CUDA专项
1、讲讲shared memory bank conflict的发生场景?以及你能想到哪些解决方案?
CUDA中的共享内存(Shared Memory)是GPU上的一种快速内存,通常用于在CUDA线程(Thread)之间共享数据。然而,当多个线程同时访问共享内存的不同位置时,可能会遇到bank conflict(银行冲突)的问题,这会导致性能下降。
Bank Conflict的发生场景
CUDA的共享内存被组织成多个bank,每个bank都可以独立地进行读写操作。然而,当多个线程访问同一个bank的不同地址时,这些访问会被串行化,导致性能下降。具体来说,bank conflict的发生场景如下:
- 同一warp中的线程访问同一个bank的不同地址:在CUDA中,线程被组织成warp(线程束),一个warp包含32个线程。如果这32个线程中的某些线程访问同一个bank的不同地址,就会发生bank conflict。
- 不规则的访问模式:如果线程访问共享内存的模式是不规则的,即线程访问的地址没有一定的规律,那么bank conflict的发生概率就会增加。
解决方案
- 合理的内存分配:通过合理的内存分配策略,将不同数据分配到不同的banks中,从而减少bank conflict的可能性。例如,可以使用CUDA提供的内存对齐工具来确保数据按照bank的大小进行对齐。
- 内存访问模式优化:通过优化线程的访存顺序和数据分布,使得不同线程访问的bank地址不重叠,从而避免bank conflict。例如,可以使用循环展开(Loop Unrolling)等技术来减少线程之间的内存访问冲突。
- 使用更多的共享内存:如果可能的话,可以增加共享内存的大小,从而减少每个bank的访问压力。但是需要注意的是,共享内存的大小是有限的,因此需要权衡性能和内存使用之间的平衡。
- 使用其他内存层次结构:除了共享内存之外,CUDA还提供了其他内存层次结构,如全局内存、常量内存和纹理内存等。在某些情况下,可以使用这些内存层次结构来替代共享内存,从而避免bank conflict的问题。
- 使用CUDA提供的内置函数:CUDA提供了一些内置函数来帮助程序员管理共享内存和避免bank conflict。例如,
__shfl_sync函数可以用于在warp内部进行数据的交换和广播,从而避免不必要的共享内存访问。 - 使用原子操作:如果必须让多个线程同时访问和修改同一个地址的数据,可以使用原子操作(Atomic Operations)来确保数据的一致性。但是需要注意的是,原子操作会引入额外的开销,并且可能会降低性能。
综上所述,避免CUDA共享内存bank conflict的关键在于合理的内存分配、内存访问模式优化以及使用CUDA提供的内置函数和工具。
2、CUDA里面如何分配GPU显存?为什么里面的参数是二级指针?
在CUDA中,GPU显存的分配主要通过使用特定的函数和内存管理策略来实现。以下是关于CUDA中显存分配的基本信息:
-
全局内存分配:全局内存是CUDA中最常用的一种显存分配方式。所有线程都可以访问和修改全局内存,它是通过
cudaMalloc函数在设备端(即GPU)上进行分配的。由于全局内存的分配是在主机端(即CPU)进行的,因此需要在主机端进行相应的内存管理。 -
为什么使用二级指针:
- 在CUDA编程中,当需要向函数(如
cudaMalloc)传递一个指针的地址,以便该函数可以修改这个指针的值(即分配的内存地址)时,就需要使用二级指针。这是因为一级指针(即普通的指针)在传递时只能传递指针本身的值(即它所指向的地址),而不能修改这个指针本身。而二级指针(即指向指针的指针)可以传递一个指针的地址,从而允许函数修改这个指针的值。 - 以
cudaMalloc为例,这个函数的目的是在GPU上分配内存,并将分配的内存地址存储在一个指针中。由于这个操作需要在GPU上进行,而函数的调用是在CPU上进行的,因此需要一个机制来将分配的内存地址从GPU传递回CPU。通过使用二级指针,cudaMalloc可以接收一个指向指针的指针(即二级指针),然后将分配的内存地址存储在这个二级指针所指向的一级指针中。这样,当cudaMalloc返回时,CPU就可以通过这个一级指针访问到在GPU上分配的内存了。
- 在CUDA编程中,当需要向函数(如
-
其他显存分配方式:除了全局内存外,CUDA还支持其他类型的显存分配方式,包括:
- 共享内存:一种位于GPU上的高速缓存,访问速度比全局内存快。它是在每个线程块(block)中共享的,同一线程块中的线程可以相互通信和共享数据。
- 常量内存:一种只读的内存,适用于在整个计算过程中不会被修改的数据。
- 纹理内存:一种特殊的内存,适用于对内存访问具有空间局部性的计算。
- 局部内存:一种在每个线程中私有的内存,用于存储线程私有的临时变量。
这些不同类型的内存具有不同的访问权限、生命周期和用途,可以根据具体的应用场景和需求来选择合适的内存类型。
3、优化CUDA程序的访存效率,你可以想到哪些?
化CUDA程序的访存效率是一个复杂而重要的任务,以下是一些建议的策略和方法:
-
优化内存访问:
- 重新组织数据布局:使数据访问更符合GPU的内存访问机制,减少内存访问延迟。
- 合并内存访问:通过合并多个内存访问请求,减少访问次数,提高内存访问效率。
- 利用缓存:通过合理的数据访问模式,尽可能利用GPU的L1和L2缓存,减少全局内存的访问。
-
减少线程同步开销:
- 优化算法设计,减少线程同步的次数,以提高GPU的并行计算效率。
- 使用原子操作(atomic operations)时,要谨慎,因为它们可能会引入额外的同步开销。
-
合理使用寄存器:
- 合理使用GPU的寄存器来存储临时数据,以减少数据传输延迟和内存访问开销。
- 避免过多的寄存器溢出,这会导致额外的内存访问和性能下降。
