Zookeeper集群和Hadoop集群安装(保姆级教程)
1. HA
-
HA(Heigh Available)高可用
- 解决单点故障,保证企业服务 7*24 小时不宕机
- 单点故障:某个节点宕机导致整个集群的宕机
-
Hadoop 的 HA
- NameNode 存在单点故障的可能,需要配置 HA 解决
- 引入第二个 NameNode 作为备份
- 同步两个 NameNode 的数据
- 在第一个 NameNode 宕机后启用第二个 NameNode
-
HA架构

2. Zookeeper
-
Zookeeper 是一个分布式服务器框架
- 提供了分布式程序通用的功能
- 统一命名服务
- 状态同步服务
- 集群管理
- 分布式应用配置项
-
Zookeeper 集群
- 为了防止 Zookeeper 出现单点故障问题,
- Zookeeper 通常以集群的方式使用
- 一般为 3 或 5 个节点
-
Zookeeper 集群角色
- Leader:被选举出的,与客户端交互
- Follower:Leader 的备份,参与选举操作
-
Zookeeper 集群选举机制
- 少数服从多少
- 编号大的优先
2.1 Zookeeper 的安装
#1、上传 Zookeeper 到 /home/hadoop 目录#2、解压 Zookeeper 到 /usr/local 目录中
sudo tar -xvf apache-zookeeper-3.6.1-bin.tar.gz -C /usr/local#3、进入 /usr/local 目录
cd /usr/local#4、将解压的目录重命名为 zookeeper
sudo mv apache-zookeeper-3.6.1-bin/ zookeeper#5、修改 zookeeper 目录的拥有者为 Hadoop
sudo chown -R hadoop zookeeper#6、进入 Zookeeper 安装目录下的 conf 目录
cd /usr/local/zookeeper/conf#7、重命名 zoo_sample.cfg 文件为 zoo.cfg
mv zoo_sample.cfg zoo.cfg#8、编辑环境变量
vim /home/hadoop/.bashrc#9、在环境变量增加以下内容
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin#10、刷新环境变量
source /home/hadoop/.bashrc
2.2 Zookeeper 的使用
#启动 Zookeeper
zkServer.sh start#查看 Zookeeper 的状态
zkServer.sh status#关闭 Zookeeper
zkServer.sh stop

3. Zookeeper 的集群规划
| 节点主机名 | ip |
|---|---|
| master | 192.168.114.133 (自己的电脑IP,后面顺延就行) |
| slave1 | 192.168.114.134 |
| slave2 | 192.168.114.135 |
-
搭建 3 节点的 Zookeeper 集群
- 规划 主机名 和 IP
-
修改节点的主机名
-
#修改 sudo hostnamectl set-hostname master #查看 hostname
-
3.1 克隆虚拟机
1、关闭虚拟机中的所有软件并关闭虚拟机
2、在已有的虚拟机下右键点击“管理”->“克隆”
3、选择完整克隆
4、点击下一步直到去修改虚拟机信息
5、等待克隆完成后关闭操作窗口
6、重置虚拟机网卡7、使用 root 用户登录,密码为 123456
8、配置 IP 地址
#1、 编辑 IP 配置文件 vim /etc/netplan/50-cloud-init.ymal#2、修改 IP 地址为 192.168.114.134#3、重启网络 netplan apply#9、修改主机名 hostnamectl set-hostname slave1 hostname10、照上操作再克隆出一个虚拟机
设置 IP 为 原克隆节点顺延后的ip
设置主机名为 slave2
3.2 搭建 Zookeeper 集群
#1、启动三台虚拟机,使用 Hadoop 用户登录
#2、编辑三台虚拟机的 hosts 文件
sudo vim /etc/hosts#3、在文件最后添加以下内容(ip是自己电脑上的ip)
192.168.114.133master
192.168.114.134slave1
192.168.114.135slave2#4、互相之间使用 ping 命令,验证是否配置成功
ping master、ping slave1、ping slave2#5、配置三个节点之间的免密登录
#1、删除 3 个节点上的 ssh 配置文件(3 个节点都执行)rm -rf /home/hadoop/.ssh#2、在 3 个节点上生成公钥(3 个节点都执行)
ssh-keygen#3、发送各个节点的公钥给 master(3 个节点都执行)
ssh-copy-id master#4、master 发送 authorized_keys 给 slave1 和 slave2
#仅在 master 执行scp /home/hadoop/.ssh/authorized_keys hadoop@slave1:/home/hadoop/.ssh/ scp /home/hadoop/.ssh/authorized_keys hadoop@slave2:/home/hadoop/.ssh/#6、配置 Zookeeper 的配置文件----------------------
#1、编辑 3 个节点上的 zoo.cfg 文件(3 个节点都执行) vim /usr/local/zookeeper/conf/zoo.cfg#2、修改第 12 行的 dataDir 值(3 个节点都执行) dataDir=/usr/local/zookeeper/data#3、在文件最后追加以下内容(3 个节点都执行) server.1=master:2888:3888 server.2=slave1:2888:3888 server.3=slave2:2888:3888#7、配置 Zookeeper 的节点编号-----------------------
#1、在 3 个节点上创建 data 目录(3 个节点都执行) mkdir /usr/local/zookeeper/data#2、在 data 目录下创建 myid 文件(3 个节点都执行) vim /usr/local/zookeeper/data/myid#3、在 myid 文件填入每个节点的编号(3 个节点都执行) master 节点填入 1 slave1 节点填入 2 slave2 节点填入 3
3.3 使用 Zookeeper 集群
#启动 Zookeeper 集群(3 个节点都执行)
zkServer.sh start#查看 Zookeeper 集群的状态(3 个节点都执行)
zkServer.sh status#关闭 Zookeeper 集群(3 个节点都执行)
zkServer.sh stop
验证状态:

