SparkSQL与Hive交互
SparkSQL与Hive交互
- 一、内嵌Hive应用
- 二、外部Hive应用
- 三、运行Spark SQL CLI
- 四、IDEA操作外部Hive
SparkSQL可以采用内嵌Hive,也可以采用外部Hive。企业开发中,通常采用外部Hive。
一、内嵌Hive应用
内嵌Hive,元数据存储在Derby数据库。
(1)如果使用Spark内嵌的Hive,则什么都不用做,直接使用即可。
[root@bigdata111 spark-local]$ bin/spark-shellscala> spark.sql("show tables").show
注意:执行完后,发现多了$SPARK_HOME/metastore_db和derby.log,用于存储元数据
(2)创建一个表
scala> spark.sql("create table user(id int, name string)")
注意:执行完后,发现多了$SPARK_HOME/spark-warehouse/user,用于存储数据库数据
(3)查看数据库
scala> spark.sql("show tables").show
(4)向表中插入数据
scala> spark.sql("insert into user values(1,'wgh')")
(5)查询数据
scala> spark.sql("select * from user").show
注意:然而在实际使用中,几乎没有任何人会使用内置的Hive,因为元数据存储在derby数据库,不支持多客户端访问。
二、外部Hive应用
如果Spark要接管Hive外部已经部署好的Hive,需要通过以下几个步骤:
(0)为了说明内嵌Hive和外部Hive区别:删除内嵌Hive的metastore_db和spark-warehouse
[root@bigdata111 spark-local]$ rm -rf metastore_db/ spark-warehouse/
(1)确定原有Hive是正常工作的
[root@bigdata111 hadoop-3.1.3]$ sbin/start-dfs.sh
[root@bigdata111 hadoop-3.1.3]$ sbin/start-yarn.sh[root@bigdata111 hive]$ bin/hive
(2)需要把hive-site.xml拷贝到spark的conf/目录下
[root@bigdata111 conf]$ cp hive-site.xml /opt/module/spark-local/conf/
(3)如果以前hive-site.xml文件中,配置过Tez相关信息,注释掉(不是必须)
(4)把MySQL的驱动copy到Spark的jars/目录下
[root@bigdata111 software]$ cp mysql-connector-java-5.1.48.jar /opt/module/spark-local/jars/
(5)需要提前启动hive服务,/opt/module/hive/bin/hiveservices.sh start(不是必须)
(6)如果访问不到HDFS,则需把core-site.xml和hdfs-site.xml拷贝到conf/目录(不是必须)
(7)启动 spark-shell
[root@bigdata111 spark-local]$ bin/spark-shell
(8)查询表
scala> spark.sql("show tables").show
(9)创建一个表
scala> spark.sql("create table student(id int, name string)")
(10)向表中插入数据
scala> spark.sql("insert into student values(1,'wgh')")
(11)查询数据
scala> spark.sql("select * from student").show
三、运行Spark SQL CLI
Spark SQL CLI可以很方便的在本地运行Hive元数据服务以及从命令行执行查询任务。在Spark目录下执行如下命令启动Spark SQL CLI,直接执行SQL语句,类似Hive窗口。
[root@bigdata111 spark-local]$ bin/spark-sqlspark-sql (default)> show tables;
四、IDEA操作外部Hive
(1)在pom中添加依赖
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.0.0</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.27</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>3.0.0</version></dependency>
</dependencies>
(2)拷贝hive-site.xml到resources目录(如果需要操作Hadoop,需要拷贝hdfs-site.xml、core-site.xml、yarn-site.xml)
(3)代码实现
package com.wghu.sparksqlimport org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession/*** User: WGH* Date:2023-03-08** idea写代码连接外部hive* 1.导入pom依赖,spark-sql mysql连接驱动,spark-hive* 2.将hive-site.xml放入到项目的类路径下* 3.代码里面获取外部hive的支持,在创建sparkSession对象是加入.enableHiveSupport()*/object SparkSQL12_Hive {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME","root")//1.创建配置对象val conf : SparkConf = new SparkConf().setAppName("SparkSQLTest").setMaster("local[*]")//2.创建sparkSession对象val spark: SparkSession = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate()//3.编写代码//连接hivespark.sql("show tables").show()spark.sql("create table bbb(id int,name string)").show()spark.sql("insert into bbb values(1,'wgh')").show()spark.sql("select * from bbb").show()//4.关闭scspark.stop()}}相关文章:

SparkSQL与Hive交互
SparkSQL与Hive交互一、内嵌Hive应用二、外部Hive应用三、运行Spark SQL CLI四、IDEA操作外部HiveSparkSQL可以采用内嵌Hive,也可以采用外部Hive。企业开发中,通常采用外部Hive。 一、内嵌Hive应用 内嵌Hive,元数据存储在Derby数据库。 &am…...

