AI大模型探索之路-训练篇23:ChatGLM3微调实战-基于P-Tuning V2技术的实践指南
系列篇章💥
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验
AI大模型探索之路-训练篇9:大语言模型Transformer库-Pipeline组件实践
AI大模型探索之路-训练篇10:大语言模型Transformer库-Tokenizer组件实践
AI大模型探索之路-训练篇11:大语言模型Transformer库-Model组件实践
AI大模型探索之路-训练篇12:语言模型Transformer库-Datasets组件实践
AI大模型探索之路-训练篇13:大语言模型Transformer库-Evaluate组件实践
AI大模型探索之路-训练篇14:大语言模型Transformer库-Trainer组件实践
AI大模型探索之路-训练篇15:大语言模型预训练之全量参数微调
AI大模型探索之路-训练篇16:大语言模型预训练-微调技术之LoRA
AI大模型探索之路-训练篇17:大语言模型预训练-微调技术之QLoRA
AI大模型探索之路-训练篇18:大语言模型预训练-微调技术之Prompt Tuning
AI大模型探索之路-训练篇19:大语言模型预训练-微调技术之Prefix Tuning
AI大模型探索之路-训练篇20:大语言模型预训练-常见微调技术对比
AI大模型探索之路-训练篇21:Llama2微调实战-LoRA技术微调步骤详解
AI大模型探索之路-训练篇22: ChatGLM3微调实战-从原理到应用的LoRA技术全解
目录
- 系列篇章💥
- 前言
- 一、服务器资源准备
- 二、下载ChatGLM3工程
- 1、下载工程
- 2、安装相关依赖
- 1)使用conda创建微调的虚拟环境
- 2)安装ChatGLM3依赖
- 3)安装微调依赖
- 三、下载ChatGLM3模型
- 1、安装git-lfs
- 2、执行:git lfs install
- 3、下载模型(模型权重相关文件)
- 4、检查权重文件
- 四、下载数据集
- 1、数据集下载
- 2、数据格式转化
- 3、数据格式检查
- 五、微调脚本说明
- 1、脚本说明(finetune_demo)
- 2、配置说明
- 六、模型微调
- 1、模型微调
- 2、从保存点进行微调
- 七、推理验证
- 1、修改模型地址
- 2、开始模型推理
- 总结
前言
在人工智能的广阔领域里,大语言模型(LLMs)的微调技术扮演着至关重要的角色。它不仅为模型注入了适应特定任务的能力,而且还是通往专业领域的关键。本文旨在深入探讨基于P-Tuning V2技术的ChatGLM3微调流程,这是一种将因果语言模型与对话优化相结合的优秀实践,我们希望借此引领读者深入了解大模型微调的内涵。
在上文中,我们详细介绍了基于LoRA技术微调ChatGLM3的操作过程。而本文将重点展示基于P-Tuning V2技术的微调过程。我们将采用GLM官方在github上提供的微调脚本进行高效微调,向大家展示一种更为简单便捷的微调方法。
一、服务器资源准备
首先,服务器资源准备是微调工作的基础。根据官方提供的显存占用说明,我们需配置相应数量的显卡资源。P-TuningV2微调所需的显存相对较少,仅需1张显卡即可展开工作。
以下是官方提供的显存的占用情况说明:
1)SFT 全量微调: 4张显卡平均分配,每张显卡占用 48346MiB 显存。
2)P-TuningV2 微调: 1张显卡,占用 18426MiB 显存。
3)LORA 微调: 1张显卡,占用 14082MiB 显存。
请注意,该结果仅供参考,对于不同的参数,显存占用可能会有所不同。请结合你的硬件情况进行调整。
二、下载ChatGLM3工程
接下来,克隆ChatGLM3工程并安装相关依赖,这一系列动作将构建起我们微调工作的基本环境。
1、下载工程
从github地址中下在ChatGLM3工程,工程中包含了很多测试的demo样例,包括微调样例
git clone https://github.com/THUDM/ChatGLM3.git
2、安装相关依赖
1)使用conda创建微调的虚拟环境
#创建虚拟环境
conda create -n ChatGLM3-6b-finetunning python=3.10
#激活虚拟环境
conda activate ChatGLM3-6b-finetunning
#激活成功如下
(ChatGLM3-6b-finetunning) root@autodl-container-90ee468393-1c276b30:~#
#退出当前虚拟环境
conda deactivate
2)安装ChatGLM3依赖
ChatGLM3的finetune_demo目录下的requirements.txt都行需要执行
cd ChatGLM3
pip install -r requirements.txt
3)安装微调依赖
cd finetune_demo
pip install -r requirements.txt
执行如下:

三、下载ChatGLM3模型
本次微调主要基于ChatGLM3-6B对话模型进行微调(也是我们常规的大部分应用场景)
ChatGLM3-6B和ChatGLM-6B-Base 说明:
ChatGLM3-6B:这是一个对话调优的大语言模型,在ChatGLM-6B-Base的基础上进行了对话训练调优;它针对对话场景进行了特定的优化,使得其在处理对话式问答、指令跟随等需要与用户进行互动的场景时表现更加出色。这种优化可能包括使用对话数据集进行微调,从而更好地理解并回应用户的需求。
ChatGLM-6B-Base:是基础的大语言模型,它是构建其他特定应用模型的基础版本。作为一个基础模型,它提供了广泛的语言理解和生成能力,但没有针对特定场景如对话进行特别的优化。这意味着它在通用的语言任务上表现良好,但在对话场景下可能不如专门对话调优过的模型。
下载ChatGLM3-6B对话模型的相关权重文件
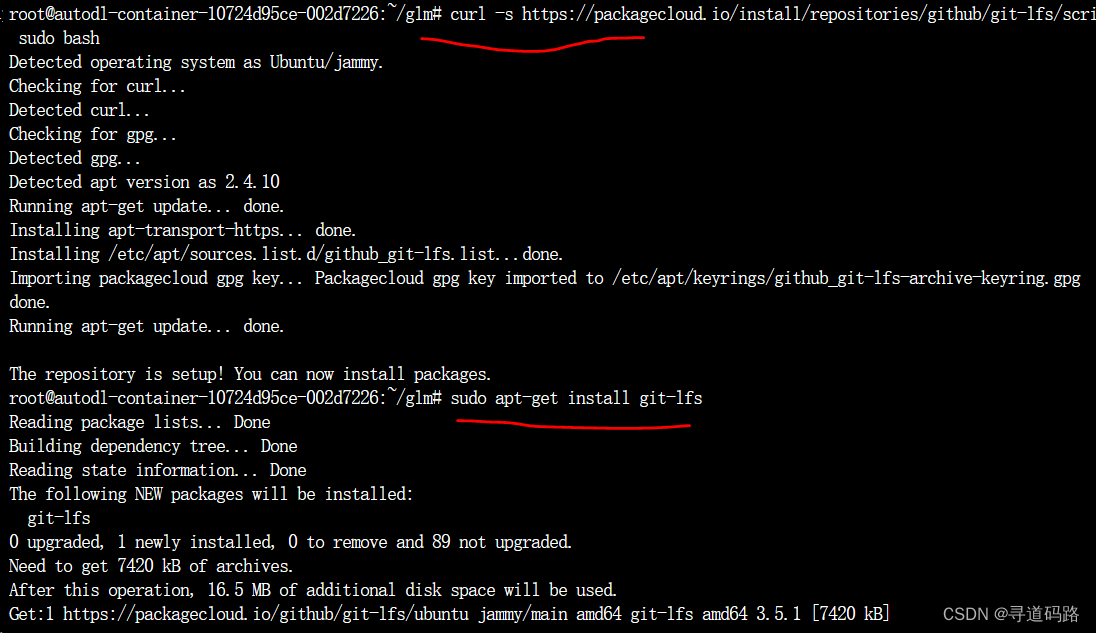
1、安装git-lfs
需要先安装Git LFS ,Ubuntu系统操作命令:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
执行如下:
Centos命令参考: curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.rpm.sh | sudo bash
sudo yum install git-lfs
2、执行:git lfs install

