redis深入理解之实战
1、SpringBoot整合redis
1.1 导入相关依赖
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>1.2 创建Jedis对象,调用API
直接使用
@Test
public void redisTestDemo() throws InterruptedException{String host = "127.0.0.1";int port = 6379;Jedis jedis = new Jedis(host, port);jedis.set("name", "hua");System.out.println("执行setAPI后,redis中的name对应的值是:"+jedis.get("name"));jedis.setex("name",20,"32");System.out.println("执行setex后,redis中的name对应的值是:"+jedis.get("name"));Thread.sleep(1000);System.out.println("线程睡一会后检查name生存时间为:");System.out.println(jedis.persist("name"));Thread.sleep(1002);System.out.println("再次线程休眠检查name是否存在");System.out.println(jedis.exists("name"));jedis.flushAll();System.out.println("执行flushAllAPI后,检查name Key是否存在");System.out.println(jedis.exists("name"));
}使用配置文件的方式实现
redisConfig.properties
jedis.host=127.0.0.1
jedis.port=6379
#jedis.password=yourpassword
#jedis.timeout=5000RedisConfig配置类
@Configuration
@PropertySource("classpath:redisConfig.properties")
public class JedisConfig {@Value("${jedis.host}")private String jdsHost;@Value("${jedis.port}")private Integer jdsPort;@Bean("jds")public Jedis getJedis(){return new Jedis(jdsHost,jdsPort);}测试类
@Autowired
@Qualifier("jds")
private Jedis jedis;@Test
public void redisTestDemo() throws InterruptedException{jedis.set("name", "hua");System.out.println("执行setAPI后,redis中的name对应的值是:"+jedis.get("name"));jedis.setex("name",20,"32");System.out.println("执行setex后,redis中的name对应的值是:"+jedis.get("name"));Thread.sleep(1000);System.out.println("线程睡一会后检查name生存时间为:");System.out.println(jedis.persist("name"));Thread.sleep(1002);System.out.println("再次线程休眠检查name是否存在");System.out.println(jedis.exists("name"));jedis.flushAll();System.out.println("执行flushAllAPI后,检查name Key是否存在");System.out.println(jedis.exists("name"));
}结果

2、redis分片机制
2.1 redis分片机制概述
1.业务需要:
由于单台redis内存容量是有限的,无法实现海量的数据实现缓存存储。
2.分片机制概述:
概念:由多个redis节点协助工作的机制就是redis的分片机制。
作用:是为了实现redis扩容。
特点:分片机制把该机制中包含的多台redis缓存服务器当做一个整体,即看做一台redis服务器使用。
缺点:当redis分片中一个节点宕机,则可能会影响整个服务的运行,redis分片没有实现高可用。
2.2 分片机制的实现
①文件配置
1.配制规划:准备3台redis
方式:一台redis启动需要一个redis配置文件。因此实现三台redis,只需三个redis.conf文件即可。
2.修改配置文件:使3台redis的端口各不相同,如果相同则必定不能同时启动三台redis。
修改内容示例:
port 6379
port 7640
port 7639
3. 启动每个redis端口
进入redis安装目录
redis-server.exe redis.windows7640.conf
redis-server.exe redis.windows7639.conf
redis-server.exe redis.windows.conf
②SpringBoot项目使用redis分片机制
- 直接使用
//redis分片机制的实现
@Test
public void redisShards(){List<JedisShardInfo> shards = new ArrayList<>();shards.add(new JedisShardInfo("localhost",6379));shards.add(new JedisShardInfo("localhost",7639));shards.add(new JedisShardInfo("localhost",7640));ShardedJedis sjedis = new ShardedJedis(shards);sjedis.setnx("z7", "redis分片操作7");sjedis.setnx("z8", "redis分片操作8");sjedis.setnx("z9", "redis分片操作9");System.out.println("z7:"+sjedis.get("z7"));System.out.println("z8:"+sjedis.get("z8"));System.out.println("z9:"+sjedis.get("z9"));
}- 配置文件方式实现
redisConfig.properties配置文件
#配置redis分片中各节点信息
jedis.info=127.0.0.1:6379,127.0.0.1:7639,127.0.0.1:7640RedisConfig配置类
@Value("${jedis.info}")
private String jdsInfo;@Bean
public ShardedJedis shardedJedis(){//第一步,获取分片机制整合的每台redis的信息,并封装成一个JedisSharedInfo对象List<JedisShardInfo> shards = new ArrayList<>();String[] jedisInfo = jdsInfo.split(",");for(String s: jedisInfo){String[] allSubStr = s.split(":");shards.add(new JedisShardInfo(allSubStr[0], Integer.parseInt(allSubStr[1])));}return new ShardedJedis(shards);
}测试类
@Autowired
private ShardedJedis sjedis;//redis分片机制的实现@Testpublic void redisShards(){sjedis.setnx("z7", "redis分片操作7");sjedis.setnx("z8", "redis分片操作8");sjedis.setnx("z9", "redis分片操作9");System.out.println("z7:"+sjedis.get("z7"));System.out.println("z8:"+sjedis.get("z8"));System.out.println("z9:"+sjedis.get("z9"));}结果