4. Hadoop的HA配置
4.1 搭建Hadoop的分布式集群
-
把slave1和slave2两个节点作为DataNode和NodeManager加入Hadoop集群
-
在masterj节点编辑slaves文件,设置Hadoop中的DataNode和NodeManager节点
-
vim /usr/local/hadoop/etc/hadoop/slaves -
替换localhost为以下内容:
-
master
slave1
slave2
验证状态:

- master把修改后的slaves文件发送给slave1和slave2节点
scp /usr/local/hadoop/etc/hadoop/slaves hadoop@slave1:/usr/local/hadoop/etc/hadoop/scp /usr/local/hadoop/etc/hadoop/slaves hadoop@slave2:/usr/local/hadoop/etc/hadoop/
- 在master修改core-site.xml文件,使用master(master:9000)替换ip地址做为Hadoop的访问地址
sudo vim /usr/local/hadoop/etc/hadoop/core-site.xml
core-site.xml
<configuration><!--hdfs的数据存储位置--><property><name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value></property><property><name>fs.defaultFS</name><value>hdfs://master:9000</value><!--这里修改--></property><property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property><property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property>
</configuration>
示例图片:

- 将修改好的core-site.xml文件发送给slave1和slave2文件
#发送给slave1
scp /usr/local/hadoop/etc/hadoop/core-site.xml hadoop@slave1:/usr/local/hadoop/etc/hadoop/
#发送给slave2
scp /usr/local/hadoop/etc/hadoop/core-site.xml hadoop@slave2:/usr/local/hadoop/etc/hadoop/
- 因为我们的slave1和slave2是从master克隆出来的,带有一些HDFS存储在master上的数据,我们需要删除。
保险起见,在三个节点执行删除操作
rm -rf /usr/local/hadoop/tmp/dfs/
- 修改完配置文件后,注意在master节点初始化namenode节点
hdfs namenode -format

