【联邦学习——手动搭建简易联邦学习】
1. 目的
用于记录自己在手写联邦学习相关实验时碰到的一些问题,方便自己进行回顾。
2. 代码
2.1 本地模型计算梯度更新
# 比较训练前后的参数变化
def compare_weights(new_model, old_model):weight_updates = {}for layer_name, params in new_model.state_dict().items():weight_updates[layer_name] = params - old_model.state_dict().get(layer_name)return weight_updates
测试代码如下:
有意思的点在于我获得了update = model2-model1
但是我去计算model1+update==model2的时候发现不相等
最后思考了一下可能是在这个计算的过程中存在精度的丢失
import torch
from torch import nn
from torchvision import transforms, datasets, models
from torch.utils.data import DataLoaderdef weight_init(m):if isinstance(m, nn.Linear):nn.init.xavier_normal_(m.weight)nn.init.constant_(m.bias, 0)# 也可以判断是否为conv2d,使用相应的初始化方式elif isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')# 是否为批归一化层elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)if __name__ == '__main__':# 建立model1和model2作为训练前后的模型model1 = models.get_model("resnet18")model1.apply(weight_init)model2 = models.get_model("resnet18")model2.apply(weight_init)weight_updates = compare_weights(model2,model1)# 创建一个临时的模型状态字典,用于存储更新后的参数updated_params = model1.state_dict().copy()for layer_name, update in weight_updates.items():# 确保该层存在于model1中且形状匹配,避免错误if layer_name in updated_params and update.shape == updated_params[layer_name].shape:# 直接相加更新参数updated_params[layer_name] += updateelse:print(f"Warning: Layer {layer_name} not found or shape mismatch, skipping update.")# 将更新后的参数加载回model1model1.load_state_dict(updated_params)for layer_name,params in model1.state_dict().items():ts = params-model2.state_dict().get(layer_name)# 很重要,这里应该是我们在做的时候会有一点模型精度上的损失,所以不能够计算这里等于0if torch.sum(ts).item()>1e-6:print(f"{layer_name}更新后与原有的不匹配,差距为")else:print(f"{layer_name}更新后与原有的匹配")
2.2 客户端代码
import numpy as np
import torch.utils.data
from tqdm import tqdm'''
conf 配置文件
model 模型
train_dataset 数据集
class_ratios 从数据集中筛选出一部分 class_ratios = {0: 0.5, 1: 0.5,..., 8: 0.5, 9: 0.5}
id 客户端的标识
'''class Client(object):def __init__(self,conf,model,device,train_loader,id=1):self.client_id = id # 客户端IDself.conf = conf # 配置文件self.local_model = model # 客户端本地模型self.train_loader = train_loader # 训练数据的迭代器,需要训练的数据已经在里面了self.grad_update = dict() # 本地训练完之后的梯度更新self.weight = conf['weight'] # 全局模型梯度更新时的权重self.device = device # 训练的设备self.local_model.to(self.device) # 将模型放入训练设备def train(self, model):self._before_train(model)self._local_train()self._after_train(model)def _before_train(self, model):self._load_global_model(model)# 用服务器模型来覆盖本地模型def _load_global_model(self,model):for name,param in model.state_dict().items():# 客户端首先用服务器端下发的全局模型覆盖本地模型self.local_model.state_dict()[name].copy_(param.clone())def _local_train(self):# 定义最优化函数器,用于本地模型训练optimizer = torch.optim.SGD(self.local_model.parameters(),lr=self.conf['lr'],momentum=self.conf['momentum'])# 本地模型训练self.local_model.train()loss = 0for epoch in range(self.conf['local_epochs']):for batch in tqdm(self.train_loader, desc=f"Epoch {epoch + 1}/{self.conf['local_epochs']}"):data, target = batch# 放入相应的设备data = data.to(self.device)target = target.to(self.device)# 梯度清零optimizer.zero_grad()output = self.local_model(data)loss = torch.nn.functional.cross_entropy(output, target)# 反向传播loss.backward()optimizer.step()print(f"Client{self.client_id}----Epoch {epoch} done.Loss {loss}")def _after_train(self,model):self._cal_update_weights(model)def _cal_update_weights(self, old_model):weight_updates = dict()for layer_name, params in self.local_model.state_dict().items():weight_updates[layer_name] = params - old_model.state_dict().get(layer_name)# 更新梯度模型的权重self.grad_update = weight_updates
2.3 服务器代码
import torch.utils.data
import torchvision.datasets as datasets
from torchvision import models
from torchvision.transforms import transformsfrom utils.CommonUtils import copy_model_params# 服务端
class Server(object):def __init__(self, conf, eval_dataset, device):self.conf = conf# 全局老模型self.old_model = models.get_model(self.conf["model_name"])# 全局的新模型self.global_model = models.get_model(self.conf["model_name"])# 创建时保持新老模型的参数是一致的copy_model_params(self.old_model,self.global_model)# 根据客户端上传的梯度进行排列组合,用于测量贡献度的模型self.sub_model = models.get_model(self.conf["model_name"])self.eval_loader = torch.utils.data.DataLoader(eval_dataset,batch_size=self.conf["batch_size"],shuffle=True)self.accuracy_history = [] # 保存accuracy的数组self.loss_history = [] # 保存loss的数组self.device = deviceself.old_model.to(device)self.global_model.to(device)self.sub_model.to(device)# 模型重构def model_aggregate(self, clients, target_model):if target_model == self.global_model:print("++++++++全局模型更新++++++++")# 更新一下老模型参数copy_model_params(self.old_model,self.global_model)else:print("========子模型重构========")sum_weight = 0# 计算总的权重for client in clients:sum_weight += client.weight# 将old_model的模型参数赋值给sub_modelcopy_model_params(self.sub_model, self.old_model)# 初始化一个空字典来累积客户端的模型更新aggregated_updates = {}# 遍历每个客户端for client in clients:# 根据客户端的权重比例聚合更新for name, update in client.grad_update.items():if name not in aggregated_updates:aggregated_updates[name] = update * client.weight / sum_weightelse:aggregated_updates[name] += update * client.weight / sum_weight# 应用聚合后的更新到sub_modelfor name, param in target_model.state_dict().items():if name in aggregated_updates:param.copy_(param + aggregated_updates[name]) # 累加更新到当前层参数上# 定义模型评估函数def model_eval(self,target_model):target_model.eval()total_loss = 0.0correct = 0dataset_size = 0for batch_id,batch in enumerate(self.eval_loader):data,target = batchdataset_size += data.size()[0]# 放入和模型对应的设备data = data.to(self.device)target = target.to(self.device)# 模型预测output = target_model(data)# 把损失值聚合起来total_loss += torch.nn.functional.cross_entropy(output,target,reduction='sum').item()# 获取最大的对数概率的索引值pred = output.data.max(1)[1]correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()# 计算准确率acc = 100.0 * (float(correct) / float(dataset_size))# 计算损失值total_l = total_loss / dataset_size# 将accuracy和loss保存到数组中self.accuracy_history.append(acc)self.loss_history.append(total_l)if target_model == self.global_model:print(f"++++++++全局模型评估++++++++acc:{acc} loss:{total_l}")else:print(f"========子模型评估========acc:{acc} loss:{total_l}")return acc,total_ldef save_results_to_file(self):# 将accuracy和loss保存到文件中with open("fed_accuracy_history.txt", "w") as f:for acc in self.accuracy_history:f.write("{:.2f}\n".format(acc))with open("fed_loss_history.txt", "w") as f:for loss in self.loss_history:f.write("{:.4f}\n".format(loss))
2.4 Utils
def copy_model_params(target_model, source_model):for name, param in source_model.state_dict().items():target_model.state_dict()[name].copy_(param.clone())
3. 运行测试代码
import jsonimport torch
from torch import nn
from torch.utils.data import DataLoader, Subset
from torchvision import models
from torchvision import transforms, datasets
from client.Client import Client
from server.Server import Serverwith open("../conf/client1.json",'r') as f:conf = json.load(f)with open("../conf/server1.json",'r') as f:serverConf = json.load(f)transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])train_dataset = datasets.CIFAR10(root='../data/', train=True, download=True,transform=transform)
eval_dataset = datasets.CIFAR10(root='../data/', train=False, download=True,transform=transform)# train_loader = DataLoader(train_dataset, shuffle=True, batch_size=32, num_workers=2)# 计算数据集长度
total_samples = len(train_dataset)
# 确保可以平均分配,否则需要调整逻辑以处理余数
assert total_samples % 2 == 0, "数据集样本数需为偶数以便完全平分"# 分割点
split_point = total_samples // 2# 创建两个子集
train_dataset_first_half = Subset(train_dataset, range(0, split_point))
train_dataset_second_half = Subset(train_dataset, range(split_point, total_samples))# 然后为每个子集创建DataLoader
batch_size = 32train_loader_first_half = DataLoader(train_dataset_first_half, shuffle=True, batch_size=batch_size, num_workers=2)
train_loader_second_half = DataLoader(train_dataset_second_half, shuffle=True, batch_size=batch_size, num_workers=2)# 检查CUDA是否可用
if torch.cuda.is_available():device = torch.device("cuda") # 如果CUDA可用,选择GPU
else:device = torch.device("cpu") # 如果CUDA不可用,选择CPUlocal_model = models.get_model("resnet18")
local_model2 = models.get_model("resnet18")server = Server(serverConf,eval_dataset,device)
client1 = Client(conf, local_model, device,train_loader_first_half, 1)
client2 = Client(conf, local_model2, device,train_loader_second_half, 2)
for i in range(2):client1.train(server.global_model)client2.train(server.global_model)server.model_aggregate([client1,client2], server.global_model)server.model_eval(server.global_model)server.model_aggregate([client1], server.sub_model)server.model_eval(server.sub_model)server.model_aggregate([client2], server.sub_model)server.model_eval(server.sub_model)相关文章:

