学习笔记——字符串(单模+多模+练习题)
单模匹配
Brute Force算法(暴力)
算法思想
母串和模式串字符依次配对,如果配对成功则继续比较后面位置是否相同,如果出现匹配不成功的位置,则j(模式串当前的位置)从头开始,i(母串当前的位置)回到上一次开始位置的下一个位置。
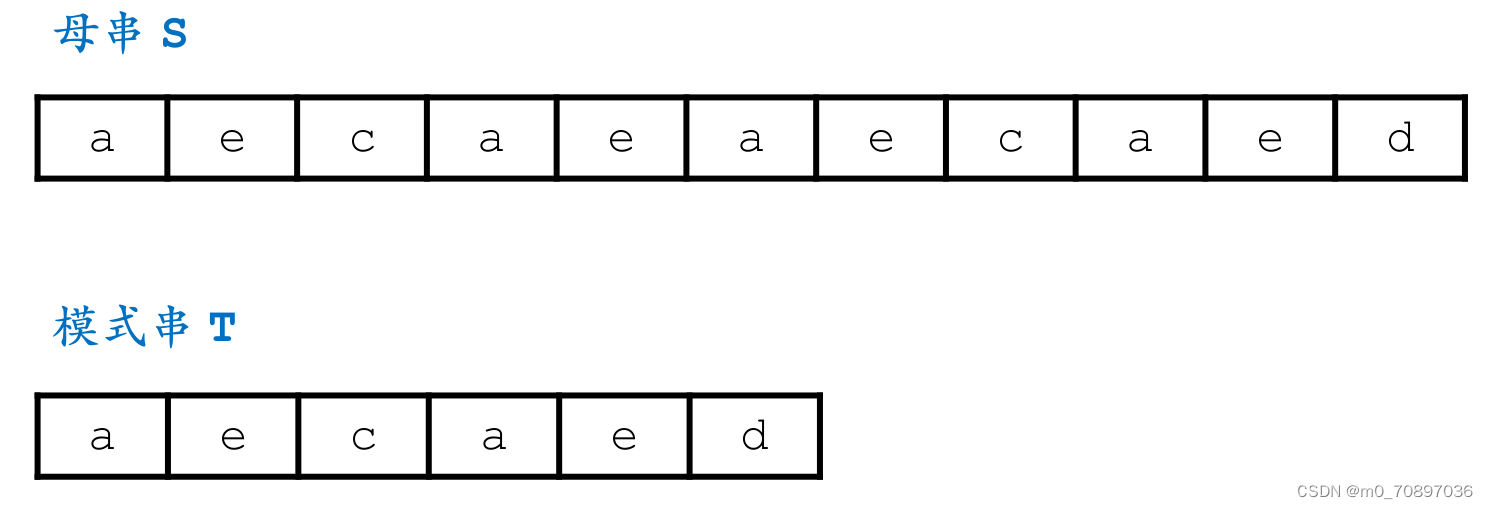
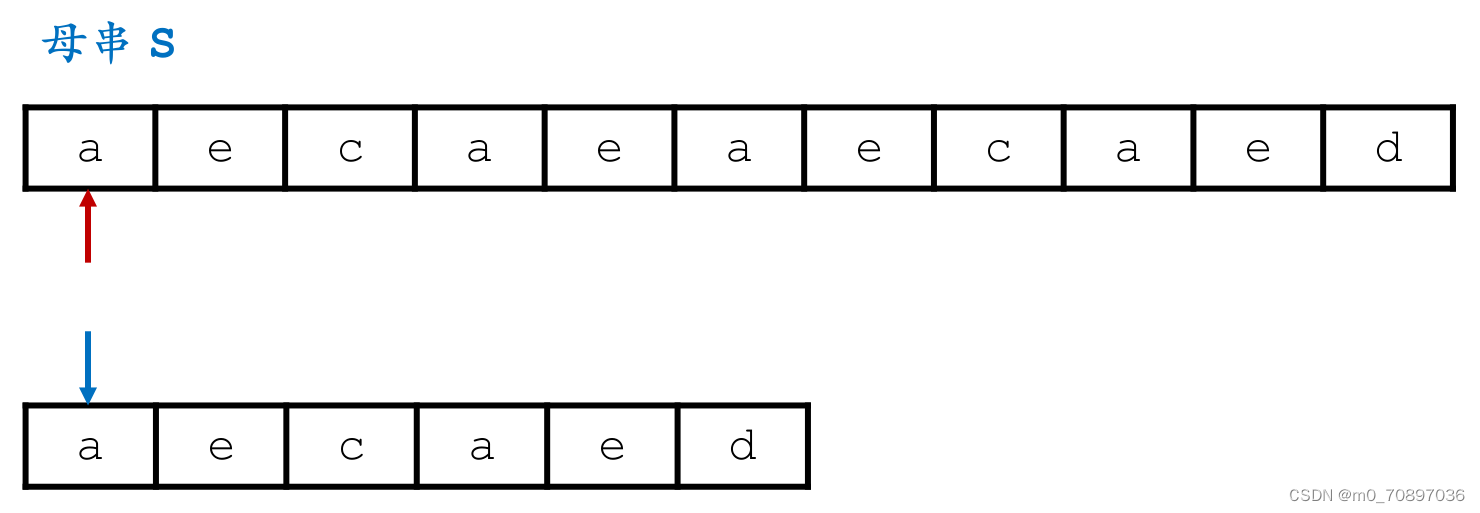
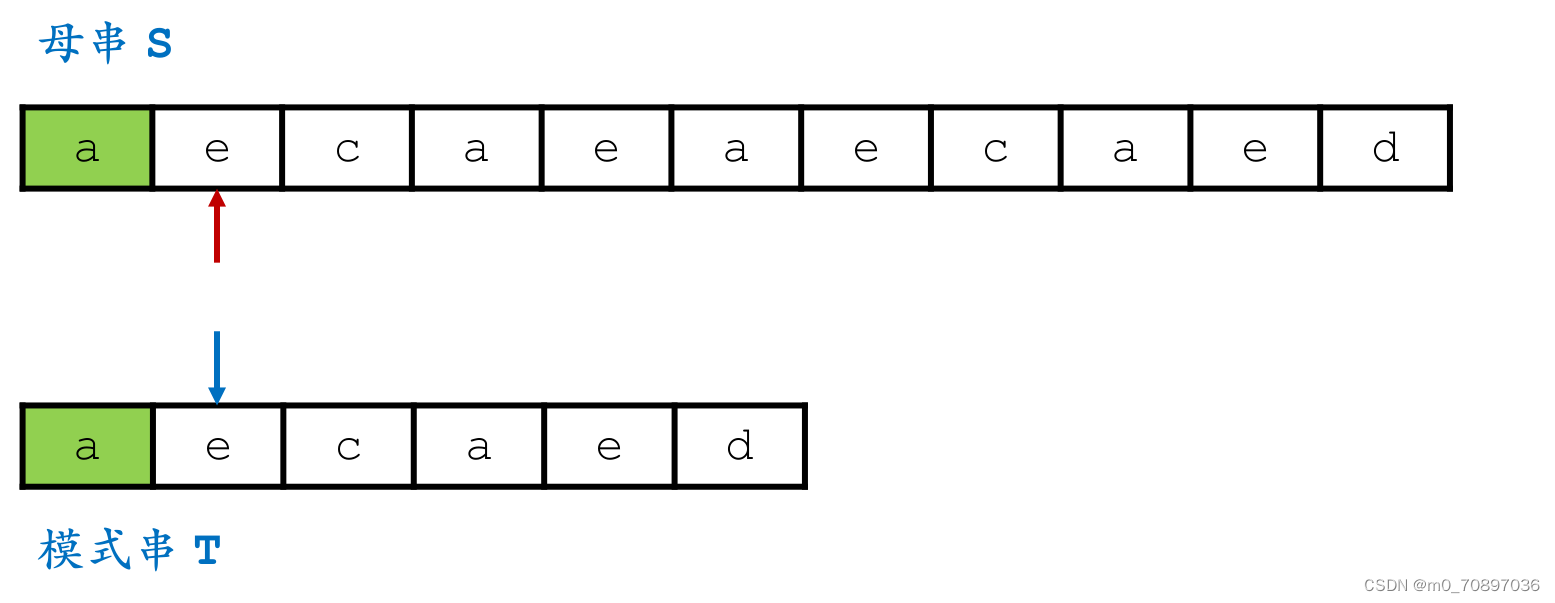
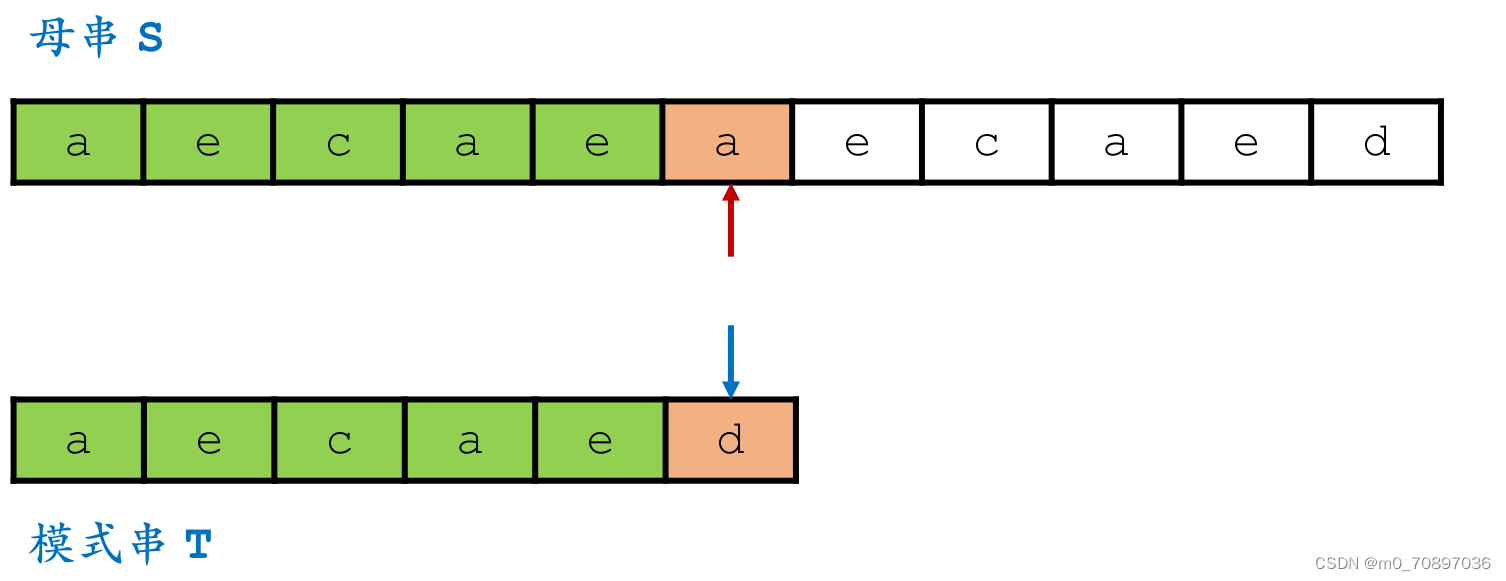
代码
int brute_force(const char *s, const char *t) {for (int i = 0; s[i]; i++) {//遍历母串int flag = 1;//标志为1说明完成了匹配for (int j = 0; t[j]; j++) {if (s[i + j] == t[j]) continue;flag = 0;//到达该位置说明出现了失配break;}if (flag == 1) return i;}return -1;
}
Sunday算法
算法思想
和BF的本质区别在于,BF的母串每次只往后移动一位,Sunday可以移动若干位,下面我们讨论若干位具体是多少位。
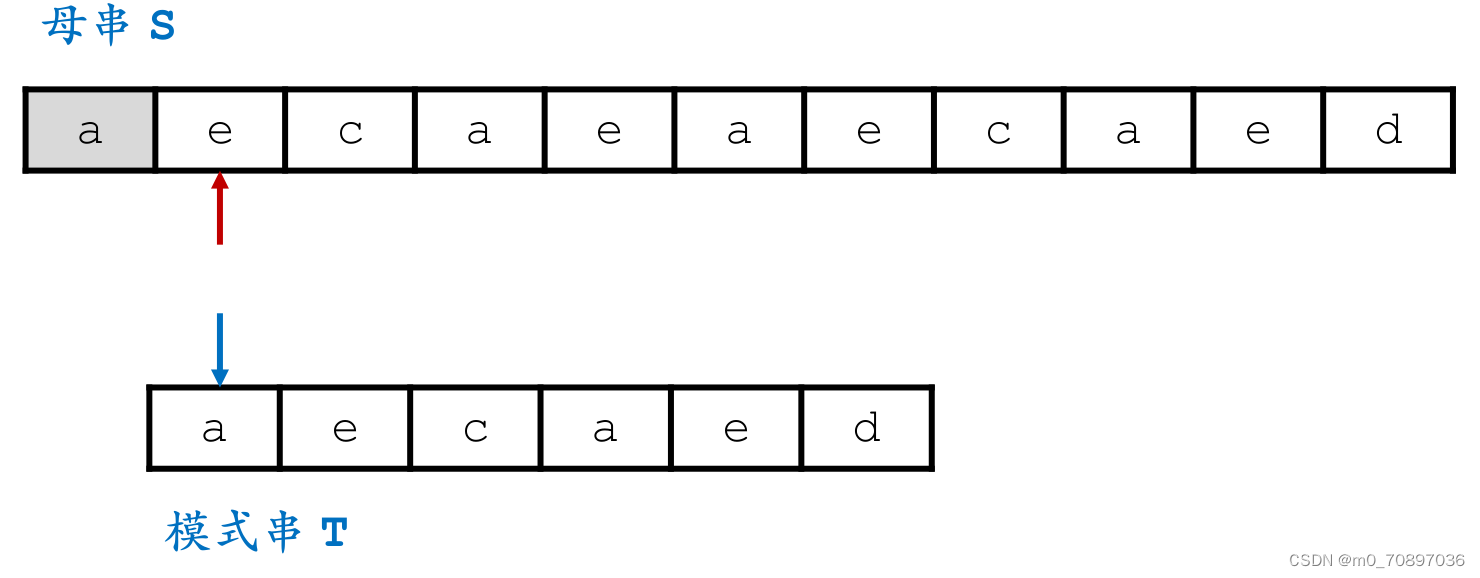
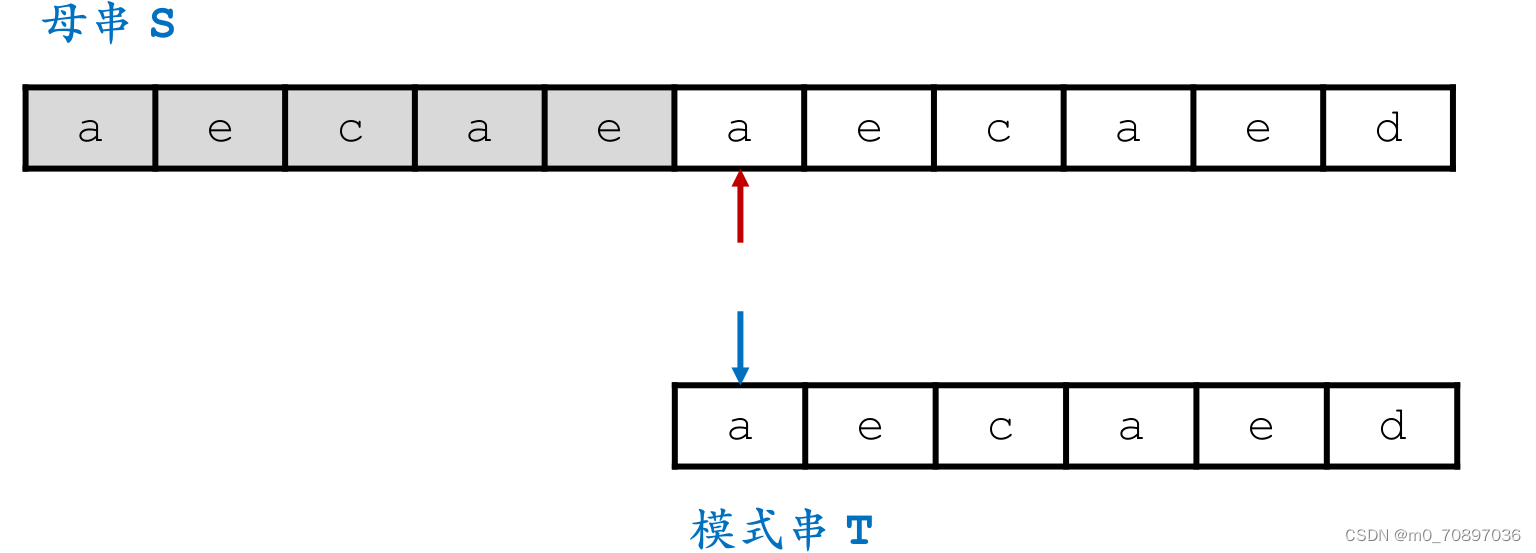
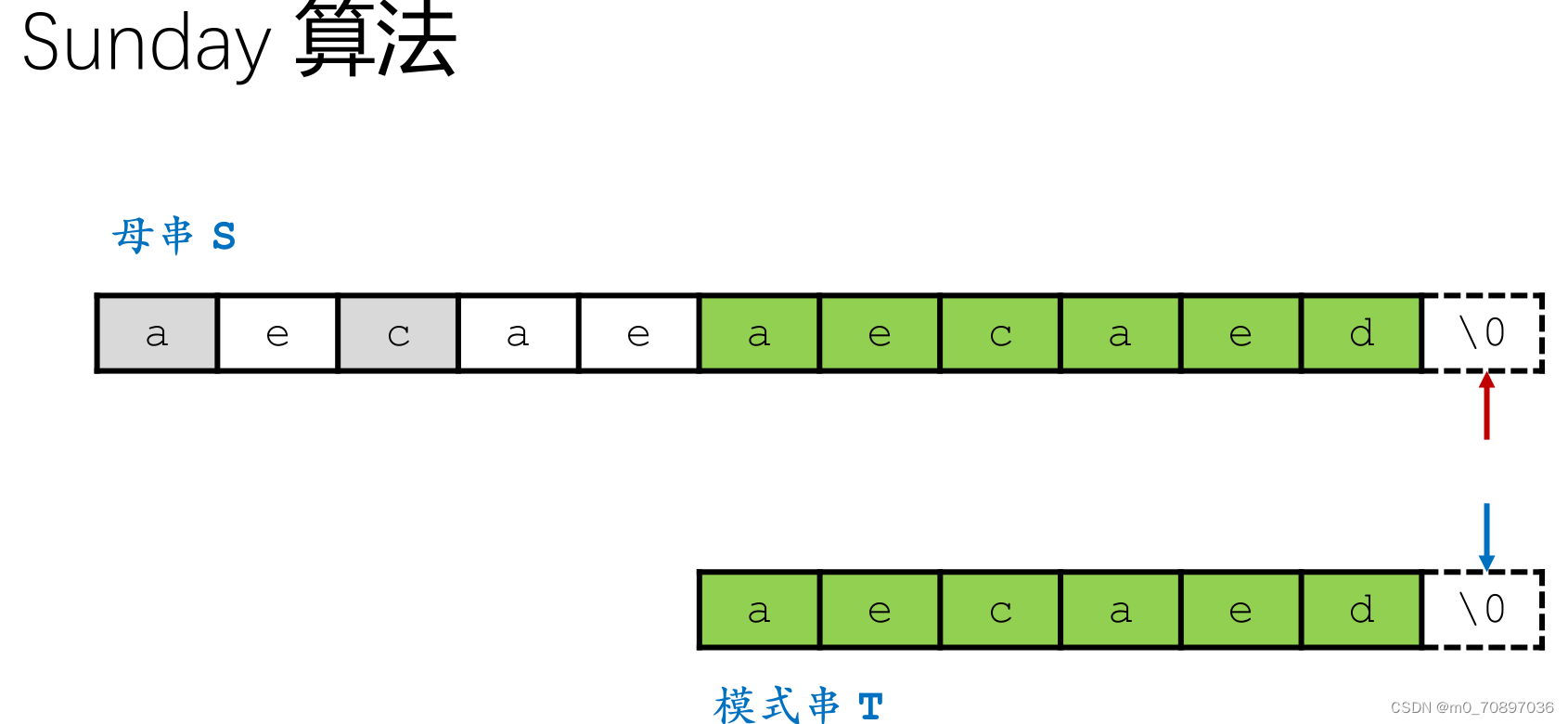
当前位置失配。
找到模式串最后一位在母串中对应位置后面一个位置(黄金对齐点位),其值为e,同时找到T中最后一次e出现的位置。
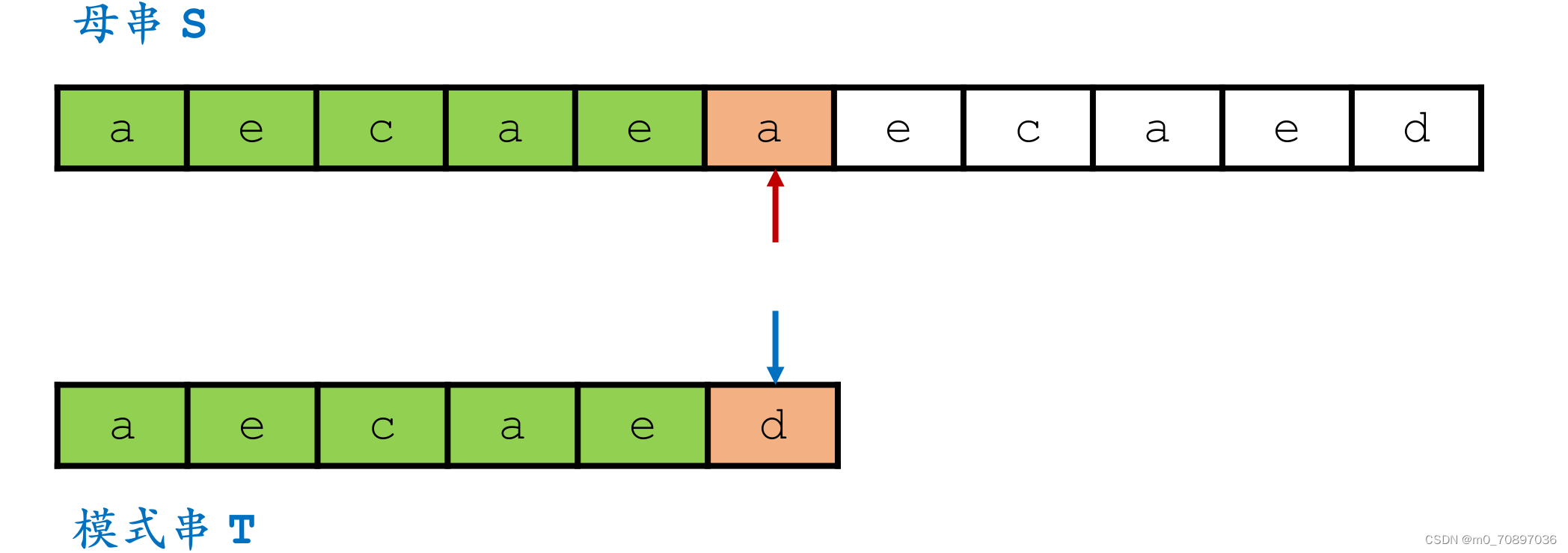
移动母串的接下来匹配的开始位置,使得上面提到的两个e对其,T的j指针从头开始。
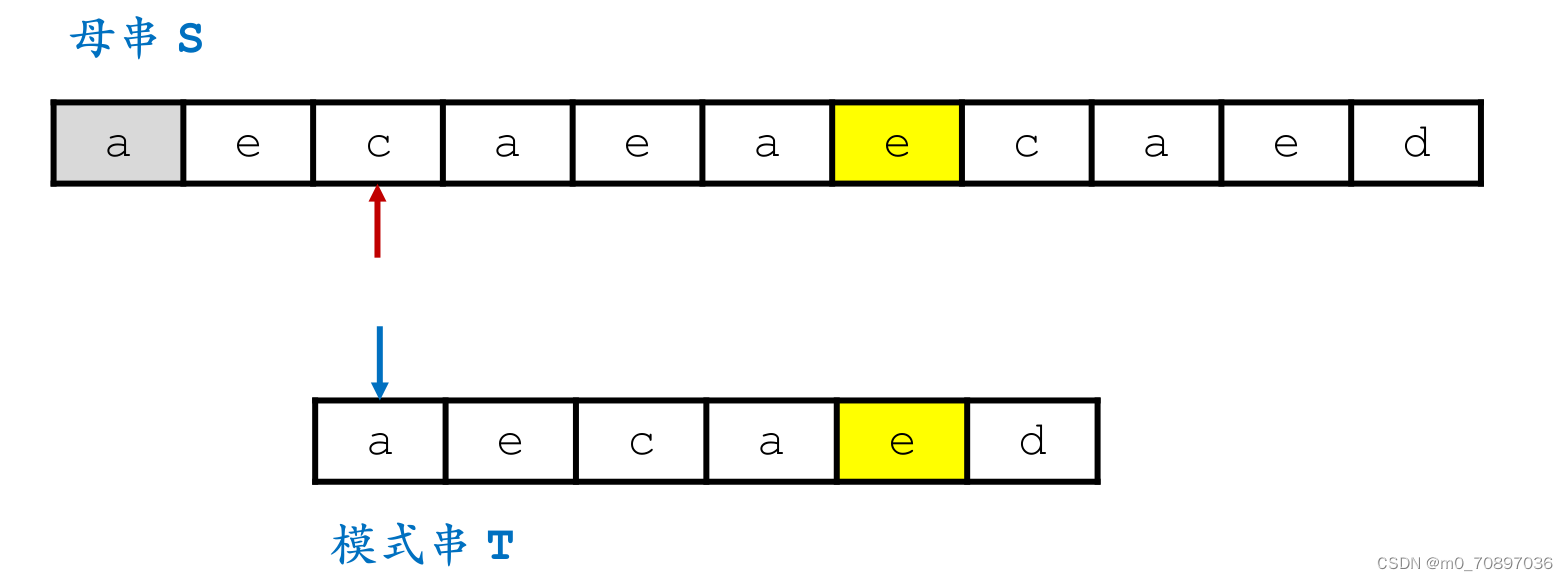
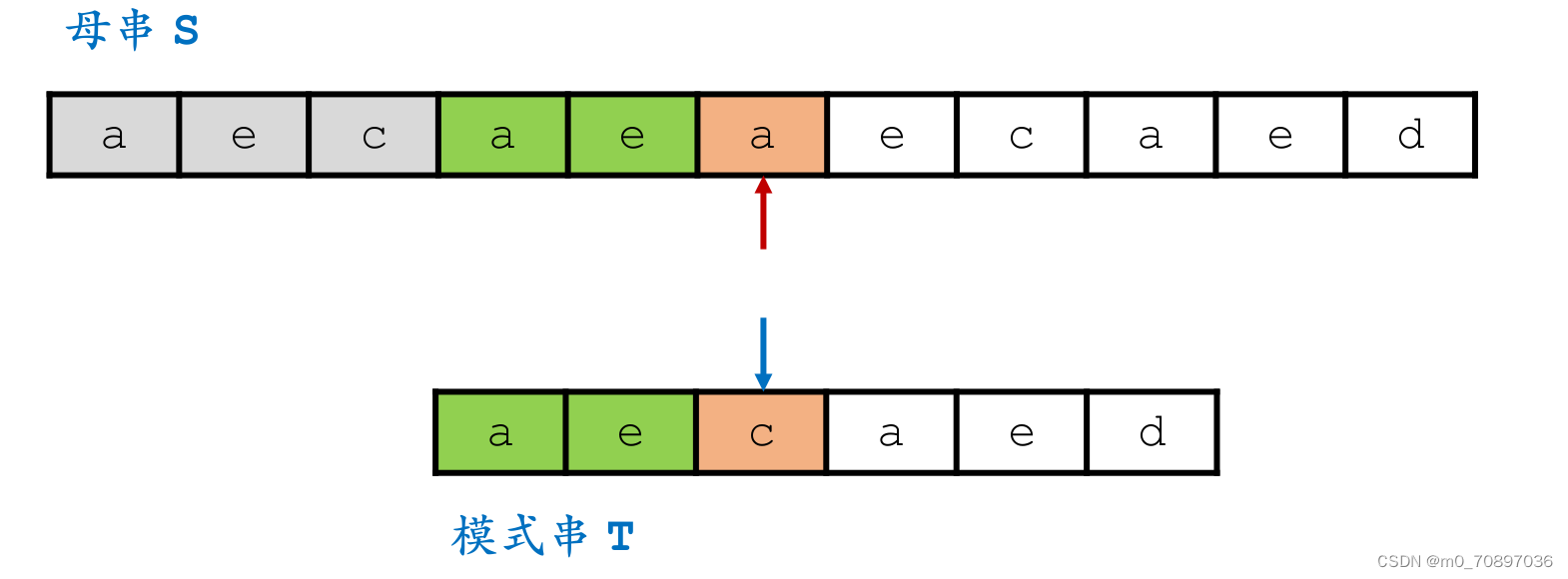
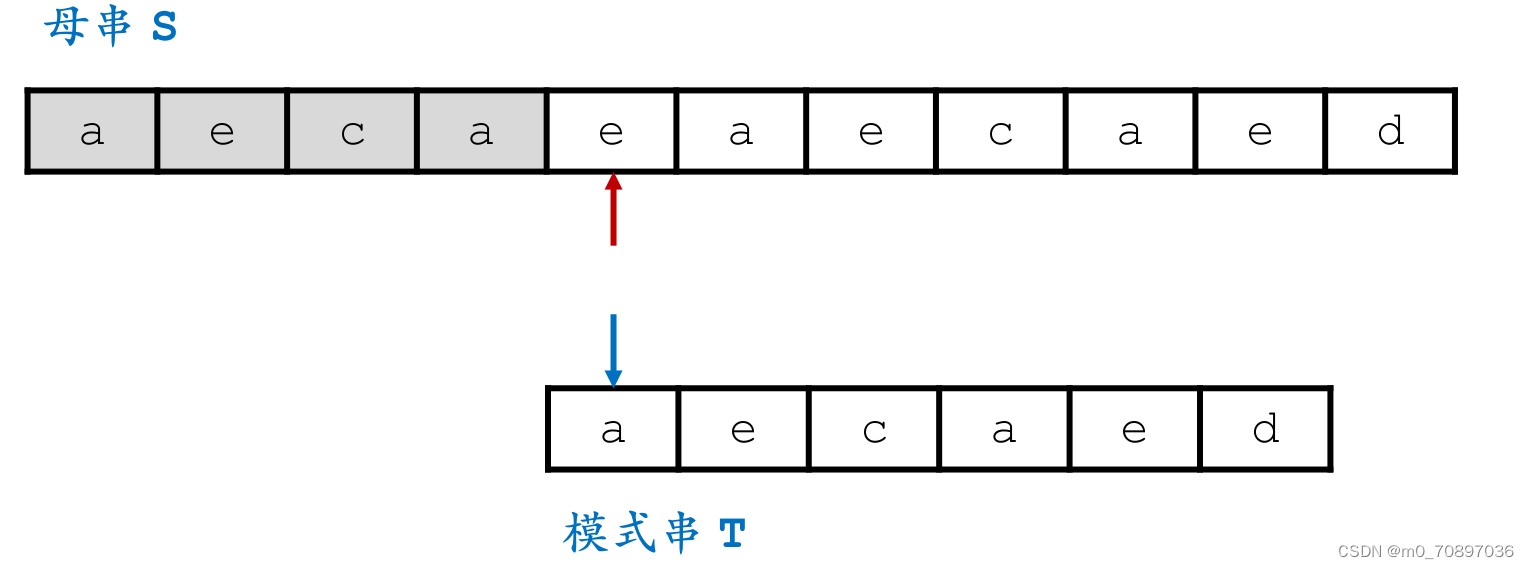
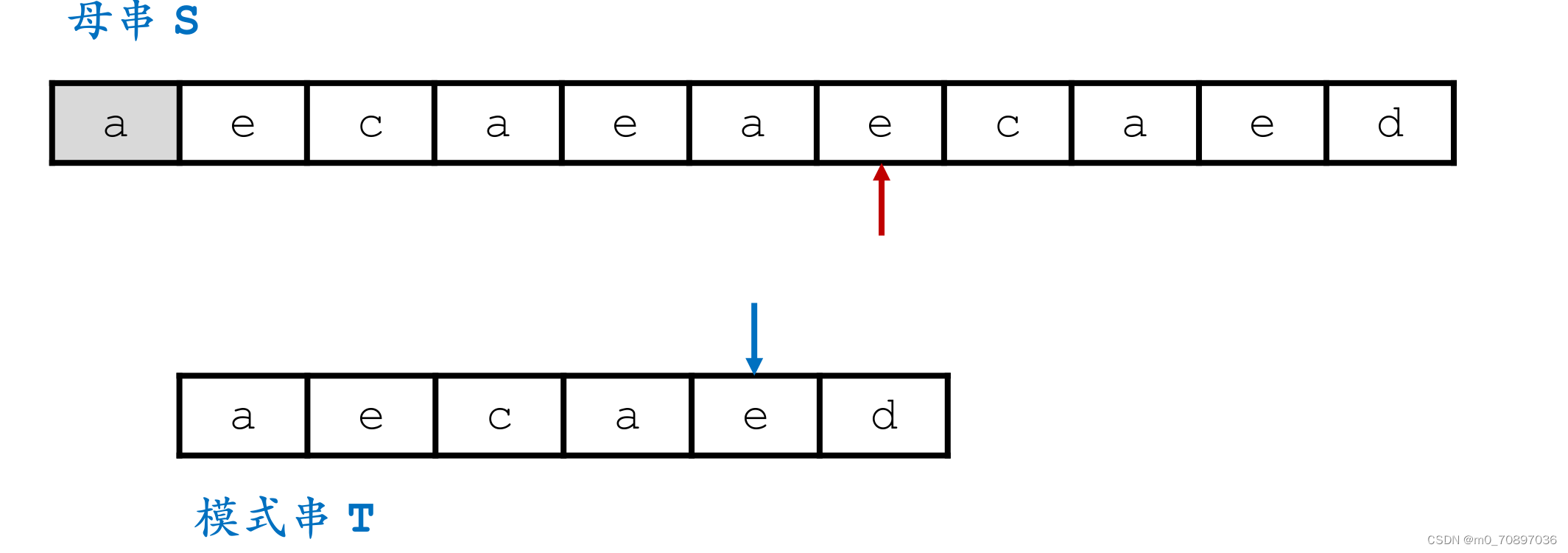
新的一轮遍历,发现第一个位置就失配。
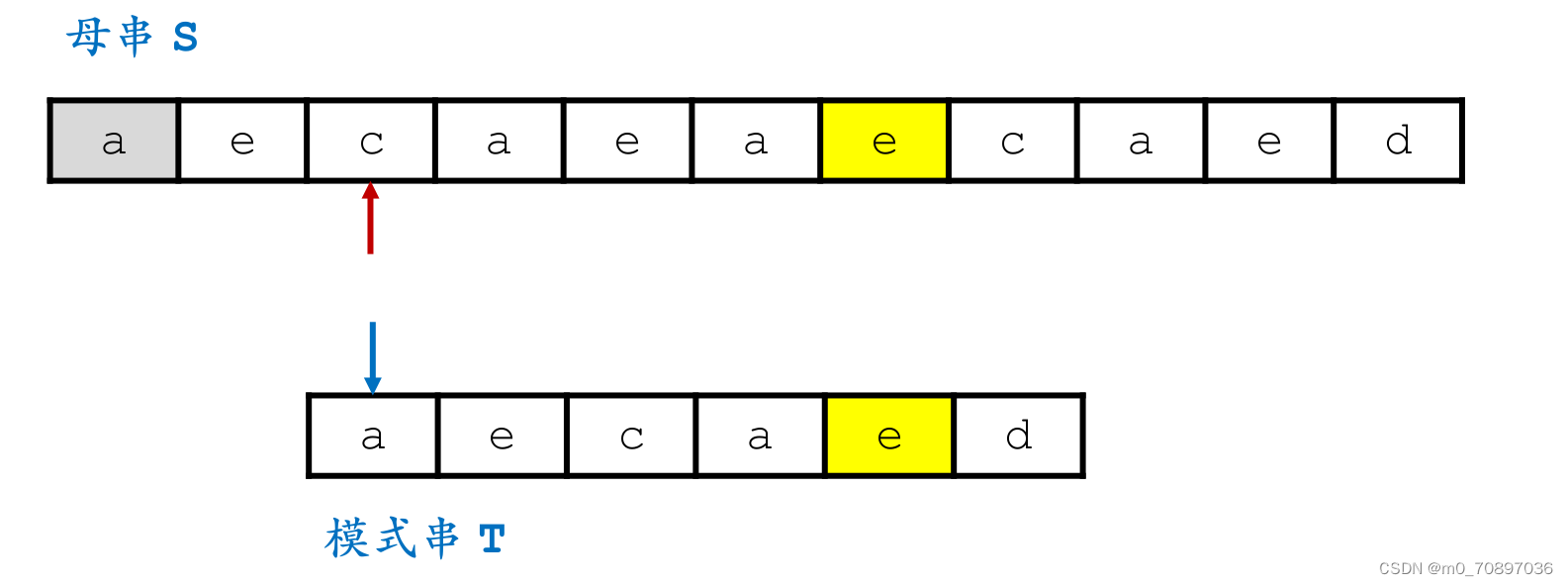
按照相同的逻辑,找到模式串最后一位在母串中对应位置后面一个位置(黄金对齐点位),其值为a,同时找到T中最后一次a出现的位置。
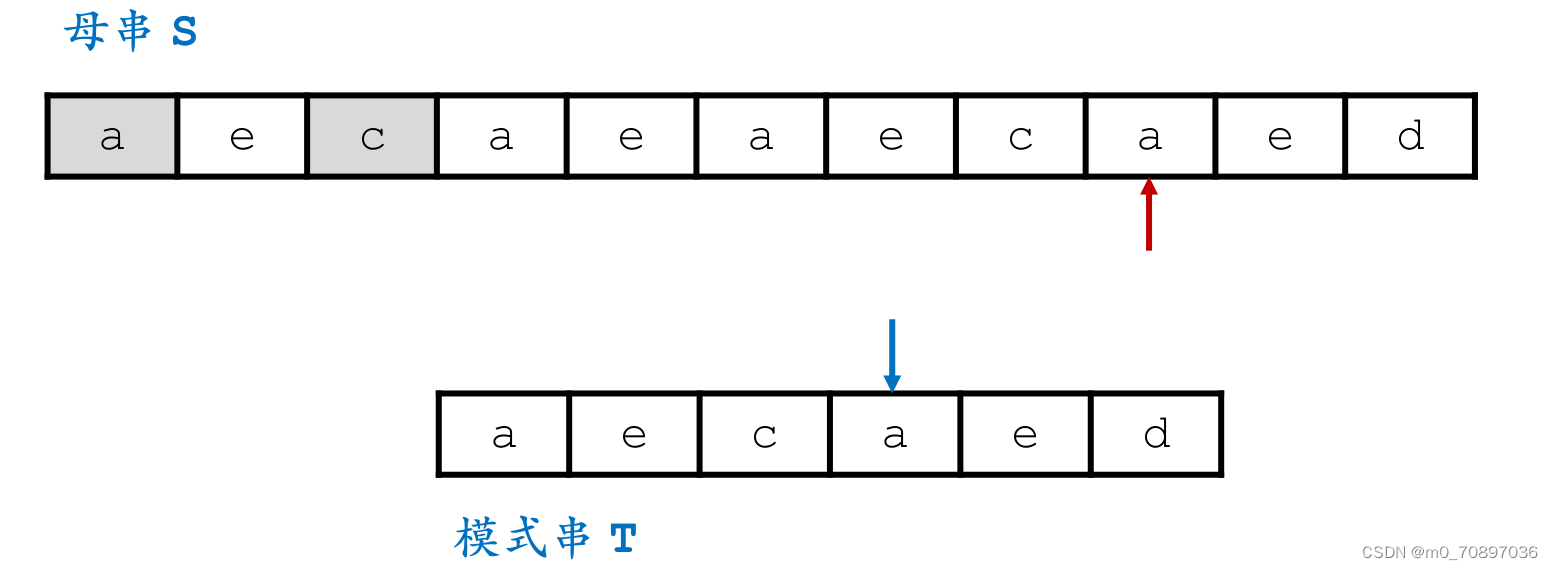
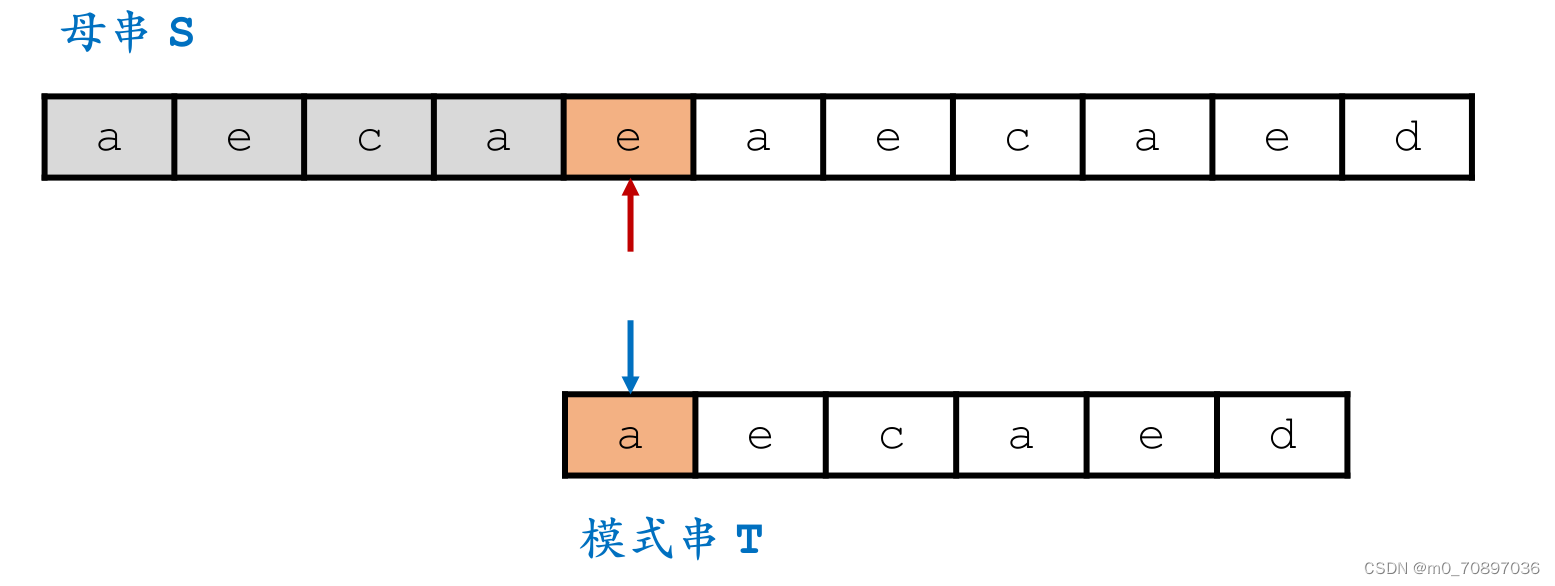
i移动若干位,使得两个a能够对齐。
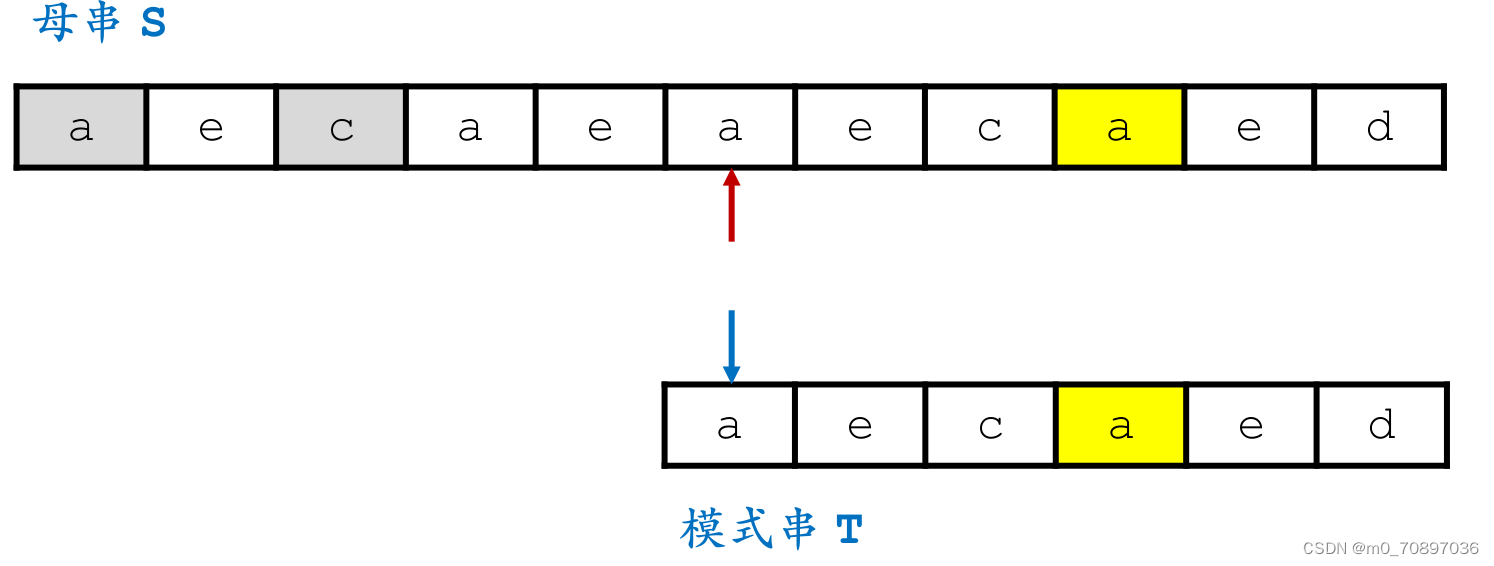
完成匹配。
代码
int sunday(const char *s, const char *t) {int len[256] = {0}, n = strlen(s), m = strlen(t);//len[x]记录当前的黄金对齐点位的元素是x时,i需要移动的距离 for (int i = 0; i < 256; i++) len[i] = m + 1;//默认为m+1,意思是如果当前值没有在T中出现过,那么直接移动m+1,使得T直接从黄金对齐点位的后面开始匹配 for (int i = 0; t[i]; i++) len[t[i]] = m - i;//移动距离为m-i,即T的长度减去所在位置 for (int i = 0; i + m <= n; i += len[s[i + m]]) {int flag = 1;//标志为1说明完成了匹配for (int j = 0; t[j]; j++) {if (s[i + j] == t[j]) continue;flag = 0;//到达该位置说明出现了失配break;}if (flag == 1) return i;}return -1;
}
Boyer Moore 算法
本算法时Sunday算法的前身,实现起来比较繁琐复杂。
算法思想
理解 BM 算法的核心法门:
- 失配时,模式串尽可能向后移动最大长度
- 移动的长度取决于2条规则中的较大值
- 规则1:坏字符规则 delta1
- 规则2:好后缀规则 delta2
匹配方向
BM的匹配方向为从后往前。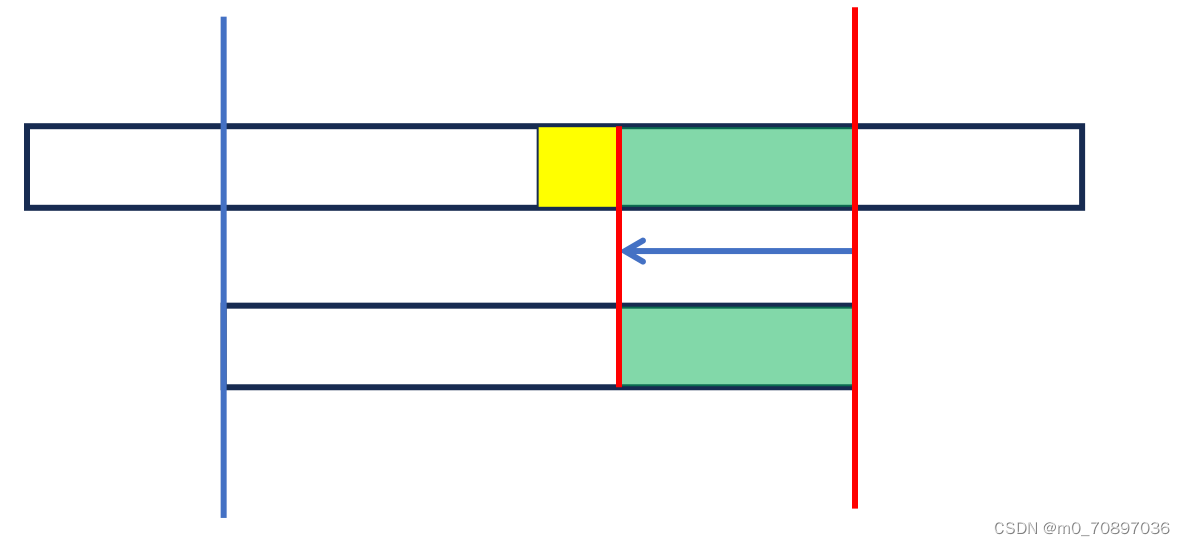
坏字符规则
向前匹配过程中出现失配点。
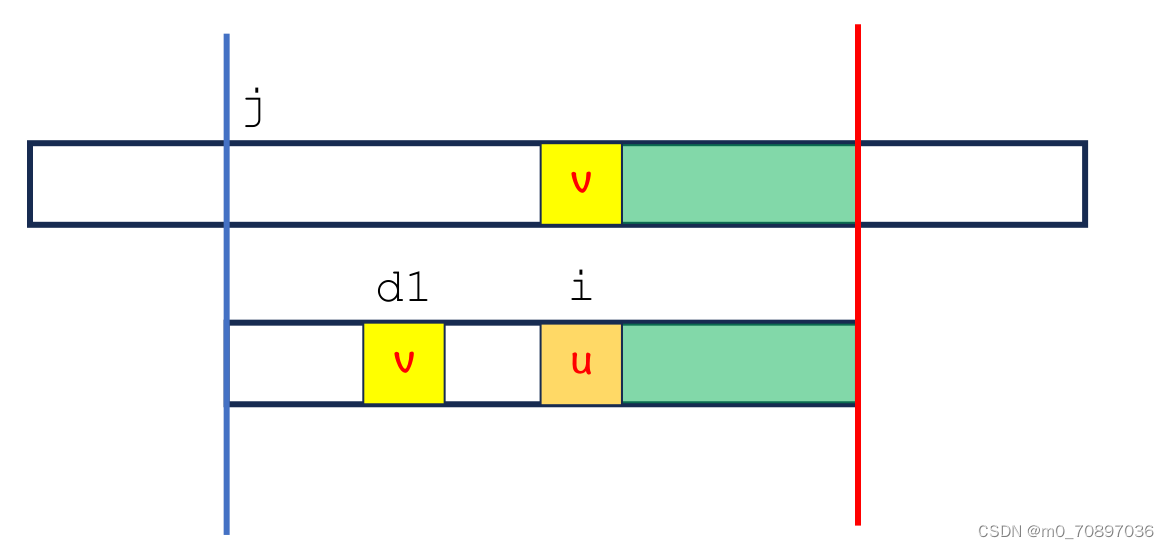
此时操作与Sunday类似,即移动S指针j,使得T最后一次出现v的位置与S中v的位置对齐。
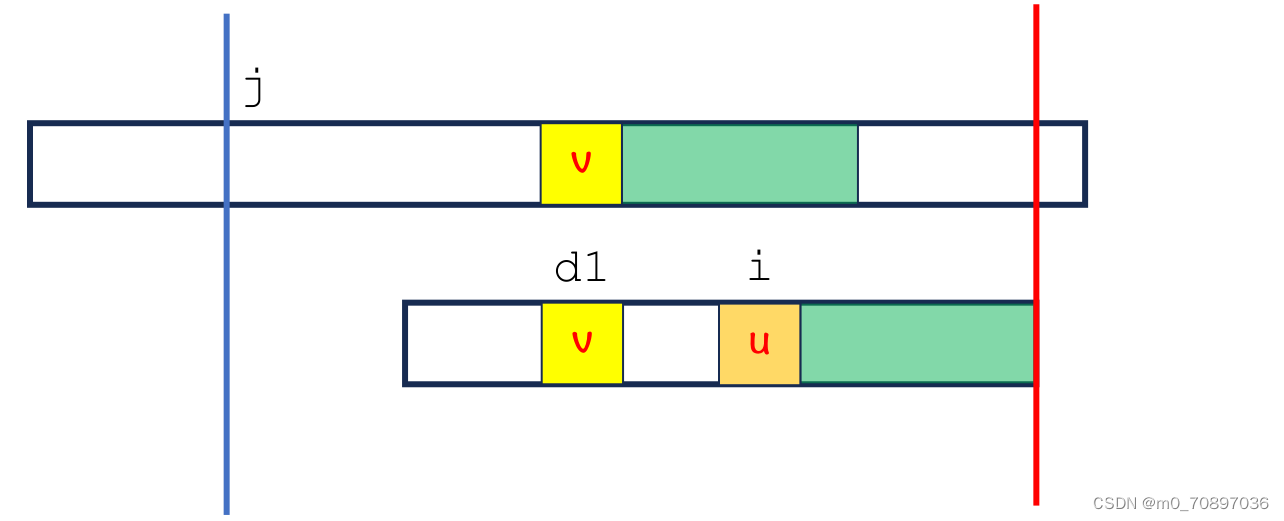
回退bug
但是BM有回退bug,在进行上述操作的过程中,模式串有可能会往前移,显然不可取。



