深入理解JVM中的G1垃圾收集器原理、过程和参数配置
在Java虚拟机(JVM)中,垃圾收集(GC)是一个自动管理内存的过程,旨在回收不再使用的对象所占用的内存空间。G1垃圾收集器(G1 GC)是JVM中的一种重要垃圾收集器,尤其适用于需要低延迟和可预测停顿时间的大型应用程序。本文将深入探讨G1垃圾收集器的工作原理、关键特性和性能优化建议。
目录
- 一、G1收集器概述
- 主要特点
- 二、G1分区划分
- 三、为什么G1收集器需要设计巨型对象
- 四、G1收集器的回收过程
- 五、G1的两种回收策略
- 5.1 Young GC(新生代回收)
- 5.2 Mix GC(混合回收)
- 六、跨代引用和RSet(记忆集)
- 七、性能优化建议
- 八、G1核心配置参数
- 九、结语
一、G1收集器概述
G1收集器(Garbage-First Garbage Collector,简称G1 GC)是Java虚拟机(JVM)中的一种垃圾收集器,专为服务器端应用设计,特别适用于具有多核处理器和大内存的机器。G1 GC在JDK 7u4版本中被正式推出,并且在JDK 9中成为默认的垃圾收集器。它的主要目标是在满足高吞吐量的同时,尽可能缩短垃圾收集造成的停顿时间。
主要特点
- 并行与并发:G1 GC能够充分利用多核处理器的优势,通过并行执行垃圾收集任务来提高效率。同时,它的大部分工作都是与应用线程并发执行的,从而减少了停顿时间。
- 分区域收集:G1 GC将整个堆内存划分为多个大小相等的独立区域(Region),这些区域在逻辑上是连续的,但在物理内存上可能不是连续的。每个Region都可以扮演Eden区、Survivor区或Old区等角色。这种设计使得G1 GC能够更加灵活地进行内存管理和垃圾收集。
- 优先回收垃圾最多区域:G1 GC通过跟踪每个Region中的垃圾堆积情况,并根据回收价值和成本进行排序,优先回收垃圾最多的Region。这种策略有助于最大限度地提高垃圾收集的效率。
- 可预测的停顿时间:G1 GC通过建立一个可预测的停顿时间模型,允许用户明确指定在一个特定时间片段内,垃圾收集所造成的停顿时间不得超过某个阈值。这使得G1 GC非常适合需要严格控制停顿时间的应用场景。
- 使用标记-整理算法:在整体上,G1 GC使用标记-整理算法来回收内存,以减少内存碎片的产生。但在两个Region之间进行垃圾收集时,它则采用标记-复制算法。这种组合策略有助于兼顾内存利用率和垃圾收集效率。
二、G1分区划分
G1收集器的分区划分是其核心特性之一,它允许G1更灵活、高效地管理内存和执行垃圾回收:
-
基本思想:
G1收集器将整个Java堆划分为多个大小相等、独立的区域,这些区域被称为“Region”。每个Region的大小可以根据堆空间的实际大小而定,通常在1MB到32MB之间,且必须是2的N次幂。这意味着Region的大小可以是1MB、2MB、4MB、8MB、16MB或32MB。默认情况下,整个堆空间被划分为约2048个这样的Region。 -
分区类型:
G1的Region可以根据其用途和状态分为不同类型。主要包括:- 自由分区(Free Heap Region, FHR):这些Region当前没有包含任何对象,是空闲的,可以用于新的对象分配。
- 新生代分区(Young Heap Region, YHR):这些Region被划分为新生代,包括Eden区和Survivor区。新生代分区主要用于存储新创建的对象。
- 大对象分区(Humongous Heap Region, HHR):专门用于存储大对象。在G1中,只要对象的大小超过了一个Region容量的一半,就被认为是大对象。这些对象会被直接分配到Humongous Region中,且每个大对象都单独占用一个或多个连续的Humongous Region。
- 老年代分区(Old Heap Region, OHR):这些Region被划分为老年代,用于存储长时间存活的对象。

