5.13学习日志
Pytorch 神经网络基础
1.模型构造
1》层和块
块可以描述单个层,由多个层组成的组件或者模型本身
块由类表示,类的任何子类都必须定义一个将其输入转换为输出的前向传播函数。为了计算梯度,块必须具有反向传播函数
自定义块:
顺序块:
import torch
from torch import nn#输入
X=torch.rand(2,20)#顺序块
class MySequential(nn.Module):def __init__(self,*args):#*args是收集参数,相当于把若干个参数打包成一个来传入super().__init__()#调用父类的__init__函数for idx, block in enumerate(args):#遍历传入的神经网络层,并将它们以字符串索引作为键存储在 MySequential 实例的 _modules 属性中self._modules[str(idx)] = block#在模型参数初始化过程中,系统直到在_modules字典中查找需要初始化参数的子块def forward(self,X):for block in self._modules.values():#遍历 _modules 中的每个神经网络层X = block(X)#将当前层的输出作为下一层输入return Xnet=MySequential(nn.Linear(20,256),nn.ReLU(),nn.Linear(256,10))
a=net(X)print(a)在前向传播函数中执行代码
当sequential函数过于简单没法满足需求,可以在init和forward函数里进行自定义运算,继承nn.Module比继承Sequential更灵活的定义参数,和进行前向运算
import torch
from torch import nn
from torch.nn import functional as FX=torch.rand(2,20)class FixedHiddenMLP(nn.Module):def __init__(self):super().__init__()self.rand_weight = torch.rand((20,20),requires_grad=False)#随机生成一组权重常数,不参与反向传播梯度更新self.linear=nn.Linear(20,20)def forward(self,X):X = self.linear(X)X = F.relu(torch.mm(X,self.rand_weight)+1)#将输入X与权重相乘X = self.linear(X)while X.abs().sum()>1:#取绝对值之和X /= 2#使用 while 循环,如果输出张量的绝对值之和大于 1,则将输出张量除以 2,直到满足条件为止。这个操作可以视为一种归一化或缩放操作,以控制输出的数值范围return X.sum()net = FixedHiddenMLP()
a = net(X)
print(a)嵌套使用Module 的子类
嵌套体现在两个方面:
NestMLP类内部的self.net和self.linear形成了一个嵌套的子模块结构。
chimera 模块通过组合 NestMLP、线性层和 FixedHiddenMLP,形成了一个嵌套的计算流程。
import torch
from torch import nn
from torch.nn import functional as FX=torch.rand(2,20)class FixedHiddenMLP(nn.Module):def __init__(self):super().__init__()self.rand_weight = torch.rand((20,20),requires_grad=False)#随机生成一组权重常数,不参与反向传播梯度更新self.linear=nn.Linear(20,20)def forward(self,X):X = self.linear(X)X = F.relu(torch.mm(X,self.rand_weight)+1)#将输入X与权重相乘X = self.linear(X)while X.abs().sum()>1:#取绝对值之和X /= 2#使用 while 循环,如果输出张量的绝对值之和大于 1,则将输出张量除以 2,直到满足条件为止。这个操作可以视为一种归一化或缩放操作,以控制输出的数值范围return X.sum()class NestMLP(nn.Module):def __init__(self):super().__init__()self.net = nn.Sequential(nn.Linear(20,64),nn.ReLU(),nn.Linear(64,32),nn.ReLU())self.linear = nn.Linear(32,16)def forward(self,X):return self.linear(self.net(X))chimera = nn.Sequential(NestMLP(),nn.Linear(16,20),FixedHiddenMLP())
chimera(X)2.参数管理
参数访问:
import torch
from torch import nn
from torch.nn import functional as Fnet = nn.Sequential(nn.Linear(4,8),nn.ReLU(),nn.Linear(8,1))
X = torch.rand(size=(2,4))
net(X)print(net[2].state_dict())#检查第二个全连接层即Linear(8,1)的参数
#OrderedDict([('weight', tensor([[ 0.2360, 0.1646, 0.0861, 0.0126, -0.0548, 0.1074, 0.0612, -0.1232]])), ('bias', tensor([-0.1082]))])访问目标参数
print(type(net[2].bias))#访问第二个全连接层的偏移的类型
print(net[2].bias)#访问第二个全连接层的偏移
print(net[2].bias.data)#访问第二个全连接层的偏移的数值
'''<class 'torch.nn.parameter.Parameter'>
Parameter containing:
tensor([0.3516], requires_grad=True)
tensor([0.3516])'''print(net[2].weight.grad == None)#访问参数梯度,由于还没有开始反向传播,因此参数的梯度处于初始状态
#True一次性访问所有参数
print(*[(name,param.shape)for name, param in net[0].named_parameters()])
#('weight', torch.Size([8, 4])) ('bias', torch.Size([8]))
print(*[(name,param.shape)for name, param in net.named_parameters()])
#('0.weight', torch.Size([8, 4])) ('0.bias', torch.Size([8])) ('2.weight', torch.Size([1, 8])) ('2.bias', torch.Size([1]))从嵌套块收集参数
import torch
from torch import nn
from torch.nn import functional as FX=torch.rand(2,4)def block1():return nn.Sequential(nn.Linear(4,8),nn.ReLU(),nn.Linear(8,4),nn.ReLU())def block2():net = nn.Sequential()#创建一个空的 nn.Sequential 容器,用于按顺序组合多个 block1 模块for i in range(4):#嵌套net.add_module(f'block{i}',block1())#将四个block1()组合起来,用add_module的好处是可以传一个字符串的名字return(net)rgnet = nn.Sequential(block2(),nn.Linear(4,1))
