Prometheus接入AlterManager配置邮件告警(基于K8S环境部署)
目录
- 一.配置Alertmanager告警发送至邮箱
- 二.Prometheus接入AlertManager
- 三.部署Prometheus+AlterManager(放到一个Pod中)
- 四. 测试告警
基于 此环境做实验
一.配置Alertmanager告警发送至邮箱
1.创建AlertManager ConfigMap资源清单
vim alertmanager-cm.yaml
---
kind: ConfigMap
apiVersion: v1
metadata:name: alertmanagernamespace: prometheus
data:alertmanager.yml: |-global: resolve_timeout: 1msmtp_smarthost: 'smtp.qq.com:25'smtp_from: '1657310554@qq.com' # 从这个邮箱发送告警smtp_auth_username: '1657310554@qq.com' # 发送告警邮箱账号smtp_auth_password: 'rehtuhigsemwbbbe' # 邮箱验证码,用自己的邮箱验证码smtp_require_tls: falseroute: # 路由配置(将邮箱发送那个路由)group_by: [alertname]group_wait: 10sgroup_interval: 10srepeat_interval: 10mreceiver: default-receiver # 告警发送到default-receiver接受者receivers:- name: 'default-receiver' # 定义default-receiver接受者email_configs:- to: '1657310554@qq.com' # 告警发送邮箱地址send_resolved: true
执行YAML资源清单:
kubectl apply -f alertmanager-cm.yaml
2.配置文件核心配置说明
- group_by: [alertname]:采用哪个标签来作为分组依据。
- group_wait:10s:组告警等待时间。就是告警产生后等待10s,如果有同组告警一起发出。
- group_interval: 10s :上下两组发送告警的间隔时间。
- repeat_interval: 10m:重复发送告警的时间,减少相同邮件的发送频率,默认是1h。
- receiver: default-receiver:定义谁来收告警。
- smtp_smarthost: SMTP服务器地址+端口。
- smtp_from:指定从哪个邮箱发送报警。
- smtp_auth_username:邮箱账号。
- smtp_auth_password: 邮箱密码(授权码)。
二.Prometheus接入AlertManager
1.创建新的Prometheus ConfigMap资源清单,添加监控K8S集群告警规则
vim prometheus-alertmanager-cfg.yaml
---
kind: ConfigMap
apiVersion: v1
metadata:labels:app: prometheusname: prometheus-confignamespace: prometheus
data:prometheus.yml: |rule_files: - /etc/prometheus/rules.yml # 告警规则位置alerting:alertmanagers:- static_configs:- targets: ["localhost:9093"] # 接入AlterManagerglobal:scrape_interval: 15sscrape_timeout: 10sevaluation_interval: 1mscrape_configs:- job_name: 'kubernetes-node'kubernetes_sd_configs:- role: noderelabel_configs:- source_labels: [__address__]regex: '(.*):10250'replacement: '${1}:9100'target_label: __address__action: replace- action: labelmapregex: __meta_kubernetes_node_label_(.+)- job_name: 'kubernetes-node-cadvisor'kubernetes_sd_configs:- role: nodescheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- target_label: __address__replacement: kubernetes.default.svc:443- source_labels: [__meta_kubernetes_node_name]regex: (.+)target_label: __metrics_path__replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor- job_name: 'kubernetes-apiserver'kubernetes_sd_configs:- role: endpointsscheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]action: keepregex: default;kubernetes;https- job_name: 'kubernetes-service-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]action: replacetarget_label: __scheme__regex: (https?)- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2- action: labelmapregex: __meta_kubernetes_service_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_name - job_name: 'kubernetes-pods' # 监控Pod配置,添加注解后才可以被发现kubernetes_sd_configs:- role: podrelabel_configs:- action: keepregex: truesource_labels:- __meta_kubernetes_pod_annotation_prometheus_io_scrape- action: replaceregex: (.+)source_labels:- __meta_kubernetes_pod_annotation_prometheus_io_pathtarget_label: __metrics_path__- action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2source_labels:- __address__- __meta_kubernetes_pod_annotation_prometheus_io_porttarget_label: __address__- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- action: replacesource_labels:- __meta_kubernetes_namespacetarget_label: kubernetes_namespace- action: replacesource_labels:- __meta_kubernetes_pod_nametarget_label: kubernetes_pod_name- job_name: 'kubernetes-etcd' # 监控etcd配置scheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crtcert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crtkey_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.keyscrape_interval: 5sstatic_configs:- targets: ['192.168.40.180:2379'] # ip为master1的iprules.yml: | # K8S集群告警规则配置文件groups:- name: examplerules:- alert: apiserver的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: apiserver的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: etcd的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: etcd的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: kube-state-metrics的cpu使用率大于80%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"value: "{{ $value }}%"threshold: "80%" - alert: kube-state-metrics的cpu使用率大于90%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 0for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"value: "{{ $value }}%"threshold: "90%" - alert: coredns的cpu使用率大于80%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"value: "{{ $value }}%"threshold: "80%" - alert: coredns的cpu使用率大于90%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"value: "{{ $value }}%"threshold: "90%" - alert: kube-proxy打开句柄数>600expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kube-proxy打开句柄数>1000expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-schedule打开句柄数>600expr: process_open_fds{job=~"kubernetes-schedule"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-schedule打开句柄数>1000expr: process_open_fds{job=~"kubernetes-schedule"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-controller-manager打开句柄数>600expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-controller-manager打开句柄数>1000expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-apiserver打开句柄数>600expr: process_open_fds{job=~"kubernetes-apiserver"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-apiserver打开句柄数>1000expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-etcd打开句柄数>600expr: process_open_fds{job=~"kubernetes-etcd"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-etcd打开句柄数>1000expr: process_open_fds{job=~"kubernetes-etcd"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: corednsexpr: process_open_fds{k8s_app=~"kube-dns"} > 600for: 2slabels:severity: warnning annotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600"value: "{{ $value }}"- alert: corednsexpr: process_open_fds{k8s_app=~"kube-dns"} > 