-
分区的管理和回收:
G1收集器通过维护一个优先列表来跟踪各个Region中的垃圾堆积情况和回收价值。在垃圾回收过程中,G1会根据这个列表优先回收价值最大的Region。这种策略使得G1能够更有效地利用处理器资源,并最大限度地减少垃圾回收造成的停顿时间。 -
优点:
G1的分区划分带来了几个显著优点。首先,它允许更细粒度的内存管理,提高了内存的利用率。其次,通过优先回收垃圾最多的Region,G1能够保持较高的吞吐量并缩短停顿时间。最后,G1的分区策略使其能够很好地适应不同的内存大小和垃圾回收需求。
三、为什么G1收集器需要设计巨型对象
G1收集器需要设计巨型对象(Humongous Objects)主要是出于对内存管理和垃圾收集效率的考虑。在G1收集器的设计中,整个堆内存被划分为多个大小相等的区域(Region),每个Region用于存放对象。然而,有些对象的大小可能会超过一个Region的容量,这就引出了巨型对象的概念。
巨型对象是指那些大小超过了一个Region容量50%以上的对象。由于这些对象太大,无法完整地存放在一个Region中,因此需要特殊处理。G1收集器通过引入巨型对象的概念,并为之设计专门的存储和管理机制,确保了这些大对象能够被有效地管理和回收。
具体来说,巨型对象在G1中被直接分配到特殊的Humongous Region中,每个巨型对象可以独占一个或多个连续的Humongous Region。这样做的好处是可以避免由于对象跨Region存储而导致的复杂性和性能开销。同时,G1收集器还会针对巨型对象进行特殊的垃圾回收策略,以提高垃圾收集的效率和整个系统的性能。
此外,巨型对象的设计也考虑到了应用的实际情况和需求。在实际应用中,往往存在一些需要占用大量内存的大对象,如大型的数组、数据结构等。如果不对这些大对象进行特殊处理,它们可能会对整个垃圾收集器的性能和内存利用率造成负面影响。因此,G1收集器通过设计巨型对象及其管理机制来应对这一挑战。
综上所述,G1收集器需要设计巨型对象主要是为了更有效地管理大内存对象,提高垃圾收集效率和整个系统的性能。
四、G1收集器的回收过程
G1收集器的回收过程主要包括以下几个步骤:
-
初始标记(Initial Marking):
这个过程是STW(Stop-The-World)的,但通常耗时非常短。它标记出从GC Roots直接可达的对象,作为后续垃圾收集的基础。 -
并发标记(Concurrent Marking):
在初始标记完成后,G1 GC会进入并发标记阶段。这个阶段与应用程序线程并发执行,通过递归地追踪所有可达的对象,并将它们标记为存活。这个过程是并发的,因此不会阻塞应用程序的执行。 -
最终标记(Final Marking):
为了处理在并发标记过程中新产生的对象引用关系,G1 GC会执行一次短暂的STW的最终标记。这个阶段确保所有在并发标记阶段漏掉的对象都被正确标记。 -
筛选回收(Live Data Counting and Evacuation):
在这个阶段,G1 GC会根据每个Region的垃圾堆积情况和回收价值进行排序,并选择性地回收部分Region中的垃圾对象。回收过程包括将存活的对象从一个Region复制或移动到另一个Region,并更新相关的引用。这个过程也是并发的,旨在最大限度地减少停顿时间。同时,这个阶段可能会涉及到对象的整理和压缩,以减少内存碎片。
此外,G1收集器还采用了分区(Region)的方式来管理内存,每个Region都被标记了不同的状态(如Eden、Survivor、Old等)。这种设计使得G1能够更灵活地进行内存分配和垃圾回收,从而提高了整体的效率和性能。
值得注意的是,G1收集器还提供了两种主要的垃圾回收模式:Young GC和Mixed GC。Young GC主要负责回收新生代中的垃圾对象,而Mixed GC则负责回收新生代和部分老年代中的垃圾对象。这两种模式都是根据堆内存的使用情况和GC的触发条件来自动选择的。
五、G1的两种回收策略
G1垃圾收集器是Java虚拟机(JVM)中的一个重要组件,它提供了两种主要的垃圾回收策略:Young GC(新生代回收)和Mix GC(混合回收)。这两种策略在回收对象和回收区域上有所不同,但都是为了提高垃圾回收的效率,减少停顿时间,从而提升应用程序的性能。
5.1 Young GC(新生代回收)
Young GC主要负责回收新生代中的对象。新生代通常包含新创建的对象,这些对象更有可能在短时间内变成垃圾。Young GC的执行过程相对较快,因为它只涉及新生代中对象的扫描和回收。
在Young GC过程中,Eden区和Survivor区的存活对象会被复制到另一个Survivor区或者晋升到老年代。这个过程是Stop-The-World(STW)的,意味着在回收过程中,应用程序的所有线程都会被暂停。但是,由于新生代中的对象通常较少,因此这个暂停时间通常较短,对应用程序的性能影响也较小。
5.2 Mix GC(混合回收)
Mix GC则是G1收集器特有的回收策略,它不仅回收新生代中的所有Region,还会回收部分老年代中的Region。这种策略的目标是在保证停顿时间不超过预期的情况下,尽可能地回收更多的垃圾对象。
在Mix GC过程中,首先会进行全局并发标记(global concurrent marking),这个过程是并发的,与应用程序线程同时执行,用于标记出所有存活的对象。然后,在回收阶段,G1会根据标记结果选择收益较高的部分老年代Region和新生代Region一起进行回收。这个选择过程是基于对Region中垃圾对象的数量和回收价值的评估。
与Young GC不同,Mix GC的停顿时间可能会更长,因为它涉及到对老年代中对象的扫描和回收。但是,由于Mix GC能够回收更多的垃圾对象,因此它通常能够更有效地释放内存空间,减少垃圾堆积对应用程序性能的影响。
六、跨代引用和RSet(记忆集)
在垃圾收集过程中,跨代引用或跨Region引用是一个需要特别注意的现象:
-
跨代引用的概念:
在垃圾收集领域,跨代引用指的是不同代际之间的对象相互引用。在G1收集器中,由于堆被划分为多个Region,跨代引用通常表现为跨Region引用。年轻代指向老年代的引用在垃圾收集中不是主要问题,因为即使年轻代的对象被清理,程序仍然可以正常运行,且未被标记到的老年代对象会在后续的Major GC中被回收。 -
