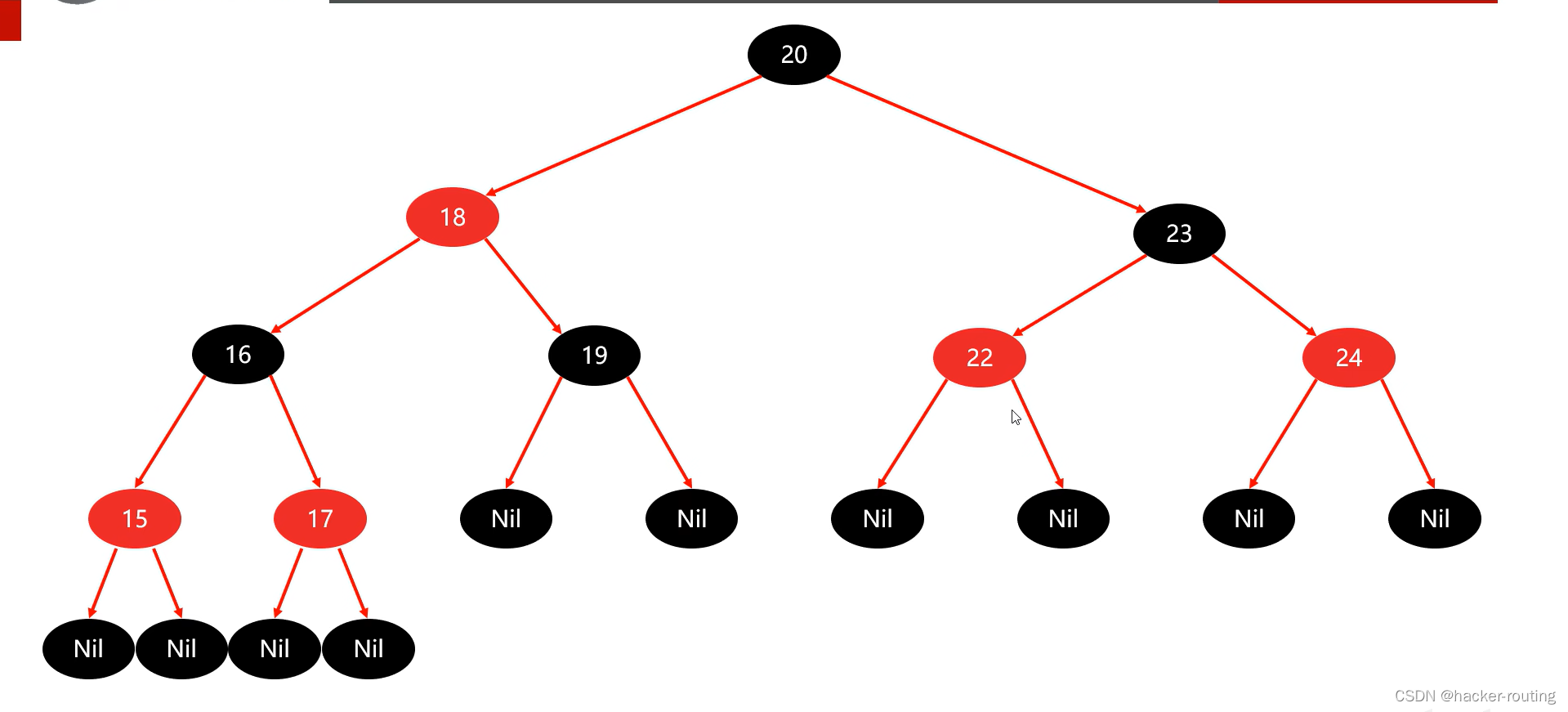
【Java集合进阶】数据结构(平衡二又树旋转机制)数据结构(红黑树、红黑规则、添加节点处理方案详解)
🍬 博主介绍👨🎓 博主介绍:大家好,我是 hacker-routing ,很高兴认识大家~ ✨主攻领域:【渗透领域】【应急响应】 【Java】 【VulnHub靶场复现】【面试分析】 🎉点赞➕评论➕收藏 …...
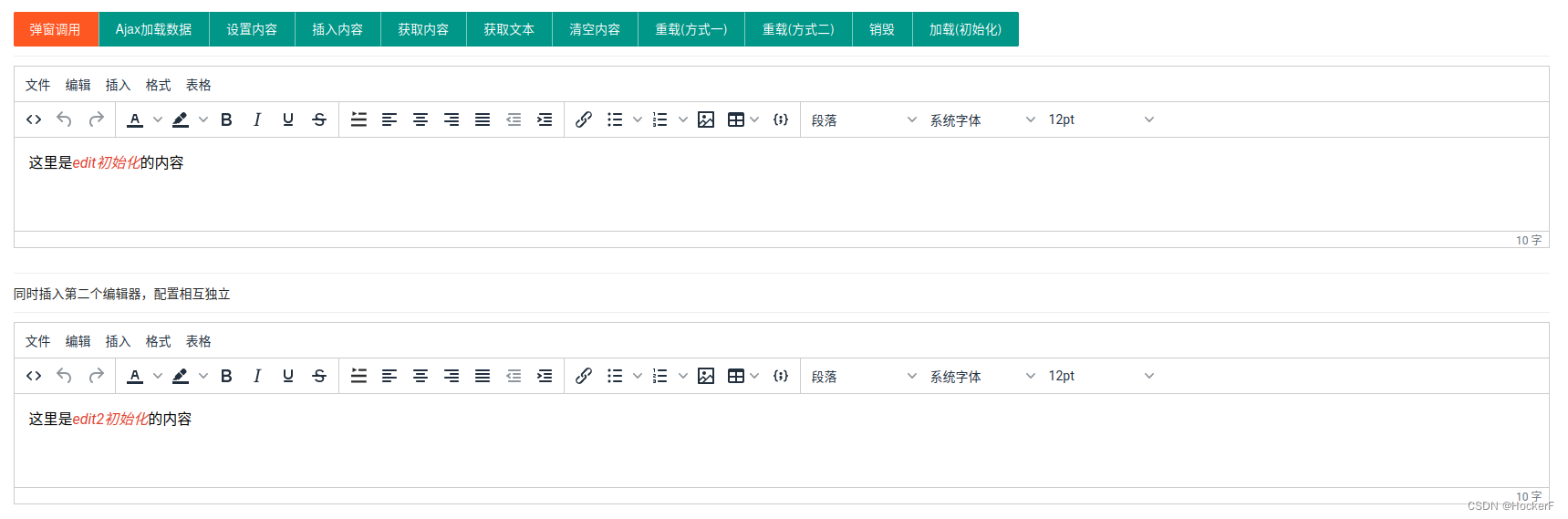
富文本在线编辑器 - tinymce
tinymce 项目是一个比较好的富文本编辑器. 这里有个小demo, 下载下来尝试一下, 需要配置个本地服务器才能够访问, 我这里使用的nginx, 下面是我的整个操作过程: git clone gitgitee.com:chick1993/layui-tinymce.git cd layui-tinymcewget http://nginx.org/download/nginx-1.…...
从汇编代码理解数组越界访问漏洞
数组越界访问漏洞是 C/C 语言中常见的缺陷,它发生在程序尝试访问数组元素时未正确验证索引是否在有效范围内。通常情况下,数组的索引从0开始,到数组长度减1结束。如果程序尝试访问小于0或大于等于数组长度的索引位置,就会导致数组…...

