bert 的MLM框架任务-梯度累积
参考:BEHRT/task/MLM.ipynb at ca0163faf5ec09e5b31b064b20085f6608c2b6d1 · deepmedicine/BEHRT · GitHub
class BertConfig(Bert.modeling.BertConfig):def __init__(self, config):super(BertConfig, self).__init__(vocab_size_or_config_json_file=config.get('vocab_size'),hidden_size=config['hidden_size'],num_hidden_layers=config.get('num_hidden_layers'),num_attention_heads=config.get('num_attention_heads'),intermediate_size=config.get('intermediate_size'),hidden_act=config.get('hidden_act'),hidden_dropout_prob=config.get('hidden_dropout_prob'),attention_probs_dropout_prob=config.get('attention_probs_dropout_prob'),max_position_embeddings = config.get('max_position_embedding'),initializer_range=config.get('initializer_range'),)self.seg_vocab_size = config.get('seg_vocab_size')self.age_vocab_size = config.get('age_vocab_size')class TrainConfig(object):def __init__(self, config):self.batch_size = config.get('batch_size')self.use_cuda = config.get('use_cuda')self.max_len_seq = config.get('max_len_seq')self.train_loader_workers = config.get('train_loader_workers')self.test_loader_workers = config.get('test_loader_workers')self.device = config.get('device')self.output_dir = config.get('output_dir')self.output_name = config.get('output_name')self.best_name = config.get('best_name')file_config = {'vocab':'', # vocabulary idx2token, token2idx'data': '', # formated data 'model_path': '', # where to save model'model_name': '', # model name'file_name': '', # log path
}
create_folder(file_config['model_path'])global_params = {'max_seq_len': 64,'max_age': 110,'month': 1,'age_symbol': None,'min_visit': 5,'gradient_accumulation_steps': 1
}optim_param = {'lr': 3e-5,'warmup_proportion': 0.1,'weight_decay': 0.01
}train_params = {'batch_size': 256,'use_cuda': True,'max_len_seq': global_params['max_seq_len'],'device': 'cuda:0'
}模型:
BertVocab = load_obj(file_config['vocab'])
ageVocab, _ = age_vocab(max_age=global_params['max_age'], mon=global_params['month'], symbol=global_params['age_symbol'])data = pd.read_parquet(file_config['data'])
# remove patients with visits less than min visit
data['length'] = data['caliber_id'].apply(lambda x: len([i for i in range(len(x)) if x[i] == 'SEP']))
data = data[data['length'] >= global_params['min_visit']]
data = data.reset_index(drop=True)Dset = MLMLoader(data, BertVocab['token2idx'], ageVocab, max_len=train_params['max_len_seq'], code='caliber_id')
trainload = DataLoader(dataset=Dset, batch_size=train_params['batch_size'], shuffle=True, num_workers=3)model_config = {'vocab_size': len(BertVocab['token2idx'].keys()), # number of disease + symbols for word embedding'hidden_size': 288, # word embedding and seg embedding hidden size'seg_vocab_size': 2, # number of vocab for seg embedding'age_vocab_size': len(ageVocab.keys()), # number of vocab for age embedding'max_position_embedding': train_params['max_len_seq'], # maximum number of tokens'hidden_dropout_prob': 0.1, # dropout rate'num_hidden_layers': 6, # number of multi-head attention layers required'num_attention_heads': 12, # number of attention heads'attention_probs_dropout_prob': 0.1, # multi-head attention dropout rate'intermediate_size': 512, # the size of the "intermediate" layer in the transformer encoder'hidden_act': 'gelu', # The non-linear activation function in the encoder and the pooler "gelu", 'relu', 'swish' are supported'initializer_range': 0.02, # parameter weight initializer range