「题解」日常遇到指针面试题
🐶博主主页:ᰔᩚ. 一怀明月ꦿ ❤️🔥专栏系列:线性代数,C初学者入门训练,题解C,C的使用文章 🔥座右铭:“不要等到什么都没有了,才下定决心去做” …...

实习生JAVA知识总结目录
一.JAVA基础学习 JAVA知识点全面总结1:零散知识 JAVA知识点全面总结2:面向对象 JAVA知识点全面总结3:String类的学习 JAVA知识点全面总结4:异常类学习 JAVA知识点全面总结5:IO流的学习 JAVA知识点全面总结6&…...

GMPC认证有哪些内容?
【GMPC认证有哪些内容?】GMP(GMP Good Manufacturing Practice)即良好生产规范,最早是美国国会为了规范药品生产而于1963年颁布的。这也是世界上第一部GMP。由于GMP在规范药品的生产,提高药品的质量,保证药品的安全方面效果非常明显…...

D2-Net: A Trainable CNN for Joint Description and Detection of Local Features精读
开源代码:D2-Net 1 摘要 在这项工作中,我们解决了在困难的成像条件下寻找可靠的像素级对应的问题。我们提出了一种由单一卷积神经网络发挥双重作用的方法:它同时是一个密集的特征描述符和一个特征检测器。通过将检测推迟到后期阶段…...

Java基础面试题
目录 一,Java基础 1.1.JDK和JRE有什么区别? 1.2.JAVA中的几种基本类型,各占用多少字节? 1.3.和equals的区别是什么? 1.4.final,finally,finalied有什么区别? 1.15.Java 中操作字符串都有哪些类?它们…...

SQL和MongoDB对比
关系型数据库如MySQL和非关系型数据库MongoDB的对应关系:SQLMongoDBdatabasedatabasetablecollectionrowdocument or Bson documentcolumnfieldindexindextable joins$lookupprimary keyprimary key指定任何唯一的列或列组合作为主键主键会自动设置为_id字段aggrega…...
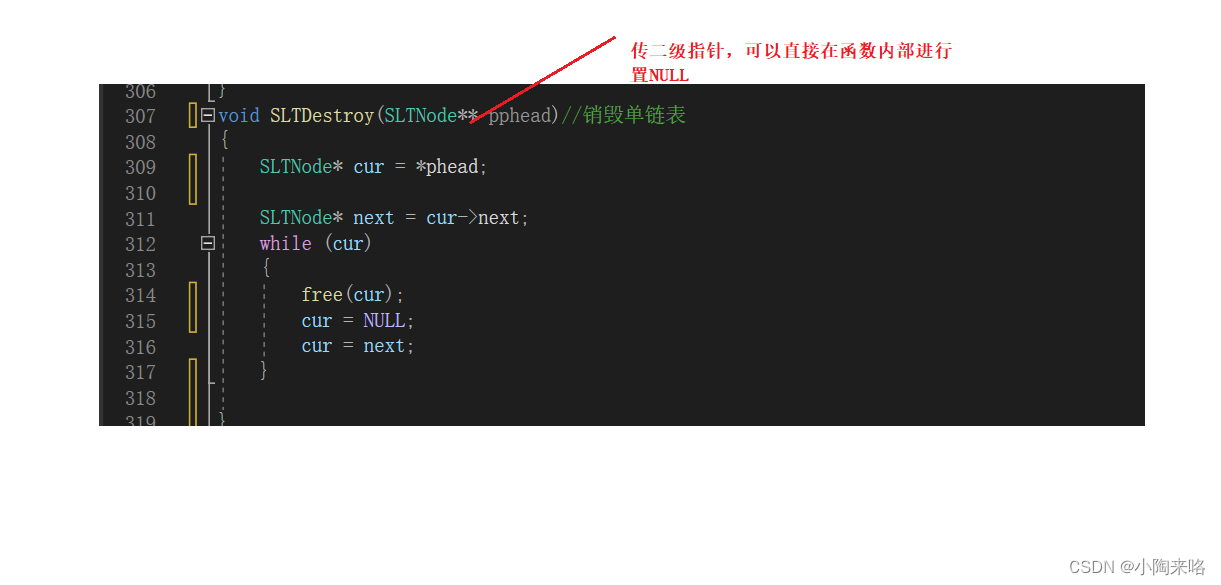
研究链表空间销毁问题
💯💯💯 1.研究链表空间销毁问题 当链表使用完后,需要将链表销毁,那么该如何销毁呢? void SLTDestroy(SLTNode* phead)//销毁单链表 {SLTNode* cur phead;while(cur){free(cur);cur cur->next;} }你…...
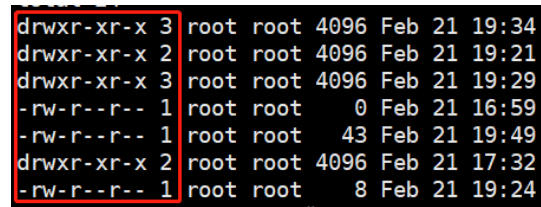
Linux面试总结
一.常用命令1.目录切换cd / 切换到根目录cd ../ 切换到上级目录cd ~ 切换到home目录2.查看目录ls 列出当前目录下所有的文件ls [路径]ls / 查看根目录 ls -l 相当于 ll 最常用的命令,用了表的方式列出当前目录的内容3.查看当前目录pwd-4.创建一组空文件touch5.显示文件内容cat6…...

