批量插入10w数据方法对比
环境准备(mysql5.7)
CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '唯一id',
`user_id` bigint(10) DEFAULT NULL COMMENT '用户id-uuid',
`user_name` varchar(100) NOT NULL COMMENT '用户名',
`user_age` bigint(10) DEFAULT NULL COMMENT '用户年龄',
`create_time` timestamp NULL DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=300001 DEFAULT CHARSET=latin1;
配置依赖
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.16</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.9</version>
</dependency>
方式一:普通JDBC插入
public class JDBCDemo {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/daily_learn_db";
String user = "root";
String password = "123456";
String driver = "com.mysql.jdbc.Driver";
// sql语句
String sql = "INSERT INTO User(user_id,user_name,user_age) VALUES (?,?,?);";
Connection conn = null;
PreparedStatement ps = null;
// 开始时间
long start = System.currentTimeMillis();
try {
Class.forName(driver);
conn = DriverManager.getConnection(url, user, password);
ps = conn.prepareStatement(sql);
// 循环遍历插入数据
for (int i = 1; i <= 100000; i++) {
ps.setLong(1, Long.parseLong(RandomUtil.randomNumbers(5)));
ps.setString(2, "coderwhs");
ps.setLong(3, Long.parseLong(RandomUtil.randomNumbers(2)));
ps.executeUpdate();
}
} catch (ClassNotFoundException | SQLException e) {
e.printStackTrace();
} finally {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (ps != null) {
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
// 结束时间
long end = System.currentTimeMillis();
System.out.println("十万条数据插入时间(普通插入方式):" + (end - start) + " ms");
}
}
运行结果 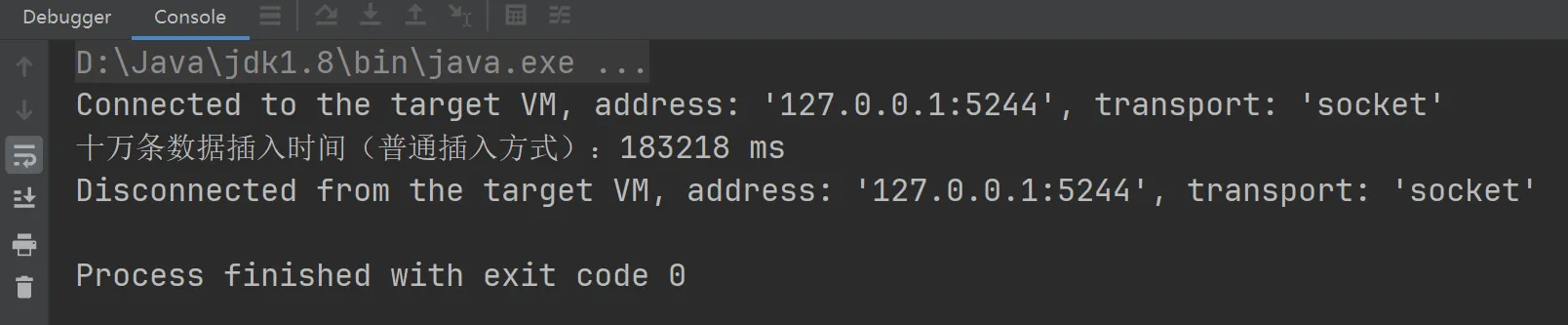 可以看到,一条一条插入10w条数据,一共需要约183s时间
可以看到,一条一条插入10w条数据,一共需要约183s时间
方式二:JDBC批量插入+手动事务提
public static void main(String[] args) {
// url 设置允许重写批量提交 rewriteBatchedStatements=true
String url = "jdbc:mysql://localhost:3306/daily_learn_db?rewriteBatchedStatements=true";
String user = "root";
String password = "123456";
String driver = "com.mysql.jdbc.Driver";
String sql = "INSERT INTO User(user_id,user_name,user_age,create_time) VALUES (?,?,?,now())";
Connection conn = null;
PreparedStatement ps = null;
long start = System.currentTimeMillis();
try {
Class.forName(driver);
conn = DriverManager.getConnection(url, user, password);
ps = conn.prepareStatement(sql);
// 关闭自动提交事务
conn.setAutoCommit(false);
for (int i = 1; i <= 100000; i++) {
ps.setLong(1, Long.parseLong(RandomUtil.randomNumbers(5)));
ps.setString(2, "coderwhs");
ps.setLong(3, Long.parseLong(RandomUtil.randomNumbers(2)));
// 加入批处理(将当前待执行的sql加入缓存)
ps.addBatch();
// 以1000条数据作为分片,参考mybatisPlus的默认切片值
if(i % 1000 == 0){
// 执行缓存中的sql语句,并且清空缓存
ps.executeBatch();
ps.clearBatch();
}
}
ps.executeBatch();
ps.clearBatch();
// 事务提交
conn.commit();
} catch (ClassNotFoundException | SQLException e) {
e.printStackTrace();
try {
// 事务回滚
if (conn != null){
conn.rollback();
}
} catch (SQLException ex) {
throw new RuntimeException(ex);
}
} finally {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (ps != null) {
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
long end = System.currentTimeMillis();
System.out.println("十万条数据插入时间(批量插入方式):" + (end - start) + " ms");
}
运行结果: 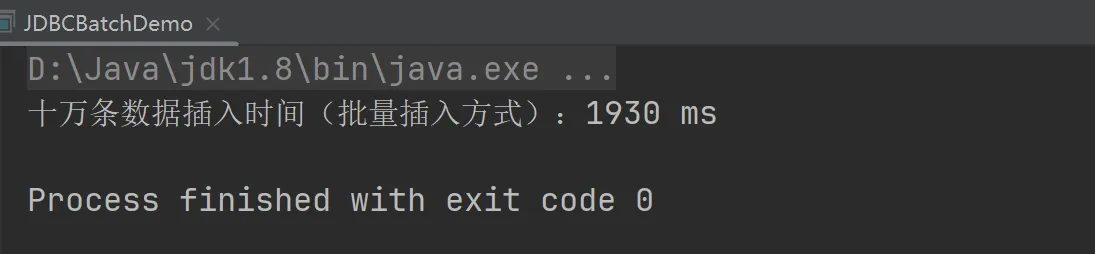 时间上约为1.9秒,比起第一种方式提高了近100倍的效率
时间上约为1.9秒,比起第一种方式提高了近100倍的效率
这种实现方式需要注意几个问题:
-
使用 prepareStatement的如下三个方法来实现批量操作
-
addBatch():该方法用于向批处理中添加一批参数。通常在执行批量操作之前,通过多次调用该方法,将不同参数的sql添加到批处理之中,然后一次性将这些参数一起提交给数据库执行。 -
executeBatch():该方法表示执行当前的批处理参数。该方法会返回一个整数数组,表示批处理每个操作所影响的行数。 -
clearBatch():该方法用于清空当前的批处理参数,每次执行完后需要调用该方法进行清空
-
在url上需要加上 rewriteBatchedStatements=true才能实现真正的批处理。这个设置是实现允许重写批量提交;在默认不开启的情况下,会无视executeBatch()方法,将原本应该批量执行的sql又拆成单条语句去执行 -
使用批处理方式时,sql语句后面不能以分号结束,单条语句执行时可以用分号结束。这是因为批处理时候需要进行sql拼接,若带有分号,则会变成 INSERT INTO User(user_id,user_name,user_age,create_time) VALUES (?,?,?,now());,(?,?,?,now());,(?,?,?,now());,则会执行报错 -
为什么以1000作为分片大小?这是参考MybatisPlus框架的默认分片大小,分片操作可以避免一次性提交的数据量过大而导致数据库处理时出现性能问题和内存占用过高问题,合理的分片大小可以减轻数据库的负担 -
手动提交事务可以提高插入速度,在批量插入大量数据时,手动事务提交相对自动事务提交可以减少磁盘的IO次数,减少锁竞争,提高性能。可以通过 setAutoCommit(false)关闭自动提交事务,等全部插入完成后再commit()手动提交事务