【联邦学习——手动搭建简易联邦学习】
1. 目的 用于记录自己在手写联邦学习相关实验时碰到的一些问题,方便自己进行回顾。 2. 代码 2.1 本地模型计算梯度更新 # 比较训练前后的参数变化 def compare_weights(new_model, old_model):weight_updates {}for layer_name, params in new_model.state_dic…...
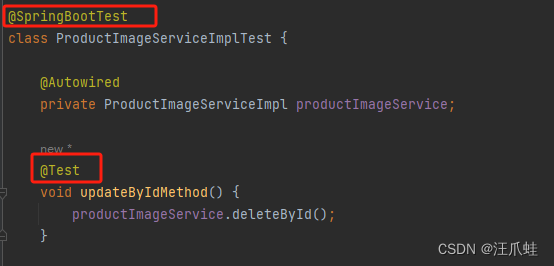
Springboot项目如何创建单元测试
文章目录 目录 文章目录 前言 一、SpringBoot单元测试的使用 1.1 引入依赖 1.2 创建单元测试类 二、Spring Boot使用Mockito进行单元测试 2.1 Mockito中经常使用的注解以及注解的作用 2.2 使用Mockito测试类中的方法 2.3 使用Mockito测试Controller层的方法 2.4 mock…...
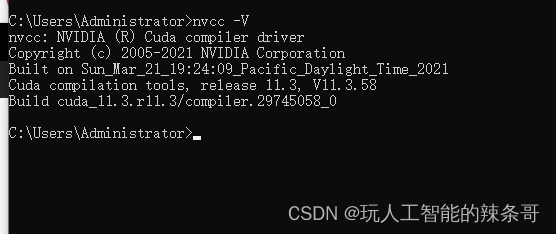
Win10 如何同时保留两个CUDA版本并自由切换使用
环境: Win10 专业版 CUDA11.3 CUDA11.8 问题描述: Win10 如何同时保留两个CUDA版本并自由切换 解决方案: 在同一台计算机上安装两个CUDA版本并进行切换可以通过一些环境配置来实现。这通常涉及到管理环境变量,特别是PATH和L…...

