NLP transformers - 文本分类

Text classification
文章目录
- Text classification
- 加载 IMDb 数据集
- Preprocess 预处理
- Evaluate
- Train
- Inference
本文翻译自:Text classification
https://huggingface.co/docs/transformers/tasks/sequence_classification
notebook : https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/pytorch/sequence_classification.ipynb
文本分类是一种常见的 NLP 任务,它为文本分配标签或类别。一些大公司在生产中运行文本分类,以实现广泛的实际应用。最流行的文本分类形式之一是 情感分析,它为文本序列分配 🙂 积极、🙁 消极或 😐 中性等标签。
本指南将向您展示:
- 在IMDb数据集上微调DistilBERT,以确定电影评论是正面还是负面。
- 使用您的微调模型进行推理。
本教程中演示的任务由以下模型架构支持:
ALBERT, BART, BERT, BigBird, BigBird-Pegasus, BioGpt, BLOOM, CamemBERT, CANINE, CodeLlama, ConvBERT, CTRL, Data2VecText, DeBERTa, DeBERTa-v2, DistilBERT, ELECTRA, ERNIE, ErnieM, ESM, Falcon, FlauBERT, FNet, Funnel Transformer, Gemma, GPT-Sw3, OpenAI GPT-2, GPTBigCode, GPT Neo, GPT NeoX, GPT-J, I-BERT, Jamba, LayoutLM, LayoutLMv2, LayoutLMv3, LED, LiLT, LLaMA, Longformer, LUKE, MarkupLM, mBART, MEGA, Megatron-BERT, Mistral, Mixtral, MobileBERT, MPNet, MPT, MRA, MT5, MVP, Nezha, Nyströmformer, OpenLlama, OpenAI GPT, OPT, Perceiver, Persimmon, Phi, PLBart, QDQBert, Qwen2, Qwen2MoE, Reformer, RemBERT, RoBERTa, RoBERTa-PreLayerNorm, RoCBert, RoFormer, SqueezeBERT, StableLm, Starcoder2, T5, TAPAS, Transformer-XL, UMT5, XLM, XLM-RoBERTa, XLM-RoBERTa-XL, XLNet, X-MOD, YOSO
在开始之前,请确保已安装所有必需的库:
pip install transformers datasets evaluate accelerate
我们鼓励您登录 Hugging Face 帐户,以便您可以上传模型并与社区分享。出现提示时,输入您的令牌进行登录:
from huggingface_hub import notebook_loginnotebook_login()
加载 IMDb 数据集
首先从 🤗 数据集库加载 IMDb 数据集:
from datasets import load_datasetimdb = load_dataset("imdb")
然后看一个数据样例:
IMDB[ “测试” ][ 0 ]
{"label" : 0 ,"text" : "我喜欢科幻小说,并且愿意忍受很多。... 一切又来了。” ,
}
该数据集中有两个字段:
text: 影评文字。label:0:表示负面评论或1正面评论的值。
Preprocess 预处理
下一步是加载 DistilBERT 分词器来预处理该text字段:
from transformers import AutoTokenizertokenizer = AutoTokenizer.from _pretrained( "distilbert/distilbert-base-uncased" )
创建一个预处理函数来对text序列进行标记和截断,使其长度不超过 DistilBERT 的最大输入长度:
def preprocess_function ( Examples ):return tokenizer(examples[ "text" ], truncation= True )
要将预处理函数应用于整个数据集,请使用 🤗 数据集 map 函数。
您可以map通过设置 batched=True 一次处理数据集的多个元素来加快速度:
tokenized_imdb = imdb.map(preprocess_function, batched=True)
现在使用 DataCollatorWithPadding 创建一批示例。在整理过程中 动态地将句子填充 到批次中的最长长度,比将整个数据集填充到最大长度更有效。
from transformers import DataCollatorWithPaddingdata_collator = DataCollatorWithPadding(tokenizer=tokenizer)
Evaluate
在训练期间包含指标通常有助于评估模型的性能。您可以使用 🤗 Evaluate库快速加载评估方法。对于此任务,加载准确性指标(请参阅 🤗 评估快速浏览以了解有关如何加载和计算指标的更多信息):
import evaluateaccuracy = evaluate.load("accuracy")
然后创建一个传递预测和标签的函数来compute计算准确性:
import numpy as npdef compute_metrics(eval_pred):predictions, labels = eval_predpredictions = np.argmax(predictions, axis=1)return accuracy.compute(predictions=predictions, references=labels)
您的compute_metrics函数现在已准备就绪,您将在设置训练时返回该函数。