方式三:MyBatis / MyBatis Plus 实现批量插入
UserMapper.xml代码
<insert id="insertByOne">
INSERT INTO user(user_id,user_name,user_age,create_time)
VALUES (#{userId},#{userName},#{userAge},now())
</insert>
<insert id="insertByForeach">
INSERT INTO user(user_id,user_name,user_age,create_time)
VALUES
<foreach collection="userList" item="user" separator=",">
(#{user.userId},#{user.userName},#{user.userAge},now())
</foreach>
</insert>
UserServiceImpl代码
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User>
implements UserService{
@Resource
private UserMapper userMapper;
@Resource
private SqlSessionFactory sqlSessionFactory;
//普通插入
@Override
public int saveByFor(List<User> feeList) {
// 记录结果(影响行数)
int res = 0;
// 循环插入
for (User user : feeList) {
res += userMapper.insertByOne(user);
}
return res;
}
//foreach动态拼接插入
@Override
public int saveByForeach(List<User> feeList) {
// 通过mapper的foreach动态拼接sql插入
return userMapper.insertByForeach(feeList);
}
//批处理插入
@Transactional
@Override
public int saveByBatch(List<User> feeList) {
// 记录结果(影响行数)
int res = 0;
// 开启批处理模式
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
UserMapper feeMapper = sqlSession.getMapper(UserMapper.class);
for (int i = 1; i <= feeList.size(); i++) {
// 利用mapper的单条插入方法插入
res += feeMapper.insertByOne(feeList.get(i-1));
// 进行分片类似 JDBC 的批处理
if (i % 100000 == 0) {
sqlSession.commit();
sqlSession.clearCache();
}
}
sqlSession.commit();
sqlSession.clearCache();
return res;
}
}
下面分别对方式三种的三种情况进行测试
3.1 普通插入
/**
* 单条插入
*/
@Test
public void saveByFor() {
// 获取 10w 条测试数据
List<User> userList = getUserList();
// 开始时间
long start = System.currentTimeMillis();
// 普通插入
userService.saveByFor(userList);
// 结束时间
long end = System.currentTimeMillis();
System.out.println("十万条数据插入时间(普通插入方式):" + (end - start) + " ms");
}
 可以看到时间上和使用原生JDBC耗时差不多,约为18.4秒
可以看到时间上和使用原生JDBC耗时差不多,约为18.4秒
3.2 foreach动态拼接插入
/**
* foreach动态拼接插入
*/
@Test
public void saveByForeach() {
// 获取 10w 条测试数据
List<User> userList = getUserList();
// 开始时间
long start = System.currentTimeMillis();
// foreach动态拼接插入
userService.saveByForeach(userList);
// 结束时间
long end = System.currentTimeMillis();
System.out.println("十万条数据插入时间(foreach动态拼接插入方式):" + (end - start) + " ms");
}
运行时报错  原因:
原因:
默认情况下 MySQL 可执行的最大 SQL 语句大小为 4194304 即 4MB,这里使用动态 SQL 拼接后的大小远大于默认值,故报错。
修改: 设置 MySQL 的默认 sql 大小来解决此问题(这里设置为 10MB) 到数据库执行:set global max_allowed_packet=10 * 1024 * 1024;
再次运行  这种方式的优缺点也很明显,优点是耗时还是比较快的,但是缺点很明显,就是无法预知SQL到底有多大,不能总是修改SQL默认的阈值
这种方式的优缺点也很明显,优点是耗时还是比较快的,但是缺点很明显,就是无法预知SQL到底有多大,不能总是修改SQL默认的阈值
3.3 批处理插入
/**
* 批处理插入
*/
@Test
public void saveByBatch() {
// 获取 10w 条测试数据
List<User> userList = getUserList();
// 开始时间
long start = System.currentTimeMillis();
// 批处理插入
userService.saveByBatch(userList);
// 结束时间
long end = System.currentTimeMillis();
System.out.println("十万条数据插入时间(批处理插入方式):" + (end - start) + " ms");
}
 可以看到使用批处理方式耗时仅1.3s,效率还是非常客观的。
可以看到使用批处理方式耗时仅1.3s,效率还是非常客观的。
但是需要注意几个问题:
-
同样需要开启允许重写批量处理提交 rewriteBatchedStatements=true -
代码中需要使用批处理模式,利用 SqlSessionFactory设置批处理模式并获取对应的Mapper接口 -
代码中也进行了分片操作 -
方法中加上 @Transactional注解起到手动提交事务的效果
3.4 mybatisPlus自带的批处理插入
/**
* mybatisPlus自带的批处理插入
*/
@Test
public void saveBatch() {
// 获取 10w 条测试数据
List<User> feeList = getUserList();
// 开始时间
long start = System.currentTimeMillis();
// MP 自带的批处理插入
userService.saveBatch(feeList);
// 结束时间
long end = System.currentTimeMillis();
System.out.println("十万条数据插入时间(mybatisPlus自带的批处理插入):" + (end - start) + " ms");
}
可以看到这种方式虽然比批处理插入方式差一丢丢,但是效率还是比较客观,不过同样需要开启允许重写批量处理提交 rewriteBatchedStatements=true
总结
-
使用 JDBC 推荐使用自己实现批处理方式
-
使用 MyBatis / MyBaits Plus 推荐使用自己实现的批处理方式或 mybatisPlus 自带的批处理方法 记得使用批处理方式进行批量插入一定要带上
rewriteBatchedStatements=true
本文由 mdnice 多平台发布
相关文章:
批量插入10w数据方法对比
环境准备(mysql5.7) CREATE TABLE user (id bigint(20) NOT NULL AUTO_INCREMENT COMMENT 唯一id,user_id bigint(10) DEFAULT NULL COMMENT 用户id-uuid,user_name varchar(100) NOT NULL COMMENT 用户名,user_age bigint(10) DEFAULT NULL COMMENT 用户年龄,create_time time…...

