Python深度学习基于Tensorflow(1)Numpy基础
文章目录
- 数据转换和数据生成
- 存取数据
- 数据变形和合并
- 算数计算
- 广播机制
- 使用Numpy实现回归实例
numpy的重要性不言而喻,一般不涉及到GPU/TPU计算,都是用numpy,常见的np就是这个玩意。其特点就是快!其实如果不涉及到深度学习,还有一个库是很重要的,scipy,集成了很多的东西。
安装和导入如下:
# pip 安装方式
pip install numpy# conda 安装方式
conda install numpy# 导入
import numpy as np
numpy对象一般有三个属性:ndarray.ndim、ndarray.shape、ndarray.dtype。分别表示数据维度,数据形状,数据类型
数据转换和数据生成
将已有数据转化为numpy类型很简单,一般来说直接numpy.array一下就好
lst = [0.30406244, 0.06466714, 0.44950621]
array = np.array(lst)
这里无论是字符串什么东西的都可以直接丢进去,这里提一下读取图片文件,需要涉及到其他的库,常见的有PIL、OpenCV
# PIL
from PIL import Image
import numpy as npim = np.array(Image.open('图片路径'))# OpenCV
import cv2
im = cv2.imread('图片路径')
这两种方式都可以读取图片文件,cv2可以直接的转化为numpy类型数据
然后就是数据生成,分为随机生成和有序生成,分为random模块以及arange、linspace模块
这里先介绍一下random
# 设置随机种子
np.random.seed(42)# 生成矩阵形状为4*4,值在0-1之间的随机数
np.random.random(size=(4,4))# 生成矩阵形状为4*4,值在low和high之间的随机整数
np.random.randint(low=0, high=1, size=(4,4))# 生成矩阵形状为4*4,值在low和high之间满足均匀分布的随机数
np.random.uniform(low=0, high=1, size=(4,4))# 生成矩阵形状为4*4,值在low和high之间满足正态分布的随机数
np.random.normal(loc=0, scale=1, size=(4,4))
这里要注意:正态分布的loc表示的是 μ \mu μ , scale表示的是 σ \sigma σ。
接下来是arange和linspace
np.arange(start, stop, step)np.linspace(start, stop, num)
arange和linspace的区别就是step和num的区别,其中step是步长,num是数量,分别表示根据步长生成有序数据和数量生成有序数据。
存取数据
numpy和list一样,可以指定行和列来对数据进行切片,但是不同的是可以利用True和False来对数据进行筛选
mu, sigma = 0, 0.1
s = np.random.normal(mu, sigma, 1000)
res = s[(s>0) & (s<1)]
这样可以提取在0-1范围上的所有数据,这里要注意的是,条件必须要带上括号
数据变形和合并
首先是数据形状的修改
arr = np.arange(10)## reshape 修改np对象维度,不修改矩阵本身
arr = arr.reshape(2,5)## resize 修改np对象维度,同时修改矩阵本身
arr.resize(2,5)## T 转置
arr.T## ravel 把np对象展平,变成一维 C表示行优先,F表示列优先
arr.ravel('C')## flatten 把np对象展平,变成一维 C表示行优先,F表示列优先
arr.flatten(order="C")## squeeze 对维数为1的维度进行降维,即清除掉维数为1的维度
arr.squeeze()## 拓展维度
np.expand_dims(arr, axis=-1)
arr[:, np.newaxis]## transpose 对高维矩阵进行轴对换
arr.transpose(1,2,0)
数据合并
lst = [1, 2, 3]
lst_ = [3, 4, 5]## append 拼接数组,维度不能发生变化
res = np.append(lst,lst_)## concatenate 拼接数组,维度不能发生变化,内存占用要比append低, 推荐使用
lst = np.array([1, 2, 3])
lst_ = np.array([3, 4, 5])