为了解决上面问题,引入好后缀规则。
好后缀规则
除了找到最后一次出现的与失配点值相同的位置外(坏字符规则),也可以找到和已经匹配的序列相同的序列,并与S串进行对其。
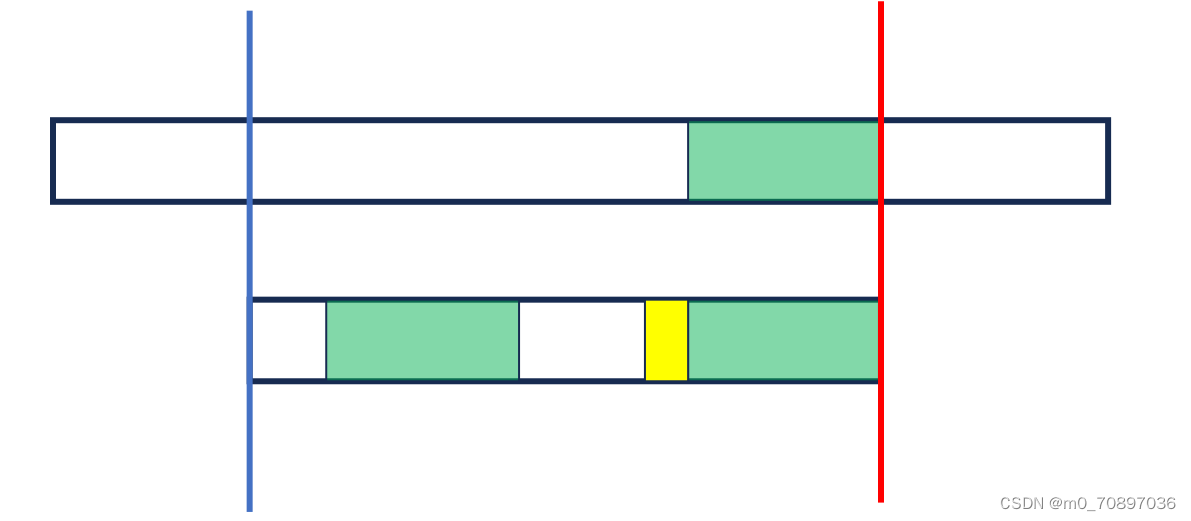
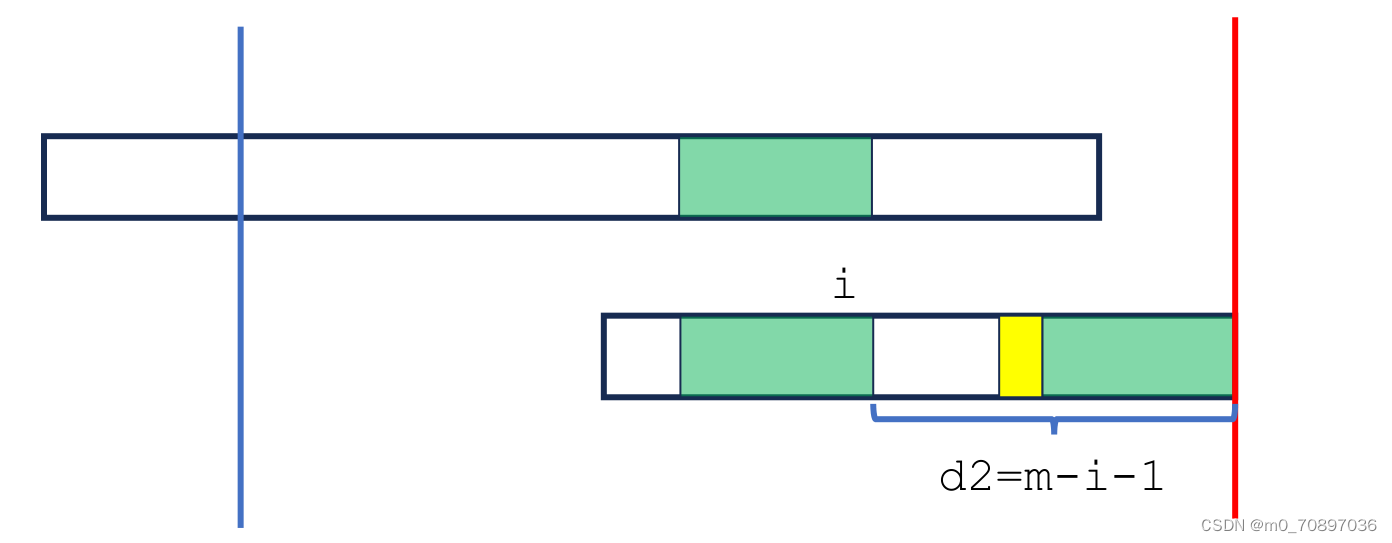
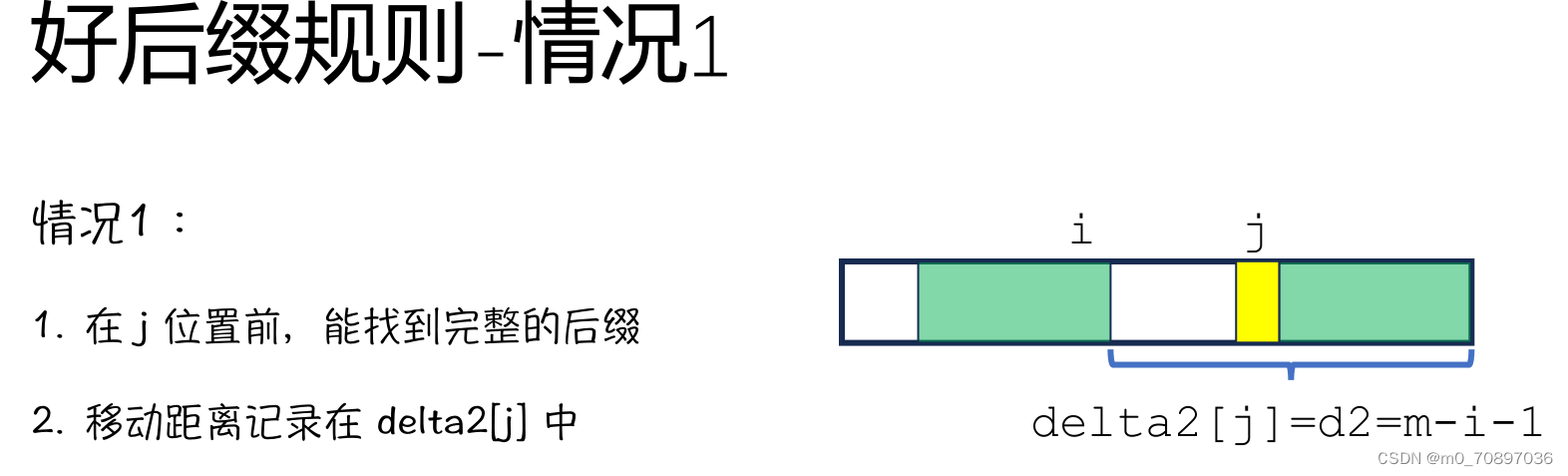