Train
在开始训练模型之前,请使用id2label 和 label2id ,创建预期 id 到其标签的映射:
id2label = {0: "NEGATIVE", 1: "POSITIVE"}
label2id = {"NEGATIVE": 0, "POSITIVE": 1}
如果您不熟悉使用 Trainer 微调模型,
请查看基本教程:<(https://huggingface.co/docs/transformers/training#train-with-pytorch-trainer>
您现在就可以开始训练您的模型了!使用 AutoModelForSequenceClassification 加载 DistilBERT以及预期标签的数量和标签映射:
from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainermodel = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased", num_labels=2, id2label=id2label, label2id=label2id
)
此时,只剩下三步:
- 在TrainingArguments中定义训练超参数。
唯一必需的参数是output_dir指定保存模型的位置。您可以通过设置将此模型推送到 Hubpush_to_hub=True(您需要登录 Hugging Face 才能上传模型)。
在每个 epoch 结束时,Trainer 将评估准确性并保存训练检查点。 - 将训练参数以及模型、数据集、分词器、数据整理器和
compute_metrics函数传递给Trainer 。 - 调用 train() 来微调您的模型。
training_args = TrainingArguments(output_dir="my_awesome_model",learning_rate=2e-5,per_device_train_batch_size=16,per_device_eval_batch_size=16,num_train_epochs=2,weight_decay=0.01,evaluation_strategy="epoch",save_strategy="epoch",load_best_model_at_end=True,push_to_hub=True,
)trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_imdb["train"],eval_dataset=tokenized_imdb["test"],tokenizer=tokenizer,data_collator=data_collator,compute_metrics=compute_metrics,
)trainer.train()
当您传递 token 给Trainer时, 它默认应用动态填充tokenizer。在这种情况下,您不需要显式指定数据整理器。
训练完成后,使用 push_to_hub()方法将您的模型共享到 Hub,以便每个人都可以使用您的模型:
trainer.push_to_hub()
有关如何微调文本分类模型的更深入示例,请查看相应的 PyTorch 笔记本 或 TensorFlow 笔记本。
Inference
太好了,现在您已经微调了模型,您可以使用它进行推理!
获取一些您想要进行推理的文本:
text = “这是一部杰作。并不完全忠实于原著,但从头到尾都令人着迷。可能是三本书中我最喜欢的。”
尝试微调模型进行推理的最简单方法是在 pipeline() 中使用它。使用您的模型实例化pipeline情感分析,并将文本传递给它:
from transformers import pipelineclassifier = pipeline("sentiment-analysis", model="stevhliu/my_awesome_model")
classifier(text)
如果您愿意,您还可以手动复制 pipeline 的结果:
对文本进行分词并返回 PyTorch 张量:
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_model")
inputs = tokenizer(text, return_tensors="pt")
将您的输入传递给模型并返回logits:
from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained("stevhliu/my_awesome_model")with torch.no_grad():logits = model(**inputs).logits
获取概率最高的类,并使用模型的id2label映射将其转换为文本标签:
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
# -> 'POSITIVE'
2024-04-28(日)
相关文章:
NLP transformers - 文本分类
Text classification 文章目录 Text classification加载 IMDb 数据集Preprocess 预处理EvaluateTrainInference 本文翻译自:Text classification https://huggingface.co/docs/transformers/tasks/sequence_classification notebook : https://colab.research.googl…...
QT 开发COM(ActiveX)组件基础介绍和方案验证
一、COM简介 1.1 COM是什么? COM,Component Object Model,即组件对象模型,是一种以组件为发布单元的对象模型,这种模型使各软件组件可以用一种统一的方式进行交互。COM 既提供了组件之间进行交互的规范,也…...
[1673]jsp在线考试管理系统Myeclipse开发mysql数据库web结构java编程计算机网页项目
一、源码特点 JSP 在线考试管理系统是一套完善的java web信息管理系统,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为TOMCAT7.0,Myeclipse8.5开发,数据库为Mysql5.0&…...