老年代指向年轻代的引用问题:
当存在老年代指向年轻代的引用时,情况就复杂了。在Minor GC阶段,我们不能简单地清理年轻代中的对象,因为老年代中可能还有对象持有对这些对象的引用。为了解决这个问题,我们需要一种机制来跟踪这些跨Region的引用。 -
RSet(记忆集)的作用:
RSet正是为了解决这个问题而设计的。它的主要作用是记录哪些Region中的老年代对象有指向年轻代的引用。在GC时,通过扫描这些Region中的RSet,我们可以快速识别出需要保留的年轻代对象,从而避免扫描整个老年代,显著提高了垃圾收集的效率。RSet的实现本质上是一种哈希表,其中Key是Region的起始地址,Value是一个集合,存储了卡表的索引号。
RSet(RememberedSet)是一个非常重要的数据结构,用于记录并跟踪其他Region指向当前Region中对象的引用。在G1收集器的分区模型中,由于堆内存被划分为多个独立的Region,对象之间的引用关系可能跨越不同的Region。为了能够在垃圾收集过程中正确地识别和处理这些跨Region的引用,G1引入了RSet的概念。
每个Region都有一个与之关联的RSet,用于记录其他Region中指向该Region内对象的引用信息。当发生对象引用关系变化时,G1会更新相应的RSet,以确保垃圾收集的准确性。在垃圾收集过程中,G1会利用RSet来快速确定哪些Region之间存在引用关系,从而避免不必要的全堆扫描,提高垃圾收集的效率。
RSet的实现通常涉及一些优化技术,如使用位图(Bitmaps)或压缩表(CompressedTables)来紧凑地存储引用信息,以减少内存占用和提高访问速度。此外,G1还采用了一些策略来维护RSet的一致性,如在并发标记阶段使用写屏障(Write Barriers)来拦截并更新跨Region的引用。
-
减少YGC时的扫描开销:
由于新生代的垃圾收集通常很频繁(即YGC),如果每次都需要扫描整个老年代来确定是否有对新生代的引用,那么开销将会非常大。通过RSet的跟踪机制,我们可以精确地知道哪些老年代Region中的对象引用了新生代对象,从而只扫描这些Region,大大降低了YGC时的扫描开销。 -
卡标记(Card Marking)技术与卡表(Card Table):
HotSpot JVM为了更高效地处理老年代到新生代的引用问题,采用了卡标记技术。具体来说,它使用了一个称为卡表(Card Table)的数据结构来辅助标记过程。堆空间被划分为一系列的卡页(Card Page),每个卡页对应卡表中的一个标记项。当发生对老年代到新生代引用的写操作时,通过写屏障(Write Barrier)机制来更新卡表中对应的标记项。这样,在GC时,我们只需要扫描那些被标记为dirty的卡页所对应的Region即可快速找到所有老年代到新生代的引用关系。
七、性能优化建议
-
合理设置堆大小:根据应用程序的内存需求和硬件资源,合理设置JVM的堆大小。过大的堆可能会导致长时间的垃圾收集停顿,而过小的堆则可能导致频繁的垃圾收集。
-
调整停顿时间目标:通过调整G1的停顿时间目标(-XX:MaxGCPauseMillis参数),可以平衡垃圾收集的效率和应用程序的响应时间。在需要低延迟的场景中,可以设置较短的停顿时间目标。
-
启用并行垃圾收集线程:通过增加并行垃圾收集线程的数量(-XX:ParallelGCThreads参数),可以提高垃圾收集的效率。然而,过多的线程可能会导致系统资源的竞争和额外的开销,因此需要谨慎调整。
-
优化对象分配和晋升策略:通过优化对象的分配和晋升策略,可以减少新生代和老年代之间的对象流动,从而降低垃圾收集的开销。例如,可以考虑使用对象池、缓存等技术来减少临时对象的创建和销毁。
-
监控和分析GC日志:定期监控和分析GC日志可以帮助识别潜在的内存泄漏、性能瓶颈和优化机会。可以使用JVM自带的工具(如jstat、jvisualvm)或第三方工具(如GCViewer、YourKit)来进行日志分析和性能调优。
八、G1核心配置参数
在JDK9及以后的版本中,G1是默认的垃圾收集器,但在JDK8中,你需要显式地启用。以下是G1收集器的一些核心配置参数:
-
-XX:+UseG1GC:
这个参数用于启用G1垃圾收集器。在JDK8中,你需要明确设置这个参数来使用G1,而在JDK9及更高版本中,G1是默认启用的。 -
-XX:G1HeapRegionSize:
这个参数用于设置每个Region的大小。Region是G1收集器管理内存的基本单位。该值必须是2的幂,范围在1MB到32MB之间。G1的目标是根据最小的Java堆大小划分出约2048个这样的区域。默认情况下,这个值是堆内存的1/2000,这意味着G1收集器管理的最小堆内存应该是2GB以上,最大堆内存为64GB。 -
-XX:MaxGCPauseMillis:
这个参数用于设置期望的最大GC停顿时间指标。G1收集器会尽力在这个时间内完成垃圾回收,以减少应用程序的停顿时间。默认值是200毫秒。 -
-XX:ParallelGCThreads:
这个参数用于设置并行垃圾回收的线程数。这个值通常设置为与可用的CPU核心数相等,最大可以设置为8。 -
-XX:ConcGCThreads:
这个参数用于设置并发标记的线程数。并发标记是G1收集器在垃圾回收过程中的一个阶段,这个阶段与应用程序线程并发执行。通常,这个值设置为并行垃圾回收线程数(ParallelGCThreads)的1/4左右。 -
-XX:InitiatingHeapOccupancyPercent:
这个参数用于设置触发并发GC周期的Java堆占用率阈值。当堆内存的占用率达到这个值时,G1收集器会启动一个并发GC周期。默认值是45%,这意味着当堆内存的45%被占用时,就会触发垃圾回收。 -
-XX:+PrintGCDetails和-verbose:gc:
这两个参数不是G1特有的,但它们对于调试和监控垃圾收集器的行为非常有用。-XX:+PrintGCDetails会打印详细的垃圾收集日志,包括每次垃圾收集的时间、回收的对象数量等信息。-verbose:gc则会启用垃圾收集的日志记录,通常与-XX:+PrintGCDetails一起使用以获取更全面的日志输出。