}conf = BertConfig(model_config)
model = BertForMaskedLM(conf)model = model.to(train_params['device'])
optim = adam(params=list(model.named_parameters()), config=optim_param)计算准确率:
def cal_acc(label, pred):logs = nn.LogSoftmax()label=label.cpu().numpy()ind = np.where(label!=-1)[0]truepred = pred.detach().cpu().numpy()truepred = truepred[ind]truelabel = label[ind]truepred = logs(torch.tensor(truepred))outs = [np.argmax(pred_x) for pred_x in truepred.numpy()]precision = skm.precision_score(truelabel, outs, average='micro')return precision开始训练:
def train(e, loader):tr_loss = 0temp_loss = 0nb_tr_examples, nb_tr_steps = 0, 0cnt= 0start = time.time()for step, batch in enumerate(loader):cnt +=1batch = tuple(t.to(train_params['device']) for t in batch)age_ids, input_ids, posi_ids, segment_ids, attMask, masked_label = batchloss, pred, label = model(input_ids, age_ids, segment_ids, posi_ids,attention_mask=attMask, masked_lm_labels=masked_label)if global_params['gradient_accumulation_steps'] >1:loss = loss/global_params['gradient_accumulation_steps']loss.backward()temp_loss += loss.item()tr_loss += loss.item()nb_tr_examples += input_ids.size(0)nb_tr_steps += 1if step % 200==0:print("epoch: {}\t| cnt: {}\t|Loss: {}\t| precision: {:.4f}\t| time: {:.2f}".format(e, cnt, temp_loss/2000, cal_acc(label, pred), time.time()-start))temp_loss = 0start = time.time()if (step + 1) % global_params['gradient_accumulation_steps'] == 0:optim.step()optim.zero_grad()print("** ** * Saving fine - tuned model ** ** * ")model_to_save = model.module if hasattr(model, 'module') else model # Only save the model it-selfcreate_folder(file_config['model_path'])output_model_file = os.path.join(file_config['model_path'], file_config['model_name'])torch.save(model_to_save.state_dict(), output_model_file)cost = time.time() - startreturn tr_loss, cost保存结果:
f = open(os.path.join(file_config['model_path'], file_config['file_name']), "w")
f.write('{}\t{}\t{}\n'.format('epoch', 'loss', 'time'))
for e in range(50):loss, time_cost = train(e, trainload)loss = loss/data_lenf.write('{}\t{}\t{}\n'.format(e, loss, time_cost))
f.close() 某大模型对上面代码梯度累积的解释:
gradient_accumulation_steps 是一个用于在训练过程中累积梯度的参数。它的作用是在每次更新模型参数之前,累积多个 batch 的梯度,然后进行一次参数更新。这个技巧有助于在显存受限的情况下仍能使用较大的 batch size,并且可以稳定模型的训练过程。
对于BERT的MLM任务来说,通常会使用梯度累积,因为BERT是一个比较大的模型,使用较大的batch size可能会导致显存不足的问题,特别是在GPU资源受限的情况下。梯度累积可以帮助解决这个问题。
在你提供的代码中,gradient_accumulation_steps 的值被用来判断是否要对 loss 进行除法操作。如果 gradient_accumulation_steps 大于1,那么会将 loss 除以 gradient_accumulation_steps,以确保在多个batch的梯度累积后对参数进行更新。这是一个常见的做法。
因此,可以说对于BERT的MLM任务,使用梯度累积是一种常见的做法,特别是在资源受限的情况下。
相关文章:

bert 的MLM框架任务-梯度累积
参考:BEHRT/task/MLM.ipynb at ca0163faf5ec09e5b31b064b20085f6608c2b6d1 deepmedicine/BEHRT GitHub class BertConfig(Bert.modeling.BertConfig):def __init__(self, config):super(BertConfig, self).__init__(vocab_size_or_config_json_fileconfig.get(vo…...
Nginx配置/.well-known/pki-validation/
当你需要在Nginx上配置.well-known/pki-validation/时,这通常是为了支持SSL证书的自动续订或其他验证目的。以下是配置步骤: 创建目录结构: 在你的网站根目录下创建一个名为.well-known的目录(SSL证书申请之如何创建/.well-known/…...
)
iOS LQG开发框架(持续更新)
基本规则 开发便利性为前提,妥协性能可维护性为前提可读性MVC各部分职责一定要清晰,controll类里面功能尽量抽离成helper,功能一定要清晰,这个非常重要,对代码可读性提升非常高方法内部尽量使用局部变量,最…...

Python 自动化脚本系列:第3集
21. 使用 cryptography 自动化文件加密 Python 的 cryptography 库提供了一种安全的方式,使用对称加密算法对文件进行加密和解密。你可以自动化加密和解密文件的过程来保护敏感数据。 示例:文件加密和解密 假设你想使用对称加密算法加密一个文件&…...
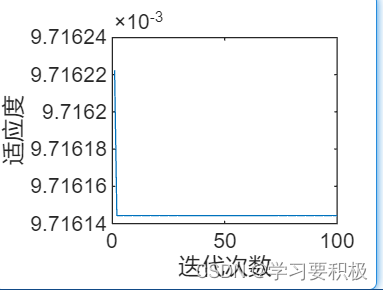
Matlab-粒子群优化算法实现
文章目录 一、粒子群优化算法二、相关概念和流程图三、例题实现结果 一、粒子群优化算法 粒子群优化算法起源于鸟类觅食的经验,也就是一群鸟在一个大空间内随机寻找食物,目标是找到食物最多的地方。以下是几个条件: (1) 所有的鸟都会共享自己的位置以及…...

python 新特性
文章目录 formatted字符串字面值formatted字符串支持 字符串新方法变量类型标注二进制表示中数字为1的数量统计字典的三个方法新增mapping属性函数zip()新增strict参数dataclass字典合并match 语法 formatted字符串字面值 formatted字符串是带有’f’字符前缀的字符串…...
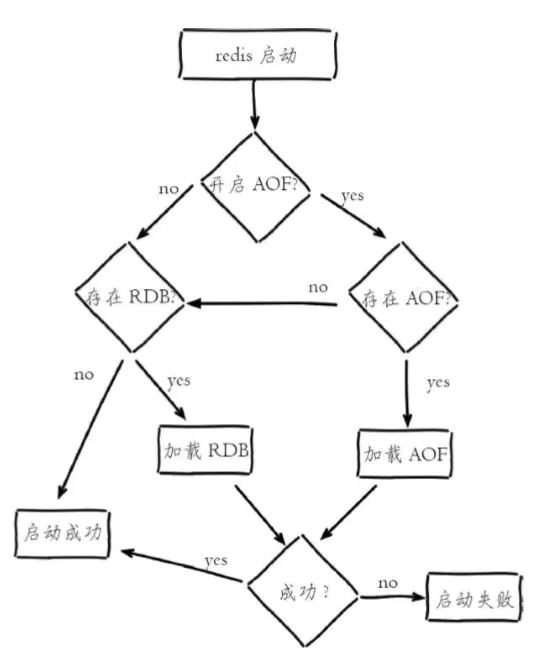
十一、Redis持久化-RDB、AOF
Redis提供了两种持久化数据的方式。一种是RDB快照,另一种是AOF日志。RDB快照是一次全量备份,AOF日志是连续的增量备份。RDB快照是以二进制的方式存放Redis中的数据,在存储上比较紧凑;AOF日志记录的是对内存数据修改的指令文本记录…...
)
Oracle闪回数据库【Oracle闪回技术】(二)
理解Oracle闪回级别【Oracle闪回技术】(一)-CSDN博客 Oracle默认是不开启闪回数据库的。如果开启闪回数据库的前提条件是,开启Oracle归档模式并启用闪回恢复区。 因为闪回日志文件存放在闪回恢复区中,如果在RAC环境下,必须将闪回恢复区存储在集群文件或者ASM文件中。 一…...

简单负载均衡
题目描述 某工程师为了解决服务器负载过高的问题,决定使用多个服务器来分担请求消息。 现给定 k 台服务器(编号从 1 到 k),以及一批请求消息的信息,格式为到达时刻 负载大小,消息说明: 每个时刻…...
Portforge:一款功能强大的轻量级端口混淆工具
关于Portforge Portforge是一款功能强大的轻量级端口混淆工具,该工具使用Crystal语言开发,可以帮助广大研究人员防止网络映射,这样一来,他人就无法查看到你设备正在运行(或没有运行)的服务和程序了。简而言…...

