Python 中的分步机器学习
1.安装 Python 和 SciPy 平台。
# Check the versions of libraries# Python version
import sys
print('Python: {}'.format(sys.version))
# scipy
import scipy
print('scipy: {}'.format(scipy.__version__))
# numpy
import numpy
print('numpy: {}'.format(numpy.__version__))
# matplotlib
import matplotlib
print('matplotlib: {}'.format(matplotlib.__version__))
# pandas
import pandas
print('pandas: {}'.format(pandas.__version__))
# scikit-learn
import sklearn
print('sklearn: {}'.format(sklearn.__version__))
Python: 3.12.2 | packaged by Anaconda, Inc. | (main, Feb 27 2024, 17:28:07) [MSC v.1916 64 bit (AMD64)]
scipy: 1.13.0
numpy: 1.26.4
matplotlib: 3.8.4
pandas: 2.2.2
sklearn: 1.4.2
2 Loading the dataset. 加载数据集。
我们将使用鸢尾花数据集。该数据集之所以著名,是因为它几乎被每个人用作机器学习和统计中的“hello world”数据集。
该数据集包含 150 个鸢尾花的观察结果。有四列以厘米为单位的花朵测量值。第五列是观察到的花的种类。所有观察到的花都属于三个物种之一。
2.1导入库
# Load libraries
from pandas import read_csv
from pandas.plotting import scatter_matrix
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
2.2加载数据集
我们可以直接从 UCI 机器学习存储库加载数据。
我们使用 pandas 来加载数据。接下来我们还将使用 pandas 通过描述性统计和数据可视化来探索数据。
请注意,我们在加载数据时指定每列的名称。这将有助于我们稍后探索数据。
...
# Load dataset
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(url, names=names)
print(dataset)
sepal-length sepal-width petal-length petal-width class
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 Iris-virginica
146 6.3 2.5 5.0 1.9 Iris-virginica
147 6.5 3.0 5.2 2.0 Iris-virginica
148 6.2 3.4 5.4 2.3 Iris-virginica
149 5.9 3.0 5.1 1.8 Iris-virginica[150 rows x 5 columns]
3 Summarizing the dataset.总结数据集。
在此步骤中,我们将通过几种不同的方式查看数据:
1 数据集的维度。
2 查看数据本身。
3 所有属性的统计摘要。
4 按类变量对数据进行细分。
3.1 数据集维度
...
# shape
print(dataset.shape)
(150, 5)
3.2 查看数据
#head
print(dataset.head(20))
sepal-length sepal-width petal-length petal-width class
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
5 5.4 3.9 1.7 0.4 Iris-setosa
6 4.6 3.4 1.4 0.3 Iris-setosa
7 5.0 3.4 1.5 0.2 Iris-setosa
8 4.4 2.9 1.4 0.2 Iris-setosa
9 4.9 3.1 1.5 0.1 Iris-setosa
10 5.4 3.7 1.5 0.2 Iris-setosa
11 4.8 3.4 1.6 0.2 Iris-setosa
12 4.8 3.0 1.4 0.1 Iris-setosa
13 4.3 3.0 1.1 0.1 Iris-setosa
14 5.8 4.0 1.2 0.2 Iris-setosa
15 5.7 4.4 1.5 0.4 Iris-setosa
16 5.4 3.9 1.3 0.4 Iris-setosa
17 5.1 3.5 1.4 0.3 Iris-setosa
18 5.7 3.8 1.7 0.3 Iris-setosa
19 5.1 3.8 1.5 0.3 Iris-setosa
3.3 统计总结
#description:
print(dataset.describe())
sepal-length sepal-width petal-length petal-width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.054000 3.758667 1.198667
std 0.828066 0.433594 1.764420 0.763161
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
3.4 类别分布
看一下属于每个类的实例(行)数。我们可以将其视为绝对计数。
...
# class distribution
# print(dataset.groupby('class'))
print(dataset.groupby('class').size())
class
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
dtype: int64
3.5 完整示例
# summarize the data
from pandas import read_csv
# Load dataset
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(url, names=names)
# shape
print(dataset.shape)
# head
print(dataset.head(20))
# descriptions
print(dataset.describe())
# class distribution
print(dataset.groupby('class').size())
(150, 5)sepal-length sepal-width petal-length petal-width class
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
5 5.4 3.9 1.7 0.4 Iris-setosa
6 4.6 3.4 1.4 0.3 Iris-setosa
7 5.0 3.4 1.5 0.2 Iris-setosa
8 4.4 2.9 1.4 0.2 Iris-setosa
9 4.9 3.1 1.5 0.1 Iris-setosa
10 5.4 3.7 1.5 0.2 Iris-setosa
11 4.8 3.4 1.6 0.2 Iris-setosa
12 4.8 3.0 1.4 0.1 Iris-setosa
13 4.3 3.0 1.1 0.1 Iris-setosa
14 5.8 4.0 1.2 0.2 Iris-setosa
15 5.7 4.4 1.5 0.4 Iris-setosa
16 5.4 3.9 1.3 0.4 Iris-setosa
17 5.1 3.5 1.4 0.3 Iris-setosa