res = np.concatenate((lst, lst_), axis=0)## stack hstack vstack dstack 堆叠数组
lst = np.array([1, 2, 3])
lst_ = np.array([3, 4, 5])
res = np.stack((lst, lst_), axis=1) # 对应dstack 沿着第三维
res = np.stack((lst, lst_), axis=0) # 对应vstack 沿着列堆叠
res = np.hstack((lst, lst_)) # 沿着行堆叠
算数计算
numpy的算术计算相比与math速度大大提升
sqrt,sin,cos,abs,dot,log,log10,log2,exp,cumsum, cumproduct,sum,mean,median,std,var,corrcoef
广播机制
- 让所有输入数组都向其中shape最长的数组看起,shape中不足的部分都通过在前面加1补齐;
- 输出数组的shape是输入数组shape的各个轴上的最大值;
- 如果输入数组的某个轴和输出数组的对应轴的长度相同或者长度为1时,则可以调整,否则将会出错;
- 当输入数组的某个轴长度为1时,沿着此轴运算时都用(或复制)此轴上的第一组值;
使用Numpy实现回归实例
假设目标函数如下:
y = 3 x 2 + 2 x + 1 y=3x^2+2x+1 y=3x2+2x+1
图像如下:
![![[Pasted image 20240505194741.png]]](https://img-blog.csdnimg.cn/direct/0fcf50a64b2b41e49dfc05ac7bdbff8e.png)
假设知道最高项为3,设函数为: y = a x 2 + b x + c y=ax^2+bx+c y=ax2+bx+c
import numpy as np
import matplotlib.pyplot as plt np.random.seed(42) x = np.linspace(-10, 10, 50)
y = 3 * np.power(x, 2) + 2 * x + 1 a = np.random.random(size=(1, 1))
b = np.random.random(size=(1, 1))
c = np.random.random(size=(1, 1)) def get_predict(x): global a, b, c res = (a * np.power(x, 2) + b * x + c).flatten() return res def get_loss(y, y_pred): return np.mean(np.square(y - y_pred)) def grad_param(y, y_pred, lr=1e-4): global a, b, c a_grad = 2 * np.mean((y_pred - y) * np.power(x, 2)) b_grad = 2 * np.mean((y_pred - y) * np.power(x, 1)) c_grad = 2 * np.mean(y_pred - y) a -= lr * a_grad b -= lr * b_grad b -= lr * c_grad return None def train_one_peoch(x, y): y_pred = get_predict(x) loss = np.mean(get_loss(y, y_pred)) grad_param(y, y_pred) return loss def main(): loss_lst = [] for i in range(100): loss = train_one_peoch(x, y) loss_lst.append(loss) print("第", i + 1, "次", "训练loss:", loss) plt.plot(loss_lst) plt.show() if __name__ == "__main__": main()
得到训练后的损失如下:
![![[Pasted image 20240505201747.png]]](https://img-blog.csdnimg.cn/direct/8adb135184fe4ba4b491821ae55ae58a.png)
相关文章:
Python深度学习基于Tensorflow(1)Numpy基础
文章目录 数据转换和数据生成存取数据数据变形和合并算数计算广播机制使用Numpy实现回归实例 numpy的重要性不言而喻,一般不涉及到GPU/TPU计算,都是用numpy,常见的np就是这个玩意。其特点就是快!其实如果不涉及到深度学习…...