2.3 分片机制原理
- 一致性哈希算法:Redis的分片机制通常使用一致性哈希算法(Consistent Hashing)来实现。一致性哈希算法将所有的key映射到一个固定的区间上(通常是一个哈希环),然后将这个区间划分为多个片段(shard),每个片段对应一个Redis节点。当客户端请求一个key时,根据一致性哈希算法计算出该key应该属于哪个片段,并将请求发送到对应的节点上进行处理。
- 哈希分片:Redis的哈希分片是将键值对通过哈希函数映射到不同的Redis实例中。常用的哈希函数有CRC16和CRC32等。当客户端想要访问某个key时,它会先计算出这个key的哈希值,然后根据哈希值和哈希环的映射关系找到对应的节点进行操作。
- 哈希槽(Hash Slots):在Redis的Cluster集群模式中,使用哈希槽的方式来进行数据分片。整个数据集被划分为多个哈希槽,每个哈希槽分配给一个节点。客户端通过计算key的哈希值并取模哈希槽的总数,来确定key所属的哈希槽,进而找到对应的节点进行操作。
- 自动故障转移和数据迁移:Redis的分片机制还提供了自动的故障转移和数据迁移机制。当某个节点出现故障或需要扩容时,Redis可以自动地将数据从故障节点迁移到其他节点,以保证系统的可用性和可扩展性。
分片机制存储数据使用的机制:一致性hash算法。
应用场景
场景
N 个 cache 服务器(后面简称 cache ),将一个对象 object 映射到 N 个 cache 上,计算 出object 的 hash 值,均匀的映射到到 N 个 cache ,如key%N,key是object 的hash值,N是服务器节点数
出现的问题
如果有一个服务器加入或退出这个集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了
一个服务器宕机退出集群
所有映射到服务器节点的对象都会失效,服务器节点从集群中移除,这时候 集群 是 N-1 台,映射公式变成了 hash(object)%(N-1)
一个服务器加入集群
集群新加服务器节点,这时候 集群 是 N+1 台,映射公式变成了 hash(object)%(N+1) ,所有映射到服务器节点的对象都会失效
解决方案
一致性Hash算法
1.一致性hash算法概述
- 目的:解决分布式缓存的问题。即解决了简单hash算法在分布式hash表中存在的动态伸缩等问题。
- 作用:在移除或添加一个服务器时,能够尽可能小地改变已存在的服务语法与处理请求服务器之间的映射关系。
一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响
如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响
2.redis分片机制的一致性hash算法的使用
- 常规hash运算
- 结果是由一个8位16进制数构成,共能表示2^32个可能性,根据计算机存储特性(即超出范围即从别一台开始),最后形成一个hash圆。
- 核心:参与运算的内容,只要运算内容相同,所得的hash运算结果一定相同。
- 常规hash运算
- 结果是由一个8位16进制数构成,共能表示2^32个可能性,根据计算机存储特性(即超出范围即从别一台开始),最后形成一个hash圆。
- 核心:参与运算的内容,只要运算内容相同,所得的hash运算结果一定相同。
- redis分片机制中的一致性hash算法的使用:只负责数据数据如何管理,不负责存储,存储操作由选取的redis节点负责。
- 通过分片中的每台redis的信息(ip地址+端口号)进行hash运算来计算出每台redis的节点信息(或者是节点位于2^32具体位置)。
- redis通过采取k-v结构存储数据。此时在程序中,redis利用传的实参key计算出该条数据位于2^32中的具体位置。
- redis利用此两类位置信息,按照自定议的方法找到该key距离最近的redis结点,将数据存储在该节点上。
- 当从redis取出数据时,还是通过key进行hash计算出具体位置,找个具体存储数据的redis节点,取出数据。
- 具体实现方法如下图所示:

3. 一致性hash的特性
1.平衡性
- 概念:指hash的结果应该平均分配到各个节点。
- 作用:从算法上解决负载均衡问题
- 作用对象:redis节点
- 实现方式:
- 当有两个以上redis节点时,两两节点经过hash运算后,位置之间的距离过大时。会在位置过大的两个节点之间生成前一个节点的虚拟节点,该虚拟节点的位置大致会位于两个真实节点位置中点的左侧靠近中点的位置。
- 一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如系统中只有两台服务器,此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点
- 当保存数据的对应的key经过计算后,位于真实节点与该真实节点的虚拟节点之间是时,该数据将存储到该真实节点中去。
- 示例:

