python数据处理(pandas)
# 新的数据格式,csv
- 纯文本,使用某个字符集,比如都是ASCII、Unicode、EBCDIC或GB2312(简体中文环境)等;
- 由记录组成(典型的是每行一条记录)
- 每条记录被分隔符(英语:Delimiter)分隔为字段(英语:Field(computer science))(典型分隔符号有逗号、分号或制表符;有时分隔符可以包括可选的空格)
- 每条记录都有同样的字段序列
import pandas as pd
import numpy as np
abs_path = r'F:\Python\learn\python附件\pythonCsv\data.csv'
df = pd.read_csv(abs_path,encoding='gbk')
df.head(2)
| 序号 | 姓名 | 性别 | 语文 | 数学 | 英语 | 物理 | 化学 | 生物 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 渠敬辉 | 男 | 80 | 60 | 30 | 40 | 30 | 60 |
| 1 | 2 | 韩辉 | 男 | 90 | 95 | 75 | 75 | 80 | 85 |
type(df)
pandas.core.frame.DataFrame
DataFrame
# 列名
print(df.columns)
# 索引
print(df.index)
Index(['序号', '姓名', '性别', '语文', '数学', '英语', '物理', '化学', '生物'], dtype='object')
RangeIndex(start=0, stop=7, step=1)
df.loc[0]
序号 1
姓名 渠敬辉
性别 男
语文 80
数学 60
英语 30
物理 40
化学 30
生物 60
Name: 0, dtype: object
a = np.array(range(10))
a > 3
array([False, False, False, False, True, True, True, True, True,True])
# 筛选数学成绩大于80
df[df.数学 > 80]
| 序号 | 姓名 | 性别 | 语文 | 数学 | 英语 | 物理 | 化学 | 生物 | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 韩辉 | 男 | 90 | 95 | 75 | 75 | 80 | 85 |
| 3 | 4 | 石天洋 | 男 | 90 | 90 | 95 | 80 | 75 | 80 |
df[df.数学 < 80]
| 序号 | 姓名 | 性别 | 语文 | 数学 | 英语 | 物理 | 化学 | 生物 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 渠敬辉 | 男 | 80 | 60 | 30 | 40 | 30 | 60 |
| 4 | 5 | 张三 | 男 | 60 | 60 | 60 | 60 | 60 | 60 |
| 6 | 7 | 王五 | 男 | 70 | 70 | 70 | 70 | 70 | 70 |
# 复杂筛选
df[(df.语文 > 80) & (df.数学 > 80) & (df.英语 > 80)]
| 序号 | 姓名 | 性别 | 语文 | 数学 | 英语 | 物理 | 化学 | 生物 | |
|---|---|---|---|---|---|---|---|---|---|
| 3 | 4 | 石天洋 | 男 | 90 | 90 | 95 | 80 | 75 | 80 |
排序
df.sort_values(['数学','语文','英语']).head()
| 序号 | 姓名 | 性别 | 语文 | 数学 | 英语 | 物理 | 化学 | 生物 | |
|---|---|---|---|---|---|---|---|---|---|
| 4 | 5 | 张三 | 男 | 60 | 60 | 60 | 60 | 60 | 60 |
| 0 | 1 | 渠敬辉 | 男 | 80 | 60 | 30 | 40 | 30 | 60 |
| 6 | 7 | 王五 | 男 | 70 | 70 | 70 | 70 | 70 | 70 |
| 5 | 6 | 李四 | 女 | 80 | 80 | 80 | 80 | 80 | 80 |
| 2 | 3 | 韩文晴 | 女 | 95 | 80 | 85 | 60 | 80 | 90 |
访问
# 按照索引去定位
df.loc[3]
序号 4
姓名 石天洋
性别 男
语文 90
数学 90
英语 95
物理 80
化学 75
生物 80
Name: 3, dtype: object
索引
scores = {'英语':[90,78,89],'数学':[64,78,45],'姓名':['wong','li','sun']