output = rgnet(X)
print(output)
print(rgnet)显示嵌套结构
Sequential((0): Sequential((block0): Sequential((0): Linear(in_features=4, out_features=8, bias=True)(1): ReLU()(2): Linear(in_features=8, out_features=4, bias=True)(3): ReLU())(block1): Sequential((0): Linear(in_features=4, out_features=8, bias=True)(1): ReLU()(2): Linear(in_features=8, out_features=4, bias=True)(3): ReLU())(block2): Sequential((0): Linear(in_features=4, out_features=8, bias=True)(1): ReLU()(2): Linear(in_features=8, out_features=4, bias=True)(3): ReLU())(block3): Sequential((0): Linear(in_features=4, out_features=8, bias=True)(1): ReLU()(2): Linear(in_features=8, out_features=4, bias=True)(3): ReLU()))(1): Linear(in_features=4, out_features=1, bias=True)
)按照以上结构,可以分层访问特定参数
print(rgnet[0][1][0].bias.data)#表示第二个 block1 模块中的第一个子模块,即第一个线性层的偏置参数
#tensor([-0.1861, -0.0683, 0.3388, -0.4251, -0.3339, 0.2232, -0.1247, 0.0476])参数初始化:
内置初始化
def init_normal(m):if type(m) == nn.Linear:#检查传入的模块 m 的类型是否为全连接层nn.init.normal_(m.weight,mean=0,std=0.01)#权重参数初始化为均值为0,标准差为0.01的正态分布#或者初始化为1#nn.init.constant_(m.weight,1)nn.init.zeros_(m.bias)#偏置参数初始化为0net.apply(init_normal)#递归地遍历 net 的每个子模块,对于每个子模块,调用 init_normal 函数。
同样可以对不同的神经网络层使用不同的初始化方法:
net[0].apply()
net[2].apply()
自定义初始化
def my_init(m):if type(m) == nn.Linear:print("Init",*[(name,param.shape) for name,param in m.named_parameters()][0])nn.init.uniform_(m.weight,-10,10)#将该层的权重参数初始化为均匀分布,范围为 [-10, 10]m.weight.data *= m.weight.data.abs()>=5#将权重参数中绝对值小于 5 的元素设置为 0
net.apply(my_init)#将 my_init 函数应用于网络 net 的每个子模块
net[0].weight[:2]#[:2] 表示对权重参数进行切片操作,选取前两行可以直接设置参数
net[0].weight.data[:]+=1
net[0].weight.data[0,0] = 42
net[0].weight.data[0]参数绑定:
多个层间共享参数
shared = nn.Linear(8,8)
net = nn.Sequential(nn.Linear(4,8),nn.ReLU(),shared,nn.ReLU(),shared,nn.ReLU(),nn.Linear())
#第二个层和第四个层是相同的3.自定义层
和自定义块相似,只需要继承层类并实现前向传播功能
不带参数的层:
import torch
from torch import nn
from torch.nn import functional as FX=torch.FloatTensor([1,2,3,4,5])
class CenteredLayer(nn.Module):def __init__(self):super().__init__()def forward(self,X):return X-X.mean()#输入减均值,将均值变为0layer = CenteredLayer()
a=layer(X)
print(a)
#tensor([-2., -1., 0., 1., 2.])#将自定义层作为组件合并到网络中
net = nn.Sequential(nn.Linear(8,128),CenteredLayer())带参数的层:
class MyLinear(nn.Module):def __init__(self,in_units,units):#in_units是输入,units是输出super().__init__()self.weight = nn.Parameter(torch.randn(in_units,units))# torch.randn 函数生成一个服从标准正态分布的随机张量,形状为(in_units, units)self.bias = nn.Parameter(torch.randn(units,))#生成一个服从标准正态分布的随机向量,形状为(units,)def forward(self,X):linear = torch.matmul(X,self.weight.data)+self.bias.data#使用 torch.matmul对输入 X 和权重参数 self.weight.data 进行矩阵乘法运算#.data 属性访问权重参数的原始数据return F.relu(linear)#将线性输出传递给 ReLU 激活函数 F.reludense = MyLinear(5,3)
print(dense.weight)
'''tensor([[ 0.1203, 1.2635, -0.7978],[-1.4768, 1.0113, -0.8263],[-0.1474, 0.9414, -1.6847],[-1.4617, 0.7734, -1.3046],[-0.7199, -0.7151, 0.8831]], requires_grad=True)'''4.读写文件
加载和保存张量:
对于单个张量,直接调用load和save函数分别读写
x=torch.arange(4)
torch.save(x,'x-file')
torch.load('x-file')
可以存储一个张量列表,把它们读回内存
x=torch.arange(4)
y= torch.zeros(4)
torch.save([x,y],'x-files')
x2,y2=torch.load('x-files')
print(x2,y2)#tensor([0, 1, 2, 3]) tensor([0., 0., 0., 0.])将x,y存入字典,写入读取
x=torch.arange(4)
y= torch.zeros(4)
mydict={'x':x,'y':y}torch.save(mydict,'mydict')
mydict2=torch.load('mydict')
print(mydict2)
#{'x': tensor([0, 1, 2, 3]), 'y': tensor([0., 0., 0., 0.])}加载和保存模型参数:
torch.save(net.state_dict(),'mil.params')
#为了恢复模型,先实例化原始模型,直接读取文件中存储的模型参数
clone=MLP()
clone.load_state_dict(torch.load('mlp.params'))
#开启评估模式clone.eval()相关文章:

5.13学习日志
Pytorch 神经网络基础 1.模型构造 1》层和块 块可以描述单个层,由多个层组成的组件或者模型本身 块由类表示,类的任何子类都必须定义一个将其输入转换为输出的前向传播函数。为了计算梯度,块必须具有反向传播函数 自定义块: …...
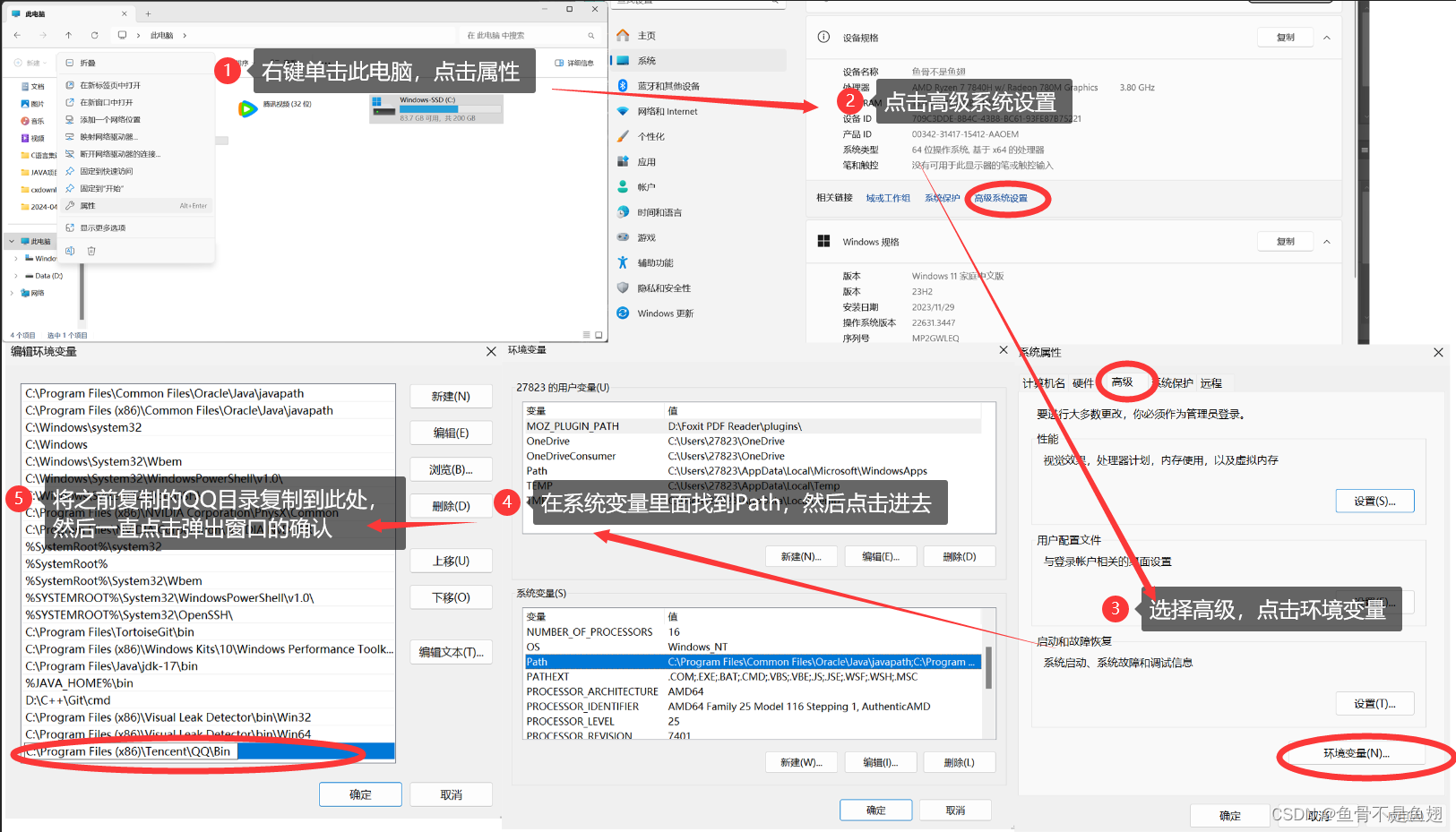
8种常见的CMD命令
1.怎么打开CMD窗口 步骤1:winr 步骤2:在弹出的窗口输入cmd,然后点击确认,就会出现一个cmd的窗口 2.CMD的8种常见命令 