MongoDB聚合运算符:$topN
MongoDB聚合运算符:$topN
文章目录
- MongoDB聚合运算符:$topN
- 语法
- 用法
- 关于null和缺失值的处理
- BSON数据类型排序
- 举例
- 查找三个得分最高的
- 查找全部游戏中三个最高的得分
- 基于分组key来计算参数n
$topN聚合运算符返回分组中指定顺序的最前面
n个元素,如果分组中的元素数量小于
n,则返回分组的全部元素。从MongoDB5.2开始支持。
语法
{$topN:{n: <expression>,sortBy: { <field1>: <sort order>, <field2>: <sort order> ... },output: <expression>}
}
n用于限制每组结果的数量,必须是正整数表达式,要么是常数,要么取决于$group的_id值sortBy制定返回结果的顺序,语法类似于$sortoutput指定分组元素输出的内容,可以是任何合法的表达式。
用法
$topN不支持作为聚合表达式。$topN只支持作为window 操作符。- 聚合管道调用
$topN受100M的限制,如果单组超过这一限制将报错。
关于null和缺失值的处理
$topN不会过滤掉空值$topN会将缺失值转换为null
db.aggregate( [{$documents: [{ playerId: "PlayerA", gameId: "G1", score: 1 },{ playerId: "PlayerB", gameId: "G1", score: 2 },{ playerId: "PlayerC", gameId: "G1", score: 3 },{ playerId: "PlayerD", gameId: "G1"},{ playerId: "PlayerE", gameId: "G1", score: null }]},{$group:{_id: "$gameId",playerId:{$topN:{output: [ "$playerId", "$score" ],sortBy: { "score": 1 },n: 3}}}}
] )
在这个例子中:
- 使用
$documents阶段创建了一些字面量(常量)文档,包含了选手的得分 $group阶段根据gameId对文档进行了分组,显然文档中的gameId都是G1PlayerD的得分缺失,PlayerE的得分为null,他们的得分都会被当做null处理playerId字段和score字段被指定为输出:["$playerId"," $score"],以数组的形式返回sortBy: { "score": 1 }指定了排序的方式,空值被排在最前面,返回playerId数组
如下:
[{_id: 'G1',playerId: [ [ 'PlayerD', null ], [ 'PlayerE', null ], [ 'PlayerA', 1 ] ]}
]
BSON数据类型排序
当不同类型排序是,使用BSON数据类型的顺序进行排序:
- 当进行正序排序时(由小到大),字符串的优先级在数值之前
- 当进行逆序排序时(由大到小),字符串的优先级在数值之前
下面的例子中包含了字符串和数值类型:
db.aggregate( [{$documents: [{ playerId: "PlayerA", gameId: "G1", score: 1 },{ playerId: "PlayerB", gameId: "G1", score: "2" },{ playerId: "PlayerC", gameId: "G1", score: "" }]},{$group:{_id: "$gameId",playerId: {$topN:{output: ["$playerId","$score"],sortBy: {"score": -1},n: 3}}}}
] )
在这个例子中:
PlayerA的得分是整数1PlayerB的得分是字符串"2"PlayerC的得分是空字符串""
因为排序指定为逆序{ "score" : -1 },字符串的字面量排在PlayerA的数值得分之前:
[{_id: "G1",playerId: [ [ "PlayerB", "2" ], [ "PlayerC", "" ], [ "PlayerA", 1 ] ]}
]
举例
使用下面的命令创建gamescores集合:
db.gamescores.insertMany([{ playerId: "PlayerA", gameId: "G1", score: 31 },{ playerId: "PlayerB", gameId: "G1", score: 33 },{ playerId: "PlayerC", gameId: "G1", score: 99 },{ playerId: "PlayerD", gameId: "G1", score: 1 },{ playerId: "PlayerA", gameId: "G2", score: 10 },{ playerId: "PlayerB", gameId: "G2", score: 14 },{ playerId: "PlayerC", gameId: "G2", score: 66 },{ playerId: "PlayerD", gameId: "G2", score: 80 }