-
使用Pinned Memory:
- Pinned Memory(页锁定存储器)可以更快地在主机和设备之间传输数据。通过cudaHostAlloc函数分配Pinned Memory,并使用cudaHostRegister函数将已分配的变量转换为Pinned Memory。Pinned Memory允许实现主机和设备之间数据的异步传输,从而提高程序的整体性能。
-
全局内存访存优化:
- 分析数据流路径,确定是否使用了L1缓存,并据此确定当前内存访问的最小粒度(如32 Bytes或128 Bytes)。
- 分析原始数据存储的结构,结合访存粒度,确保数据访问的内存对齐和合并访问。
- 使用Nvprof或Nsight等工具来分析和优化全局内存的访问效率。
-
选择合适的CUDA版本和编译器选项:
- 根据GPU的型号和CUDA版本,选择最适合的编译器选项和内存访问模式。
- 关注CUDA的更新和改进,以利用新的功能和优化。
-
算法和代码优化:
- 优化算法和数据结构,减少不必要的计算和内存访问。
- 使用循环展开(loop unrolling)和向量化(vectorization)等技术来提高代码的执行效率。
- 避免在内核函数中使用复杂的条件语句和循环,以减少分支预测错误和同步开销。
-
内存管理优化:
- 使用内存池(memory pooling)技术来管理GPU内存,减少内存分配和释放的开销。
- 在必要时,使用零拷贝(zero-copy)技术来避免不必要的数据传输。
-
性能分析和调试:
- 使用CUDA的性能分析工具(如Nsight和Visual Profiler)来分析和识别性能瓶颈。
- 根据性能分析结果,针对瓶颈进行针对性的优化。
-
注意GPU的硬件特性:
- 了解GPU的硬件特性,如缓存大小、内存带宽和延迟等,以编写更高效的CUDA代码。
- 根据硬件特性选择合适的优化策略和方法。
通过综合应用以上策略和方法,可以有效地提高CUDA程序的访存效率,从而提升程序的整体性能。
4、优化CUDA程序的计算效率,你又可以想到哪些?
优化CUDA程序的计算效率是一个复杂但重要的任务,以下是一些可以考虑的优化策略:
- 优化内存访问:
- 重新组织数据布局,使得数据访问更符合GPU的内存访问机制,以减少内存访问延迟。
- 合并多个内存访问请求,以减少访问次数,提高内存访问效率。
- 尽量减少Host(CPU)和Device(GPU)之间的数据拷贝,通过优化算法和数据结构来减少数据传输的开销。
- 合理使用GPU资源:
- 在配置kernel时,分配合理的thread(线程)个数和block(线程块)个数,以最大化device的使用效率,充分利用硬件资源。
- 尽可能使用shared memory(共享内存)来存储需要频繁访问的数据,以减少对global memory(全局内存)的访问次数。
- 减少线程同步开销:
- 优化算法设计,减少线程同步的次数,以提高GPU的并行计算效率。
- 在同一个warp(线程束)中,尽量减少分支,以减少线程之间的分歧和同步开销。
- 优化算法和数据结构:
- 将串行代码并行化,特别是针对可以并行化的循环结构,如for循环。
- 使用更高效的数据结构和算法来减少计算量和内存使用。
- 注意数据类型和精度:
- 在可能的情况下,使用更小的数据类型来减少内存使用和传输开销。
- 注意浮点数的精度问题,避免不必要的精度损失和计算开销。
- 编译器优化:
- 使用合适的编译器选项和设置来优化代码生成和性能。
- 了解并使用CUDA编译器提供的性能分析工具来找出性能瓶颈和优化点。
- 硬件和驱动优化:
- 确保GPU驱动和硬件是最新的,以获得最佳的性能和兼容性。
- 根据具体的应用场景和硬件特性,调整CUDA程序的配置和参数设置。
- 使用CUDA提供的内置函数和库:
- CUDA提供了许多内置函数和库,如数学函数库、内存管理库等,这些函数和库经过优化,可以提供更高的性能。
- 代码审查和重构:
- 定期进行代码审查,找出潜在的性能问题和改进点。
- 对代码进行重构和优化,以提高代码的可读性、可维护性和性能。
- 测试和验证:
- 在不同的硬件和配置下测试CUDA程序的性能,确保优化策略的有效性。
- 使用验证数据集来验证CUDA程序的正确性和准确性。
请注意,优化CUDA程序的计算效率是一个持续的过程,需要不断地进行实验和调整。同时,不同的应用场景和硬件环境可能需要不同的优化策略。
1、GPU是如何与CPU协调工作的?
GPU与CPU的协调工作主要通过它们之间的接口和通信机制实现。具体而言,以下是它们协同工作的一般流程:
- 任务分配:CPU作为计算机系统的主要控制单元,负责将需要处理的任务分配给不同的处理器。当任务涉及大量的图形、图像处理或视频编码等计算密集型任务时,CPU会将这些任务分配给GPU处理。
- 数据传输:在任务分配后,CPU需要将相关的数据传输给GPU。这通常通过内存总线或专用接口(如PCIe总线)进行。数据传输的速度和带宽对于整个系统的性能至关重要,因为它们决定了GPU能够多快地获取所需的数据。
- 并行处理:GPU接收到数据后,会利用其大量的核心进行并行处理。GPU的核心数量远多于CPU,因此能够同时处理更多的任务和数据。这使得GPU在处理计算密集型任务时具有显著的优势。
- 结果回传:当GPU完成处理后,会将结果回传给CPU。CPU会对这些结果进行处理和整合,以便后续使用或输出。
在硬件层面,GPU和CPU的协调工作主要通过以下方式实现:
- 架构差异:CPU的架构通常是基于冯·诺依曼体系结构的,采用串行的方式执行指令,每个时钟周期只能执行一条指令。而GPU的架构通常是基于SIMD(单指令多数据流)的,采用并行的方式执行指令,每个时钟周期可以执行多条指令。这种架构差异使得GPU更适合处理计算密集型任务。