1.8. 离散时间鞅-无界停时定理与随机游走
无界停时定理与随机游走 无界停时定理与随机游走1. 无界停时定理1.1. 一致可积1.2. 非一致可积2. 应用于随机游动-鞅方法2.1. 随机游走构造的鞅2.2. 对称简单随机游走无界停时定理与随机游走 1. 无界停时定理 本节给出一致可积下鞅的无界停时定理,说明一致可积下鞅的停止过程…...
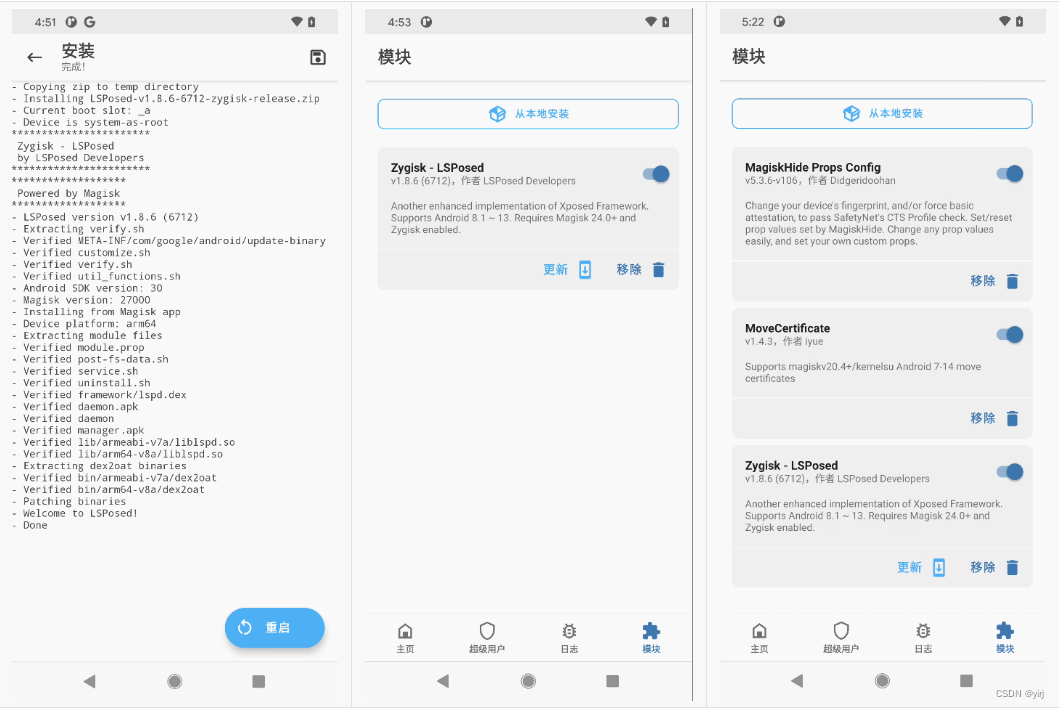
Google Pixel4手机刷机+Root+逆向环境详细教程
Google Pixel4手机刷机Root逆向环境配置详细教程 刷机工具下载 Windows10、Google Pixel4手机当前安卓10系统、adb工具、要刷的谷歌原生的Android11最新刷机包、安装google usb驱动、美版临时twrp-3.6.0_11-0-flame.img和美版永久twrp-installer-3.6.0_11-0-flame.zip、Magis…...