1000for: 2slabels:severity: criticalannotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000"value: "{{ $value }}"- alert: kube-proxyexpr: process_virtual_memory_bytes{job=~"kubernetes-kube-proxy"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: schedulerexpr: process_virtual_memory_bytes{job=~"kubernetes-schedule"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-controller-managerexpr: process_virtual_memory_bytes{job=~"kubernetes-controller-manager"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-apiserverexpr: process_virtual_memory_bytes{job=~"kubernetes-apiserver"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-etcdexpr: process_virtual_memory_bytes{job=~"kubernetes-etcd"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kube-dnsexpr: process_virtual_memory_bytes{k8s_app=~"kube-dns"} > 2000000000for: 2slabels:severity: warnningannotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: HttpRequestsAvgexpr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000"value: "{{ $value }}"threshold: "1000" - alert: Pod_restartsexpr: kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor-sa"} > 0for: 2slabels:severity: warnningannotations:description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启,这个监控指标是由{{$labels.instance}}采集的"value: "{{ $value }}"threshold: "0"- alert: Pod_waitingexpr: kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中"value: "{{ $value }}"threshold: "1" - alert: Pod_terminatedexpr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor-sa"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除"value: "{{ $value }}"threshold: "1"- alert: Etcd_leaderexpr: etcd_server_has_leader{job="kubernetes-etcd"} == 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader"value: "{{ $value }}"threshold: "0"- alert: Etcd_leader_changesexpr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变"value: "{{ $value }}"threshold: "0"- alert: Etcd_failedexpr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败"value: "{{ $value }}"threshold: "0"- alert: Etcd_db_total_sizeexpr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G"value: "{{ $value }}"threshold: "10G"- alert: Endpoint_readyexpr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用"value: "{{ $value }}"threshold: "1"- name: 物理节点状态-监控告警rules:- alert: 物理节点cpu使用率expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90for: 2slabels:severity: ccriticalannotations:summary: "{{ $labels.instance }}cpu使用率过高"description: "{{ $labels.instance }}的cpu使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert: 物理节点内存使用率expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90for: 2slabels:severity: criticalannotations:summary: "{{ $labels.instance }}内存使用率过高"description: "{{ $labels.instance }}的内存使用率超过90%,当前使用率[{{ $value }}],需要排查处理"- alert: InstanceDownexpr: up == 0for: 2slabels:severity: criticalannotations: summary: "{{ $labels.instance }}: 服务器宕机"description: "{{ $labels.instance }}: 服务器延时超过2分钟"- alert: 物理节点磁盘的IO性能expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!"description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"- alert: 入网流量带宽expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流入网络带宽过高!"description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"- alert: 出网流量带宽expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流出网络带宽过高!"description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"- alert: TCP会话expr: node_netstat_Tcp_CurrEstab > 1000for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!"description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"- alert: 磁盘容量expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!"description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
执行资源清单:
kubectl apply -f prometheus-alertmanager-cfg.yaml
2.由于在prometheus中新增了etcd,所以生成一个etcd-certs,这个在部署prometheus需要
kubectl -n prometheus create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/
三.部署Prometheus+AlterManager(放到一个Pod中)
1.在node1节点创建/data/alertmanager目录,存放alertmanager数据
mkdir /data/alertmanager -p
chmod -R 777 /data/alertmanager
2.删除旧的prometheus deployment资源
kubectl delete deploy prometheus-server -n prometheus
3.创建deployment资源
vim prometheus-alertmanager-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:name: prometheus-servernamespace: prometheuslabels:app: prometheus
spec:replicas: 1selector:matchLabels:app: prometheuscomponent: servertemplate:metadata:labels:app: prometheuscomponent: serverannotations:prometheus.io/scrape: 'false'spec:nodeName: node1 # 调度到node1节点serviceAccountName: prometheus # 指定sa服务账号containers:- name: prometheusimage: prom/prometheus:v2.33.5imagePullPolicy: IfNotPresentcommand:- "/bin/prometheus"args:- "--config.file=/etc/prometheus/prometheus.yml"- "--storage.tsdb.path=/prometheus"- "--storage.tsdb.retention=24h"- "--web.enable-lifecycle"ports:- containerPort: 9090protocol: TCPvolumeMounts:- mountPath: /etc/prometheusname: prometheus-config- mountPath: /prometheus/name: prometheus-storage-volume- name: k8s-certsmountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/- name: alertmanagerimage: prom/alertmanager:v0.23.0imagePullPolicy: IfNotPresentargs:- "--config.file=/etc/alertmanager/alertmanager.yml"- "--log.level=debug"ports:- containerPort: 9093protocol: TCPname: alertmanagervolumeMounts:- name: alertmanager-configmountPath: /etc/alertmanager- name: alertmanager-storagemountPath: /alertmanager- name: localtimemountPath: /etc/localtimevolumes:- name: prometheus-configconfigMap:name: prometheus-config- name: prometheus-storage-volumehostPath:path: /datatype: Directory- name: k8s-certssecret:secretName: etcd-certs- name: alertmanager-configconfigMap:name: alertmanager- name: alertmanager-storagehostPath:path: /data/alertmanagertype: DirectoryOrCreate- name: localtimehostPath:path: /usr/share/zoneinfo/Asia/Shanghai
执行YAML资源清单:
kubectl apply -f prometheus-alertmanager-deploy.yaml
查看状态:
kubectl get pods -n prometheus