2.1盘符名称冒号 说明:切换盘的路径 打开CMD窗口这里默认的是C盘的Users的27823路径底下…...
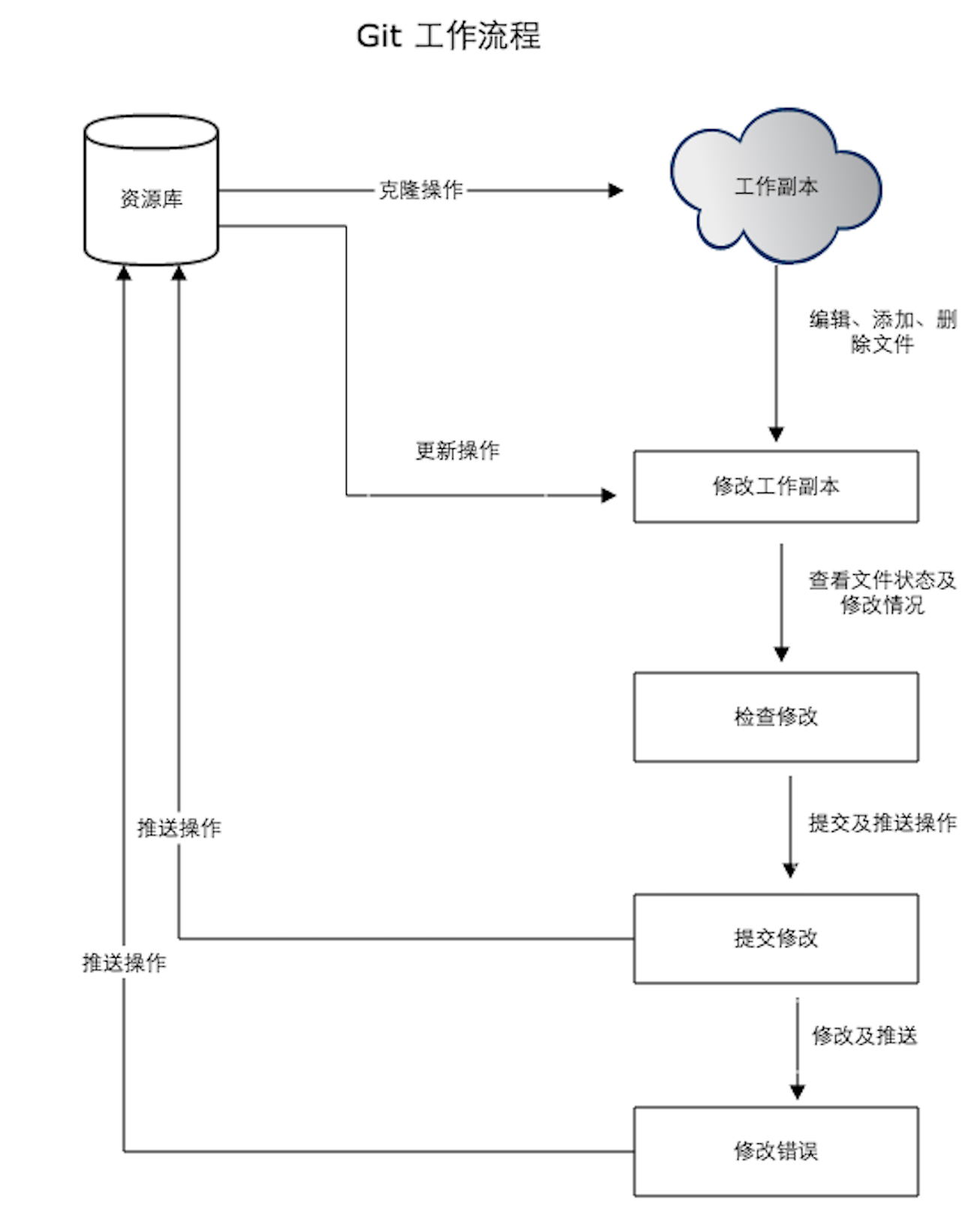
版本控制工具之Git的基础使用教程
Git Git是一个分布式版本控制系统,由Linux之父Linus Torvalds 开发。它既可以用来管理和追踪计算机文件的变化,也是开发者协作编写代码的工具。 本文将介绍 Git 的基础原理、用法、操作等内容。 一、基础概念 1.1 版本控制系统 版本控制系统&#x…...