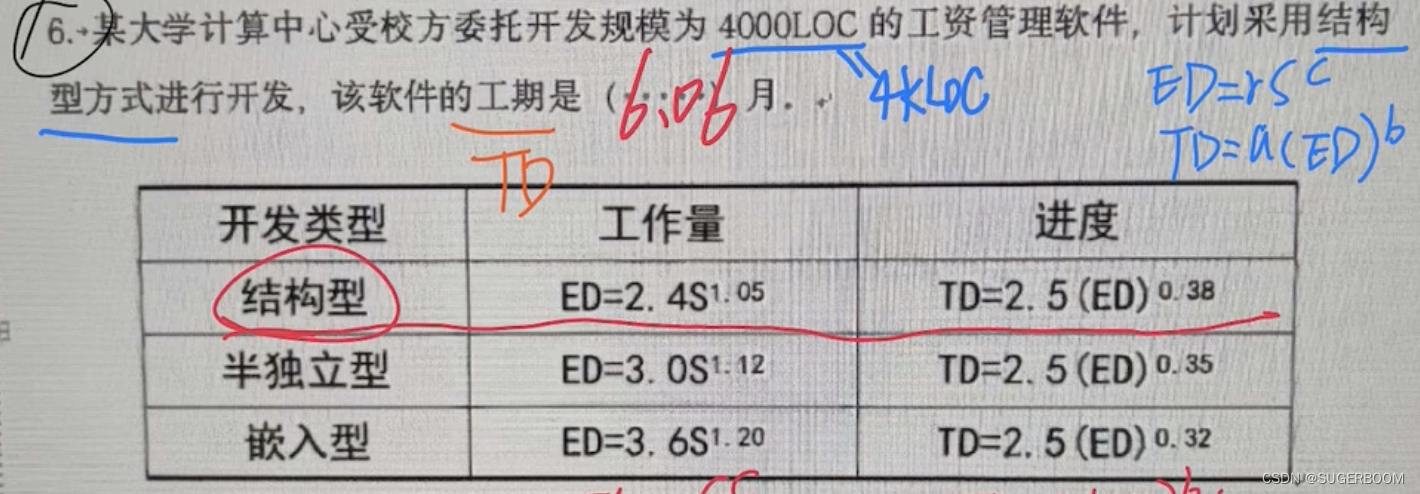
IT项目管理-小题计算【太原理工大学】
1.合同总价问题 问承包商的利润是? 实际利润目标利润(目标成本-实际成本)*卖方分担比例 解:10 000(100 000 - 90 000)* 0.2 12 000(元) 实际成本有时也写作最终成本,问承…...
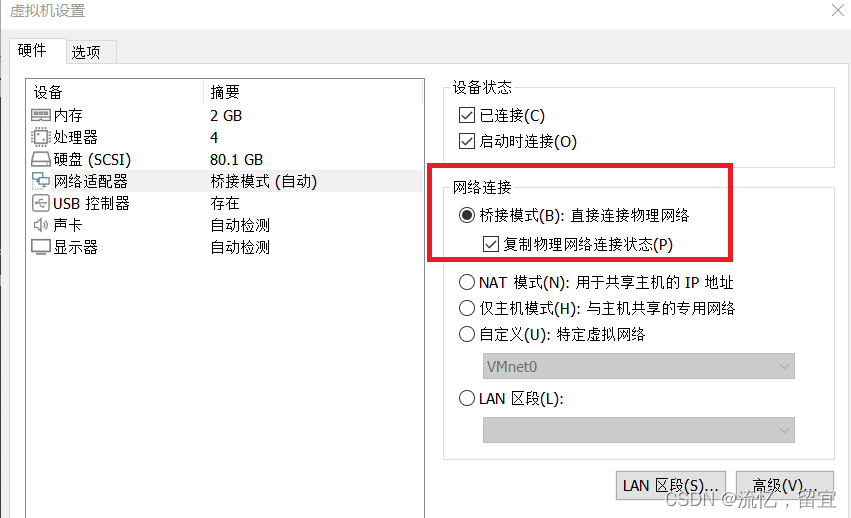
ARP欺骗使局域网内设备断网
一、实验准备 kali系统:可使用虚拟机软件模拟 kali虚拟机镜像链接:https://www.kali.org/get-kali/#kali-virtual-machines 注意虚拟机网络适配器采用桥接模式 局域网内存在指定断网的设备 二、实验步骤 打开kali系统命令行:ctrlaltt可快…...