实验室纳新宣讲会(java后端)
前言 这是陈旧已久的草稿2021-09-16 15:41:38 当时我进入实验室,也是大二了,实验室纳新需要宣讲, 但是当时有疫情,又没宣讲成。 现在2024-5-12 22:00:39,发布到[个人]专栏中。 实验室纳新宣讲会(java后…...
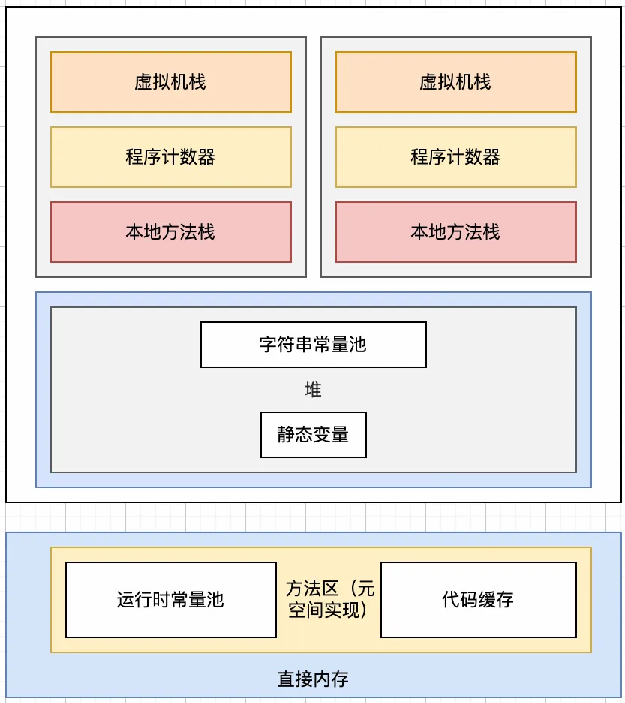
class常量池、运行时常量池和字符串常量池的关系
类常量池、运行时常量池和字符串常量池这三种常量池,在Java中扮演着不同但又相互关联的角色。理解它们之间的关系,有助于深入理解Java虚拟机(JVM)的内部工作机制,尤其是在类加载、内存分配和字符串处理方面。 类常量池…...

