推荐算法详解
文章目录
- 推荐算法引言
- 基于内容的推荐
- 原理
- 算法步骤
- 注意点
- 可以优化的地方
- 示例
- 代码讲解
- 协同过滤推荐
- 原理
- 算法步骤
- 注意点
- 可以优化的地方
- 示例
- 代码讲解
- 混合推荐系统
- 原理
- 算法步骤
- 注意点
- 可以优化的地方
- 示例1
- 代码讲解1
- 示例2
- 代码讲解2
- 基于知识的推荐
- 原理
- 算法步骤
- 注意点
- 可以优化的地方
- 示例
- 代码讲解
- 基于模型的推荐
- 原理
- 算法步骤
- 注意点
- 可以优化的地方
- 示例
- 代码讲解
- 多臂老虎机
- 原理
- 算法步骤
- 注意点
- 可以优化的地方
- 示例
- 示例背景
- 代码实现
- 代码讲解
推荐算法引言
推荐算法是信息检索领域的一种技术,它旨在预测用户对物品(如商品、电影、新闻等)的偏好,并据此向用户推荐他们可能感兴趣的内容。随着大数据和机器学习技术的发展,推荐算法在电子商务、社交媒体、在线视频和音乐服务等多个领域得到了广泛应用。
-
基于内容的推荐 (Content-Based Recommendation)
- 这种方法根据用户过去喜欢的物品的特征,推荐具有相似特征的新物品。它侧重于物品的属性,如文本、关键词、描述等。
-
协同过滤推荐 (Collaborative Filtering, CF)
- 协同过滤推荐分为两种:用户基于的(User-based)和物品基于的(Item-based)。
- 用户基于的CF:通过查找与目标用户有相似喜好的其他用户,推荐这些相似用户喜欢的物品。
- 物品基于的CF:通过分析用户对物品的评分模式,找出相似的物品,然后推荐给用户。
-
混合推荐系统 (Hybrid Recommendation Systems)
- 结合多种推荐方法,如内容推荐和协同过滤推荐,以提高推荐的准确性和覆盖率。
-
基于知识的推荐 (Knowledge-Based Recommendation)
- 利用专家系统和语义技术,理解用户需求和物品特性,进行推荐。
-
基于模型的推荐 (Model-based Recommendation)
- 使用机器学习模型,如随机决策森林、支持向量机(SVM)、神经网络等,从用户行为数据中学习推荐模型。
-
深度学习推荐 (Deep Learning Recommendation)
- 利用深度学习技术,如卷积神经网络(CNN)和循环神经网络(RNN),处理复杂的非线性关系和高维数据。
-
基于图的推荐 (Graph-based Recommendation)
- 利用图结构来表示用户和物品之间的关系,通过图算法发现推荐。
-
基于时间序列的推荐 (Time-Series Based Recommendation)
- 考虑用户行为随时间的变化,预测用户未来的兴趣点。
-
基于上下文的推荐 (Context-Aware Recommendation)
- 根据用户当前的上下文环境(如位置、时间、设备等)进行推荐。
-
强化学习推荐 (Reinforcement Learning Based Recommendation)
- 使用强化学习来优化推荐策略,通过与环境的交互学习最佳推荐动作。
-
多臂老虎机 (Multi-Armed Bandit)
- 一种权衡探索(Exploration)和利用(Exploitation)的推荐策略,用于在线推荐系统中。
-
序列推荐 (Sequential Recommendation)
- 考虑用户行为序列,如观看视频或听歌的顺序,推荐下一个可能感兴趣的物品。
推荐算法的设计和选择取决于多种因素,包括数据的可用性、推荐系统的目标、用户的偏好变化速度以及系统的实时性要求。随着技术的不断进步,新的推荐算法和模型仍在持续发展中。
基于内容的推荐
基于内容的推荐算法(Content-based Recommendation)是推荐系统的一种,它通过分析物品的内容特征,然后根据用户过去的喜好记录,推荐与用户喜好相似的物品。这种方法的核心思想是,如果一个用户过去喜欢某个物品,那么与他过去喜欢的物品在内容上相似的其他物品,用户很可能也会喜欢。
原理
基于内容的推荐算法依赖于物品的属性描述。每个物品被表示为一个特征向量,这些特征可能包括文本描述、元数据或任何其他可以量化的属性。用户的历史偏好也被转换成相似的特征向量。然后,算法通过计算用户特征向量与物品特征向量之间的相似度来推荐物品。
算法步骤
- 物品特征表示:将每个物品表示为一个特征向量。例如,对于电影,特征可能包括导演、演员、类型、评分等。
- 用户档案构建:根据用户的历史行为,构建用户喜好特征向量。这通常涉及到对用户评分或选择过的物品的特征进行加权平均。
- 相似度计算:计算用户特征向量与物品特征向量之间的相似度。常用的相似度度量方法有余弦相似度、欧氏距离等。
- 推荐生成:根据相似度排序,选择最相似的物品作为推荐结果。
注意点
- 特征质量:推荐系统的质量很大程度上取决于特征的选择和表示。不好的特征选择可能导致无效的推荐。
- 冷启动问题:对于新用户或新物品,由于缺乏足够的信息,基于内容的推荐可能效果不佳。
- 过拟合:如果特征过多或权重调整不当,可能导致模型在训练数据上表现良好,但在新数据上表现不佳。
可以优化的地方
- 特征工程:通过深入分析数据,选择更有信息量的特征,可以提高推荐质量。
- 动态调整:根据用户反馈动态调整推荐,可以更好地适应用户的变化。
- 混合推荐系统:将基于内容的推荐与其他推荐方法(如协同过滤)结合,可以弥补各自的不足。
示例
下面是一个简单的Python代码示例,用于实现基于内容的推荐系统:
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 假设我们有以下电影特征向量
movies = {'Movie1': {'Director': 1, 'Actor': 0.5, 'Genre': 'Action'},'Movie2': {'Director': 0, 'Actor': 1, 'Genre': 'Drama'},'Movie3': {'Director': 1, 'Actor': 0, 'Genre': 'Comedy'},
}
# 将电影特征转换为数值向量
def feature_vector(movie):director = 1 if movie['Director'] == 1 else 0actor = movie['Actor']genre = 1 if movie['Genre'] == 'Action' else 0return [director, actor, genre]
# 转换所有电影特征
movie_vectors = [feature_vector(movie) for movie in movies.values()]
# 假设用户喜欢动作片
user_profile = [1, 0, 1]
# 计算用户档案与电影特征向量之间的余弦相似度
similarities = cosine_similarity([user_profile], movie_vectors)
# 排序相似度并获取推荐的电影
movie_indices = np.argsort(-similarities)[0]
recommended_movies = [list(movies.keys())[i] for i in movie_indices]
print(recommended_movies)
代码讲解
- 特征向量转换:将电影的文本特征转换为数值形式,便于计算相似度。
- 余弦相似度计算:使用
cosine_similarity函数计算用户特征向量与电影特征向量之间的相似度。 - 推荐生成:根据相似度排序,获取最相似的movie_indices,然后映射回电影名称,得到推荐列表。
这个示例非常简化,实际应用中,特征工程会更复杂,且通常会使用更高级的机器学习模型来提高推荐准确性。
协同过滤推荐
协同过滤推荐算法(Collaborative Filtering)是推荐系统中的一种常用技术,它主要通过分析用户之间的行为和偏好来进行推荐。协同过滤不需要物品的内容信息,而是通过收集用户对物品的评价信息(如评分、点击等)来发现用户之间的相似性或物品之间的相似性,进而基于这些相似性做出推荐。
原理
协同过滤基于这样一个假设:用户倾向于喜欢与他们有相似喜好的其他用户喜欢的物品。协同过滤主要分为两类:
- 用户基于的协同过滤(User-based):通过分析用户之间的相似度,找到与目标用户相似的用户群体,然后推荐这些相似用户喜欢的物品给目标用户。
- 物品基于的协同过滤(Item-based):通过分析物品之间的相似度,为用户推荐与他们过去喜欢的物品相似的物品。
算法步骤
以用户基于的协同过滤为例:
- 收集数据:收集用户对物品的评价数据,如评分矩阵。
- 计算相似度:计算用户之间的相似度,常用的方法有余弦相似度、皮尔逊相关系数等。
- 找出邻居用户:根据相似度找出目标用户的邻居用户,即最相似的几个用户。
- 生成推荐:根据邻居用户的喜好,预测目标用户对未评价物品的喜好,并推荐评分最高的物品。
注意点
- 数据稀疏性:用户和物品的数量可能非常大,导致评分矩阵非常稀疏,这会影响推荐的准确性。
- 冷启动问题:对于新用户或新物品,由于缺乏足够的评价数据,协同过滤难以生成有效的推荐。
- 算法扩展性:随着用户和物品数量的增加,算法的计算复杂度也会增加,需要考虑算法的扩展性。
可以优化的地方
- 矩阵分解(MF):使用矩阵分解技术来降低数据维度,提高推荐准确性,并减少计算量。
- 混合推荐:将协同过滤与其他推荐技术(如基于内容的推荐)结合,以弥补各自的不足。
- 增量学习:随着新数据的不断产生,使用增量学习更新模型,以适应数据的变化。
示例
下面是一个简单的Python代码示例,使用Surprise库实现基于用户的协同过滤推荐系统:
from surprise import KNNWithMeans
from surprise import Dataset
from surprise import Reader
from surprise.model_selection import train_test_split
# 假设我们有以下用户对电影的评分数据
ratings = [{'user': 'A', 'item': 'Movie1', 'rating': 5},{'user': 'A', 'item': 'Movie2', 'rating': 3},{'user': 'B', 'item': 'Movie1', 'rating': 4},{'user': 'B', 'item': 'Movie3', 'rating': 5},{'user': 'C', 'item': 'Movie2', 'rating': 2},{'user': 'C', 'item': 'Movie3', 'rating': 4},
]
# 将评分数据转换为Surprise库需要的格式
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(pd.DataFrame(ratings), reader)
# 划分训练集和测试集
trainset, testset = train_test_split(data, test_size=0.25)
# 使用KNNWithMeans算法进行训练
algo = KNNWithMeans(k=2, sim_options={'name': 'pearson_baseline', 'user_based': True})
algo.fit(trainset)
# 为用户A推荐一个电影
user_inner_id = algo.trainset.to_inner_uid('A')
predictions = algo.get_recommendations(user_inner_id, 1)
predicted_movie = algo.trainset.to_raw_iid(predictions[0][0])