4.创建AlertManager SVC资源
vim alertmanager-svc.yaml
---
apiVersion: v1
kind: Service
metadata:labels:name: prometheuskubernetes.io/cluster-service: 'true'name: alertmanagernamespace: prometheus
spec:ports:- name: alertmanagernodePort: 30066port: 9093protocol: TCPtargetPort: 9093selector:app: prometheussessionAffinity: Nonetype: NodePort
执行YAML资源清单:
kubectl apply -f alertmanager-svc.yaml
查看状态:
kubectl get svc -n prometheus

四. 测试告警
浏览器访问:http://IP:30066
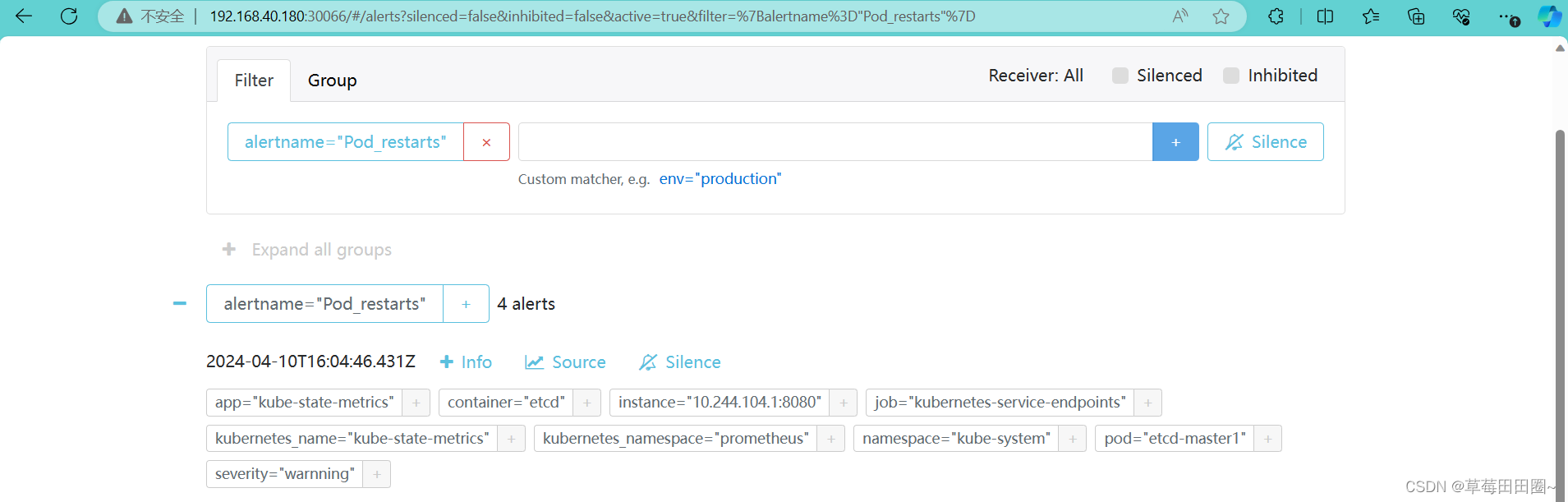
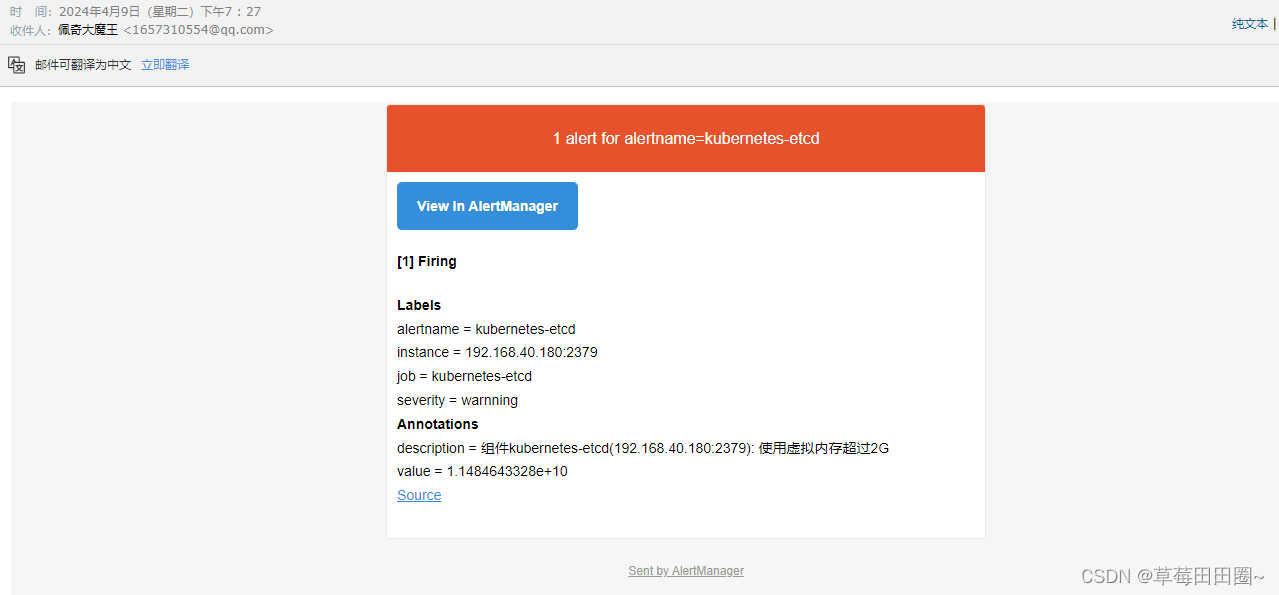
如上图可以看到,Prometheus的告警信息已经发到AlterManager了,AlertManager收到报警数据后,会将警报信息进行分组,然后根据AlertManager配置的 group_wait 时间先进行等待。等wait时间过后再发送报警信息至邮件!
相关文章:
Prometheus接入AlterManager配置邮件告警(基于K8S环境部署)
目录 一.配置Alertmanager告警发送至邮箱二.Prometheus接入AlertManager三.部署PrometheusAlterManager(放到一个Pod中)四. 测试告警 基于 此环境做实验 一.配置Alertmanager告警发送至邮箱 1.创建AlertManager ConfigMap资源清单 vim alertmanager-cm.yaml --- kind: Confi…...

