序列到序列模型在语言识别Speech Applications中的应用 Transformer应用于TTS Transformer应用于ASR 端到端RNN
序列到序列模型在语言识别Speech Applications中的应用
A Comparative Study on Transformer vs RNN in Speech Applications
序列到序列(Seq2Seq)模型在语音识别(Speech Applications)中有重要的应用。虽然Seq2Seq模型最初是为了解决自然语言处理中的序列生成问题而设计的,特别是机器翻译,但它在语音识别领域也展现出了强大的能力。
在语音识别中,Seq2Seq模型可以将输入的语音信号(即声音波形)转化为文字序列。这个过程通常包括两个主要步骤:首先,编码器(Encoder)将输入的语音信号转换为一种中间表示形式,这通常是一个固定长度的向量或者一系列向量。然后,解码器(Decoder)根据这个中间表示来生成对应的文字序列。
具体来说,在编码器部分,通常使用循环神经网络(RNN)或其变种(如长短期记忆网络LSTM或门控循环单元GRU)来处理输入的语音信号。这些网络能够捕捉语音信号中的时间依赖关系,并将其转换为一种适合解码器处理的表示形式。
在解码器部分,同样可以使用RNN或其变种来根据编码器的输出生成文字序列。解码器通常使用一种称为“注意力机制”(Attention Mechanism)的技术来关注输入序列中的不同部分,从而更准确地生成对应的输出。
通过结合编码器和解码器,Seq2Seq模型能够实现从语音信号到文字序列的转换,这在智能家居、智能客服等领域具有广泛的应用前景。例如,智能音箱可以通过语音识别技术来理解用户的语音指令,并执行相应的操作;智能客服系统也可以通过语音识别来与用户进行交互,提供更高效、更便捷的服务。
总的来说,Seq2Seq模型在语音识别中的应用展示了深度学习在处理序列数据方面的强大能力,为语音交互技术的发展提供了有力的支持。
介绍
随着深度学习技术的不断发展,Transformer模型在序列到序列任务中逐渐取代了传统的RNN模型,尤其是在自动语音识别(ASR)、语音翻译(ST)和文本到语音(TTS)等语音处理领域。以下是对您描述的论文内容的进一步概述和扩展:
将Transformer应用于语音的主要困难
Transformer模型在NLP领域取得了巨大成功,但在将其应用于语音领域时,面临了一些挑战。首先,语音数据通常具有更高的时间分辨率,这要求模型能够处理更长的序列。而Transformer模型在处理长序列时,由于自注意力机制的计算复杂度是O(n^2),可能导致计算资源和时间的急剧增加。
此外,语音数据中的特征表示通常与文本数据不同。在NLP中,单词或字符通常是模型的输入单元,而在语音中,常用的输入单元是帧级别的声学特征(如MFCC或log-Mel spectrograms)。这要求模型能够适应不同类型的输入数据。
Transformer与RNN的比较研究
论文通过大规模的实验比较了Transformer和RNN在ASR任务中的性能。实验结果显示,Transformer模型在多个数据集上均取得了比RNN模型更好的性能。这主要得益于Transformer模型中的自注意力机制,它能够捕捉输入序列中的全局依赖关系,而不仅仅是局部依赖关系。
Transformer在语音应用中的训练技巧
论文还提供了一些针对语音应用的Transformer训练技巧,这些技巧包括:
优化器选择:选择适合语音数据的优化器,如Adam、Noam学习率衰减等。
网络结构设计:针对语音数据的特性,设计合适的网络结构,如调整Transformer中的编码器和解码器的层数、注意力头数等。
数据增强:采用数据增强技术来增加训练数据的多样性,如添加噪声、混响、速度扰动等。
预训练:利用大规模无标注语音数据进行预训练,以提高模型的泛化能力。
开放源代码工具包ESPnet
论文还在ESPnet工具包中提供了可复制的端到端配置和预训练模型。ESPnet是一个用于端到端语音处理的开源工具包,它支持多种任务(如ASR、ST、TTS)和多种模型(如RNN、Transformer)。通过在ESPnet中提供预训练的模型和配置,其他研究人员可以更容易地复现论文中的实验结果,并进一步探索Transformer在语音处理中的应用。
将Transformer应用于语音处理领域是一个有前景的研究方向。通过克服一些挑战并采用合适的训练技巧,Transformer模型可以在ASR、ST和TTS等任务中取得更好的性能。同时,开放源代码工具包如ESPnet为研究人员提供了方便的实验平台,促进了该领域的发展。
序列到序列模型已广泛用于端到端语音处理中,例如自动语音识别(ASR),语音翻译(ST)和文本到语音(TTS)。本文着重介绍把Transformer应用在语音领域上并与RNN进行对比。与传统的基于RNN的模型相比,将Transformer应用于语音的主要困难之一是,它需要更复杂的配置(例如优化器,网络结构,数据增强)。在语音应用实验中,论文研究了基于Transformer和RNN的系统的几个方面,例如,根据所有标注数据、训练曲线和多个GPU的可伸缩性来计算单词/字符/回归错误。本文的几个主要贡献:
- 将Transformer和RNN进行了大规模的比较研究,尤其是在ASR相关任务方面,它们具有显着的性能提升。
- 提供了针对语音应用的Transformer的训练技巧:包括ASR,TTS和ST
- 在开放源代码工具包ESPnet中提供了可复制的端到端配置和模型,这些配置和模型已在大量可公开获得的数据集中进行了预训练。