18 5.7 3.8 1.7 0.3 Iris-setosa
19 5.1 3.8 1.5 0.3 Iris-setosasepal-length sepal-width petal-length petal-width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.054000 3.758667 1.198667
std 0.828066 0.433594 1.764420 0.763161
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
class
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
dtype: int64
4Visualizing the dataset.可视化数据集。
我们将看两种类型的图:
1 单变量图可以更好地理解每个属性。
2 多元图可以更好地理解属性之间的关系。
4.1 单变量图
鉴于输入变量是数字,我们可以为每个变量创建箱线图和须线图。
# box and whisker plots
dataset.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)
plt.show<function matplotlib.pyplot.show(close=None, block=None)>
我们还可以创建每个输入变量的直方图以了解分布。
#histograms
dataset.hist()
plt.show()
4.2 多元图
现在,我们可以查看变量之间的相互作用。
首先,让我们看一下所有属性的散点图。这可能有助于发现输入变量之间的结构化关系
# scatter plot matrix
scatter_matrix(dataset)
plt.show()
4.3 完整示例
# visualize the data
from pandas import read_csv
from pandas.plotting import scatter_matrix
from matplotlib import pyplot as plt
# Load dataset
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(url, names=names)
# box and whisker plots
dataset.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)
plt.show()
# histograms
dataset.hist()
plt.show()
# scatter plot matrix
scatter_matrix(dataset)
plt.show()
5 Evaluating some algorithms.评估一些算法。
现在是时候创建一些数据模型并估计其在看不见的数据上的准确性了。
这是我们将在此步骤中涵盖的内容:
1 分开验证数据集。
2 设置测试线束以使用10倍的交叉验证。
3 构建多个不同的模型以预测花朵测量的物种
4 选择最佳模型。
5.1创建验证数据集
我们需要知道我们创建的模型很好。
稍后,我们将使用统计方法来估计我们在看不见的数据上创建的模型的准确性。我们还希望通过对实际看不见的数据进行评估,对最佳模型的准确性进行更具体的估计。
也就是说,我们将删除算法无法看到的一些数据,我们将使用这些数据来获得第二个独立的想法,即最佳模型的实际性如何。
我们将将加载的数据集分为两个,其中80%将用于训练,评估和选择我们的模型,而20%我们将作为验证数据集退缩。
#split-out validation dataset
array = dataset.values
X = array[:, 0:4]
y = array[:, 4]
X_train, X_validation, Y_train, Y_validation = train_test_split(X, y, test_size=0.20, random_state=1)
现在,可以在X_Train和Y_Train中使用训练数据,用于准备模型以及X_validation和Y__Validation集,我们可以在以后使用。
5.2 测试工具
我们将使用分层 10 倍交叉验证来估计模型准确性。
这会将我们的数据集分为 10 个部分,对 9 个部分进行训练,对 1 个部分进行测试,然后对训练-测试分割的所有组合重复此操作。
分层意味着数据集的每次折叠或分割都旨在具有与整个训练数据集中存在的相同的类示例分布。
我们通过 random_state 参数将随机种子设置为固定数字,以确保每个算法在训练数据集的相同分割上进行评估。
我们使用“准确性”指标来评估模型。
这是正确预测的实例数除以数据集中的实例总数再乘以 100 得出的百分比(例如,准确率 95%)。当我们接下来运行构建和评估每个模型时,我们将使用评分变量。
5.3 构建模型
我们不知道哪种算法适合解决这个问题或使用什么配置。
我们从图中了解到,某些类在某些维度上是部分线性可分的,因此我们预计总体上会得到良好的结果。
让我们测试 6 种不同的算法:
- Logistic Regression (LR)
逻辑回归 (LR) - Linear Discriminant Analysis (LDA)
线性判别分析 (LDA) - K-Nearest Neighbors (KNN).
K 最近邻 (KNN)。 - Classification and Regression Trees (CART).
分类和回归树 (CART)。 - Gaussian Naive Bayes (NB).
高斯朴素贝叶斯 (NB)。 - Support Vector Machines (SVM).
支持向量机 (SVM)。
这是简单线性(LR 和 LDA)、非线性(KNN、CART、NB 和 SVM)算法的良好组合。
让我们构建并评估我们的模型:
# from sklearn.linear_model import LogisticRegression
# from sklearn.tree import DecisionTreeClassifier
# from sklearn.neighbors import KNeighborsClassifier
# from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# from sklearn.naive_bayes import GaussianNB
# from sklearn.svm import SVC
# spot check algorithms
models = []
models.append(('LR', LogisticRegression(solver = 'liblinear', multi_class = 'ovr' )))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC(gamma = 'auto')))
# evaluate each model in turn
results = []
names = []
for name, model in models:kfold = StratifiedKFold(n_splits=10, random_state=1, shuffle=True)cv_results = cross_val_score(model, X_train, Y_train, cv=kfold, scoring='accuracy')results.append(cv_results)names.append(name)print('%s: %f (%f)' % (name, cv_results.mean(), cv_results.std()))
LR: 0.941667 (0.065085)
LDA: 0.975000 (0.038188)
KNN: 0.958333 (0.041667)
CART: 0.950000 (0.040825)
NB: 0.950000 (0.055277)
SVM: 0.983333 (0.033333)
5.4 选择最佳模型