])
查找三个得分最高的
使用$topN查找单个游戏中得分最高的3个:
db.gamescores.aggregate( [{$match : { gameId : "G1" }},{$group:{_id: "$gameId",playerId:{$topN:{output: ["$playerId", "$score"],sortBy: { "score": -1 },n:3}}}}
] )
本例中:
- 使用
$match阶段用一个gameId对结果进行筛选,即:G1 - 使用
$group阶段依据gameId对结果进行分组,本例中只有一个分组G1 - 使用
sortBy: { "score": -1 }按照得分进行逆序排序 - 使用
output : ["$playerId"," $score"]为$topN指定输出字段 - 使用
$topN返回游戏得分最高的3个选手和得分
结果如下:
[{_id: 'G1',playerId: [ [ 'PlayerC', 99 ], [ 'PlayerB', 33 ], [ 'PlayerA', 31 ] ]}
]
与下面的SQL查询等价:
SELECT T3.GAMEID,T3.PLAYERID,T3.SCORE
FROM GAMESCORES AS GS
JOIN (SELECT TOP 3GAMEID,PLAYERID,SCOREFROM GAMESCORESWHERE GAMEID = 'G1'ORDER BY SCORE DESC) AS T3ON GS.GAMEID = T3.GAMEID
GROUP BY T3.GAMEID,T3.PLAYERID,T3.SCOREORDER BY T3.SCORE DESC
查找全部游戏中三个最高的得分
使用$topN查找所有游戏中得分最高的三个
db.gamescores.aggregate( [{$group:{ _id: "$gameId", playerId:{$topN:{output: [ "$playerId","$score" ],sortBy: { "score": -1 },n: 3}}}}
] )
在本例中:
- 使用
$group按照groupId对结果排序 - 使用
output : ["$playerId", "$score"]指定bottom输出的字段 - 使用
sortBy: { "score": -1 }按照得分进行逆序排序 - 使用
$topN返回所有游戏中得分最高的三个
结果如下:
[{_id: 'G1',playerId: [ [ 'PlayerC', 99 ], [ 'PlayerB', 33 ], [ 'PlayerA', 31 ] ]},{_id: 'G2',playerId: [ [ 'PlayerD', 80 ], [ 'PlayerC', 66 ], [ 'PlayerB', 14 ] ]}
]
这个操作与下面的SQL语句等价:
SELECT PLAYERID,GAMEID,SCORE
FROM(SELECT ROW_NUMBER() OVER (PARTITION BY GAMEID ORDER BY SCORE DESC) AS GAMERANK,GAMEID,PLAYERID,SCOREFROM GAMESCORES
) AS T
WHERE GAMERANK <= 3
ORDER BY GAMEID
基于分组key来计算参数n
可以动态指定n的值,在本例中$cond表达式用在gameId字段:
db.gamescores.aggregate([{$group:{_id: {"gameId": "$gameId"},gamescores:{$topN:{output: "$score",n: { $cond: { if: {$eq: ["$gameId","G2"] }, then: 1, else: 3 } },sortBy: { "score": -1 }}}}}
] )
在本例中:
- 使用
$group按照groupId对结果排序 - 使用
output : "$score"指定$topN输出的字段 - 如果
gameId是G2则n为1,否则n为3 - 使用
sortBy: { "score": -1 }按照得分进行逆序排序
操作结果如下:
[{ _id: { gameId: 'G1' }, gamescores: [ 99, 33, 31 ] },{ _id: { gameId: 'G2' }, gamescores: [ 80 ] }
]
相关文章:

MongoDB聚合运算符:$topN
MongoDB聚合运算符:$topN 文章目录 MongoDB聚合运算符:$topN语法用法关于null和缺失值的处理BSON数据类型排序 举例查找三个得分最高的查找全部游戏中三个最高的得分基于分组key来计算参数n $topN聚合运算符返回分组中指定顺序的最前面 n个元素…...

什么是顶级域名、二级域名、三级域名?
什么是顶级域名、二级域名、三级域名? 一般域名都由两部分组成,中间用“.”隔开,一个域名是几级域名,简单的可以通过数“.”的方式来判断。 如baidu.com,它是由baidu和后缀“.com”组成,我们可以认定它是顶…...
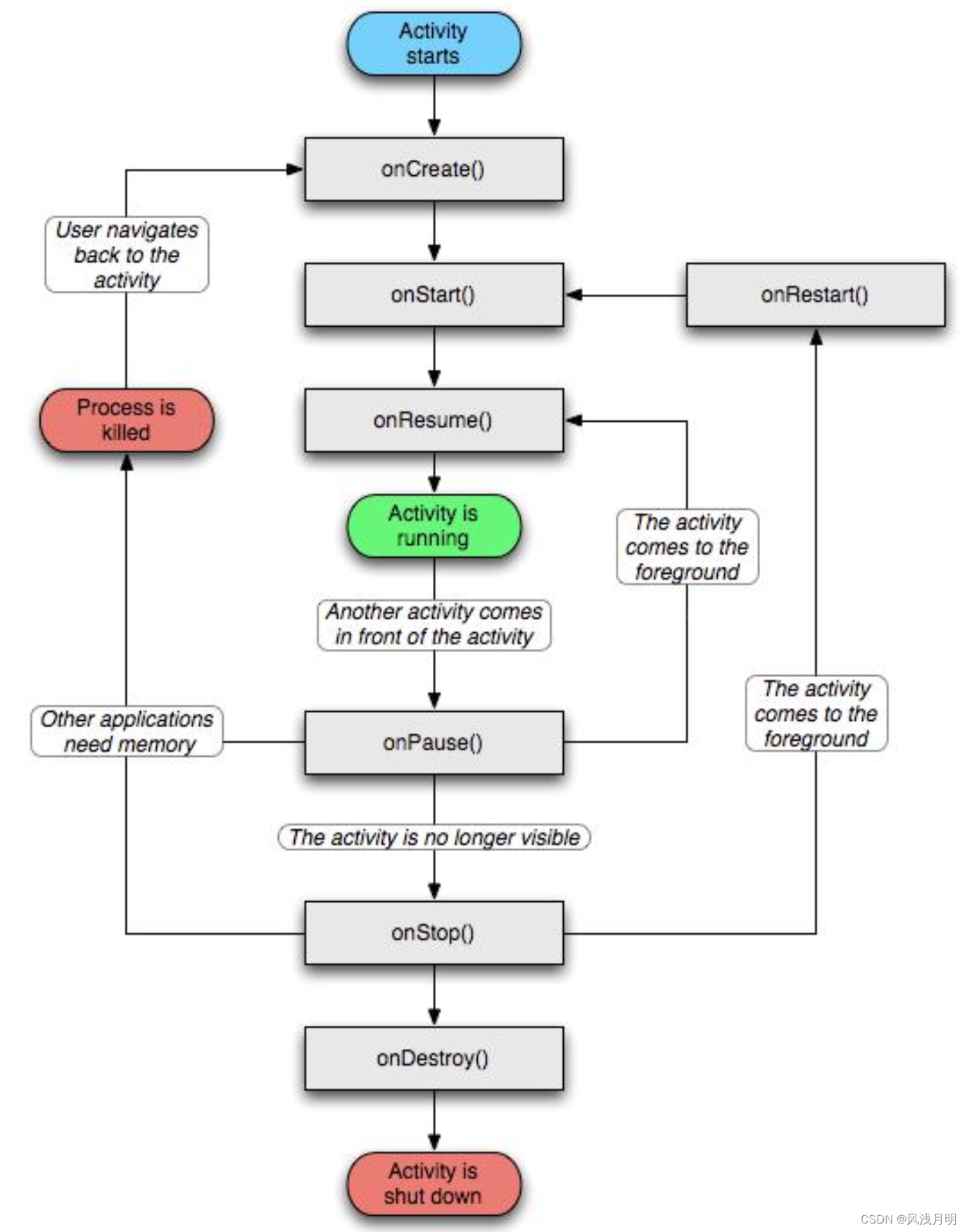
[Android]四大组件简介
在 Android 开发中,“四大组件”(Four Major Components)是指构成 Android 应用程序的四种核心组件,它们通过各自的方式与系统交互,实现应用的多样功能。这些组件是:Activity、Service、Broadcast Receiver…...
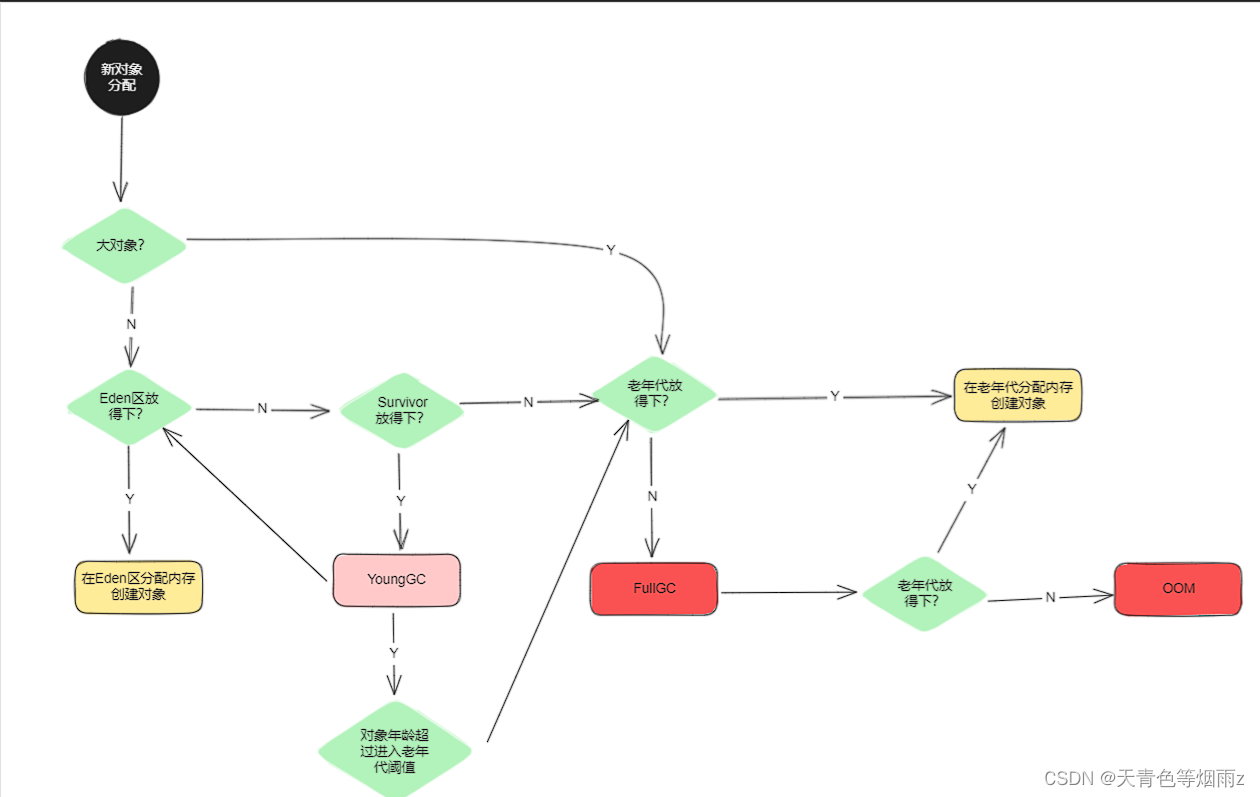
一次完整的GC流程
Java堆中内存区分 Java的堆由新生代(Young Generation)和老年代(Old Generation)组成。新生代存放新分配的对象,老年代存放长期存在的对象。 新生代(Young)由年轻区(Eden&a…...
GAME101-Lecture06学习
前言 上节课主要讲的是三角形的光栅化。重要的思想是要利用像素的中心对三角形可见性的函数进行采样。 这节课主要就是反走样。 课程链接:Lecture 06 Rasterization 2 (Antialiasing and Z-Buffering)_哔哩哔哩_bilibili 反走样引入 通过采样,得到…...
等级考试试卷(二级))
202203青少年软件编程(Python)等级考试试卷(二级)
第 1 题 【单选题】 关于Python中的列表,下列描述错误的是?( ) A :列表是Python中内置可变序列,是若干元素的有序集合; B :列表中的每一个数据称为“元素”; C :在Python中,一个列表中的数据类型可以各不相同; D :可以使用s[1]来获取列表s的第一个元素。 正确答案…...