2.单调性
- 概念:指新增或删除节点时,不影响系统正常运行。如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区
- 特点:在进行数据迁移时,要求尽可能小的改变数据。
3.分散性
- 概念:指数据应该分散的存在在分布式集群中的各个节点,不必每个节点都存储所有的数据。
3、redis哨兵机制
3.1 redis哨兵机制的概述
1.哨兵机制作用
- 通过哨兵机制实现redis分片的高可用,即在redis的分片中当有一台节点宕机时,不会对整个redis分片的造成影响,从而实现分片的机制的高可用。
2.哨兵机制的实现原理
- 将多台实现主从结构的redis当做整体。
- 主机即可读又可写同时会将数据同步到从机中;
- 而从机平时当作用备用机使用,只接收主机同步的数据,而不接受其它的写操作,但可以接受客户端的读操作;
- 当主机宕机时,哨兵机制会从从机中选取一台当做主机使用,从而保证整个系统不会因主机宕机而造成访问失败,实现redis高可用。
哨兵通过发送命令(ping命令),等待Redis服务器响应,如果在指定时间内,主机Redis无响应,从机则判断主机宕机,选举从机上位,从而监控运行的多个Redis实例。
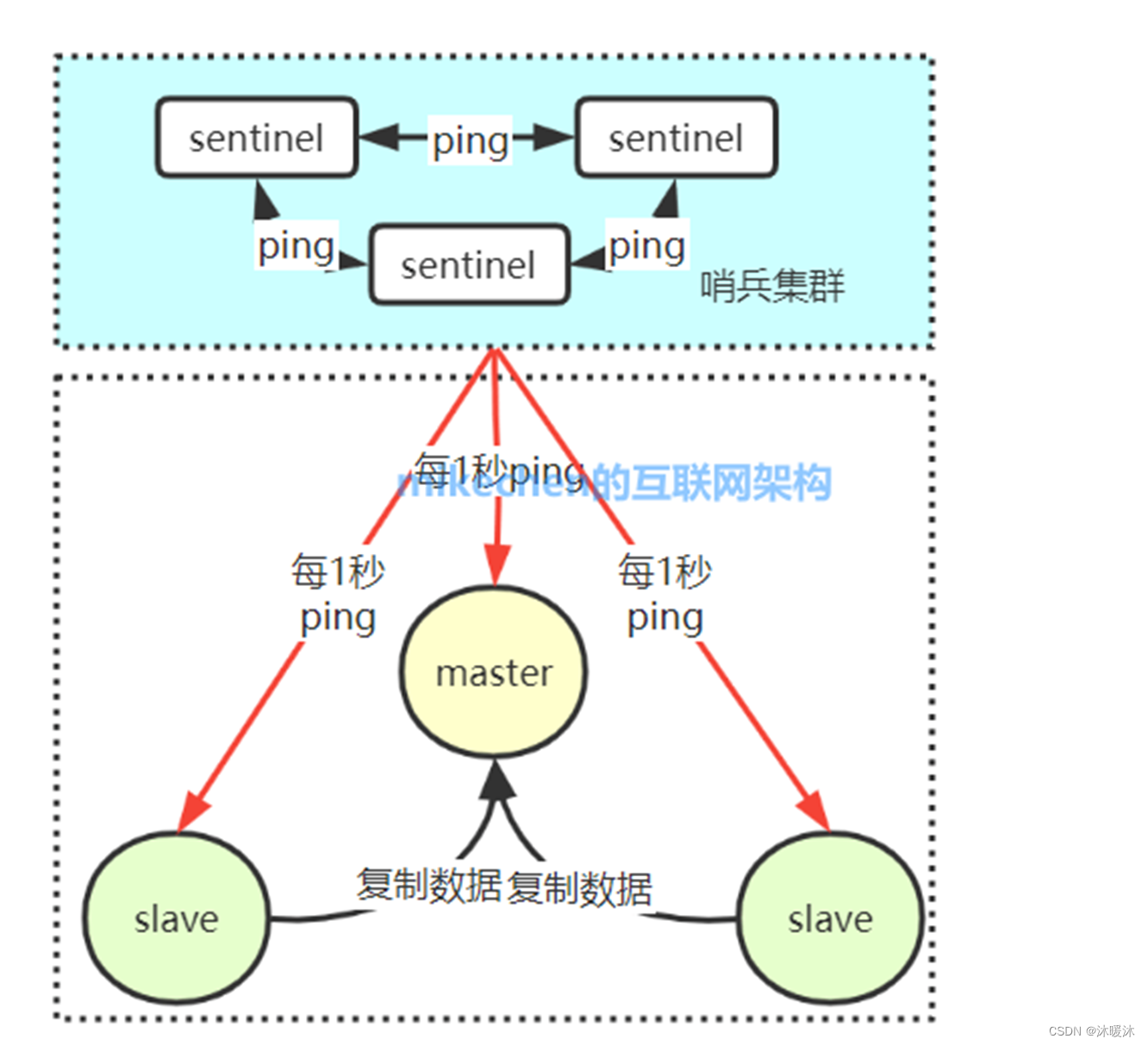
第一步:心跳机制
每个 Sentinel 会每秒钟 一次的频率向它所知的 主服务器、从服务器以及其他 Sentinel 实例 发送一个 PING 命令,获取其拓扑结构和状态信息。
第二步:判断master节点是否下线
每个 sentinel 哨兵节点每隔1s向所有的节点发送一个PING命令,作用是通过心跳检测,检测主从服务器的网络连接状态。
如果 master 节点回复 PING 命令的时间超过down-after-milliseconds 设定的阈值(默认30s),则这个 master 会被 sentinel 标记为主观下线。
第三步:基于Raft算法选举领头sentinel
master客观下线,那就需要一个sentinel来负责故障转移,所以需要通过选举一个sentinel的领头羊来解决。
第四步:故障转移
故障转移的一个主要问题和选择领头sentinel问题差不多,就是要选择一个slaver节点来作为master。
选择主Maseter过程大致如下:
①选择优先级最高的节点,通过sentinel配置文件中的replica-priority配置项,这个参数越小,表示优先级越高;
②如果第一步中的优先级相同,选择offset最大的,offset表示主节点向从节点同步数据的偏移量,越大表示同步的数据越多;
③ 如果第二步offset也相同,选择run id较小的;
这样通过以上四大步骤,实现由RedisSentinel自动完成故障发现和转移,实现自动高可用。
第五步:通知
通知所有子节点新的master,后边从新的master上边同步数据;广播通知所有客户端新的master。
3.适用时机
- 主要针对多台redis构成的实现主从配置或集群里使用。
3.2 哨兵机制的实现
1.准备工作
复制三份redis.conf文件,端口分别为6379,6380,6381