九、结语
G1垃圾收集器以其可预测的停顿时间、灵活的内存管理和高效的并发标记等特点,在JVM中占据了重要的地位。通过深入理解G1的工作原理和关键特性,并根据实际应用场景进行性能优化,我们可以更好地利用G1来提升Java应用程序的性能和响应时间。

相关文章:
深入理解JVM中的G1垃圾收集器原理、过程和参数配置
码到三十五 : 个人主页 心中有诗画,指尖舞代码,目光览世界,步履越千山,人间尽值得 ! 在Java虚拟机(JVM)中,垃圾收集(GC)是一个自动管理内存的过程ÿ…...
VUE3 + Elementui-Plus 之 树形组件el-tree 一键展开(收起);一键全选(不全选)
需求: 产品要求权限树形结构添加外部复选框进行全部展开或收起;全选或不全选。 实现步骤: tree组件部分: <div class"role-handle"><div>权限选择(可多选)</div><div><el-checkbox v-mode…...
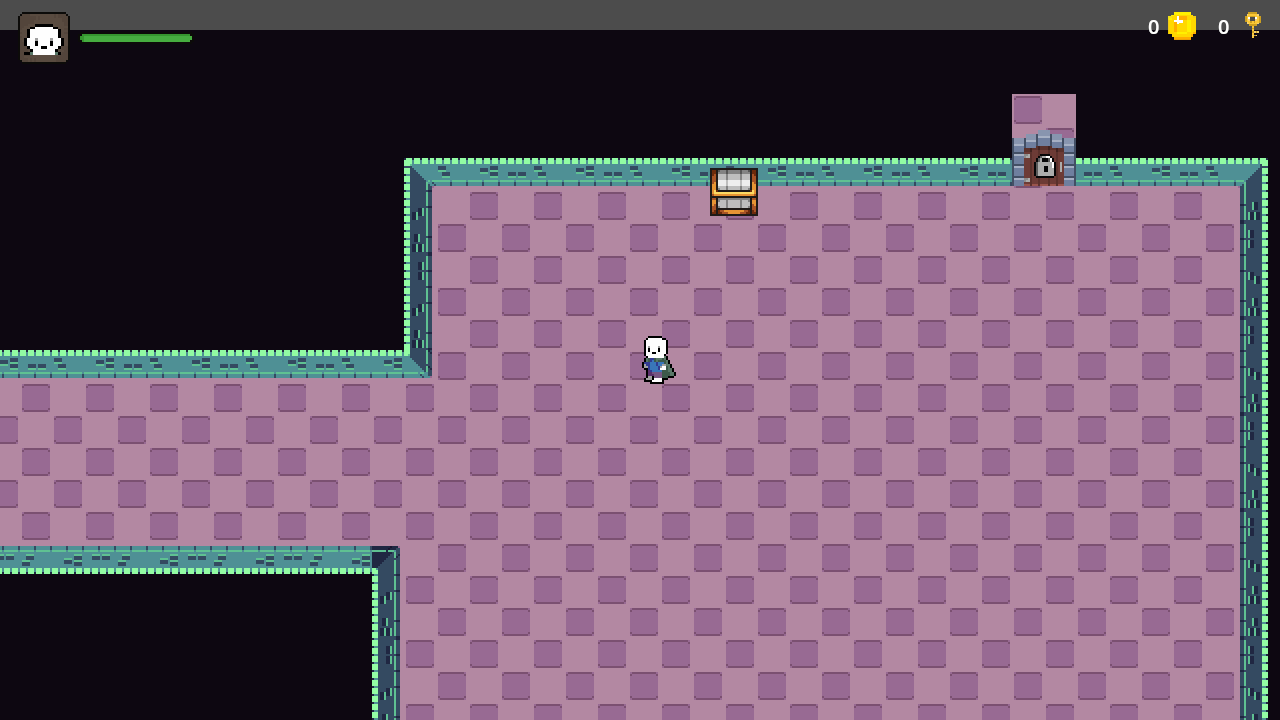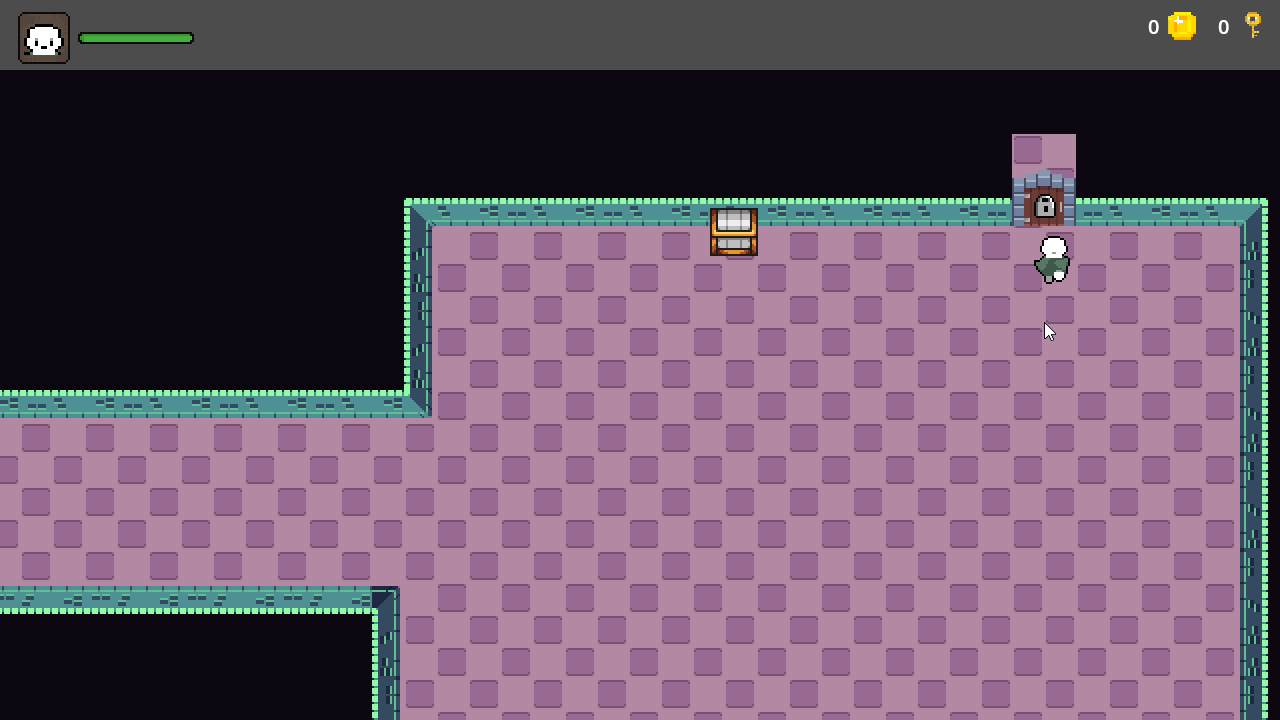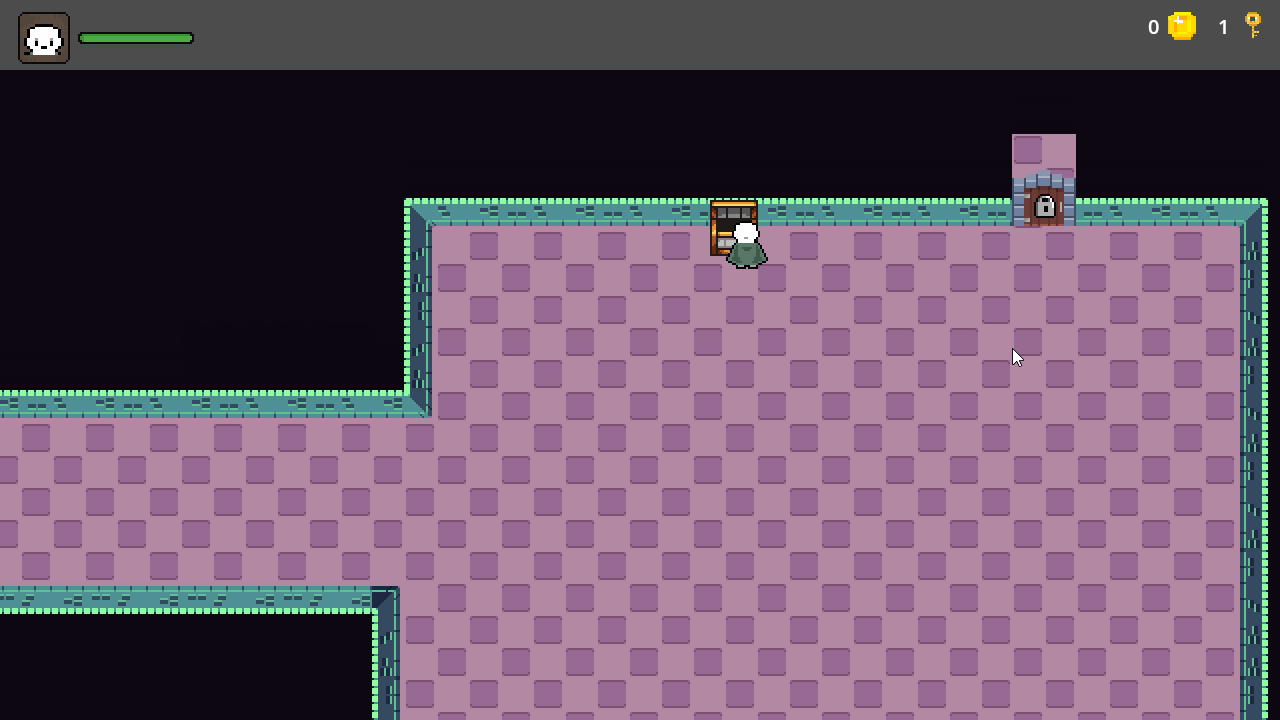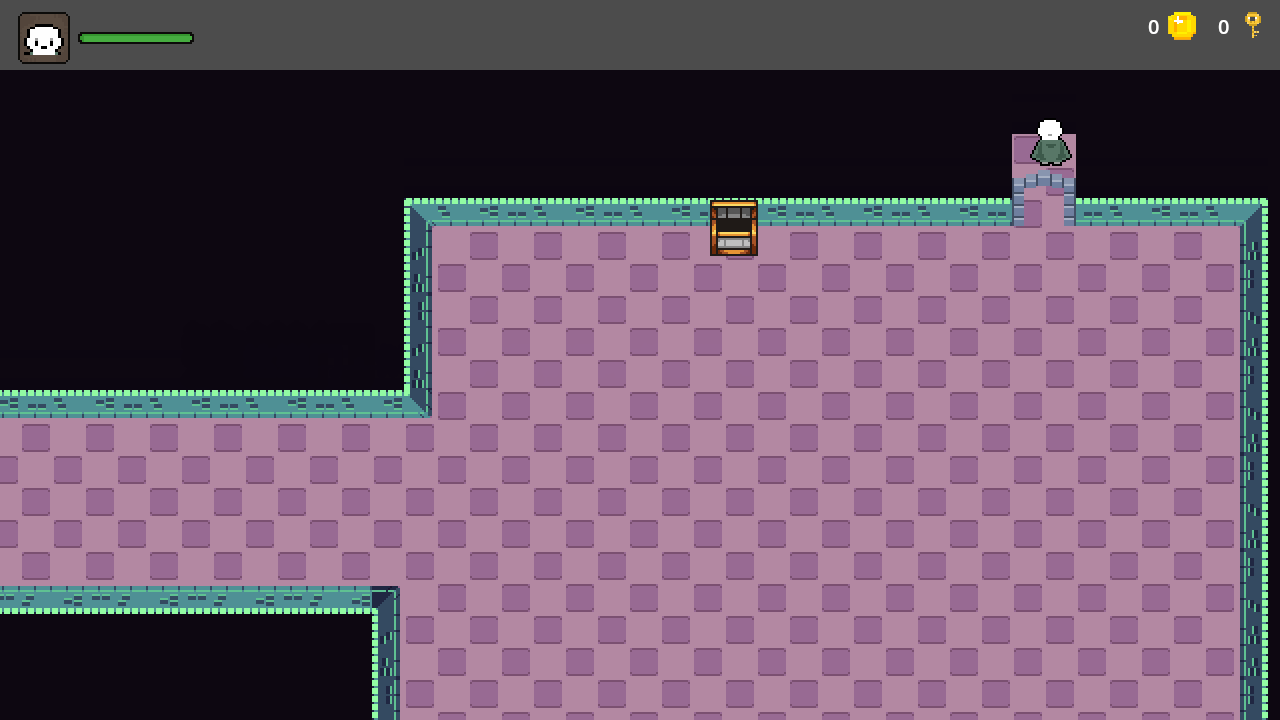
【Godot4自学手册】第三十七节钥匙控制开门
有些日子没有更新了,实在是琐事缠身啊,今天继续开始自学Godot4,继续完善地宫相关功能,在地宫中安装第二道门,只有主人公拿到钥匙才能开启这扇门,所以我们在合适位置放置一个宝箱,主人公开启宝箱…...