anaconda的linux版本以及jupyter的安装和DataSpell连接linux的jupyter服务器
anaconda安装:官网:https://www.anaconda.com/拷贝下载网址后,在Linux里进行下载:wget https://repo.anaconda.com/archive/Anaconda3-2022.10-Linux-x86_64.sh执行sh:./Anaconda3-2022.10-Linux-x86_64.sh 安装完后&a…...

Zookeeper集群和Hadoop集群安装(保姆级教程)
1. HA HA(Heigh Available)高可用 解决单点故障,保证企业服务 7*24 小时不宕机单点故障:某个节点宕机导致整个集群的宕机 Hadoop 的 HA NameNode 存在单点故障的可能,需要配置 HA 解决引入第二个 NameNode 作为备份同…...

利用matlab的newff构建BP神经网络来实现数据的逼近和拟合
假设P是原始数据向量; T是对应的目标向量; 现在需要通过神经网络来实现P->T的非线性映射。 net newff(minmax(P),[16,1],{tansig,purelin},trainlm); net.trainParam.epochs 2000; net.trainParam.goal 1e-5; net init(net); net train(n…...
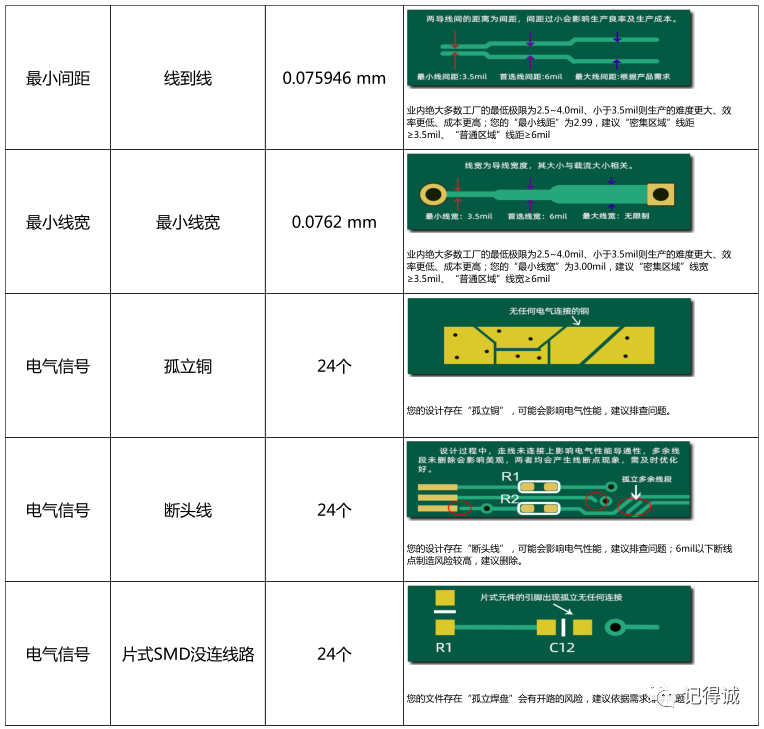
【经验分享】电路板上电就挂?新手工程师该怎么检查PCB?
小伙伴们有没有经历过辛辛苦苦,加班加点设计的PCB,终于搞定下单制板。接下来焦急并且忐忑地等待PCB板到货,焊接,验证,一上电,结果直接挂了... 连忙赶紧排查,找问题。最终发现,是打过…...
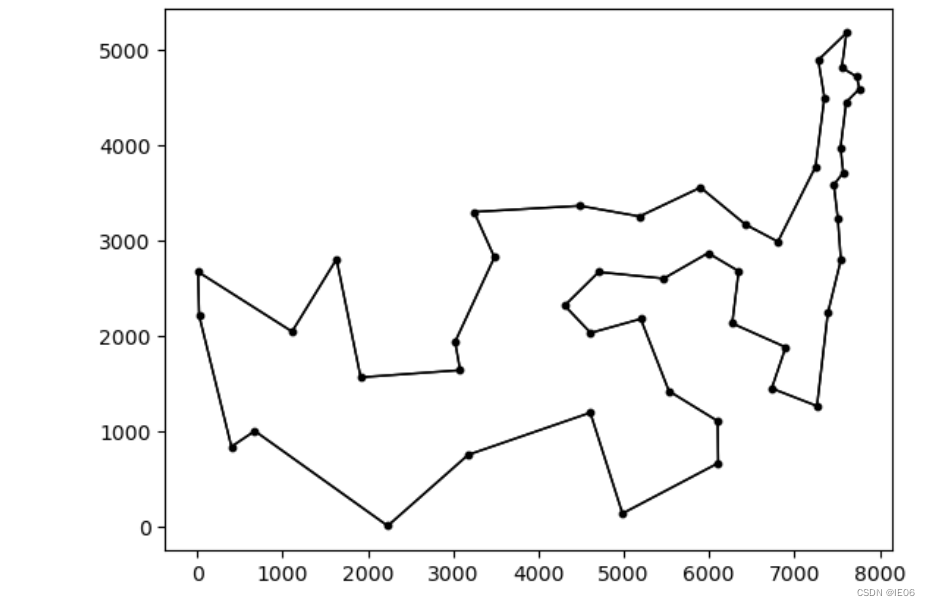
运筹系列68:TSP问题Held-Karp下界的julia实现