}
df = pd.DataFrame(scores,index=['one','two','three'])
df
| 英语 | 数学 | 姓名 | |
|---|---|---|---|
| one | 90 | 64 | wong |
| two | 78 | 78 | li |
| three | 89 | 45 | sun |
df.index
Index(['one', 'two', 'three'], dtype='object')
# 因为此时不存在数字索引,所以不能通过数字索引去访问
# df.loc[1]
df.loc['one']
英语 90
数学 64
姓名 wong
Name: one, dtype: object
# 实实在在的所谓的第几行
df.iloc[0]
英语 90
数学 64
姓名 wong
Name: one, dtype: object
# 合并了loc和iloc的功能,新版本下ix方法已被弃用
df.ix[0]
---------------------------------------------------------------------------AttributeError Traceback (most recent call last)<ipython-input-22-413c174d3cd1> in <module>1 # 合并了loc和iloc的功能
----> 2 df.ix[0]G:\Anaconda\lib\site-packages\pandas\core\generic.py in __getattr__(self, name)5272 if self._info_axis._can_hold_identifiers_and_holds_name(name):5273 return self[name]
-> 5274 return object.__getattribute__(self, name)5275 5276 def __setattr__(self, name: str, value) -> None:AttributeError: 'DataFrame' object has no attribute 'ix'
df.loc[:2]
| 序号 | 姓名 | 性别 | 语文 | 数学 | 英语 | 物理 | 化学 | 生物 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 渠敬辉 | 男 | 80 | 60 | 30 | 40 | 30 | 60 |
| 1 | 2 | 韩辉 | 男 | 90 | 95 | 75 | 75 | 80 | 85 |
| 2 | 3 | 韩文晴 | 女 | 95 | 80 | 85 | 60 | 80 | 90 |
# 当索引为数字索引的时候,ix和loc是等价的,新版本下ix方法已被弃用
df.ix[:2]
---------------------------------------------------------------------------AttributeError Traceback (most recent call last)<ipython-input-33-a97de2692f80> in <module>1 #当索引为数字索引的时候,ix和loc是等价的
----> 2 df.ix[:2]G:\Anaconda\lib\site-packages\pandas\core\generic.py in __getattr__(self, name)5272 if self._info_axis._can_hold_identifiers_and_holds_name(name):5273 return self[name]
-> 5274 return object.__getattribute__(self, name)5275 5276 def __setattr__(self, name: str, value) -> None:AttributeError: 'DataFrame' object has no attribute 'ix'
# 访问某一行,是错误的
# df[0]# 访问多行数据是可以使用切片的
df[:2]
| 序号 | 姓名 | 性别 | 语文 | 数学 | 英语 | 物理 | 化学 | 生物 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 渠敬辉 | 男 | 80 | 60 | 30 | 40 | 30 | 60 |
| 1 | 2 | 韩辉 | 男 | 90 | 95 | 75 | 75 | 80 | 85 |
# dataframe中的数组
df.数学.values
array([60, 95, 80, 90, 60, 80, 70], dtype=int64)