find方法
find() 方法用于在数组中查找符合条件的第一个元素,并返回该元素。如果找到匹配的元素,则返回该元素的值;如果未找到匹配的元素,则返回 undefined。 例如: const firstWithdrawal movements.find(mov > mov < 0); consol…...
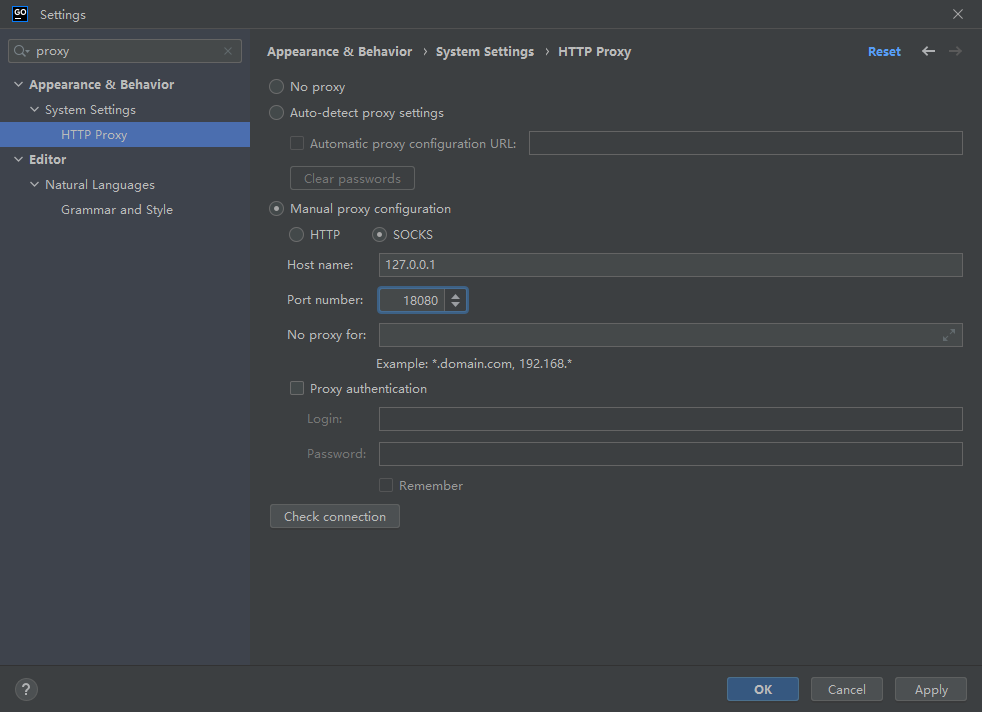
TLS v1.3 导致JetBrains IDE jdk.internal.net.http.common CPU占用高
开发环境 GoLand版本:2022.3.4 问题原因 JDK 中的 TLS v1.3 实现引起 解决办法 使用 SOCKS 代理代替HTTP代理 禁用 Space 和 Code With Me 插件 禁用 TLS v1.3,参考:https://stackoverflow.com/questions/54485755/java-11-httpclient-…...
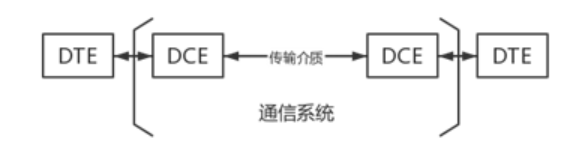
计算机网络 2.2数据传输方式
第二节 数据传输方式 一、数据通信系统模型 添加图片注释,不超过 140 字(可选) 1.数据终端设备(DTE) 作用:用于处理用户数据的设备,是数据通信系统的信源和信宿。 设备:便携计算机…...