print(f"为用户A推荐的电影是: {predicted_movie}")
代码讲解
- 数据准备:首先,我们将用户对电影的评分数据转换为Pandas DataFrame,然后使用Surprise的Reader类将其转换为Surprise库需要的格式。
- 训练测试集划分:使用
train_test_split函数将数据集划分为训练集和测试集。 - 模型训练:使用
KNNWithMeans算法进行训练,这里我们设置了user_based为True,表示我们使用基于用户的协同过滤。 - 生成推荐:使用
get_recommendations函数为用户A生成一个推荐,这里我们请求推荐一个物品。
这个示例非常简化,实际应用中,协同过滤推荐系统会更加复杂,需要处理的数据量也会更大。此外,Surprise库提供了许多参数和算法供我们选择和调整,以适应不同的推荐场景。
混合推荐系统
混合推荐系统(Hybrid Recommendation System)是将多种推荐技术结合在一起的系统,目的是结合不同推荐技术的优势,以克服单一推荐技术的局限性。混合推荐系统可以提高推荐的准确性、覆盖率和鲁棒性。
原理
混合推荐系统可以通过多种方式结合不同的推荐技术:
- 加权混合:将不同推荐系统的输出进行加权组合,权重可以根据实际情况调整。
- 切换混合:根据不同的情况选择不同的推荐系统。
- 特征混合:将不同推荐系统的特征向量进行组合,然后输入到机器学习模型中进行训练。
- 层叠混合:一个推荐系统的输出作为另一个推荐系统的输入。
算法步骤
以加权混合为例:
- 选择推荐系统:选择要结合的推荐系统,如基于内容的推荐、协同过滤等。
- 独立训练:分别训练每个推荐系统。
- 生成推荐:使用每个推荐系统生成推荐列表。
- 加权合并:根据预定的权重合并推荐列表,生成最终的推荐结果。
注意点
- 权重选择:权重的选择对推荐结果有很大影响,需要通过实验和数据分析来确定最佳权重。
- 系统复杂度:混合推荐系统通常比单一推荐系统更复杂,需要更多的计算资源和维护工作。
- 数据一致性:不同推荐系统可能需要不同的数据格式和预处理步骤,需要确保数据的一致性。
可以优化的地方
- 自动化权重调整:使用机器学习算法自动调整权重,以适应数据的变化。
- 集成学习:使用集成学习技术,如堆叠(Stacking)或提升(Boosting),来提高推荐的准确性。
- 实时反馈:结合实时用户反馈来调整推荐结果,以提高推荐的实时性和个性化。
示例1
下面是一个简单的Python代码示例,使用Surprise库实现一个加权混合推荐系统:
from surprise import SVD, KNNWithMeans
from surprise import Dataset
from surprise import Reader
from surprise.model_selection import train_test_split
# 假设我们有以下用户对电影的评分数据
ratings = [{'user': 'A', 'item': 'Movie1', 'rating': 5},{'user': 'A', 'item': 'Movie2', 'rating': 3},{'user': 'B', 'item': 'Movie1', 'rating': 4},{'user': 'B', 'item': 'Movie3', 'rating': 5},{'user': 'C', 'item': 'Movie2', 'rating': 2},{'user': 'C', 'item': 'Movie3', 'rating': 4},
]
# 将评分数据转换为Surprise库需要的格式
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(pd.DataFrame(ratings), reader)
# 划分训练集和测试集
trainset, testset = train_test_split(data, test_size=0.25)
# 训练SVD算法
algo_svd = SVD()
algo_svd.fit(trainset)
# 训练KNNWithMeans算法
algo_knn = KNNWithMeans()
algo_knn.fit(trainset)
# 为用户A生成推荐
user_inner_id = algo_svd.trainset.to_inner_uid('A')
# 使用SVD算法生成推荐
svd_recommendations = algo_svd.get_recommendations(user_inner_id, 1)
svd_predicted_movie = algo_svd.trainset.to_raw_iid(svd_recommendations[0][0])
# 使用KNNWithMeans算法生成推荐
knn_recommendations = algo_knn.get_recommendations(user_inner_id, 1)
knn_predicted_movie = algo_knn.trainset.to_raw_iid(knn_recommendations[0][0])
# 加权合并推荐结果
final_recommendation = (svd_predicted_movie, knn_predicted_movie)
print(f"为用户A推荐的混合推荐结果是: {final_recommendation}")
代码讲解1
- 数据准备:首先,我们将用户对电影的评分数据转换为Pandas DataFrame,然后使用Surprise的Reader类将其转换为Surprise库需要的格式。
- 训练测试集划分:使用
train_test_split函数将数据集划分为训练集和测试集。 - 模型训练:分别训练SVD和KNNWithMeans算法。
- 生成推荐:使用每个算法生成推荐列表。
- 加权合并:在这个简单的示例中,我们没有加权合并推荐结果,而是简单地将两个推荐结果并列展示。在实际应用中,可以根据算法的性能或用户偏好来设定权重,并进行加权合并。
这个示例非常简化,实际应用中,混合推荐系统会更加复杂,需要处理的数据量也会更大。此外,Surprise库提供了许多参数和算法供我们选择和调整,以适应不同的场景。
混合推荐系统的示例和代码讲解:
示例2
在实际应用中,我们可能会使用更复杂的方法来合并推荐结果。例如,我们可以根据每个算法在测试集上的表现来分配权重。以下是一个如何实现加权合并的示例:
# 假设我们已经有了SVD和KNN算法的推荐结果
svd_recommendations = algo_svd.test(testset)
knn_recommendations = algo_knn.test(testset)
# 假设我们根据测试集的表现决定权重
# 例如,SVD的RMSE是1.0,KNN的RMSE是1.2,我们可能会给SVD更高的权重
weight_svd = 1.0 / 1.0
weight_knn = 1.0 / 1.2
# 加权合并推荐结果
weighted_svd_recommendations = [(iid, score * weight_svd) for uid, iid, score, _ in svd_recommendations]
weighted_knn_recommendations = [(iid, score * weight_knn) for uid, iid, score, _ in knn_recommendations]
# 合并推荐列表
all_recommendations = weighted_svd_recommendations + weighted_knn_recommendations
# 根据合并后的分数对推荐进行排序
all_recommendations.sort(key=lambda x: x[2], reverse=True)
# 获取前N个推荐
final_recommendations = all_recommendations[:10]
print(f"为用户A推荐的加权混合推荐结果是: {final_recommendations}")
代码讲解2
- 测试集评估:我们使用测试集来评估SVD和KNN算法的性能。这通常通过计算均方根误差(RMSE)或其他指标来完成。
- 权重分配:根据每个算法在测试集上的表现来分配权重。在这个例子中,我们假设SVD的表现比KNN好,因此给它更高的权重。
- 加权合并:我们将每个推荐结果的分数乘以其对应的权重,以得到加权分数。
- 排序和选择:我们将所有推荐结果合并到一个列表中,并根据加权分数进行排序。然后我们选择前N个推荐作为最终的推荐结果。
这个示例展示了如何将不同算法的推荐结果进行加权合并。在实际应用中,权重的选择可能会更加复杂,可能需要考虑多种因素,如算法性能、用户反馈、业务目标等。此外,权重的确定可能需要通过交叉验证和其他模型评估技术来进行。
混合推荐系统的关键在于如何有效地结合不同推荐技术的优势,以提供更加准确和个性化的推荐。这通常需要大量的实验和调优,以确保系统在不同场景下的表现都是最佳的。
基于知识的推荐
基于知识的推荐算法(Knowledge-based Recommendation)是一种依赖于领域知识和逻辑推理的推荐方法。它不依赖于用户的历史行为或物品的属性,而是基于一系列预先定义的规则或约束来生成推荐。这种方法特别适用于那些用户很少、物品很多且具有复杂关系的场景,如医疗、旅游规划等。
原理
基于知识的推荐算法使用领域专家提供的知识,通过推理引擎来生成推荐。这些知识通常以规则的形式存在,例如“如果用户有高血压,则不推荐含咖啡因的饮料”。算法会根据这些规则和用户的具体情况来生成推荐。
算法步骤
- 定义规则:与领域专家合作,定义一系列推荐规则。
- 收集用户信息:收集用户的背景信息、偏好、需求等。
- 推理:使用推理引擎(如专家系统、逻辑编程等)根据规则和用户信息进行推理。
- 生成推荐:根据推理结果生成推荐列表。
注意点
- 规则质量:推荐系统的质量很大程度上取决于规则的准确性和完整性。
- 冷启动问题:由于不依赖于用户的历史行为,基于知识的推荐算法在一定程度上可以缓解冷启动问题。
- 可扩展性:随着规则数量的增加,系统的管理和维护可能会变得复杂。
可以优化的地方
- 自动化规则学习:使用机器学习算法自动从数据中学习规则,以提高推荐的准确性。
- 用户反馈整合:结合用户反馈来调整规则,以适应用户的变化。
- 混合推荐系统:将基于知识的推荐与其他推荐技术(如协同过滤)结合,以提供更全面的推荐。
示例
下面是一个简单的Python代码示例,用于实现一个基于知识的推荐系统:
class KnowledgeBasedRecommender:def __init__(self, rules):self.rules = rulesdef recommend(self, user_info):recommendations = []for item in items:if self._is_recommended(item, user_info):recommendations.append(item)return recommendationsdef _is_recommended(self, item, user_info):for rule in self.rules:if rule['condition'](user_info) and not rule['exclusion'](item):return Truereturn False
# 定义规则
rules = [{'condition': lambda user: user['age'] > 18, 'exclusion': lambda item: item['age_restriction'] == 'adult'},{'condition': lambda user: user['allergies'].includes('nuts'), 'exclusion': lambda item: item['ingredients'].includes('nuts')},