# 简单的统计
df.数学.value_counts()
60 2
80 2
95 1
70 1
90 1
Name: 数学, dtype: int64
# 提取多列
new = df[['数学','语文']].head()
new
| 数学 | 语文 | |
|---|---|---|
| 0 | 60 | 80 |
| 1 | 95 | 90 |
| 2 | 80 | 95 |
| 3 | 90 | 90 |
| 4 | 60 | 60 |
new * 2
| 数学 | 语文 | |
|---|---|---|
| 0 | 120 | 160 |
| 1 | 190 | 180 |
| 2 | 160 | 190 |
| 3 | 180 | 180 |
| 4 | 120 | 120 |
重点
def func(score):if score>=80:return '优秀'elif score>=70:return '良'elif score>=60:return '及格'else:return '不及格'passdf['数学分类'] = df.数学.map(func)
df.head()
| 序号 | 姓名 | 性别 | 语文 | 数学 | 英语 | 物理 | 化学 | 生物 | 数学分类 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 渠敬辉 | 男 | 80 | 60 | 30 | 40 | 30 | 60 | 及格 |
| 1 | 2 | 韩辉 | 男 | 90 | 95 | 75 | 75 | 80 | 85 | 优秀 |
| 2 | 3 | 韩文晴 | 女 | 95 | 80 | 85 | 60 | 80 | 90 | 优秀 |
| 3 | 4 | 石天洋 | 男 | 90 | 90 | 95 | 80 | 75 | 80 | 优秀 |
| 4 | 5 | 张三 | 男 | 60 | 60 | 60 | 60 | 60 | 60 | 及格 |
# applymap对dataframe中所有的数据进行操作的一个函数,非常重要
def func(number):return number + 10
# 等价
func = lambda number : number + 10df.applymap(lambda x : str(x) + ' - ').head(2)
| 序号 | 姓名 | 性别 | 语文 | 数学 | 英语 | 物理 | 化学 | 生物 | 数学分类 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 - | 渠敬辉 - | 男 - | 80 - | 60 - | 30 - | 40 - | 30 - | 60 - | 及格 - |
| 1 | 2 - | 韩辉 - | 男 - | 90 - | 95 - | 75 - | 75 - | 80 - | 85 - | 优秀 - |
匿名函数
# 列表推导式
[i+100 for i in range(10)]
[100, 101, 102, 103, 104, 105, 106, 107, 108, 109]
def func(x):return x + 100
list(map(func,range(10)))
[100, 101, 102, 103, 104, 105, 106, 107, 108, 109]
# 匿名函数的使用条件:
# 1.函数就一行
# 2.函数不经常使用
# 3.函数没有必要取名字
list(map(lambda x : x+100,range(10)))
[100, 101, 102, 103, 104, 105, 106, 107, 108, 109]
# apply根据多列生成新的一个列的操作,用apply
df['new_score'] = df.apply(lambda x : x.数学 + x.语文, axis=1)
# 前几行
df.head(2)
# 最后几行
df.tail(2)
| 序号 | 姓名 | 性别 | 语文 | 数学 | 英语 | 物理 | 化学 | 生物 | 数学分类 | new_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 6 | 李四 | 女 | 80 | 80 | 80 | 80 | 80 | 80 | 优秀 | 160 |
| 6 | 7 | 王五 | 男 | 70 | 70 | 70 | 70 | 70 | 70 | 良 | 140 |
panda中的dataframe的操作,很大一部分跟numpy中的二位数组的操作是近似的
相关文章:
)
python数据处理(pandas)
# 新的数据格式,csv纯文本,使用某个字符集,比如都是ASCII、Unicode、EBCDIC或GB2312(简体中文环境)等;由记录组成(典型的是每行一条记录)每条记录被分隔符(英语ÿ…...