每日一算法
问题 等待登机的你看着眼前有老有小长长的队伍十分无聊,你突然 想要知道,是否存在两个年龄相仿的乘客。每个乘客的年龄用 1个0 到 36500 的整数表示,两个乘客的年龄相差 365 以内 就认为是相仿的。 具体来说,你有一个长度为 n 的…...

Spring Cloud Gateway直接管理Vue.js的静态资源
1. 构建Vue.js应用 像之前一样,构建你的Vue.js应用,并将生成的静态资源(位于dist目录)复制到Spring Boot项目的某个目录,比如src/main/resources/static。 2. 配置Spring Boot静态资源处理 Spring Boot默认会处理sr…...
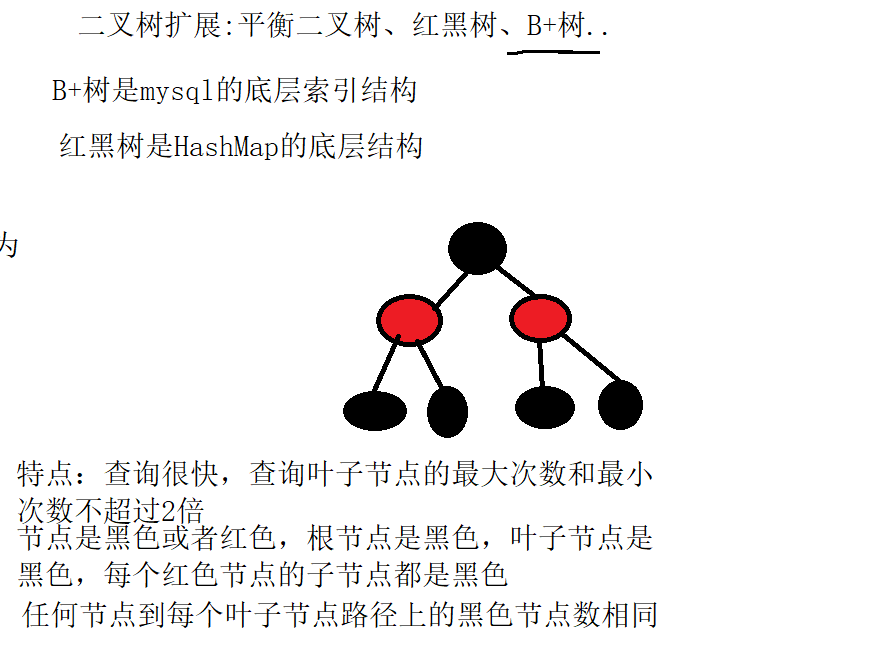
14.集合、常见的数据结构
集合 概念 Java中的集合就是一个容器,用来存放Java对象。 集合在存放对象的时候,不同的容器,存放的方法实现是不一样的, Java中将这些不同实现的容器,往上抽取就形成了Java的集合体系。 Java集合中的根接口&#x…...

NLP从入门到实战——命名实体识别
1. 命名实体识别 1.1 概念 中文命名实体识别(Named Entity Recognition,NER是指识别中文文本中实体的边界和类别。命名实体识别是文本处理中的基础技术,广泛应用在自然语言处理、推荐系统、知识图谱等领域,比如推荐系统中的基于…...

接口测试工具-postman介绍
一、介绍 Postman是一款功能强大的网页调试与发送网页HTTP请求的Chrome插件。 作用:常用于进行接口测试。 它可以模拟浏览器发起任何形式的HTTP请求...
服务器爆了)
日志中看到来自User Agent go-http-client / 1.1的大量请求(go-http-client 1.1)服务器爆了
在日志中看到来自User Agent go-http-client / 1.1的大量请求 The go-http-client/1.1 User Agent 是Google的Bot / Crawler 这不是真的。这可能是指Go库(根据您提到的来源,由Google开发,但是我找不到可靠的信息)。 之前写过“G…...
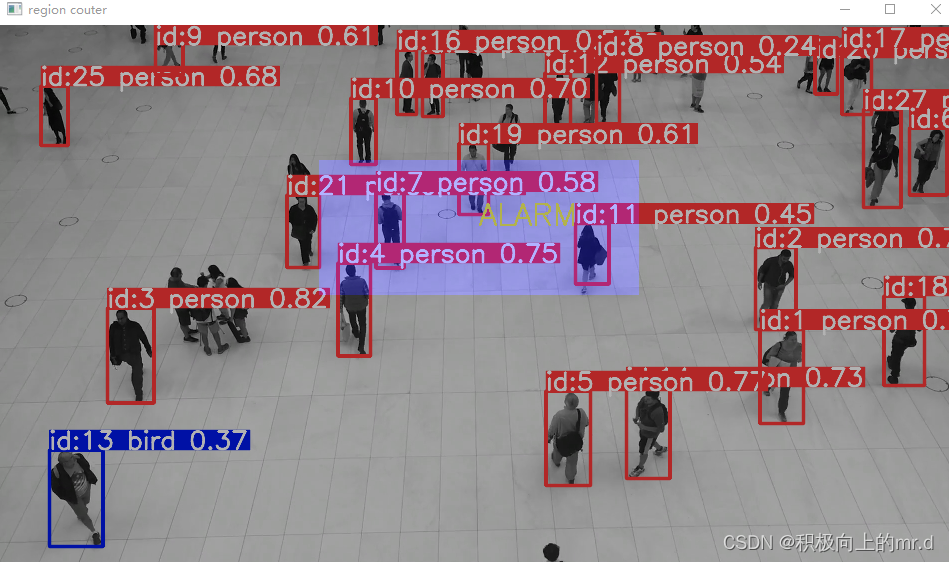
yolov8 区域声光报警+计数
yolov8 区域报警计数 1. 基础2. 报警功能2. 1声音报警代码2. 2画面显示报警代码 3. 完整代码4. 源码 1. 基础 本项目是在 yolov8 区域多类别计数 的基础上实现的,具体区域计数原理可见上边文章 2. 报警功能 设置一个区域region_points,当行人这一类别…...