Java | Leetcode Java题解之第88题合并两个有序数组
题目: 题解: class Solution {public void merge(int[] nums1, int m, int[] nums2, int n) {int p1 m - 1, p2 n - 1;int tail m n - 1;int cur;while (p1 > 0 || p2 > 0) {if (p1 -1) {cur nums2[p2--];} else if (p2 -1) {cur nums1[p…...
韵搜坊(全栈)-- 前后端初始化
文章目录 前端初始化后端初始化 前端初始化 使用ant design of vue 组件库 官网快速上手:https://www.antdv.com/docs/vue/getting-started-cn 安装脚手架工具 进入cmd $ npm install -g vue/cli # OR $ yarn global add vue/cli创建一个项目 $ vue create ant…...

Android:资源的管理,Glide图片加载框架的使用
目录 一,Android资源分类 1.使用res目录下的资源 res目录下资源的使用: 2.使用assets目录下的资源 assets目录下的资源的使用: 二,glide图片加载框架 1.glide简介 2.下载和设置 3.基本用法 4.占位符(Placehold…...

conll-2012-formatted-ontonotes-5.0中文数据格式说明
CoNLL-2012 数据格式是用于自然语言处理任务的一种常见格式,特别是在命名实体识别、词性标注、句法分析和语义角色标注等领域。这种格式在 CoNLL-2012 共享任务中被广泛使用,该任务主要集中在语义角色标注上。 CoNLL-2012 数据格式通常包括多列…...
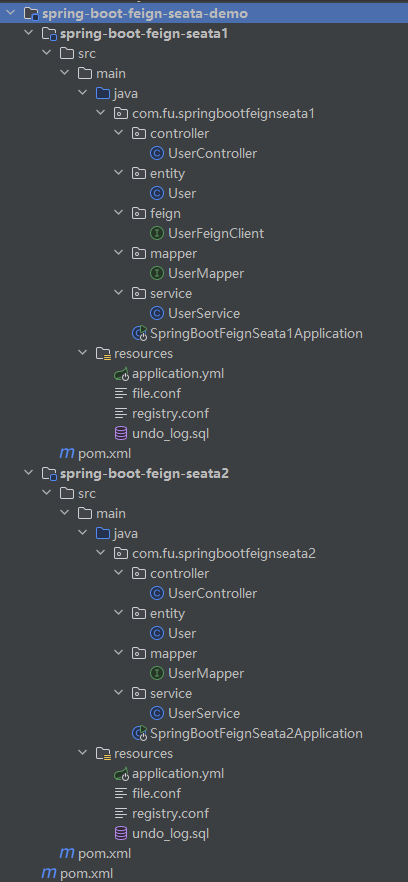
SpringBoot集成Seata分布式事务OpenFeign远程调用
Docker Desktop 安装Seata Server seata 本质上是一个服务,用docker安装更方便,配置默认:file docker run -d --name seata-server -p 8091:8091 -p 7091:7091 seataio/seata-server:2.0.0与SpringBoot集成 表结构 项目目录 dynamic和dyna…...