陇剑杯 流量分析 webshell CTF writeup
陇剑杯 流量分析 链接:https://pan.baidu.com/s/1KSSXOVNPC5hu_Mf60uKM2A?pwdhaek 提取码:haek目录结构 LearnCTF ├───LogAnalize │ ├───linux简单日志分析 │ │ linux-log_2.zip │ │ │ ├───misc日志分析 │ │ …...
【测试开发学习历程】python常用的模块(下)
目录 8、MySQL数据库的操作-pymysql 8.1 连接并操作数据库 9、ini文件的操作-configparser 9.1 模块-configparser 9.2 读取ini文件中的内容 9.3 获取指定建的值 10 json文件操作-json 10.1 json文件的格式或者json数据的格式 10.2 json.load/json.loads 10.3 json.du…...

GCDAsynSocket之TCP简析
GCDAsynSocket是一个开源的基于GCD的异步的socket库。它支持IPV4和IPV6地址,TLS/SSL协议。同时它支持iOS端和Mac端。本篇主要介绍一下GCDAsynSocket中的TCP用法和实现。 首先通过下面这个方法初始化一个GCDAsynSocket对象。 - (id)initWithDelegate:(id<GCDAsyn…...
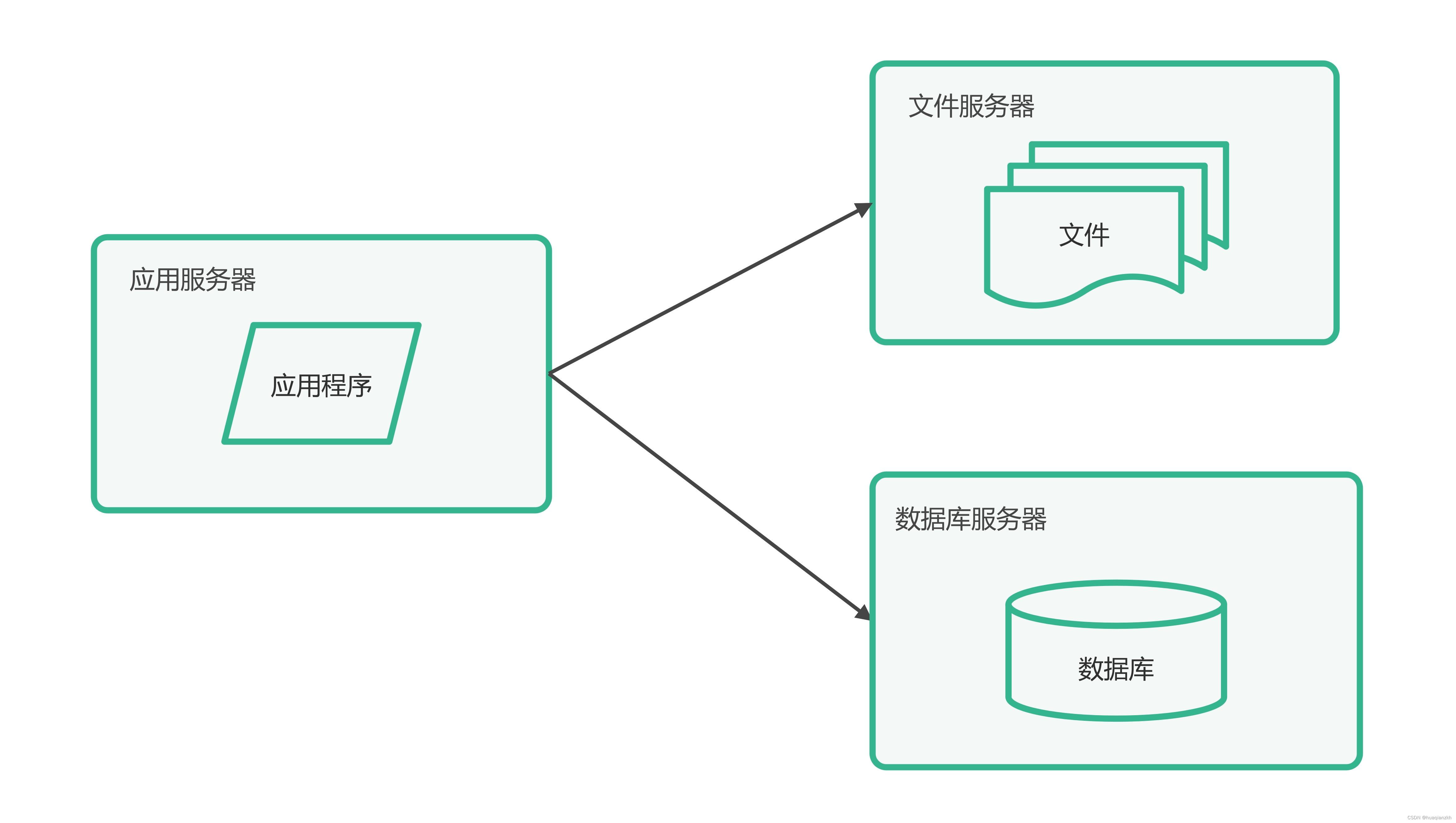
大型网站系统架构演化实例_1.单体架构和垂直架构
大型网站的技术挑战主要来自于庞大的用户,高并发的访问和海量的数据,任何简单的业务一旦需要处理数以P计的数据和面对数以亿计的用户,问题就会变得很棘手。通常大型网站架构主要解决这类问题。 1.第一阶段:单体架构 大型网站都是…...
2024蓝桥杯——宝石问题
先展示题目 声明 以下代码仅是我的个人看法,在自己考试过程中的优化版,本人考试就踩了很多坑,我会—一列举出来。代码可能很多,但是总体时间复杂度不高只有0(N) 函数里面的动态数组我没有写开辟判断和free,这里我忽略…...

three.js加载模型报错,Error: THREE.GLTFLoader: No DRACOLoader instance provided.
three.js加载模型报错,Error: THREE.GLTFLoader: No DRACOLoader instance provided. 原因:该模型是压缩过的,需要 DRACOLoader 我们先找到该文件夹 node_modules three examples jsm libs draco 将draco拷贝到public下 import { GLTFLoad…...