- 在master节点分别使用start-dfs.sh和start-yarn.sh命令启动HDFS和Yarn。

4.2 配置Hadoop的HA
背景:
Hadoop集群已经是一个包含了3个节点的分布式集群了。其中NameNode和ResourceManager都是运行在master节点上,一旦master节点宕机,整个Hadoop集群就无法对外提供服务。为了防止出现这种情况,我们可以在slave1上再准备一份备用的NameNode和ResourceManager。由Zookeeper监控master上NameNode和ResourceManager的状态,一旦不可以立即切换slave1的NameNode和ResourceManager进行工作。
- 修改master节点的core-site.xml
#1 在master修改core-site.xml文件,使用ns(集群名字)替换master做为Hadoop的访问地址
sudo vim /usr/local/hadoop/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!--hdfs的数据存储位置--><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value></property><!--hdfs的访问地址,ns是NameNode集群名字,在hdfs-site.xml文件里面配置--><property><name>fs.defaultFS</name><value>hdfs://ns</value><!--改这里的名字--></property><!--允许Hive中的用户操作hdfs--><property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property><property><name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value></property><!--配置Zookeeper地址,JournalNode通过Zookeeper实现功能--><property><name>ha.zookeeper.quorum</name><value>master:2181,slave1:2181,slave2:2181</value></property>
</configuration>
- 将修改好的core-site.xml文件发送给slave1和slave2文件
#发送给slave1
scp /usr/local/hadoop/etc/hadoop/core-site.xml hadoop@slave1:/usr/local/hadoop/etc/hadoop/
#发送给slave1
scp /usr/local/hadoop/etc/hadoop/core-site.xml hadoop@slave2:/usr/local/hadoop/etc/hadoop/
- 在master修改hdfs-site.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!--设置NameNode集群的名字为ns--><property><name>dfs.nameservices</name><value>ns</value></property><!--为ns集群中的NameNode起一个名字--><property><name>dfs.ha.namenodes.ns</name><value>nn1,nn2</value></property><!--分别配置每个NameNode的请求端口和监控页面端口--><property><name>dfs.namenode.rpc-address.ns.nn1</name><value>master:9000</value></property><property><name>dfs.namenode.http-address.ns.nn1</name><value>master:50070</value></property><property><name>dfs.namenode.rpc-address.ns.nn2</name><value>slave1:9000</value></property><property><name>dfs.namenode.http-address.ns.nn2</name><value>slave1:50070</value></property><!--在哪些节点启动JournalNode进程,用于在两个NameNode之间同步fsimage和edits,通常是单数个--><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://master:8485;slave1:8485;slave2:8485/ns</value></property><!--journalnode数据存放位置--><property><name>dfs.journalnode.edits.dir</name><value>/usr/local/hadoop/tmp/journal</value></property><!--NameNode数据存放位置--><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><!--DataNode数据存放位置--><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property><!--启动自动切换--><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!--Avtive,StandBy状态的类--><property><name>dfs.client.failover.proxy.provider.ns</name><!--provider不要写错--><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!--启动fence软件切换--><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><!--指定fencex需要的私钥位置--><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hadoop/.ssh/id_rsa</value></property><!--NameNode等待JournalNode启动的超时时间 --><property><name>dfs.qjournal.write-txns.timeout.ms</name><value>60000</value></property></configuration>注意理解下面每个步骤的作用
#(4) 将修改好的hdfs-site.xml文件发送给slave1和slave2文件
scp /usr/local/hadoop/etc/hadoop/hdfs-site.xml hadoop@slave1:/usr/local/hadoop/etc/hadoop/
scp /usr/local/hadoop/etc/hadoop/hdfs-site.xml hadoop@slave2:/usr/local/hadoop/etc/hadoop/#(5) 3个节点都执行以下命令清除HDFS上存储的数据
rm -rf /usr/local/hadoop/tmp/dfs/#(6) 3个节点都使用以下命令启动Zookeeper
#启动Zookeeper:
zkServer.sh start
#查看Zookeeper状态:
zkServer.sh status#(7) 3个节点都使用以下命令启动JournalNode
hadoop-daemon.sh start journalnode#(8)在master上格式化NameNode,在master使用以下命令:
#注意仅仅是master节点!!!!
hdfs namenode -format
#看到格式化成功的标志再进行后面操作!!!
#看到格式化成功的标志再进行后面操作!!!
#看到格式化成功的标志再进行后面操作!!!

#(9)启动master上的NameNode,在master使用以下命令:
#注意仅仅是master节点!!!!
hadoop-daemon.sh start namenode#(10) 同步master上NameNode的数据到slave1,在slave1使用以下命令:
#换节点了,注意是slave1节点!!!!
#执行完毕后同样有和上面类似的格式化成功的信息,检查
hdfs namenode -bootstrapStandby#(11) 关闭master上的NameNode,在master使用以下命令:
#回到master节点了!!!!
hadoop-daemon.sh stop namenode#(12) 在master初始化Zookeeper监控工具,在master使用以下命令:
hdfs zkfc -formatZK#(13) 安装切换NameNode状态的psmisc软件,在master和slave1使用以下命令:
sudo apt-get install psmisc#(14) 启动hdfs验证NameNode的HA,在master使用以下命令:
start-dfs.sh4.3 验证Hadoop的HA
#(1) 启动Zookeeper集群,在3个节点都执行以下命令:
zkServer.sh start
#(2) 启动Hadoop集群,在master节点执行以下命令:
start-dfs.sh
#(3) 查看各个节点的进程,在3个节点都执行以下命令:
jps
验证状态:
此时的状态是启动了,hdfs,Zookeeper

(4) 在浏览器访问HDFS的监控页面,分别输入以下地址:
http://(master的ip):50070
http://(slave1的ip):50070
我们可以看到现在master上的NameNode处于active状态,slave1上的NameNode处于standby状态,

- 现在我们模拟master的NameNode宕机,验证是否可以切换slave1的NameNode为active状态。
- 通过使用jps命令查询出NameNode对应的进程ID是8604,使用kill -9 8604命令杀死NameNode进程,模拟master宕机。

- 等待几秒钟,然后再次访问slave1的监控页面,可以发现slave1的NameNode已经切换为active状态,接替master的NameNode为集群提供服务。

相关文章:
Zookeeper集群和Hadoop集群安装(保姆级教程)
1. HA HA(Heigh Available)高可用 解决单点故障,保证企业服务 7*24 小时不宕机单点故障:某个节点宕机导致整个集群的宕机 Hadoop 的 HA NameNode 存在单点故障的可能,需要配置 HA 解决引入第二个 NameNode 作为备份同…...