《QT实用小工具·五十五》带有标签、下划线的Material Design风格输入框
1、概述 源码放在文章末尾 该项目实现了一个带有标签动画、焦点动画、正确提示、错误警告的单行输入框控件。下面是demo演示: 项目部分代码如下所示: #ifndef LABELEDEDIT_H #define LABELEDEDIT_H#include <QObject> #include <QWidget>…...

用Go实现一个无界资源池
写在文章开头 我们希望通过go语言实现一个简单的资源池,而这个资源池的资源包括但不限于: 数据库连接池线程池协程池网络连接池 只要这些资源实现我们指定的关闭方法,则都可以通过我们封装的资源池进行统一管理,需要简单说明一下这个资源池…...
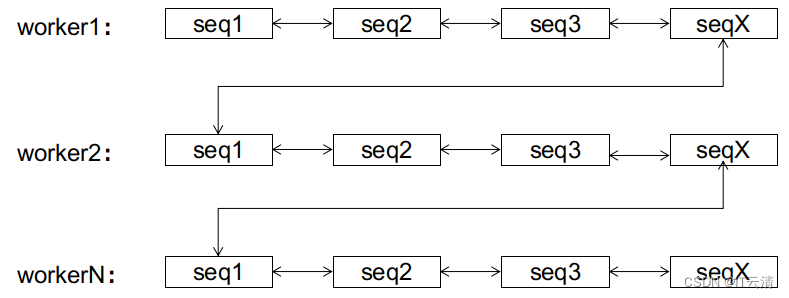
Apache Seata基于改良版雪花算法的分布式UUID生成器分析2
title: 关于新版雪花算法的答疑 author: selfishlover keywords: [Seata, snowflake, UUID, page split] date: 2021/06/21 本文来自 Apache Seata官方文档,欢迎访问官网,查看更多深度文章。 关于新版雪花算法的答疑 在上一篇关于新版雪花算法的解析中…...

13、揭秘JVM垃圾回收器:面试必备知识,你掌握了吗?
13.1、前文回顾 在上一篇文章中,我们详细分析了触发Minor GC的时机,以及对象何时会从新生代迁移到老年代。我们还讨论了为了确保新生代向老年代的内存迁移安全,需要在Minor GC之前如何检查老年代的内存空间,以及在什么情况下会触发老年代的Full GC,以及老年代的垃圾回收算…...
治疗耳鸣患者案例分享第二期
“患者耳鸣20年了,目前耳朵没有堵或者胀的感觉,但是偶尔有点痒,平时会有头晕头胀这种情况,然后头晕是稍微晕炫一下。然后头疼是经常有的,头胀不经常。” 患者耳鸣持续20年,虽然耳朵没有堵或胀的感觉&#x…...

数据加密的方法
这些方法可以单独或结合使用,以提高数据的安全性和保护隐私。 对称加密:使用相同的密钥对数据进行加密和解密。常见的对称加密算法包括DES、AES和RC4。 非对称加密:使用一对密钥(公钥和私钥)对数据进行加密和解密。发…...

Android BINDER是干嘛的?
1.系统架构 2.binder 源码位置: 与LINUX传统IPC对比...
)
运维各种中间件的手动安装(非常详细)
压缩文件夹 tar -zcvf newFolder.tar.gz oldFolder 把oldFolder文件夹压缩成newFolder.tar.gz解压文件夹 tar -zxvf 压缩文件名.tar.gzlinux安装jdk (参考 https://blog.csdn.net/qq_42269466/article/details/124079963 ) 1、创建目录存放jdk包 mkd…...