HAL STM32 I2C方式读取MT6701磁编码器获取角度例程
HAL STM32 I2C方式读取MT6701磁编码器获取角度例程 📍相关篇《Arduino通过I2C驱动MT6701磁编码器并读取角度数据》🎈《STM32 软件I2C方式读取MT6701磁编码器获取角度例程》📌MT6701当前最新文档资料:https://www.magntek.com.cn/u…...

如何排查nginx服务启动情况,杀死端口,以及防火墙开放指定端口【linux与nginx排查手册】
利用NGINX搭建了视频服务,突然发现启动不了了,于是命令开始 使用以下命令查看更详细的错误信息: systemctl status nginx.service Warning: The unit file, source configuration file or drop-ins of nginx.service changed on disk. Run…...
用Rust实现免费调用ChatGPT的命令行工具 (一)
代码已经开源:🚀 fgpt 欢迎大家star⭐和fork 👏 ChatGPT现在免费提供了GPT3.5的Web访问,不需要注册就可以直接使用,但是,它的使用方式是通过Web页面,不够方便。 更多技术分享关注 入职啦&…...

mysql 查询实战1-题目
学习了mysql 查询实战-变量方式-解答-CSDN博客,接着练习sql,从实战中多练习。 1,题目: 1,查询部门工资最高的员工 1,建表: DROP TABLE IF EXISTS department; create table department(dept_i…...

Word学习笔记之奇偶页的页眉与页码设置
1. 常用格式 在毕业论文中,往往有一下要求: 奇数页右下角显示、偶数页左下角显示奇数页眉为每章标题、偶数页眉为论文标题 2. 问题解决 2.1 前期准备 首先,不论时要求 1、还是要求 2,这里我们都要做一下设置: 鼠…...