skynet 使用protobuf
一、安装protobuf 下面的操作方法都是在 centos 环境下操作 #下载 Protocol Buffers 源代码: #您可以从 Protocol Buffers 的 GitHub 仓库中获取特定版本的源代码。使用以下命令克隆仓库 git clone -b v3.20.3 https://github.com/protocolbuffers/protobuf.git#编译…...

Vue Router 4 与 Router 3 路由配置与区别
文章目录 路由安装路由配置vue-router 3.x版本写法配置路由使用路由 vue-router 4.x版本写法配置路由使用路由 Vue Router 4 与 Vue Router 3 区别 路由安装 Vue 2 (使用 Vue Router 3) :npm install vue-router3 Vue 3 (使用 Vue Router 4) :npm insta…...

python借助elasticsearch实现标签匹配计数
给定一组标签 [{“tag_id”: “1”, “value”: “西瓜”}, {“tag_id”: “1”, “value”: “苹果”}],我想精准匹配到现有的标签库中存在的标签并记录匹配成功的数量。 标签id(tag_id)标签名(tag_name)标签值(tag_name )1水果西瓜1水果苹果1水果橙子2动物老虎 …...
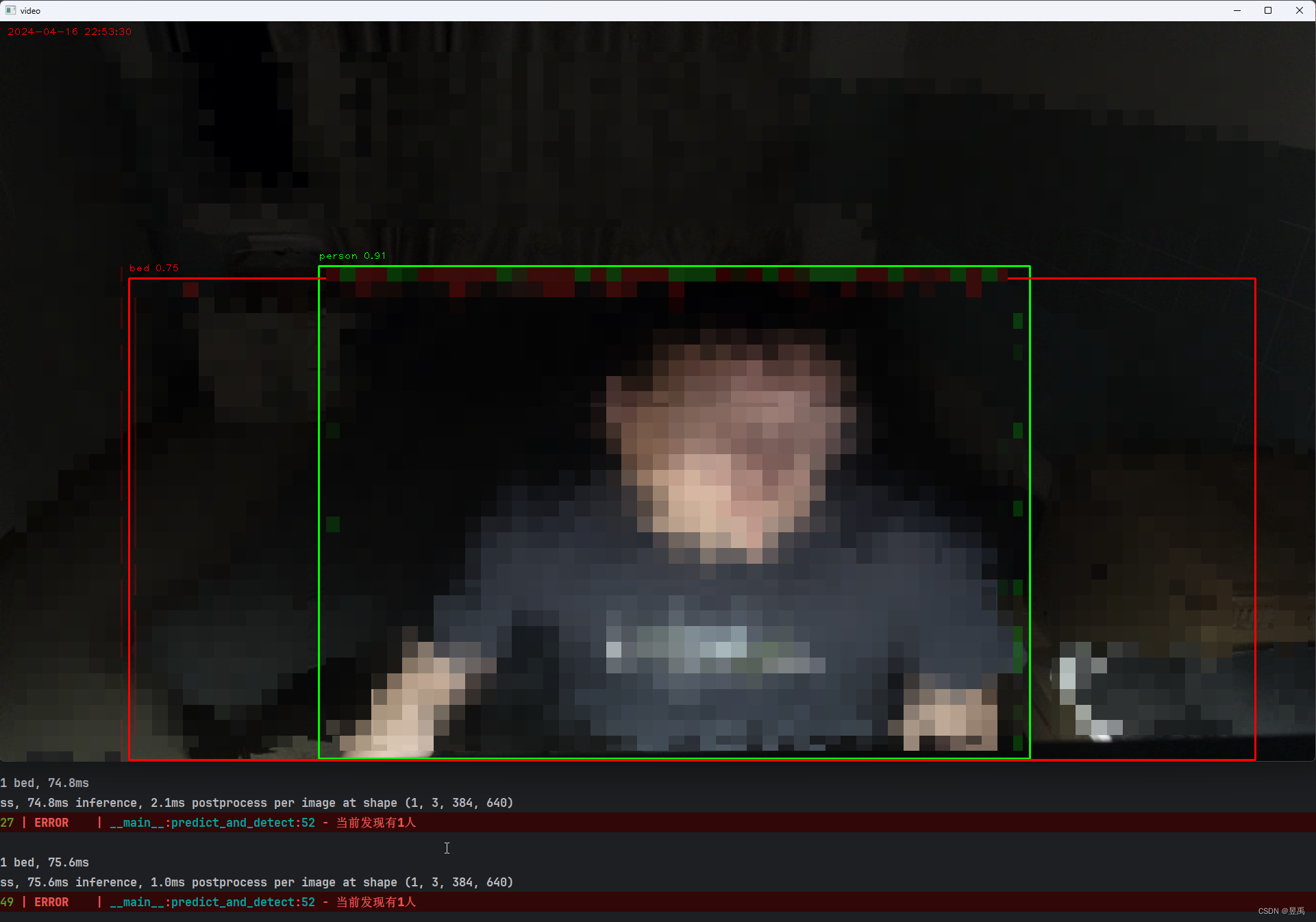
Yolo-world+Python-OpenCV之摄像头视频实时目标检测
上一次介绍了如何使用最基本的 Yolo-word来做检测,现在我们在加opencv来做个实时检测的例子 基本思路 1、读取离线视频流 2、将视频帧给yolo识别 3、根据识别结果 对视频进行绘制边框、加文字之类的 完整代码如下: import datetimefrom ultralytics …...
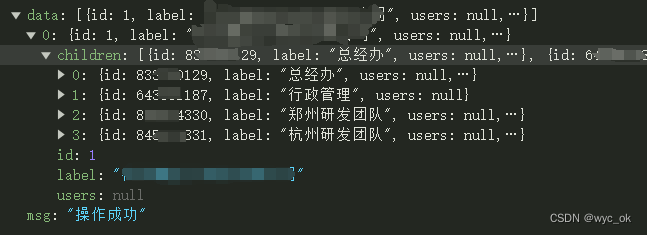
vue-treeselect 的基本使用
vue-treeselect 的基本使用 1. 效果展示2. 安装 插件3. 引入组件4. 代码 1. 效果展示 2. 安装 插件 vue-treeselect是一个树形的下拉菜单,至于到底有多少节点那就要看你的数据源有多少层了,挺方便的。下面这个这个不用多说吧,下载依赖 npm in…...

