Python 原生爬虫
Python
- 描述
- 代码
描述
- 爬网站的页面
- 配合正则表达式
- 设置定时任务
仅学习参考,切勿使用其他用途
代码
import re
import schedule
import timefrom urllib.request import urlopenclass Spider:def __init__(self):# 初始化代码...pass# self.start_schedule()# 需要爬的网址url = 'https://www.**.com/game/'# 可以匹配文档中任何一个位置# 贪婪匹配,因为没有?# \s 空白符# \S 非空白符# [\s\S]任意字符# [\s\S]* 0个到任意多个字符# [\s\S]*? 0个字符,匹配任何字符前的位置# ([\s\S]*?) 加括号就可以排除 <div></div> 标签, 只获取里面的信息# ------------------------------# root_pattern = r'<div class="w-video-module-videolist w-video-module-videolist-withtags">(.*?)</div>'root_pattern = '<div class="w-video-module-videolist w-video-module-videolist-withtags">([\s\S]*?)</div>'# 正则:获取主播名称name_pattern = '<span class="intro">([\s\S]*?)</span>'# 正则:获取标题title_pattern = '<span class="title">([\s\S]*?)</span>'# 正则:获取视频浏览量watched_pattern = '<i>([\s\S]*?)</i>'# 定义一个私有方法, 读取URL里面内容def __fetch_content(self):try:# 实例里面读取类变量response = urlopen(Spider.url)# 读取 url 内容htmls = response.read()# 设置字符串编码 UTF-8htmls = str(htmls, encoding='utf-8')# print(htmls)return htmlsexcept Exception as e:print("Error decoding the response:", e)# 定义一个私有方法# 1. 分析html文本, 通过正则表达式获取 <div class="w-video-module-videolist w-video-module-videolist-withtags"> 标签里的内容# 2. 去除多余的 '/n' 字符# 3. for 循环解析# 3.1. 获取到的内容, 使用正则表达式获取 <span class="intro"> 标签里的内容# 3.2. 获取到的内容, 使用正则表达式获取 <span class="title"> 标签里的内容# 3.3. 获取到的内容, 使用正则表达式获取 <i> 标签里的内容# 4. 通过for循环解析得到的数据, 定义键值对# 4.1 存放到字典里面 (类似Java的集合)def __analysis(self, htmls):# 定义字典anchors = []# 使用正则表达式转换成需要获取的内容root_html = re.findall(Spider.root_pattern, htmls)# 使用正则表达式去除每个元素中带有 \n 的root_html = [re.sub('\n', '', item) for item in root_html]for html in root_html:name = re.findall(Spider.name_pattern, html)title = re.findall(Spider.title_pattern, html)watched = re.findall(Spider.watched_pattern, html)# 定义字典的键值对anchor = {'name': name,'title': title,'watched': watched}# 添加到字典里面anchors.append(anchor)# print(anchors)return anchors# 定义一个私有方法: 用于组装List数据def __refine(self, anchors):# 这个函数的作用是对传入的 anchors 列表进行处理,将每个字典元素中的 'name'、'title' 和 'watched' 键对应的值组合成一个新的字典,# 并将这些新的字典对象存储在 refined_data 列表中# 这是通过使用列表推导式和 zip() 函数实现的,zip() 函数将三个列表中对应位置的元素打包成一个元组,然后通过列表推导式将每个元组中的元素取出来,组合成一个新的字典对象# 最后,函数返回处理后的 refined_data 列表## refined_data = [{# 'name': name,# 'title': title,# 'watched': watched# } for name, title, watched in zip(anchors[0]['name'], anchors[0]['title'], anchors[0]['watched'])]# # print(refined_data)# return refined_data# 使用了 lambda 函数来创建一个匿名函数,该函数接受一个元组 x 作为参数,并返回一个包含 'name'、'title' 和 'watched' 键的字典# 然后,我们使用 map 函数将这个 lambda 函数应用于 zip(anchors[0]['name'], anchors[0]['title'], anchors[0]['watched']) 返回的元组序列中的每个元组,# 最终得到处理后的字典对象列表refined_data = list(map(lambda x: {'name': x[0], 'title': x[1], 'watched': x[2]},zip(anchors[0]['name'], anchors[0]['title'], anchors[0]['watched'])))# print(refined_data)return refined_data# 定义一个私有方法:# 排序规则: 包含“万”表示的字符串转换为数字, 并且转换成整型(int)def __sort_seed(self, anchor):# 从anchor字典中获取"watched"键对应的值,然后通过"正则表达式"找到其中的数字部分并转换为浮点数r = re.findall('[1-9]\d*.?', anchor["watched"])watched = float(r[0])if '万' in anchor["watched"]:# 如果值中包含"万"这个字符,就将数字乘以10000watched = watched * 10000return watched# 定义一个私有方法: 排序函数def __soft(self, anchors):# 根据观看数量倒序排序anchors = sorted(anchors, key=self.__sort_seed, reverse=True)return anchors# 定义一个私有方法: 展示数据,将已经排序好的数据打印出来def __show(self, anchors):# 不带序号# for a in anchors:# print(a['name'] + '---' + a['title'] + '---' + str(a['watched']))# 带序号print("---------------------[王者荣耀]---------------------")print("----------------" + time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) + "----------------")print("---------------------------------------------------")for a in range(0, len(anchors)):print("Seq.", a + 1, ": ","Name: ", anchors[a]['name'],", Title: ", anchors[a]['title'],", Watched: ", anchors[a]['watched'])# 定义一个公有方法: 入口方法def go(self):# 获取HTML内容htmls = self.__fetch_content()# 分析HTML内容anchors = self.__analysis(htmls)# 组装List数据anchors = self.__refine(anchors)# 排序anchors = self.__soft(anchors)# 展现数据self.__show(anchors)# 设置定时任务def start_schedule(self):schedule.every(30).seconds.do(lambda: self.go())# 循环执行定时任务while True:schedule.run_pending()time.sleep(1)# 创建类的实例并开始定时任务
spider = Spider()
# 调用入口方法
spider.go()
仅学习参考,切勿使用其他用途
相关文章:

Python 原生爬虫
Python 描述代码 描述 爬网站的页面配合正则表达式设置定时任务 仅学习参考,切勿使用其他用途 代码 import re import schedule import timefrom urllib.request import urlopenclass Spider:def __init__(self):# 初始化代码...pass# self.start_schedule()# 需要…...
数据结构---经典链表OJ
乐观学习,乐观生活,才能不断前进啊!!! 我的主页:optimistic_chen 我的专栏:c语言 点击主页:optimistic_chen和专栏:c语言, 创作不易,大佬们点赞鼓…...

HTML_CSS学习:CSS像素与颜色
一、像素 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>像素</title> </head><style>.atguigu1{/*单位可以是cm,但不能是m,dm*/width: 1cm;height: 1cm;background-c…...

华为交换机配置导出备份python脚本
一、脚本编写思路 (一)针对设备型号 主要针对华为(Huawei)和华三(H3C)交换机设备的配置备份 (二)导出前预处理 1.在配置导出前,自动打开crt软件或者MobaXterm软件&am…...

DS:时间复杂度和空间复杂度
欢迎各位来到 Harper.Lee 的学习世界! 博主主页传送门:Harper.Lee的博客主页 想要一起进步的uu欢迎来后台找我哦! 本片博客主要介绍的是数据结构中关于算法的时间复杂度和空间复杂度的概念。 一、算法 1.1 什么是算法? 算法(Alg…...

AI跟踪报道第41期-新加坡内哥谈技术-本周AI新闻:本周Al新闻: 准备好了吗?事情即将変得瘋狂
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

Go 之 interface接口理解
go语言并没有面向对象的相关概念,go语言提到的接口和java、c等语言提到的接口不同,它不会显示的说明实现了接口,没有继承、子类、implements关键词。go语言通过隐性的方式实现了接口功能,相对比较灵活。 interface是go语言的一大…...
简约在线生成短网址系统源码 短链防红域名系统 带后台
简约在线生成短网址系统源码 短链防红域名系统 带后台 安装教程:访问 http://你的域名/install 进行安装 源码免费下载地址抄笔记 (chaobiji.cn)https://chaobiji.cn/...