视觉检测系统,是否所有产品都可以进行视觉检测?
视觉检测系统作为一种先进的质检工具,虽然具有广泛的应用范围,但并非所有产品都适合进行视觉检测。本文将探讨视觉检测系统的适用范围及其局限性。 随着机器视觉技术的快速发展,视觉检测系统已广泛应用于各个行业,为产品质检提供…...
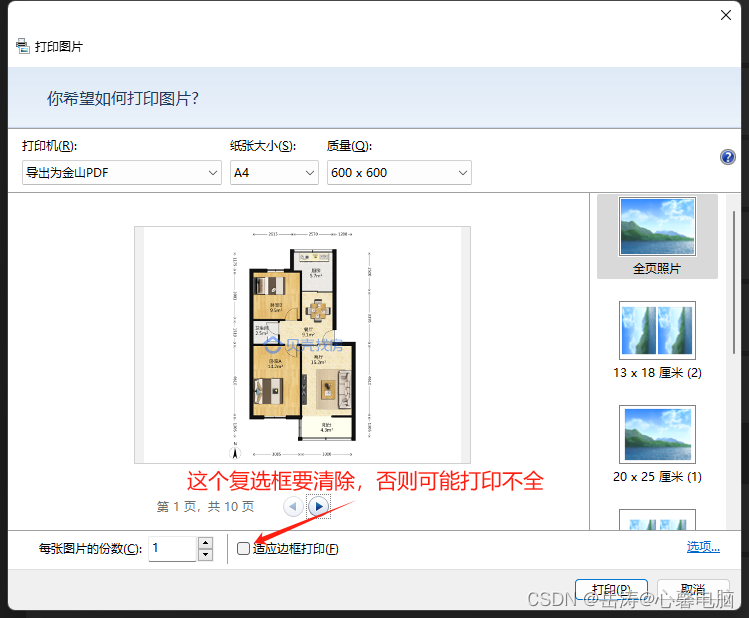
通过金山和微软虚拟打印机转换PDF文件,流程方法及优劣对比
文章目录 一、WPS/金山 PDF虚拟打印机1、常规流程2、PDF文件位置3、严重缺陷二、微软虚拟打印机Microsoft Print to Pdf1、安装流程2、微软虚拟打印机的优势一、WPS/金山 PDF虚拟打印机 1、常规流程 安装过WPS办公组件或金山PDF独立版的电脑,会有一个或两个WPS/金山 PDF虚拟…...
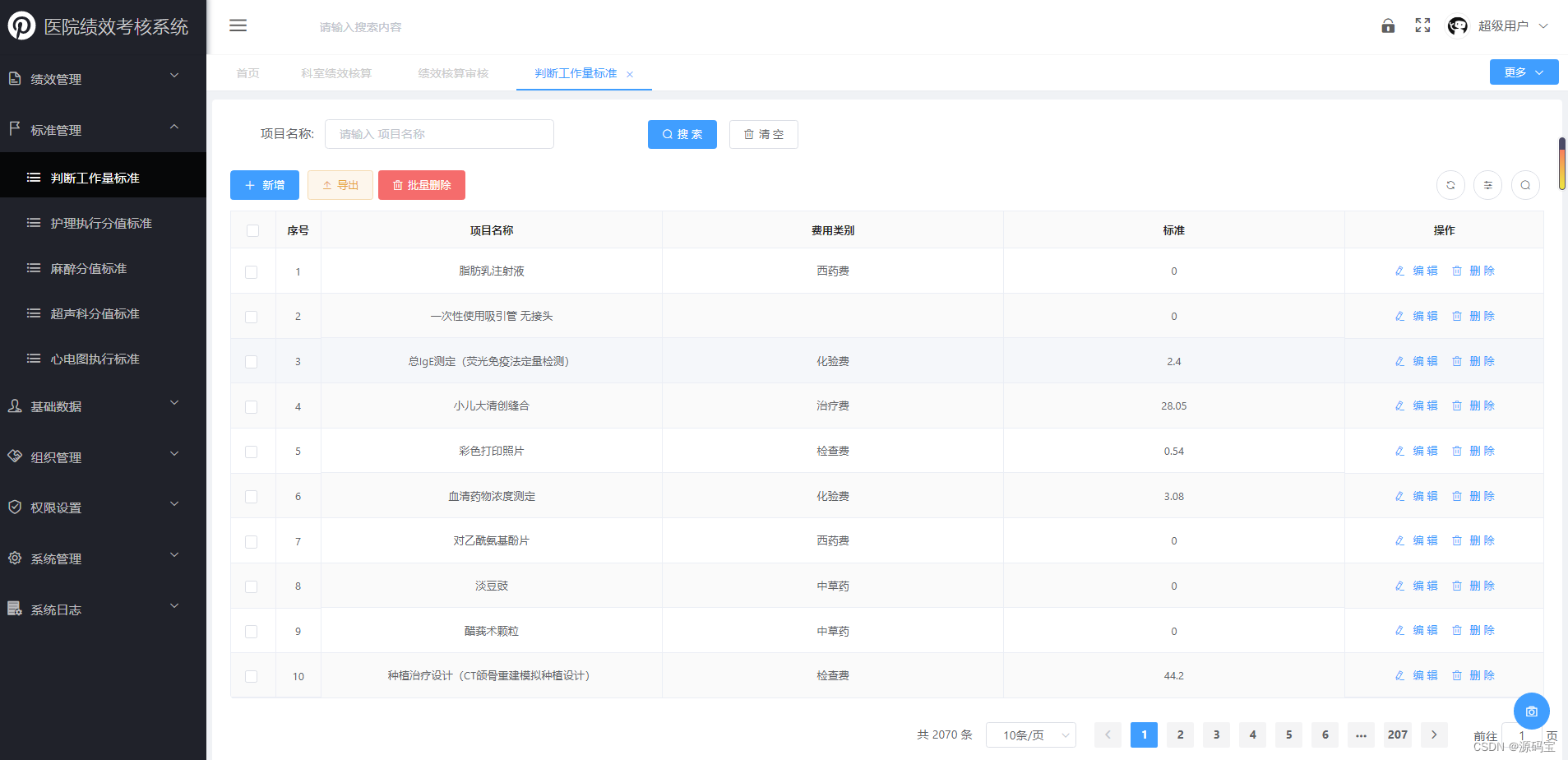
采用java+B/S开发的全套医院绩效考核系统源码springboot+mybaits 医院绩效考核系统优势
采用java开发的全套医院绩效考核系统源码springbootmybaits 医院绩效考核系统优势 医院绩效管理系统解决方案紧扣新医改形势下医院绩效管理的要求,以“工作量为基础的考核方案”为核心思想,结合患者满意度、服务质量、技术难度、工作效率、医德医风等管…...