1. 介绍 Held-Karp下界基于1tree下界,但是增加了点权重,如下图 通过梯度下降的方法找到最优的π\piπ。 这里用到的1tree有下面几种: 全部点用来生成最小生成树,再加上所有叶子结点第二短的边中数值最大的那个任意选一个点&…...
)
神经影像信号处理总成(EEG、SEEG、MRI、CT)
目录一. EEG(脑电图)1.1 脑波1.2 伪迹1.2.1 眼动伪迹1.2.2 肌电伪迹1.2.3 运动伪迹1.2.4 心电伪迹1.2.5 血管波伪迹1.2.6 50Hz和静电干扰1.3 伪迹去除方法1.3.1 避免伪迹产生法1.3.2 直接移除法1.3.3 伪迹消除法二. SEEG(立体脑电图)三. CT(计算机断层扫描ÿ…...

ZooKeeper 进阶:基本介绍
zppkeeper是什么 zookeeper是一个高性能、开源的分布式应用协调服务,它提供了简单原始的功能,分布式应用可以基于它实现更高级的服务,比如实现同步(分布式锁)、配置管理、集群管理。它被设计为易于编程,使用文件系统目录树作为数…...

CSS的常用元素属性,显示模式,盒模型,弹性布局
目录 1.常用元素属性 1.1字体属性 设置字体 设置大小 字体粗细 文字样式 1.2文本属性 文字颜色 文字对齐 编辑文本装饰 文本缩进 编辑行高 编辑1.3背景属性 背景颜色 背景位置 背景尺寸 1.4圆角矩形 2.元素的显示模式 2.1块级元素(display:block) 2.…...
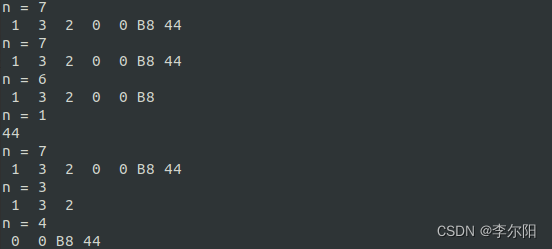
【20230308】串口接收数据分包问题处理(Linux)
1 问题背景 一包数据可能由于某些传输原因,经常出现一包数据分成几包的情况。 2 解决方法 2.1 通过设定最小读取字符和读取超时时间 可以使用termios结构体来控制终端设备的输入输出。可以通过VTIME和VMIN的值结合起来共同控制对输入的读取。此外,两…...