]
# 创建推荐系统实例
recommender = KnowledgeBasedRecommender(rules)
# 假设我们有以下用户和物品信息
user_info = {'age': 25, 'allergies': ['nuts']}
items = [{'name': 'Item1', 'age_restriction': 'teen', 'ingredients': ['nuts']},{'name': 'Item2', 'age_restriction': 'adult', 'ingredients': []},{'name': 'Item3', 'age_restriction': 'teen', 'ingredients': []},
]
# 生成推荐
recommendations = recommender.recommend(user_info)
print(f"为该用户推荐的结果是: {recommendations}")
代码讲解
- 规则定义:我们定义了一个规则列表,每个规则包含一个条件和一个排除条件。
- 推荐类:
KnowledgeBasedRecommender类接受规则列表并实现推荐方法。 - 推荐方法:
recommend方法接受用户信息,并遍历所有物品,使用_is_recommended方法检查每个物品是否被推荐。 - 推荐检查:
_is_recommended方法根据规则检查物品是否适合用户。如果所有规则的条件都满足且没有排除条件被触发,则物品被推荐。 - 生成推荐:我们创建了一个推荐系统实例,并提供了用户信息和物品列表。然后调用
recommend方法生成推荐列表。
这个示例非常简化,实际应用中,基于知识的推荐系统会更加复杂,规则的数量和复杂性会更高,并且可能需要结合专业的领域知识。此外,在实际应用中,可能需要使用更强大的推理引擎来处理复杂的逻辑和规则。
基于模型的推荐
基于模型的推荐系统(Model-based Recommendation)是利用机器学习算法来预测用户对物品的喜好。这种推荐系统通常将推荐问题视为一个评分预测问题,即预测用户对未评分物品的可能评分,然后根据这些预测评分来推荐物品。
原理
基于模型的推荐系统使用用户的历史评分数据来训练一个预测模型,这个模型能够预测用户对未知物品的评分。常用的模型包括矩阵分解(Matrix Factorization)、聚类算法、深度学习模型等。模型通常尝试捕捉用户和物品之间的潜在因素,这些因素可以解释用户的行为和偏好。
算法步骤
- 数据准备:收集用户对物品的评分数据,构建用户-物品评分矩阵。
- 模型选择:选择一个或多个机器学习模型来训练推荐系统。
- 模型训练:使用用户的历史评分数据来训练模型。
- 预测评分:使用训练好的模型来预测用户对未知物品的评分。
- 生成推荐:根据预测评分生成推荐列表。
注意点
- 模型选择:选择合适的模型对推荐系统的性能有很大影响。
- 过拟合风险:复杂的模型可能会导致过拟合,即模型在训练数据上表现良好,但在未见过的新数据上表现不佳。
- 冷启动问题:对于新用户或新物品,由于缺乏足够的评分数据,基于模型的推荐系统可能难以生成有效的推荐。
可以优化的地方
- 特征工程:通过深入分析数据,选择更有信息量的特征,可以提高推荐质量。
- 模型融合:使用多个模型进行预测,并通过加权或堆叠(Stacking)方法结合它们的预测结果。
- 实时反馈:结合实时用户反馈来调整模型,以提高推荐的实时性和个性化。
示例
下面是一个使用Python的Surprise库实现基于模型的推荐系统的示例:
from surprise import SVD
from surprise import Dataset
from surprise import Reader
from surprise.model_selection import train_test_split
# 假设我们有以下用户对电影的评分数据
ratings = [{'user': 'A', 'item': 'Movie1', 'rating': 5},{'user': 'A', 'item': 'Movie2', 'rating': 3},{'user': 'B', 'item': 'Movie1', 'rating': 4},{'user': 'B', 'item': 'Movie3', 'rating': 5},{'user': 'C', 'item': 'Movie2', 'rating': 2},{'user': 'C', 'item': 'Movie3', 'rating': 4},
]
# 将评分数据转换为Surprise库需要的格式
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(pd.DataFrame(ratings), reader)
# 划分训练集和测试集
trainset, testset = train_test_split(data, test_size=0.25)
# 使用SVD算法进行训练
algo = SVD()
algo.fit(trainset)
# 为用户A预测对Movie4的评分
user_inner_id = algo.trainset.to_inner_uid('A')
item_inner_id = algo.trainset.to_inner_iid('Movie4')
predicted_rating = algo.predict(user_inner_id, item_inner_id, r_ui=0, verbose=True)
print(f"为用户A预测的Movie4评分是: {predicted_rating.est}")
代码讲解
- 数据准备:首先,我们将用户对电影的评分数据转换为Pandas DataFrame,然后使用Surprise的Reader类将其转换为Surprise库需要的格式。
- 训练测试集划分:使用
train_test_split函数将数据集划分为训练集和测试集。 - 模型训练:使用SVD算法进行训练。SVD是一种矩阵分解技术,它可以分解用户-物品评分矩阵为用户特征矩阵和物品特征矩阵的乘积。
- 预测评分:使用训练好的模型来预测用户对未知物品的评分。在这个例子中,我们预测用户A对Movie4的评分。
- 生成推荐:在实际应用中,我们会预测用户对所有未知物品的评分,并基于这些预测来生成推荐列表。
这个示例非常简化,实际应用中,基于模型的推荐系统会更加复杂,需要处理的数据量也会更大。此外,Surprise库提供了许多参数和算法供我们选择和调整,以适应不同的推荐场景。
多臂老虎机
基于多臂老虎机(Multi-Armed Bandit, MAB)的推荐算法是一种决策策略,它用于在不确定性下平衡探索(尝试新物品)和开发(选择已知的好物品)。这种算法在推荐系统中非常有用,因为它可以帮助解决冷启动问题,并且在面对新用户或新物品时能够快速适应。
原理
多臂老虎机问题是一个经典的决策问题,其中有一个老虎机(或多个),每个老虎机有多个臂(动作)。每个臂的奖励分布是未知的,目标是最大化总奖励。在推荐系统的上下文中,老虎机的臂可以被视为不同的物品,而奖励则是用户对物品的反馈(如点击、评分等)。
算法步骤
- 初始化:对于每个物品,初始化一个估计的奖励值(如平均评分)和一个选择次数。
- 选择动作:根据当前奖励估计和选择次数,选择一个物品推荐给用户。这个选择可以基于不同的策略,如ε-贪婪策略、UCB(Upper Confidence Bound)策略等。
- 用户反馈:观察用户对推荐物品的反馈(如果有的话)。
- 更新估计:根据用户反馈更新物品的奖励估计和选择次数。
- 重复:重复步骤2-4,随着时间的推移,算法会逐渐改进物品的选择策略。
注意点
- 冷启动问题:MAB算法特别适合解决冷启动问题,因为它能够快速适应新用户或新物品。
- 探索与开发的平衡:算法需要平衡探索(尝试新物品)和开发(选择已知的好物品)。这个平衡取决于探索系数(如ε-贪婪策略中的ε)。
- 非平稳环境:推荐系统的用户偏好可能会随时间变化,MAB算法需要能够适应这种非平稳环境。
可以优化的地方
- 个性化探索:根据用户的个性化和历史行为来调整探索策略。
- 多臂老虎机策略的选择:根据推荐系统的具体需求选择合适的MAB策略。
- 与其他推荐算法结合:将MAB与其他推荐算法(如协同过滤、基于内容的推荐)结合,以提供更全面的推荐。
示例
假设我们有一个新闻推荐系统,我们需要决定是向用户推荐热门新闻还是探索性新闻。热门新闻可能会带来更高的点击率,但探索性新闻可能会帮助我们发现用户的潜在兴趣。
示例背景
我们的新闻推荐系统有三种新闻类型:热门新闻(A)、体育新闻(B)和科技新闻(C)。我们希望通过多臂老虎机算法来决定向用户推荐哪种新闻类型。
代码实现
我们将使用Python的Thompson Sampling策略来实现多臂老虎机算法。
import random
class ThompsonSampling:def __init__(self, arms):self.arms = armsselfRewards = {arm: [] for arm in arms}self.NumPlays = {arm: 0 for arm in arms}def select_arm(self):# 计算每个臂的采样值samples = {arm: random.betavariate(self.NumPlays[arm] + 1, sum(selfRewards[arm]) + 1) for arm in self.arms}# 选择采样值最大的臂return max(self.arms, key=lambda arm: samples[arm])def update(self, chosen_arm, reward):# 更新选择次数和奖励self.NumPlays[chosen_arm] += 1self.Rewards[chosen_arm].append(reward)
# 初始化多臂老虎机
arms = ['热门新闻', '体育新闻', '科技新闻']
thompson_sampling = ThompsonSampling(arms)
# 假设我们进行了10次推荐
for _ in range(10):# 选择一个新闻类型chosen_arm = thompson_sampling.select_arm()print(f"推荐 {chosen_arm}")# 假设用户点击了推荐的新闻reward = 1 if random.random() < 0.5 else 0thompson_sampling.update(chosen_arm, reward)print(f"用户点击了 {reward} 次")
代码讲解
- 初始化:我们创建了一个
ThompsonSampling类,它接受一个臂的列表。在这个例子中,臂是新闻类型。我们还初始化了奖励和选择次数的字典。 - 选择动作:
select_arm方法使用Thompson采样来选择一个臂。每个臂的采样值是通过Beta分布计算得出的,然后选择采样值最大的臂。 - 用户反馈:我们模拟了用户对推荐新闻的点击行为。如果用户点击了新闻,我们将其视为奖励1,否则为0。
- 更新估计:
update方法根据用户的反馈来更新选择次数和奖励。我们通过将选择次数加1来更新选择次数,并将奖励添加到奖励列表中。
这个示例是一个非常简化的多臂老虎机推荐系统。在实际应用中,多臂老虎机算法可能会更加复杂,需要处理更多的用户和物品,并且可能需要更复杂的探索策略来适应不同的推荐场景。此外,实际应用中的奖励可能需要通过更复杂的方法来估计,而不是简单的点击行为。
多臂老虎机算法在推荐系统中非常有用,因为它可以帮助解决冷启动问题,并且在面对新用户或新物品时能够快速适应。然而,实际应用中的推荐系统可能会更加复杂,需要考虑更多的因素和优化点。
相关文章:

推荐算法详解
文章目录 推荐算法引言基于内容的推荐原理算法步骤注意点可以优化的地方示例代码讲解 协同过滤推荐原理算法步骤注意点可以优化的地方示例代码讲解 混合推荐系统原理算法步骤注意点可以优化的地方示例1代码讲解1示例2代码讲解2 基于知识的推荐原理算法步骤注意点可以优化的地方…...
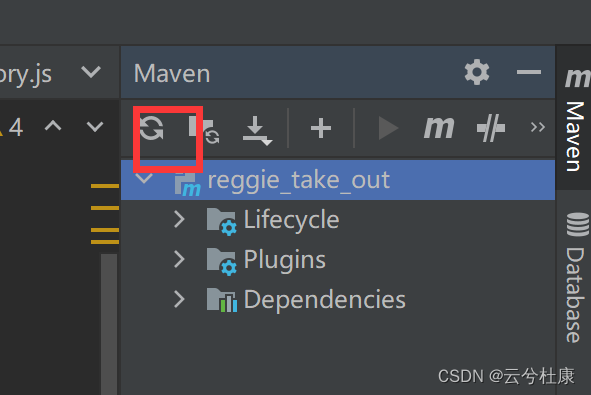
Java找不到包解决方案
在跟着教程写Spingboot后端项目时,为了加快效率,有时候有的实体文件可以直接粘贴到目录中,此时运行项目会出现Java找不到包的情况,即无法找到导入的实体文件,这是项目没有更新的原因。解决方法: 刷新Maven:…...
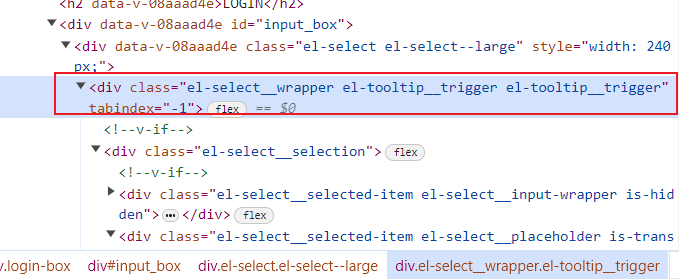
vue的css深度选择器 deep /deep/
作用及概念 当 <style> 标签有 scoped 属性时,它的 CSS 只作用于当前组件中的元素,父组件的样式将不会渗透到子组件。在vue中是这样描述的: 处于 scoped 样式中的选择器如果想要做更“深度”的选择,也即:影响到子…...
-OD统一考试(C卷D卷))
2024年华为OD机试真题-计算三叉搜索树的高度-(C++)-OD统一考试(C卷D卷)
题目描述: 定义构造三叉搜索树规则如下: 每个节点都存有一个数,当插入一个新的数时,从根节点向下寻找,直到找到一个合适的空节点插入。 查找的规则是: 1. 如果数小于节点的数减去500,则将数插入节点的左子树 2. 如果数大于节点的数加上500,则将…...
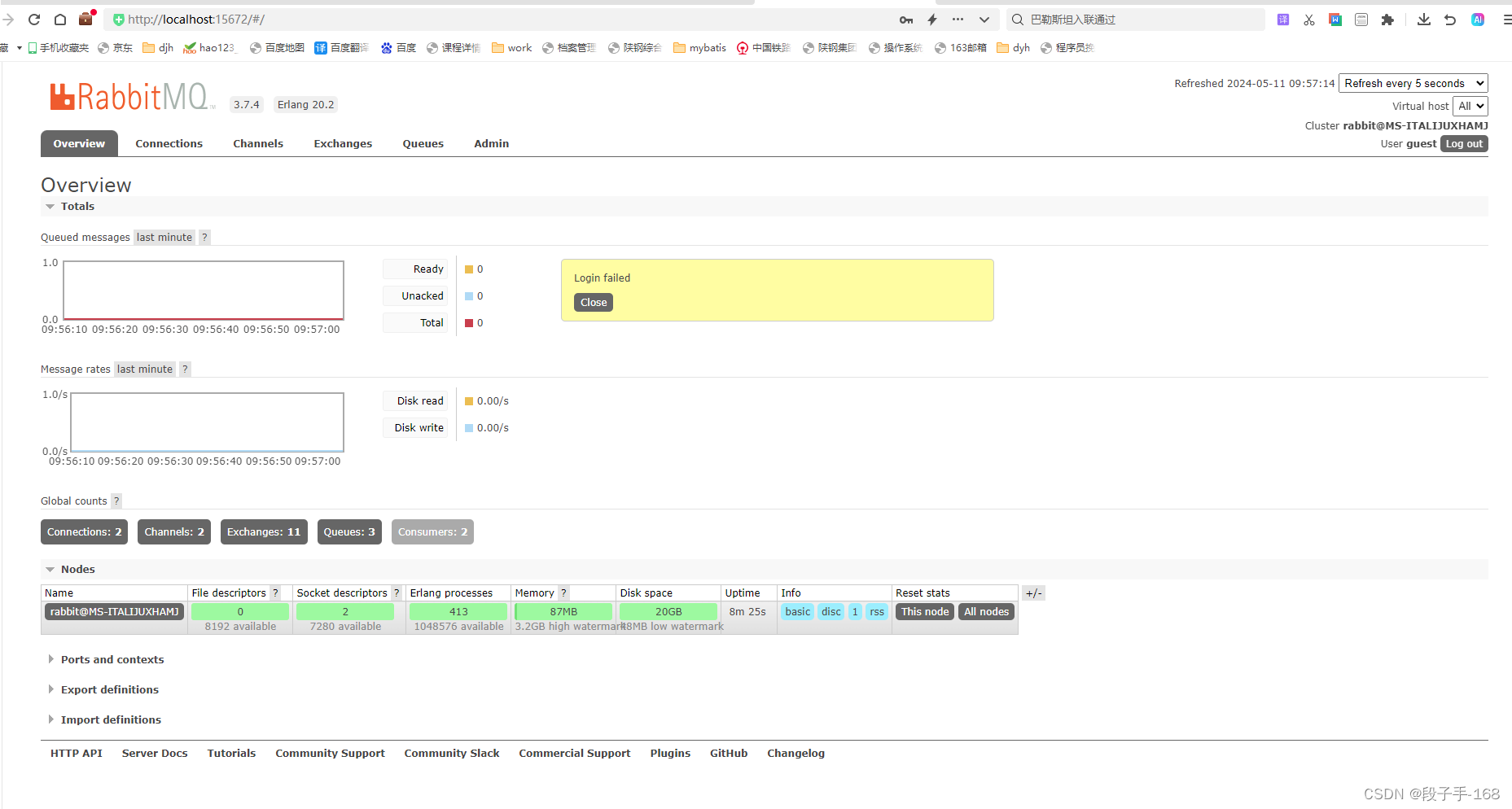
# ERROR: node with name “rabbit“ already running on “MS-ITALIJUXHAMJ“ 解决方案
ERROR: node with name “rabbit” already running on “MS-ITALIJUXHAMJ” 解决方案 一、问题描述: 1、启动 rabbitmq-server.bat 服务时,出错 Error 2、查询 rabbitmqctl status 状态时,出错 Error 3、停止 rabbitmqctl stop 服务时&a…...