修改如下配置,并启动
bind 127.0.0.1 #主从机设定为统一的端口号绑定
port 6380 #修改成不同的端口号
protected-mode no #关闭保护模式
daemonize yes #设置成后台启动
masterauth <master-password> #如果主机设置了密码,从机中需要添加这个,修改为主机的密码
#启动命令,进入到redis安装目录下
redis-server redis6379.conf
redis-server redis6380.conf
redis-server redis6381.conf2.主从搭建
- 节点信息检查命令:
- 命令格式:info replication
- 作用:检查redis节点的状态信息
- 节点划分策略:根据业务需要要求。
- 示例:以6379为主机、6380、6381为从机
- 实现主从挂载
- 方法通过主从挂载命令完成。
- 主从挂载命令:slaveof host port
- 实现过程:
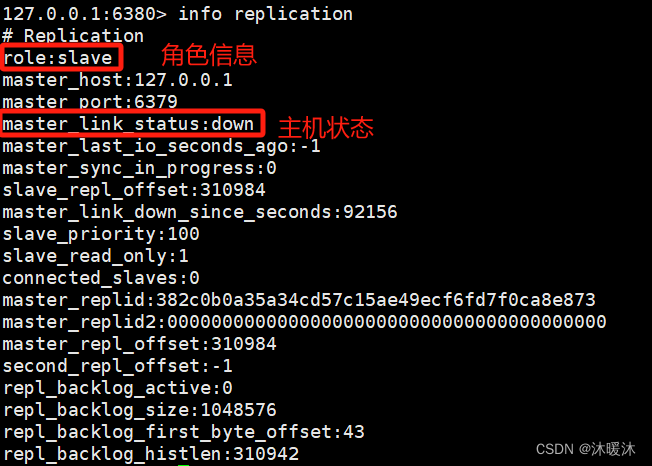
- 第一步:进入从机客户端,执行主从挂载命令

执行主从挂载后从机信息:
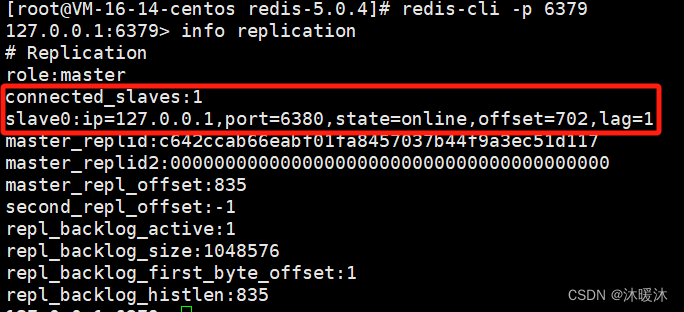
执行主从挂载后主机信息:
3.哨兵机制
- 原理:
- 当哨兵工作时会连接redis主机,并通过主机,获取所有从机的信息。
- 监控主机运行状况
- 通过心跳检测(pingpong)机制,定时向主机发ping命令,当达到规定次数仍然没有得到主机的pong结果,认定主机宕机。
- 通过随机算法将从所有从机选举出新主机。
- 负责剩下的从机重新挂载到新主机上。
- 当主机恢复后,会做为从机挂载到当前主机上。
- 哨兵机制的实现
- 编辑redis.conf文件
- 编辑sentinel.conf文件
- 位置:

基础配置方法
protected-mode no #关闭保护模式,默认为启动
port 26379 #哨兵工作时的端口,默认为26379
sentinel monitor mymaster 127.0.0.1 6379 1 #哨兵监控的主机信息以及投票次数
#投票次数一般设置为哨兵次数的一半加1即可
#sentinel down-after-milliseconds <master-name> <milliseconds>
#设置主机宕机后到哨兵开始投票之间的时间
#sentinel failover-timeout <master-name> <milliseconds>
#设置投票结果到新主机开始工作之间的时间,如果超过该时间,哨兵视作新主机也宕机,则重新开始投票- 哨兵启动与停止
- 哨兵的启动
- 前置条件:sentinel.conf
- 启动命令:redis-sentinel sentinel.conf
- 哨兵的启动