情况2即无法找到完整的后缀,此时蓝色部分后缀一定在T的起始位置,证明略。
BM总结
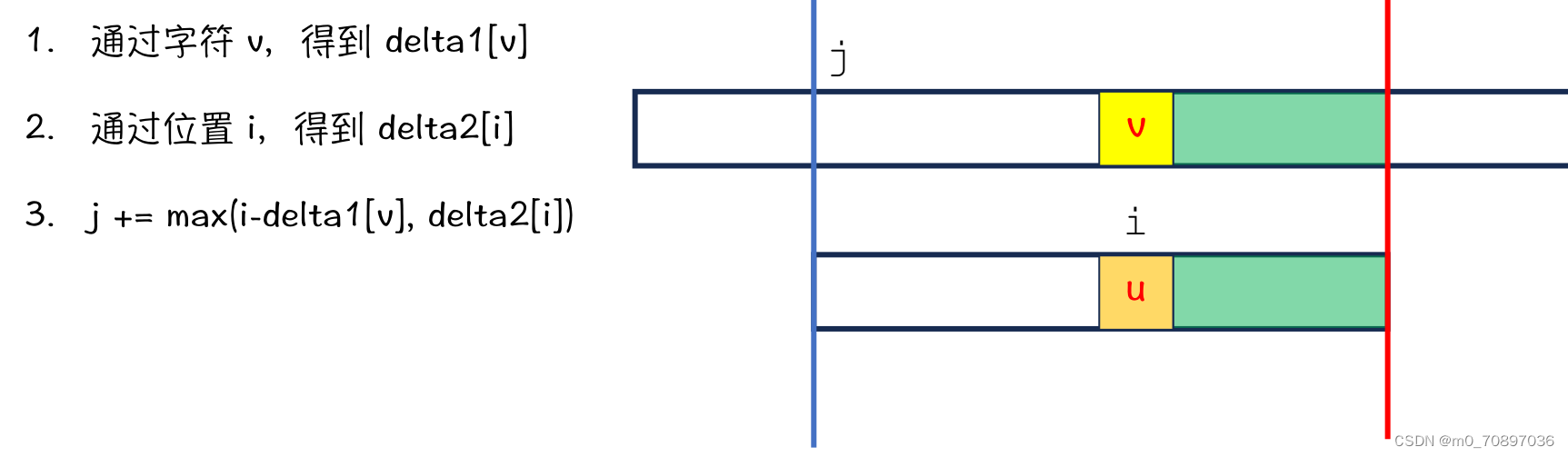
代码
int *getDelta1(const char *t) {int *delta1 = (int *)malloc(sizeof(int) * 256);for (int i = 0; i < 256; i++) delta1[i] = -1;for (int i = 0; t[i]; i++) {delta1[t[i]] = i;}return delta1;
}int *getSuffixes(const char *t) { int tlen = strlen(t);int *suff = (int *)malloc(sizeof(int) * tlen);suff[tlen - 1] = tlen;for (int i = 0; i < tlen - 1; i++) {int j = 0;while (j <= i && t[tlen - j - 1] == t[i - j]) ++j;suff[i] = j;}return suff;
}int *getDelta2(const char *t) {int *suff = getSuffixes(t);// printf("suff : ");// for (int i = 0; t[i]; i++) printf("%d ", suff[i]);// printf("\n");int tlen = strlen(t), lastInd = tlen - 1;int *delta2 = (int *)malloc(sizeof(int) * tlen);for (int i = 0; t[i]; i++) delta2[i] = tlen;for (int i = 0; i < tlen; i++) {if (suff[i] != i + 1) continue;for (int j = 0; j <= lastInd - suff[i]; j++) delta2[j] = lastInd - i;}for (int i = 0; i < lastInd; i++) {delta2[lastInd - suff[i]] = lastInd - i;}return delta2;
}int BM(const char *s, const char *t) {int *delta1 = getDelta1(t);int *delta2 = getDelta2(t);int slen = strlen(s), tlen = strlen(t);for (int j = 0; j + tlen <= slen;) {int i = tlen - 1;while (i >= 0 && t[i] == s[j + i]) --i;if (i == -1) return j;// printf("i=%d, delta1[%c]=%d, delta2[%d]=%d\n", i, s[j + i], delta1[s[j + i]], i, delta2[i]);j += max(i - delta1[s[j + i]], delta2[i]);}return -1;
}
KMP算法
算法思想
出现失配点
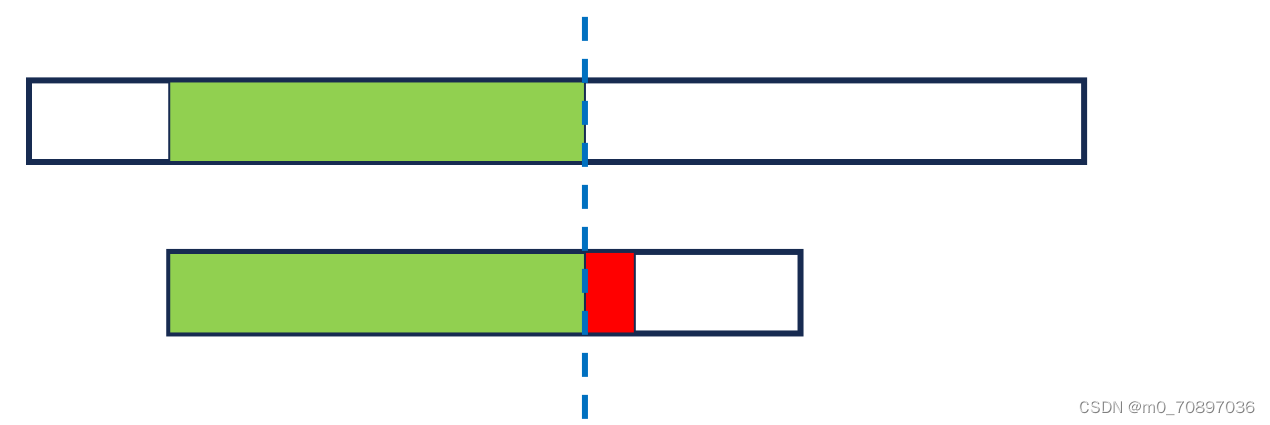
将模式串后移,使得开始部分能够和S中具有重合
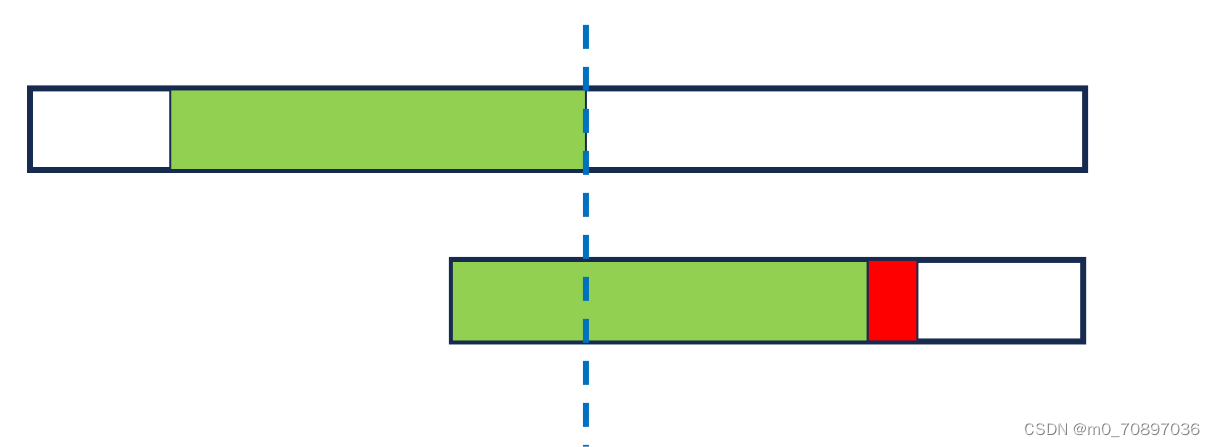
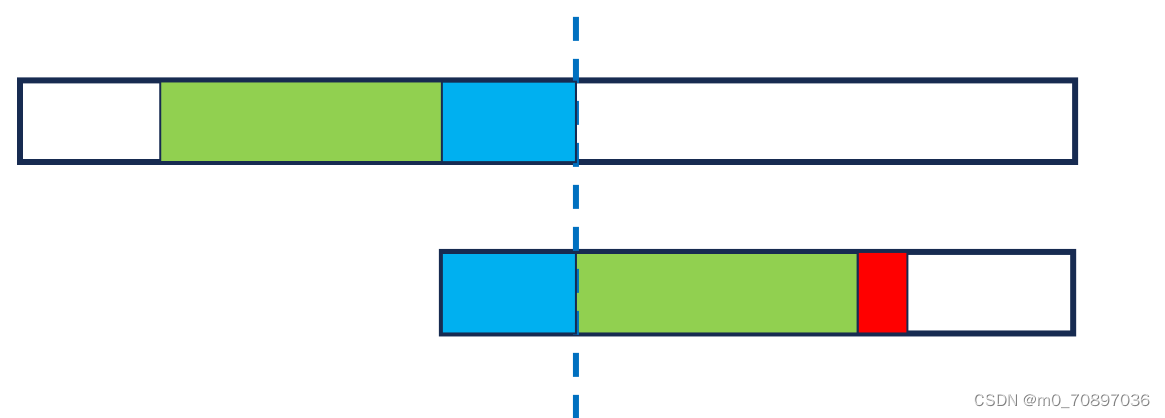
经简单推到得,四个蓝色部分相同。
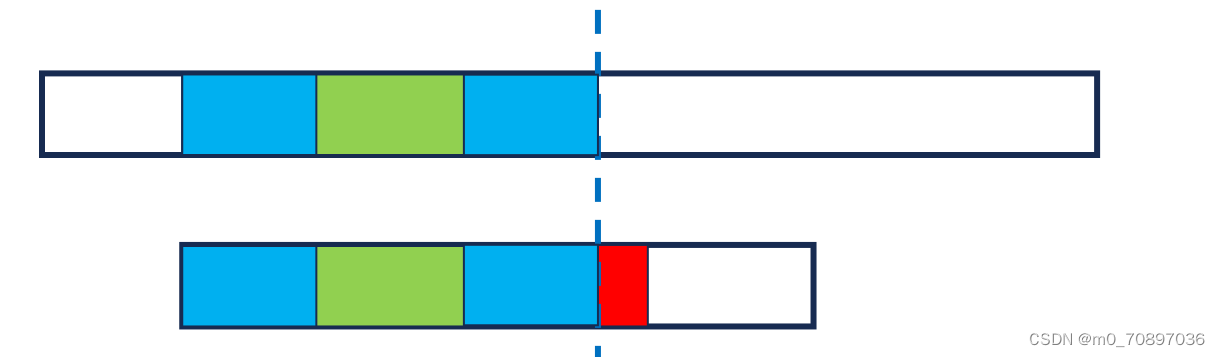
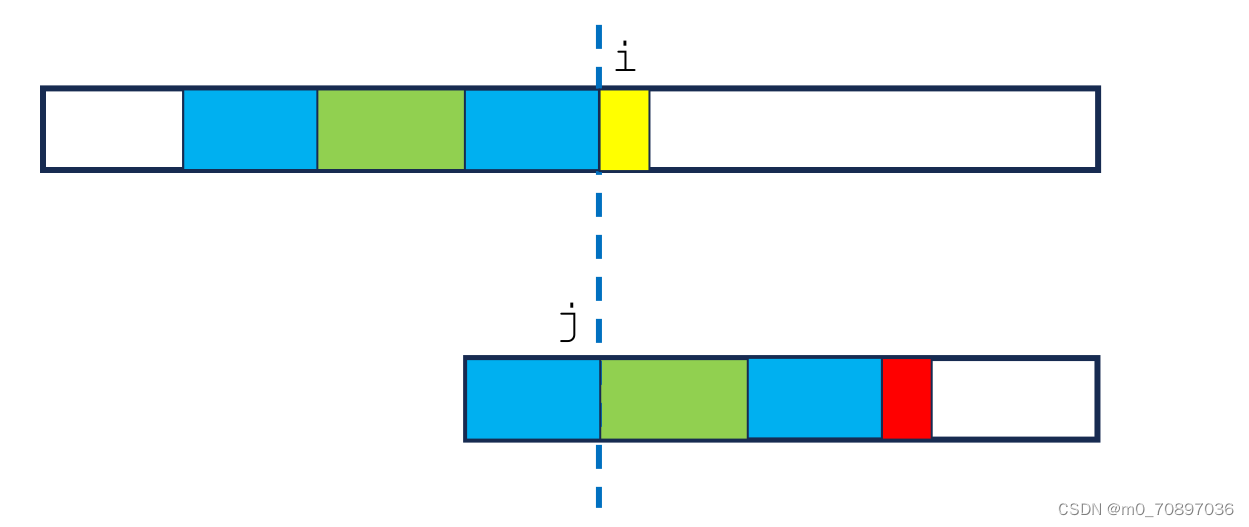
next数组