class常量池、运行时常量池和字符串常量池详解
类常量池、运行时常量池和字符串常量池这三种常量池,在Java中扮演着不同但又相互关联的角色。理解它们之间的关系,有助于深入理解Java虚拟机(JVM)的内部工作机制,尤其是在类加载、内存分配和字符串处理方面。 类常量池…...
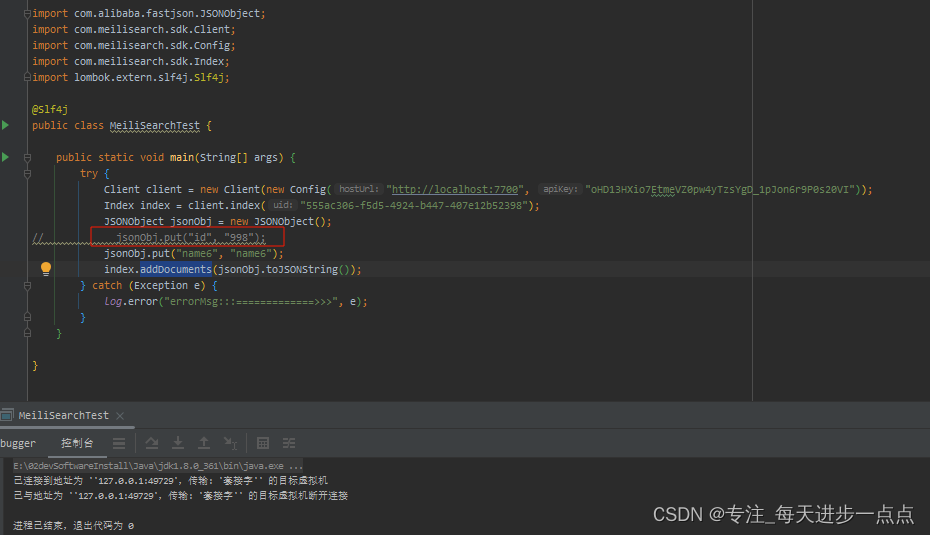
Meilisearch使用过程趟过的坑
Elasticsearch 做为老牌搜索引擎,功能基本满足,但复杂,重量级,适合大数据量。 MeiliSearch 设计目标针对数据在 500GB 左右的搜索需求,极快,单文件,超轻量。 所以,对于中小型项目来说…...

