如何在Python中实现文本相似度比较?
在Python中实现文本相似度比较可以通过多种方法,每种方法都有其适用场景和优缺点。以下是一些常见的文本相似度比较方法:
1. 余弦相似度(Cosine Similarity)
余弦相似度是通过计算两个向量之间夹角的余弦值来确定它们之间的相似度。在文本处理中,可以使用TF-IDF(Term Frequency-Inverse Document Frequency)将文本转换为向量。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity# 示例文本
text1 = "The quick brown fox jumps over the lazy dog"
text2 = "A fast brown fox leaped over the dog"# 使用TF-IDF向量化文本
vectorizer = TfidfVectorizer().fit_transform([text1, text2])# 计算余弦相似度
cosine_sim = cosine_similarity(vectorizer[0:1], vectorizer[1:2])[0][0]
print(f"Cosine Similarity: {cosine_sim}")
2. Jaccard 相似度
Jaccard 相似度是衡量两个集合相似度的一种方法,通过计算两个集合交集的大小与并集的大小之比得到。
def jaccard_similarity(text1, text2):set1 = set(text1.split())set2 = set(text2.split())intersection = set1.intersection(set2)union = set1.union(set2)return len(intersection) / len(union)text1 = "The quick brown fox jumps over the lazy dog"
text2 = "A fast brown fox leaped over the dog"similarity = jaccard_similarity(text1, text2)
print(f"Jaccard Similarity: {similarity}")
3. Levenshtein 距离(编辑距离)
Levenshtein 距离是两个序列之间的距离,定义为将一个序列转换为另一个序列所需的最少单字符编辑(插入、删除或替换)次数。
from Levenshtein import distancetext1 = "example text one"
text2 = "sample text one"distance = distance(text1, text2)
similarity = 1 - distance / max(len(text1), len(text2))
print(f"Levenshtein Similarity: {similarity}")
4. Ratcliff/Obershelp 算法
这是一种字符串比较算法,用于计算两个字符串之间的相似度。
from ratcliff_obershelp import similaritytext1 = "example text one"
text2 = "sample text one"similarity_score = similarity(text1, text2)
print(f"Ratcliff/Obershelp Similarity: {similarity_score}")
5. Word2Vec 和 Doc2Vec
这些是基于深度学习的文本相似度比较方法,它们使用预训练的词嵌入(如Word2Vec)或文档嵌入(如Doc2Vec)来将文本转换为向量,然后使用余弦相似度等度量来比较这些向量。
from gensim.models import Word2Vec# 假设word2vec_model是一个预训练的Word2Vec模型
text1 = "The quick brown fox jumps over the lazy dog"
text2 = "A fast brown fox leaped over the dog"# 使用Word2Vec模型将文本转换为向量
vector1 = word2vec_model.wmdistance(text1.split(), text2.split())
print(f"Word2Vec Similarity: {vector1}")
6. BERT 和其他 Transformer 模型
最新的自然语言处理模型,如BERT,可以用于计算文本之间的相似度。这些模型能够捕捉到文本的深层语义信息。
from transformers import BertModel, BertTokenizer# 初始化BERT的分词器和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')# 将文本转换为BERT的输入格式
text1 = "The quick brown fox jumps over the lazy dog"
text2 = "A fast brown fox leaped over the dog"encoded1 = tokenizer(text1, return_tensors='pt')
encoded2 = tokenizer(text2, return_tensors='pt')# 使用BERT模型获取向量表示
with torch.no_grad():output1 = model(**encoded1)output2 = model(**encoded2)# 计算余弦相似度
cosine_sim = cosine_similarity(output1.last_hidden_state[:, 0, :], output2.last_hidden_state[:, 0, :])[0][0]
print(f"BERT Similarity: {cosine_sim}")
注意事项
- 文本预处理:在进行相似度比较之前,通常需要对文本进行预处理,如分词、去除停用词、词干提取或词形还原等。
- 选择方法:根据具体应用场景和需求选择最合适的方法。例如,如果需要捕捉语义层面的相似度,可能需要使用深度学习方法。
这些方法各有优势,你可能需要根据你的具体需求和资源来选择最合适的一种或几种方法的组合。
相关文章:

如何在Python中实现文本相似度比较?
在Python中实现文本相似度比较可以通过多种方法,每种方法都有其适用场景和优缺点。以下是一些常见的文本相似度比较方法: 1. 余弦相似度(Cosine Similarity) 余弦相似度是通过计算两个向量之间夹角的余弦值来确定它们之间的相似…...