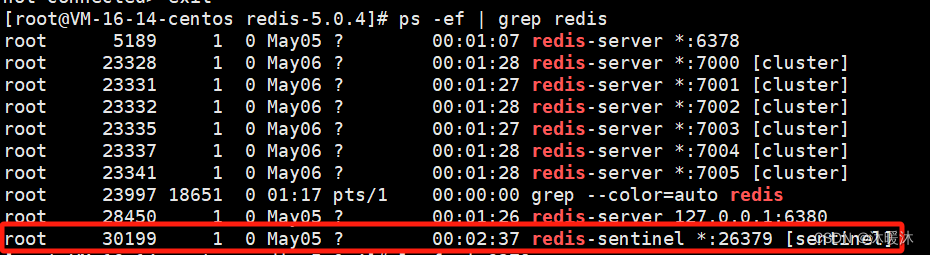
进入哨兵客户端及查看相关信息
redis-cli -p 26379
info sentinel
哨兵的停止
redis-cli -p 26379 shutdown3.3 java整合redis哨兵
- 实现要求:redis哨兵是从哨兵池中获取的。
- 实现步骤:
- 第一步:实现redis池信息配置
- 创建redis池信息配置类JedisPoolConfig的对象。
- 通过setter方法对JedisPoolConfig对象属性赋值完成对redis池配置
- 第二步:指定哨兵主机信息
- 使用Set集合来保存哨兵的主机信息,由此可知哨兵同样可以实现集群。实现方式:
- 第三步:通过redis配置类对象和保存哨兵主机信息的Set对象构建哨兵池:即JedisSentinelPool对象。
- 第四步:从哨兵池(JedisSentinelPool)中获取哨兵,并当做单台Jedis使用。
- 第五步:通过获取的Jedis的对象,操作redis。
- 第六步:使用完毕必须关闭获取的jedis对象。
- 方法:jedis.close();
- 实现示例:
@Testpublic void testSentinel(){// Redis哨兵的master名称String masterName = "mymaster";// Redis哨兵的hosts列表Set<String> sentinels = new HashSet<String>();sentinels.add("127.0.0.1:26379");
// sentinels.add("sentinel2-host:port");
// sentinels.add("sentinel3-host:port");// 创建Jedis哨兵连接池JedisSentinelPool sentinelPool = new JedisSentinelPool(masterName, sentinels);// 从连接池获取Jedis实例Jedis jedis = sentinelPool.getResource();try {// 使用Jedis实例进行操作,例如设置键值对jedis.set("key", "value");// 获取并打印键对应的值System.out.println(jedis.get("key"));} finally {// 释放Jedis实例到连接池jedis.close();}// 关闭哨兵连接池sentinelPool.close();}
2.springBoot项目整合redis哨兵。
- 第一步:完成redis哨兵池对象构建并交由spring框架管理。
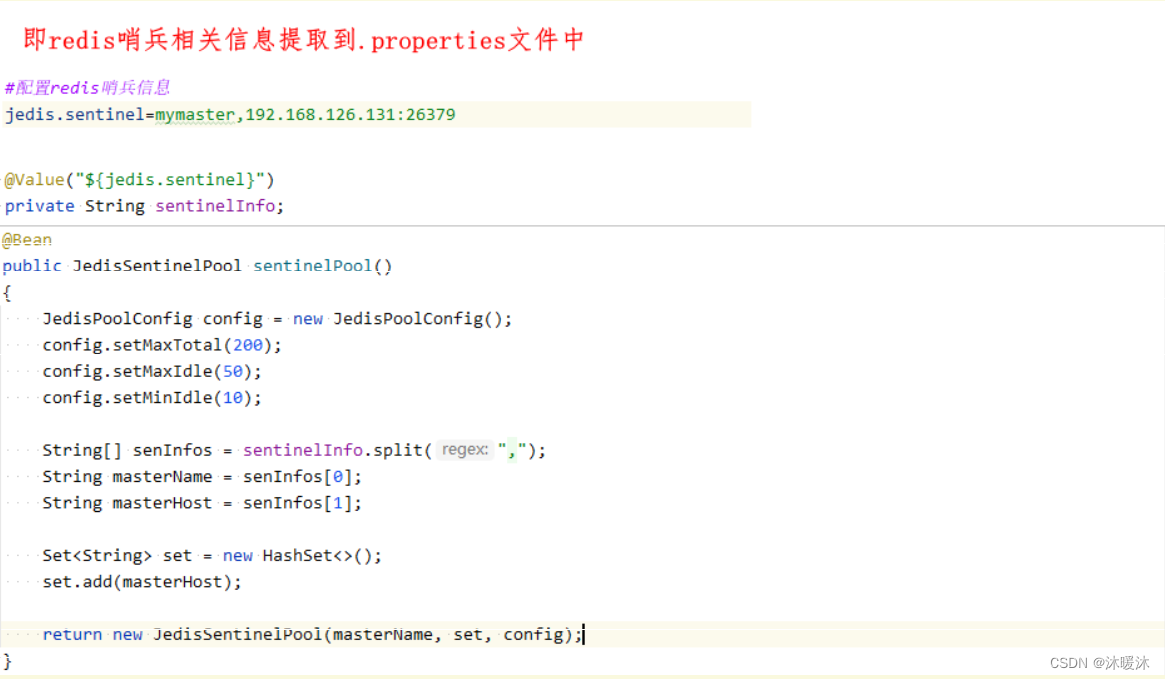
- 第二步:完成redis哨兵的DI注入

- 第三步:获取Jedis对象并通过该对象操作redis
- 参照单台redis在SpringBoot项目中的应用
- 第四步:关闭Jedis:jedis.close();
4、redis集群搭建
4.1 redis集群的概述
① 为什么要用集群
通常,为了提高网站响应速度,总是把热点数据保存在内存中而不是直接从后端数据库中读取。
Redis是一个很好的Cache工具。大型网站应用,热点数据量往往巨大,几十G上百G是很正常的事儿。
由于内存大小的限制,使用一台Redis 实例显然无法满足需求,这时就需要使用多台 Redis作为缓存数据库。但是如何保证数据存储的一致性呢,这时就需要搭建redis集群.采用合理的机制,保证用户的正常的访问需求.
采用redis集群,可以保证数据分散存储,同时保证数据存储的一致性.并且在内部实现高可用的机制.实现了服务故障的自动迁移.
② 集群概念
- 通过集群机制将哨兵机制的高可用和分片机制的高容量整合到一起,来实现redis的高性能和高可用。
③ 集群优势
- 采用redis集群,可以保证数据分散存储,同时保证数据存储的一致性。并且在内部实现高可用机制。实现了服务故障的自动迁移。
4.2 redis集群的实现
1.实现需求:准备6台redis,完成3主3从集群搭建,端口号从7000-7005
2.实现步骤:
- 第一步:复制原始redis.conf文件到指定目录,创建了一个cluster文件夹,文件夹里分别创建7000-7005文件夹,将redis.conf文件分别放到里面