体验GM CHM Reader Pro,享受高效阅读
还在为CHM文档的阅读而烦恼吗?试试GM CHM Reader Pro for Mac吧!它拥有强大的功能和出色的性能,能够让你轻松打开和阅读CHM文件,享受高效、舒适的阅读体验。无论是学习、工作还是娱乐,GM CHM Reader Pro都能成为你的得…...
校园网拨号上网环境下多开虚拟机,实现宿主机与虚拟机互通,并访问外部网络
校园网某些登录客户端只允许同一时间一台设备登录,因此必须使用NAT模式共享宿主机的真实IP,相当于访问外网时只使用宿主机IP,此方式通过虚拟网卡与物理网卡之间的数据转发实现访问外网及互通 经验证,将centos的物理地址与主机物理…...

cpu常用命令
1.平台信息 # 读节点 adb shell "cat proc/cpuinfo" # 读属性 adb shell getprop ro.hardware 2.负载信息 # 负载信息 adb shell dumpsys cpuinfo 3.原生定频 # 频率档位 adb shell "cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_available_frequencies&q…...
--- Axios 基本用法)
Vue3实战笔记(06)--- Axios 基本用法
文章目录 前言一、发送get请求二、发送post请求三、另一种写法总结 前言 今天学习Vue官方推荐的请求工具Axios ,Axios 是一个基于 promise 的 HTTP 库,可用于浏览器和 node.js 中。它简洁、易用且功能强大,支持多种请求类型(GET、…...
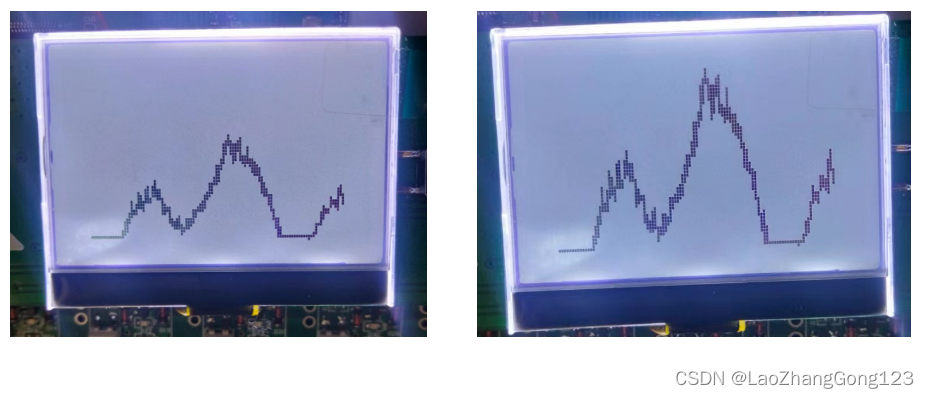
使用单片机在图形点阵LCD上绘制波形图
使用单片机在图形点阵LCD上绘制波形图 需求: 假如有一组浮点数据,是通过AD转换得到的,保存在数组MyArray[]中,采集点数为len,采集周期为T,现在想用单片机在LCD上绘制出这组数据对应的波形图,该…...

生信人写程序1. Perl语言模板及配置
生物信息领域常用语言 个人认为:是否能熟悉使用Shell(项目流程搭建)R(数据统计与可视化)Perl/Python/Java…(胶水语言,数据格式转换,软件间衔接)三门语言是一位合格生物信息工程师的标准。 生物信息常用语言非常广泛,我常用的有…...
【Android】Kotlin学习之数据容器 -- 集合
一. 定义 List : 是一个有序列表, 可通过下标访问元素. 元素可以在list中出现多次, 元素可重复 Set : 是元素唯一的集合, 一般来说Set中元素的顺序并不重要, 无序集合. Map : 是一组键值对, 键是唯一的, 每个键刚好映射到一个值, 值可以重复 二. 集合创建 三. 示例 mutabl…...
超详细 springboot 整合 Mock 进行单元测试!本文带你搞清楚!
文章目录 一、什么是Mock1、Mock定义2、为什么使用3、常用的Mock技术4、Mokito中文文档5、集成测试和单元测试区别 二、API1、Mockito的API2、ArgumentMatchers参数匹配3、OngoingStubbing返回操作 三、Mockito的使用1、添加Maven依赖2、InjectMocks、Mock使用3、SpringbootTes…...
国产操作系统下Chrome的命令行使用 _ 统信 _ 麒麟
原文链接:国产操作系统下Chrome的命令行使用 | 统信 | 麒麟 Hello,大家好啊!今天我们来聊聊如何在国产操作系统上使用命令行操作Google Chrome。无论是进行自动化测试、网页截图还是网页数据抓取,使用命令行操作Google Chrome都能…...
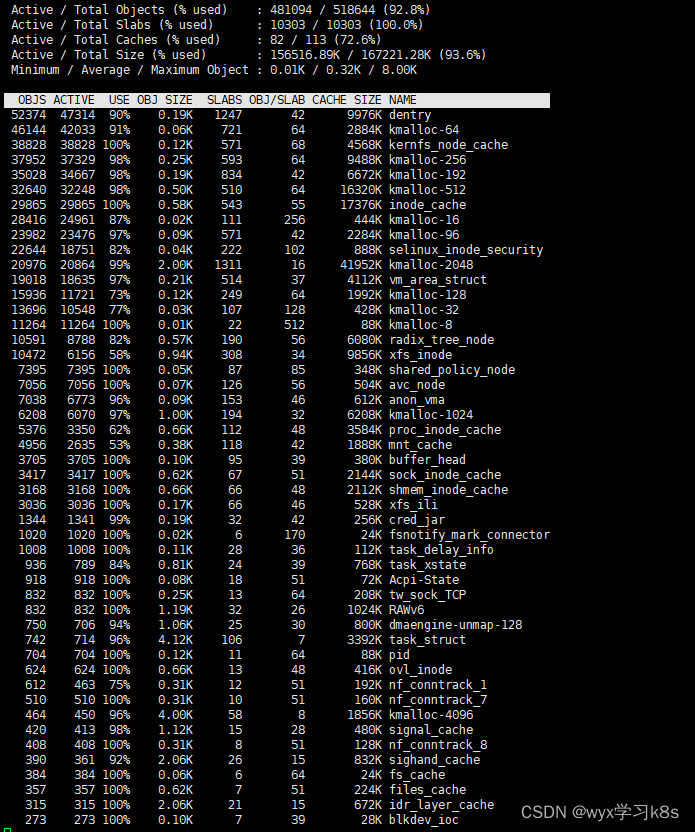
linux性能监控之slabtop
slabtop命令是以实时的方式显示内核slab缓冲区的细节信息,是linux自带的命令 [rootk8s-master ~]# slabtop --helpUsage:slabtop [options]Options:-d, --delay <secs> delay updates-o, --once only display once, then exit-s, --sort <char&…...