带有-i选项的sed命令在Linux上执行成功,但在MacOS上失败了
问题: 我已经成功地使用以下 sed 命令在Linux中搜索/替换文本: sed -i s/old_string/new_string/g /path/to/file然而,当我在Mac OS X上尝试时,我得到: command i expects \ followed by text我以为我的Mac运行的是…...

[Linux_IMX6ULL驱动开发]-GPIO子系统和Pinctrl子系统
目录 Pinctrl子系统的概念 GPIO子系统的概念 定义自己的GPIO节点 GPIO子系统的函数 引脚号的确定 基于GPIO子系统的驱动程序 驱动程序 设备树修改 之前我们进行驱动开发的时候,对于硬件的操作是依赖于ioremap对寄存器的物理地址进行映射,以此来达…...
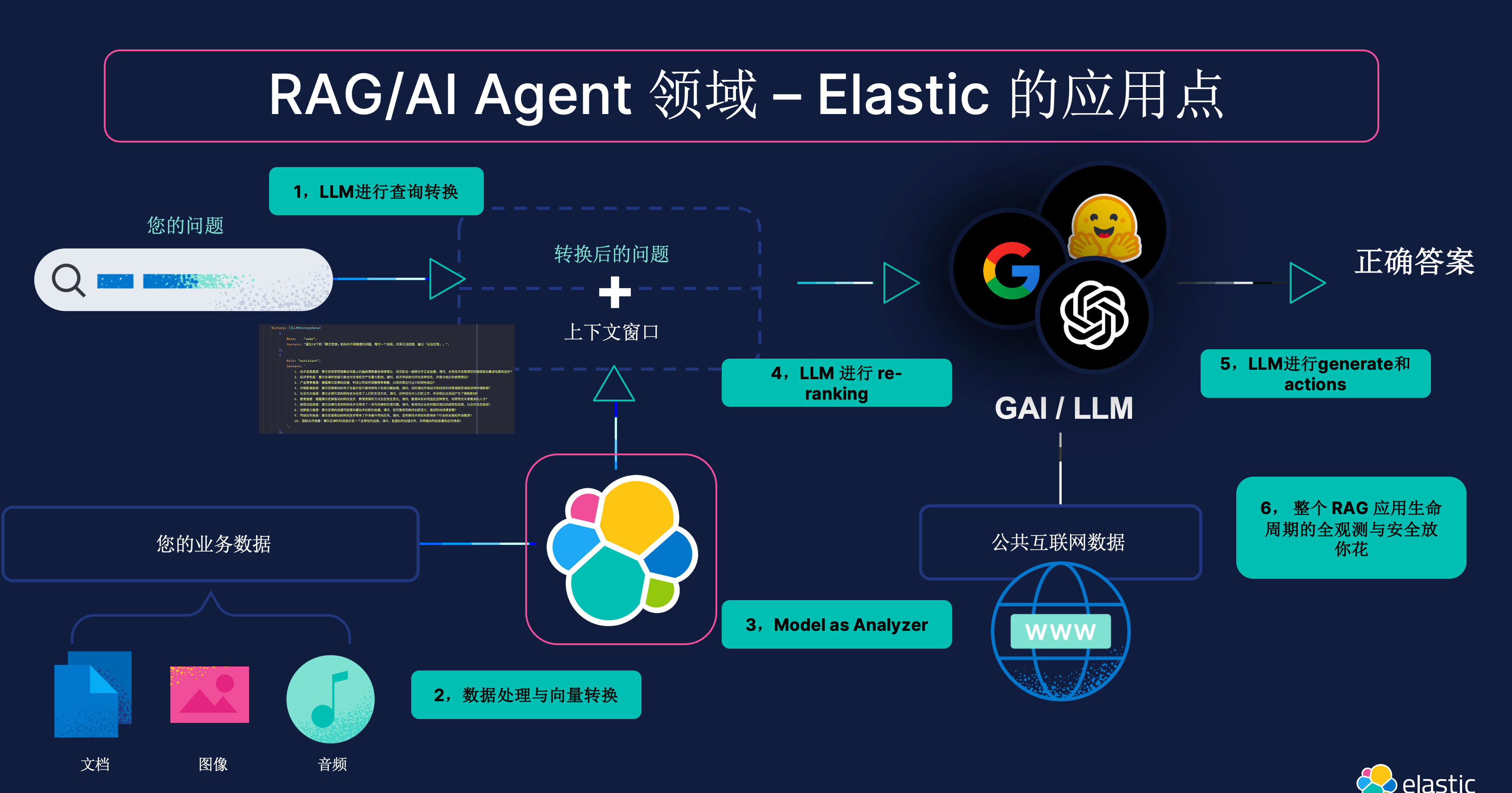
Elasticsearch:理解人工智能相似性搜索
理解相似性搜索(也称为语义搜索)的指南,这是人工智能最新阶段的关键发现之一。 最新阶段人工智能的关键发现之一是根据相似性搜索和查找文档的能力。相似性搜索是一种比较信息的方法,其基于含义而非关键字。 相似性搜索也被称为语…...