数据赋能(58)——要求:数据赋能实施部门能力
“要求:数据赋能实施部门能力”是作为标准的参考内容编写的。 在实施数据赋能中,数据赋能实施部门的能力体现在多个方面,关键能力如下图所示。 在实施数据赋能的过程中,数据赋能实施部门应具备的关键能力如下。 理性思维与逻辑分…...
Unity URP PBR_Cook-Torrance模型
Cook-Torrance模型是一个微表面光照模型,认为物体的表面可以看作是由许多个理想的镜面反射体微小平面组成的。 单点反射镜面反射漫反射占比*漫反射 漫反射 基础色/Π 镜面反射DFG/4(NV)(NL) D代表微平面分布函数,描述的是法线与半角向量normalize(L…...
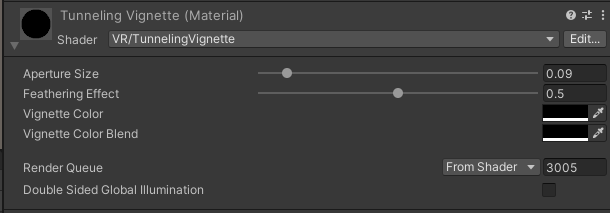
Unity之XR Interaction Toolkit如何在VR中实现渐变黑屏效果
前言 做VR的时候,有时会有跳转场景,切换位置,切换环境,切换进度等等需求,此时相机的画面如果不切换个黑屏,总会感觉很突兀。刚好Unity的XR Interaction Toolkit插件在2.5.x版本,出了一个TunnelingVignette的效果,我们今天就来分析一下他是如何使用的,然后我们自己再来…...