端到端RNN
如下图中,说明了实验用于ASR,TTS和ST任务的通用S2S结构。
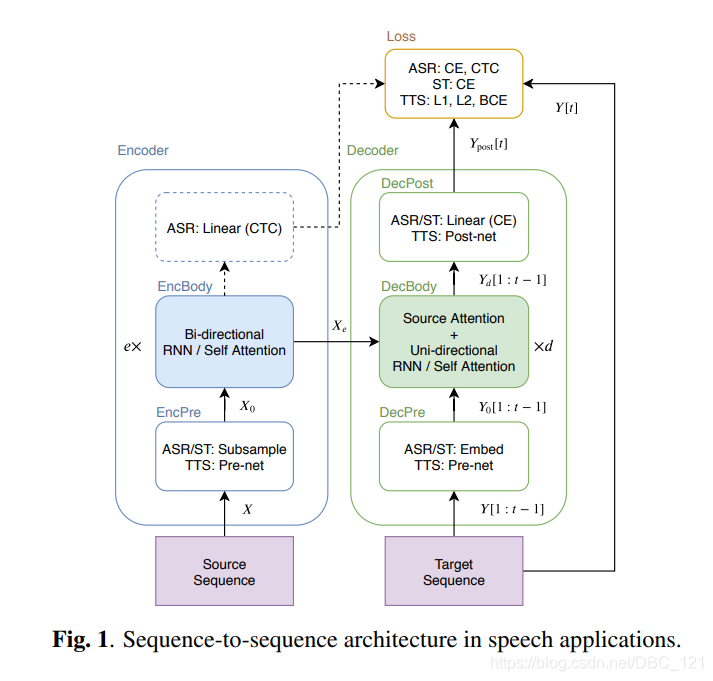
S2S包含两个神经网络:其中编码器如下:
( 1 ) : X 0 = E n c P r e ( X ) (1):X_0=EncPre(X) (1):X0=EncPre(X) ( 2 ) : X e = E n c B o d y ( X 0 ) (2):X_e=EncBody(X_0) (2):Xe=EncBody(X0)
解码器如下:
( 3 ) : Y 0 [ 1 : t − 1 ] = D e c P r e ( Y [ 1 : t − 1 ] ) (3):Y_0[1:t-1]=DecPre(Y[1:t-1]) (3):Y0[1:t−1]=DecPre(Y[1:t−1]) ( 4 ) : Y d [ t ] = D e c B o d y ( X e , Y 0 [ 1 : t − 1 ] ) (4):Y_d[t]=DecBody(X_e,Y_0[1:t-1]) (4):Yd[t]=DecBody(Xe,Y0[1:t−1]) ( 5 ) : Y p o s t [ 1 : t ] = D e c P o s t ( Y d [ 1 : t ] ) (5):Y_{post}[1:t]=DecPost(Y_d[1:t]) (5):Ypost[1:t]=DecPost(Yd[1:t])
其中 X X X 是源序列,例如,语音特征序列(对于ASR和ST)或字符序列(对于TTS), e e e 是EncBody层数, d d d 是DecBody中的层数, t t t 是目标帧索引,以上等式中的所有方法均由神经网络实现。对于解码器输入 Y [ 1 : t − 1 ] Y [1:t − 1] Y[1:t−1],我们在训练阶段使用一个真实标注的前缀,而在解码阶段使用一个生成的前缀。在训练过程中,S2S模型学习是将在生成的序列 Y p o s t Y_{post} Ypost 和目标序列 Y Y Y 之间标量损失值最小化:
( 6 ) : L = L o s s ( Y p o s t , Y ) (6):L=Loss(Y_{post},Y) (6):L=Loss(Ypost,Y)
本节的其余部分描述了基于RNN的通用模块:“EncBody”和“DecBody”。而将“EncPre”,“DecPre”,“DecPost”和“Loss”视为特定于任务的模块,我们将在后面的部分中介绍。
等式(2)中的EncBody将源序列 X 0 X_0 X0 转换为中间序列 X e X_e Xe,现有的基于RNN的EncBody实现通常采用双向长短记忆(BLSTM)。对于ASR,编码序列 X e X_e Xe 还可以在进行联合训练和解码中,用基于神经网络的时序类分类(CTC)进行逐帧预测。
等式(4)中的DecBody()将生成具有编码序列 X e X_e Xe 和目标前缀 Y 0 [ 1 : t − 1 ] Y_0 [1:t − 1] Y0[1:t−1] 的前缀的下一个目标帧。对于序列生成,解码器通常是单向的。 例如,具有注意力机制的单向LSTM通常用于基于RNN的DecBody()实现中。该注意力机制计算逐帧权重,以将编码后的帧 X e X_e Xe 求和,并作为要以前缀 Y 0 [ 0 : t − 1 ] Y0 [0:t-1] Y0[0:t−1] 进行转换的逐帧目标向量,我们称这种注意为“encoder-decoder attention”
Transformer
Transformer包含多个dot-attention层:
( 7 ) : a t t ( X q , X k , X v ) = s o f t m a x ( X q X k T d a t t ) X v (7):att(X^q,X^k,X^v)=softmax(\frac{X^qX^{kT}}{\sqrt{d^{att}}})X^v (7):att(Xq,Xk,Xv)=softmax(dattXqXkT)Xv
其中 X k , X v ∈ R n k × d
相关文章:
序列到序列模型在语言识别Speech Applications中的应用 Transformer应用于TTS Transformer应用于ASR 端到端RNN
序列到序列模型在语言识别Speech Applications中的应用 A Comparative Study on Transformer vs RNN in Speech Applications 序列到序列(Seq2Seq)模型在语音识别(Speech Applications)中有重要的应用。虽然Seq2Seq模型最初是为了解决自然语言处理中的序列生成问题而设计的…...
【Linux】- Linux环境变量[8]
目录 环境变量 $符号 自行设置环境变量 环境变量 环境变量是操作系统(Windows、Linux、Mac)在运行的时候,记录的一些关键性信息,用以辅助系统运行。在Linux系统中执行:env命令即可查看当前系统中记录的环境变量。 …...
前端笔记-day04
文章目录 01-后代选择器02-子代选择器03-并集选择器04-交集选择器05-伪类选择器06-拓展-超链接伪类07-CSS特性-继承性08-CSS特性-层叠性09-CSS特性-优先级11-Emmet写法12-背景图13-背景图平铺方式14-背景图位置15-背景图缩放16-背景图固定17-background属性18-显示模式19-显示模…...