GitHub repository - Pulse - Contributors - Network
GitHub repository - Pulse - Contributors - Network 1. Pulse2. Contributors3. NetworkReferences 1. Pulse 显示该仓库最近的活动信息。该仓库中的软件是无人问津,还是在火热地开发之中,从这里可以一目了然。 2. Contributors 显示对该仓库进行过…...
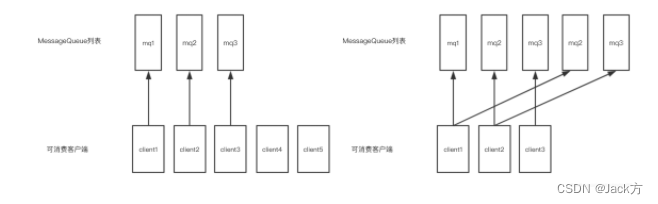
RocketMQ 10 面试题FAQ
RocketMQ 面试FAQ 说说你们公司线上生产环境用的是什么消息中间件? 为什么要使用MQ? 因为项目比较大,做了分布式系统,所有远程服务调用请求都是同步执行经常出问题,所以引入了mq 解耦 系统耦合度降低,没有强依赖…...

【Spring进阶系列丨第十篇】基于注解的面向切面编程(AOP)详解
文章目录 一、基于注解的AOP1、配置Spring环境2、在beans.xml文件中定义AOP约束3、定义记录日志的类【切面】4、定义Bean5、在主配置文件中配置扫描的包6、在主配置文件中去开启AOP的注解支持7、测试8、优化改进9、总结 一、基于注解的AOP 1、配置Spring环境 <dependencie…...

Leetcode 152. 乘积最大子数组和Leetcode 162. 寻找峰值
文章目录 Leetcode 152. 乘积最大子数组题目描述C语言题解和思路解题思路 Leetcode 162. 寻找峰值题目描述C语言题解和思路解题思路 Leetcode 152. 乘积最大子数组 题目描述 给你一个整数数组 nums ,请你找出数组中乘积最大的非空连续子数组(该子数组中…...