五子棋对战(网页版)
目录 一、项目背景 用户模块 匹配模块 对战模块 二、核心技术 三、相关知识 WebSocket 原理 报文格式 代码 服务器代码 客户端代码 四、项目创建 4.1、实现用户模块 编写数据库代码 数据库设计 配置MyBatis 创建实体类 创建UserMapper 创建UserMapper接口 实现UserMapper.xml 前…...

在 Ubuntu系统中,可以使用以下几种方法查看网络速率
1 使用终端命令:可以使用ifconfig命令查看网络接口的信息,包括网络接口名称、IP地址、子网掩码等。也可以使用nload命令查看网络流量和传输速率。 2 使用网络监控工具:例如nethogs,可以更加直观地查看网络吞吐量。 3 使用网络测…...

这是摆脱困境的最好方法
20多年前,我开始涉足创业,经历过的那种停滞感我都记不清了。这是这条职业道路上最常见的挣扎之一,而且很难摆脱。 卡住的城市是一个地方,任何有创造力的,自由职业者和好奇的人经常去。这是一个很难逃离的地方。 被困…...

OceanBase 中的ROWID与Oracle的差异与如何迁移
1. ROWID 1.1 OB和Oracle中rowid的区别 正如大家所知道的,OceanBase兼容Oracle的rowid特性,但在其生成规则上却存在不同,具体表现如下: OceanBase ● 定义:OceanBase(简称 OB)的rowid是通过…...
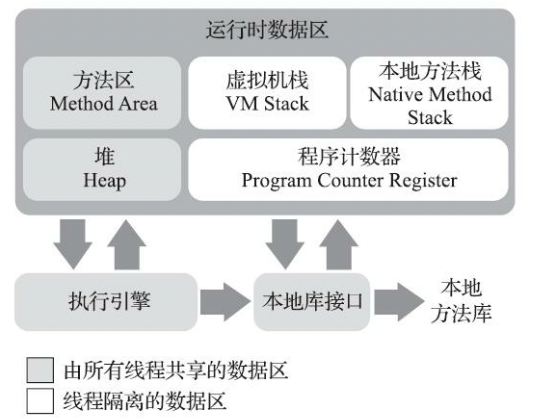
秋招后端开发面试题 - JVM运行时数据区
目录 运行时数据区前言面试题JVM 内存区域 / 运行时数据区?说一下 JDK1.6、1.7、1.8 内存区域的变化?为什么使用元空间替代永久代作为方法区的实现?Java 堆的内存分区了解吗?运行时常量池?字符串常量池了解吗ÿ…...
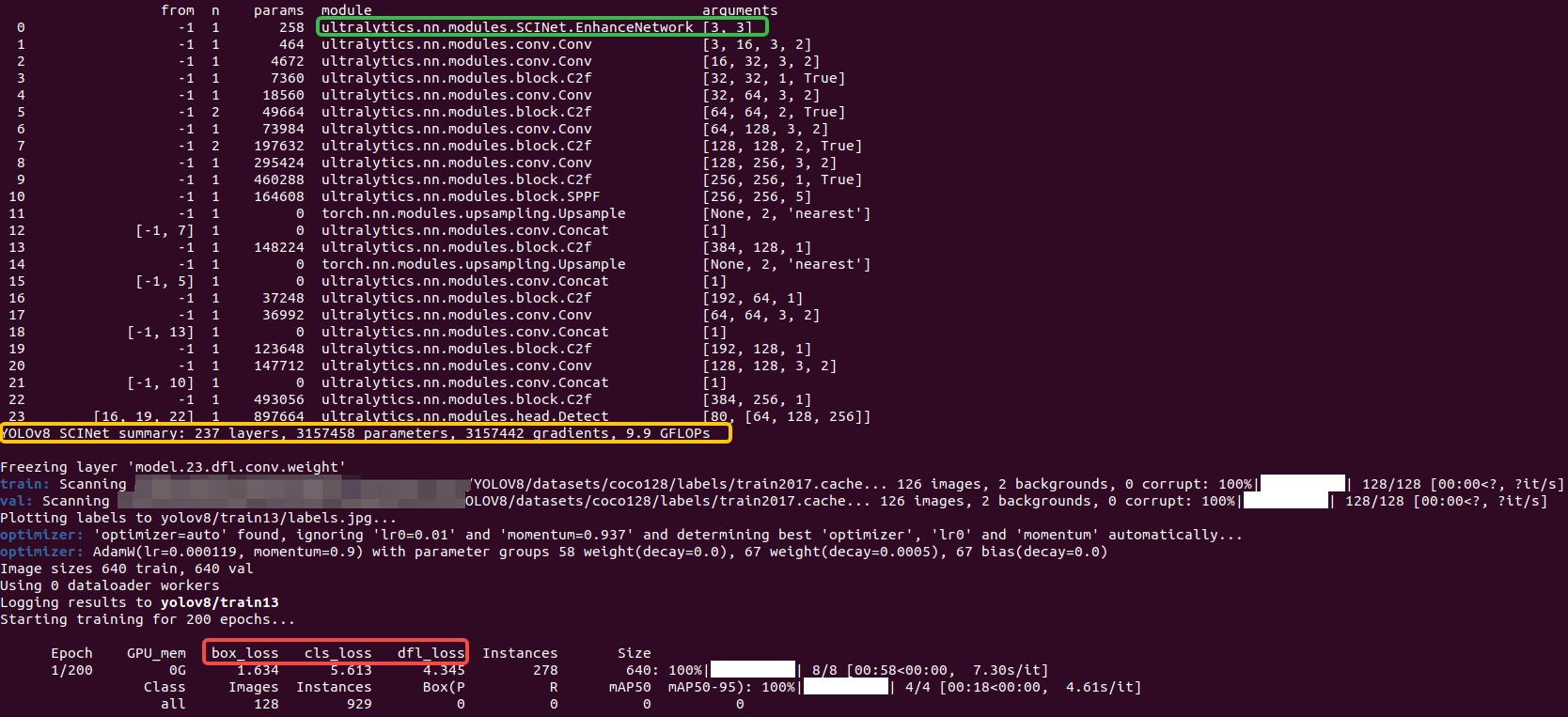
【YOLOv8改进[Backbone]】使用SCINet改进YOLOv8在黑暗环境的目标检测效果
目录 一 SCINet 1 本文方法 ① 权重共享的照明学习 ② 自校准模块 ③ 无监督训练损失 二 使用SCINet助力YOLOv8在黑暗环境的目标检测效果 1 整体修改 2 配置文件 3 训练 其他 一 SCINet 官方论文地址:https://arxiv.org/pdf/2204.10137 官方代码地址&…...