计算机字符集产生的历史与乱码
你好,我是 shengjk1,多年大厂经验,努力构建 通俗易懂的、好玩的编程语言教程。 欢迎关注!你会有如下收益: 了解大厂经验拥有和大厂相匹配的技术等 希望看什么,评论或者私信告诉我! 文章目录 一…...
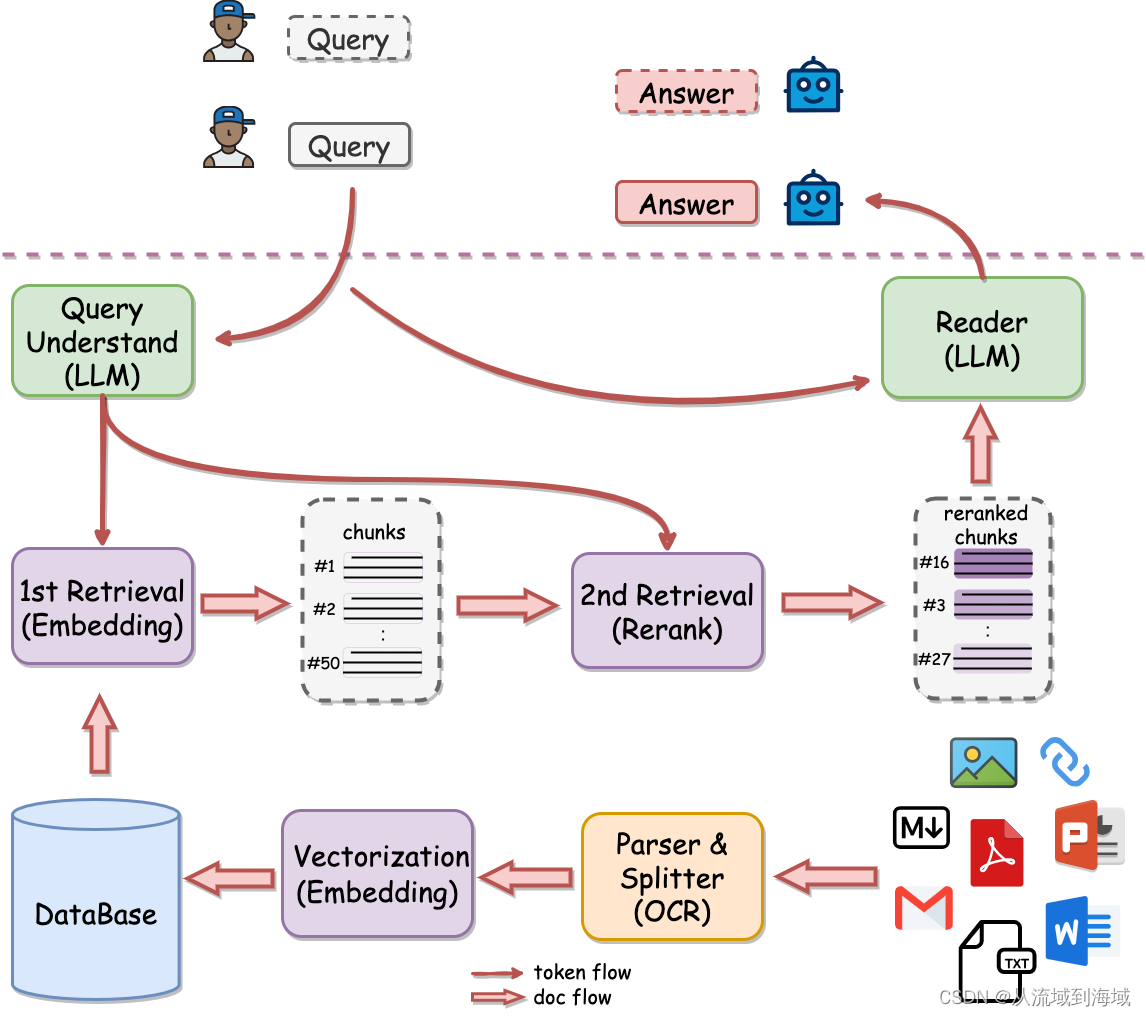
Rerank进一步提升RAG效果
RAG & Rerank 目前大模型应用中,RAG(Retrieval Augmented Generation,检索增强生成)是一种在对话(QA)场景下最主要的应用形式,它主要解决大模型的知识存储和更新问题。 简述RAG without R…...