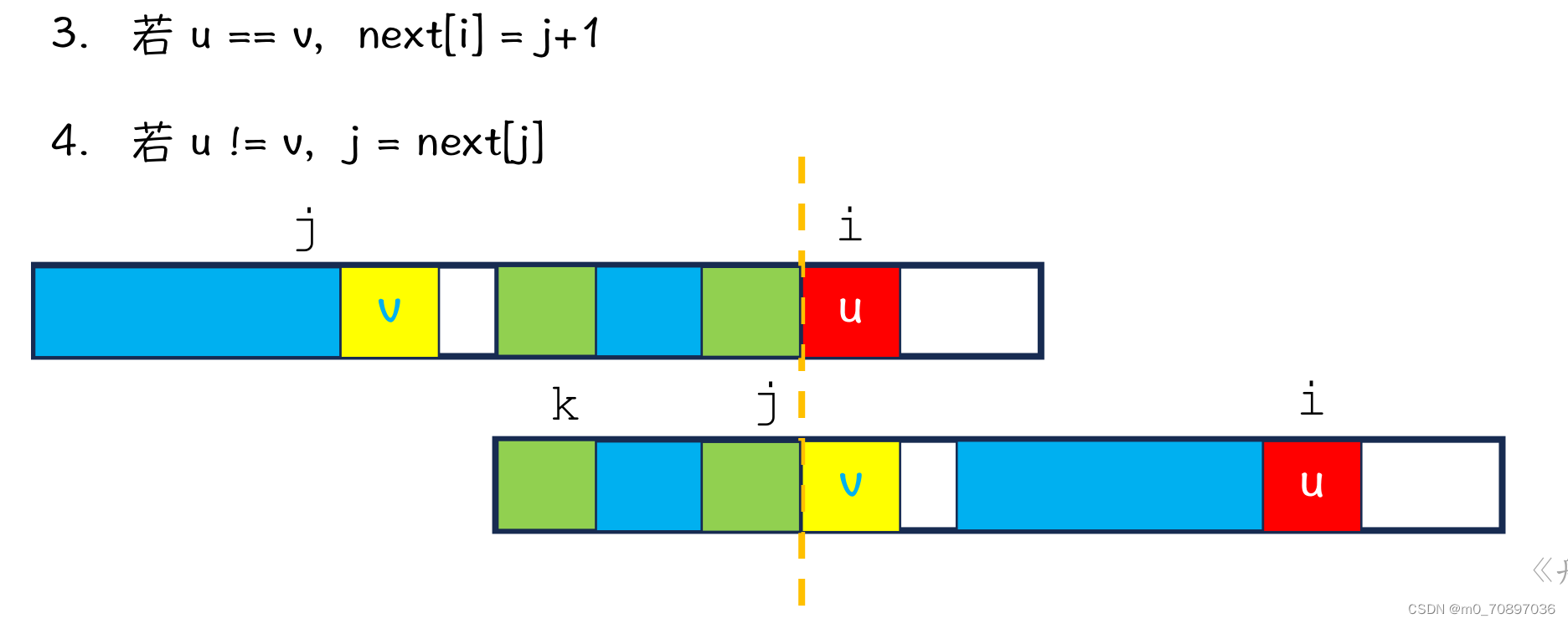
kmp算法理解的核心:与前面三种算法不同的是,KMP算法移动的是模式串,母串中的位置指针一路向前,没有回退。
代码
int *getNext(const char *t) {int tlen = strlen(t);int *next = (int *)malloc(sizeof(int) * tlen);next[0] = -1;//第一个位置特殊处理 int j = -1;//含义为当前位置前一个位置得next值 for (int i = 1; t[i]; i++) {while (j != -1 && t[i] != t[j + 1]) j = next[j];//失配,找到next[j] if (t[i] == t[j + 1]) j += 1;//成功匹配,j+1 next[i] = j;}return next;
}int KMP(const char *s, const char *t) {int *next = getNext(t);int j = -1, tlen = strlen(t);//j为T中当前匹配到的位置 for (int i = 0; s[i]; i++) {while (j != -1 && s[i] != t[j + 1]) j = next[j];//失配,模式串移动 if (s[i] == t[j + 1]) j += 1;//成功匹配,模式串的位置指针移动 if (t[j + 1] == 0) return i - tlen + 1;//整个T成功匹配,返回T在S上开头的位置 }return -1;
}
完整测试代码
#include <iostream>
#include <cstring>
using namespace std;#define TEST(func, s, t) { \printf("%s(%s, %s) = %d\n", #func, s, t, func(s, t)); \
}int brute_force(const char *s, const char *t) {for (int i = 0; s[i]; i++) {//遍历母串int flag = 1;//标志为1说明完成了匹配for (int j = 0; t[j]; j++) {if (s[i + j] == t[j]) continue;flag = 0;//到达该位置说明出现了失配break;}if (flag == 1) return i;}return -1;
}int sunday(const char *s, const char *t) {int len[256] = {0}, n = strlen(s), m = strlen(t);//len[x]记录当前的黄金对齐点位的元素是x时,i需要移动的距离 for (int i = 0; i < 256; i++) len[i] = m + 1;//默认为m+1,意思是如果当前值没有在T中出现过,那么直接移动m+1,使得T直接从黄金对齐点位的后面开始匹配 for (int i = 0; t[i]; i++) len[t[i]] = m - i;//移动距离为m-i,即T的长度减去所在位置 for (int i = 0; i + m <= n; i += len[s[i + m]]) {int flag = 1;//标志为1说明完成了匹配for (int j = 0; t[j]; j++) {if (s[i + j] == t[j]) continue;flag = 0;//到达该位置说明出现了失配break;}if (flag == 1) return i;}return -1;
}int *getDelta1(const char *t) {int *delta1 = (int *)malloc(sizeof(int) * 256);for (int i = 0; i < 256; i++) delta1[i] = -1;for (int i = 0; t[i]; i++) {delta1[t[i]] = i;}return delta1;
}int *getSuffixes(const char *t) { int tlen = strlen(t);int *suff = (int *)malloc(sizeof(int) * tlen);suff[tlen - 1] = tlen;for (int i = 0; i < tlen - 1; i++) {int j = 0;while (j <= i && t[tlen - j - 1] == t[i - j]) ++j;suff[i] = j;}return suff;
}int *getDelta2(const char *t) {int *suff = getSuffixes(t);// printf("suff : ");// for (int i = 0; t[i]; i++) printf("%d ", suff[i]);// printf("\n");int tlen = strlen(t), lastInd = tlen - 1;int *delta2 = (int *)malloc(sizeof(int) * tlen);for (int i = 0; t[i]; i++) delta2[i] = tlen;for (int i = 0; i < tlen; i++) {if (suff[i] != i + 1) continue;for (int j = 0; j <= lastInd - suff[i]; j++) delta2[j] = lastInd - i;}for (int i = 0; i < lastInd; i++) {delta2[lastInd - suff[i]] = lastInd - i;}return delta2;
}int BM(const char *s, const char *t) {int *delta1 = getDelta1(t);int *delta2 = getDelta2(t);int slen = strlen(s), tlen = strlen(t);for (int j = 0; j + tlen <= slen;) {int i = tlen - 1;while (i >= 0 && t[i] == s[j + i]) --i;if (i == -1) return j;// printf("i=%d, delta1[%c]=%d, delta2[%d]=%d\n", i, s[j + i], delta1[s[j + i]], i, delta2[i]);j += max(i - delta1[s[j + i]], delta2[i]);}return -1;
}int *getNext(const char *t) {int tlen = strlen(t);int *next = (int *)malloc(sizeof(int) * tlen);next[0] = -1;//第一个位置特殊处理 int j = -1;//含义为当前位置前一个位置得next值 for (int i = 1; t[i]; i++) {while (j != -1 && t[i] != t[j + 1]) j = next[j];//失配,找到next[j] if (t[i] == t[j + 1]) j += 1;//成功匹配,j+1 next[i] = j;}return next;
}int KMP(const char *s, const char *t) {int *next = getNext(t);int j = -1, tlen = strlen(t);//j为T中当前匹配到的位置 for (int i = 0; s[i]; i++) {while (j != -1 && s[i] != t[j + 1]) j = next[j];//失配,模式串移动 if (s[i] == t[j + 1]) j += 1;//成功匹配,模式串的位置指针移动 if (t[j + 1] == 0) return i - tlen + 1;//整个T成功匹配,返回T在S上开头的位置 }return -1;
}int main() {char s[100], t[100];while (~scanf("%s%s", s, t)) { TEST(brute_force, s, t);TEST(sunday, s, t);TEST(BM, s, t);TEST(KMP, s, t);}return 0;
}
多模匹配
Rabin-Karp
基本思想
两种常见的字符串哈希:
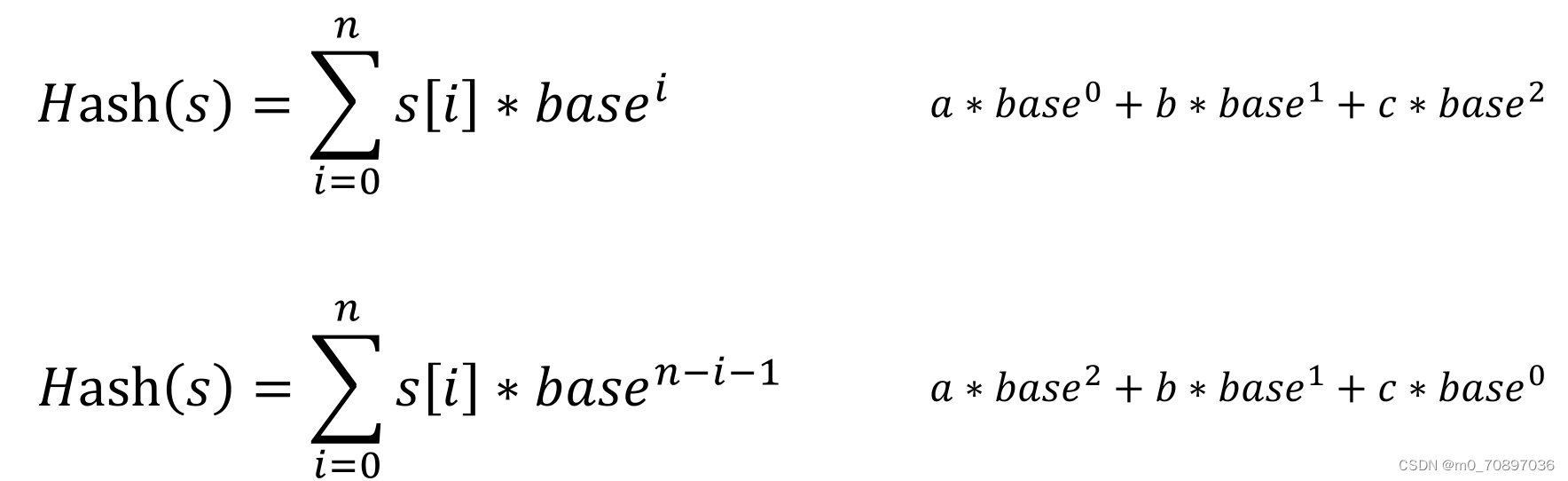
Rabin_Karp是基于哈希的字符串匹配算法,主要基于上面的第二种。
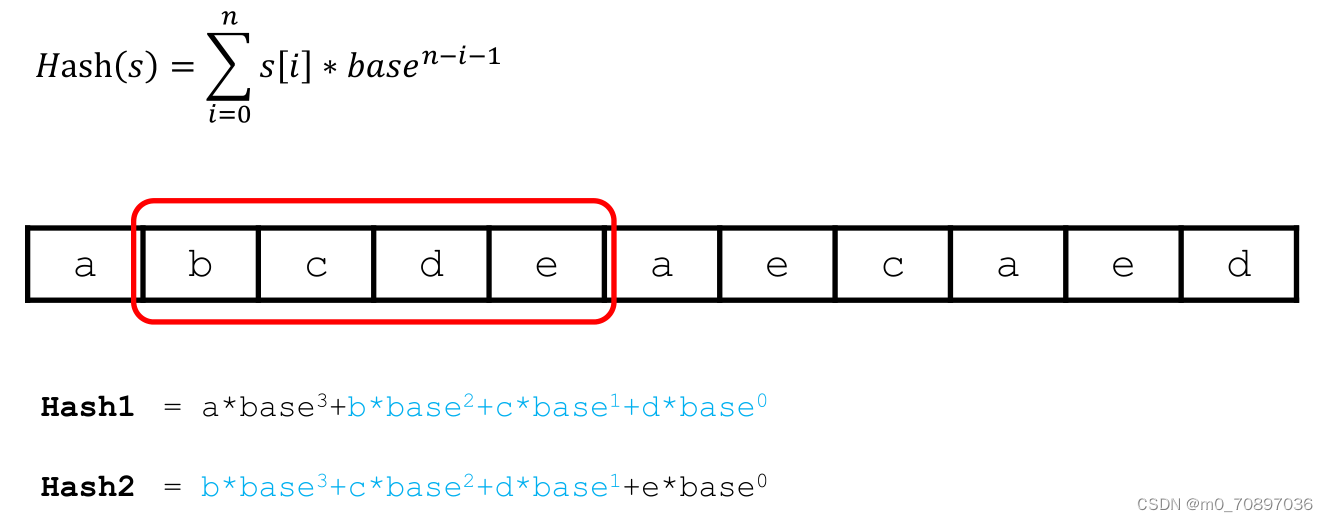
如何在已知hash1的基础上表示出hash2?
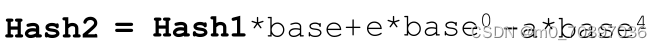
如果两个字符串具有相同的哈希值要怎么办?
一旦匹配到和模式串具有相同哈希值的字符串,需要单独进行一次逐个位置的匹配。
代码
单模匹配
#include <iostream>
using namespace std;#define TEST(func, s, t) { \printf("%s(%s, %s) = %d\n", #func, s, t, func(s, t)); \
}#define MOD 9973
#define BASE 131int hash_func(const char *s) {//求取当前模式串的哈希值 int h = 0, slen = strlen(s);for (int i = slen - 1, kbase = 1; i >= 0; i--) {//从后往前,越往前权重越大 h = (h + s[i] * kbase) % MOD;//新找到了一位,哈希值更新 kbase = kbase * BASE % MOD;//更新权重 }return h;
}int RabinKarp(const char *s, const char *t) {int thash = hash_func(t);//模式串的哈希值 int nbase = 1, tlen;for (tlen = 0; t[tlen]; tlen++) nbase = nbase * BASE % MOD;//为了方便由hashi求出hashj过程中减去开头项,引入值nbase for (int i = 0, h = 0; s[i]; i++) {h = h * BASE + s[i];//更新base if (i >= tlen) h = (h - s[i - tlen] * nbase % MOD + MOD) % MOD;//位数足够之后才减去前面的 if (i + 1 < tlen) continue;//位数不够,不执行下面的比较 if (h != thash) continue; //哈希值不匹配,继续下一次 if (strncmp(s + i - tlen + 1, t, tlen) == 0) {//哈希值匹配,进行一次逐个位置的检查 return i - tlen + 1;//返回当前匹配串的开始位置 }}return -1;
}int main() {char s[100], t[100];while (~scanf("%s%s", s, t)) { TEST(RabinKarp, s, t);}return 0;
}
多模匹配
#include <iostream>
#include <string>
using namespace std;#define MOD 9973
#define BASE 131int hash_func(string &s) {//求模式串的哈希值 int h = 0;for (int i = s.size() - 1, kbase = 1; i >= 0; i--) {h = (h + s[i] * kbase) % MOD;kbase = kbase * BASE % MOD;}return h;
}void RabinKarp(string &s, vector<string> &t) {unordered_map<int, vector<int>> thash;//存放着哈希值与模式串下标的对应关系 for (int i = 0; i < t.size(); i++) thash[hash_func(t[i])].push_back(i);//遍历每一个模式串,求出对应哈希值,并存储对应关系 int nbase = 1, tlen;for (tlen = 0; t[0][tlen]; tlen++) nbase = nbase * BASE % MOD;for (int i = 0, h = 0; s[i]; i++) {h = h * BASE + s[i];if (i >= tlen) h = (h - s[i - tlen] * nbase % MOD + MOD) % MOD;if (i + 1 < tlen) continue;if (thash.find(h) == thash.end()) continue;//如果当前匹配到串的哈希值没有记录,继续向后查找 for (int j = 0; j < thash[h].size(); j++) {//如果查找到了,那么就遍历具有当前哈希值的每一个模式串 if (strncmp(s.c_str() + i - tlen + 1, t[thash[h][j]].c_str(), tlen) == 0) {//对于每一个模式串判断时候能够进行匹配 printf("pos %d : %s\n", i - tlen + 1, t[thash[h][j]].c_str());}}}return ;
}int main() {int n;string s;vector<string> t(100);//存放若干个等待匹配的模式串 cin >> n;for (int i = 0; i < n; i++) cin >>t[i];while (cin >> s) {RabinKarp(s, t);}return 0;
}
Shift-and
基本思想
将模式串中出现的每一个字符的出现位置进行编码,如下图所示,1表示在此位置出现。
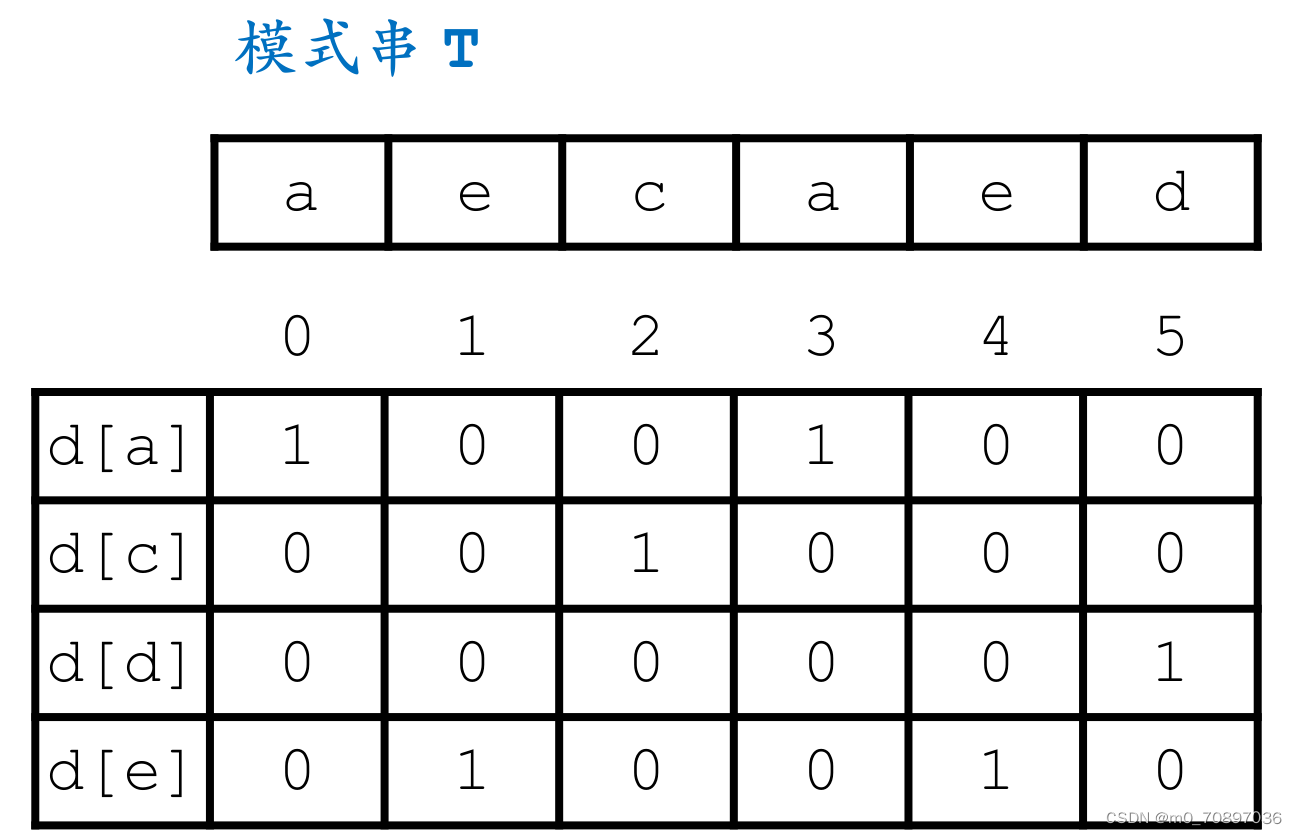
接下来初始化一个p=0,每次我们执行如下操作。
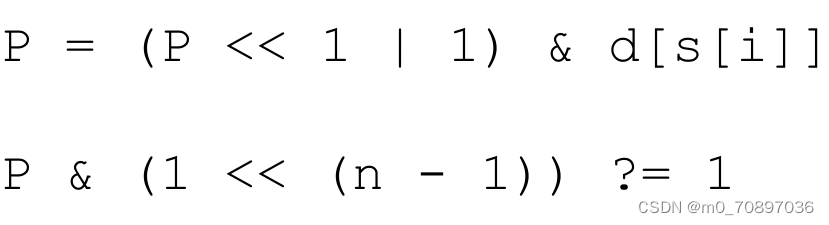
如何理解?我们每次让p左移一位,当前p最左边的位置表示当前能够有机会匹配到的最大长度(从最左边1到最右边的距离,例如我当前是0100,说明上一次我匹配到了两位,接下来我要匹配第三位)。
只有上一次能够成功匹配,我们上一次的1才能左移,意味着我要匹配下一位;如果我们上一次我们没有成功匹配,那么上一次我们得到的结果将会是0,因为我们有一个|1的操作,意味着我可以得到001,此时我将匹配第一位。
匹配完一次之后,我们需要判断当前最左边的1是否已经移动了整个字符串的长度。
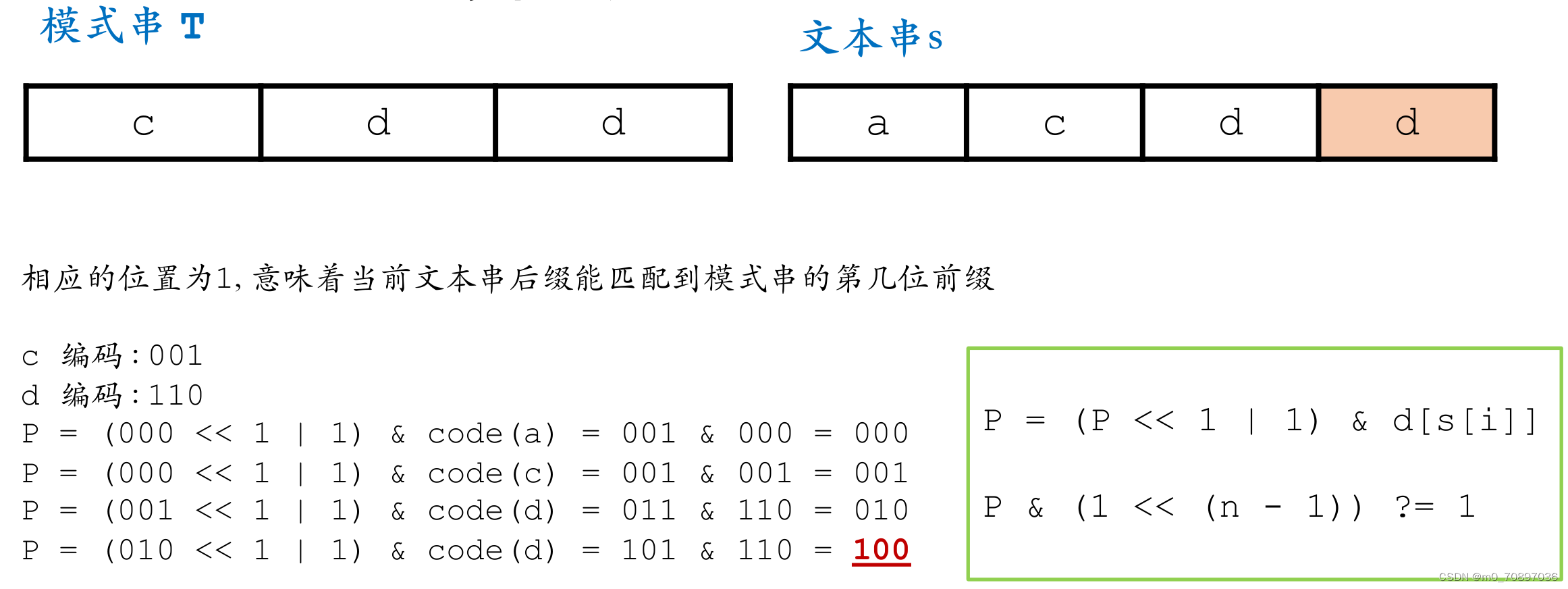
Shift-and使用的特殊情景:

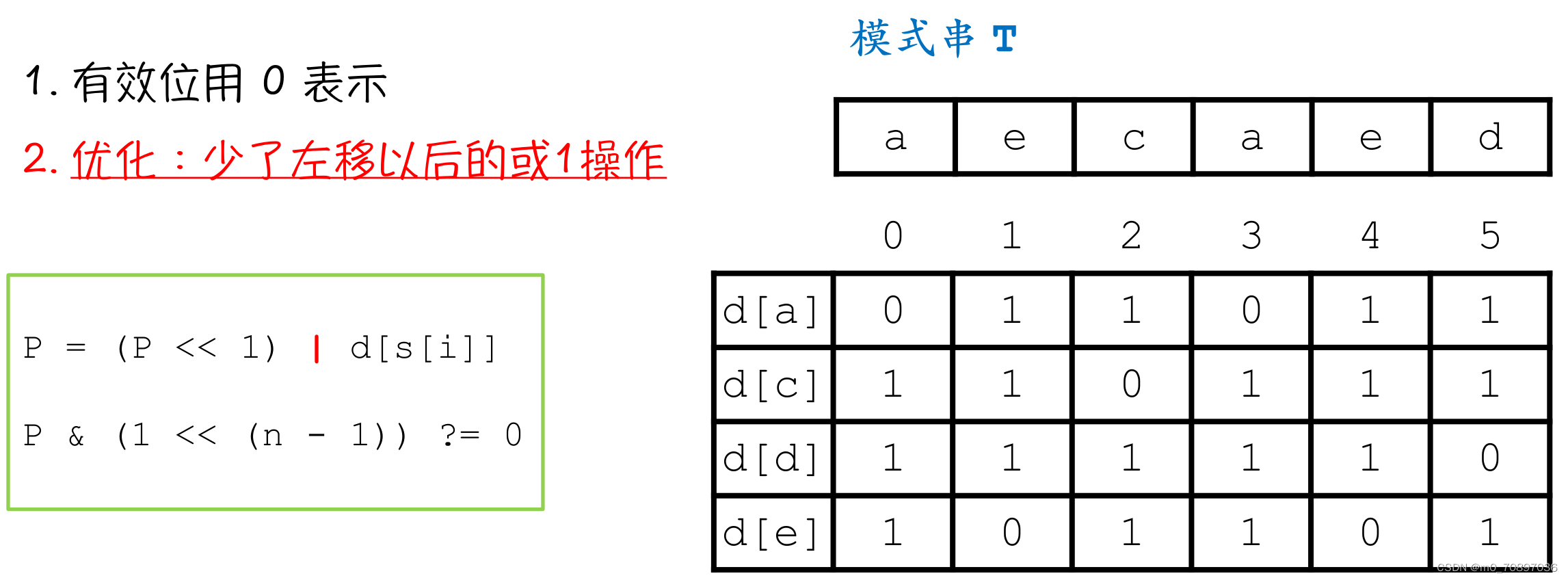
此时可以给以上模式串进行以下编码:
a:101
b:101
c:110
d:010
代码
#include <iostream>
using namespace std;#define TEST(func, s, t) { \printf("%s(%s, %s) = %d\n", #func, s, t, func(s, t)); \
}int shift_and(const char *s, const char *t) {int code[256] = {0}, n = 0;//code表示每一个字符在此规则下的编码 for (n = 0; t[n]; n++) code[t[n]] |= (1 << n);//此时的|相当于+ int p = 0;for (int i = 0; s[i]; i++) {p = (p << 1 | 1) & code[s[i]];if (p & (1 << (n - 1))) return i - n + 1;}return -1;
}int main() {char s[100], t[100];while (~scanf("%s%s", s, t)) {TEST(shift_and, s, t);}return 0;
}
Shift-or
和Shift-and相比,Shift-or只有编码方式的变化。在Shift-or中,有效位用0表示,此时可以少掉左移以后的或1操作。
字典树
1.Trie字典树
基本思想
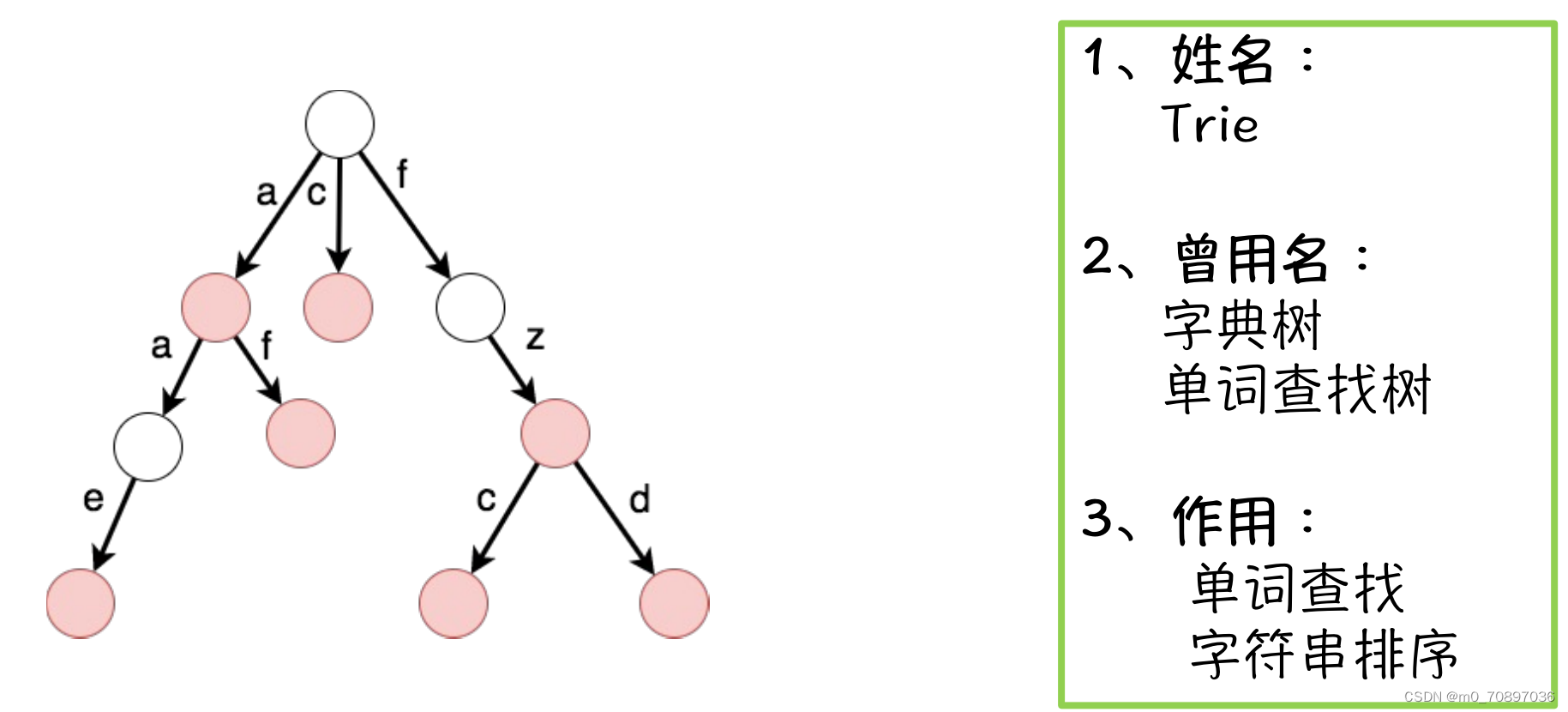
图中的节点有红色和白色之分,红色表示从根节点到当前位置记录了一个单词。
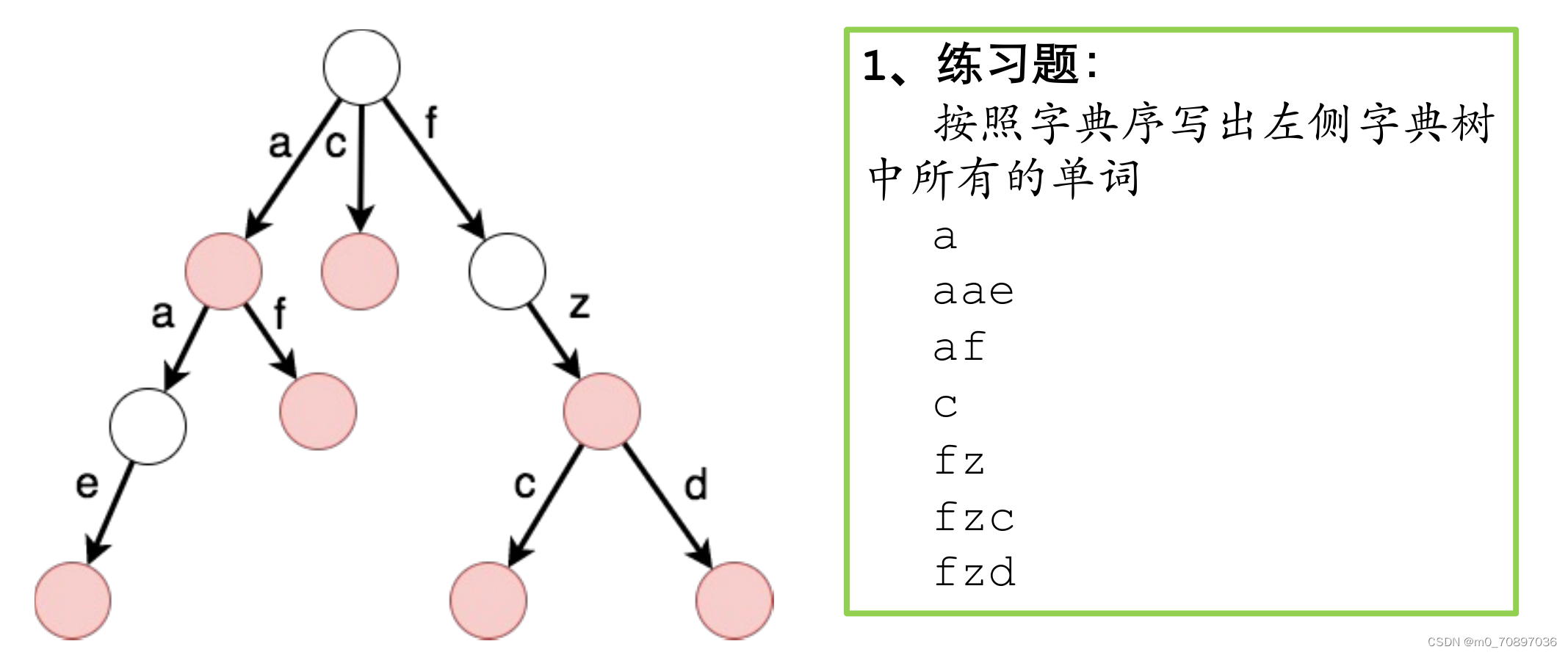
树的 节点 代表 集合
树的 边 代表 关系
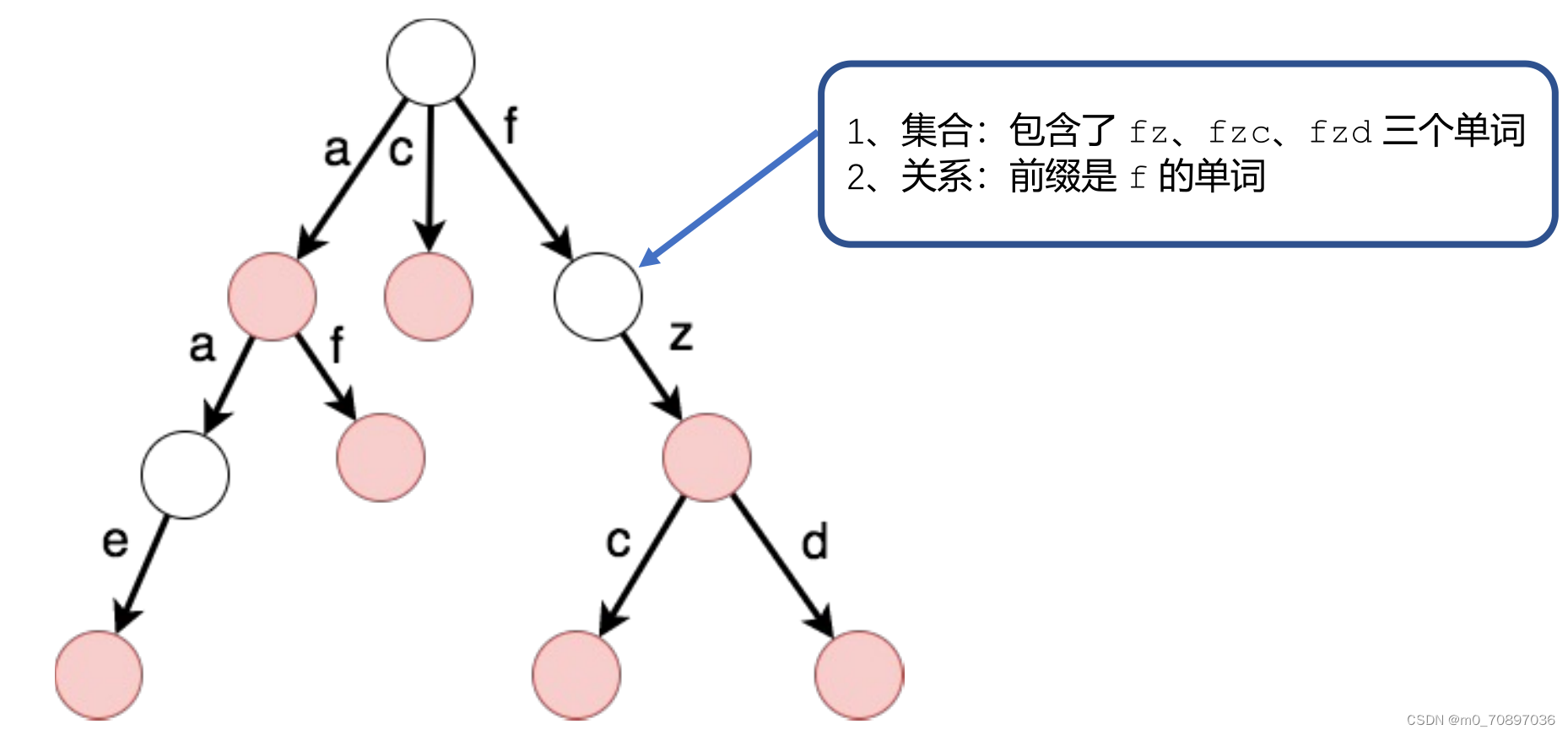
为什么要如此设计?
以树形结构的形式进行存储大大减小了查询的开销,例如我们要查一个单词hello,我们只需要按照以下流程查找:查找h,如果未查到则直接判断不存在此单词,反之查找e,如果未查到则直接判断不存在此单词,反之查找l,以此类推。也就是说,我们只是相当于对这个单词遍历了一边,时间复杂度相当低。
代码
#include <iostream>
using namespace std;#define BASE 26typedef struct Node {//每个节点存放26个子节点,以及一个flag值表示走到当前节点的位置能否表示一个单词 struct Node *next[BASE];int flag;
} Node;Node *getNewNode() {//创建一个节点 Node *p = (Node *)malloc(sizeof(Node));for (int i = 0; i < BASE; i++) p->next[i] = NULL;p->flag = 0;return p;
}void insert(Node *root, const char *s) {//插入一个单词 Node *p = root;//当前检查到的位置 for (int i = 0; s[i]; i++) {int ind = s[i] - 'a';//当前字符的下标 if (p->next[ind] == NULL) p->next[ind] = getNewNode();//如果当前位置为空,表示这棵树上不存在当前位置的字符,此时需要创建 p = p->next[ind];//让p走到下一个位置 }p->flag = 1;//表示走到当前位置是一个单词 return ;
}int find(Node *root, const char *s) {//查找单词 Node *p = root;//表示当前检查到的位置 for (int i = 0; s[i]; i++) {int ind = s[i] - 'a';//当前字符表示的下标 p = p->next[ind];//p走到下一个位置 if (p == NULL) return 0;//p为空表示匹配到一半时断掉了,也即不存在此单词 }return p->flag;//即使每一个字符都成功匹配,我们也需要判断最走到后一个节点的路径是否表示了一个完整的单词
}void clear(Node *root) {//递归的方式进行空间释放 if (root == NULL) return ;for (int i = 0; i < BASE; i++) clear(root->next[i]);free(root);return ;
}void output(Node *root, int k, char *buff) {//按照字典序输出每一个单词 buff[k] = 0;//用于下面输出的遍历,一但输出到当前位置可以立即停止 if (root->flag) {//找到了单词 printf("find : %s\n", buff);}for (int i = 0; i < BASE; i++) {//每一个子节点 if (root->next[i] == NULL) continue;buff[k] = i + 'a';//根据下标求出对应的字符 output(root->next[i], k + 1, buff);//深搜的方式向下继续查找 }return ;
}int main() {int op;char s[100];Node *root = getNewNode();do {cin >> op;if (op == 3) break;cin >> s;switch (op) {case 1: {printf("insert %s to trie\n", s);insert(root, s);} break;case 2: {printf("find %s from trie : %d\n",s, find(root, s));} break;}} while (1);output(root, 0, s);clear(root);return 0;
}
2.双数组字典树
为什么要有双数组字典树?和Trie字典树相比,双数组字典树可以大大节省存储空间。
基本思想
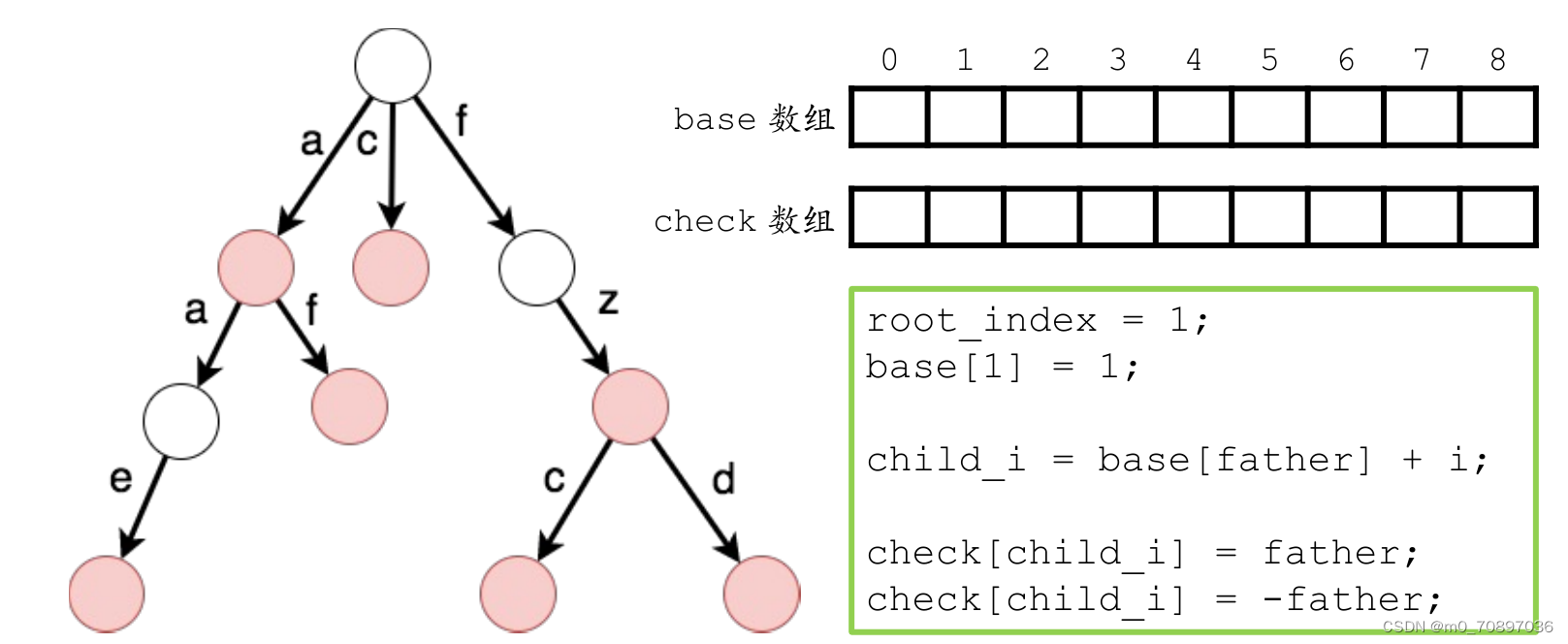
双数组字典树使用了两个数组base和check去维护了每一个节点的子节点以及flag值两个关系。
一个节点的子节点序号为base+i,其中i为此子节点的字符所对应的编号。例如a对应0,这里维护了子节点的关系。但是有一个问题,例如两个点的base值分别为8,9,这样的话第一个点走‘c’的孩子和第二个点走‘b’的孩子编号相同,显然有问题,因此引入了check数组。
check数组的绝对值为当前点父节点的编号,同时其正负表示了到达当前点能否形成一个单词,负数表示可以,正数表示不可以。
本程序的重点问题在于base值的确定。
双数组字典树有一个缺陷——不支持单词的随机插入。再在程中,双数组字典树一般和Trie字典树结合使用,先将所有的信息插入到Trie字典树中,之后再将Trie字典树转化为双数组字典树,我们可以再双数组字典树中将base和check数组导出,此时我们便可以只拿着这两个数组去做字符串的匹配工作。即离线构造,在线查询。
代码
#include <iostream>
using namespace std;
#define MAXSIZE 100000
#define BASE 26
typedef struct DANode{//双数组字典树节点定义 int base,check;
}DANode;
DANode trie[MAXSIZE+5];
typedef struct Node {//每个节点存放26个子节点,以及一个flag值表示走到当前节点的位置能否表示一个单词 struct Node *next[BASE];int flag;
} Node;
int da_trie_root=1;//根节点的编号
Node *getNewNode() {//创建一个节点 Node *p = (Node *)malloc(sizeof(Node));for (int i = 0; i < BASE; i++) p->next[i] = NULL;p->flag = 0;return p;
}void insert(Node *root, const char *s) {//插入一个单词 Node *p = root;//当前检查到的位置 for (int i = 0; s[i]; i++) {int ind = s[i] - 'a';//当前字符的下标 if (p->next[ind] == NULL) p->next[ind] = getNewNode();//如果当前位置为空,表示这棵树上不存在当前位置的字符,此时需要创建 p = p->next[ind];//让p走到下一个位置 }p->flag = 1;//表示走到当前位置是一个单词 return ;
}int find(DANode *trie, const char *s) {//查找单词int p=da_trie_root; //p为当前节点父节点的编号 for (int i = 0; s[i]; i++) { int ind=trie[p].base+s[i]-'a';//当前节点的编号 if(abs(trie[ind].check)!=p)return 0;//如果当前节点的父节点不是p,说明找不到 p=ind;//更新p }return trie[p].check<0;//即使每一个字符都成功匹配,我们也需要判断最走到后一个节点的路径是否表示了一个完整的单词
}void clear(Node *root) {//递归的方式进行空间释放 if (root == NULL) return ;for (int i = 0; i < BASE; i++) clear(root->next[i]);free(root);return ;
}
int getbase(Node*root,int ind,DANode*trie)//获取当前节点的base值
{int base=2;//从2开始 int flag;do{flag=1;for(int i=0;i<BASE;i++){if(!root->next[i])continue;if(!trie[base+i].check)continue;//如果当前子节点的check值已存在,说明不能取这个位置 base++;//更新base flag=0;break;}if(flag)break;}while(1);return base;
}
void convert_to_double_array_trie(Node*root,int ind,DANode*trie)//将trie转化为datrie
{trie[ind].base=getbase(root,ind,trie);//获取当前节点的base值 for(int i=0;i<BASE;i++)//对于每一个子节点设置check {if(!root->next[i])continue;trie[trie[ind].base+i].check=(root->next[i]->flag?-ind:ind); //设置每一个子节点的check值 }for(int i=0;i<BASE;i++)//递归对每一个子节点进行转换 {if(!root->next[i])continue;convert_to_double_array_trie(root->next[i],trie[ind].base+i,trie);}return ;
}
int main() {int n;cin>>n;char s[100];Node *root = getNewNode();for(int i=0;i<n;i++){cin>>s;insert(root,s);}convert_to_double_array_trie(root,da_trie_root,trie);while (scanf("%s", s) != EOF) {printf("find %s from double array trie : %d\n", s, find(trie, s));}clear(root);return 0;
}
3.可持久化字典树
为什么要引入可持久化字典树?或者说可持久化字典树为我们解决了什么特定的问题?