Spring VS Spring Boot
目录 定义 Spring Spring Boot 区别 优劣对比 Spring Spring的优势 Spring的劣势 Spring Boot Spring Boot的优势 Spring Boot的劣势 适用场景 Spring的适用场景 Spring Boot的适用场景 初学者如何选择学习 定义 Spring Spring是一个轻量级的、开源的Java开发…...
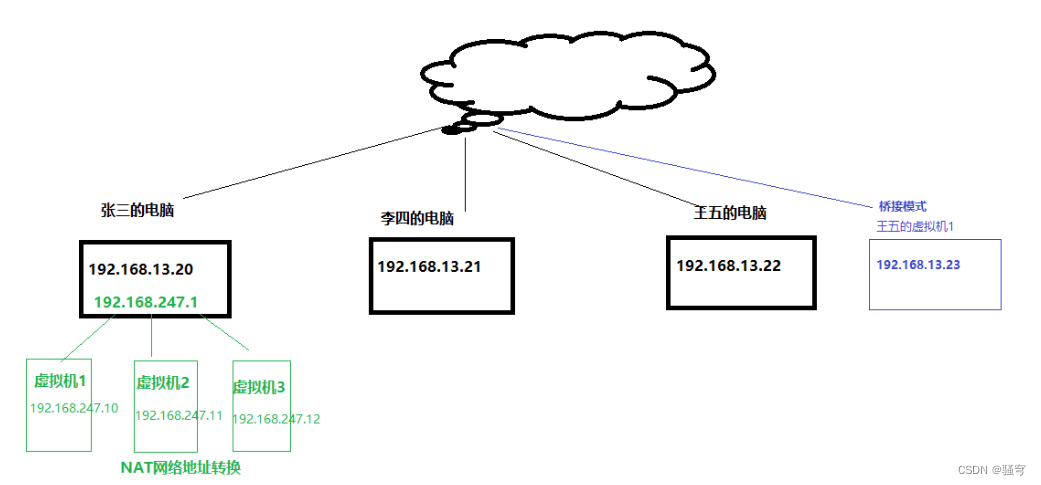
Linux入门(Linux介绍,安装,常用命令,防火墙的设置,注意事项)
目录 一、Linux介绍 1. Linux简介 1 什么是Linux 2 Linux的应用 3 为什么要学习Linux 2. Linux分类 1 按照市场需求分 2 按照原生程度分 3.小结 二、Linux安装 1. vmware介绍 2. 安装VMWare 3. 安装CentOS 4. 登录查看ip 5. 远程连接工具 1 使用FinalShell连接L…...
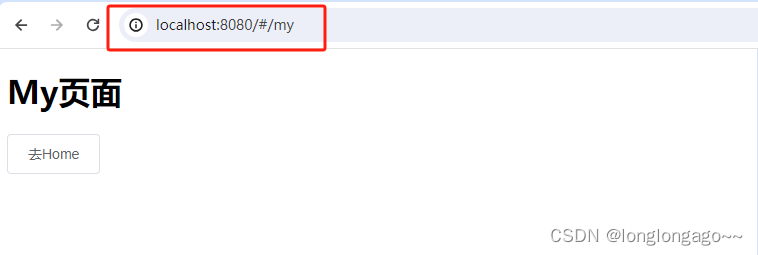
vue2创建项目的两种方式,配置路由vue-router,引入element-ui
提示:vue2依赖node版本8.0以上 文章目录 前言一、创建项目基于vue-cli二、创建项目基于vue/cli三、对吧两种创建方式四、安装Element ui并引入五、配置路由跳转四、效果五、参考文档总结 前言 使用vue/cli脚手架vue create创建 使用vue-cli脚手架vue init webpack创…...
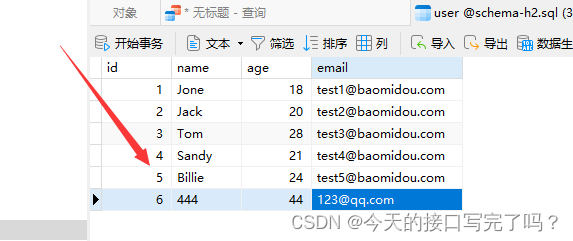
MySql 表中的id突然变很大,如何给id重新排序
目录 一、场景 二、解决方法 一、场景 我们在开发过程中,难免遇到id突然增大的情况。 由于id突然增大很多,我们重新增加数据时候id会默认加1 那么如何让id 重新从1按顺序排序呢 二、解决方法 点击编辑表,然后新建一个字段id2,将…...