利用matlab的newff构建BP神经网络来实现数据的逼近和拟合
假设P是原始数据向量; T是对应的目标向量; 现在需要通过神经网络来实现P->T的非线性映射。 net newff(minmax(P),[16,1],{tansig,purelin},trainlm); net.trainParam.epochs 2000; net.trainParam.goal 1e-5; net init(net); net train(n…...
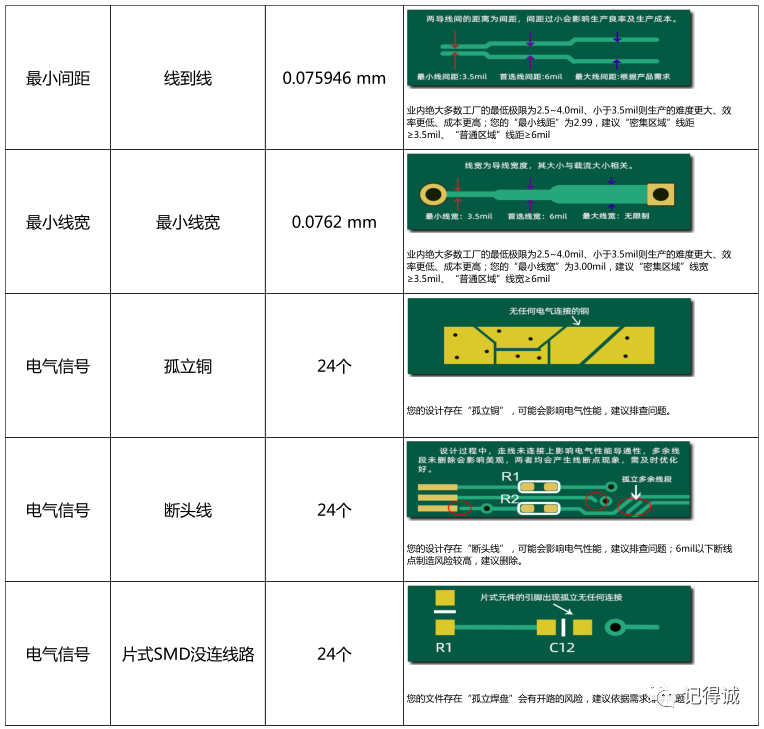
【经验分享】电路板上电就挂?新手工程师该怎么检查PCB?
小伙伴们有没有经历过辛辛苦苦,加班加点设计的PCB,终于搞定下单制板。接下来焦急并且忐忑地等待PCB板到货,焊接,验证,一上电,结果直接挂了... 连忙赶紧排查,找问题。最终发现,是打过…...
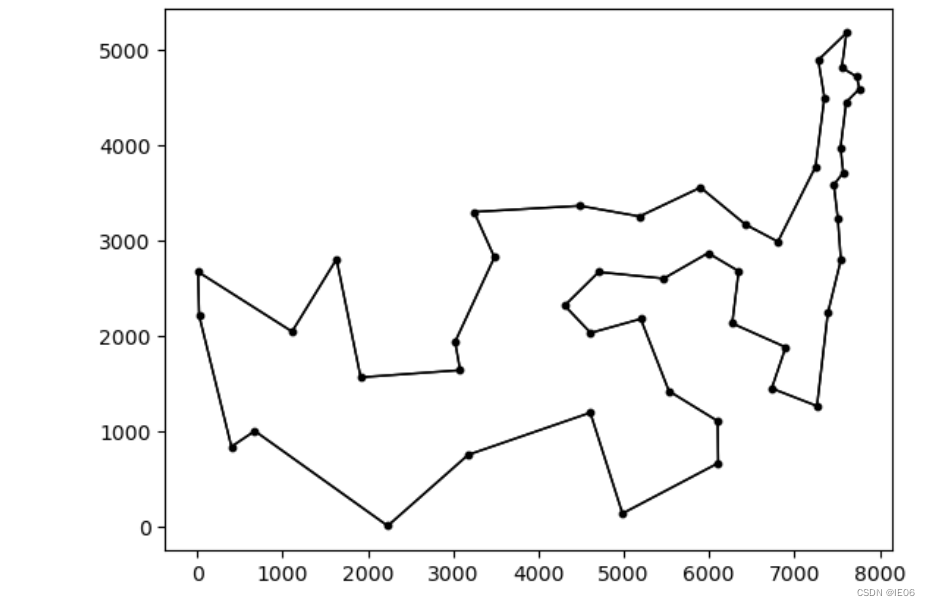
运筹系列68:TSP问题Held-Karp下界的julia实现
1. 介绍 Held-Karp下界基于1tree下界,但是增加了点权重,如下图 通过梯度下降的方法找到最优的π\piπ。 这里用到的1tree有下面几种: 全部点用来生成最小生成树,再加上所有叶子结点第二短的边中数值最大的那个任意选一个点&…...
)
神经影像信号处理总成(EEG、SEEG、MRI、CT)
目录一. EEG(脑电图)1.1 脑波1.2 伪迹1.2.1 眼动伪迹1.2.2 肌电伪迹1.2.3 运动伪迹1.2.4 心电伪迹1.2.5 血管波伪迹1.2.6 50Hz和静电干扰1.3 伪迹去除方法1.3.1 避免伪迹产生法1.3.2 直接移除法1.3.3 伪迹消除法二. SEEG(立体脑电图)三. CT(计算机断层扫描ÿ…...