ASE docker related research
ASE 2022 Understanding and Predicting Docker Build Duration: An Empirical Study of Containerized Workflow of OSS Projects 理解和预测 Docker 构建持续时间:OSS 项目容器化工作流程的实证研究 Docker 构建是容器化工作流程的关键组成部分,它…...
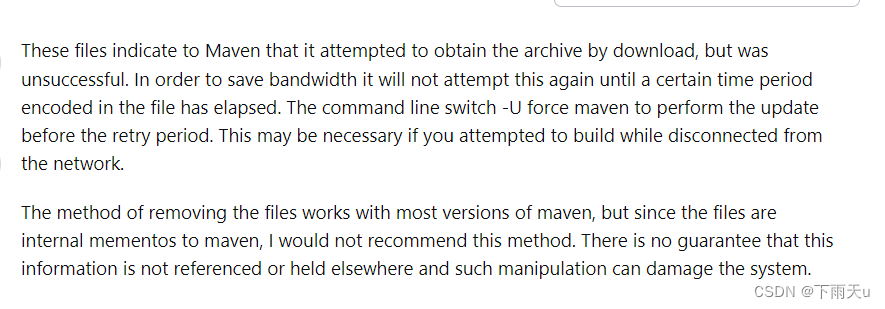
maven .lastUpdated文件作用
现象 有时候我在用maven管理项目时会发现有些依赖报错,这时你可以看一下本地仓库中是否有.lastUpdated文件,也许与它有关。 原因 有这个文件就表示依赖下载过程中发生了错误导致依赖没成功下载,可能是网络原因,也有可能是远程…...
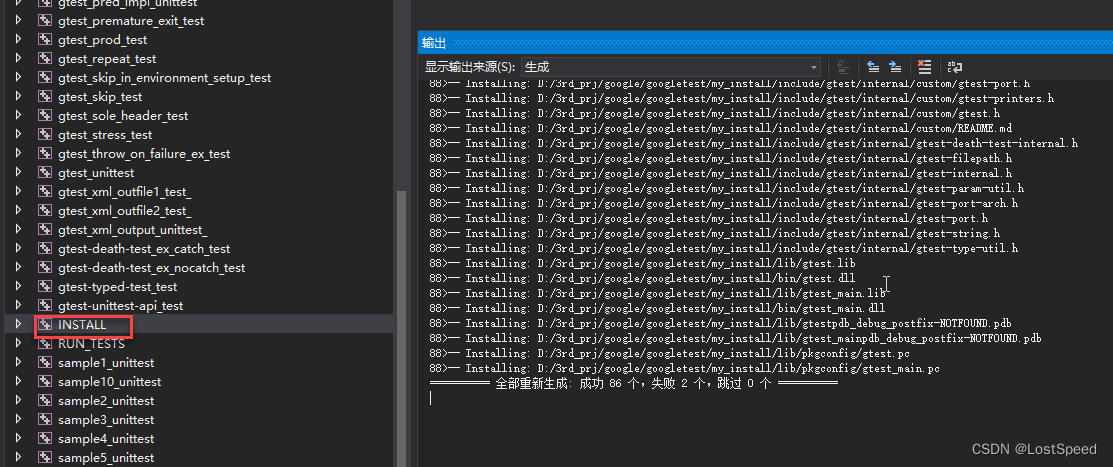
gtest的编译与使用
文章目录 gtest的编译与使用概述笔记CMake参数官方文档测试程序测试效果END gtest的编译与使用 概述 gTest是 googletest的缩写,如果直接找gTest项目,是找不到的。 库地址 https://github.com/google/googletest.git 迁出到本地后,切到最新…...
【 npm详解:从入门到精通】
文章目录 npm详解:从入门到精通1. [npm](https://www.npmjs.com/)的安装2. npm的基础用法2.1 初始化项目2.2 安装依赖2.3 卸载依赖2.4 更新依赖 3. npm的高级用法3.1 运行脚本3.2 使用npm scope3.3 使用npm link 4. npm资源5. 使用npm进行依赖树分析和可视化6. npm进…...

【Web后端】实现文件上传
表单必须使用post提交 ,enctype 必须是multipart/form-data在Servlet上填加注解 MultipartConfiglocation :默认情况下将存储文件的目录,默认值为“”。maxFileSize :允许上传文件的最大大小,其值以字节为单位。 默认值为-1L表示无…...
)
react 逻辑 AND 运算符 ()
在 React 组件中,当你想在条件为 true 时渲染一些 JSX 时,它经常会出现,或者什么都不渲染。使用 ,只有在以下情况下才能有条件地呈现复选标记:&&isPackedtrue return (<li className"item">{…...
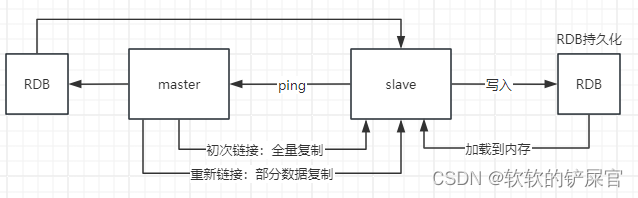
Redis详解(二)
事务 什么是事务? 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。 事务是一个原子操作:事务中的命令要么全部被执行,要么全部都…...