leetcode练习——哈希表
目录 3. 无重复字符的最长子串 题目描述 解题思路 代码实现 349. 两个数组的交集 题目描述 解题思路 代码实现 454. 四数相加 II 题目描述 解题思路 代码实现 242. 有效的字母异位词 题目描述 解题思路 代码实现 438. 找到字符串中所有字母异位词 题目…...
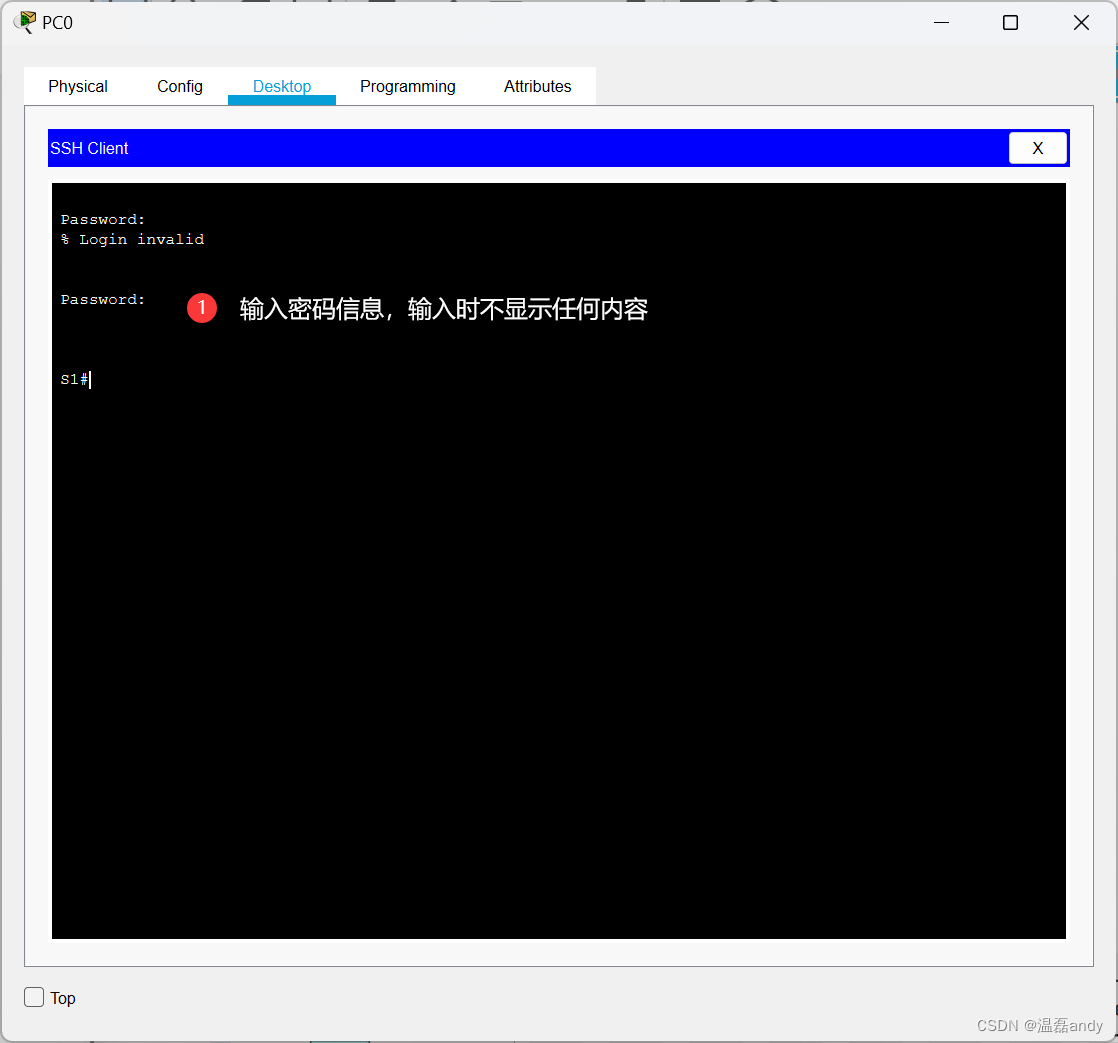
配置交换机 SSH 管理和端口安全
实验1:配置交换机基本安全和 SSH管理 1、实验目的 通过本实验可以掌握: 交换机基本安全配置。SSH 的工作原理和 SSH服务端和客户端的配置。 2、实验拓扑 交换机基本安全和 SSH管理实验拓扑如图所示。 3、实验步骤 (1)配置交换机S1 Swit…...

基于SpringBoot+Vue的装饰工程管理系统(源码+文档+包运行)
一.系统概述 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解决一些老技术的弊端问题。因为传统装饰工程项目信息管理难度大,容错率低&a…...