3、下载模型(模型权重相关文件)
在autodl-tmp下新建model用于放模型文件
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git

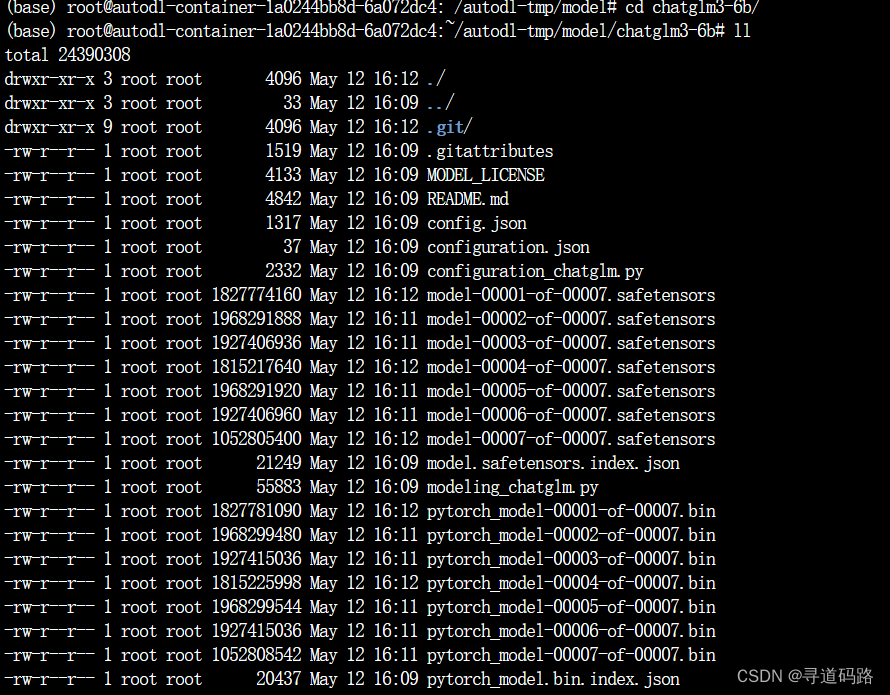
4、检查权重文件
对比modelscope上的文件列表和文件的大小,检查是否下载完整
四、下载数据集
数据准备阶段,我们除了下载了专为对话场景优化的ChatGLM3-6B模型及其权重文件,并对数据集进行下载和格式转换。这一过程确保了我们拥有充足的训练样本和适配的数据结构,为接下来的微调奠定了坚实基础。
1、数据集下载
数据集地址:https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
这是官方准备的数据集;下载处理好的 AdvertiseGen 数据集,将解压后的 AdvertiseGen 目录放到本目录的 /data/ 下, 例如:/root/ChatGLM3/finetune_demo/data/AdvertiseGen
数据格式如下:

我们需要进行数据格式转化,转为目标数据格式:

2、数据格式转化
执行如下python脚本,对数据格式进行处理
python translate_fomat.py
translate_fomat.py 放在/root/ChatGLM3/finetune_demo目录下
import json
from typing import Union
from pathlib import Pathdef _resolve_path(path: Union[str, Path]) -> Path:return Path(path).expanduser().resolve()def _mkdir(dir_name: Union[str, Path]):dir_name = _resolve_path(dir_name)if not dir_name.is_dir():dir_name.mkdir(parents=True, exist_ok=False)def convert_adgen(data_dir: Union[str, Path], save_dir: Union[str, Path]):def _convert(in_file: Path, out_file: Path):_mkdir(out_file.parent)with open(in_file, encoding='utf-8') as fin:with open(out_file, 'wt', encoding='utf-8') as fout:for line in fin:dct = json.loads(line)sample = {'conversations': [{'role': 'user', 'content': dct['content']},{'role': 'assistant', 'content': dct['summary']}]}fout.write(json.dumps(sample, ensure_ascii=False) + '\n')data_dir = _resolve_path(data_dir)save_dir = _resolve_path(save_dir)train_file = data_dir / 'train.json'if train_file.is_file():out_file = save_dir / train_file.relative_to(data_dir)_convert(train_file, out_file)dev_file = data_dir / 'dev.json'if dev_file.is_file():out_file = save_dir / dev_file.relative_to(data_dir)_convert(dev_file, out_file)convert_adgen('data/AdvertiseGen', 'data/AdvertiseGen_fix')
3、数据格式检查
格式转化脚本执行完,在/root/ChatGLM3/finetune_demo/data下会新增AdvertiseGen_fix文件夹,包含转换后的文件,格式如下:

五、微调脚本说明
讲章节主要解了各配置文件的作用,包括数据配置、模型参数、优化器设置及训练监控等。这些配置细节对于理解微调流程和调整训练策略至关重要。通过修改配置文件,我们可以根据需要调整模型的训练行为,实现精确匹配项目需求的目标。
1、脚本说明(finetune_demo)
| configs | 配置目录(包含多种微调的配置,支持LoRA、P-Tuning V2等微调) |
|---|---|
| finetune_hf.py | 微调接口文件 |
| inference_hf.py | 推理接口文件 |
2、配置说明
微调配置文件位于 config 目录下,包括以下文件:
ds_zereo_2 / ds_zereo_3.json: deepspeed 配置文件。
lora.yaml / ptuning.yaml / sft.yaml: 模型不同方式的配置文件,包括模型参数、优化器参数、训练参数等。 部分重要参数解释如下:
1)data_config 部分
train_file: 训练数据集的文件路径。
val_file: 验证数据集的文件路径。
test_file: 测试数据集的文件路径。
num_proc: 在加载数据时使用的进程数量。
2)max_input_length: 输入序列的最大长度。
3)max_output_length: 输出序列的最大长度。
4)training_args 部分
output_dir: 用于保存模型和其他输出的目录。
max_steps: 训练的最大步数。
per_device_train_batch_size: 每个设备(如 GPU)的训练批次大小。
dataloader_num_workers: 加载数据时使用的工作线程数量。
remove_unused_columns: 是否移除数据中未使用的列。
save_strategy: 模型保存策略(例如,每隔多少步保存一次)。
save_steps: 每隔多少步保存一次模型。
log_level: 日志级别(如 info)。
logging_strategy: 日志记录策略。
logging_steps: 每隔多少步记录一次日志。
per_device_eval_batch_size: 每个设备的评估批次大小。
evaluation_strategy: 评估策略(例如,每隔多少步进行一次评估)。
eval_steps: 每隔多少步进行一次评估。
predict_with_generate: 是否使用生成模式进行预测。
5)generation_config 部分
max_new_tokens: 生成的最大新 token 数量。
6)peft_config 部分
peft_type: 使用的参数有效调整类型(如 LORA)。
task_type: 任务类型,这里是因果语言模型(CAUSAL_LM)。
7)Lora 参数:
r: LoRA 的秩。
lora_alpha: LoRA 的缩放因子。
lora_dropout: 在 LoRA 层使用的 dropout 概率
8)P-TuningV2 参数:
num_virtual_tokens: 虚拟 token 的数量。
六、模型微调
进入模型微调阶段,我们采用了命令行接口执行微调脚本,选择了P-Tuning V2作为微调策略,并指定了必要的参数如数据路径、模型地址和配置文件。此外,还展示了如何从中断点继续微调,这对于节省计算资源和时间成本具有显著意义。
1、模型微调
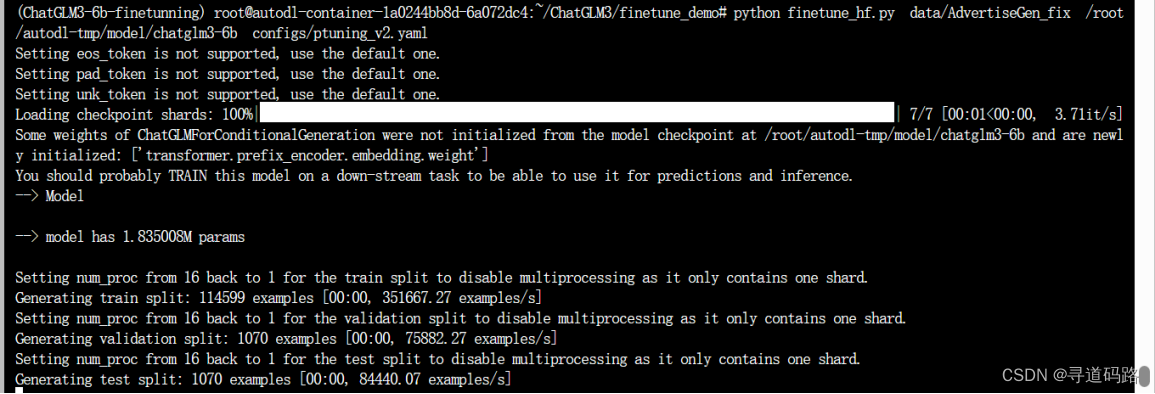
进入 finetune_demo目录
使用命令行进行高效微调,在configs下有多种微调的配置,我们使用 p-tuning v2进行微调;主要修改本地的/chatglm3-6b模型地址
cd finetune_demo
python finetune_hf.py data/AdvertiseGen_fix /root/autodl-tmp/model/chatglm3-6b configs/ptuning_v2.yaml
执行如下:
2、从保存点进行微调
如果按照上述方式进行训练,每次微调都会从头开始,如果你想从训练一半的模型开始微调,你可以加入第四个参数,这个参数有两种传入方式:
yes, 自动从最后一个保存的 Checkpoint开始训练
XX, 断点号数字 例 600 则从序号600 Checkpoint开始训练
例如,这就是一个从最后一个保存点继续微调的示例代码
cd finetune_demo
python finetune_hf.py data/AdvertiseGen_fix /root/autodl-tmp/model/chatglm3-6b configs/ptuning_v2.yaml yes
七、推理验证
最后,在推理验证环节,我们利用微调后的模型进行了实际推理,以检验微调效果。通过指定合适的prompt,可以引导模型生成符合预期的输出,进一步验证了微调模型在特定任务上的适用性。
使用微调的数据集进行推理(在 inference_hf.py 文件中有封装推理验证的接口)
1、修改模型地址
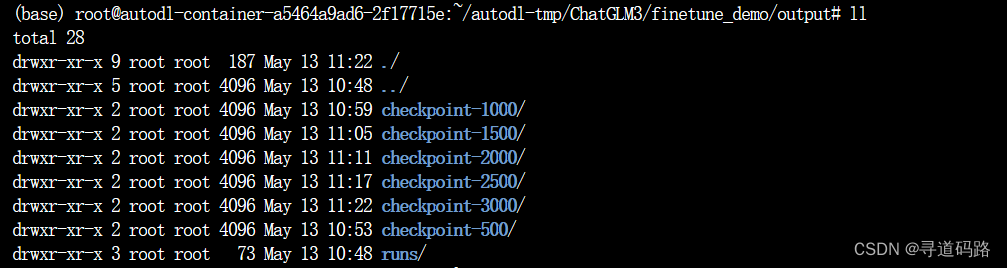