韩顺平0基础学Java——第7天
p110-p154 控制结构(第四章) 多分支 if-elseif-else import java.util.Scanner; public class day7{public static void main(String[] args) {Scanner myscanner new Scanner(System.in);System.out.println("input your score?");int s…...

性能远超GPT-4!谷歌发布Med-Gemini医疗模型;李飞飞首次创业瞄准空间智能;疫苗巨头联合OpenAl助力AI医疗...
AI for Science 企业动态速览—— * 谷歌 Med-Gemini 医疗 AI 模型性能远超 GPT-4 * 斯坦福李飞飞首次创业瞄准「空间智能」 * 疫苗巨头 Moderna 与 OpenAl 达成合作 * 美国能源部推动 AI 在清洁能源领域的应用 * 美年健康荣获「2024福布斯中国人工智能创新场景应用企业TOP10」…...
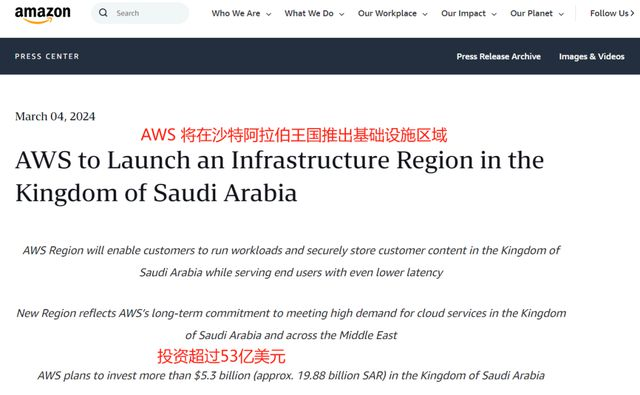
中国科技大航海时代,“掘金”一带一路
文|白 鸽 编|王一粟 “这不就是90年代的内地吗?” 在深度考察完沙特市场后,华盛集团联合创始人兼CEO张霆对镜相工作室感慨道。 在张霆看来,沙特落后的基建(意味着大量创新空间)、刚刚开放…...

ffmpeg7.0 flv支持hdr
ffmpeg7.0 flv支持hdr 自从ffmpeg6.0应用enhance rtmp支持h265/av1的flv格式后,7.0迎来了flv的hdr能力。本文介绍ffmpeg7.0如何支持hdr in flv。 如果对enhance rtmp如何支持h265不了解,推荐详解Enhanced-RTMP支持H.265 1. enhance rtmp关于hdr 文档…...
【教程】极简Python接入免费语音识别API
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,请不吝给个[点赞、收藏、关注]哦~ 安装库: pip install SpeechRecognition 使用方法: import speech_recognition as srr sr.Recognizer() harvard sr…...
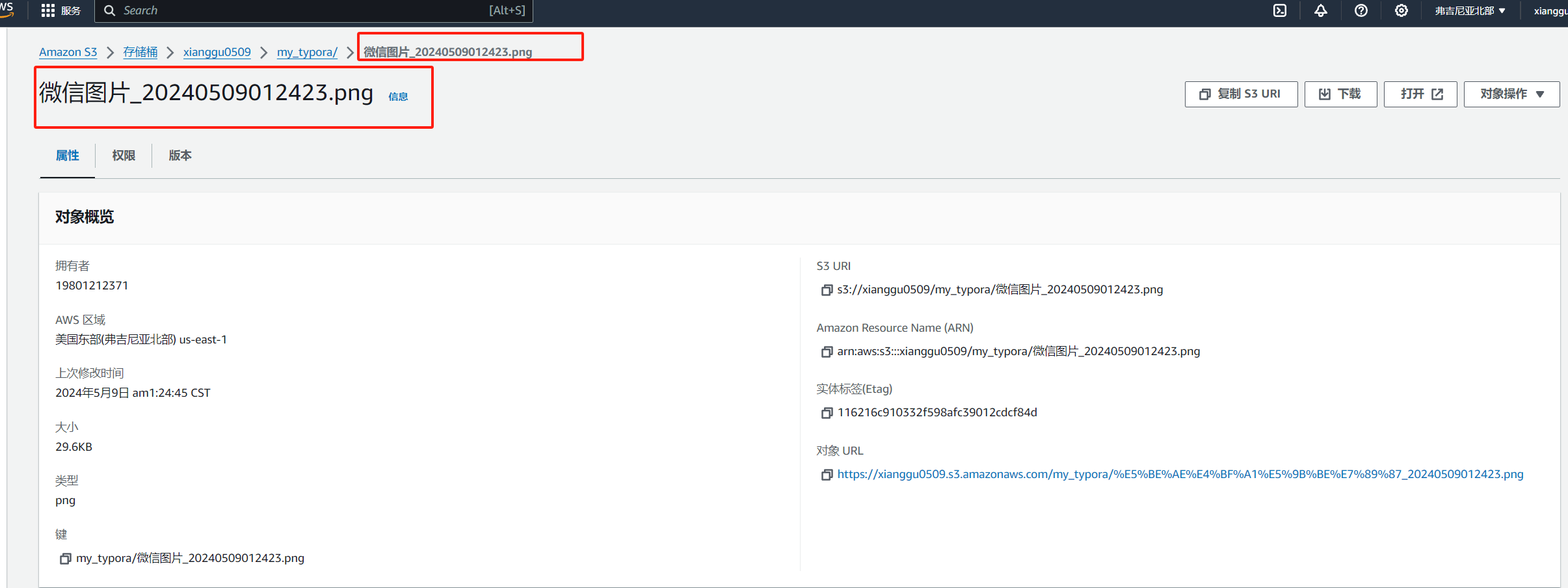
详解typora配置亚马逊云科技Amazon S3图床
欢迎免费试用亚马逊云科技产品:https://mic.anruicloud.com/url/1333 当前有很多不同的博客社区,不同的博客社区使用的编辑器也不尽相同,大概可以分为两种,一种是markdown格式,另外一种是富文本格式。例如华为云开发者…...