全面升级企业网络安全 迈入SASE新时代
随着数字化业务、云计算、物联网和人工智能等技术的飞速发展,企业的业务部署环境日渐多样化,企业数据的存储由传统的数据中心向云端和SaaS迁移。远程移动设备办公模式的普及,企业多分支机构的加速设立,也使得企业业务系统的用户范…...
2024.1IDEA 到2026年
链接:https://pan.baidu.com/s/1hjJEV5A5k1Z9JbPyBXywSw?pwd9g4i 提取码:9g4i解压之后,按照 操作说明.txt 操作; IntelliJ IDEA 2024.1 (Ultimate Edition) Build #IU-241.14494.240, built on March 28, 2024 Licensed to gurgles tumbles You have…...
uniapp——点赞、取消点赞
案例 更新点赞状态,而不是每次都刷新整个列表。避免页面闪烁,提升用户体验 代码 <view class"funcBtn zan" click"onZan(index,item.id)"><image src"/static/images/circle/zan.png" mode"aspectFill&…...

react经验15:拖拽排序组件dnd-kit的使用经验
应用场景 列表中的成员可鼠标拖拽改变顺序 实施步骤 前置引入 import type { DragEndEvent } from dnd-kit/core import { DndContext } from dnd-kit/core import {arrayMove,/*垂直列表使用verticalListSortingStrategy,横向列表使用horizontalListSortingStrategy*/vert…...