驱动开发-用户空间和内核空间数据传输
1.用户空间-->内核空间(写) #include<linux/uaccess.h> int copy_from_user(void *to,const void __user volatile*from,unsigned long n) 函数功能:将用户空间数据拷贝到内核空间 参数: to:内核空间首地…...
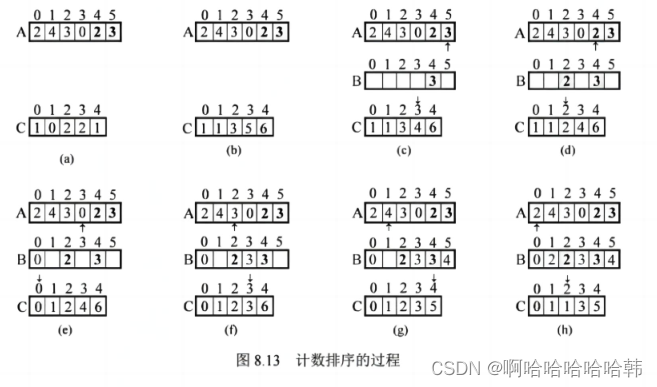
【408精华知识】速看!各种排序的大总结!
文章目录 一、插入排序(一)直接插入排序(二)折半插入排序(三)希尔排序 二、交换排序(一)冒泡排序(二)快速排序 三、选择排序(一)简单选…...
【STM32 |程序实例】按键控制、光敏传感器控制蜂鸣器
目录 前言 按键控制LED 光敏传感器控制蜂鸣器 前言 上拉输入:若GPIO引脚配置为上拉输入模式,在默认情况下(GPIO引脚无输入),读取的GPIO引脚数据为1,即高电平。 下拉输入:若GPIO引脚配置为下…...