我们现在有 6 个模型以及每个模型的准确度估计。我们需要对模型进行相互比较并选择最准确的模型。
注意:由于算法或评估过程的随机性或数值精度的差异,您的结果可能会有所不同。考虑运行该示例几次并比较平均结果。
在这种情况下,我们可以看到支持向量机 (SVM) 的估计准确度分数最大,约为 0.98 或 98%。
我们还可以创建模型评估结果图,并比较每个模型的分布和平均准确度。每个算法都有一组准确度度量,因为每个算法都被评估了 10 次(通过 10 次交叉验证)。
比较每种算法的结果样本的一个有用方法是为每个分布创建箱须图并比较分布。
#compare algorithms
plt.boxplot(results, labels= names)
plt.title('Algorithm Comparison')
plt.show()
我们可以看到箱线图和须线图在范围的顶部被压扁,许多评估达到了 100% 的准确度,有些则降低到了 80% 的准确度。
5.5 完整示例
作为参考,我们可以将前面的所有元素组合到一个脚本中。
下面列出了完整的示例。
# compare algorithms
from pandas import read_csv
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
# Load dataset
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(url, names=names)
# Split-out validation dataset
array = dataset.values
X = array[:, 0:4]
y = array[:, 4]
X_train, X_validation, Y_train, Y_validation = train_test_split(X, y, test_size=0.20, random_state=1)
# Spot Check Algorithms
models = []
models.append(('LR', LogisticRegression(solver='liblinear', multi_class='ovr')))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC(gamma='auto')))
# evaluate each model in turn
results = []
names = []
for name, model in models:kfold = StratifiedKFold(n_splits=10, random_state=1, shuffle=True)cv_results = cross_val_score(model, X_train, Y_train, cv=kfold, scoring='accuracy')results.append(cv_results)names.append(name)print('%s: %f (%f)' % (name, cv_results.mean(), cv_results.std()))
# Compare Algorithms
plt.boxplot(results, labels=names)
plt.title('Algorithm Comparison')
plt.show()LR: 0.941667 (0.065085)
LDA: 0.975000 (0.038188)
KNN: 0.958333 (0.041667)
CART: 0.958333 (0.041667)
NB: 0.950000 (0.055277)
SVM: 0.983333 (0.033333)
6 Making some predictions.做出一些预测。
我们必须选择一种算法来进行预测。
上一节的结果表明 SVM 可能是最准确的模型。我们将使用这个模型作为我们的最终模型。
现在我们想要了解模型在验证集上的准确性。
这将使我们能够对最佳模型的准确性进行独立的最终检查。保留验证集很有价值,以防万一您在训练过程中出现失误,例如训练集过度拟合或数据泄漏。这两个问题都会导致过于乐观的结果。
6.1 做出预测
我们可以将模型拟合到整个训练数据集上,并对验证数据集进行预测。
#make predictions on validaton dataset
model = SVC(gamma='auto')
model.fit(X_train, Y_train)
predictions = model.predict(X_validation)
您可能还想对单行数据进行预测。有关如何执行此操作的示例,请参阅教程:https://machinelearningmastery.com/make-predictions-scikit-learn/
您可能还想将模型保存到文件并稍后加载以对新数据进行预测。有关如何执行此操作的示例,请参阅教程:https://machinelearningmastery.com/save-load-machine-learning-models-python-scikit-learn/
6.2 评估预测
我们可以通过将预测与验证集中的预期结果进行比较来评估预测,然后计算分类准确性以及混淆矩阵和分类报告。
# Evaluate predictions
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))
0.9666666666666667
[[11 0 0][ 0 12 1][ 0 0 6]]precision recall f1-score supportIris-setosa 1.00 1.00 1.00 11
Iris-versicolor 1.00 0.92 0.96 13Iris-virginica 0.86 1.00 0.92 6accuracy 0.97 30macro avg 0.95 0.97 0.96 30weighted avg 0.97 0.97 0.97 30
我们可以看到,在保留数据集上,准确率为 0.966,即 96% 左右。
混淆矩阵提供了所犯错误的指示。
最后,分类报告按精度、召回率、f1 分数和支持度对每个类别进行了细分,显示出出色的结果(假设验证数据集很小)。
6.3 完整示例
# make predictions
from pandas import read_csv
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.svm import SVC# load dataset
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(url, names=names)
# split-out validation dataset
array = dataset.values
X = array[:, 0:4]
y = array[:, 4]
X_train, X_validation, Y_train, Y_validation = train_test_split(X, y, test_size=0.20, random_state=1)
# make predictions on validation dataset
model = SVC(gamma='auto')
model.fit(X_train, Y_train)
predictions = model.predict(X_validation)
# evaluate predictions
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))0.9666666666666667
[[11 0 0][ 0 12 1][ 0 0 6]]precision recall f1-score supportIris-setosa 1.00 1.00 1.00 11
Iris-versicolor 1.00 0.92 0.96 13Iris-virginica 0.86 1.00 0.92 6accuracy 0.97 30macro avg 0.95 0.97 0.96 30weighted avg 0.97 0.97 0.97 30
相关文章:

Python 中的分步机器学习
1.安装 Python 和 SciPy 平台。 # Check the versions of libraries# Python version import sys print(Python: {}.format(sys.version)) # scipy import scipy print(scipy: {}.format(scipy.__version__)) # numpy import numpy print(numpy: {}.format(numpy.__version__)…...

C++错题集(持续更新ing)
Day 1 一、选择题 解析: 在数字不会溢出的前提下,对于正数和负数,有: 1)左移n位,相当于操作数乘以2的n次方; 2)右移n位,相当于操作数除以2的n次方。 解析:…...
静态IP代理:网络世界的隐秘通道
在数字化时代,网络安全和隐私保护日益受到重视。静态IP代理作为一种网络服务,为用户提供了一个稳定且可预测的网络连接方式,同时保护了用户的在线身份。本文将从五个方面深入探讨静态IP代理的概念、优势、应用场景、技术实现以及选择时的考量…...

信号和槽的其他说明和优缺点
🐌博主主页:🐌倔强的大蜗牛🐌 📚专栏分类:QT❤️感谢大家点赞👍收藏⭐评论✍️ 目录 一、信号与槽的断开 二、使用Lambda 表达式定义槽函数 1、局部变量引入方式 [ ] 2、函数参数 &am…...

手工创建 kamailio database tables
有些场景可能kamdbctl create不好使,可能需要手工创建 kamailio database tables,可参考下面的命令序列: USE mysql # 删除之前创建的用户 SELECT user,host FROM user; DROP USER kamailio%; FLUSH PRIVILEGES; # 删除之前创建的数据库 DROP…...
SpringBoot接收参数的19种方式