ZooKeeper 进阶:基本介绍
zppkeeper是什么 zookeeper是一个高性能、开源的分布式应用协调服务,它提供了简单原始的功能,分布式应用可以基于它实现更高级的服务,比如实现同步(分布式锁)、配置管理、集群管理。它被设计为易于编程,使用文件系统目录树作为数…...

CSS的常用元素属性,显示模式,盒模型,弹性布局
目录 1.常用元素属性 1.1字体属性 设置字体 设置大小 字体粗细 文字样式 1.2文本属性 文字颜色 文字对齐 编辑文本装饰 文本缩进 编辑行高 编辑1.3背景属性 背景颜色 背景位置 背景尺寸 1.4圆角矩形 2.元素的显示模式 2.1块级元素(display:block) 2.…...
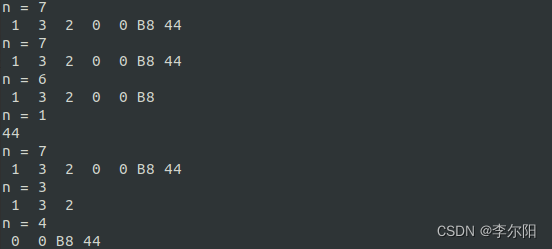
【20230308】串口接收数据分包问题处理(Linux)
1 问题背景 一包数据可能由于某些传输原因,经常出现一包数据分成几包的情况。 2 解决方法 2.1 通过设定最小读取字符和读取超时时间 可以使用termios结构体来控制终端设备的输入输出。可以通过VTIME和VMIN的值结合起来共同控制对输入的读取。此外,两…...

数据库复试问题总结
数据库复试问题 由《数据库系统概论(第5版)》总结而来,用于本人研究生复试准备。也欢迎各位准研究生们学习使用。 文章目录数据库复试问题1、三级模式结构及二级映射有什么优点?2、关系模型中的完整性约束是哪几类?3、SQL的特点?…...

Linux操作系统安装——服务控制
个人简介:云计算网络运维专业人员,了解运维知识,掌握TCP/IP协议,每天分享网络运维知识与技能。座右铭:海不辞水,故能成其大;山不辞石,故能成其高。个人主页:小李会科技的…...
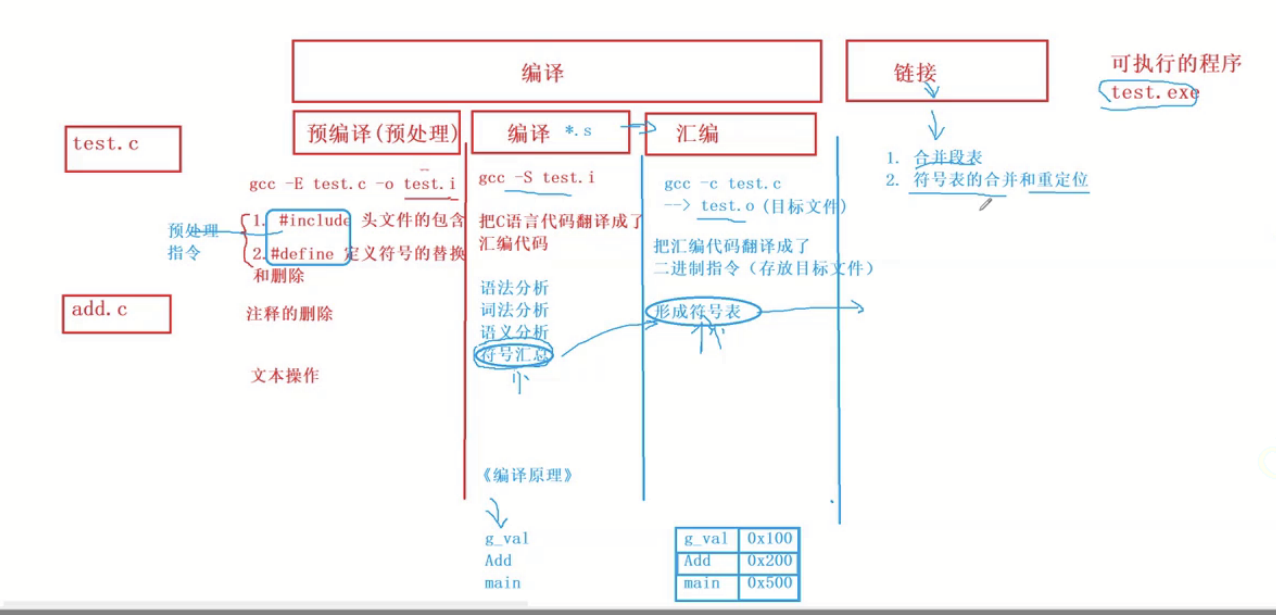
【C语言】编译+链接
一、程序的翻译环境和执行环境 在ANSI C的任何一种实现中,存在两个不同的环境。 第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令。 第2种是执行环境,它用于实际执行代码。详解编译链接翻译环境1.组成一个程序的每个源文件通过…...