项目实战之网络电话本之发送邮件名片和导出word版个人信息
1、项目介绍 1)项目功能 用户管理:分为管理员、和普通用户,设置不同用户的权限 电话本信息管理:支持管理员和普通用户对电话本的信息进行增删改操作,模糊查询(根据姓名、地址、单位) 文件批…...

前端面试问题汇总 - HTTP篇
1. 登录拦截如何实现? 在前端,可以拦截所有需要登录的请求,如果用户未登录或者登录过期,则跳转到登录页面。 2. http 缓存有哪些? 强缓存: 强缓存是指在客户端请求资源时,先检查本地是否存在缓存…...

Java的IO流
Day35 Java的IO流 概念 Java的IO流是用来处理输入和输出操作的机制,用于在程序和外部数据源(如文件、网络连接、内存等)之间进行数据传输。Java的IO流主要分为字节流和字符流两种类型,每种类型又分为输入流和输出流。 理解&#…...

Node.js 中的 RSA 加密、解密、签名与验证详解
引言 在现代的网络通信中,数据安全显得尤为重要。RSA加密算法因其非对称的特性,广泛应用于数据的加密、解密、签名和验证等安全领域。本文将详细介绍RSA算法的基本原理,并结合Node.js环境,展示如何使用内置的crypto模块和第三方库…...
vue+element作用域插槽
作用域插槽的样式由父组件决定,内容却由子组件控制。 在el-table使用作用域插槽 <el-table><el-table-column slot-scope" { row, column, $index }"></el-table-column> </el-table>在el-tree使用作用域插槽 <el-tree>…...

MUSA模型
MUSA模型在软件可靠性工程中起到的作用是估计软件的故障/失效数量和故障率。具体来说,MUSA模型包括基本模型和对数模型。 MUSA基本模型假设故障发生的时间间隔服从参数为lambda的指数分布。在这个模型中,当故障被检测到时,发生故障的部分会被…...
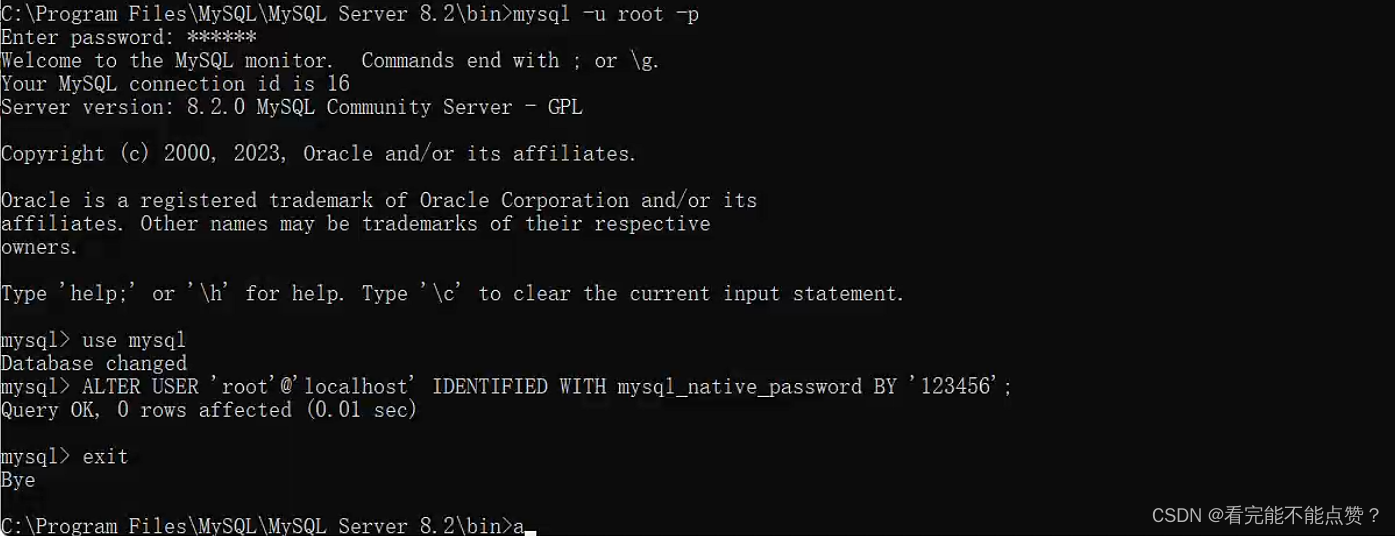
avicat连接异常,错误编号2059-authentication plugin…
错误原因为密码方式不对,具体可自行百度 首先管理员执行cmd进入 mysql安装目录 bin下边 我的是C:\Program Files\MySQL\MySQL Server 8.2\bin> 执行 mysql -u -root -p 然后输入密码 123456 进入mysql数据库 use mysql 执行 ALTER USER rootlocalhost IDE…...
阿里云云效CI/CD配置
1.NODEJS项目流水线配置(vue举例) nodejs构建配置 官方教程 注意:下图的dist是vue项目打包目录名称,根据实际名称配置 # input your command here cnpm cache clean --force cnpm install cnpm run build 主机部署配置 rm -rf /home/vipcardmall/frontend/ mkdir -p /home/…...