【Android】Android应用性能优化总结
AndroidApp应用性能优化总结 最近大半年的时间里,大部分投在了某国内新能源汽车的某款AndroidApp开发上。 由于该App是该款车上,常用重点应用。所以车厂对应用性能的要求比较高。 主要包括: 应用冷启动达到***ms。应用热(温)启动达到***ms应…...

FBA头程海运发货流程是怎样的?
FBA头程发货作为整个FBA流程的关键一环,更是直接影响到商品从起点到终点的流通效率和成本。其中,海运作为一种经济、稳定的运输方式,在FBA头程发货中扮演着举足轻重的角色。那么,FBA头程海运发货流程究竟是怎样的呢? 1、装箱与发…...
图解ConvTranspose1d:从计算图到代码实现的逆向思维
1. 从Conv1d到ConvTranspose1d的思维转换 第一次接触ConvTranspose1d时,我和大多数人一样困惑:为什么要把好好的卷积操作反过来计算?直到在语音合成项目中被迫深入使用后,才明白这种"逆向思维"的价值。想象你正在玩拼图…...

3步解放暗黑2存档:Diablo Edit2角色编辑器完全指南
3步解放暗黑2存档:Diablo Edit2角色编辑器完全指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾因暗黑破坏神2角色build失误而懊恼?是否厌倦了数百小时刷装备却…...

英伟达收购SwiftStack:AI时代从算力到数据管道的战略布局
1. 项目概述:一次战略收购的深度拆解最近在梳理科技巨头的战略动向时,一个几年前的老新闻——“英伟达收购SwiftStack”——重新进入了我的视野。乍一看,这似乎只是一次普通的商业并购,一个做GPU的巨头买下了一家名不见经传的软件…...

3分钟解锁WeMod高级功能:开源工具Wand-Enhancer完全指南
3分钟解锁WeMod高级功能:开源工具Wand-Enhancer完全指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否因为WeMod的高级功能需要付费…...

RK3568 Debian系统Docker安装与ARM64容器化部署实战指南
1. 项目概述与核心价值最近在折腾一块基于瑞芯微RK3568的开发板,想在上面跑一些服务,自然而然地就想到了Docker。毕竟,Docker带来的环境隔离和便捷部署,对于嵌入式开发和边缘计算场景来说,简直是“神器”。但当我真正动…...
终极指南:从入门到实战的完整教程)
多尺度地理加权回归(MGWR)终极指南:从入门到实战的完整教程
多尺度地理加权回归(MGWR)终极指南:从入门到实战的完整教程 【免费下载链接】mgwr Multiscale Geographically Weighted Regression (MGWR) 项目地址: https://gitcode.com/gh_mirrors/mg/mgwr 面对复杂多变的空间数据,传统的地理加权回归(GWR)常…...

终极Java数据结构指南:从链表到红黑树的实现与原理
终极Java数据结构指南:从链表到红黑树的实现与原理 【免费下载链接】CodeGuide :books: 本代码库是作者小傅哥多年从事一线互联网 Java 开发的学习历程技术汇总,旨在为大家提供一个清晰详细的学习教程,侧重点更倾向编写Java核心内容。如果本仓…...

怎么快速降AI率?答辩前1周从60%降到10%以内实操指南!
怎么快速降AI率?答辩前1周从60%降到10%以内实操指南! 答辩前 1 周拿到 AI 率 65% 报告,是什么具体场景? 周一早上 9 点。我硕士答辩定在下周一上午 9 点——还有整整 7 天。导师周日晚发消息:「答辩前再送一次维普看…...
【Transformer系列】从One-Hot到Embedding:构建AI语言理解的基石
1. 从One-Hot编码说起:AI的第一堂语言课 想象你正在教一个外星人认识汉字。你拿出一本字典说:"这里有10万个字,每个字对应一个编号,猫是第12345号,狗是第67890号。"这就是最原始的One-Hot编码思想——用一串…...

我的思维模型 -- 11.数学与统计学篇
正态分布 核心逻辑:均值回归中心极限定理:大量相互独立、来自同一分布的随机变量,它们的平均值(或总和)在样本量足够大时,都会趋向于正态分布约 68% 的数据落在 范围内约 95% 的数据落在 范围内均值…...