数据库复试问题总结
数据库复试问题 由《数据库系统概论(第5版)》总结而来,用于本人研究生复试准备。也欢迎各位准研究生们学习使用。 文章目录数据库复试问题1、三级模式结构及二级映射有什么优点?2、关系模型中的完整性约束是哪几类?3、SQL的特点?…...

Linux操作系统安装——服务控制
个人简介:云计算网络运维专业人员,了解运维知识,掌握TCP/IP协议,每天分享网络运维知识与技能。座右铭:海不辞水,故能成其大;山不辞石,故能成其高。个人主页:小李会科技的…...

艾尔登法环存档救星:5分钟学会角色迁移,告别数百小时进度丢失
艾尔登法环存档救星:5分钟学会角色迁移,告别数百小时进度丢失 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 艾尔登法环存档管理器是你守护游戏进度的终极解决方案。想象一下…...

多重插补与MICE:量化ESG评分不确定性的工程实践
1. 项目概述:当ESG评分遇上数据“黑洞”,我们如何量化不确定性?在金融和可持续投资领域,ESG评分正成为评估公司长期价值与风险的关键标尺。然而,从业者们都心知肚明一个公开的秘密:支撑这些评分的底层数据&…...

【前端国际化】i18next实战:打造多语言支持的前端应用
【前端国际化】i18next实战:打造多语言支持的前端应用 前言 大家好,我是cannonmonster01!今天咱们来聊聊前端国际化这个话题。随着互联网的全球化发展,支持多语言已经成为现代Web应用的标配。想象一下,你的应用能让来…...

终极免费方案:如何5分钟搞定Axure RP全界面中文汉化
终极免费方案:如何5分钟搞定Axure RP全界面中文汉化 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 还在为Axure RP的…...
)
ChatGPT可视化输出总失真?深度解析其底层渲染引擎限制(基于OpenAI v4.12.3源码逆向分析)
更多请点击: https://kaifayun.com 第一章:ChatGPT可视化输出失真现象的实证观察 在实际工程调试与教学演示中,开发者频繁反馈 ChatGPT(尤其是通过 API 或网页界面返回 Markdown 渲染结果)对代码块、数学公式、表格及…...

CFD湍流模型不确定性量化:特征空间扰动框架原理与应用
1. 项目概述与核心挑战在计算流体力学(CFD)的工程实践中,我们常常面临一个核心困境:如何高效且可靠地预测复杂湍流?雷诺平均纳维-斯托克斯(RANS)模型因其在计算成本和工程实用性之间的绝佳平衡&…...

ChatGPT账号被封怎么办?20年合规架构师给出终极答案:1套可审计的账号生命周期管理SOP
更多请点击: https://codechina.net 第一章:ChatGPT账号被封怎么办 当您的ChatGPT账号突然无法登录、提示“Account suspended”或跳转至封禁通知页时,需冷静判断原因并采取合规应对措施。OpenAI官方明确指出,封禁通常源于违反《…...

Thorium浏览器深度解析:如何通过编译优化实现300%性能提升的技术革命
Thorium浏览器深度解析:如何通过编译优化实现300%性能提升的技术革命 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Source code and Linux releases. Windows/MacOS/ARM builds served in different repos, links are towards …...

从API调用日志看Taotoken在访问控制与审计上的价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API调用日志看Taotoken在访问控制与审计上的价值 对于将大模型能力集成到业务流程中的团队而言,API调用不仅是功能实…...

医疗AI数据陷阱:ICD编码与金标准诊断的鸿沟及应对策略
1. 项目概述:当医疗AI遇上“计费标签”的陷阱在医疗人工智能领域,我们常常听到一个令人振奋的故事:利用海量的电子健康记录(EHR)数据,训练出能够预测疾病、辅助诊断的机器学习模型。这听起来像是未来医疗的…...