为「IT女神勋章」而战
大家好,我是空空star,今天为「IT女神勋章」而战 文章目录前言一、IT女神勋章二、绘制爱心1.htmlcssjs来源:一行代码代码效果2.python来源:C知道代码效果3.go来源:复制代码片代码效果4.java来源:download代码…...

JS 动画 之 setInterval、requestAnimationFram
帧率:一秒中内页面刷新的次数,一般为60FPS,每一帧的时间是1000/6016.67ms setInterval 当我们使用setInterval做动画时,有两点会影响动画效果 由于setInterval是异步任务(宏任务),会放到异步队…...
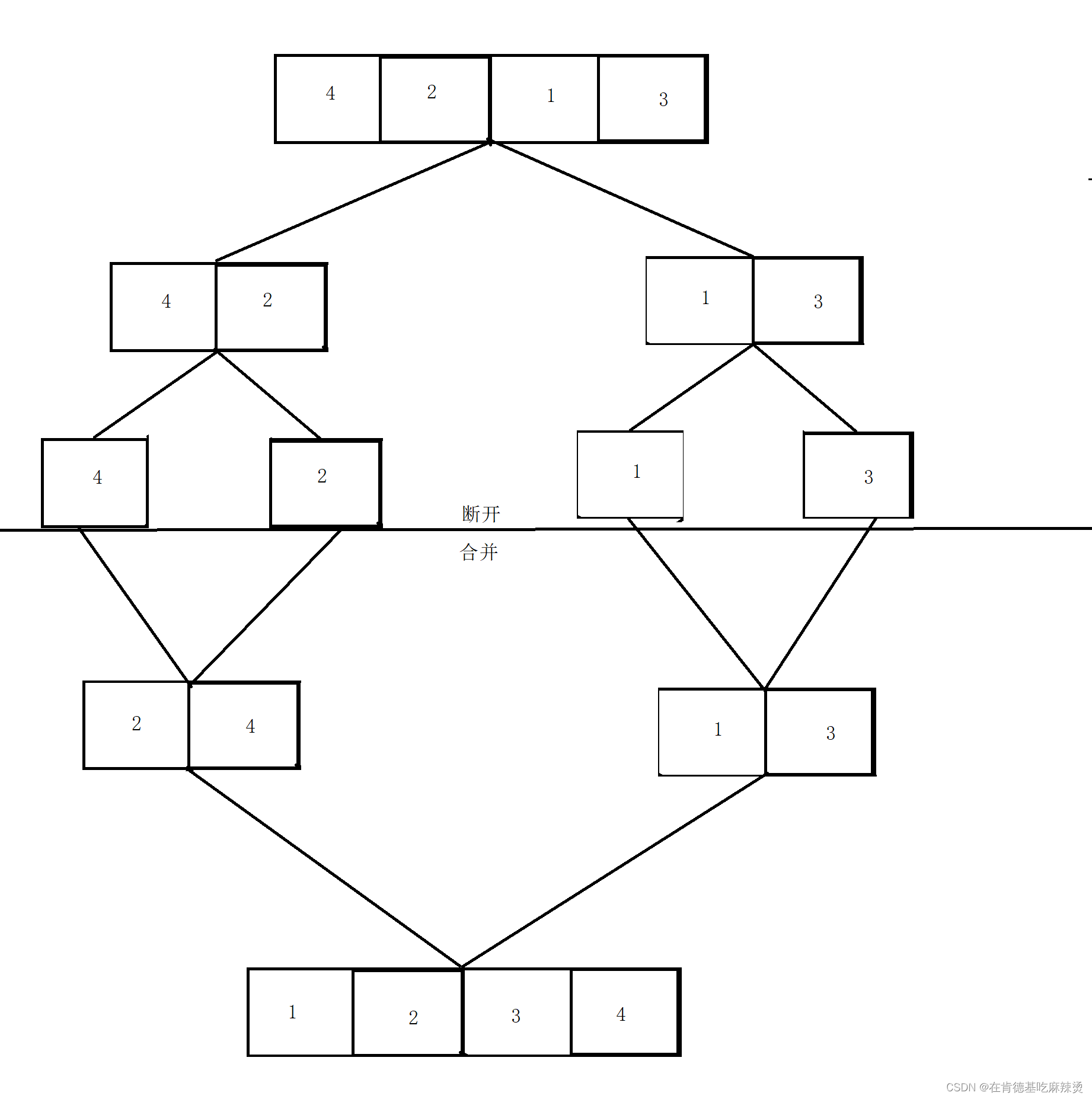
【LeetCode——排序链表】
文章目录排序链表二、解题思路:二.实现的代码总结:排序链表 一道链表排序题,链接在这里 二、解题思路: 解题思路:使用归并排序(用递归实现) 第一步:先找到链表的中间节点 第二步…...