Allure 在 Python 中的安装与使用
Allure 是一个灵活轻量级的测试报告工具,它能够生成详细且富有洞察力的测试报告。在 Python 中,Allure 通常与 Pytest 结合使用,以提供更加丰富的测试结果展示。下面我将介绍关于如何在 Python 中使用 Allure 的详细操作。 一、环境准备 在…...

python实现动态时钟功能
欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 一.前言 时钟,也被称为钟表,是一种用于测量、记录时间的仪器。时钟通常由时针、分针、秒针等计时仪器组成,是现代社会不可或缺的一种计时工具。它的发明和使用极大地改变了人类的生活方式和时间观念。 时钟的类型有很多,…...
QueryPerformanceCounter实现高精度uS(微妙)延时
参考连接 C# 利用Kernel32的QueryPerformanceCounter封装的 高精度定时器Timer_kernel32.dll queryperformancecounter-CSDN博客https://blog.csdn.net/wuyuander/article/details/111831973 特此记录 anlog 2024年5月11日...

Logstash详解
Logstash详解:构建强大日志收集与处理管道的利器 一、引言 在大数据和云计算的时代,日志数据作为企业运营和故障排查的重要依据,其收集、处理和分析能力显得尤为重要。Logstash,作为一款强大的日志收集、处理和转发工具…...

QT设计模式:适配器模式
基本概念 适配器模式(Adapter Pattern)是一种结构型设计模式,允许将一个类的接口转换成客户端所期望的另一个接口,可以让原本由于接口不兼容而不能一起工作的类能够一起工作。 适配器模式需要实现的部分为: Target类…...
开发规范相关
1.对IDEA集成的代码检查 或 AliBaBa的代码检查 定义的规则进行取消或新增 代码自动扫描检查对于代码规范来说至关重要,但有时,我们希望忽略掉某些不必要的检查,比如忽略掉这个检查 可以如下操作 此时即可不再提示告警...
——Set操作)
C++ 容器(五)——Set操作
一、Set容器定义 set 是一个有序关联容器,其中的元素按照升序排列,且不允许重复元素。 set 中的元素是唯一的,即任意两个元素不能相等。 1、set 可以用来对元素进行排序,因为它会自动对元素进行有序排列。 2、set 可以用来去重,当我们需要对一个容器中的元素进行去重操…...