- 第二步:修改redis.conf
# bind 127.0.0.1 #解除本地ip绑定
protected-mode no #关闭保护模式
port 7000 #修改端口号为对应端口号,分别是:7000 7001 7002 7003 7004
daemonize yes #开启后台运行模式
pidfile /usr/local/src/cluster/7000/redis_7000.pid #是设置pid文件夹,通常和reids.conf位于同一文件夹
dir /usr/local/src/cluster/7000 #设置持久化文件目录,与pid同一目录
maxmemory-policy volatile-lru #设置内存优化算法
appendonly no #关闭appendonly持久化策略
cluster-enabled yes #支持redis集群,必须设置
cluster-config-file nodes-7000.conf #设置集群配置文件
cluster-node-timeout 15000 #设置集群超时时间,单位毫秒- 第三步:开启所有redis
- 可以通过脚本文件启动所有redis
- 创建并编辑start.sh
- 可以通过脚本文件启动所有redis
#!/bin/sh
redis-server /usr/local/src/cluster/7000/redis.conf &
redis-server /usr/local/src/cluster/7001/redis.conf &
redis-server /usr/local/src/cluster/7002/redis.conf &
redis-server /usr/local/src/cluster/7003/redis.conf &
redis-server /usr/local/src/cluster/7004/redis.conf &
redis-server /usr/local/src/cluster/7005/redis.conf - 通过脚本启动多台redis:
sh start.sh
- 可以通过脚本关闭多台redis:
- 创建stop.sh脚本
#!/bin/sh
redis-cli -p 7000 shutdown &
redis-cli -p 7001 shutdown &
redis-cli -p 7002 shutdown &
redis-cli -p 7003 shutdown &
redis-cli -p 7004 shutdown &
redis-cli -p 7005 shutdown - 通过脚本关闭所有redis
sh stop.sh- 第四步:执行创建集群命令
- 命令自动运行阶段一:收集信息,提出集群创建策略。
redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005- 命令自动运行阶段二:加载节点到集群中

命令自动运行阶段三:完成主从搭建,计算hash槽道,并完成槽道分配

- 第五步:测试集群
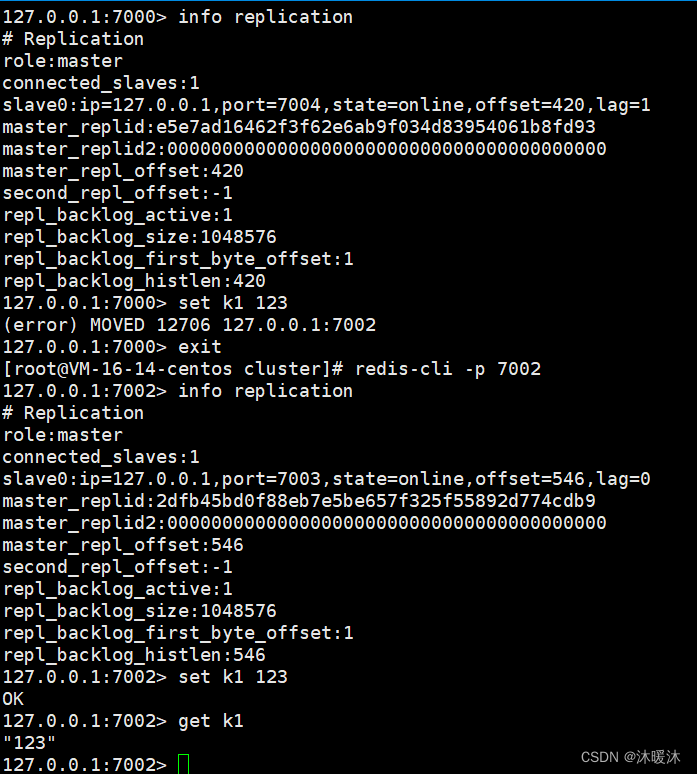
当角色是从机时,仅是备份作用,当其它主机宕机后成为主机,才能按槽道读写;当角色是主机,能读能写,还能向所属从机写入主机数据
集群是根据槽道向主机写入数据,当主机写入数据时,集群会首先计算槽道,按槽道选择所属主机,如果当前主机不是所选主机,则会提示前往对应主机写入数据
相关文章:
redis深入理解之实战
1、SpringBoot整合redis 1.1 导入相关依赖 <dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId> </dependency> <dependency><groupId>org.springframework.boot</groupId><artifactId&g…...

python设计模式---工厂模式
定义了一个抽象类Animal,并且让具体的动物类(Dog、Cat、Duck)继承自它,并实现了speak方法。然后创建了AnimalFactory工厂类,根据传入的参数来决定创建哪种动物的实例。 from abc import abstractmethod, ABCclass Anim…...

探索Vue 3.0中的v-html指令
探索Vue 3.0中的v-html指令 一、什么是v-html指令?1、 在Vue 3.0中使用v-html2、 注意事项 二、结语 一、什么是v-html指令? Vue.js作为一款流行的JavaScript框架,不断地演进着。随着Vue 3.0的发布,开发者们迎来了更加强大和灵活…...

anaconda 环境配置
官方网站下载地址: https://www.anaconda.com/download/ 国内清华镜像下载地址: https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/ 配置国内环境: conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ …...