Python sqlite3库 实现 数据库基础及应用 输入地点,可输出该地点的爱国主义教育基地名称和批次的查询结果。
目录 【第11次课】实验十数据库基础及应用1-查询 要求: 提示: 运行结果: 【第11次课】实验十数据库基础及应用1-查询 声明:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 1.简答题 数据库文件Edu_Base.db&#…...

iOS-SSL固定证书
文章目录 1. SSL简介2. 证书锁定原理1.1 证书锁定1.2 公钥锁定1.3 客户端获取公钥1.4 客户端使用SSL锁定选择1.5 项目支持SSL证书锁定1.6 问题记录1. SSL简介 证书锁定(SSL/TLS Pinning)顾名思义,将服务器提供的SSL/TLS证书内置到移动端开发的APP客户端中,当客户端发起请求…...

docker 开启 tcp 端口
前言:查了很多网上资料 都说要修改daemons,json 完全不管用,而且还导致添加 {“host”:["tcp://0.0.0.0:2375","unix:///var/lib/docker.sock"]} 后,docker restart 失败,浪费了不少时间 !&am…...

zookeeper之分布式环境搭建
ZooKeeper的分布式环境搭建是一个涉及多个步骤的过程,主要包括准备工作、安装ZooKeeper、配置集群、启动服务以及验证集群状态。以下是搭建ZooKeeper分布式环境的基本步骤: 1. 准备工作 确保所有节点的系统时间同步。确保所有节点之间网络互通…...

java设计模式三
工厂模式是一种创建型设计模式,它提供了一个创建对象的接口,但允许子类决定实例化哪一个类。工厂模式有几种变体,包括简单工厂模式、工厂方法模式和抽象工厂模式。下面通过一个简化的案例和对Java标准库中使用工厂模式的源码分析来说明这一模…...

##12 深入了解正则化与超参数调优:提升神经网络性能的关键策略
文章目录 前言1. 正则化技术的重要性1.1 L1和L2正则化1.2 Dropout1.3 批量归一化 2. 超参数调优技术2.1 网格搜索2.2 随机搜索2.3 贝叶斯优化 3. 实践案例3.1 设置实验3.2 训练和测试 4. 结论 前言 在深度学习中,构建一个高性能的模型不仅需要一个好的架构…...
TODESK怎么查看有人在远程访问
odesk怎么查看有人在远程访问 Todesk作为一款远程桌面控制软件,为用户提供了便捷的远程访问与控制功能。但在享受这种便利的同时,许多用户也关心如何确保自己设备的安全,特别是如何知道是否有人在未经授权的情况下远程访问自己的电脑。本文将…...
)
【Web漏洞指南】服务器端 XSS(动态 PDF)
【Web漏洞指南】服务器端 XSS(动态 PDF) 概述流行的 PDF 生成工具常见攻击载荷 概述 如果一个网页使用用户控制的输入创建 PDF,您可以尝试欺骗创建 PDF 的机器人以执行任意的 JS 代码。 因此,如果PDF 创建机器人发现某种HTML标签…...