https://juejin.cn/post/7343243744479625267?share_token6D3AD82C-0404-47A7-949C-CA71F9BC9583...

Disk Map for Mac,让您的Mac更“轻”松
还在为Mac磁盘空间不足而烦恼吗?Disk Map for Mac来帮您轻松解决!通过独特的TreeMap视觉显示技术,让您一眼就能看出哪些文件和文件夹占用了大量空间。只需简单几步操作,即可快速释放磁盘空间,让您的Mac更“轻”松。快来…...

【二叉树】(三)二叉树的基础修改构造及属性求解2
(二)二叉树的基础修改构造及属性求解2 二叉树的所有路径思路递归法迭代法 左叶子之和递归法迭代法 找树左下角的值递归法迭代法 路径总和从中序与后序遍历序列构造二叉树最大二叉树合并二叉树 二叉树的所有路径 力扣原题链接:257. 二叉树的所…...
PyCharm2024安装教程
PyCharm是一款功能强大的Python集成开发环境(IDE),它提供了许多工具和功能来帮助开发者编写、调试和测试Python代码。以下是使用PyCharm的基本步骤: 安装PyCharm:首先,你需要从JetBrains官方网站下载并安装…...

JavaScript基础知识强化:变量提升、作用域逻辑及TDZ的全面解析
🔥 个人主页:空白诗 文章目录 ⭐️ 引言🎯 变量提升(Hoisting)👻 暂时性死区(Temporal Dead Zone, TDZ)解释📦 var声明🔒 let与const声明📖 函数声明 与 函数表达式函数声…...
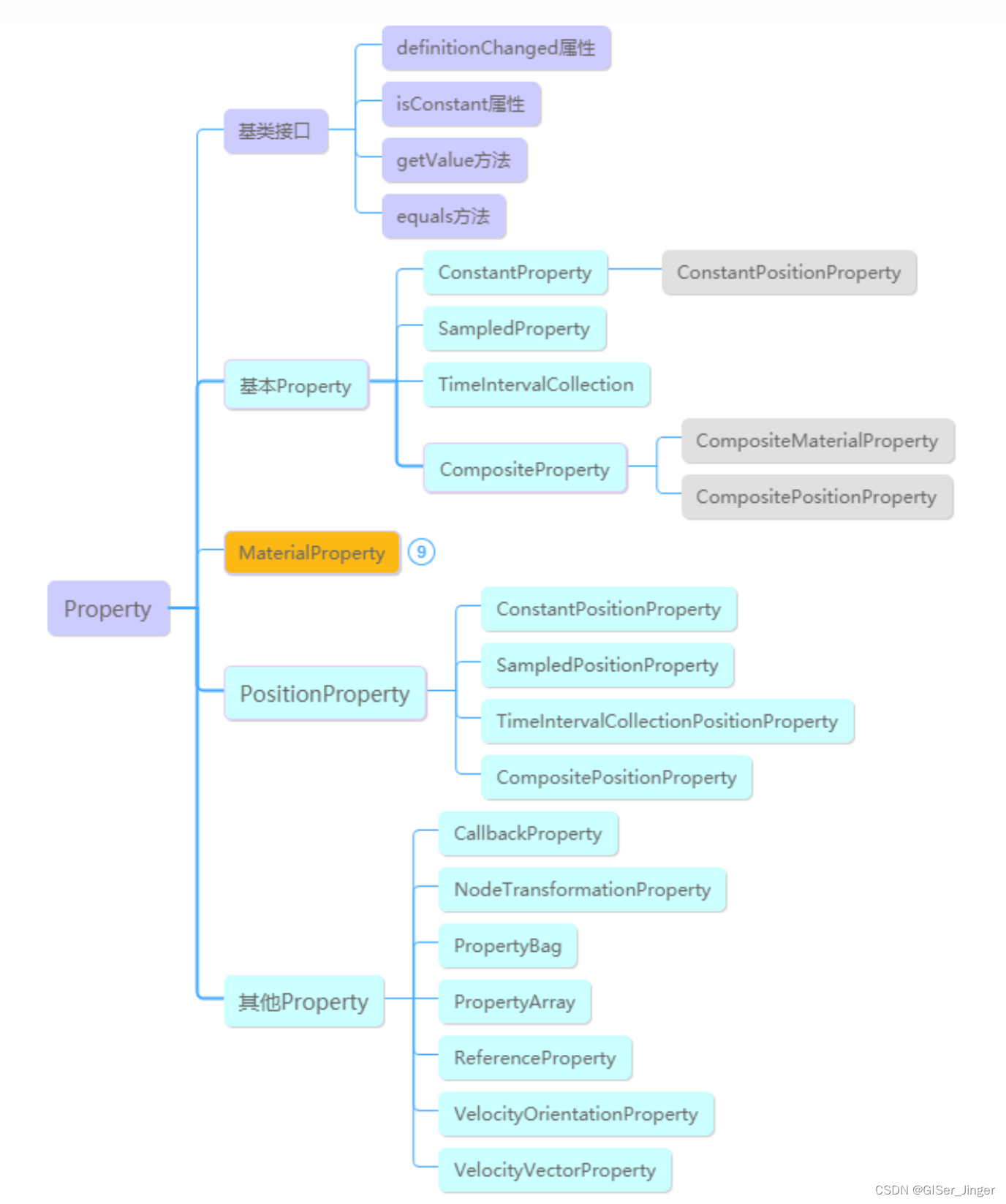
[Cesium]Cesium基础学习——Primitive
Cesium开发高级篇 | 01空间数据可视化之Primitive - 知乎 Primitive由两部分组成:几何体(Geometry)和外观(Appearance)。几何体定义了几何类型、位置和颜色,例如三角形、多边形、折线、点、标签等ÿ…...