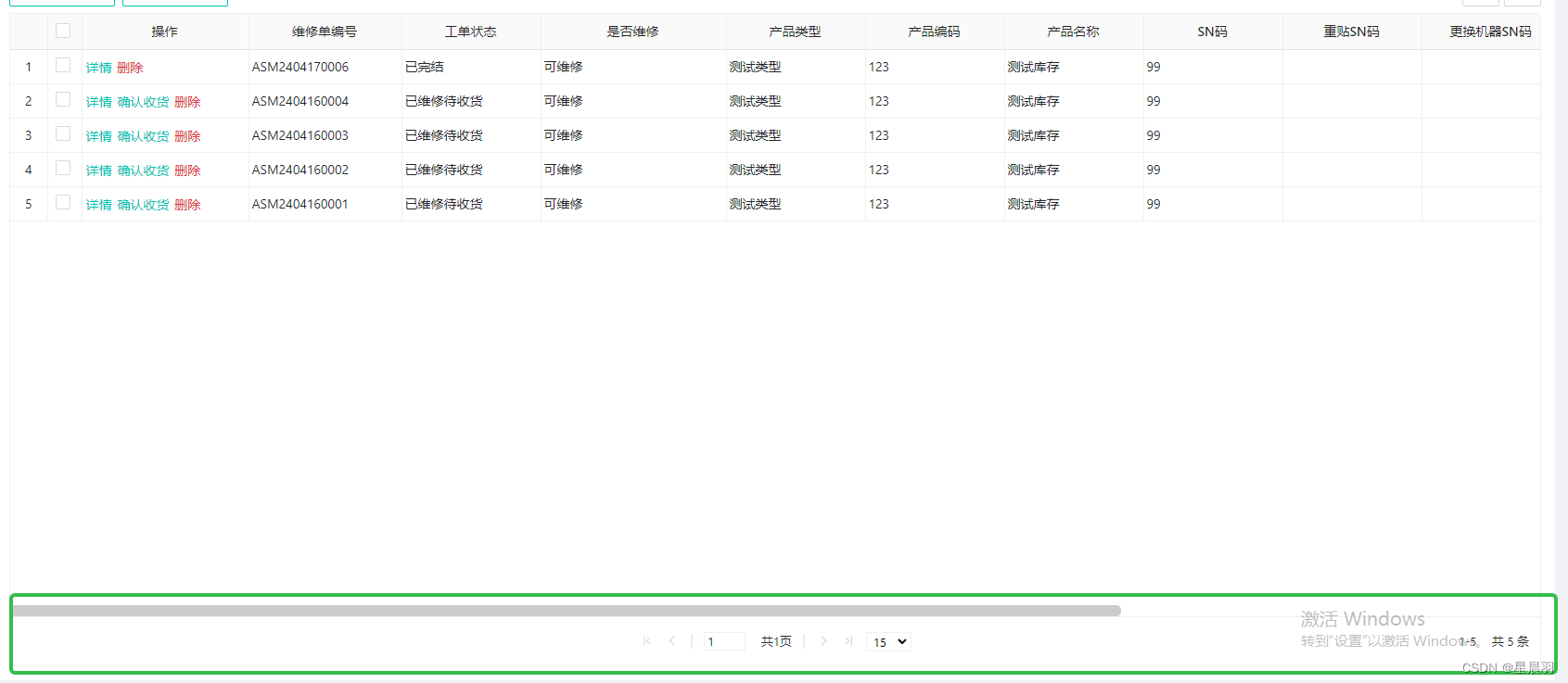
html+vue编写分页功能
效果: html关键代码: <div class"ui-jqgrid-resize-mark" id"rs_mlist_table_C87E35BE"> </div><div class"list_component_pager ui-jqgrid-pager undefined" dir"ltr"><div id"pg…...
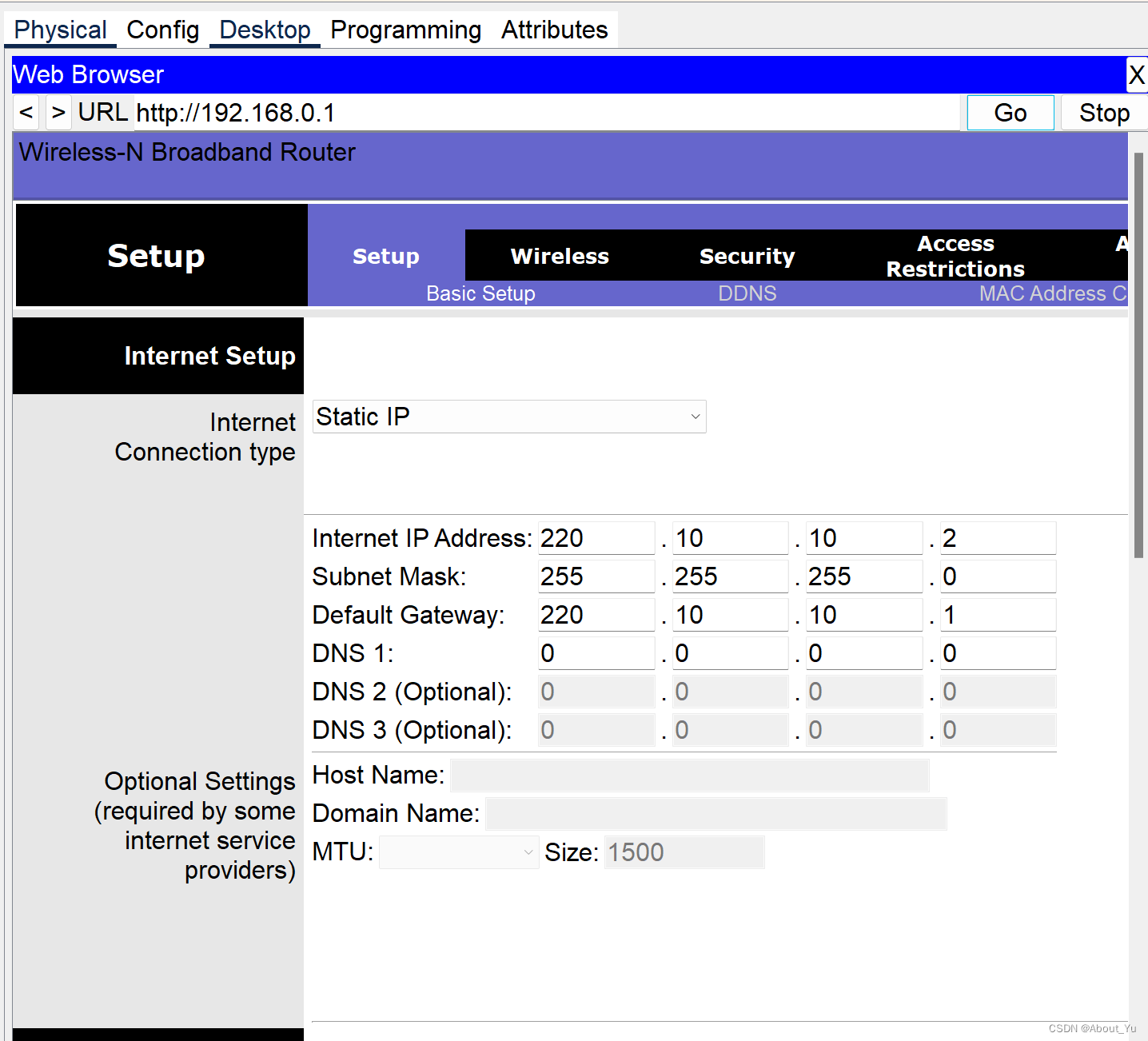
计算机网络 实验指导 实验17
实验17 配置无线网络实验 1.实验拓扑图 Table PC0 和 Table PC1 最开始可能还会连Access Point0,无影响后面会改 名称接口IP地址网关地址Router0fa0/0210.10.10.1fa0/1220.10.10.2Tablet PC0210.10.10.11Tablet PC1210.10.10.12Wireless互联网220.10.10.2LAN192.16…...