普通的字典树只支持在当前插入的所有单词中查找是否存在单词x,二可持久化字典树支持在已插入的第i到第j个单词里面查找是否存在x。
基本思想
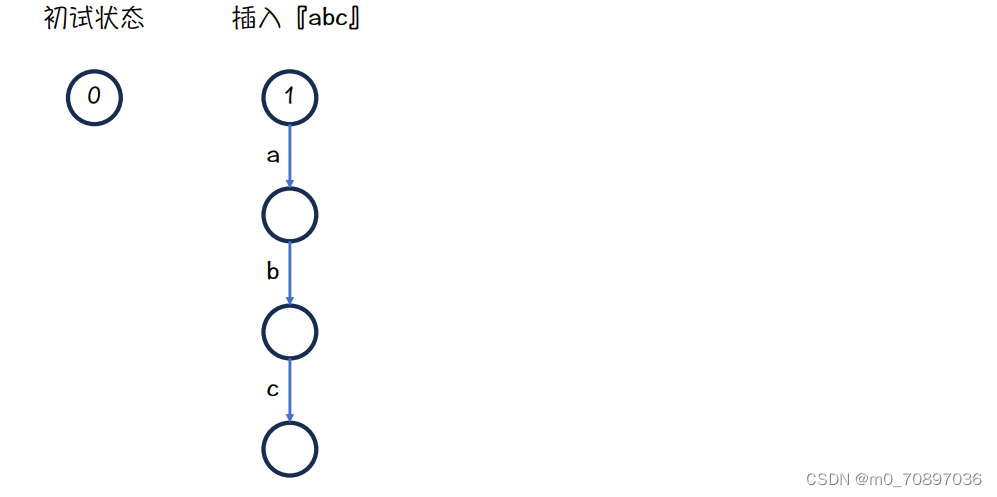
每插入一个新的单词都创建一个新的根节点,故在可持久化字典树里不只有一个根节点。每次创建的新根不仅包含本次插入的单词,同时也继承了之前所有能够表示的单词。
初始状态是一个0节点,我们插入新的单词abc
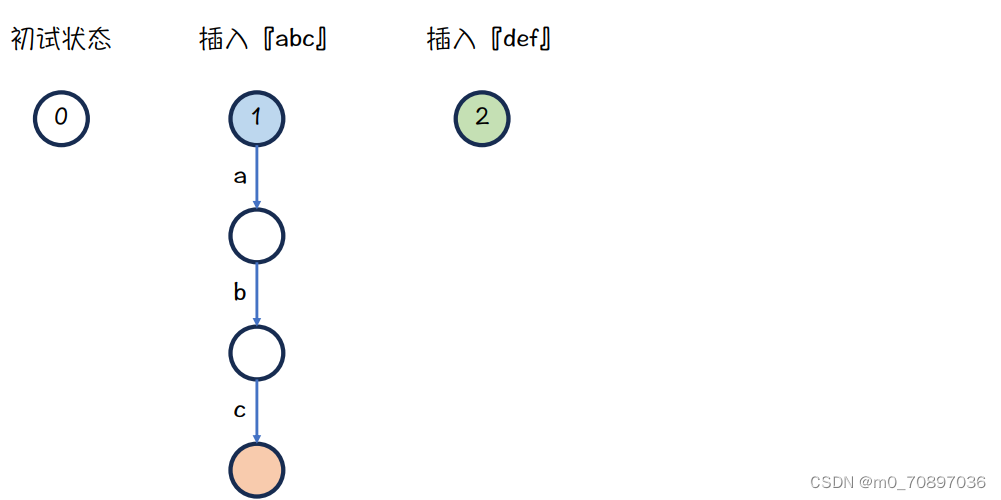
接下来插入def,我们有两个指针,分别指向abc和def的根
把字母d插入
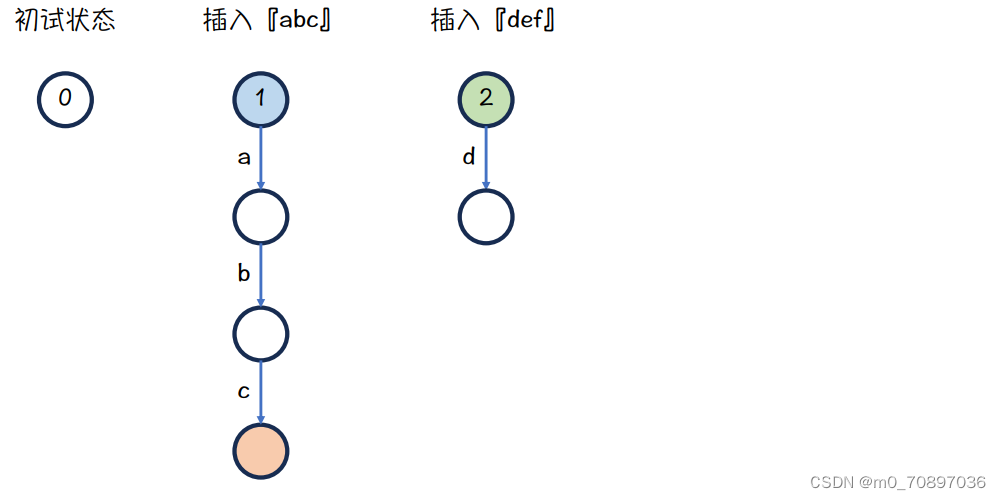
蓝色节点下面是a,而绿色节点下面没有a,故需要继承,从绿色节点引一条边
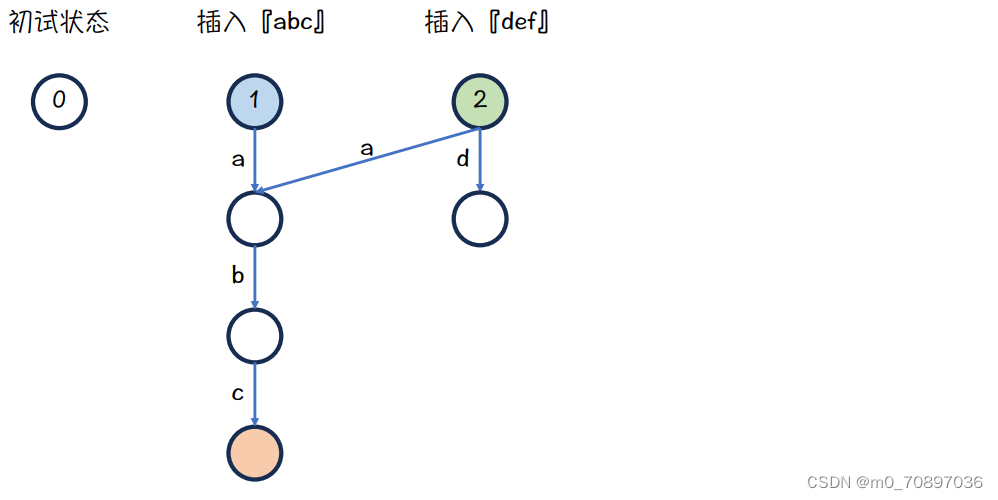
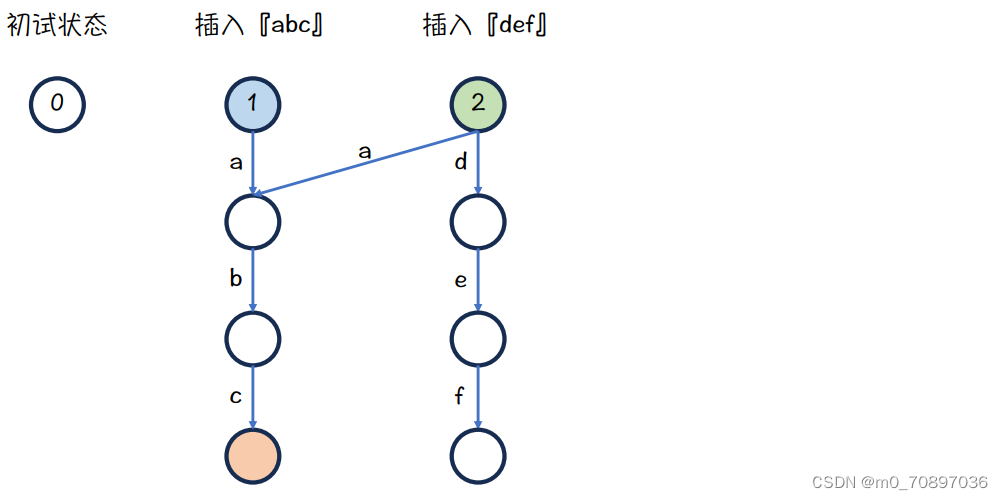
最终结果,因为蓝色节点下面没有d,所以def可以一直向下插入
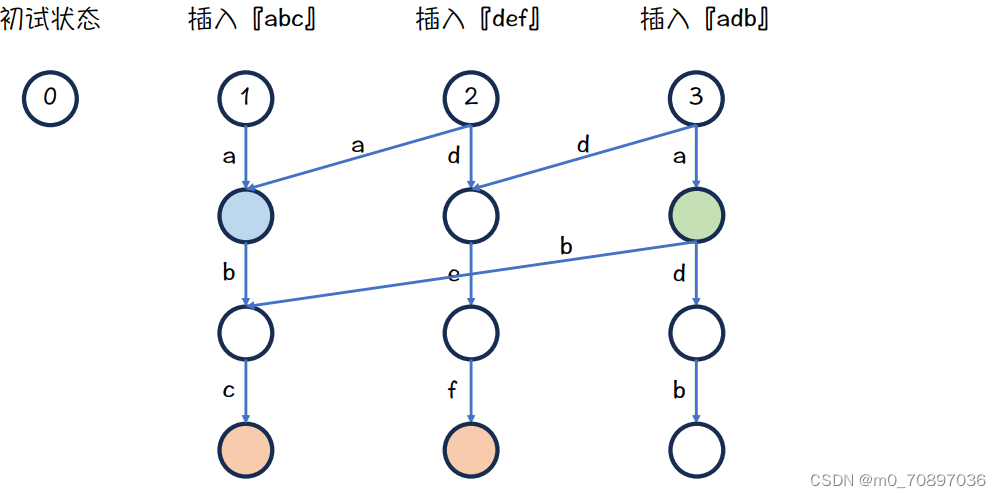
插入abd的最终结果
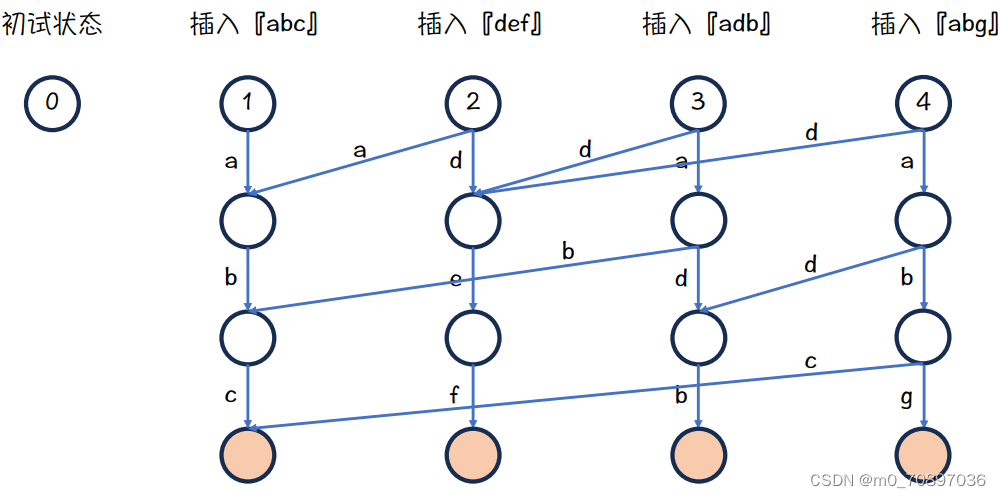
插入abg的最终结果
代码
#include<iostream>
using namespace std;
#define MAX_N 10000
#define BASE 26
int rt[MAX_N+5]={0};//记录每一个根节点的序号
int ch[MAX_N*30][BASE]={0};//记录每一个节点的序号
int val[MAX_N*30]={0};//到达每一个点包含的单词数量
int cnt=0;//记录编号,递增
void insert(int o,int lst,const char*s)//在o为根节点的树插入s,并继承以lst为根的树
{for(int i=0;s[i];i++)//遍历字符串每一位 {int ind=s[i]-'a';ch[o][ind]=++cnt;//节点编号赋值 for(int j=0;j<BASE;j++)//对于当前节点每一条边 {if(ch[o][j])continue;//只会出现一次,即在上方赋值过 ch[o][j]=ch[lst][j];//未出现则赋值为lst节点以j为边的下一个节点的序号 }o=ch[o][ind];//更新o为o以ind为边的下一个节点 lst=ch[lst][ind];val[o]+=val[lst];//将lst为节点的val值拷贝给o节点 }val[o]+=1;return ;
}
int find_once(int a,const char*s)//在a中查s出现的数量
{int p=rt[a];//p记录当前编号 for(int i=0;s[i];i++){p=ch[p][s[i]-'a'];}return val[p];
}
int query(int a,int b,const char*s)//作差,查询a,b区间是否出现s
{int x1=find_once(b,s);int x2=find_once(a-1,s);return x1-x2;
}
int main()
{int n;cin>>n;char s[100];for(int i=1;i<=n;i++){cin>>s;rt[i]=++cnt;//根节点编号赋值 insert(rt[i],rt[i-1],s); }int a,b;while (~scanf("%d%d%s", &a, &b, s)) {printf("from %d to %d, find %s : %d\n",a, b, s, query(a, b, s));}return 0;
}
AC自动机
基本思想
AC自动机是结合了KMP算法的思想,以字典树为基础实现的。
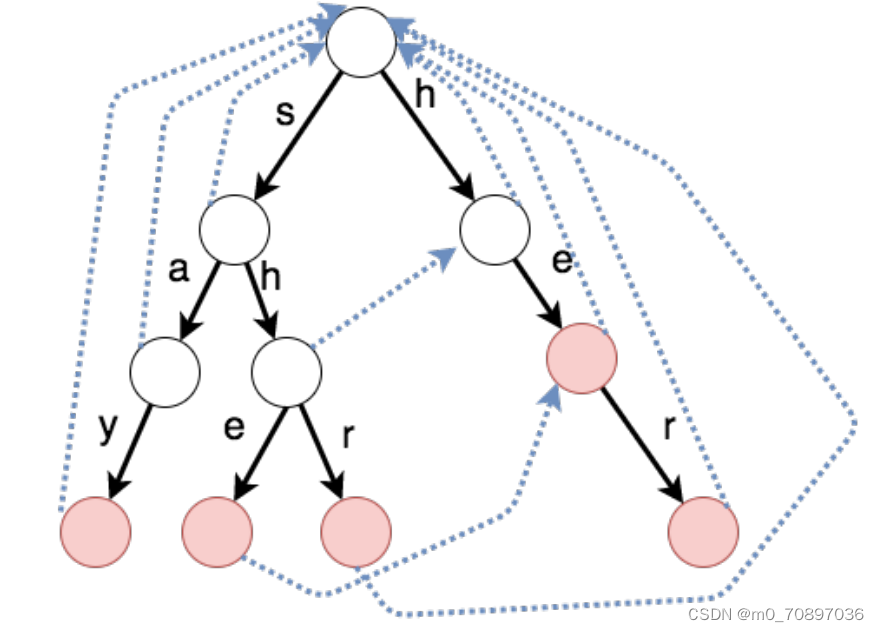
在KMP中,对于模式串每个位置都记录了最大匹配长度,这样可以在失配的时候,直接据此对模式串进行一个大距离的移动,而不需要逐一匹配。在若干个单词构成的字典树里,如果我们想知道在一个模式串中这些单词出现的有哪些,我们同样可以在失配的时候直接转向当前位置对应的下一位置,而不需要从头重新进行匹配。
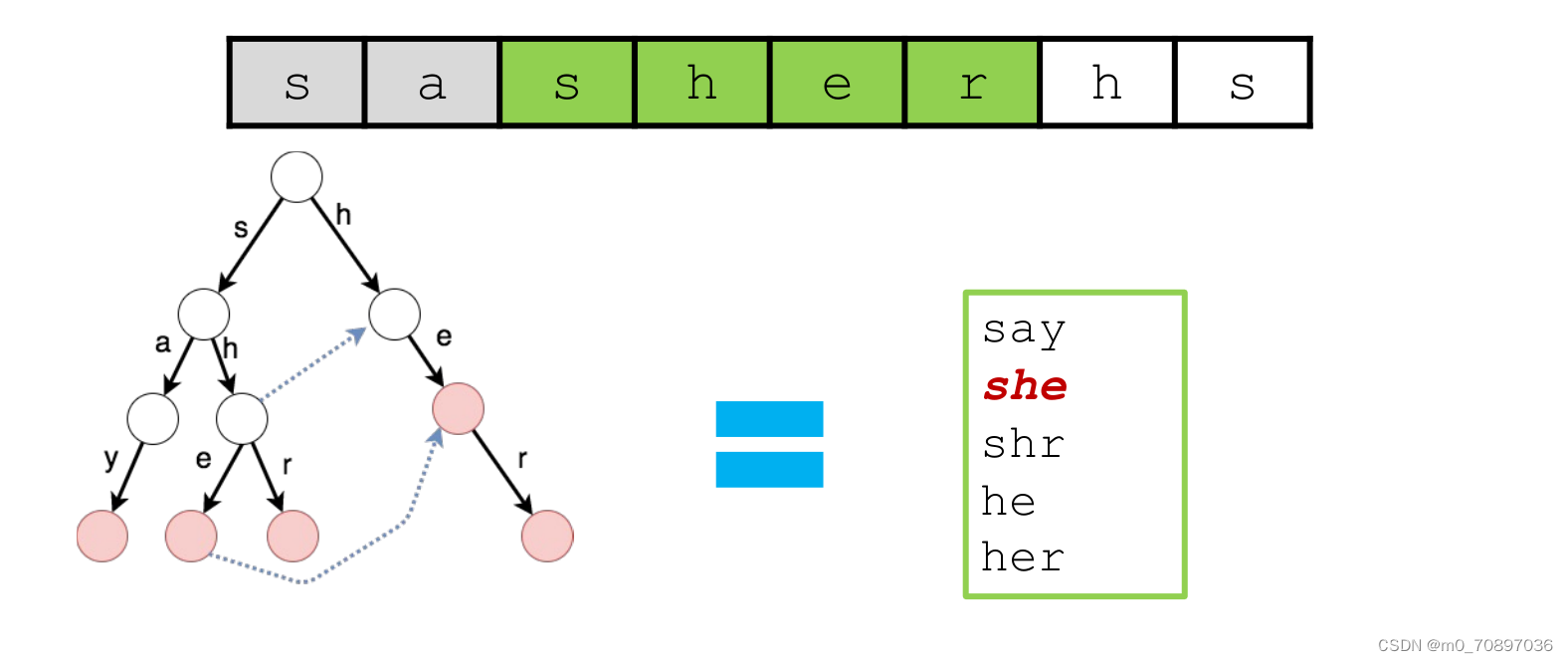
每一个节点都有一个fail指针,指向在此位置失配后要转向的位置。
代码
/*************************************************************************> File Name: 11.ac.cpp> Author: hug> Mail: hug@haizeix.com> Created Time: 浜? 3/26 21:10:59 2024************************************************************************/#include <iostream>
#include <queue>
using namespace std;#define BASE 26typedef struct Node {int flag;struct Node *next[26];struct Node *fail;//失败指针 const char *s;//记录当前点所表示的单词,便于直接输出
} Node;Node *getNewNode() {//初始化一个节点 Node *p = (Node *)malloc(sizeof(Node));p->flag = 0;p->fail = NULL;p->s = NULL;for (int i = 0; i < BASE; i++) p->next[i] = NULL;return p;
}void insert(Node *root, const char *s) {//插入一个单词 Node *p = root;//p指向当前位置 for (int i = 0; s[i]; i++) {//遍历单词的每一位 int ind = s[i] - 'a';//当前单词对应的下标 if (p->next[ind] == NULL) p->next[ind] = getNewNode();//如果当前字符不存在字典树中,创建一个新的节点 p = p->next[ind];//p往后走一个,走到当前位置 }p->s = strdup(s);//当前位置是一个单词的末尾,把s赋值给p->s p->flag = 1;return ;
}void build_ac(Node *root) {//建立ac自动机,以层序遍历的方式 queue<Node *> q;for (int i = 0; i < BASE; i++) {//对于根节点 if (root->next[i] == NULL) continue;root->next[i]->fail = root;//对于根节点的下面一层节点,失败指针可以直接连接到根节点 q.push(root->next[i]);//进入队列 }while (!q.empty()) {//不断从队列取出Node Node *cur = q.front(), *p;q.pop();for (int i = 0; i < BASE; i++) {//对于每一个cur,确定他每一个孩子节点的fail if (cur->next[i] == NULL) continue;p = cur->fail;//p指向cur的fail while (p && p->next[i] == NULL) p = p->fail;//如果p后面不能接i+'a',则继续向上寻找p,一直到NULL为止 if (p == NULL) p = root;else p = p->next[i];cur->next[i]->fail = p;q.push(cur->next[i]);}}return ;
}void find_ac(Node *root, const char *s) {//寻找ac自动机中在s中出现的所有单词 Node *p = root, *q;//p指向当前节点 for (int i = 0; s[i]; i++) {int ind = s[i] - 'a';while (p && p->next[ind] == NULL) p = p->fail;//如果当前节点下无法找到该字符,则不断向上走 if (p == NULL) p = root;else p = p->next[ind];q = p;while (q) {//为什么要while?如果s中包含world,ac自动机中又包含world,rld,ld,那么while才可以保证输出每一个存在的单词 if (q->flag) {int len = strlen(q->s);printf("find [%d, %d] = %s\n", i - len + 1, i, q->s);}q = q->fail;}}return ;
}void clear(Node *root) { if (root == NULL) return ;for (int i = 0; i < BASE; i++) {if (root->next[i] == NULL) continue;clear(root->next[i]);}free(root);return ;
}int main() {int n;char s[100];Node *root = getNewNode();scanf("%d", &n);for (int i = 0; i < n; i++) {scanf("%s", s);insert(root, s);}build_ac(root);scanf("%s", s);find_ac(root, s);return 0;
}
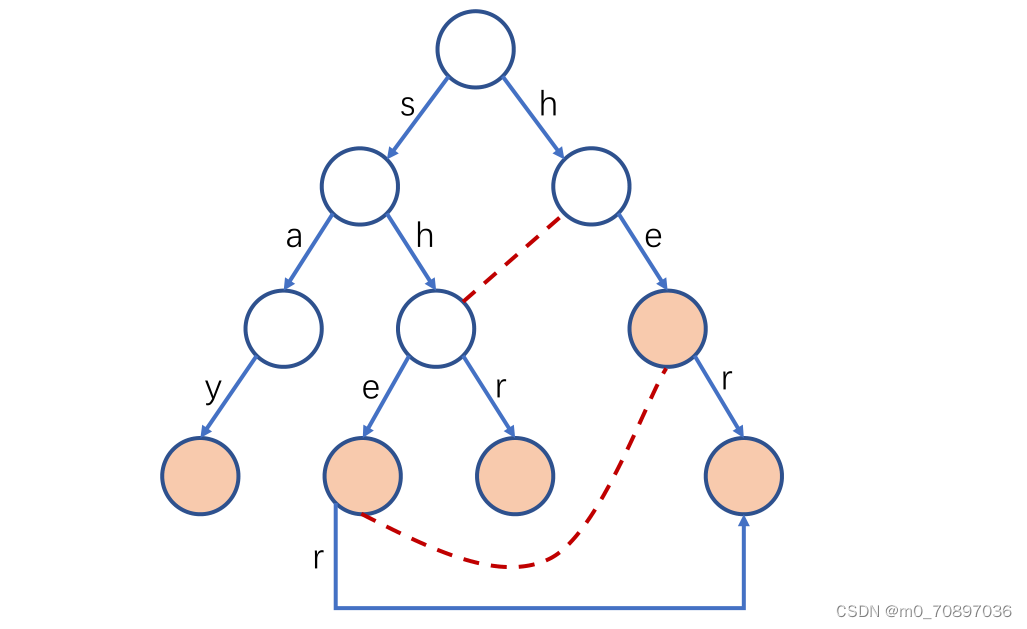
线索化优化
借鉴线索二叉树的思想,这里要充分利用空指针。如果一个节点cur的next[i]为NULL,那么让他指向cur->fail->next[i]。
代码
/*************************************************************************> File Name: 11.ac.cpp> Author: hug> Mail: hug@haizeix.com> Created Time: 浜? 3/26 21:10:59 2024************************************************************************/#include <iostream>
#include <queue>
using namespace std;#define BASE 26typedef struct Node {int flag;struct Node *next[26];struct Node *fail;const char *s;
} Node;vector<Node *> node_vec;Node *getNewNode() {Node *p = (Node *)malloc(sizeof(Node));p->flag = 0;p->fail = NULL;p->s = NULL;for (int i = 0; i < BASE; i++) p->next[i] = NULL;node_vec.push_back(p);return p;
}void insert(Node *root, const char *s) {Node *p = root;for (int i = 0; s[i]; i++) {int ind = s[i] - 'a';if (p->next[ind] == NULL) p->next[ind] = getNewNode();p = p->next[ind];}p->s = strdup(s);p->flag = 1;return ;
}void build_ac(Node *root) {queue<Node *> q;q.push(root);while (!q.empty()) {Node *cur = q.front(), *p;q.pop();for (int i = 0; i < BASE; i++) {if (cur->next[i] == NULL) {if (cur == root) cur->next[i] = root;else cur->next[i] = cur->fail->next[i];continue;}p = cur->fail;if (p == NULL) p = root;else p = p->next[i];cur->next[i]->fail = p;q.push(cur->next[i]);}}return ;
}void find_ac(Node *root, const char *s) {Node *p = root, *q;for (int i = 0; s[i]; i++) {int ind = s[i] - 'a';p = p->next[ind];q = p;while (q) {if (q->flag) {int len = strlen(q->s);printf("find [%d, %d] = %s\n", i - len + 1, i, q->s);}q = q->fail;}}return ;
}void clear() {for (int i = 0; i < node_vec.size(); i++) {free(node_vec[i]);}return ;
}int main() {int n;char s[100];Node *root = getNewNode();scanf("%d", &n);for (int i = 0; i < n; i++) {scanf("%s", s);insert(root, s);}build_ac(root);scanf("%s", s);find_ac(root, s);clear();return 0;
}
练习题
AC自动机模板题
8/100
发布文章
m0_70897036
未选择文件
AC 自动机(简单版)
题目描述
给定 n n n 个模式串 s i s_i si 和一个文本串 t t t,求有多少个不同的模式串在文本串里出现过。
两个模式串不同当且仅当他们编号不同。
输入格式
第一行是一个整数,表示模式串的个数 n n n。
第 2 2 2 到第 ( n + 1 ) (n + 1) (n+1) 行,每行一个字符串,第 ( i + 1 ) (i + 1) (i+1) 行的字符串表示编号为 i i i 的模式串 s i s_i si。
最后一行是一个字符串,表示文本串 t t t。
输出格式
输出一行一个整数表示答案。
样例 #1
样例输入 #1
3
a
aa
aa
aaa
样例输出 #1
3
样例 #2
样例输入 #2
4
a
ab
ac
abc
abcd
样例输出 #2
3
样例 #3
样例输入 #3
2
a
aa
aa
样例输出 #3
2
提示
样例 1 解释
s 2 s_2 s2 与 s 3 s_3 s3 编号(下标)不同,因此各自对答案产生了一次贡献。
样例 2 解释
s 1 s_1 s1, s 2 s_2 s2, s 4 s_4 s4 都在串 abcd 里出现过。
数据规模与约定
- 对于 50 % 50\% 50% 的数据,保证 n = 1 n = 1 n=1。
- 对于 100 % 100\% 100% 的数据,保证 1 ≤ n ≤ 1 0 6 1 \leq n \leq 10^6 1≤n≤106, 1 ≤ ∣ t ∣ ≤ 1 0 6 1 \leq |t| \leq 10^6 1≤∣t∣≤106, 1 ≤ ∑ i = 1 n ∣ s i ∣ ≤ 1 0 6 1 \leq \sum\limits_{i = 1}^n |s_i| \leq 10^6 1≤i=1∑n∣si∣≤106。 s i , t s_i, t si,t 中仅包含小写字母。
代码实现
#include<iostream>
using namespace std;
#define MAXSIZE 1000000
int node[MAXSIZE+5][26];
int fail[MAXSIZE+5]={0};
int val[MAXSIZE+5]={0};
int que[MAXSIZE+5]={0};
char s[MAXSIZE+5];
int cnt=1,root=1;
int getNewNode()
{return ++cnt;
}
void insert(const char*s)
{int p=root;for(int i=0;s[i];i++){int ind=s[i]-'a';if(!node[p][ind])node[p][ind]=getNewNode();p=node[p][ind];}val[p]+=1;return ;
}
void build_ac()
{int head=0,tail=0,p;que[tail++]=root;while(head<tail){int cur=que[head++];for(int i=0;i<26;i++){if(!node[cur][i]){if(!fail[cur])node[cur][i]=root;else node[cur][i]=node[fail[cur]][i];continue;}p=fail[cur];if(p==0)p=root;else p=node[p][i];fail[node[cur][i]]=p;que[tail++]=node[cur][i];} }return ;
}
int find_all(const char*s)
{int p=root,q,ans=0;for(int i=0;s[i];i++){int ind=s[i]-'a';p=node[p][ind];q=p;while(q&&val[q]!=-1){ans+=val[q];val[q]=-1;q=fail[q];}}return ans;
}
int main()
{int n;cin>>n;for(int i=0;i<n;i++){scanf("%s\n",s);insert(s);}build_ac();scanf("%s",s);cout<<find_all(s);return 0;}
AC 自动机(简单版 II)
题目描述
有 N N N 个由小写字母组成的模式串以及一个文本串 T T T。每个模式串可能会在文本串中出现多次。你需要找出哪些模式串在文本串 T T T 中出现的次数最多。
输入格式
输入含多组数据。保证输入数据不超过 50 50 50 组。
每组数据的第一行为一个正整数 N N N,表示共有 N N N 个模式串, 1 ≤ N ≤ 150 1 \leq N \leq 150 1≤N≤150。
接下去 N N N 行,每行一个长度小于等于 70 70 70 的模式串。下一行是一个长度小于等于 1 0 6 10^6 106 的文本串 T T T。保证不存在两个相同的模式串。
输入结束标志为 N = 0 N=0 N=0。
输出格式
对于每组数据,第一行输出模式串最多出现的次数,接下去若干行每行输出一个出现次数最多的模式串,按输入顺序排列。
样例 #1
样例输入 #1
2
aba
bab
ababababac
6
beta
alpha
haha
delta
dede
tata
dedeltalphahahahototatalpha
0
样例输出 #1
4
aba
2
alpha
haha
代码实现
#include<iostream>
#include<queue>
#include<cstring>
using namespace std;
typedef struct Node{int id;Node*fail;Node*next[26];
}Node;
int node_cnt=0;
char s[1000005],t[200][75];
int tcnt[200];
Node*getNewNode()
{Node*p=(Node*)malloc(sizeof(Node));p->id=-1;p->fail=NULL;for(int i=0;i<26;i++)p->next[i]=NULL;return p;
}
void insert(Node*root,const char*s,int k)
{Node*p=root;for(int i=0;s[i];i++){int ind=s[i]-'a';if(!p->next[ind])p->next[ind]=getNewNode();p=p->next[ind];}p->id=k;strcpy(t[k],s);return ;
}
void build_ac(Node*root)
{queue<Node*>q;q.push(root);while(!q.empty()){Node*cur=q.front();q.pop();for(int i=0;i<26;i++){if(!cur->next[i]){if(!cur->fail)cur->next[i]=root;else cur->next[i]=cur->fail->next[i];continue;} Node*p=cur->fail;if(!p)p=root;else p=p->next[i];cur->next[i]->fail=p;q.push(cur->next[i]);}}return ;
}
void find_ac(Node*root,const char*s)
{Node*p=root,*q;for(int i=0;s[i];i++){int ind=s[i]-'a';p=p->next[ind];q=p;while(q){if(q->id!=-1)tcnt[q->id]++;q=q->fail;}}return ;
}
void Init()
{node_cnt=0;memset(t,0,sizeof(t));memset(tcnt,0,sizeof(tcnt));return ;
}
void solve(int n)
{Init();Node*root=getNewNode();for(int i=0;i<n;i++){scanf("%s",s);insert(root,s,i);}build_ac(root);scanf("%s",s);find_ac(root,s);int ans=0;for(int i=0;i<n;i++){if(ans<tcnt[i])ans=tcnt[i];}printf("%d\n",ans);for(int i=0;i<n;i++){if(ans==tcnt[i])printf("%s\n",t[i]);}return ;
}
int main()
{int n;while(~scanf("%d",&n)!=EOF){if(n==0)break;solve(n);}return 0;}
循环的字符串
题目描述
给出一个字符串,从字符串起始位遍历到最后一位,若起始位至当前位能被一个前缀串循环 n 次组成,则输出当前位的位置和 n。(n≥2)
输入
第一行输入一个数 L 表示字符串长度。
第二行输入字符串。
输出
每当能达成题目要求时输出一行两个数,表示当前位置和 n。
样例输入
12
aabaabaabaab
样例输出
2 2
6 2
9 3
12 4
解题思路
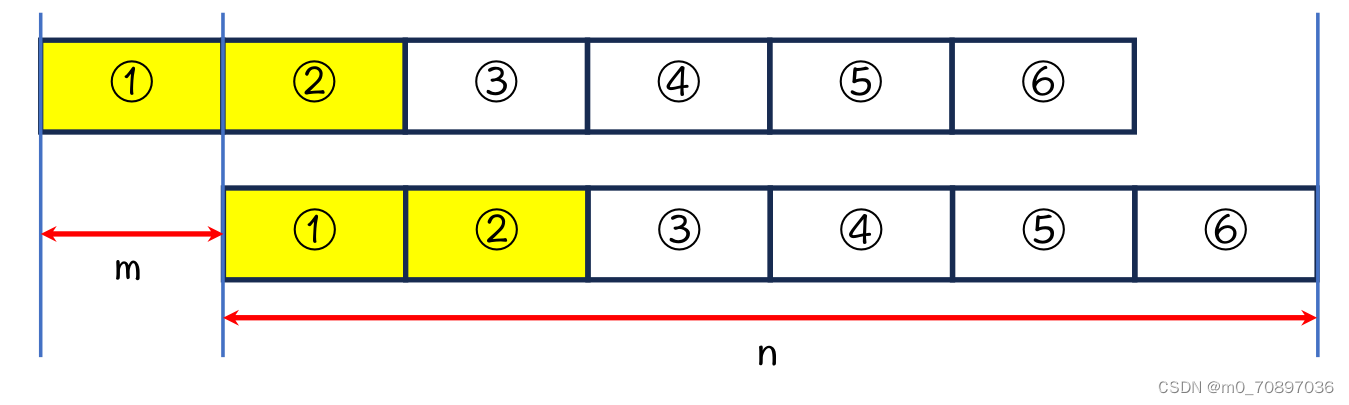
下面需要证明一个结论,当字符串的2-6于1-5部分重合时,如果字符串长度n是1部分的长度m的整数倍时,1部分是字符串的循环节。
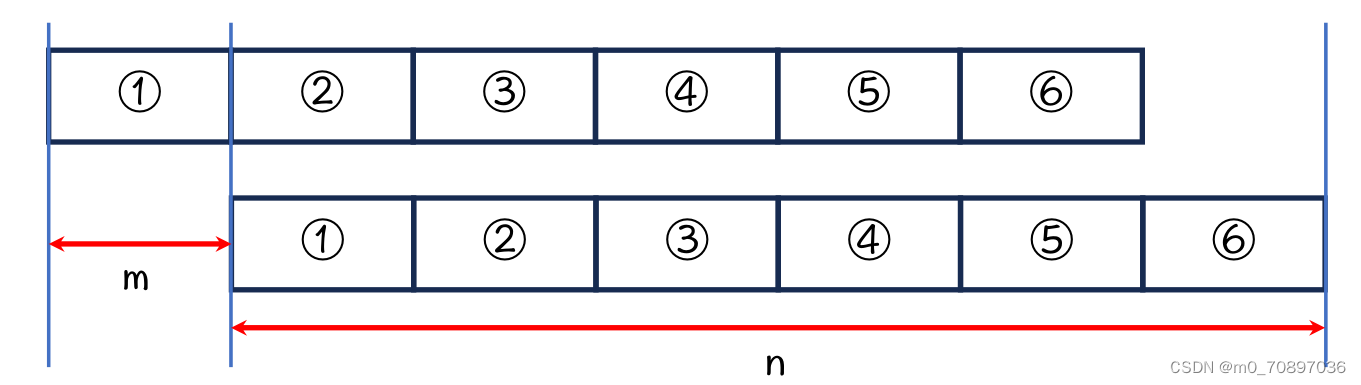
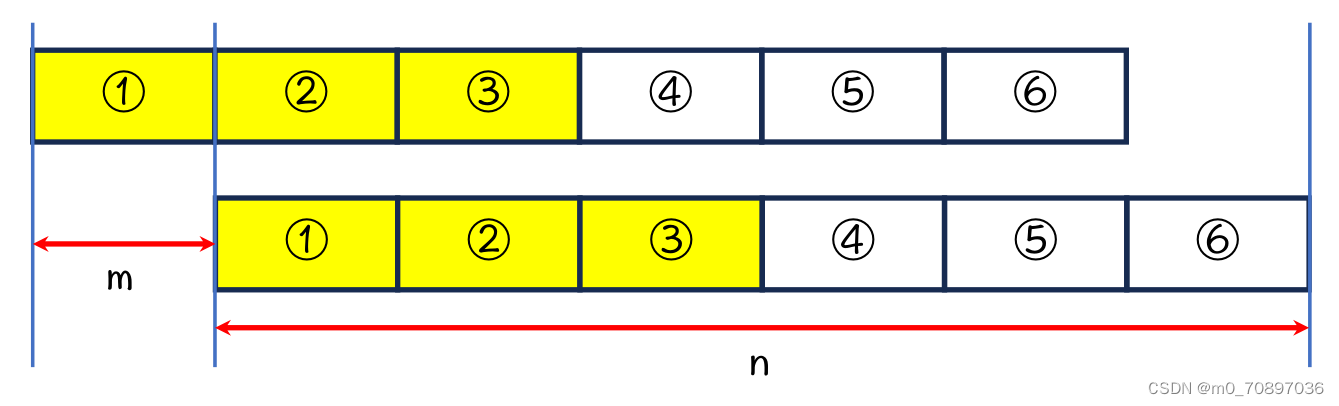
因为上下是同一个字符串,所以上1=下1,上2=下2,又上2=下1,所以黄色四部分相等。
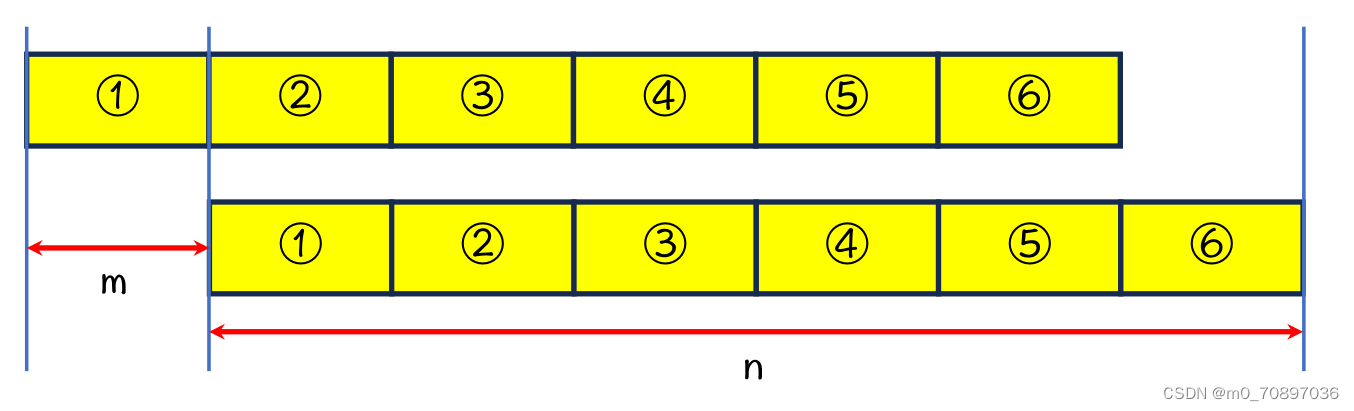
因为上3=下3,上3=下2,所以黄色六个部分相等。
同理,如果n为m的整数倍,则每一个m长度的部分均相等。
代码实现
#include<iostream>
using namespace std;
#define MAX_N 1000000
int nxt[MAX_N+5];
char s[MAX_N+5];
void get_nxt()//参考KMPnext数组的求解