Qt中的对象树
一. QT对象树的概念 QObject 的构造函数中会传入一个 Parent 父对象指针,children() 函数返回 QObjectList。即每一个 QObject 对象有且仅有一个父对象,但可以有很多个子对象。 那么Qt这样设计的好处是什么呢?很简单,就是为了方…...
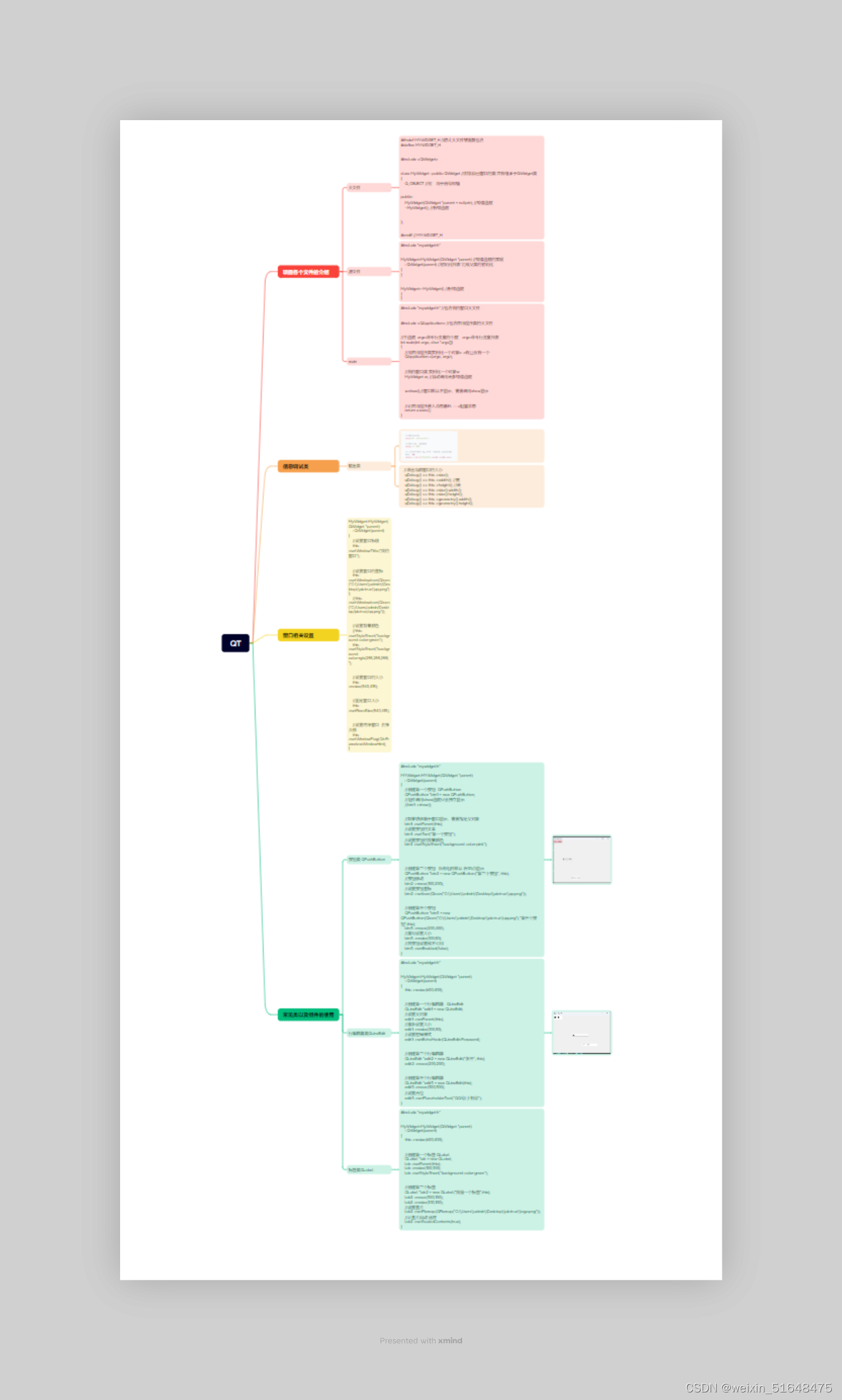
QT-day1
1、 自由发挥应用场景,实现登录界面。 要求:尽量每行代码都有注释。 #ifndef MYWIDGET_H #define MYWIDGET_H #include <QWidget> #include <QIcon>//窗口 #include <QLabel>//标签库 #include <QMovie>//动态图片库 #include…...
安装oh-my-zsh(命令行工具)
文章目录 一、安装zsh、git、wget二、安装运行脚本1、curl/wget下载2、手动下载 三、切换主题1、编辑配置文件2、切换主题 四、安装插件1、zsh-syntax-highlighting(高亮语法错误)2、zsh-autosuggestions(自动补全) 五、更多优化配…...