在 Vue中,v-for 指令的使用
在 Vue中,v-for 指令用于渲染一个列表,基于源数据多次渲染元素或模板块。它对于展示数组或对象中的数据特别有用。 数组渲染 假设你有一个数组,并且你想为每个数组元素渲染一个 <li> 标签: <template> <ul>…...

达梦数据库执行sql报错:数据溢出
数据库执行sql报错数据溢出 单独查询对应的数字进行计算是不是超过了某个字段类型的上限或下限 如果已经超过了,进行对字段进行cast类型转换处理,转换为dec num都可以尝试 这里就是从 max(T.BLOCK_ID as dec*8192t.bytes)/1024/1024 max_MB,换成了这个…...
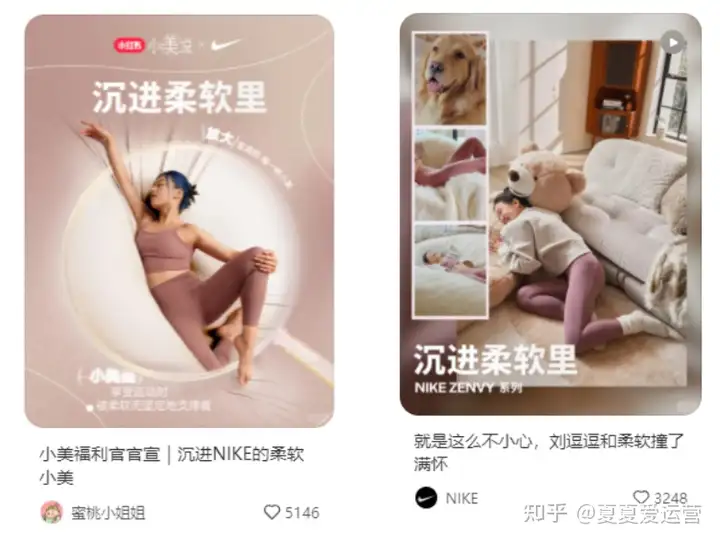
从「宏大叙事」到「生活叙事」,小红书品牌种草的的“正确姿势”
不同于抖音和微博,在小红书上,品牌营销的基调应该是怎样的?品牌怎样与小红书用户对话?什么样的内容,才能走进小红书用户的心中?本期,小编将带大家洞察品牌在小红书营销的“正确姿势”。从「小美…...