{int j=-1;nxt[0]=-1;for(int i=1;s[i];i++){while(j!=-1&&s[j+1]!=s[i])j=nxt[j];if(s[j+1]==s[i])j+=1; nxt[i]=j;}return ;
}
int main()
{int n;cin>>n;cin>>s;get_nxt();for(int i=1;i<n;i++)//从字符串第二位开始{int n=i+1,m=n-nxt[i]-1;//n表示当前字符串的长度:下标+1,n的值为字符串长度减去重叠部分长度,即nxt[i]+1if(n%m==0&&n/m>=2)//如果n是m整数倍,同时存在相交的部分{printf("%d %d\n",n,n/m);}}return 0;}
项链的主人
题目描述
有一天,小明同学捡到了一条价值连城宝石项链,他想知道项链的主人是谁。在得知此事后,很多人向小明发来了很多邮件,都说项链是自己的,要求他归还(显然其中最多只有一个人说了真话)。
小明要求每个人都写了一段关于自己项链的描述:
项链上的宝石用数字 0 至 9 来表示。一个对于项链的表示就是从项链的某个宝石开始,逆时针绕一圈,沿途记下经过的宝石,比如如下项链:
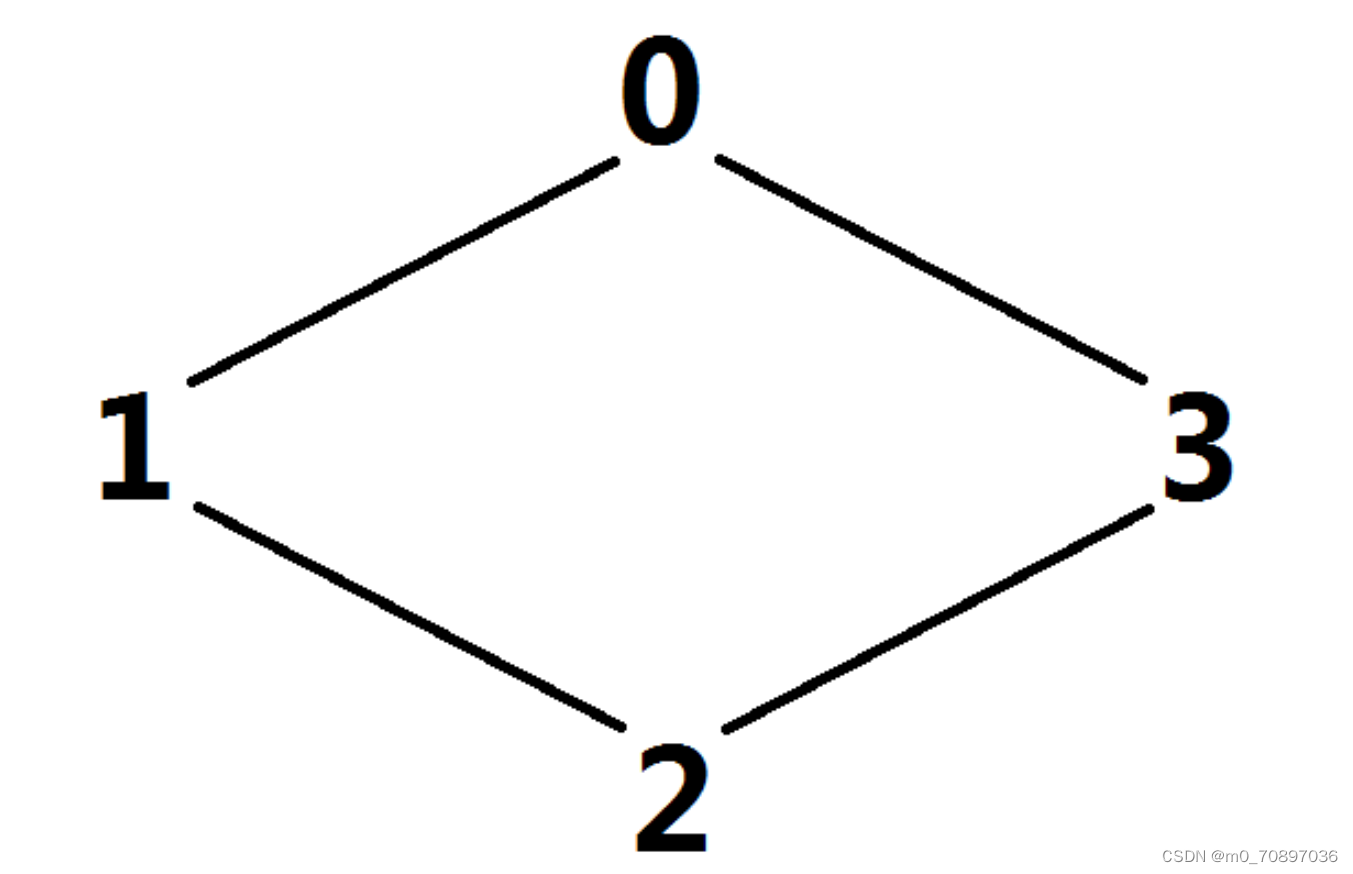
它的可能的四种表示是 0123,1230,2301,3012。
给定两个项链的表示,判断他们是否可能是一条项链。(注意,项链是不会翻转的)。
输入
输入文件只有两行,每行一个由 0 至 9 组成的字符串,描述一个项链的表示(保证项链的长度是相等的)。
输出
如果两条项链不可能同构,那么输出 No,否则的话,第一行输出一个 Yes,第二行输出该项链的字典序最小的表示。L 为项链长度。
样例输入
2234342423
2423223434
样例输出
Yes
2234342423
解题思路
求出两个项链的字典序最小的表示,之后逐个位置比较。
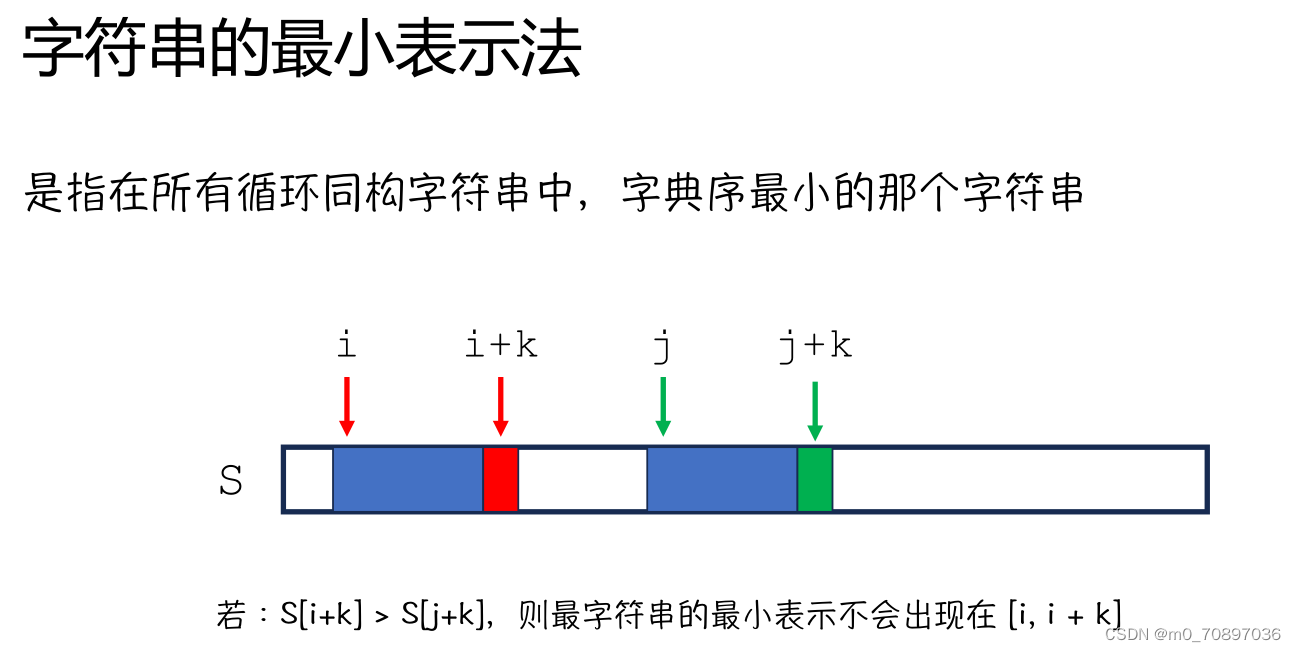
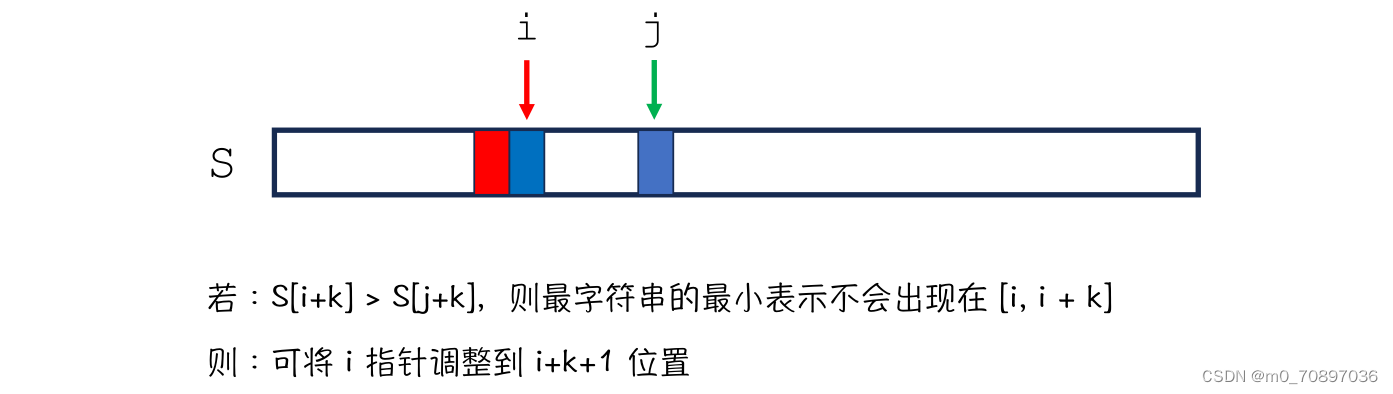
循环这个过程。
代码实现
#include<iostream>
#include<cstring>
using namespace std;
#define MAX_N 1000000
char s[MAX_N+5],t[MAX_N+5];
int string_min(char*s)
{int n=strlen(s);int i=0,j=1,k=0;while(i<n&&j<n&&k<n){if(s[(i+k)%n]==s[(j+k)%n])k+=1;else if(s[(i+k)%n]>s[(j+k)%n]){i=k+i+1;k=0;}else {j=k+j+1;k=0;}if(i==j)i+=1;}return min(i,j);
}
int main()
{scanf("%s",s);scanf("%s",t);int sz=strlen(s);int min_s=string_min(s),min_t=string_min(t);int flag=1;for(int i=min_s,j=min_t,n=0;n<sz;n++){if(s[(i+n)%sz]==t[(j+n)%sz])continue;flag=0;break;}if(flag){cout<<"Yes"<<endl;for(int i=min_s,n=0;n<sz;n++)printf("%c",s[(i+n)%sz]);cout<<endl;}else{cout<<"No"<<endl;}return 0;}
前缀统计
题目描述
给定 N 个字符串 S1,S2…SN,接下来进行 M 次询问,每次询问给定一个字符串 T,求 S1−SN中有多少个字符串是 T 的前缀。输入字符串的总长度不超过 106,仅包含小写字母。
输入
第一行两个整数 N,M。接下来 N 行每行一个字符串 Si。接下来 M 行每行一个字符串表示询问。
输出
对于每个询问,输出一个整数表示答案。
样例输入
3 2
ab
bc
abc
abc
efg
样例输出
2
0
解题思路
套用字典树模板,将前n组数插入到字典树中,之后在字典树中分别查找后m的字符串,如果某个字符串路径上有完整单词存在,则cnt++。
代码实现
#include<iostream>
#include<stdlib.h>
#include<cstring>
using namespace std;
#define MAX_N 1000000
#define BASE 26
typedef struct Node{struct Node*next[BASE];int flag;int val;
}Node;
char s[MAX_N+5],t[MAX_N+5];
Node*getNewNode()
{Node*p=(Node*)malloc(sizeof(Node));for(int i=0;i<BASE;i++)p->next[i]=NULL;p->flag=0;p->val=0;return p;
}
void insert(Node*root,char*s)
{Node*p=root;for(int i=0;s[i];i++){int ind=s[i]-'a';if(!p->next[ind])p->next[ind]=getNewNode();p=p->next[ind];}p->val++;p->flag=1;return ;
}
int query(Node*root,char*s)
{int cnt=0;Node*p=root;for(int i=0;s[i];i++){int ind=s[i]-'a';if(!p->next[ind])break;if(p->next[ind]->flag)cnt+=p->next[ind]->val;p=p->next[ind];}return cnt;
}
int main()
{int n,m;cin>>n>>m;Node*root=getNewNode();while(n--){scanf("%s",s);insert(root,s);}while(m--){scanf("%s",t);printf("%d\n",query(root,t));}return 0;
}
最大异或对
题目描述
在给定的 N 个正整数 A1,A2……AN 中选出两个进行异或运算,得到的结果最大是多少?
输入
第一行一个整数 N,第二行 N 个正整数 A1−AN。
输出
输出一个整数表示答案。
样例输入
3
1 2 3
样例输出
3
解题思路
首先把每一个对应的二进制数存放到字典树中,之后分别在字典树中遍历每一个数,求出其最大的异或值,求解逻辑为尽可能选择和当前位不一样的值,若当前位是0则选择1,如果不存在则只能选择相同的值,最后在所有异或值里面选择最大的。
代码实现
#include<iostream>
#include<stdlib.h>
using namespace std;
#define MAX_N 100000
#define BASE 31
int s[MAX_N+5];
typedef struct Node{struct Node*next[2];int val;
}Node;
Node*getNewNode()
{Node*p=(Node*)malloc(sizeof(Node));p->next[0]=NULL;p->next[1]=NULL;p->val=0;return p;
}
void insert(Node*root,int a)
{Node*p=root;for(int i=BASE;i>=0;i--){if(a/(1<<i)==1){a-=(1<<i); if(!p->next[1])p->next[1]=getNewNode();p=p->next[1]; }else{if(!p->next[0])p->next[0]=getNewNode();p=p->next[0]; } }p->val+=1;return ;
}
int query(Node*root,int a)
{int ans=0;Node*p=root;for(int i=BASE;i>=0;i--){if(a/(1<<i)==1){a-=(1<<i); if(!p->next[0])p=p->next[1];else{p=p->next[0];ans+=(1<<i);} }else{if(!p->next[1])p=p->next[0];else{p=p->next[1];ans+=(1<<i);} } }return ans;
}
int main()
{int n;cin>>n;Node*root=getNewNode();for(int i=0;i<n;i++){scanf("%d",&s[i]);insert(root,s[i]);}int max_val=0;for(int i=0;i<n;i++){max_val=max(max_val,query(root,s[i]));}cout<<max_val;return 0;}
拨号
题目描述
观察如下的电话号码组:
911,91152358
有一部奇怪的电话机,若想拨打 91152358 这个号码,当输入前缀 911 时,由于 911 这个号码的存在,会直接拨通 911 这个号码,导致无法拨通 91152358。现在给定 N 个号码,判断所有号码是否都能拨通。
输入
第一行一个整数 N,接下来 N 行每行一个电话号。
输出
每个号码都能拨通输出 YES,否则输出 NO。
样例输入
5
113
12340
123440
12345
98346
样例输出
YES
解题思路
把每一个号码插入到字典树中,之后分别在字典树中遍历每一个号码,如果在此号码的路径上存在一个完整的号码,则输出NO。
代码实现
#include<iostream>
#include<stdlib.h>
using namespace std;
#define MAX_N 10000
#define BASE 10
char s[MAX_N+5][MAX_N+5];
typedef struct Node{Node*next[BASE];int flag;
}Node;
Node*getNewNode()
{Node*p=(Node*)malloc(sizeof(Node));for(int i=0;i<BASE;i++)p->next[i]=NULL;p->flag=0;return p;
}
void insert(Node*root,char*t)
{Node*p=root;for(int i=0;t[i];i++){int ind=t[i]-'0';if(!p->next[ind])p->next[ind]=getNewNode();p=p->next[ind];}p->flag=1;return ;
}
bool query(Node*root,char*t)
{Node*p=root;for(int i=0;t[i];i++){int ind=t[i]-'0';if(p->flag)return 0;p=p->next[ind];}return 1;
}
int main()
{int n;cin>>n;Node*root=getNewNode();for(int i=0;i<n;i++){scanf("%s",s[i]);insert(root,s[i]);}for(int i=0;i<n;i++){if(!query(root,s[i])){cout<<"NO"<<endl;return 0;}}cout<<"YES"<<endl;return 0;
}
【模板】字符串哈希
题目描述
如题,给定 N N N 个字符串(第 i i i 个字符串长度为 M i M_i Mi,字符串内包含数字、大小写字母,大小写敏感),请求出 N N N 个字符串中共有多少个不同的字符串。
友情提醒:如果真的想好好练习哈希的话,请自觉。
输入格式
第一行包含一个整数 N N N,为字符串的个数。
接下来 N N N 行每行包含一个字符串,为所提供的字符串。
输出格式
输出包含一行,包含一个整数,为不同的字符串个数。
样例 #1
样例输入 #1
5
abc
aaaa
abc
abcc
12345
样例输出 #1
4
提示
对于 30 % 30\% 30% 的数据: N ≤ 10 N\leq 10 N≤10, M i ≈ 6 M_i≈6 Mi≈6, M m a x ≤ 15 Mmax\leq 15 Mmax≤15。
对于 70 % 70\% 70% 的数据: N ≤ 1000 N\leq 1000 N≤1000, M i ≈ 100 M_i≈100 Mi≈100, M m a x ≤ 150 Mmax\leq 150 Mmax≤150。
对于 100 % 100\% 100% 的数据: N ≤ 10000 N\leq 10000 N≤10000, M i ≈ 1000 M_i≈1000 Mi≈1000, M m a x ≤ 1500 Mmax\leq 1500 Mmax≤1500。
样例说明:
样例中第一个字符串(abc)和第三个字符串(abc)是一样的,所以所提供字符串的集合为{aaaa,abc,abcc,12345},故共计4个不同的字符串。
Tip:
感兴趣的话,你们可以先看一看以下三题:
BZOJ3097:http://www.lydsy.com/JudgeOnline/problem.php?id=3097
BZOJ3098:http://www.lydsy.com/JudgeOnline/problem.php?id=3098
BZOJ3099:http://www.lydsy.com/JudgeOnline/problem.php?id=3099
如果你仔细研究过了(或者至少仔细看过AC人数的话),我想你一定会明白字符串哈希的正确姿势的_
代码实现
#include<iostream>
#include<unordered_map>
#include<vector>
#include<string>
using namespace std;
long long get_hash(string s)
{long long base=131,num=0;for(int i=0;i<s.size();i++){num=((num*base)%20030524+s[i])%20030524;}return num;
}
char s[1500];
int main()
{int n;cin>>n;int cnt=0;long long hash_code;unordered_map<long long,vector<string>>h;for(int i=0;i<n;i++){scanf("%s",s);hash_code=get_hash(s);if(h.find(hash_code)==h.end()){cnt++;h[hash_code].push_back(s);}else{int flag=1;for(auto j:h[hash_code]){if(s!=j)continue;flag=0;break;}if(flag){cnt++;h[hash_code].push_back(s);}}}cout<<cnt;return 0;
}
[USACO2.3] 最长前缀 Longest Prefix
题目描述
在生物学中,一些生物的结构是用包含其要素的大写字母序列来表示的。生物学家对于把长的序列分解成较短的序列(即元素)很感兴趣。
如果一个集合 P P P 中的元素可以串起来(元素可以重复使用)组成一个序列 s s s ,那么我们认为序列 s s s 可以分解为 P P P 中的元素。元素不一定要全部出现(如下例中 BBC 就没有出现)。举个例子,序列 ABABACABAAB 可以分解为下面集合中的元素:{A,AB,BA,CA,BBC}
序列 s s s 的前面 k k k 个字符称作 s s s 中长度为 k k k 的前缀。设计一个程序,输入一个元素集合以及一个大写字母序列 ,设 s ′ s' s′ 是序列 s s s 的最长前缀,使其可以分解为给出的集合 P P P 中的元素,求 s ′ s' s′ 的长度 k k k。
输入格式
输入数据的开头包括若干个元素组成的集合 O O O,用连续的以空格分开的字符串表示。字母全部是大写,数据可能不止一行。元素集合结束的标志是一个只包含一个 . 的行,集合中的元素没有重复。
接着是大写字母序列 s s s ,长度为,用一行或者多行的字符串来表示,每行不超过 76 76 76 个字符。换行符并不是序列 s s s 的一部分。
输出格式
只有一行,输出一个整数,表示 S 符合条件的前缀的最大长度。
样例 #1
样例输入 #1
A AB BA CA BBC
.
ABABACABAABC
样例输出 #1
11
提示
【数据范围】
对于 100 % 100\% 100% 的数据, 1 ≤ card ( P ) ≤ 200 1\le \text{card}(P) \le 200 1≤card(P)≤200, 1 ≤ ∣ S ∣ ≤ 2 × 1 0 5 1\le |S| \le 2\times 10^5 1≤∣S∣≤2×105, P P P 中的元素长度均不超过 10 10 10。
翻译来自NOCOW
USACO 2.3
解题思路
把集合中的元素加入到字典树中,对字符串进行一次遍历,如果以当前位开头不存在一个完整的单词则跳过该位,否则寻找以当前位开头能匹配到的所有单词,并记录在字符串中对应的最后一位,以便下一次允许从此位置往后寻找,被记录的最大值就是答案。
代码实现
#include<iostream>
#include<string>
using namespace std;
#define BASE 26
#define MAX_N 200000
int dp[MAX_N+5];
typedef struct Node{Node*next[BASE];int val;int dep;
}Node;
Node*getNewNode()
{Node*p=(Node*)malloc(sizeof(Node));for(int i=0;i<BASE;i++)p->next[i]=NULL;p->val=0;p->dep=0;return p;
}
void insert(Node*root,string s)
{Node*p=root;for(int i=0;s[i];i++){int ind=s[i]-'A';if(!p->next[ind])p->next[ind]=getNewNode();p->next[ind]->dep=p->dep+1;p=p->next[ind];}p->val+=1;return ;
}
void mark(Node*root,string s,int pos)
{Node*p=root;for(int i=pos;s[i];i++){int ind=s[i]-'A';if(!p->next[ind])return ;p=p->next[ind];if(p->val)dp[pos+p->dep]=1;}return ;
}
int main()
{string s,t;Node*root=getNewNode();while(cin>>s){if(s==".")break;insert(root,s);}s="";while(cin>>t)s+=t;dp[0]=1;int ans=0;for(int i=0;s[i];i++){if(dp[i]==0)continue;ans=i;mark(root,s,i);}if(dp[s.size()])ans=s.size();cout<<ans;return 0;
}
【模板】字典树
题目描述
给定 n n n 个模式串 s 1 , s 2 , … , s n s_1, s_2, \dots, s_n s1,s2,…,sn 和 q q q 次询问,每次询问给定一个文本串 t i t_i ti,请回答 s 1 ∼ s n s_1 \sim s_n s1∼sn 中有多少个字符串 s j s_j sj 满足 t i t_i ti 是 s j s_j sj 的前缀。
一个字符串 t t t 是 s s s 的前缀当且仅当从 s s s 的末尾删去若干个(可以为 0 个)连续的字符后与 t t t 相同。
输入的字符串大小敏感。例如,字符串 Fusu 和字符串 fusu 不同。
输入格式
本题单测试点内有多组测试数据。
输入的第一行是一个整数,表示数据组数 T T T。
对于每组数据,格式如下:
第一行是两个整数,分别表示模式串的个数 n n n 和询问的个数 q q q。
接下来 n n n 行,每行一个字符串,表示一个模式串。
接下来 q q q 行,每行一个字符串,表示一次询问。
输出格式
按照输入的顺序依次输出各测试数据的答案。
对于每次询问,输出一行一个整数表示答案。
样例 #1
样例输入 #1
3
3 3
fusufusu
fusu
anguei
fusu
anguei
kkksc
5 2
fusu
Fusu
AFakeFusu
afakefusu
fusuisnotfake
Fusu
fusu
1 1
998244353
9
样例输出 #1
2
1
0
1
2
1
提示
数据规模与约定
对于全部的测试点,保证 1 ≤ T , n , q ≤ 1 0 5 1 \leq T, n, q\leq 10^5 1≤T,n,q≤105,且输入字符串的总长度不超过 3 × 1 0 6 3 \times 10^6 3×106。输入的字符串只含大小写字母和数字,且不含空串。
说明
std 的 IO 使用的是关闭同步后的 cin/cout,本题不卡常。
解题思路
在插入的时候每路过一个节点就让该节点的cnt++,表示以从根节点到此节点为前缀的字符串的数量+1,之后询问的字符串的最后一个节点的cnt值就是以此字符串为前缀的字符串数量。
代码实现
#include<iostream>
using namespace std;
#define MAX_N 100000
#define MAX_LEN 3000000
#define BASE 62
char s[MAX_LEN+5];
typedef struct Node{Node*next[BASE];int flag;int val; int cnt;
}Node;
Node*getNewNode()
{Node*p=(Node*)malloc(sizeof(Node));for(int i=0;i<BASE;i++)p->next[i]=NULL;p->val=0;p->cnt=0;p->flag=0;return p;
}
void insert(Node*root,char*s)
{Node*p=root;for(int i=0;s[i];i++){p->cnt+=1;int ind;if(s[i]>='a')ind=s[i]-'a'+36;else if(s[i]>='A')ind=s[i]-'A'+10;else ind=s[i]-'0';if(!p->next[ind])p->next[ind]=getNewNode();p=p->next[ind];}p->cnt+=1;p->val+=1;p->flag=1;return ;
}
int query(Node*root,char*s)
{Node*p=root;for(int i=0;s[i];i++){int ind;if(s[i]>='a')ind=s[i]-'a'+36;else if(s[i]>='A')ind=s[i]-'A'+10;else ind=s[i]-'0';if(!p->next[ind])return 0;p=p->next[ind];}return p->cnt;
}
void clear(Node*root)
{if(!root)return ;for(int i=0;i<BASE;i++)if(!root->next[i])clear(root->next[i]);free(root);return ;
}
int main()
{int t,a,b;cin>>t;while(t--){Node*root=getNewNode();scanf("%d%d",&a,&b);while(a--){scanf("%s",s);insert(root,s);}while(b--){cin>>s;cout<<query(root,s)<<endl;}clear(root);}return 0;
}
相关文章:
学习笔记——字符串(单模+多模+练习题)
单模匹配 Brute Force算法(暴力) 算法思想 母串和模式串字符依次配对,如果配对成功则继续比较后面位置是否相同,如果出现匹配不成功的位置,则j(模式串当前的位置)从头开始,i&…...