嵌入式:基于STM32的智能家居照明控制系统
在智能家居系统中,自动照明控制不仅提高了居住舒适度,还有助于节能减排。本教程旨在引导读者通过使用STM32微控制器来开发一个智能照明控制系统。该系统能够根据环境光线自动调整室内照明的亮度,并支持通过简单的用户界面手动控制光线。 一、…...

三种基本排序-冒泡,选择,二分
闲话不多说,直接上代码,简明易懂,条理清晰,交互性强,尽善尽美 码住,建议copy下来: 先上二分法吧,稍复杂点的,代码多一些,用了函数调用 二分排序࿱…...

windows查找重复的物理地址
单独查询所有物理(mac)地址(cmd执行):arp -a 查找同一局域网下重复的mac,打开power shell执行以下命令: Get-NetNeighbor | Where-Object { $_.State -eq "Reachable" } | Select-O…...
-shell脚本应用(三))
linux进阶高级配置,你需要知道的有哪些(8)-shell脚本应用(三)
1、for循环语句的结构: for 变量名 in 取值列表 do 命令序列 done 2、while循环语句结构: while 条件测试 do 命令序列 done 3、for和while的区别 for:控制循环来自于取值列表 while:控制循环来自于条件测试 4、case语句的…...
综合通信实训)
硬件入门 + 单片机基础(第14天)综合通信实训
ESP32 物联网结业项目:WiFi MQTT 继电器 温湿度 整合完整版 项目说明 这是物联网综合结业项目,整合了你学过的所有核心技术: WiFi 自动联网 断网重连MQTT 远程控制继电器(开关)DHT11 温湿度自动上报心跳包 消息…...

实测Taotoken多模型聚合调用的响应延迟与稳定性观感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测Taotoken多模型聚合调用的响应延迟与稳定性观感 在项目开发中,我们常常需要接入不同的大模型来满足多样化的需求。…...
XUnity Auto Translator:3分钟为Unity游戏添加多语言支持的终极解决方案
XUnity Auto Translator:3分钟为Unity游戏添加多语言支持的终极解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾因语言障碍而放弃心爱的Unity游戏?或者作为开发者…...

OpenVort开源文本嵌入引擎:本地化部署与语义搜索实战指南
1. 项目概述与核心价值最近在折腾一些需要处理大量文本数据的项目,比如日志分析、文档摘要生成,或者是想给自己的应用加个智能问答功能,总是绕不开一个核心环节:如何高效、准确地将非结构化的文本转换成机器能理解的向量。这个“向…...

DESIGN.md,让AI设计不跑偏
使用 AI 设计工具时,最烦人的问题之一,就是输出不稳定。你明明已经告诉它:颜色怎么用、字体怎么搭、按钮要什么风格。可它生成几次之后,还是会偷偷改一点,最后做出来的界面风格前后不一致。DESIGN.md 就是为了解决这个…...

Ubuntu 20.04远程桌面翻车记:手把手教你从LightDM救回默认GNOME桌面
Ubuntu 20.04桌面环境救援指南:从LightDM回归GNOME的完整方案 那天下午,实验室的Ubuntu服务器突然变得陌生——熟悉的GNOME桌面消失了,取而代之的是一个简陋的登录界面。前一天还能流畅运行的深度学习模型,现在连Jupyter Noteboo…...

影像技术实战05:视频上传后无法在线播放?MP4 封装、编码兼容与 FastStart 修复方案
影像技术实战05:视频上传后无法在线播放?MP4 封装、编码兼容与 FastStart 修复方案 一、问题场景:视频明明是 MP4,为什么网页还是播不了? 在很多视频系统里,用户上传视频后,后台保存文件&#x…...

崩坏星穹铁道终极自动化指南:三月七小助手完整使用教程
崩坏星穹铁道终极自动化指南:三月七小助手完整使用教程 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 还在为《崩坏:星穹铁道》中繁琐的日常…...
)
【2026最新】应对维普算法升级,5大降AI工具横测,一次稳降至25%(附手改秘籍)
知网和维普的AIGC检测系统又更新了! 在当下的关口,如何在不牺牲质量的前提下,优化初稿表达,安全地降低AI痕迹,成了所有小伙伴们必须解决的一个问题。网络上各种“降AI神器”铺天盖地,这些工具到底靠不靠谱…...

Roborock 与 Ecovacs 机器人吸尘器多维度对比,谁更适合你?
选购机器人吸尘器:Roborock 与 Ecovacs 多维度对比,谁更适合你?当考虑购买机器人吸尘器时,面对众多品牌和型号,可能会让人无从下手。十年前,购买机器人吸尘器的选择范围还局限于少数几个竞争品牌࿰…...