DS:顺序表、单链表的相关OJ题训练(2)
欢迎各位来到 Harper.Lee 的学习世界! 博主主页传送门:Harper.Lee的博客主页 想要一起进步的uu欢迎来后台找我哦! 一、力扣--141. 环形链表 题目描述:给你一个链表的头节点 head ,判断链表中是否有环。如果链表中有某个…...
上传到 PyPI
将软件包上传到 PyPI(Python Package Index),您需要遵循以下步骤: 准备软件包:确保您的软件包满足以下要求: 包含一个 setup.py 文件,用于描述软件包的元数据和依赖项。包含软件包的源代码和必要…...
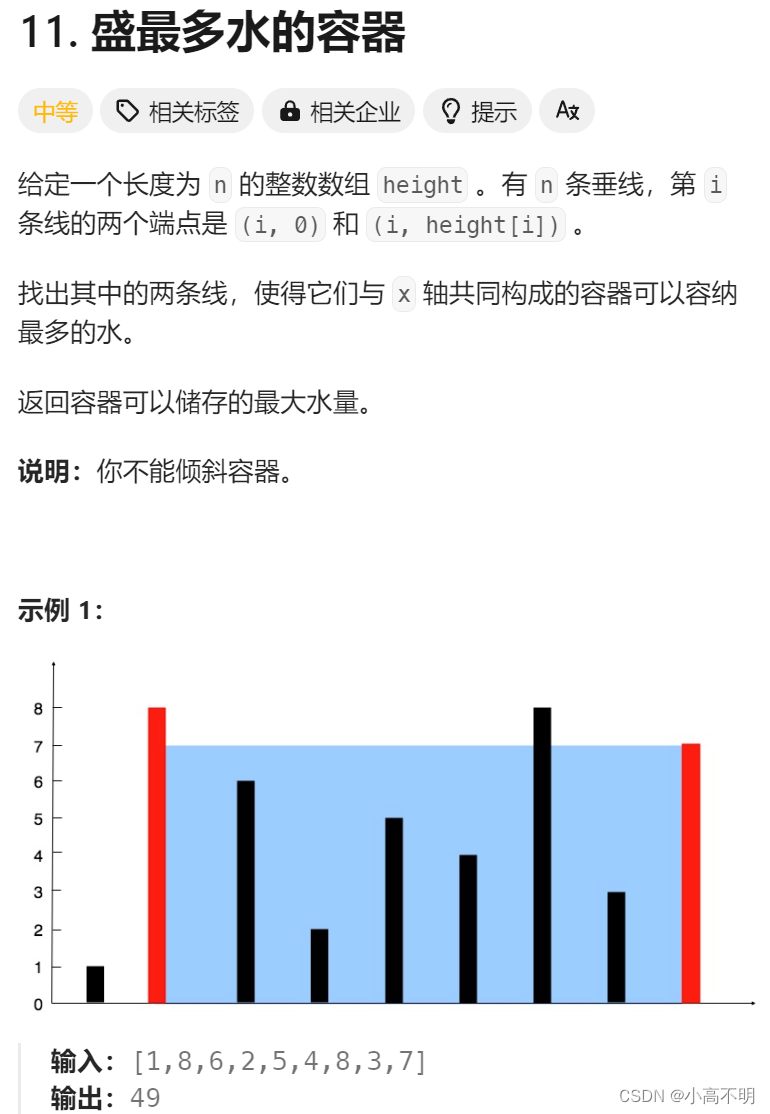
盛最多水的容器(双指针)
解题思路: 1,暴力解法(超时) 我们可以使用两层for循环进行遍历。找到那个最大的面积即可,这里我就不写代码了,因为写了也是超时。 2,双指针法 先定义两个指针一个在最左端,一个在…...
【深度学习】实验3 特征处理
特征处理 python 版本 3.7 scikit-learn 版本 1.0.2 1.标准化 from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import MinMaxScaler from matplotlib import gridspec import numpy as np import matplotlib.pyplot as plt cps np.random.…...
MoneyPrinter国内版改造
背景: MoneyPrinter 是一个自动生成短视频的开源项目。只需要输入短视频主题,然后就可以生成视频。 在国内环境运行时,框架中使用的youtube、抖音文字转语音等功能无法使用,需要对框架进行国内版改造,使其使用国内网络…...

C++ 派生类的引入与特性
一 继承与派生 从上面的例子可以看出: 继承:一旦指定了某种事物父代的本质特征,那么它的子代将会自动具有哪些性质。这就是一种朴素的可重用的概念。 派生:而且子代可以拥有父代没有的特性,这是可扩充的概念。 1 C 的…...
Poe是什么?怎样订阅Poe?
Poe(全称“开放探索平台”,Platform for Open Exploration)是一款由Quora开发的移动应用程序,于2022年12月推出。该应用程序内置建基于AI技术的聊天机器人,可供用户向机器人询问专业知识、食谱、日常生活,甚…...

基于FPGA的视频矩阵切换方案
一、单个显示设备的系统方案:会议室只有1个显示设备 会议室的信号源有很多,但是显示设备只有1个,这个时候最佳方案是使用切换器。 (1)切换器(控制方式:遥控器、软件、机箱面板、中控ÿ…...

.NET周刊【5月第1期 2024-05-05】
国内文章 一个开源轻量级的C#代码格式化工具(支持VS和VS Code) https://www.cnblogs.com/Can-daydayup/p/18164905 CSharpier是一个开源、免费的C#代码格式化工具,特点是轻量级且依赖Roslyn引擎重构代码格式。支持的IDE包括Visual Studio …...
springcloud -nacos实战
一、nacos 功能简介 1.1.什么是Nacos? 官方简介:一个更易于构建云原生应用的动态服务发现(Nacos Discovery )、服务配置(Nacos Config)和服务管理平台。 Nacos的关键特性包括: 服务发现和服务健康监测动态配置服务动态DNS服务服务及其元数…...