java相等忽略音调
来自百度,亲测可用 java相等忽略音调 在Java中,如果你想比较两个字符串而忽略它们的音调符号,你可以使用java.text.Collator类来进行区域敏感的字符串比较。Collator类提供了根据特定区域的规则进行字符串比较的能力,可以设置忽略音调的选项…...

自养号测评实战指南:Shopee、Lazada销量翻倍不再是难题
对于速卖通、亚马逊、eBay、敦煌网、SHEIN、Lazada、虾皮等平台的卖家而言,提高店铺流量并转化为实际销量是共同追求的目标。在这个过程中,自养号进行产品测评显得尤为重要。通过精心策划和执行的测评活动,卖家不仅能够显著增加产品的销量&am…...
)
【Java开发面试系列】JVM相关面试题(精选)
【Java开发面试系列】JVM相关面试题(精选) 文章目录 【Java开发面试系列】JVM相关面试题(精选)前言一、JVM组成二、类加载器三、垃圾回收四、JVM实践(调优) 🌈你好呀!我是 山顶风景独…...

解决Win11下SVN状态图标显示不出来
我们正常SVN在Windows资源管理器都是有显示状态图标的, 如果不显示状态图标,可能你的注册表的配置被顶下去了,我们查看一下注册表 运行CMD > regedit 打开注册表编辑器 然后打开这个路径:计算机\HKEY_LOCAL_MACHINE\SOFTWARE…...

代码随想录训练营第四十天 | 343. 整数拆分、96.不同的二叉搜索树
343. 整数拆分 题目链接:. - 力扣(LeetCode) 文档讲解:代码随想录 视频讲解:动态规划,本题关键在于理解递推公式!| LeetCode:343. 整数拆分_哔哩哔哩_bilibili 状态:未通…...

python爬取数据并将数据写入execl表中
文章目录 概要 概要 提示:python爬取数据并将数据写入execl表中,仅供学习使用,代码是很久前的,可能执行不通,自行参考学习。 # -*- coding: utf-8 -*- import datetime # 日期库 import requests # 进行网络请求 im…...