Spring boot使用websocket实现在线聊天
maven依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spr…...

品牌设计理念和logo设计方法
一 品牌设计的目的 设计是为了传播,让传播速度更快,传播效率更高,减少宣传成本 二 什么是好的品牌设计 好的设计是为了让消费者更容易看懂、记住的设计, 从而辅助传播, 即 看得懂、记得住。 1 看得懂 就是让别人看懂…...

Python | Leetcode Python题解之第88题合并两个有序数组
题目: 题解: class Solution:def merge(self, nums1: List[int], m: int, nums2: List[int], n: int) -> None:"""Do not return anything, modify nums1 in-place instead."""p1, p2 m - 1, n - 1tail m n - 1whi…...

vscode新版本remotessh服务端报`GLIBC_2.28‘ not found解决方案
问题现象 通过vscode的remotessh插件连接老版本服务器(如RHEL7,Centos7)时,插件会报错,无法连接。 查看插件的错误日志可以看到类似如下的报错信息: dc96b837cf6bb4af9cd736aa3af08cf8279f7685/node: /li…...

taotoken多模型聚合平台为matlab开发者提供稳定ai能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken多模型聚合平台为matlab开发者提供稳定ai能力 对于使用MATLAB进行数据分析、仿真建模或算法开发的工程师和研究人员而言&a…...

MultiHighlight智能高亮插件架构解析与性能优化实践
MultiHighlight智能高亮插件架构解析与性能优化实践 【免费下载链接】MultiHighlight Jetbrains IDE plugin: highlight identifiers with custom colors 🎨💡 项目地址: https://gitcode.com/gh_mirrors/mu/MultiHighlight 在复杂的代码阅读场景…...

SPT-AKI存档编辑器完整指南:快速定制你的离线塔科夫体验
SPT-AKI存档编辑器完整指南:快速定制你的离线塔科夫体验 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_mirrors…...

AI Scientist-v2最佳实践:提高研究成功率的10个技巧
AI Scientist-v2最佳实践:提高研究成功率的10个技巧 【免费下载链接】AI-Scientist-v2 The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search 项目地址: https://gitcode.com/GitHub_Trending/ai/AI-Scientist-v2 想…...

如何在JavaScript中精确计算太阳位置和月亮相位:SunCalc终极指南
如何在JavaScript中精确计算太阳位置和月亮相位:SunCalc终极指南 【免费下载链接】suncalc A tiny JavaScript library for calculating sun/moon positions and phases. 项目地址: https://gitcode.com/gh_mirrors/su/suncalc 你是否曾想过,如何…...

Office自定义界面编辑器:打造你的专属Office工作台
Office自定义界面编辑器:打造你的专属Office工作台 【免费下载链接】office-custom-ui-editor Standalone tool to edit custom UI part of Office open document file format 项目地址: https://gitcode.com/gh_mirrors/of/office-custom-ui-editor 你是否厌…...

在自动化工作流中集成大模型,利用Taotoken统一API调用与管理
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化工作流中集成大模型,利用Taotoken统一API调用与管理 将大模型能力集成到自动化工作流中,例如CI/CD…...

AI音频转封面终极指南:3步打造专业音乐封面
AI音频转封面终极指南:3步打造专业音乐封面 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen 想要为你的音乐作…...

智能网盘直链解析工具:免会员下载加速的全新解决方案
智能网盘直链解析工具:免会员下载加速的全新解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云…...

作业5:案例挑战
文章目录1、密码锁设计 P110,2、基于PWM的可调光台灯设计 P131,3、动态密码获取系统设计 P210,效果(1) 密码模式说明(2) 测试密码输入(3) 测试修改密码(4) 测试修改密码模式4、数码管时钟系统设计 P228,7.5.2 数码管时钟系统设计&…...