微信小程序开发秘籍:玩转麦克风录音与音频上传【代码示例】
微信小程序开发秘籍:玩转麦克风录音与音频上传【代码示例】 基本概念麦克风录音音频上传 实战演练1. 初始化录音功能2. 设计录音界面3. 实现音频上传安全性与性能优化 结语与讨论 在移动互联网时代,语音交互已成为提升用户体验的重要手段之一。微信小程序…...

spring的核心详解
Spring 核心详解 文章目录 Spring 核心详解前言什么是springspring的优点spring用到了哪些设计模式 什么是AOPAOP的实现方式静态代理动态代理 什么是IOCIOC的好处什么是依赖注入 前言 什么是spring Spring是一个开源的Java/Java EE全功能栈(full-stack)…...
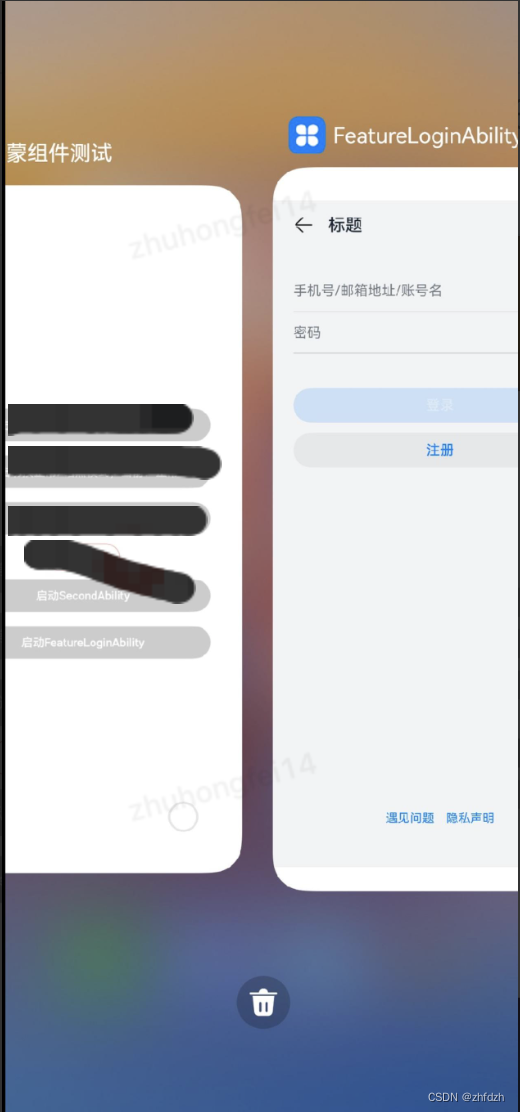
一、写给Android开发者之harmony入门
一、创建新项目 对比 android-studio:ability类似安卓activity ability分为两种类型(Stage模型) UIAbility和Extensionability(提供系统服务和后台任务) 启动模式 1、 singleton启动模式:单例 2、 multiton启动模式࿱…...
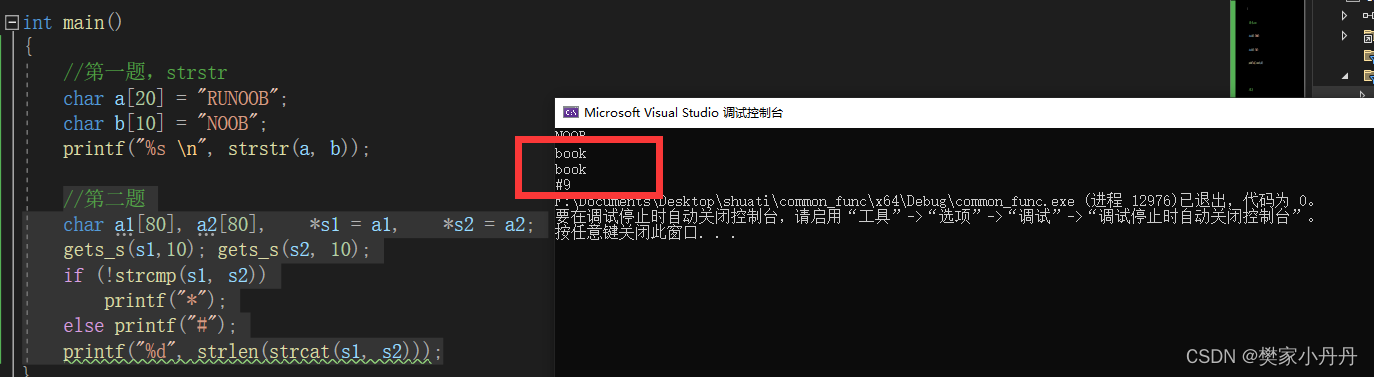
C++常用库函数——strstr、strcat
1、strstr:查找字符串子串函数,查找到的子串中第一个字符的地址,返回值是第一次出现子串字符串的位置。 例如: char a[20] "RUNOOB"; char b[10] "NOOB"; printf("%s", strstr(a, b)); 在这里…...