Vue(二)
文章目录 1.条件渲染1.关于js中的false的判定2.基本介绍3.v-if1.需求分析2.代码实例 4.v-show实现5.v-if与v-show比较6.课后练习 2.列表渲染1.代码实例2.课后练习 3.组件化编程1.基本介绍2.实现方式一_普通方式2.实现方式二_全局组件方式3.实现方式三_局部组件方式 4.生命周期和…...

Python基于深度学习的车辆特征分析系统
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...

推理还原的干货
故事的递进还原 从下层故事到上层故事 设定还原 还原的逻辑 隐藏信息拼凑、因果导致果推因、规则还原现象 设计思路: 真解答 真解答的关键信息 推理逻辑链 哪些环节可以被误导 如何把关键信息变成伪解答 解释变形信息 给出识别变形信息的方法或线索 其实看似一个…...

从愚人节玩笑到工程实践:四个软硬件结合的创意项目技术拆解
1. 从愚人节玩笑到工程师的创意沙盘每年四月一日,总有些介于荒诞与现实之间的“产品”构想冒出来,在工程师社区里引发一阵会心一笑。但如果你仔细琢磨,会发现这些看似玩笑的点子,往往藏着一丝对技术边界、用户体验乃至市场需求的犀…...

航空摇篮长岛:从早期飞行到现代航空工业的技术演进与创新集群
1. 项目概述:从长岛的天空回望航空摇篮如果你对航空史感兴趣,或者像我一样,是个对机械、工程和人类如何突破物理极限着迷的工程师,那么“长岛”这个名字绝对绕不开。它不仅仅是纽约市旁边的一个地理名词,在航空史上&am…...

CV前沿论文实战解码:轻量化与多模态对齐的工程落地指南
1. 这不是“论文速递”,而是一份面向实战者的CV研究动态解码指南你点开这个标题,大概率不是为了收藏一份PDF列表,而是想快速判断:这篇新出的视觉论文,值不值得我花三小时精读?它背后的技术思路,…...

进化发育生物学启发AI新范式:基因调控、弱连接与局部变异选择
1. 项目概述:从生物进化到机器学习的范式迁移在人工智能领域,我们常常陷入一种“局部最优”的困境:模型越做越大,参数越来越多,但系统的根本“智慧”——比如持续学习新任务而不遗忘旧知识、灵活重组已有技能解决新问题…...

ARM GICv5 IRS寄存器架构与缓存控制机制详解
1. ARM GICv5 IRS寄存器架构解析中断控制器(GIC)是现代SoC设计中不可或缺的核心组件,负责高效管理和分发系统中各类中断请求。GICv5版本引入的中断路由服务(IRS)模块代表了ARM架构在中断处理领域的重大革新。IRS通过精心设计的寄存器组实现了前所未有的中断管理灵活…...

AsyncRun.vim 项目根目录管理:智能识别和高效利用
AsyncRun.vim 项目根目录管理:智能识别和高效利用 【免费下载链接】asyncrun.vim :rocket: Run Async Shell Commands in Vim 8.0 / NeoVim and Output to the Quickfix Window !! 项目地址: https://gitcode.com/gh_mirrors/as/asyncrun.vim AsyncRun.vim 是…...

MCP Loom:快速构建AI工具与数据连接器的开发框架
1. 项目概述:MCP Loom,一个连接AI与真实世界的“织布机”如果你最近在折腾AI应用开发,特别是想让你的AI助手(比如Claude、Cursor等)能直接操作你电脑上的文件、数据库,甚至调用外部API,那么你很…...

基于MCP的AI智能体:自动化与优化亚马逊DSP广告实战指南
1. 项目概述:用AI智能体管理亚马逊DSP广告如果你正在寻找一种更高效、更智能的方式来管理亚马逊需求方平台(Amazon DSP)的广告活动,那么这个项目可能就是为你准备的。作为一个在程序化广告领域摸爬滚打了十多年的从业者࿰…...

量子噪声对机器学习模型的影响与优化策略
1. 量子噪声与机器学习模型的复杂博弈在量子计算领域,噪声问题就像一位不请自来的客人,总是干扰着我们的计算过程。特别是在量子机器学习(QML)中,噪声的影响更为微妙且复杂。我最近使用Qiskit平台进行了一系列实验,试图揭示不同类…...

gogoclaw:基于文件与技能的自主智能体运行时设计与实践
1. 项目概述:一个以文件为基石的自主智能体运行时如果你和我一样,对市面上那些“黑盒”式的AI智能体框架感到厌倦,总觉得它们把太多逻辑和状态藏在运行时深处,调试和扩展起来像在拆盲盒,那么gogoclaw这个项目可能会让你…...