Mac YOLO V9推理测试(基于ultralytics)
环境: Mac M1 (MacOS Sonoma 14.3.1) Python 3.11PyTorch 2.1.2 一、准备工作 使用YOLO一般都会接触ultralytics这个框架,今天来试试用该框架进行YOLO V9模型的推理。 YOLOv9目前提供了四种模型下载:yolov9-c.pt、yolov9-e.pt、gelan-c.p…...

OuterClass.this cannot be referenced from a static context
目标,定义了一个内部类,然后把这个内部类设置为单例 一 使用非静态内部类 public class OuterClass {public class InnerClass {} } 直接定义单例: .OuterClass.this cannot be referenced from a static context public class OuterClass …...

CAP与BASE分布式理论
一、分布式理论 1.CAP理论 CAP理论是说对于分布式数据存储,最多只能同时满足一致性(C,Consistency)、可用性(A, Availability)、分区容忍性(P,Partition Tolerance&…...

JavaScript性能优化策略
JavaScript性能优化策略可以分为以下几个方面: 减少内存使用:避免创建不必要的对象和数组,使用对象池或数组缓存来重复利用已有的对象和数组。此外,及时释放不再需要的对象和数组,避免内存泄漏。 减少重绘和回流&…...

curl访问流式非流式大模型openai api接口
参考:https://platform.openai.com/docs/api-reference/making-requests 命令行访问: 直接是vllm的openai api接口 curl http://192.168.***:10860/v1/chat/completions -H "Content-Type: application/json" -H "Authorization: EMPTY" -d {"mod…...

Go 使用 MongoDB
MongoDB 安装(Docker)安装 MongoDB Go 驱动使用 Go Driver 连接到 MongoDB在 Go 里面使用 BSON 对象CRUD 操作 插入文档更新文档查询文档删除文档 下一步 MongoDB 安装(Docker) 先装个 mongo,为了省事就用 docker 了。 docker 的 daemon.json 加一个国内的源地址…...

什么是g++-arm-linux-gnueabihf
2024年5月3日,周五晚上 g-arm-linux-gnueabihf 是针对 ARM 架构(ARMv7 和 ARMv8)的 Linux 系统开发的 GNU C 编译器套件,可以在 x86 或 x86_64 架构的主机上使用,用于交叉编译 ARM Linux 应用程序和库。 与 gcc-arm-l…...

Unity延时触发的几种常规方法
目录 1、使用协程Coroutine2、使用Invoke、InvokeRepeating函数3、使用Time.time4、使用Time.deltaTime5、使用DOTween。6、使用Vision Timer。 1、使用协程Coroutine public class Test : MonoBehaviour {// Start is called before the first frame updatevoid Start(){ …...
CSS文字描边,文字间隔,div自定义形状切割
clip-path: polygon( 0 0, 68% 0, 100% 32%, 100% 100%, 0 100% );//这里切割出来是少一角的正方形 letter-spacing: 1vw; //文字间隔 -webkit-text-stroke: 1px #fff; //文字描边1px uniapp微信小程序顶部导航栏设置透明,下拉改变透明度 onP…...

XWiki 服务没有正确部署在tomcat中,如何尝试手动重新部署?
1. 停止 Tomcat 服务 首先,您需要停止正在运行的 Tomcat 服务器,以确保在操作文件时不会发生冲突或数据损坏: sudo systemctl stop tomcat2. 清空 webapps 下的 xwiki 目录和 work 目录中相关的缓存 删除 webapps 下的 xwiki 目录和 work …...

【退役之重学Java】关于 Redis
一、Redis 都有哪些数据类型 String 最基本的类型,普通的set和get,做简单的kv缓存hash 这是一个类似map 的一种结构,这个一般可以将结构化的数据,比如一个对象(前提是这个对象没有嵌套其他的对象)给缓存在…...