个人开发者,Spring Boot 项目如何部署
今天给大家分享一下,作为个人开发者,Spring Boot 项目是如何部署的。 环境介绍 Linux docker docker-compose 目录结构 erwin-windrunner - backups - data - jars - build-docker-compose.sh - docker-compose.yml - Dockerfile文件 Dockerfile …...

【Spring进阶系列丨第九篇】基于XML的面向切面编程(AOP)详解
文章目录 一、基于XML的AOP1.1、打印日志案例1.1.1、beans.xml中添加aop的约束1.1.2、定义Bean 1.2、定义记录日志的类【切面】1.3、导入AOP的依赖1.4、主配置文件中配置AOP1.5、测试1.6、切入点表达式1.6.1、访问修饰符可以省略1.6.2、返回值可以使用通配符,表示任…...

学习记录:转发和重定向
转发(Forward)和重定向(Redirect)是两种不同的 Web 请求处理方式,它们在功能和行为上有着显著的区别。 区别 转发(Forward): 服务器内部跳转:转发是服务器内部的行为&…...
数据上云存储)
实现(图像、视频等)数据上云存储
实现(图像、视频等)数据上云存储 实现(图像、视频等)数据上云存储通常涉及以下几个步骤: 选择云存储服务商: 根据您的需求、预算、地域覆盖、数据安全性、服务稳定性等因素,选择一家合适的云存储…...

LeetCode 454.四数相加II
LeetCode 454.四数相加II 1、题目 题目链接:454. 四数相加 II - 力扣(LeetCode) 给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足: 0 <…...

GPU内存优化:深度学习检查点技术原理与实践
1. GPU内存优化:深度学习训练中的检查点技术解析在训练现代深度神经网络时,GPU内存限制往往成为制约模型规模扩展的关键瓶颈。以典型的VGG-19模型为例,当批量大小设置为256时,仅正向传播阶段就需要消耗超过20GB的显存,…...

告别Let‘s Encrypt:用开源XCA构建私有CA,签发全站浏览器信任的SSL证书
1. 为什么你需要私有CA? 每次看到浏览器里那个"不安全"的红色警告,我就浑身难受。以前我也和大家一样用Lets Encrypt,直到有次紧急发布时遇到证书续期失败,整个团队熬夜排查到凌晨三点。从那天起,我就开始研…...

Next.js企业级开发样板Next-Enterprise:一站式集成最佳实践与工具链
1. 项目概述:为什么说 Next-Enterprise 是 Next.js 企业级开发的“瑞士军刀”? 如果你正在用 Next.js 构建一个中大型、对代码质量和开发体验有要求的企业级应用,那你大概率遇到过这些头疼事:项目初始化配置繁琐,得花…...

【Gemini Chrome插件实战指南】:20年老司机亲测的5大生产力跃迁技巧,90%用户还不知道
更多请点击: https://intelliparadigm.com 第一章:Gemini Chrome插件的核心架构与能力边界 Gemini Chrome 插件并非简单封装的 API 调用前端,而是一个基于 Chromium 扩展模型(Manifest V3)构建的多层协同系统…...
及对应--stylize动态补偿值)
Midjourney Minwa风格终极调试手册:7类常见失效场景(水墨晕染失真、线条断裂、文化符号错位)及对应--stylize动态补偿值
更多请点击: https://intelliparadigm.com 第一章:Midjourney Minwa风格的本质解构与美学基因图谱 Minwa(民画)风格源自朝鲜半岛传统民间绘画,其核心并非写实再现,而是以象征性构图、平涂色块、非透视空间…...

多波束声呐接收机与信号处理算法【附程序】
✨ 长期致力于多通道声呐接收机、电路设计、FPGA、数字信号处理、波束形成研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)小型化96通道接收机硬件电路…...

【Arcgis实战技巧】巧用DOM目视解译,从DSM中精准“挖”出地面高程点
1. 为什么需要从DSM中提取地面高程点? 在测绘和地理信息领域,数字表面模型(DSM)记录了地表所有物体的顶部高程信息,包括建筑物、树木、电线杆等。但很多时候我们需要的是数字高程模型(DEM)&…...
)
Windows 10下保姆级教程:Quartus Prime 18.0 + ModelSim SE 安装与破解全流程(含USB-Blaster驱动)
Windows 10下Quartus Prime 18.0与ModelSim SE完整安装指南 第一次接触FPGA开发的朋友们,面对Quartus Prime和ModelSim的安装过程可能会感到无从下手。这份指南将带你一步步完成从软件下载到最终验证的全过程,确保你的开发环境搭建顺利。不同于网络上零散…...

ESXi 8.0 最低存储要求:8GB 起步,这样装最稳
在部署 VMware ESXi 8.0 虚拟化环境时,存储规划是基础且关键的一步,很多新手常混淆系统引导盘与虚拟机数据盘的要求。核心结论清晰:ESXi 8.0 最低需 8GB SD 卡 / USB 作为引导介质,同时必须搭配独立的数据存储;生产环境…...

迪士尼收购卢卡斯影业:顶级IP运营与商业并购的教科书案例
1. 一笔改变好莱坞格局的交易:迪士尼收购卢卡斯影业深度解析2012年10月30日,一则新闻震动了全球娱乐产业和无数影迷的心:华特迪士尼公司宣布,将以约40.5亿美元的价格,收购乔治卢卡斯创立的卢卡斯影业及其旗下最核心的资…...