- 内存和缓存:GPU拥有独立的显存和缓存机制,用于存储和处理图形和图像数据。这些内存和缓存与CPU的内存和缓存是分开的,但可以通过内存总线或专用接口进行通信。在数据处理过程中,CPU和GPU会根据需要相互协作,将数据从主内存传输到显存或缓存中。
- 通信接口:CPU和GPU之间的通信主要通过PCIe总线等接口进行。这些接口提供了高速的数据传输通道,使得CPU和GPU能够快速地交换数据和指令。
在编程和开发层面,程序员可以通过特定的编程语言和库(如CUDA、OpenCL等)来利用GPU进行加速计算。这些库提供了丰富的API和工具,使得程序员能够轻松地编写和调试GPU程序,并将其与CPU程序进行集成和协同工作。
总之,GPU和CPU的协调工作是通过它们之间的接口、通信机制以及编程和开发层面的支持来实现的。这种协同工作使得计算机能够更高效地处理各种任务和数据,提高了整个系统的性能和效率。
2、GPU也有缓存机制吗?有几层?它们的速度差异多少?
GPU也有缓存机制,但通常主流GPU芯片上的缓存层数比CPU少。主流CPU芯片上有四级缓存,而主流GPU芯片最多有两层缓存。
关于GPU缓存的速度差异,一般来说,离处理器越近的缓存级别速度越快,但容量也越小。例如,L1缓存(一级缓存)的速度最快,但容量最小;L2缓存(二级缓存)的速度稍慢,但容量较大。这种设计是为了在速度和容量之间找到一个平衡,以便在处理数据时能够快速访问到所需的数据。
然而,具体的速度差异取决于具体的处理器和缓存设计。不同的GPU型号和制造商可能会使用不同的缓存设计和架构,因此它们之间的速度差异也会有所不同。
总的来说,GPU的缓存机制对于提高处理器的性能和效率非常重要,但具体的缓存层数和速度差异取决于处理器的设计和制造商的选择。
3、GPU的渲染流程有哪些阶段?它们的功能分别是什么?
- 顶点处理(Vertex Processing):
- 功能:此阶段主要负责处理输入的顶点数据,包括三维坐标(x, y, z)和其他顶点属性(如颜色、法线等)。通过顶点着色器(Vertex Shader)对这些顶点进行变换,将三维顶点坐标映射到二维屏幕坐标上,并计算各顶点的亮度值等。
- 特点:这个阶段是可编程的,允许开发者定义自己的顶点处理逻辑。输入与输出一一对应,即一个顶点被处理后仍然是一个顶点,各顶点间的处理相互独立,可以并行完成。
- 图元生成(Primitive Generation):
- 功能:根据应用程序定义的顶点拓扑逻辑(如三角形、线段等),将上阶段输出的顶点组织起来形成有序的图元流。这些图元记录了由哪些顶点组成,以及它们在输出流中的顺序。
- 图元处理(Primitive Processing):
- 功能:此阶段进一步处理图元,通常通过几何着色器(Geometry Shader)完成。几何着色器可以创建新的图元(例如,将点转换为线,或将线转换为三角形),也可以丢弃图元。这个阶段也是可编程的,允许开发者定义自己的图元处理逻辑。
- 光栅化(Rasterization):
- 功能:光栅化阶段将图元转换为像素(片段),并为每个像素生成一个片元记录。这些片元记录包含了像素在屏幕空间中的位置、与视点之间的距离以及通过插值获得的顶点属性等信息。
- 特点:这一阶段会对每一个图元在屏幕空间进行采样,每个采样点对应一个片元记录。
- 片元处理(Fragment Processing):
- 功能:在片元着色器(Fragment Shader)中,对每个片元进行颜色计算和纹理映射等操作。片元着色器会考虑各种因素(如光照、材质等),为每个片元计算出最终的颜色值。
- 屏幕映射(Screen Mapping):
- 功能:此阶段将处理后的片元信息映射到屏幕坐标系中,以便最终显示在屏幕上。
- 输出合并(Output Merging):
- 功能:在这一阶段,将片元着色器输出的颜色与屏幕上已有的颜色进行合并。这通常包括深度测试(确保物体按正确的顺序渲染)、模板测试(用于实现特殊效果,如阴影)和混合(用于实现透明效果)等操作。
需要注意的是,不同的GPU架构和渲染引擎可能会有一些细微的差别,但上述阶段和功能是GPU渲染流程中比较通用的部分。
4、Early-Z技术是什么?发生在哪个阶段?这个阶段还会发生什么?会产生什么问题?如何解决?
5、SIMD和SIMT是什么?它们的好处是什么?co-issue呢?
6、GPU是并行处理的么?若是,硬件层是如何设计和实现的?
7、GPC、TPC、SM是什么?Warp又是什么?它们和Core、Thread之间的关系如何?
8、顶点着色器(VS)和像素着色器(PS)可以是同一处理单元吗?为什么?
顶点着色器(VS)和像素着色器(PS)不是同一处理单元。尽管它们都是GPU中的可编程着色阶段,但它们各自执行不同的任务和具有不同的功能。
- 顶点着色器(VS)阶段处理输入汇编程序的顶点,执行每个顶点运算,例如转换、外观、变形和每顶点照明。顶点着色器始终在单个输入顶点上运行并生成单个输出顶点。它的主要任务是处理图形的顶点数据,进行坐标变换、光照计算等操作。
- 像素着色器(PS)阶段则支持丰富的着色技术,如每像素照明和后处理。像素着色器是一个程序,它将常变量、纹理数据、内插的每顶点值和其他数据组合起来以生成每像素输出。它的主要任务是对每个像素进行颜色计算和渲染,以实现更丰富的视觉效果。
由于顶点着色器和像素着色器在图形渲染过程中执行的任务不同,因此它们需要不同的处理单元来分别处理。在GPU中,通常会有多个顶点着色器和像素着色器的处理单元,以便能够并行处理多个顶点和像素的数据,提高渲染效率。
因此,顶点着色器和像素着色器不是同一处理单元,它们在图形渲染过程中各自扮演着不同的角色,协同工作以实现高效的图形渲染。
9、像素着色器(PS)的最小处理单位是1像素吗?为什么?会带来什么影响?
10、Shader中的if、for等语句会降低渲染效率吗?为什么?
相关文章:

CUDA专项
1、讲讲shared memory bank conflict的发生场景?以及你能想到哪些解决方案? CUDA中的共享内存(Shared Memory)是GPU上的一种快速内存,通常用于在CUDA线程(Thread)之间共享数据。然而࿰…...

C# 判断Access数据库中表是否存在,表中某个字段是否存在
在C#中判断Access数据库中某个表是否存在以及该表中某个字段是否存在,可以通过以下步骤实现: 判断表是否存在 可以使用ADO.NET中的OleDbConnection.GetOleDbSchemaTable方法来获取数据库的架构信息,并检查特定的表是否存在。 using System…...

【C++】学习笔记——模板进阶
文章目录 十一、模板进阶1. 非类型模板参数2. 按需实例化3. 模板的特化类模板的特化 4. 模板的分离编译 未完待续 十一、模板进阶 1. 非类型模板参数 模板参数分为类型形参和非类型形参 。类型形参即:出现在模板参数列表中,跟在class或者typename之类的…...
JAVA系列 小白入门参考资料 接口
目录 接口 接口的概念 语法 接口使用 接口实现用例 接口特性 实现多个接口和实现用例 接口间的继承 接口 接口的概念 在现实生活中,接口的例子比比皆是,比如:笔记本上的 USB 口,电源插座等。 电脑的 USB 口上&am…...