Simple Comic:Mac平台的开源漫画阅读解决方案
Simple Comic:Mac平台的开源漫画阅读解决方案 【免费下载链接】Simple-Comic OS X comic viewer 项目地址: https://gitcode.com/gh_mirrors/si/Simple-Comic 你是否曾遇到这样的困扰:在Mac上尝试打开漫画文件时,不是格式不兼容就是阅…...
)
150元搞定无人机自主避障?上交大开源方案实测(附部署教程)
150元打造无人机自主避障系统:开源方案实战指南 当大多数人还在为动辄上万元的无人机避障系统望而却步时,一个仅需150元计算硬件的开源方案正在创客圈掀起风暴。这不是实验室里的概念验证,而是经过真实环境测试、能部署在你家后院的技术方案。…...
)
VINS-Mono跑EUROC数据集后,如何用evo工具包进行轨迹精度评估与可视化(附完整命令)
VINS-Mono轨迹精度评估实战:从EUROC数据集到evo工具包全流程解析 在完成VINS-Mono算法在EUROC数据集上的运行后,如何科学评估其轨迹精度成为算法优化和论文撰写的关键环节。本文将深入讲解使用evo工具包进行定量分析的完整流程,涵盖指标计算、…...

Pcap-Analyzer:Python可视化离线数据包分析工具全攻略
Pcap-Analyzer:Python可视化离线数据包分析工具全攻略 【免费下载链接】Pcap-Analyzer Python编写的可视化的离线数据包分析器 项目地址: https://gitcode.com/gh_mirrors/pc/Pcap-Analyzer 一、功能解析:数据包分析的瑞士军刀 1.1 核心功能图谱…...

如何高效获取六大网盘直链下载地址:开源工具的实用指南
如何高效获取六大网盘直链下载地址:开源工具的实用指南 【免费下载链接】baiduyun 油猴脚本 - 一个免费开源的网盘下载助手 项目地址: https://gitcode.com/gh_mirrors/ba/baiduyun 在当今数字时代,网盘已成为我们日常工作和学习中不可或缺的工具…...

Realistic Vision V5.1显存占用对比:启用offload前后VRAM峰值下降62%实测
Realistic Vision V5.1显存占用对比:启用offload前后VRAM峰值下降62%实测 1. 项目背景与技术特点 Realistic Vision V5.1是目前Stable Diffusion 1.5生态中最顶级的写实风格模型之一,能够生成媲美专业单反相机拍摄的人像作品。然而在实际使用中&#x…...

SeqGPT-560M代码补全能力展示:Python开发效率提升50%
SeqGPT-560M代码补全能力展示:Python开发效率提升50% 1. 引言 作为一名长期与代码打交道的开发者,我深知代码补全工具的重要性。好的补全工具不仅能减少敲击键盘的次数,更能帮助我们避免低级错误、保持编码思路的连贯性。最近体验了SeqGPT-…...

Dify工作流实战:用Agent节点串联多个MCP服务,让智能体同时操作数据库和外部工具
Dify工作流深度实战:用Agent节点构建多服务协同的智能体系统 在AI应用开发领域,Dify平台的工作流功能正在重新定义智能体的能力边界。不同于简单的单点工具调用,工作流允许开发者将多个MCP服务像乐高积木一样组合起来,创造出能够…...

3大核心突破!MAT图像修复技术全解析:从环境部署到实战应用
3大核心突破!MAT图像修复技术全解析:从环境部署到实战应用 【免费下载链接】MAT MAT: Mask-Aware Transformer for Large Hole Image Inpainting 项目地址: https://gitcode.com/gh_mirrors/ma/MAT MAT(Mask-Aware Transformer for La…...

汇川H5U PLC通过EtherNET/IP网关实现MODBUS RTU设备高效数据采集
1. 为什么需要EtherNET/IP网关连接MODBUS RTU设备 在工业自动化现场,经常会遇到这样的场景:主控系统使用的是支持EtherNET/IP协议的汇川H5U PLC,但现场大量传感器、仪表等设备仍然采用传统的MODBUS RTU协议(通过RS485接口通信&…...