vue3中axios添加请求和响应的拦截器
本章主要是以记录为主。 在src创建一个utils文件夹,并在utils中创建一个request.js文件。 // 引入axios import axios from "axios"; // import qs from "qs"; // 创建axios实例 const instance axios.create(); // 请求拦截器 instance.int…...
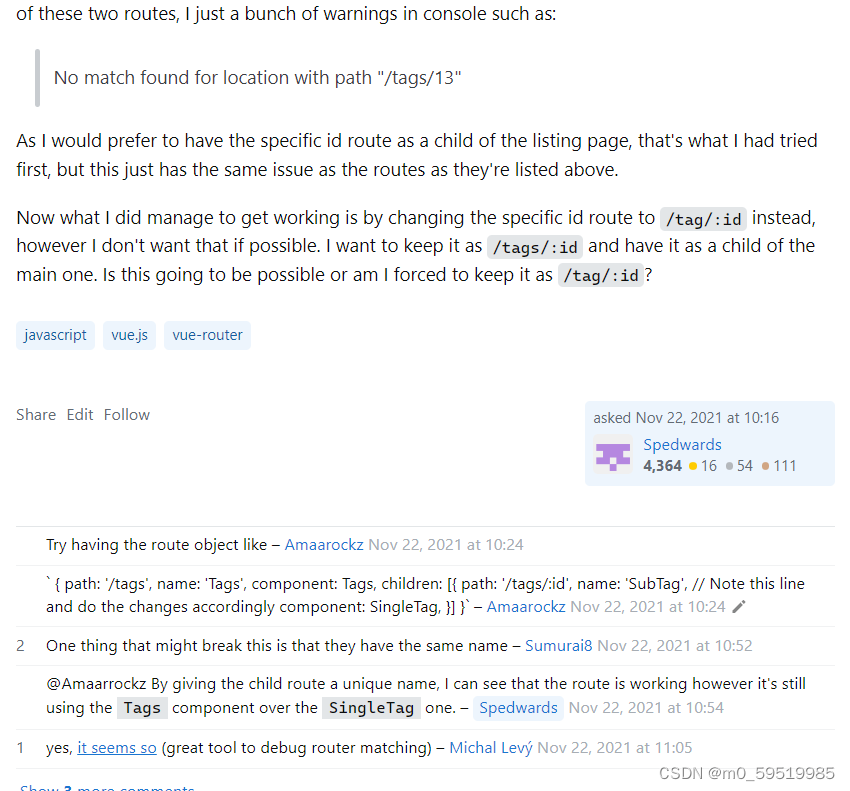
<router-link>出现Error: No match for {“name“:“home“,“params“:{}}
在将<a></a>标签换到<router-link></router-link>的时候出现No match for {"name":"home","params":{}}这样的错误,其中格式并无错误, <router-link class"navbar-brand active" …...
prompt 工程整理(未完、持续更新)
工作期间会将阅读的论文、一些个人的理解整理到个人的文档中,久而久之就积累了不少“个人”能够看懂的脉络和提纲,于是近几日准备将这部分略显杂乱的内容重新进行梳理。论文部分以我个人的理解对其做了一些分类,并附上一些简短的理解…...

终极图片去重神器:AntiDupl.NET帮你一键清理重复图片释放磁盘空间
终极图片去重神器:AntiDupl.NET帮你一键清理重复图片释放磁盘空间 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾因电脑里堆积如山的重复照片而烦…...

OpenAEON:从AI Agent到自主认知引擎的架构解析与实战
1. 项目概述:从“智能助手”到“自主认知引擎”的跃迁 如果你和我一样,在AI Agent领域摸爬滚打了几年,从早期的简单聊天机器人框架,到后来的工具调用(Function Calling)和RAG(检索增强生成&…...

在多模型间切换时Taotoken路由策略带来的稳定性体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多模型间切换时Taotoken路由策略带来的稳定性体验 在构建基于大模型的应用时,服务的稳定性是开发者关心的核心问题之…...

如何快速掌握硬件性能优化:面向暗影精灵的完整教程
如何快速掌握硬件性能优化:面向暗影精灵的完整教程 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否曾经在玩游戏时突然遭遇卡顿…...

Ubuntu 18.04下ISE 14.7与Vivado 2018.2的避坑安装与深度配置指南
1. 环境准备与依赖安装 在Ubuntu 18.04上安装ISE 14.7和Vivado 2018.2之前,系统环境配置是决定成败的关键。我遇到过不少开发者因为跳过这个步骤,导致后续安装过程频繁报错。这里分享几个必须检查的要点: 首先确认系统架构,虽然…...

Display Driver Uninstaller:显卡驱动问题的终极解决方案
Display Driver Uninstaller:显卡驱动问题的终极解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-uninstall…...

【典型电路设计】直流400V转24V电源设计,超宽输入高压非隔离Buck降压芯片XD308H,包含芯片介绍以及参考电路详细解读
一款工业场景中非常实用的高压降压芯片——XD308H,这款芯片主打超宽输入、外围极简、低成本,特别适合400VDC母线、220VAC整流后等高压场景,实现小功率非隔离降压(如24V、12V),广泛应用于工业控制、BMS、智能…...

【高光谱图像数据处理实战】基于Python的ENVI图像交互式裁剪与光谱数据预处理
前言在处理高光谱图像数据(Hyperspectral Imaging, HSI)时,我们常常需要面对两个核心问题:一是如何从庞大的三维数据立方体(Data Cube)中高效、准确地提取感兴趣区域(ROI)…...

汽车软件平台演进:从AUTOSAR到Hypervisor,如何重塑开发与商业模式
1. 汽车软件平台现状:从“硬骨头”到“乐高积木”的演进干了十几年汽车电子,我亲眼看着车里的代码从几万行膨胀到上亿行。十年前,我们还在为某个ECU(电子控制单元)里塞进一个简单的网络协议栈而通宵调试;现…...

如何彻底解决Windows热键冲突问题:Hotkey Detective的完整实战指南
如何彻底解决Windows热键冲突问题:Hotkey Detective的完整实战指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...