在完成微调任务之后,我们可以查看到 output 文件夹下多了很多个checkpoint-*的文件夹,这些文件夹代表了训练的轮数。 我们选择最后一轮的微调权重,并使用inference进行导入。
说明:对于 LORA 和 P-TuningV2 官方没有合并训练后的模型,而是在adapter_config.json 中记录了微调型的路径;因此需要先修改基础模型的地址,直接修改dapter_config.json中的基础模型地址(在adapter_config.json 中记录了微调型的路径,如果原始模型位置发生更改,要修改adapter_config.json中base_model_name_or_path的路径)。
注意、注意、注意: 如果没有adapter_config.json 不用修改了
inference_hf.py
from typing import Union, Path, Tuple # 导入所需的类型注解# 定义一个函数,它接受模型目录的路径和是否信任远程代码的标志,
# 并返回一个包含模型和分词器的元组。
def load_model_and_tokenizer(model_dir: Union[str, Path], # 模型目录的路径,可以是字符串或Path对象。trust_remote_code: bool = True # 是否信任远程代码的布尔值,默认为True。
) -> tuple[ModelType, TokenizerType]: # 返回值是一个元组,包含模型(ModelType)和分词器(TokenizerType)。# 使用内部函数_resolve_path解析model_dir参数,确保它是一个完整的文件系统路径。model_dir = _resolve_path(model_dir)# 检查model_dir路径下是否存在名为adapter_config.json的文件。if (model_dir / 'adapter_config.json').exists():# 如果存在adapter_config.json,加载适配器模型。model = AutoPeftModelForCausalLM.from_pretrained(model_dir, # 模型目录路径。trust_remote_code=trust_remote_code, # 是否信任远程代码。device_map='auto' # 设备映射设置为'auto',自动决定如何将模型分配到设备上。)# 从模型的适配器配置中获取分词器目录。tokenizer_dir = model.peft_config['default'].base_model_name_or_pathelse:# 如果不存在adapter_config.json,加载标准的预训练模型。model = AutoModelForCausalLM.from_pretrained(model_dir, # 模型目录路径。trust_remote_code=trust_remote_code, # 是否信任远程代码。device_map='auto' # 设备映射设置为'auto'。)# 使用模型目录作为分词器目录。tokenizer_dir = model_dir# 加载与模型对应的分词器。tokenizer = AutoTokenizer.from_pretrained(tokenizer_dir, # 分词器目录。trust_remote_code=trust_remote_code # 是否信任远程代码。)# 返回一个包含模型和分词器的元组。return model, tokenizer
检查训练输出
2、开始模型推理
python inference_hf.py output/checkpoint-3000/ --prompt "鱼尾裙"
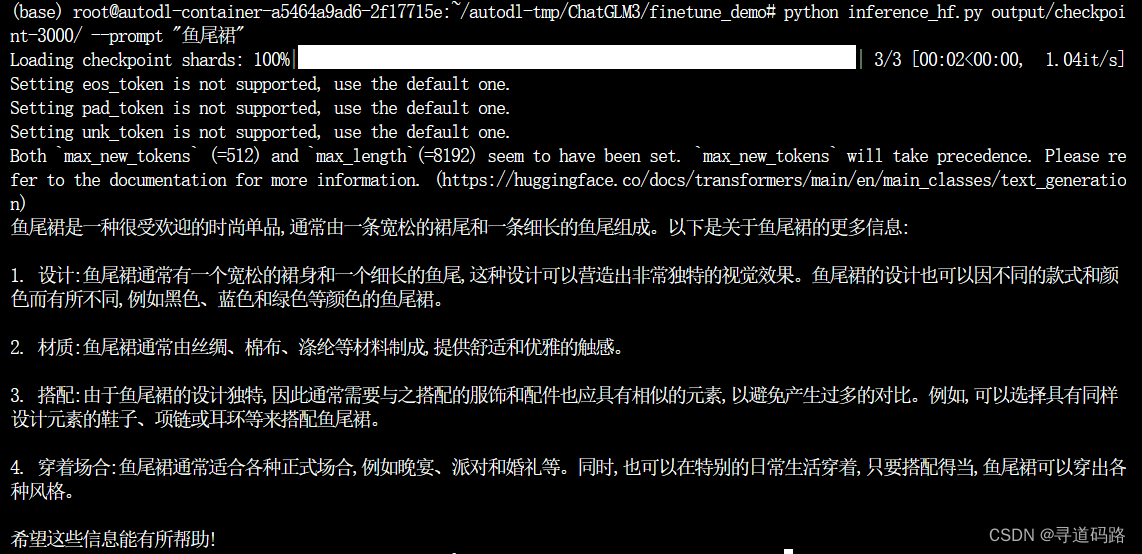
根据内容可以看到,回答基本正确,响应结果都是来源于原数据集中的内容。
总结
通过本文的深度解析,我们希望读者能够洞察到大语言模型微调过程中的每一个关键步骤,从而更加自信地应对各种自然语言处理挑战。P-Tuning V2技术以其独特的优势,为ChatGLM3的对话能力提升提供了强大助力,标志着我们在人工智能对话系统领域又向前迈进了一大步。未来,随着技术的不断进步和创新,我们期待着更多突破性的成果,以推动人工智能与人类交流的界限不断拓宽。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
相关文章:
AI大模型探索之路-训练篇23:ChatGLM3微调实战-基于P-Tuning V2技术的实践指南
系列篇章💥 AI大模型探索之路-训练篇1:大语言模型微调基础认知 AI大模型探索之路-训练篇2:大语言模型预训练基础认知 AI大模型探索之路-训练篇3:大语言模型全景解读 AI大模型探索之路-训练篇4:大语言模型训练数据集概…...
)
掌握核心概念:Java高级面试难题精解(一)
Java 高级面试问题及答案 问题1: 在Java中,什么是泛型擦除?为什么需要它? 答案: 泛型擦除是Java编译器的一个特性,它在运行时移除泛型类型信息,以确保类型安全。Java的泛型是在J2SE 1.5中引入的ÿ…...