Webpack模块联邦:微前端架构的新选择
Webpack模块联邦(Module Federation)是Webpack 5引入的一项革命性特性,它彻底改变了微前端架构的实现方式。模块联邦允许不同的Web应用程序(或微前端应用)在运行时动态共享代码,无需传统的打包或发布过程中…...
)
CMake 学习笔记(访问Python)
CMake 学习笔记(访问Python) 利用Python可以做很多事情。比如: 利用 Python 自动生成一些代码。 在我们的程序中植入一个 Python 解释器。 为了做这些事情。就需要 CMake 能够知道 python 装在哪里,装的是什么版本的 python&a…...

【ruoyi】docker部署 captchaImage接口 FontConfiguration空指针异常
后台服务报错captchaImage接口空指针异常,无法启动项目: [http-nio-4431-exec-27] ERROR c.r.f.w.e.GlobalExceptionHandler - [handleRuntimeException,93] - 请求地址/captchaImage,发生未知异常.java.lang.NullPointerException: nullat sun.awt.Font…...

P1443 马的遍历
题目描述: 有一个 𝑛𝑚nm 的棋盘,在某个点 (𝑥,𝑦)(x,y) 上有一个马,要求你计算出马到达棋盘上任意一个点最少要走几步。 代码: package lanqiao;import java.util.*;public class Main {static int n,m…...