第十五章 数据管理成熟度评估练习
单选题 (每题1分,共19道题) 1、 [单选] 下列选项中属于数据管理成熟度2级特征的选项是? A:很少或没有治理;有限的工具集;单个竖井(系统)内定义角色;控件(如果有的话的应用完全不一致);未解决的数据质量问题 B:治理开始出现;引入一致的工具集;定义了一些角色和…...

tcpdump速查表
tcpdump 速查表 -D 列出网络设备 ~]$ sudo tcpdump -D1.eth02.nflog (Linux netfilter log (NFLOG) interface)3.nfqueue (Linux netfilter queue (NFQUEUE) interface)4.any (Pseudo-device that captures on all interfaces)5.lo [Loopback]-i 指定网卡 前面列出的设备可以…...

单元测试与集成测试:软件质量的双重保障
目录 概述 单元测试 集成测试 单元测试的方法 白盒测试 黑盒测试 白盒测试的方法和用例设计 代码审查 集成测试 单元测试工具 结语 在软件开发中,测试是一个不可或缺的环节,它能够帮助我们发现和修复缺陷,确保软件的质量和可靠性。…...
孙宇晨对话大公网:香港Web3政策友好环境示范意义重大
日前,全球知名华文媒体大公网发布《湾区web3大有可为》重磅系列报道。报道通过对中国香港与大湾区其他城市Web3政策、行业创新和生态建设等方面的梳理,以及对行业领袖和重要行业机构的走访,全面展现了在大湾区一体化发展的背景下,Web3等数字经济模式在该地区的长远发展潜力。 …...

Python运维之多线程!!
一、多线程 二、多线程编程之threading模块 2.1、使用threading进行多线程操作有两种方法: 三、多线程同步之Lock(互斥锁) 四、多线程同步之Semaphore(信号量) 五、多线程同步之Condition 六、多线程同步之Event…...

milvus插入数据时,明明不超长,但总是报长度错误?
在处理插入milvus数据时,设置了字段长度为512. 明明考虑了预留,插入的数据中没有这么长的,但还是会有报错 类似:MilvusException: (code0, messagethe length (564) of 78th string exceeds max length (512) 查找max(len(x) for …...

猫抓浏览器扩展:三步实现网页视频自由下载的完整指南
猫抓浏览器扩展:三步实现网页视频自由下载的完整指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到这样的情况&#x…...

YOLO算法集成 车道线识别 + 目标检测 +图像分割识别
YOLO车道线识别 目标检测 可行驶区域(Freespace)的综合应用引言 随着自动驾驶技术和智能交通系统的迅速发展,车辆环境感知技术变得愈加重要。准确地理解周围环境对于确保自动驾驶的安全性和可靠性至关重要。在众多的环境感知任务中…...

DDrawCompat:让经典DirectX游戏在现代Windows系统上重获新生的兼容神器
DDrawCompat:让经典DirectX游戏在现代Windows系统上重获新生的兼容神器 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_m…...

【效率革命】PolyWindow插件:从多边形到精美窗户的3dMax一键生成秘籍
1. 为什么你需要PolyWindow插件? 如果你经常用3dMax做建筑可视化或室内设计,肯定遇到过这样的烦恼:项目里需要做几十个风格各异的窗户,每个都要手动建模、分格、赋材质,光是想到这个工作量就让人头皮发麻。我去年接的一…...

Qt程序图标设置全攻略:从.ico文件到任务栏显示,一个坑都不踩
Qt程序图标设置全攻略:从资源文件到系统缓存的完整解决方案 第一次用Qt打包发布程序时,我盯着任务栏上那个丑陋的默认图标发呆了十分钟——明明在代码里设置了图标,为什么还是显示不出来?相信很多Qt开发者都遇到过类似问题。图标…...

用ZYNQ和LWIP搞定8路ADS8681数据采集:从Vivado Block Design到上位机TCP通信的完整流程
ZYNQ与LWIP构建的8通道高速数据采集系统实战指南 在工业自动化、测试测量和科研领域,多通道高精度数据采集系统正变得越来越重要。本文将详细介绍如何利用Xilinx ZYNQ SoC和LWIP协议栈,构建一个支持8路ADS8681同步采集的实时数据传输系统。不同于简单的代…...

终极CoreCycler教程:简单三步完成CPU稳定性测试与优化
终极CoreCycler教程:简单三步完成CPU稳定性测试与优化 【免费下载链接】corecycler Script to test single core stability, e.g. for PBO & Curve Optimizer on AMD Ryzen or overclocking/undervolting on Intel processors 项目地址: https://gitcode.com/…...

UABEA:终极跨平台Unity资源编辑器,免费解锁游戏资源分析新境界
UABEA:终极跨平台Unity资源编辑器,免费解锁游戏资源分析新境界 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA UABEA(Unity Asset Bundle Extractor Avalonia&#…...

Python自动化Excel数据抓取:OpenClaw技能实战指南
1. 项目概述:从Excel表格到智能数据抓取如果你每天的工作都离不开Excel,并且经常需要从各种网页、文档甚至PDF里手动复制粘贴数据,然后费劲地整理到表格里,那你一定对“Excel大师”这个称号既向往又头疼。我们总希望Excel能更“聪…...

百度网盘直链解析终极指南:如何实现高速下载的完整技术方案
百度网盘直链解析终极指南:如何实现高速下载的完整技术方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在云存储服务普及的今天,百度网盘作为国内用…...