DOT + graphviz 轻松画图
GraphViz:2 DOT语法和相关应用_graphviz dot-CSDN博客 图可视化之Graphviz - 知乎 Graphviz 是由AT&T Research、Lucent Bell实验室开源的可视化图形工具,可以很方便的用来绘制结构化的图形网络。具体地,其使用一种名为dot语言的DSL来编…...

使用Vue调用ColaAI Plus大模型,实现聊天(简陋版)
首先去百度文心注册申请自己的api 官网地址:LuckyCola 注册点开个人中心 查看这个文档自己申请一个ColaAI Plus定制增强大模型API | LuckyColahttps://luckycola.com.cn/public/docs/shares/api/colaAi.html来到vue的页面 写个样式 <template><Header …...

Unity使用sherpa-onnx实现离线语音合成
sherpa-onnx https://github.com/k2-fsa/sherpa-onnx 相关dll和lib库拷进Unity,官方示例代码稍作修改 using SherpaOnnx; using System; using System.IO; using System.Runtime.InteropServices; using UnityEngine;public class TTS : MonoBehaviour {public st…...

Elasticsearch入门基础和集群部署
Elasticsearch入门基础和集群部署 简介基础概念索引(Index)类型(Type)(逐步弃用)文档(Document)字段(Field)映射(Mapping)分片&#x…...

12、24年--信息系统治理——IT治理
主要考选择题,2分左右,案例、论文涉及概率不大,需要认证读课本原文。 1、IT治理基础 IT治理是描述组织采用有效的机制对信息技术和数据资源开发利用,平衡信息化发展和数字化转型过程中的风险,确保实现组织的战略目标的过程。 1.1 IT治理的驱动因素 1)存在很多问题: 信…...

Electron学习笔记(三)
文章目录 相关笔记笔记说明 五、界面1、获取 webContents 实例(1)通过窗口对象的 webContent 属性获取 webContent 实例:(2)获取当前激活窗口的 webContents 实例:(3)在渲染进程中获…...

【Redis】Redis键值存储
大家好,我是白晨,一个不是很能熬夜,但是也想日更的人。如果喜欢这篇文章,点个赞👍,关注一下👀白晨吧!你的支持就是我最大的动力!💪💪💪…...
C++系统编程篇——Linux初识(系统安装、权限管理,权限设置)
(1)linux系统的安装 双系统---不推荐虚拟机centos镜像(可以使用)云服务器/轻量级云服务器(强烈推荐) ①云服务器(用xshell连接) ssh root公网IP 然后输入password ①添加用户: addus…...

No Cortex-M SW Device Found
将DIO和CLK管脚调换一下...

提升写作效率的秘密武器:一个资深编辑的AI写作体验
有句话说:“写作是一项你坐在打字机前流血的工作。”而如今,各类生成式软件的涌现似乎打破了写作这一古老的艺术形式壁垒。过去,作家们独自在书桌前冥思苦想,如今,一款名为“玲珑AI工具”的ai写作助手正悄然改变着文案写作行业的创作生态,成为提升写作效率的秘密武器。 在传统…...

Python sort() 和 sorted() 的区别应用实例详解
大家好,今天针对 Python 中 sort() 和 sorted() 之间的区别,来一个实例详细解读。sort — 顾名思义就是排序的意思,它可以接收的对象为可迭代的数据类型。今天以列表为例子演示两者的不同点、相同点,以及其中一些常用的高级参数使…...
七、Redis三种高级数据结构-HyperLogLog
Redis HyperLogLog是用来做基数统计的算法,HyperLogLog在优点是,在输入的元素的数量或者体积非常大时,计算基数占用的空间总是固定的、并且非常小。在Redis里每个HyperLogLog键只需花费12KB内存,就可以计算接近 264 个元素的基数。…...

2024年【金属非金属矿山(露天矿山)安全管理人员】模拟考试题库及金属非金属矿山(露天矿山)安全管理人员作业模拟考试
题库来源:安全生产模拟考试一点通公众号小程序 金属非金属矿山(露天矿山)安全管理人员模拟考试题库参考答案及金属非金属矿山(露天矿山)安全管理人员考试试题解析是安全生产模拟考试一点通题库老师及金属非金属矿山&a…...

网站DDoS攻击应对策略:全面防护与恢复指南
随着互联网的发展,网络安全问题日益凸显,其中DDoS(分布式拒绝服务)攻击成为了网站安全的主要威胁之一。当网站遭受DDoS攻击时,可能会面临服务中断、性能下降、数据泄露等严重后果。因此,了解并掌握DDoS攻击…...
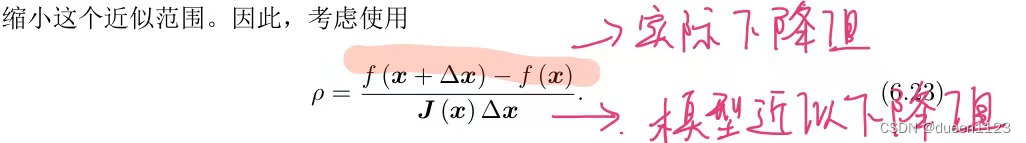
线性/非线性最小二乘 与 牛顿/高斯牛顿/LM 原理及算法
最小二乘分为线性最小二乘和非线性最小二乘 最小二乘目标函数都是min ||f(x)||2 若f(x) ax b,就是线性最小二乘;若f(x) ax2 b / ax2 bx 之类的,就是非线性最小二乘; 1. 求解线性最小二乘 【参考】 2. 求解非线性最小二乘…...

mysqldump: Error 2013 导致mysql停止运行
https://www.cnblogs.com/DataArt/p/10173957.html 1 查询表大小 SELECT table_name AS "表名", round(((data_length index_length) / 1024 / 1024), 2) AS "大小(MB)" FROM information_schema.tables WHERE table_schema your_database_name AND …...

2023年数维杯国际大学生数学建模挑战赛D题洗衣房清洁计算解题全过程论文及程序
2023年数维杯国际大学生数学建模挑战赛 D题 洗衣房清洁计算 原题再现: 洗衣房清洁是人们每天都要做的事情。洗衣粉的去污作用来源于一些表面活性剂。它们可以增加水的渗透性,并利用分子间静电排斥机制去除污垢颗粒。由于表面活性剂分子的存在ÿ…...

python 两种colorbar 最大最小和分类的绘制
1 colorbar 按照自定义的最值绘制 归一化方法使用Normalize(vmin0, vmax40.0) import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt import matplotlib.cm as cm import matplotlib.colors as mcolors from matplotlib import rcParams from matplot…...

Linux-基础IO
🌎Linux基础IO 文章目录: Linux基础IO C语言中IO交互 常用C接口 fopen fputs fwrite fgets 当前路径 三个文件流 系统文件IO open函数 …...

别再只问ChatGPT答案了!试试这个Prompt技巧,让大模型把解题思路‘说’给你听
解锁大模型思维密码:用Prompt技巧让AI展示完整推理路径 当你向ChatGPT抛出一个复杂问题时,是否曾对那个突然出现的最终答案感到困惑?就像看到魔术师从空帽子中变出兔子,却不知道机关在哪里。现代大型语言模型确实能给出惊人准确的…...

程序员AI大模型转型:从入门到精通,轻松掌握大模型开发,高薪职位等你来拿!
在人工智能(AI)迅速发展的背景下,从传统的编程领域如Java程序员转向大模型开发是一个既充满挑战也充满机遇的过程。对于 Java 程序员来说,这也是一个实现职业转型、提升薪资待遇的绝佳机遇。 一、明确大模型概念 简单来说…...

金融公共服务机构钓鱼邮件威胁治理研究 —— 以 NSI 安全事件为例
摘要 英国国家储蓄与投资机构 NS&I 近三年拦截各类恶意邮件 132,126 封,其中垃圾邮件 97,777 封,钓鱼攻击从 1,043 起激增至 4,414 起,呈现总量下降但精准化、AI 化、高危害性显著上升的趋势。作为管理海量公众资金与敏感数据的金融公共服…...
》)
《字节码到JVM:Java基础核心知识点全解析(小林八股·上)》
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

科研抢发期必看:Perplexity图书推荐查询速效组合技——3分钟生成带引用格式的跨学科书单
更多请点击: https://codechina.net 第一章:科研抢发期必看:Perplexity图书推荐查询速效组合技——3分钟生成带引用格式的跨学科书单 在论文投稿前的关键窗口期,快速定位权威参考文献是提升学术严谨性与跨学科说服力的核心能力。…...

Phantora:革新GPU集群模拟的LLM训练优化技术
1. Phantora:GPU集群模拟技术的革新者 在大型语言模型(LLM)训练领域,分布式GPU集群的性能优化一直是个棘手问题。传统方法通常需要在实际硬件上反复试错,这不仅成本高昂,而且调试周期漫长。想象一下&#x…...

Windows防撤回补丁终极指南:微信QQ消息永久保存的完整解决方案
Windows防撤回补丁终极指南:微信QQ消息永久保存的完整解决方案 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gi…...

摆脱人员穿戴约束,无感定位颠覆 UWB 强制管理模式
摆脱人员穿戴约束,无感定位颠覆 UWB 强制管理模式一、UWB 先天短板:深陷强制穿戴、强管控困局传统 UWB 定位天生依赖基站有源标签,想要实现厘米级定位,前提必须是全员强制佩戴标签手环/胸卡。不仅硬性要求内部人员全天候穿戴&…...

WIFI6 OFDMA工作原理
WiFi6 OFDMA 工作原理 一、OFDMA 基础定义与诞生背景 1. 名词释义 OFDMA:Orthogonal Frequency Division Multiple Access,正交频分多址 前身:WiFi4/WiFi5 使用 OFDM(正交频分复用),仅做单用户频域调制升级…...

RT-Thread裁剪实战:从98KB到28KB的嵌入式系统瘦身指南
1. 项目概述:为什么我们需要裁剪RT-Thread?如果你是一名嵌入式软件工程师,或者正在学习RT-Thread,那么“裁剪”这个词对你来说一定不陌生。RT-Thread作为一款优秀的国产开源实时操作系统,其标准版(或称完整…...