Nagle算法
Nagle算法简介 Nagle算法主要是避免发送小的数据包,要求TCP连接上最多只能有一个未被确认的小分组,在该分组的确认到达之前不能发送其他的小分组。 在默认的情况下,Nagle算法是默认开启的,Nagle算法比较适用于发送方发送大批量的小数据&…...

MPLS小实验
实验图: 实验要求: 要求使用MPLS技术,将实验通,并在实验结束后使用命令:tracert -v -a 看是否基于标签进行转发。 如上:在每台路由器上都有两个环回,一个用于模拟用户网段,一个用于M…...

MongoDB聚合运算符:$week
MongoDB聚合运算符:$week 文章目录 MongoDB聚合运算符:$week语法使用举例 $week聚合运算符返回指定日期日期为一年中第几周的数字值为0到53之间。周从周日开始,第1周从一年的第一个周日开始。一年中第一个星期日之前的日期为第0周。这和 str…...
【Linux】如何定位客户端程序的问题
文章目录 1 客户端程序和服务端程序的差别2 问题类型2.1 崩溃(crash)2.2 CPU高2.3 内存高2.4 线程卡死 3 总结 1 客户端程序和服务端程序的差别 客户端程序是运行在终端上,通常都会与业务系统共存,而服务端程序通常会运行在单独的节点上,或者…...

AI学习指南数学工具篇-PCA基础知识
AI学习指南数学工具篇-PCA基础知识 1. PCA是什么? PCA,即主成分分析(Principal Component Analysis),是一种常用的数据降维技术。它通过线性变换将原始数据投影到一个新的坐标系中,旨在找到数据中的“主成…...

《系统架构设计师教程(第2版)》第4章-信息安全技术基础知识-02-信息加密技术
文章目录 1. 信息加密技术1.1 数据加密1.2 对称密钥加密算法1)数据加密标准(DES)2)三重DES(Triple-DES)3)国际数据加密算法(IDEA)4)高级加密标准(AES…...