解决方案:‘Series‘ object has no attribute ‘xxxx‘
文章目录 一、现象二、解决方案 一、现象 ...... model.fit(X_train, y_train) y_pred model.predict(X_test) recall recall_score(y_test, y_pred) precision precision_score(y_test. y_pred) ......执行语句到**“precision precision_score(y_test. y_pred)”**这里发…...
智慧手术室手麻系统源码,C#手术麻醉临床信息系统源码,符合三级甲等医院评审要求
手麻系统全套源码,C#手术麻醉系统源码,支持二次开发,授权后可商用。 手术麻醉临床信息系统功能符合三级甲等医院评审要求,实现与医院现有信息系统如HIS、LIS、PACS、EMR等系统全面对接,全面覆盖从患者入院,…...

终极免费风扇控制软件:如何让你的电脑既安静又凉爽
终极免费风扇控制软件:如何让你的电脑既安静又凉爽 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/Fa…...

物联网技术如何重塑智能电网的底层架构
1. 物联网技术重塑智能电网的底层逻辑2003年美加大停电事故导致5000万人陷入黑暗,这场灾难直接催生了现代智能电网的诞生。如今,当我们谈论智能电网时,本质上是在讨论一个由物联网(IoT)技术重构的能源神经系统。这个系统通过海量智能终端实时…...

一站式Steam Deck控制器配置方案:Windows平台完整游戏体验指南
一站式Steam Deck控制器配置方案:Windows平台完整游戏体验指南 【免费下载链接】steam-deck-windows-usermode-driver A windows usermode controller driver for the steam deck internal controller. 项目地址: https://gitcode.com/gh_mirrors/st/steam-deck-w…...

Python开发者三步完成Taotoken OpenAI兼容接口的接入与调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者三步完成Taotoken OpenAI兼容接口的接入与调用 对于习惯使用OpenAI官方Python SDK的开发者来说,接入Taoto…...

HsMod终极指南:50+功能全面解锁炉石传说模改插件
HsMod终极指南:50功能全面解锁炉石传说模改插件 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx框架开发的炉石传说模改插件,通过50多项实用…...

别再“另存为”了!职场人90%的无效内耗都源于这一个操作。企业文档如何管理?
加班到晚上八点,职场人小林终于改完了项目方案,随手点了“另存为”,命名为“方案_最终版.doc“后发到了工作群。本以为可以安心下班,群里却炸锅了:“小林,你这个最终版和我手里的不一样啊?”“我…...

PHPExcel批量数据导入终极指南:验证、清洗与入库全流程 [特殊字符]
PHPExcel批量数据导入终极指南:验证、清洗与入库全流程 🚀 【免费下载链接】PHPExcel ARCHIVED 项目地址: https://gitcode.com/gh_mirrors/ph/PHPExcel PHPExcel是一款强大的PHP库,专门用于处理Excel文件的读取、写入和操作。虽然该项…...

stm32开发者如何快速接入大模型api实现智能对话功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 STM32开发者如何快速接入大模型API实现智能对话功能 为嵌入式设备增加自然语言交互能力,是许多STM32开发者希望实现的功…...

ZoneMinder开源监控系统:30分钟打造专业级安防解决方案,支持IP/USB/模拟摄像头全兼容
ZoneMinder开源监控系统:30分钟打造专业级安防解决方案,支持IP/USB/模拟摄像头全兼容 【免费下载链接】zoneminder ZoneMinder is a free, open source Closed-circuit television software application developed for Linux which supports IP, USB and…...

C#集成AI对话:开源库ha.openclaw.conversation实战指南
1. 项目概述:一个面向对话式AI的C#开源库最近在折腾一个需要集成智能对话能力的桌面应用,后台服务是用C#写的。大家都知道,现在搞AI对话,主流玩法是调用OpenAI、Claude这些大模型的API,或者用一些开源的本地模型。但真…...