AI学习指南概率论篇-贝叶斯推断
AI学习指南概率论篇-贝叶斯推断 概述 在人工智能中,贝叶斯推断是一种基于贝叶斯统计理论的推理方法。它通过使用概率论的知识,结合先验信息和观测数据,来更新对未知变量的推断。贝叶斯推断提供了一种合理的方法来处理不确定性,并…...

大数据测试
1、前言 大数据测试是对大数据应用程序的测试过程,以确保大数据应用程序的所有功能按预期工作。大数据测试的目标是确保大数据系统在保持性能和安全性的同时,平稳无差错地运行。 大数据是无法使用传统计算技术处理的大型数据集的集合。这些数据集的测试涉…...
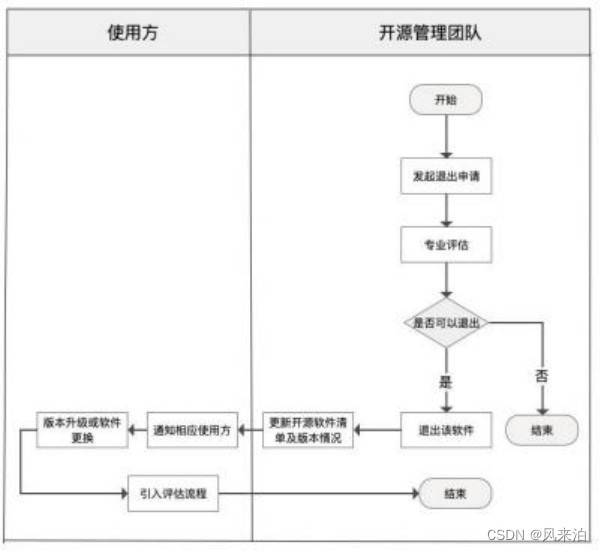
金融业开源软件应用 管理指南
金融业开源软件应用 管理指南 1 范围 本文件提供了金融机构在应用开源软件时的全流程管理指南,对开源软件的使用和管理提供了配套 组织架构、配套管理规章制度、生命周期流程管理、风险管理、存量管理、工具化管理等方面的指导。 本文件适用于金融机构规范自身对开…...

SolidWorks 齿轮配合
SolidWorks 齿轮配合 在SolidWorks中,齿轮配合是一种特殊的配合类型,用于模拟两个或多个齿轮之间的旋转关系。这种配合确保当一个齿轮旋转时,其他齿轮按照特定的比例旋转,非常适合模拟机械传动系统。以下是使用齿轮配合的详细步骤…...

鸿蒙开发-ArkTS语言-XML
鸿蒙开发-UI-web 鸿蒙开发-UI-web-页面 鸿蒙开发-ArkTS语言-基础类库 鸿蒙开发-ArkTS语言-并发 鸿蒙开发-ArkTS语言-并发-案例 鸿蒙开发-ArkTS语言-容器 鸿蒙开发-ArkTS语言-非线性容器 文章目录 前言 一、XML概述 二、XML生成 三、XML解析 1.解析XML标签和标签值 2.解析XML属性…...

5个关键步骤:让你的Windows视频播放体验达到专业级水准
5个关键步骤:让你的Windows视频播放体验达到专业级水准 【免费下载链接】VideoRenderer Внешний видео-рендерер 项目地址: https://gitcode.com/gh_mirrors/vi/VideoRenderer 你是否曾经在Windows上观看高质量视频时,感觉画…...

终极指南:如何在5分钟内让魔兽争霸3在现代电脑上完美运行
终极指南:如何在5分钟内让魔兽争霸3在现代电脑上完美运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典游戏魔兽争霸3在现代W…...

告别复杂命令:3步搞定M3U8视频下载的终极指南
告别复杂命令:3步搞定M3U8视频下载的终极指南 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 你是否曾经遇到过这样的困扰?在网上找到了心仪的视频教程或精…...

5分钟上手TegraRcmGUI:Windows平台最简单的Switch注入工具终极指南
5分钟上手TegraRcmGUI:Windows平台最简单的Switch注入工具终极指南 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI TegraRcmGUI是专为Nintendo S…...

BiliTools终极指南:免费下载B站视频的跨平台工具箱
BiliTools终极指南:免费下载B站视频的跨平台工具箱 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools Bili…...

Windows右键菜单终极清理教程:ContextMenuManager免费工具帮你告别臃肿与卡顿
Windows右键菜单终极清理教程:ContextMenuManager免费工具帮你告别臃肿与卡顿 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你的Windows右键菜单是…...

AI 变频调速水泵智能功率 MOSFET 完整选型方案
2026年,AI技术在智能水务及工业泵控系统深度渗透(如预测性维护、能效优化、智能流量调节),变频器对功率 MOSFET 提出更高要求:高效节能、高可靠性、快速响应。微碧半导体(VBsemi)基于先进的 Tre…...

2026年AI辅助研发趋势:智能知识问答如何重塑企业知识库的未来?
在2026年的当下,大模型技术已经从最初的"聊天玩具"逐渐渗透到企业级研发的毛细血管中。作为深耕DevOps领域的架构师,我观察到一个显著的变化:企业知识库(Knowledge Base)正在从单纯的"文档存储中心&quo…...

聊聊 KaiwuDB 的开源压测工具:kwdb-tsbs 上手分享
上一篇我们聊了一下通用 TSBS 工具《聊一聊TSBS:时序数据库跑分,为啥大家都用它?》 今天想就一家国内厂商开源的TSBS工具展开讲讲。怎么看这件事儿,怎么用,以及好不好用。 最近一直在玩时序数据库,做性能对…...

终极指南:如何用5分钟安装FF14动画跳过插件提升副本效率
终极指南:如何用5分钟安装FF14动画跳过插件提升副本效率 【免费下载链接】FFXIV_ACT_CutsceneSkip 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIV_ACT_CutsceneSkip 还在为《最终幻想14》国服副本中冗长的动画而烦恼吗?FFXIV_ACT_Cutscene…...