二叉树的遍历(前序、中序、后序)| C语言
目录 0.写在前面 1.前序遍历 步骤详解 代码实现 2.中序遍历 步骤详解 代码实现 3.后序遍历 步骤详解 代码实现 0.写在前面 认识二叉树结构最简单的方式就是遍历二叉树。所谓遍历二叉树就是按照某种特定的规则,对二叉树的每一个节点进行访问,…...

【建议收藏】深入浅出Yolo目标检测算法(含Python实现源码)
深入浅出Yolo目标检测算法(含Python实现源码) 文章目录深入浅出Yolo目标检测算法(含Python实现源码)1. One-stage & Two-stage2. Yolo详解2.1 Yolo命名2.2 端到端输入输出2.3 Yolo中的标定框2.4 Yolo网络结构2.5 Yolo的算法流…...
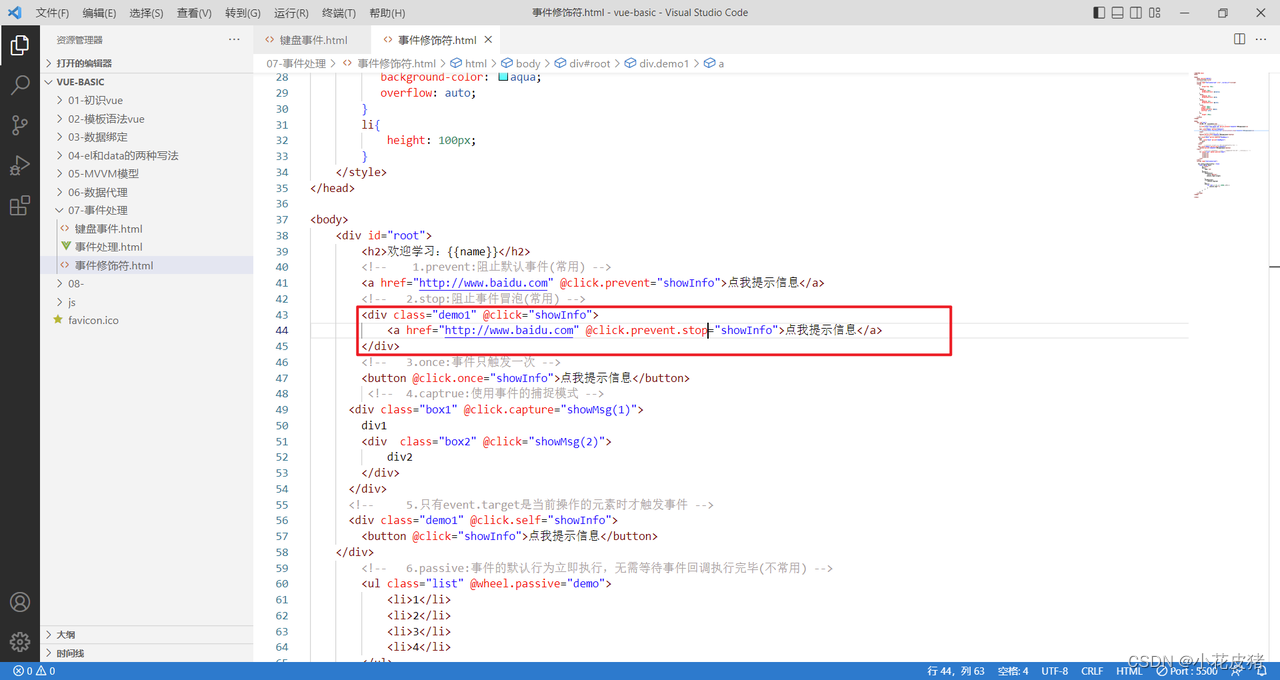
Vue常见的事件修饰符
前言 vue一共给我们准备了6个事件修饰符,前三个比较常用,后三个少见,这里着重讲下前三个 1.prevent:阻止默认事件(常用) 2. stop:阻止事件冒泡(常用) 3. once:事件只触发一次(常用) 4.captrue:使用事件的捕捉模式(不常用) 5.self:只有event…...
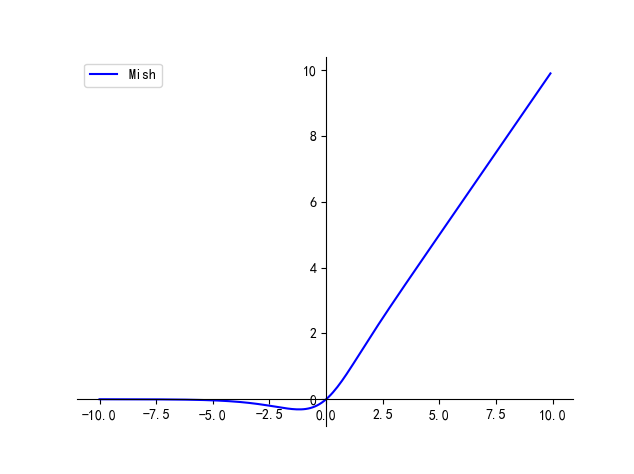
【卷积神经网络】激活函数 | Tanh / Sigmoid / ReLU / Leaky ReLU / ELU / SiLU / GeLU
文章目录一、Tanh二、Sigmoid三、ReLU四、Leaky ReLU五、ELU六、SiLU七、Mish本文主要介绍卷积神经网络中常用的激活函数及其各自的优缺点 最简单的激活函数被称为线性激活,其中没有应用任何转换。 一个仅由线性激活函数组成的网络很容易训练,但不能学习…...