Kafak 消费异常:The coordinator is not available.
Kafak 消费异常:The coordinator is not available. 1. 问题描述2. 问题排查2.1 Topic 状态异常2.2 `__consumer_offsets` 简介1. 问题描述 在新环境部署 Kafak 时,发现可以正常产生消息,但是无法正常消费消息,消费消息的异常日志如下: 11:59:53.315 [main] DEBUG org.a…...

JavaScript中的对象
这里写目录标题 JavaScript中的对象属性 对象的使用属性和访问方法和调用遍历对象null 内置对象Math属性方法 JavaScript中的对象 对象(object)是JavaScript里的一种数据类型,可以理解为一种无序的数据集合(数组是有序的数据集合…...
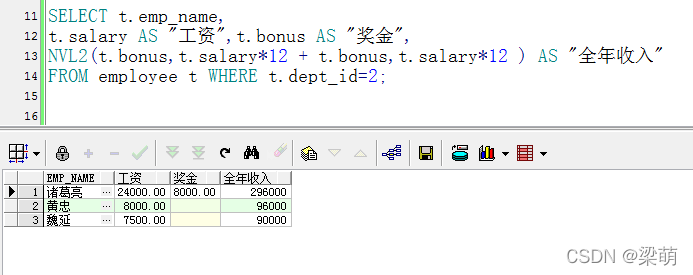
Oracle对空值(NULL)的 聚合函数 排序
除count之外sum、avg、max、min都为null,count为0 Null 不支持加减乘除,大小比较,相等比较,否则只能为空;只能用‘is [not] null’来进行判断; Max等聚合函数会自动“过滤null” null排序默认最大…...
我独自升级崛起下载教程 我独自升级崛起一键下载
动作RPG游戏基于广大喜爱的动画和在线漫画《我独自升级崛起》在5月8日,这款新的游戏首次在全球亮相,意在给那些对游戏情有独钟的玩家带来更加丰富和多种多样的游戏体验。这个网络武侠题材的游戏设计非常具有创意,其主要故事围绕着“独孤求败”…...

RS2057XH功能和参数介绍及规格书
RS2057XH 是一款由润石科技(Runic Semiconductor)生产的模拟开关芯片,其主要功能和参数如下: 产品特点: 低电压操作:支持低至1.8V的工作电压,适用于低功耗应用。 高带宽:具有300MHz的…...
ICML 2024有何亮点?9473篇论文投稿,突破历史记录
会议之眼 快讯 2024年5月1日,第42届国际机器学习大会ICML 2024放榜啦!录用率27.5%!ICML 2024的录用结果受到了广泛的关注,本届会议的投稿量达到了9473篇,创下了历史新高,比去年的6538篇增加了近3000篇&…...
U盘提示“被写保护”无法操作处理怎么办?
今天在使用U盘复制拷贝文件时,U盘出现“U盘被写保护”提示,导致U盘明明有空闲内存却无法复制的情况。这种情况很常见,很多人在插入U盘到电脑后,会出现"U盘被写保护"的提示,导致无法进行删除、保存、复制等操…...

算法训练营第二十天 | LeetCode 110平衡二叉树、LeetCode 257 二叉树的所有路径、LeetCode 404 左叶子之和
LeetCode 110 平衡二叉树 递归写法很简单,直接自底向上每个节点判断是否为空,为空说明该层高度为0。不为空用一个int型变量l记录左子树高度(递归调用该函数自身),一个int型变量r记录右子树高度(同样递归调…...

Docker:centos7安装docker
官网:https://www.docker.com/官网 文档地址 - 确认centos7及其以上的版本 查看当前系统版本 cat /etc/redhat-release- 卸载旧版本 依照官网执行 - yum安装gcc相关 yum -y install gccyum -y install gcc-c- 安装需要的软件包 yum install -y yum-utils- 设置s…...

EasyExcel导出工具类
目录 工具类 头部实体类(要和工具类在同一个module或项目下) 日期转换器 工具类 /*** 导出Excel工具类*/ public class EasyExcelUtil<T> {/*** 单sheet(Map写入)* param response 响应对象* param headList 头部集合* p…...