Python Selenium 的基本使用方法
文章目录 1. 概述2. 安装Chrome及ChromeDriver2.1 安装Chrome2.2 安装ChromeDriver 3. 安装Selenium4. 常见用法4.1 启动4.2 查找元素4.3 等待页面加载元素 1. 概述 Selenium 是一个用于自动化 web 浏览器的工具,它提供了一套用于测试 web 应用程序的工具和库。Sel…...
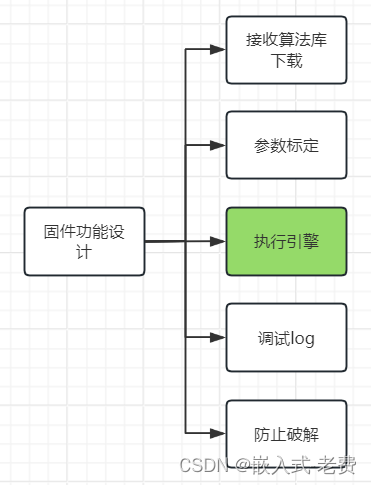
上位机图像处理和嵌入式模块部署(树莓派4b固件功能设计)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 前面我们说过,上位机的功能都是基于插件进行开发的。但是上位机的成本比较贵,一般的企业不一定愿意接接受。这个时候另外一…...

新手入门人工智能:从零开始学习AI的正确途径
你是否对人工智能(AI)充满了好奇心和探索欲?你是否想了解如何从零开始学习AI,成为一名人工智能领域的专家?那么,这篇文章就是为你准备的!我们将带你了解人工智能的基本概念,学习如何…...

ubuntu git相关操作
1 安装git sudo apt install git git --version git version 2.25.1 2 解决git超时 2.1 扩大post的buffer git config --global http.postBuffer 524288000 git config --global http.postBuffer 157286400 2.2 换回HTTP1上传。上传之后再切换回HTTP2 …...
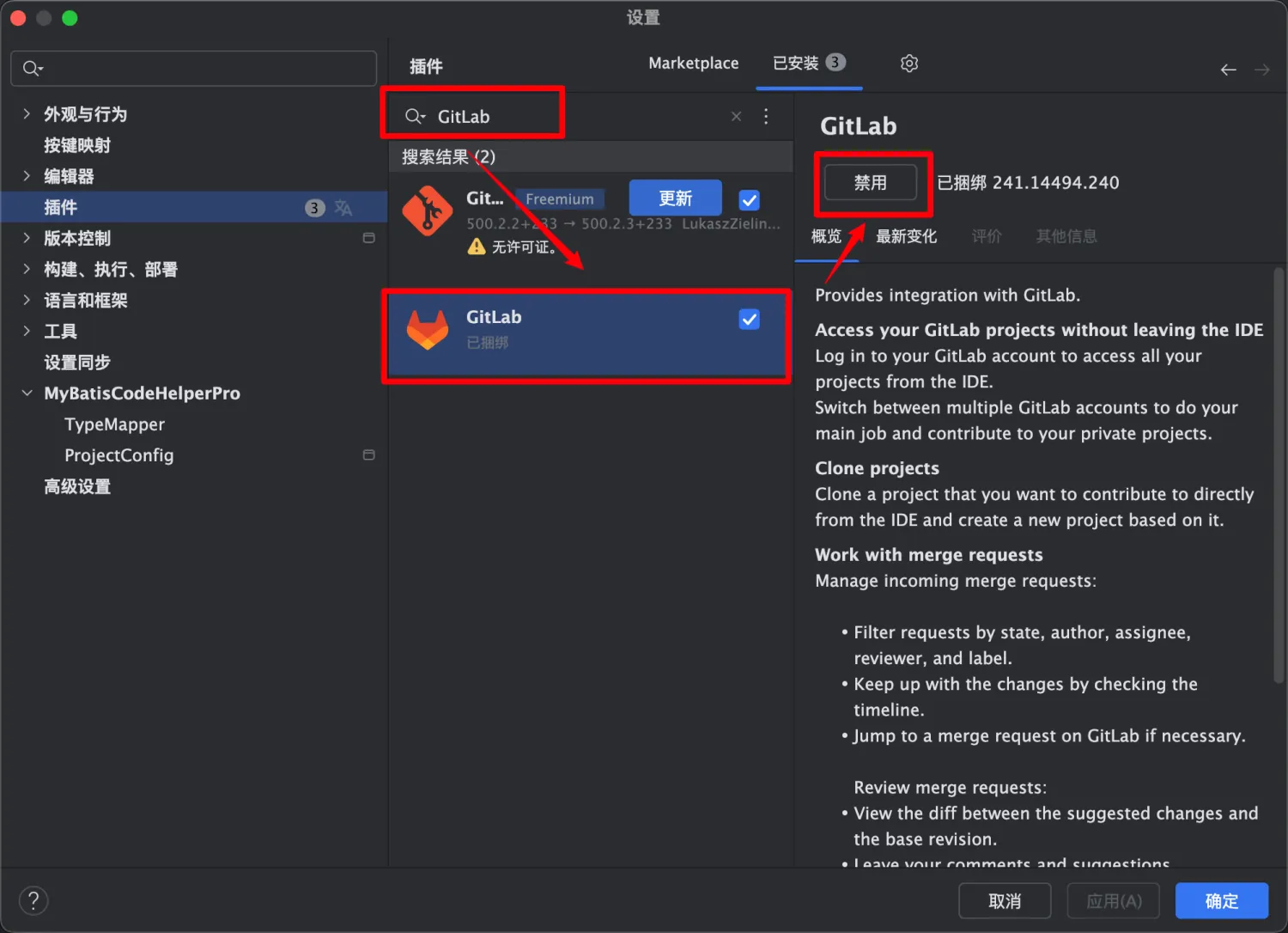
IDEA工具|添加 GitLab 账户之两三事
📫 作者简介:「六月暴雪飞梨花」,专注于研究Java,就职于科技型公司后端工程师 🏆 近期荣誉:华为云云享专家、阿里云专家博主、腾讯云优秀创作者、ACDU成员 🔥 三连支持:欢迎 ❤️关注…...
)
蓝桥杯:棋盘(Java)
目录 问题描述输入格式输出格式代码实现 问题描述 小蓝拥有n n大小的棋盘,一开始棋盘上全都是白子。小蓝进行了m.次操作,每次操作会将棋盘上某个范围内的所有棋子的颜色取反(也就是白色棋子变为黑色,黑色棋子变为白色)。请输出所…...