日报表定时任务优化历程
报表需求背景 报表是一个很常见的需求,在项目中后期往往会需要加多种维度的一些统计信息,今天就来谈谈上线近10个月后的一次报表优化优化之路(从一天报表跑需要五分钟,优化至秒级) 需求:对代理商进行日统计…...
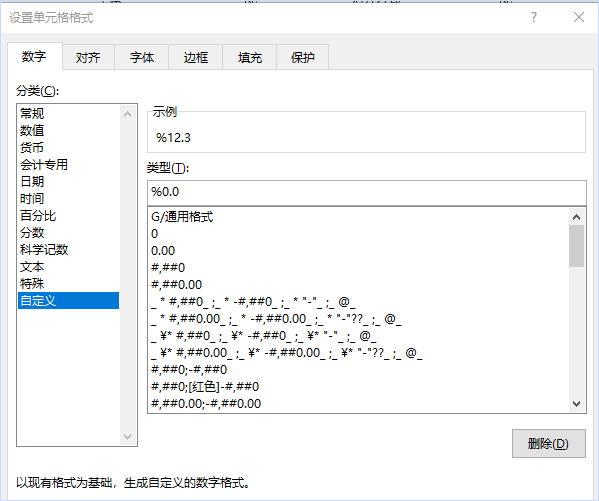
excel表格里,可以把百分号放在数字前面吗?
在有些版本里是可以的,这样做: 选中数据,鼠标右键,点击设置单元格格式,切换到自定义,在右侧栏输入%0,点击确定就可以了。 这样设置的好处是,它仍旧是数值,并且数值大小没…...