设置默认表空间和重命名
目录 设置默认表空间 创建的临时表空间 tspace4 修改为默认临时表空间 创建的永久性表空间 tspace3 修改为默认永久表空间 重命名表空间 将表空间 tspace3 修改为 tspace3_1 Oracle从入门到总裁:https://blog.csdn.net/weixin_67859959/article/details/13520…...

Hive大表join大表如何调优
目录 一、调优思路1、SQL优化1.1 大小表join1.2 大大表join 2、insert into替换union all3、排序order by换位sort by4、并行执行5、数据倾斜优化6、小文件优化 二、实战2.1 场景2.2 限制所需的字段,间接mapjoin2.2 解决异常值倾斜,如NULL加随机数打散2.…...

SAF文件选择、谷歌PhotoPicker图片视频选择与真实路径转换
一、构建选择文件与回调方法 //文件选择回调ActivityResultLauncher<String[]> pickFile registerForActivityResult(new ActivityResultContracts.OpenDocument(), uri->{if (uri ! null) {Log.e("cxy", "返回的uri:" uri);Log.e("cxy&q…...

java可变参数
前言 我们虽然能够用重载实现,但多个参数无法弹性匹配 代码 class mycalculator{//下面的四个calculate方法构成了重载//计算2个数的和,3个数的和,4,5,6个数的和// public void calculate(int n1){// System.out.…...

Flutter 中的 Expanded 小部件:全面指南
Flutter 中的 Expanded 小部件:全面指南 在 Flutter 中,Expanded 是一个用于控制子控件占据可用空间的布局小部件,通常与 Row、Column 或 Flex 等父级布局小部件一起使用。Expanded 允许你创建灵活的布局,其中子控件可以按照指定…...
[Kubernetes] KubeKey 部署 K8s v1.28.8
文章目录 1.K8s 部署方式2.操作系统基础配置3.安装部署 K8s4.验证 K8s 集群5.部署测试资源 1.K8s 部署方式 kubeadm: kubekey, sealos, kubespray二进制: kubeaszrancher 2.操作系统基础配置 主机名内网IP外网IPmaster192.168.66.2139.198.9.7node1192.168.66.3139.198.40.17…...