使用train.py----yolov7
准备工作 在训练之前,数据集的工作和配置环境的工作要做好 数据集:看这里划分数据集,训练自己的数据集。_划分数据集后如何训练-CSDN博客 划分数据集2,详细说明-CSDN博客 配置环境看这里 从0开始配置环境-yolov7_gpu0是inter g…...
机器学习第37周周报 GGNN
文章目录 week37 GGNN摘要Abstract一、文献阅读1. 题目2. abstract3. 网络架构3.1 数据处理部分3.2 门控图神经网络3.3 掩码操作 4. 文献解读4.1 Introduction4.2 创新点4.3 实验过程4.3.1 传感器设置策略4.3.2 数据集4.3.3 实验设置4.3.4 模型参数设置4.3.5 实验结果 5. 结论 …...
Baidu Comate:释放编码潜能,革新软件开发
Baidu Comate Baidu Comate,智能代码助手,凭借着文心大模型的强大支撑,结合了百度多年的编程实战数据和丰富的开源资源,形成了一款崭新的编码辅助利器。它不仅具备着高智能、多场景、价值创造的特质,更可广泛应用于各…...

MATLAB的Bar3函数调节渐变色(内附渐变色库.mat及.m文件免费下载链接)
一. colormap函数 可以使用colormap函数: t1[281.1,584.6, 884.3,1182.9,1485.2; 291.6,592.6,896,1197.75,1497.33; 293.8,596.4,898.6,1204.4,1506.4; 295.8,598,904.4,1209.0,1514.6];bar3(t1,1) set(gca,XTickLabel,{300,600,900,1200,1500},FontSize,10) set…...