Linux动静态库
Linux动静态库 1.动静态库介绍 在程序翻译的链接阶段,其实就是把一堆.o文件链接在一起形成.exe文件。如果一个程序中需要链接很多个.o文件,那么这些.o文件就需要被打包才方便管理,**库文件本质就是把.o文件打包。**库文件是一种提高开发效率…...
)
线程与进程___(一)
1、线程 Thread 类创建得线程为前台线程,线程池中的为后台线程,,,Main方法结束后,前台线程仍然运行,直到完成,而后台线程立刻结束。 调用线程时候不会立刻进入 Running 状态, 而是…...

Google IO 2024有哪些看点呢?
有了 24 小时前 OpenAI 用 GPT-4o 带来的炸场之后,今年的 Google I/O 还未开始,似乎就被架在了一个相当尴尬的地位,即使每个人都知道 Google 将发布足够多的新 AI 内容,但有了 GPT-4o 的珠玉在前,即使是 Google 也不得…...

tinySPL 与 U-Boot 核心区别
tinySPL 与 U-Boot 核心区别 一、定位本质项目tinySPLU-Boot定位轻量极简二级引导,专为RTOS/裸机设计通用全能大型Bootloader,主打Linux系统体积极小,几十KB级别大,几百KB~数MB设计目标极速启动、轻量化、适配嵌入式轻系统功能最全…...

无王无帝定乾坤,来自田间第一人 道统传承兴万民
无王无帝定乾坤 来自田间第一人 华夏千载文脉绵延,万古道统源远流长,自古圣贤立心传道,只为正本清源、润泽苍生。往昔道统多依附王权存续,受朝堂礼制所拘,流传受限,难入寻常百姓之家,普惠世间之…...

嵌入式边缘AI论坛参会全攻略:从技术趋势到实战社交
1. 论坛核心价值与参会目标拆解“6天倒计时!”这个标题,精准地抓住了所有技术从业者在面对一个高价值行业活动时,那种既兴奋又略带紧迫感的共同心理。这不仅仅是一个简单的会议通知,它更像是一份来自同行的“战前简报”。对于嵌入…...

技术从业者的时间管理:如何平衡工作、学习和生活
在敏捷开发大行其道、技术迭代日新月异的当下,软件测试从业者正面临着前所未有的时间压力。一边是项目交付的紧迫期限、层出不穷的缺陷排查需求,一边是自动化测试工具、AI测试框架等新技术的学习焦虑,再加上对个人生活品质的追求,…...

初次使用 Taotoken 模型广场进行模型选型与测试的流程指引
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用 Taotoken 模型广场进行模型选型与测试的流程指引 对于刚接触大模型服务的开发者而言,面对众多厂商和模型&…...

三分钟带你读懂C++中的排序方式
在 C 中,有多种方式可以用于排序,每种方法都有其适用场景。以下是几种常见的排序方式:1. 使用标准库中的 sort 函数C STL(标准模板库)提供了 <algorithm> 头文件中的 sort 函数,这是最常用的排序方法…...

Hyper-V虚拟机文件迁移避坑指南:从C盘挪走Ubuntu,释放系统盘空间
Hyper-V虚拟机文件迁移实战:安全释放C盘空间的完整方案 当你在Windows系统上使用Hyper-V运行Ubuntu虚拟机时,是否注意到C盘空间正在被悄悄吞噬?许多技术爱好者初次接触Hyper-V时,往往直接采用默认设置,将所有虚拟机文件…...

B站视频下载神器:如何优雅地将Bilibili内容保存到本地
B站视频下载神器:如何优雅地将Bilibili内容保存到本地 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/b…...

DWC_ether_qos驱动软复位实战:解决网络丢包与DMA死锁
1. 项目概述:从一次诡异的网络丢包说起最近在调试一块基于某款主流SoC的工控板卡时,遇到了一个让人头疼的问题:设备在长时间高负载运行后,网络会间歇性地出现严重丢包,甚至完全断连。重启网络服务能暂时恢复࿰…...

Perplexity新闻资讯搜索终极对比:VS Google News、Bing News、Feedly——基于3000+查询样本的准确率/时效性/溯源完整性三维压测报告
更多请点击: https://kaifayun.com 第一章:Perplexity新闻资讯搜索终极对比:VS Google News、Bing News、Feedly——基于3000查询样本的准确率/时效性/溯源完整性三维压测报告 在为期12周的基准测试中,我们构建了覆盖科技、金融、…...