应用案例 | 商业电气承包商借助Softing NetXpert XG2节省网络验证时间
一家提供全方位服务的电气承包商通过使用Softing NetXpert XG2顺利完成了此次工作任务——简化了故障排查的同时,还在很大程度上减少了不必要的售后回访。 对已经安装好的光纤或铜缆以太网网络进行认证测试可能会面临不同的挑战,这具体取决于网络的规模、…...
【JAVA语言-第20话】多线程详细解析(二)——线程安全,非线程安全的集合转换成线程安全
目录 线程安全 1.1 概述 1.2 案例分析 1.3 解决线程安全问题 1.3.1 使用synchronized关键字 1.3.1.1 同步代码块 1.3.1.2 同步方法 1.3.2 使用Lock锁 1.3.2.1 概述 代码示例: 1.4 线程安全的类 1.4.1 非线程安全集合转换成线程安全集合 1.5 总结 …...

区块链中的加密算法及其作用
区块链技术以其去中心化、不可篡改、透明公开的特性,在全球范围内引发了广泛的关注和讨论。其中,加密算法作为区块链技术的核心组成部分,对于维护区块链网络的安全、确保数据的完整性和真实性起到了至关重要的作用。本文将详细介绍区块链中常…...

微信小程序跳转微信管理平台配置的客服及意见页面
<button open-type"contact" bindcontact"handleContact" session-from"sessionFrom">帮助与客服</button> 不需要路径 在当前小程序中会自动进入 open-type"contact" 其他参数不用修改 只修改这个参数对应表单组件 /…...
灌溉机器人 状压dp
灌溉机器人 题目描述 农田灌溉是一项十分费体力的农活,特别是大型的农田。小明想为农民伯伯们减轻农作负担,最近在研究一款高科技——灌溉机器人。它可以在远程电脑控制下,给农田里的作物进行灌溉。 现在有一片 N 行 M 列的农田。农田的土…...

用于接收参数的几个注解
了解四种主要请求方法的传参格式 GET方法: 参数通常通过URL的查询字符串(query string)传递,形式为key1value1&key2value2。示例:http://example.com/api/resource?key1value1&key2value2 POST方法…...

Flask-Login 实现用户认证
Flask-Login 实现用户认证 Flask-Login 是什么 Flask-Login 是 Flask 中的一个第三方库,用于处理用户认证和管理用户会话,它提供了一组工具和功能,使得在 Flask 应用程序中实现用户认证变得更加简单和方便。 如何使用 Flask-Login 1.安装…...
基于WPF的DynamicDataDisplay曲线显示
一、DynamicDataDisplay下载和引用 1.新建项目,下载DynamicDataDisplay引用: 如下图: 二、前端开发: <Border Grid.Row"0" Grid.Column"2" BorderBrush"Purple" BorderThickness"1"…...

股票问题(至多两次购买
class Solution {public int maxProfit(int[] prices) {int[] dpnew int[4];dp[0]-prices[0];//第一次持有dp[1]0;dp[2]-prices[0];//第二次持有dp[3]0;for(int i1;i<prices.length;i){dp[0]Math.max(dp[0],-prices[i]);dp[1]Math.max(dp[1],dp[0]prices[i]);dp[2]Math.max(…...

车辆运动模型中LQR代码实现
一、前言 最近看到关于架构和算法两者关系的一个描述,我觉得非常认同,分享给大家。 1、好架构起到两个作用:合理的分解功能、合理的适配算法; 2、好的架构是好的功能的必要条件,不是充分条件,一味追求架构…...

Springboot集成feign远程调用
需求:在leadnews-wemedia微服务里需要调用leadnews-article微服务的接口。新建一个支持feign调用的名为heima-leadnews-feign-api的模块 heima-leadnews-feign-api的pom文件里导入openfeign依赖 <dependency><groupId>org.springframework.cloud</g…...

构建NFS远程共享存储
nfs-server:10.1.59.237 nfs-web:10..159.218 centos7,服务端和客户端都关闭防火墙和selinux内核防火墙,如果公司要求开启防火墙,那需要放行几个端口 firewall-cmd --add-port2049/tcp --permanent firewall-cmd --add-port111/tcp --permanent firew…...
X9C103SIZT1 数字电位计 IC 10K SOIC-8 参数 应用案例
X9C103SIZT1 是一款数字电位器,属于 X9C103 系列。它是一款100抽头的非易失性数字电位器,阻值为 10 kOhm,封装形式为 SOIC-8。这款器件常用于需要调整电子设备阻值的应用中,如音频设备、电源管理以及传感器校准等。 X9C103SIZT1 的…...
redis深入理解之数据存储
1、redis为什么快 1)Redis是单线程执行,在执行时顺序执行 redis单线程主要是指Redis的网络IO和键值对读写是由一个线程来完成的,Redis在处理客户端的请求时包括获取(socket 读)、解析、执行、内容返回 (socket 写)等都由一个顺序串行的主线…...