【Godot4.2】EasyTreeData通用解析
概述 之前在《【Godot4.2】Tree控件自定义树形数据ETD及其解析》一文中,实现了对带缩进的层级结构文本的解析,并将其用于Tree控件的列表项构造。 不过当时并没有实现专门的类,今天花了一点时间实现了一下。现在可以更方便的构造和解析ETD数…...
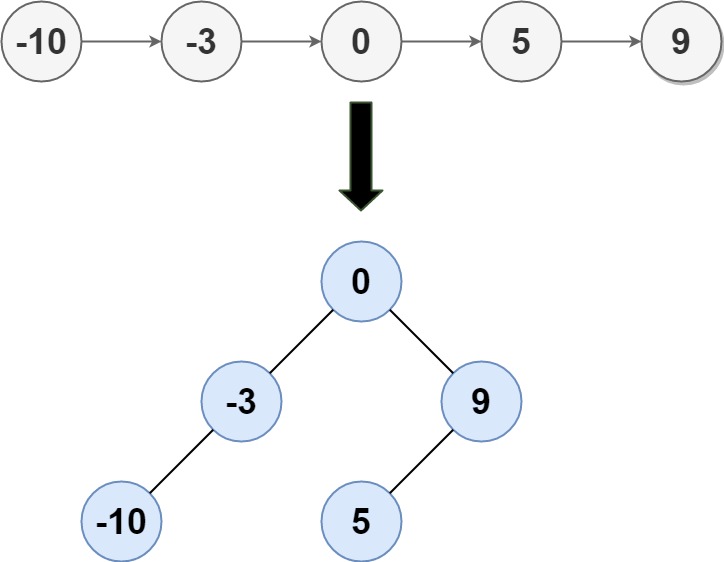
力扣每日一题109:有序链表转换二叉搜索树
题目 中等 给定一个单链表的头节点 head ,其中的元素 按升序排序 ,将其转换为 平衡 二叉搜索树。 示例 1: 输入: head [-10,-3,0,5,9] 输出: [0,-3,9,-10,null,5] 解释: 一个可能的答案是[0,-3,9,-10,null,5],它…...

企业计算机服务器中了locked勒索病毒怎么处理,locked勒索病毒解密建议
随着互联网技术在企业当中的应用,越来越多的企业利用网络开展各项工作业务,网络为企业提供了极大便利,也大大加快了企业发展步伐,提高了企业生产办公效率。但网络技术的发展也为企业的数据安全带来严重威胁。近期,云天…...
开源推荐榜【MalusAdmin基于 Vue3/TypeScript/NaiveUI 和 NET7 Sqlsugar 开发的后台管理框架】
简介 Malus是海棠的意思,顾名思义,海棠后台管理系统,读音与【马卢斯】相近,也可称作为马卢斯后台管理系统。 基于NET Core | NET7/8 & Sqlsugar | Vue3 | vite4 | TypeScript | NaiveUI 开发的前后端分离式权限管理系统,采用…...
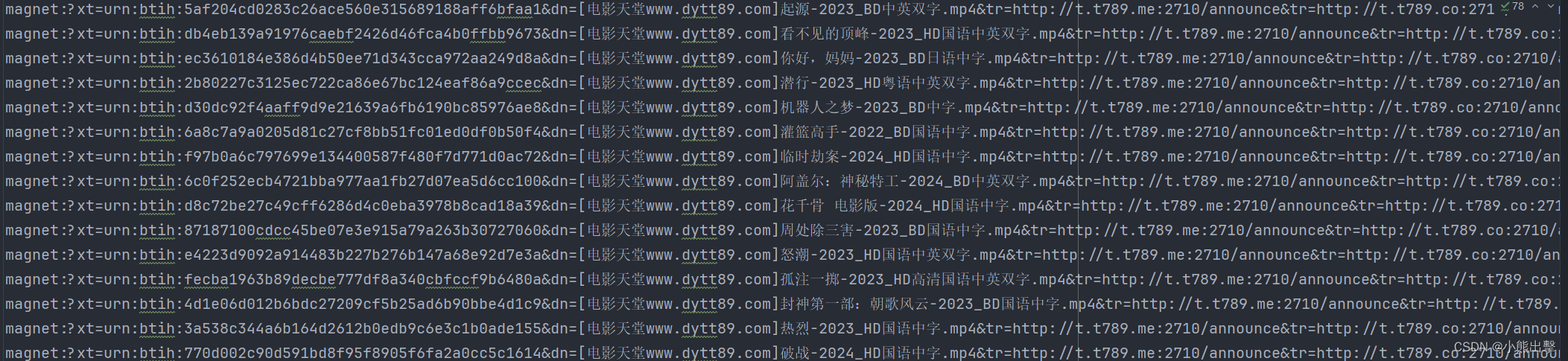
批量抓取某电影网站的下载链接
思路: 进入电影天堂首页,提取到主页面中的每一个电影的背后的那个urL地址 a. 拿到“2024必看热片”那一块的HTML代码 b. 从刚才拿到的HTML代码中提取到href的值访问子页面,提取到电影的名称以及下载地址 a. 拿到子页面的页面源代码 b. 数据提…...