刷题记录:牛客NC24048[USACO 2017 Jan P]Promotion Counting 求子树的逆序对个数
传送门:牛客 题目描述 奶牛们又一次试图创建一家创业公司,还是没有从过去的经验中吸取教训–牛是可怕的管理者! 为了方便,把奶牛从 1∼n1\sim n1∼n 编号,把公司组织成一棵树,1 号奶牛作为总裁(这棵树的根…...

MpAndroidChart3最强实践攻略
本篇主要总结下Android非常火爆的一个三方库MpAndroidChart的使用。可能在大多数情况下,我们很少会在Android端去开发图表。但如果说去做一些金融财经类、工厂类、大数据类等的app,那么绝对会用到MpAndroidChart。 一、前言 2018年,那年的我…...

如何快速配置游戏存档编辑器:面向玩家的完整指南
如何快速配置游戏存档编辑器:面向玩家的完整指南 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_mirrors/sp/SPT…...

YOLOv11农田烟草叶片病害目标检测数据集-470张-tobacco-plant-1
YOLOv11农田烟草叶片病害目标检测数据集 📊 数据集基本信息 目标类别: [‘Black shank’, ‘Healthy Leaf’, ‘Tobacco leaf curl disease -TLCD-’, ‘Tobacco mosaic virus -TMV-’, ‘brown sport’, ‘frogeye leaf spot’]中文类别:[‘…...

Taotoken的用量看板如何帮助团队清晰掌控AI支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的用量看板如何帮助团队清晰掌控AI支出 对于团队管理者而言,将大模型能力集成到业务流程中后,一个…...

RAG增强检索在AIGC工作流中的实战:从文档解析到向量召回全流程
系列导读 你现在看到的是《从0到1构建AIGC工作流自动化平台:架构、实践与运维全指南》的第 3/10 篇,当前这篇会重点解决:让读者掌握RAG从理论到代码的完整落地流程,并学会在工作流中优雅复用。 上一篇回顾:第 2 篇《搭建你的第一个AIGC工作流:基于LangChain实现多步链式…...

昇腾CANN torchtitan-npu 3D 并行实战:DP+TP+PP 组合策略与 Pipeline Bubble 消除
175B 参数的大模型不能放在一张 NPU 上——需要分布式。三种并行策略各有优劣:数据并行(DP)简单但显存不降、张量并行(TP)通信密集但显存降得最多、流水线并行(PP)显存也降但有 bubbleÿ…...
)
2026年Java面试突围指南(附高频场景题+答案)
前言今年的面试比往年要难得多,各个互联网企业对于 Java 岗位的要求越来越多,也越来越高,主要是初级岗位已经趋近饱和,但高级岗位又相对来说缺乏,这类的人才偏少,因此作为 Java 开发人员,我们应…...

Gemini从部署到退役的全周期价值追踪:3类企业实测数据揭示87%团队忽略的关键衰减点
更多请点击: https://kaifayun.com 第一章:Gemini从部署到退役的全周期价值追踪:3类企业实测数据揭示87%团队忽略的关键衰减点 在真实生产环境中,Gemini模型的价值并非随部署即达峰值,而是呈现典型的“倒U型衰减曲线”…...

机器学习在临床精神病学的经济性分析:成本效益与落地挑战
1. 项目概述:当机器学习遇见临床精神病学,一场关于效率与成本的深度对话作为一名长期关注技术与医疗交叉领域的从业者,我观察到,近年来关于人工智能(AI)和机器学习(ML)在医学中应用的…...

【2026年版|必收藏】从0到1!AI大模型保姆级学习路线
2026年,大模型已从实验室走向规模化落地,AI Agent(智能体)、多模态、世界模型成为行业核心热点,无论是零基础小白想入门AI赛道,还是程序员想转型大模型领域,一套系统、不踩坑的学习路线都至关重…...

毫米波雷达8.6米非接触生命体征监测:mmVital-Signs开源项目完整指南
毫米波雷达8.6米非接触生命体征监测:mmVital-Signs开源项目完整指南 【免费下载链接】mmVital-Signs mmVital-Signs project aims at vital signs detection and provide standard python API from Texas Instrument (TI) mmWave hardware, such as xWR14xx, xWR16x…...