InternLM2-Chat-1.8B多场景落地:跨境电商产品描述生成+多语言翻译实战
InternLM2-Chat-1.8B多场景落地:跨境电商产品描述生成多语言翻译实战 1. 跨境电商的痛点与AI解决方案 跨境电商卖家每天面临着一个共同的挑战:如何为成千上万的商品快速生成高质量的产品描述,并且还要满足不同语言市场的需求。传统的人工撰…...

Java 物联网无人健身房设备联动与计费系统源码
以下是一个基于Java的物联网无人健身房设备联动与计费系统的源码实现框架,涵盖核心模块、技术细节及优化策略:一、系统架构分层架构:表现层:使用UniApp实现三端适配(微信小程序、H5、APP),管理后…...

Java 使用国密算法实现数据加密传输
本文是混合加密:前端 SM2 SM4,后端 Spring Boot Hutool 解密的完整示例。 方案的逻辑是: 前端随机生成一个 SM4 key 用 SM4 加密整个业务 JSON 用后端提供的 SM2 公钥 加密这个 SM4 key 后端先用 SM2 私钥 解出 SM4 key 再用 SM4 解出…...

FFTW实战指南:从编译优化到音频信号处理
1. FFTW库简介与核心优势 FFTW(Fastest Fourier Transform in the West)是当前公认性能最优异的快速傅里叶变换开源库,其名称直译为"西方最快的傅里叶变换"。我在音频信号处理项目中首次接触这个库时,就被它惊人的运算…...

ESP32-IDF开发实战:内置JTAG与OpenOCD高效调试指南
1. 为什么选择ESP32内置JTAG调试? 第一次接触ESP32开发时,你可能会有疑问:市面上这么多调试工具,为什么非要折腾内置JTAG?我刚开始用串口打印调试信息,后来发现这种方法在排查复杂逻辑时效率太低。直到尝试…...
)
QT实战:用QChartView快速打造动态折线图(附完整代码)
QT实战:用QChartView快速打造动态折线图(附完整代码) 在数据可视化领域,动态折线图因其直观展示数据变化趋势的能力,成为监控系统、金融分析、工业控制等场景的标配。QT框架提供的QChartView组件,让开发者能…...

手把手教你排查PCIe设备异常:从`Malformed TLP`错误看MPS/MRRS配置
深度解析PCIe设备异常:从Malformed TLP错误到MPS/MRRS调优实战 当你在嵌入式Linux系统中接入一块高性能FPGA加速卡时,突然在系统日志中发现Malformed TLP错误,设备性能骤降甚至完全无法工作——这种场景对任何嵌入式开发者都不陌生。PCIe总线…...

AIGlasses_for_navigation 开发环境快速配置:Anaconda虚拟环境指南
AIGlasses_for_navigation 开发环境快速配置:Anaconda虚拟环境指南 你是不是也遇到过这种情况:好不容易在本地跑通了一个项目,换台电脑或者更新了几个库,结果就报了一堆莫名其妙的错误。或者,你想同时维护两个需要不同…...

避坑指南:RuoYi-Vue2集成Flowable 6.7.2时,关于database-schema-update和nullCatalogMeansCurrent的配置详解
深度解析:RuoYi-Vue2集成Flowable 6.7.2的数据库配置陷阱与实战策略 当企业级应用需要引入工作流引擎时,Flowable因其轻量化和高性能成为许多开发团队的首选。然而在RuoYi-Vue2框架中集成Flowable 6.7.2版本时,数据库配置环节往往成为开发者的…...

Hunyuan-MT-7B效果展示:学术论文摘要英→中翻译在专业术语一致性表现
Hunyuan-MT-7B效果展示:学术论文摘要英→中翻译在专业术语一致性表现 1. 引言:专业翻译的技术挑战 学术论文翻译一直是机器翻译领域的难点,特别是专业术语的一致性保持。传统翻译工具在处理学术文献时,经常出现术语翻译不统一、…...