【数字IC设计】芯片设计中的RDC
RDC问题定义 在芯片设计中,RDC是reset domain crossing 的缩写,类似于CDC(clock domain crossing),由于现在SOC芯片是有很多ECUs组成,为了使整个系统能够快速从复位中恢复, 用户希望SOC里面每个ECU模块都可以有自己独立的异步复位信号,这样可以在出问题的时候只复位有错…...

spark history server异常
现象:spark 日志文件突然新增了很多.hprof文件, 查找日志spark配置参数spark_log_dir进入日志目录: 查看historyServer日志: Spark Command: /usr/lib/jvm/java-1.8.0/bin/java -cp /opt/apps/JINDOSDK/jindosdk-current/lib/*:/…...
)
统信UOS离线部署实战:手把手教你用yum缓存提取sshpass等软件包(附完整命令)
统信UOS离线部署全流程指南:从缓存提取到依赖解析 在高度安全隔离的内网环境中,统信UOS系统管理员常面临一个核心挑战:如何将联网环境获取的软件包完整迁移到离线机器。与常见的/var/cache/yum路径不同,统信UOS的缓存机制有其特殊…...

JavaScript进阶:ES6+特性与异步编程
JavaScript进阶:ES6特性与异步编程 1. 技术分析 1.1 ES6概述 ES6为JavaScript带来了革命性的改进: ES6特性变量声明: let, const箭头函数: () > {}解构赋值: const {a, b} obj类: class语法模块化: import/export异步编程:Promiseasync/awaitGenerat…...

Bifrost三星固件下载器:免费跨平台获取官方系统的一站式解决方案
Bifrost三星固件下载器:免费跨平台获取官方系统的一站式解决方案 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 你是否曾为寻找三星设备官方固件而烦…...
)
手把手教你用VAMI 5480界面给vCenter Server 7.0打补丁(附备份确认与CEIP选择避坑)
从零开始:vCenter Server 7.0小版本升级全流程指南 第一次为vCenter Server执行小版本升级,就像给心脏做手术——既不能出错,又必须确保每一步都万无一失。作为VMware虚拟化环境的核心枢纽,vCenter的稳定性直接关系到整个IT基础设…...

为Claude Code配置Taotoken作为备用模型服务商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken作为备用模型服务商 对于经常使用Claude Code进行编程辅助的开发者而言,直接依赖单一服务商…...

FreeRTOS互斥锁的‘坑’与‘宝’:优先级翻转那些事儿,用ESP32实测给你看
FreeRTOS互斥锁的‘坑’与‘宝’:优先级翻转那些事儿,用ESP32实测给你看 在嵌入式实时系统中,任务调度和资源管理是核心挑战。当你开始设计多任务系统时,很快会遇到一个经典问题:多个任务需要访问共享资源(…...

通过curl命令快速测试Taotoken接口连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken接口连通性与返回格式 在集成大模型服务时,直接使用curl命令进行接口测试是一种高效、轻…...

如何掌握Il2CppDumper:Unity逆向工程实战指南与深度解析
如何掌握Il2CppDumper:Unity逆向工程实战指南与深度解析 【免费下载链接】Il2CppDumper Unity il2cpp reverse engineer 项目地址: https://gitcode.com/gh_mirrors/il/Il2CppDumper 你是否曾面对Unity游戏的il2cpp二进制文件感到无从下手?是否在…...

嵌入式开发实战:软硬件协同设计与深度调试指南
1. 项目概述:嵌入式开发,一场与硬件的深度对话 干了十几年嵌入式,我越来越觉得,这行当本质上就是一场开发者与硬件之间旷日持久的“对话”。你写的每一行代码,最终都要落到那块小小的电路板上,去驱动LED闪烁…...

华为鸿蒙与欧拉操作系统:全场景战略下的技术架构与生态构建
1. 从“备胎”到“主干”:华为操作系统的战略突围之路 最近科技圈里关于华为的消息,大家讨论得最多的,除了孟晚舟女士的归国,可能就是华为在软件领域接连放出的几个“大招”了。作为一名在ICT行业摸爬滚打了十几年的老兵ÿ…...