Android动画(四):PathMeasure实现路径动画
文章概览 1 PathMeasure概述2 实现路径加载动画3 实现箭头加载动画4 实现操作成功动画 本系列将介绍以下内容: Android动画 1 PathMeasure概述 PathMeasure是一个单独的类,其全部源码如下(请详细研读注释): package…...

HTTP 连接详解
概述 世界上几乎所有的 HTTP 通信都是由 TCP/IP 承载的,客户端可以打开一条TCP/IP连接,连接到任何地方的服务器。一旦连接建立,客户端和服务器之间交换的报文就永远不会丢失、受损或失序 TCP(Transmission Control Protocol&…...
练习题(2024/5/12)
1二分查找 给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。 示例 1: 输入: nums [-1,0,3,5,9,12], target 9 输出: 4…...

Day50代码随想录动态规划part12:309.最佳买卖股票时机含冷冻期、714.买卖股票的最佳时机含手续费
Day50 动态规划part12 股票问题 309.最佳买卖股票时机含冷冻期 leetcode题目链接:309. 买卖股票的最佳时机含冷冻期 - 力扣(LeetCode) 题意:给定一个整数数组,其中第 i 个元素代表了第 i 天的股票价格 。设计一个算…...

【软考】scrum的步骤
目录 1. 明确产品愿景和需求2. 制定计划和任务列表3. 进行迭代开发(Sprint)4. Sprint评审会议5. Sprint回顾会议6. 重复迭代 1. 明确产品愿景和需求 1.这个过程通常由项目所有者和利益相关者参与,目的是确保整个团队对项目的目标和方向有清晰…...
【C语言】编译与链接
✨✨欢迎大家来到Celia的博客✨✨ 🎉🎉创作不易,请点赞关注,多多支持哦🎉🎉 所属专栏:C语言 个人主页:Celias blog~ 目录 引言 一、翻译环境 1.1 编译 1.1.1 预处理 1.1.2 编译 …...

DocQuery最佳实践:企业文档自动化处理的10个技巧
DocQuery最佳实践:企业文档自动化处理的10个技巧 【免费下载链接】docquery An easy way to extract information from documents 项目地址: https://gitcode.com/gh_mirrors/do/docquery DocQuery是一款强大的文档信息提取工具,能轻松分析半结构…...

PolyHook 2.0导入导出表钩子:IatHook和EatHook的10个核心技巧
PolyHook 2.0导入导出表钩子:IatHook和EatHook的10个核心技巧 【免费下载链接】PolyHook_2_0 C20, x86/x64 Hooking Libary v2.0 项目地址: https://gitcode.com/gh_mirrors/po/PolyHook_2_0 PolyHook 2.0是一个功能强大的C20 x86/x64钩子库,提供…...
C166架构_testclear_函数原理与应用解析
1. C166开发中的_testclear_函数使用解析在嵌入式C166架构开发过程中,开发人员经常会遇到一些编译器特有的内置函数(intrinsic functions)使用问题。其中_testclear_函数就是一个典型的例子,它用于原子性地测试并清除某个内存位置的值。最近我在调试一个…...

为什么你的Perplexity搜索总返回噪音结果?7步精准提示工程诊断流程
更多请点击: https://intelliparadigm.com 第一章:Perplexity搜索结果噪音现象的本质剖析 Perplexity 作为基于大语言模型的语义搜索引擎,其结果页中高频出现的“噪音”并非传统关键词匹配失准所致,而是源于其底层推理机制与用户…...
)
别再手动写代码了!用Coze工作流的Code节点,让AI帮你搞定Python/JS脚本(附IDE调试技巧)
解放双手:用Coze工作流Code节点实现智能编码全攻略 在代码的世界里,我们常常陷入重复劳动的泥潭——那些格式固定的API调用、千篇一律的数据处理、周而复始的脚本编写。有没有一种方式,能让我们从这些机械性编码中解脱出来,把创造…...
)
Perplexity引用格式设置全链路解析(含BibTeX/CSL/DOI自动映射底层逻辑)
更多请点击: https://kaifayun.com 第一章:Perplexity引用格式设置全链路解析(含BibTeX/CSL/DOI自动映射底层逻辑) Perplexity 在学术写作支持中并非原生集成引文管理,但其底层可对接外部文献元数据服务,实…...

std::accumulate算法深度解析:从求和到通用折叠,解锁STL隐藏的瑞士军刀
1. 重新认识std::accumulate:不只是求和工具 第一次接触std::accumulate时,大多数人都是从求和开始的。确实,这个算法默认行为就是对范围内的元素进行累加。但如果你只把它当作一个高级计算器,那就太小看这个STL中的"瑞士军刀…...

告别通用OCR:如何用PaddleOCR针对银行卡场景做定制化检测模型优化?
告别通用OCR:如何用PaddleOCR针对银行卡场景做定制化检测模型优化? 银行卡识别一直是金融科技领域的高频需求,但通用OCR模型在应对银行卡这类特殊场景时往往力不从心。我曾参与过多个银行的移动端项目,亲眼见证过通用模型在识别卡…...

技术从业者的时间管理:如何平衡工作、学习和生活
在敏捷开发大行其道、技术迭代日新月异的当下,软件测试从业者正面临着前所未有的时间压力。一边是项目交付的紧迫期限、层出不穷的缺陷排查需求,一边是自动化测试工具、AI测试框架等新技术的学习焦虑,再加上对个人生活品质的追求,…...

魔兽争霸3终极优化指南:如何用WarcraftHelper实现高帧率宽屏体验
魔兽争霸3终极优化指南:如何用WarcraftHelper实现高帧率宽屏体验 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专为…...