C# 与 Qt 的对比分析
C# 与 Qt 的对比分析 目录 C# 与 Qt 的对比分析 1. 语言特性 2. 开发环境 3. 框架和库 4. 用户界面设计 5. 企业级应用 6. 性能考量 在软件开发领域,C# 和 Qt 是两种常用的技术栈,它们分别在.NET平台和跨平台桌面应用开发中占据重要位置。本文将深…...
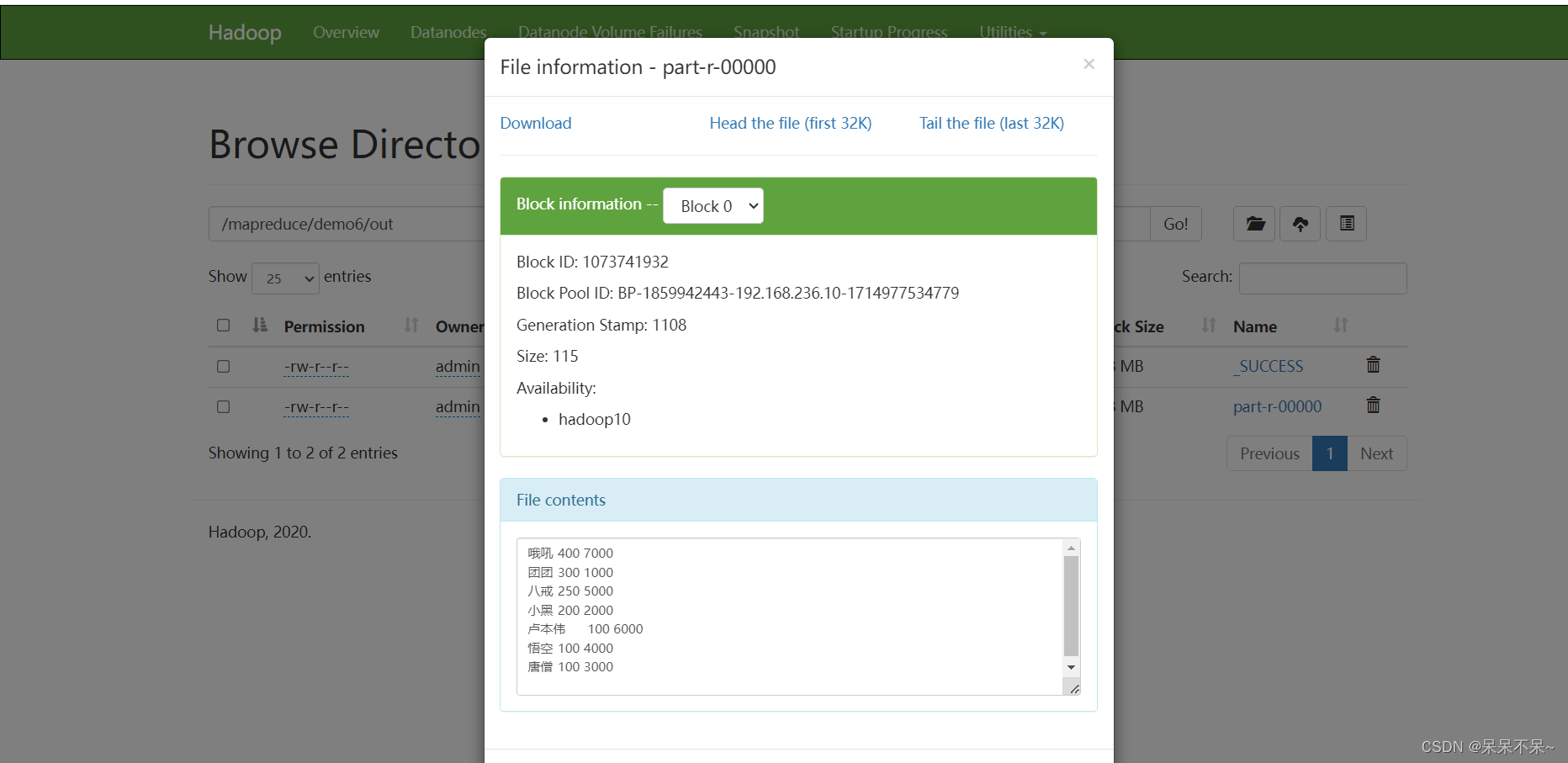
MapReduce | 二次排序
1.需求 主播数据--按照观众人数降序排序,如果观众人数相同,按照直播时长降序 # 案例数据 用户id 观众人数 直播时长 团团 300 1000 小黑 200 2000 哦吼 400 7000 卢本伟 100 6000 八戒 250 5000 悟空 100 4000 唐僧 100 3000 # 期望结果 哦吼 4…...

Java后端初始化项目(项目模板)
介绍 emmmm,最近看了一些网络资料,也是心血来潮,想自己手工搭建一个java后端的初始化项目模板来简化一下开发,也就发一个模板的具体制作流程,(一步一步搭建,从易到难) okÿ…...
)
electron 多窗口 vuex/pinia 数据状态同步简易方案(利用 LocalStorage)
全局 stroe 添加 mutations 状态同步方法 // 用于其他窗口同步 vuex 中的 DeviceTcpDataasyncDeviceTcpData(state: StateType, data: any) {state.deviceTcpData data},App.vue 里 onMounted(() > {console.log("App mounted");/*** vuex 多窗口 store 同步*//…...

自定义数据集图像分类实现
模型训练 要使用自己的图片分类数据集进行训练,这意味着数据集应该包含一个目录,其中每个子目录代表一个类别,子目录中包含该类别的所有图片。以下是一个使用Keras和TensorFlow加载自定义图片数据集进行分类训练的例子。 我们自己创建的数据集…...