ARM核心板在POCT设备开发中的选型与应用实战
1. 项目概述:ARM核心板如何重塑POCT设备开发在医疗设备这个对稳定性和可靠性要求近乎苛刻的领域,每一次技术选型都像是一次精密的手术,容不得半点闪失。我接触过不少体外诊断(IVD)设备厂商,尤其是做即时检验…...

智能语义分块:chunkhound如何解决RAG应用中的文档处理难题
1. 项目概述:从“分块”到“猎犬”的智能进化如果你在数据处理的深海里游过泳,尤其是处理过那些动辄几十上百GB的文本、代码或日志文件,那你一定对“分块”(Chunking)这个概念又爱又恨。爱的是,它是我们处理…...

基于CircuitPython与RP2350的嵌入式多声道音频系统设计与实践
1. 项目概述:用CircuitPython打造你的专属交互式音频系统如果你玩过树莓派Pico或者Adafruit的Feather系列开发板,可能会觉得在微控制器上处理音频是件挺麻烦的事——要么得用专门的解码芯片,要么代码复杂得让人头疼。但最近我在一个互动艺术装…...

青岛X射线探伤机服务好的供应商
在工业检测领域,X射线探伤机并非一次性采购的设备——它需要持续的技术支持、稳定的运行保障,以及服务商在关键时刻的响应能力。选择一家服务好的供应商,往往比选择一台设备本身更需要慎重。在青岛,有一家名为华誉机电设备有限公司…...

GraphRAG 深度解析:把知识图谱接进检索链路,多跳推理准确率从 50% 提到 85%
很多同学搭完向量 RAG 之后,调了无数遍 Chunk 大小、换了好几个 Embedding 模型,多跳推理准确率就是卡在 50% 左右,怎么都上不去。比如「A 公司 CTO 和 B 公司 CEO 到底有什么合作关系」这类问题,答案散落在三个文档里,…...
)
DeepSeek MMLU 86.7分是怎么炼成的?从提示工程、校准策略到知识蒸馏链路(内部训练日志首次公开)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek MMLU 86.7分的里程碑意义与基准解读 MMLU 基准的本质与挑战 MMLU(Massive Multitask Language Understanding)是一项覆盖57个学科领域的综合性评测基准,涵…...

为什么顶尖考古团队已弃用传统文献管理?NotebookLM实现遗址报告生成效率提升300%的底层逻辑
更多请点击: https://intelliparadigm.com 第一章:NotebookLM考古学研究辅助的范式革命 NotebookLM 作为 Google 推出的基于文档理解的 AI 助手,正悄然重塑考古学研究的信息处理范式。传统考古工作依赖大量手写笔记、田野报告、碳十四测年数…...

2026届最火的AI论文助手解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在人工智能生成内容(AIGC)技术迅猛发展之际,它一方面提升…...

别再混淆了!给数据科学新手的平稳性、自相关性核心概念白话图解
时间序列分析入门:用生活化类比理解平稳性与自相关性 刚接触时间序列分析时,你是否曾被"平稳性"和"自相关性"这些术语搞得一头雾水?就像第一次学游泳时,教练说的"打腿节奏"和"换气时机"一…...

Barlow字体完全指南:如何用这款开源字体提升设计质感
Barlow字体完全指南:如何用这款开源字体提升设计质感 【免费下载链接】barlow Barlow: a straight-sided sans-serif superfamily 项目地址: https://gitcode.com/gh_mirrors/ba/barlow 想要为你的设计项目寻找一款既现代又实用的免费字体吗?Barl…...