使用 TensorFlow.js 和 OffscreenCanvas 实现实时防挡脸弹幕
首先,要理解我们的目标,我们将实时获取视频中的面部区域并将其周围的内容转为不透明以制造出弹幕的“遮挡效应”。 步骤一:环境准备 我们将使用 TensorFlow.js 的 Body-segmentation 库来完成面部识别部分,并使用 OffscreenCanv…...
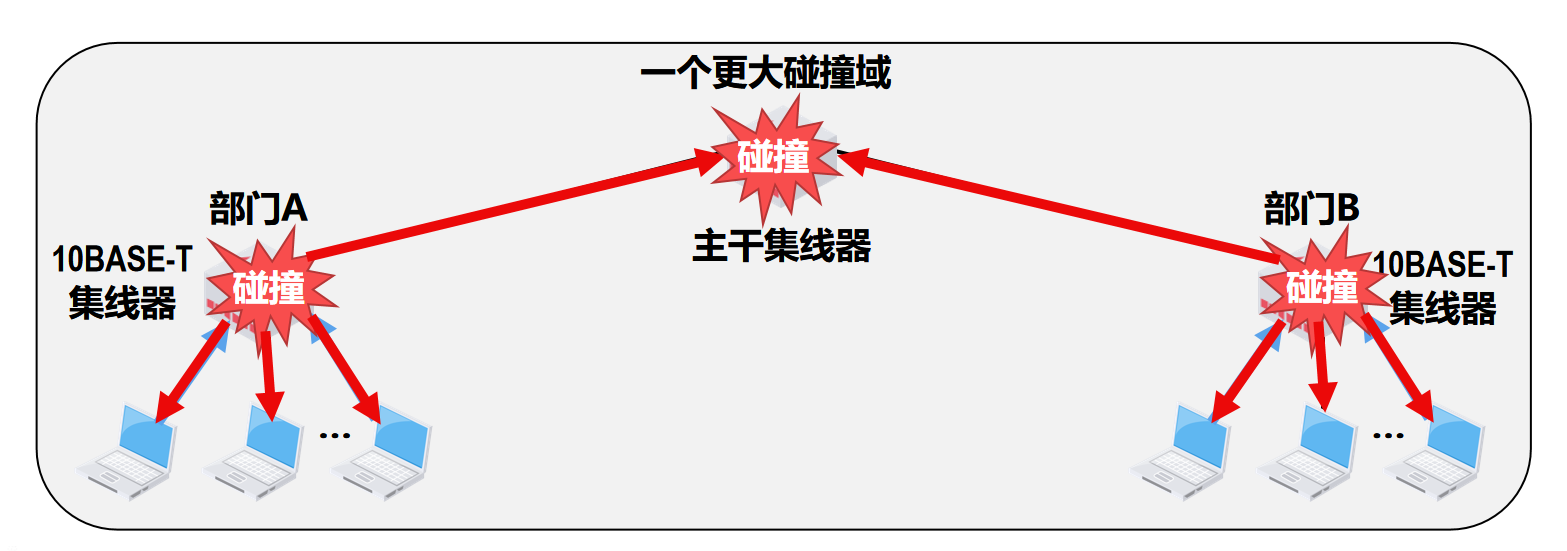
【计算机网络篇】数据链路层(10)在物理层扩展以太网
文章目录 🍔扩展站点与集线器之间的距离🛸扩展共享式以太网的覆盖范围和站点数量 🍔扩展站点与集线器之间的距离 🛸扩展共享式以太网的覆盖范围和站点数量 以太网集线器一般具有8~32个接口,如果要连接的站点数量超过了…...