【C++】手搓读写ini文件源码
【C】手搓读写ini文件源码 思路需求:ini.hini.cppconfig.confmian.cpp 思路 ini文件是一种系统配置文件,它有特定的格式组成。通常做法,我们读取ini文件并按照ini格式进行解析即可。在c语言中,提供了模板类的功能,所以…...

智慧树视频自动播放插件:3分钟搞定所有课程学习的终极指南
智慧树视频自动播放插件:3分钟搞定所有课程学习的终极指南 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台繁琐的手动操作而烦恼吗&#x…...

告别网络玄学:手把手教你用寄存器调试法搞定YT8521 PHY‘ping不通’故障
寄存器调试实战:用YT8521 PHY案例解析RGMII时序优化 当一块嵌入式开发板的网络接口出现"能发不能收"的诡异现象时,多数工程师的第一反应往往是检查驱动配置或网线连接。但在实际项目中,这种看似简单的"ping不通"问题&…...

终极指南:3步掌握Path of Building装备规划与角色构建
终极指南:3步掌握Path of Building装备规划与角色构建 【免费下载链接】PathOfBuilding Offline build planner for Path of Exile. 项目地址: https://gitcode.com/gh_mirrors/pat/PathOfBuilding Path of Building是一款强大的离线Build规划工具࿰…...

云英谷开启招股:拟募资11亿港元 5月27日上市 小米华为红杉是股东
雷递网 雷建平 5月18日云英谷科技股份有限公司(简称:“云英谷”,股票代码:“03310”)日前开启招股,准备2026年5月27日在港交所上市。云英谷发行价为20.81港元,发行5285.92万股,募资总…...
)
保姆级教程:用kitti2bag把KITTI数据集转成ROS bag,新手避坑指南(附2011_09_26小数据集下载)
从KITTI到ROS Bag:零基础实战转换指南 第一次接触KITTI数据集和ROS时,我完全被那些复杂的文件结构和专业术语搞晕了。作为一个计算机视觉和机器人领域的经典数据集,KITTI包含了丰富的传感器数据,但直接使用这些原始数据对新手来说…...

网易云音乐API深度解析:模块化接口开发与实战应用指南
网易云音乐API深度解析:模块化接口开发与实战应用指南 【免费下载链接】NeteaseCloudMusicApiBackup 项目地址: https://gitcode.com/gh_mirrors/ne/NeteaseCloudMusicApiBackup 在当今音乐应用开发领域,后端服务的稳定性和可扩展性至关重要。网…...

AM62A1-Q1汽车视觉处理器:低功耗、高集成度的车载视觉解决方案
1. 项目概述:为什么我们需要一颗“小而美”的汽车视觉处理器?最近在做一个车载环视和DMS(驾驶员监控系统)的预研项目,客户对成本和功耗卡得非常死,但功能要求却一点没降:需要同时处理1到2路摄像…...

如何高效掌握LAMMPS:分子动力学模拟的完整实战指南
如何高效掌握LAMMPS:分子动力学模拟的完整实战指南 【免费下载链接】lammps Public development project of the LAMMPS MD software package 项目地址: https://gitcode.com/gh_mirrors/la/lammps 想要快速掌握强大的分子动力学模拟工具吗?LAMM…...
)
Perplexity招聘搜索失效?别再用Google了!工程师亲测有效的4层穿透式检索法(含Chrome插件配置清单)
更多请点击: https://kaifayun.com 第一章:Perplexity招聘信息搜索 Perplexity AI 作为一家快速发展的生成式人工智能公司,其招聘动态常通过官方渠道与技术社区同步更新。掌握高效、可复现的招聘信息检索方法,对求职者与行业观察…...

OpenClaw 2.7.5 Windows 一键部署教程|零配置开箱即用
前言 本地 AI 智能体技术持续迭代,私有化部署、数据安全可控、低门槛快速落地,已成为用户选型的核心考量。开源轻量化 AI 智能体 OpenClaw 2.7.5 版本完成全面优化升级,在环境适配性、服务稳定性与模型集成能力上均有显著提升,原…...