Anything to RealCharacters 2.5D转真人引擎效果可视化:预处理前后对比与输出质量评估
Anything to RealCharacters 2.5D转真人引擎效果可视化:预处理前后对比与输出质量评估 你是否曾想过,将心爱的动漫角色、游戏立绘或者卡通头像,一键变成一张以假乱真的真人照片?这听起来像是魔法,但现在,借…...
)
不用Animator!用Playable+Timeline打造Unity自定义动画状态机(含项目代码片段)
突破Animator限制:Playable与Timeline构建Unity高阶动画系统 在Unity游戏开发中,动画系统一直是角色表现的核心。传统Animator虽然入门简单,但当项目复杂度上升时,状态机臃肿、过渡僵硬、调试困难等问题逐渐暴露。许多中高级开发…...

Z-Image-GGUF提示词工程实战:写出高质量描述生成惊艳图像
Z-Image-GGUF提示词工程实战:写出高质量描述生成惊艳图像 你是不是也遇到过这种情况:用同一个AI绘画模型,别人生成的图片美轮美奂,自己生成的却总差点意思?问题很可能出在“提示词”上。 提示词,就是你告…...

旧设备优化指南:iPhone 6s系统降级与性能提升全攻略
旧设备优化指南:iPhone 6s系统降级与性能提升全攻略 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to downgrade/restore, save SHSH blobs, and jailbreak legacy iOS devices 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit 当你的iP…...

AIGlasses OS Pro性能调优指南:跳帧、画面缩放设置,流畅运行低算力设备
AIGlasses OS Pro性能调优指南:跳帧、画面缩放设置,流畅运行低算力设备 智能眼镜作为穿戴设备,其计算资源往往有限。AIGlasses OS Pro作为一款本地运行的智能视觉系统,如何在有限的硬件资源下保持流畅运行,是许多开发…...

跨平台音频格式兼容性处理:让FRCRN支持更多音视频文件
跨平台音频格式兼容性处理:让FRCRN支持更多音视频文件 你有没有遇到过这种情况?精心搭建了一个基于FRCRN模型的音频降噪服务,信心满满地准备上线,结果用户一上传文件,服务就报错。有的用户传的是手机录的.m4a…...

Scarab:基于Avalonia的跨平台空洞骑士模组管理器架构解析
Scarab:基于Avalonia的跨平台空洞骑士模组管理器架构解析 【免费下载链接】Scarab An installer for Hollow Knight mods written in Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab Scarab是一款专为《空洞骑士》游戏设计的跨平台模组管理器…...

ChatGLM3-6B部署避坑指南:解决组件冲突,实现稳定运行
ChatGLM3-6B部署避坑指南:解决组件冲突,实现稳定运行 1. 项目概述与核心优势 ChatGLM3-6B-32k是智谱AI团队推出的新一代开源对话模型,基于本地化部署方案,特别针对组件冲突问题进行了深度优化。相比传统云端方案,本方…...

构建向量搜索医疗诊断系统:患者数据的相似性匹配终极指南
构建向量搜索医疗诊断系统:患者数据的相似性匹配终极指南 【免费下载链接】usearch Fastest Open-Source Search & Clustering engine for Vectors & 🔜 Strings in C, C, Python, JavaScript, Rust, Java, Objective-C, Swift, C#, GoLang, a…...

OpenClaw 网关重启指南:常用指令与故障修复
手把手教你一键部署OpenClaw,连接微信、QQ、飞书、钉钉等,1分钟全搞定! 一、几种快速重启的法子 看你当初是怎么部署的,挑下面最适合你的那条命令就行: 适用情况具体命令最省事的(系统托管模式ÿ…...