conan2 基础入门(03)-使用(msvc为例)
conan2 基础入门(03)-使用(msvc为例) 文章目录 conan2 基础入门(03)-使用(msvc为例)⭐准备生成profile文件预备文件和Code ⭐使用指令预览正确执行结果可能出现的问题 ⭐具体讲解conanconanfile.txt执行 install cmakeCMakeLists.txt生成项目构建 END ⭐准备 在阅读和学习本文…...

uniapp this 作用域保持的方法
在 UniApp(或任何基于 Vue.js 的框架)中,this 关键字通常用于引用当前 Vue 实例的上下文。然而,当你在回调函数、定时器、Promise、异步函数等中使用 this 时,你可能会发现 this 的值不再指向你期望的 Vue 实例&#x…...

vue2 与vue3的差异汇总
Vue 2 与 Vue 3 之间存在多方面的差异,这些差异主要体现在性能、API设计、数据绑定、组件结构、以及生命周期等方面。以下是一些关键差异的汇总: 数据绑定与响应式系统 Vue 2 使用 Object.defineProperty 来实现数据的响应式,这意味着只有预…...
Java反射(含静态代理模式、动态代理模式、类加载器以及JavaBean相关内容)
目录 1、什么是反射 2、Class类 3、通过Class类取得类信息/调用属性或方法 4、静态代理和动态代理 5.类加载器原理分析 6、JavaBean 1、什么是反射 Java反射机制的核心是在程序运行时动态加载类并获取类的详细信息,从而操作类或对象的属性和方法。本质是JVM得…...

Scoop国内安装、国内源配置
安装配置源可参考gitee上的大佬仓库,里面的步骤、代码都很详细,实测速度也很好 glsnames/scoop-installer 也可以结合其它bucket使用 使用Github加速网站,也可以换做其他代理方式,自行测试 例如:https://mirror.ghprox…...

【软件开发规范篇】JAVA后端开发编程规范
作者介绍:本人笔名姑苏老陈,从事JAVA开发工作十多年了,带过大学刚毕业的实习生,也带过技术团队。最近有个朋友的表弟,马上要大学毕业了,想从事JAVA开发工作,但不知道从何处入手。于是࿰…...

数据结构与算法学习笔记三---循环队列的表示和实现(C语言)
目录 前言 1.为啥要使用循环队列 2.队列的顺序表示和实现 1.定义 2.初始化 3.销毁 4.清空 5.空队列 6.队列长度 7.获取队头 8.入队 9.出队 10.遍历队列 11.完整代码 前言 本篇博客介绍栈和队列的表示和实现。 1.为啥要使用循环队列 上篇文章中我们知道了顺序队列…...

vue3中的reactive和ref
在Vue 3中,reactive和ref是两个常用的响应式API,用于创建响应式的数据。它们的主要区别在于reactive用于创建对象或数组的响应式引用,而ref用于创建单个值的响应式引用。下面我将分别介绍它们的详细用法,并提供代码示例。 1. rea…...

Centos安装 docker和docker-compose
安装docker yum install -y yum-utils yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo yum install docker-ce docker-ce-cli containerd.io sudo systemctl start docker sudo systemctl enable docker docker version 在L…...

Karpathy 加入 Anthropic 真相:不是人才争夺,是「用 AI 训练 AI」的自我加速时代
先想象一个场景 2026 年初,你是一家 AI 实验室的 CTO。预算有限,买不起 OpenAI 那量级的 GPU。你有三个选择: A. 追着头部跑,花 80% 的钱买算力,剩下 20% 养团队——永远比别人慢半步 B. 放弃预训练,专注…...

案例之 ANN案例_手机价格分类
案例之 ANN案例_手机价格分类...

告别智能插座!用Python和nilmtk库,5分钟入门非侵入式用电分析
告别智能插座!用Python和nilmtk库,5分钟入门非侵入式用电分析 你是否曾好奇家中每台电器究竟消耗了多少电量?传统方案需要在每个插座安装智能电表,成本高昂且部署复杂。现在,借助**非侵入式负载监控(NILM&…...

Cadence Allegro焊盘设计避坑指南:从SMD到通孔,这些层设置错了板子就废了
Cadence Allegro焊盘设计避坑指南:从SMD到通孔的关键层设置解析 当一块PCB板从设计文件变成实体电路板时,最令人崩溃的莫过于发现焊盘设计不当导致整批产品无法使用。作为使用Cadence Allegro进行PCB设计的工程师,Padstack Editor中的每个参数…...

从游戏画面Bug到图形学原理:一次深度测试失败的排查与透视矫正插值的深度理解
从游戏画面Bug到图形学原理:深度测试失败的排查与透视矫正插值解析 深夜调试游戏引擎时,屏幕上的三角形边缘突然出现诡异的闪烁——这种被称为"深度冲突"的现象,往往让开发者陷入漫长的调试循环。本文将以一个实际开发中的深度测试…...

3步极速配置:LXMusic音源完全指南
3步极速配置:LXMusic音源完全指南 【免费下载链接】LXMusic音源 lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/guoyue2010/lxmusic- 作为全网音乐资源的整合引擎,LXMusic音源为你提供一站式音乐解决方…...

UML类图实战:从设计到代码的精准映射
1. 为什么需要从UML类图到代码的精准映射? 第一次接触UML类图时,我总觉得它像是一张"纸上谈兵"的设计稿。直到在实际项目中踩过几次坑才明白,类图与代码之间的精准映射能力,是区分普通程序员和架构师的关键技能之一。 …...

云端开发新体验:code-server部署与多场景应用指南
1. 为什么你需要一个云端开发环境? 记得去年我同时参与三个项目时,每天要在办公室台式机、家里笔记本和平板电脑之间来回切换。每次换设备最头疼的就是开发环境不一致——Node.js版本不同、Python包缺失、配置文件没同步...有次紧急修复线上bug时&#x…...

2025届毕业生推荐的六大降AI率助手实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 针对内容创作范畴而言,AI生成内容也就是AIGC的运用愈发普遍,然而所生…...

开发AI应用时如何利用Taotoken实现模型的快速选型与A/B测试
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发AI应用时如何利用Taotoken实现模型的快速选型与A/B测试 在开发AI应用的过程中,选择合适的模型是影响最终效果与成本…...