Leetcode 404:左叶子之和
给定二叉树的根节点 root ,返回所有左叶子之和。 思路:遍历树,寻找左叶子节点; 如果判断是左叶子节点,就更新sum。 public static int sumOfLeftLeaves(TreeNode root){int sum0;sumcompute(root,sum);return sum;}/…...
Keil问题解决:结构体数组初始化,初始化后的值不是目标值
省流:使用的编译器为compiler version 6,切换为compiler version 5 如果缺少编译器,请参考:Keil手动安装编译器V5版本 结构体定义: typedef struct _TASK_COMPONENTS {uint8_t Run; // 程序运行标…...

C++set关联式容器
Cset 1. 关联式容器 vector、list、deque、forward_list(C11)等STL容器,其底层为线性序列的数据结构,里面存储的是元素本身,这样的容器被统称为序列式容器。而map、set是一种关联式容器,关联式容器也是用来存储数据的࿰…...
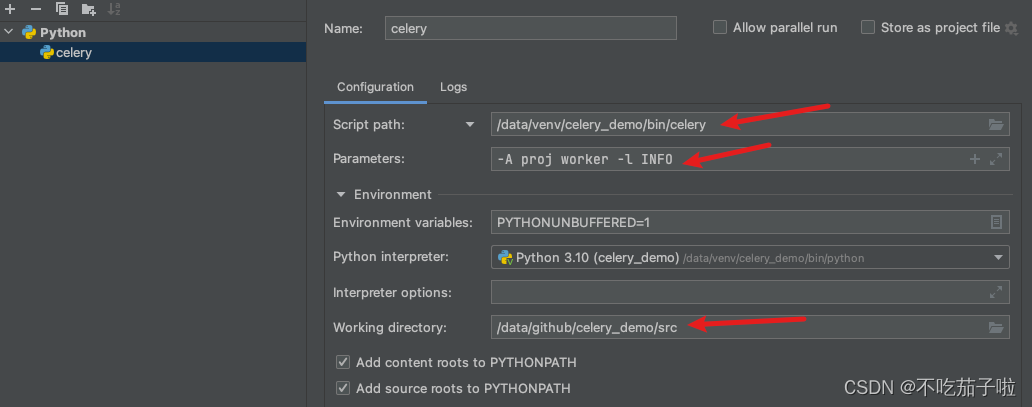
Celery Redis 集群版连接和PyCharm启动配置
目录 使用Redis cluster版作为broker原因 PyCharm配置 使用Redis cluster版作为broker 在celery5及其之前版本,需要配置如下才可行 celery_app.conf.update( broker_transport_options{“global_keyprefix”: “{celery}:”}, ) 原因 https://github.com/celery/…...

「AIGC算法」readLink实现url识别pdf、网页标题和内容
本文主要介绍AIGC算法,readLink实现url识别pdf、html标题和内容 一、设计思路 识别url是pdf或者网页网页处理逻辑,使用cheerio解析网页PDF处理逻辑,使用pdf-parse解析PDF文件自定义的函数来提取标题和内容二、可执行核心代码 const express = require("express")…...

Vue3+ts(day06:路由)
学习源码可以看我的个人前端学习笔记 (github.com):qdxzw/frontlearningNotes 觉得有帮助的同学,可以点心心支持一下哈(笔记是根据b站上学习的尚硅谷的前端视频【张天禹老师】,记录一下学习笔记,用于自己复盘,有需要学…...

springboot集成dubbo实现微服务系统
目录 1.说明 2.示例 3.总结 1.说明 dubbo官网:https://cn.dubbo.apache.org/zh-cn/ Apache Dubbo 是一款 RPC 服务开发框架,用于解决微服务架构下的服务治理与通信问题,支持多种语言,官方提供了 Java、Golang 等多语言 SDK 实…...
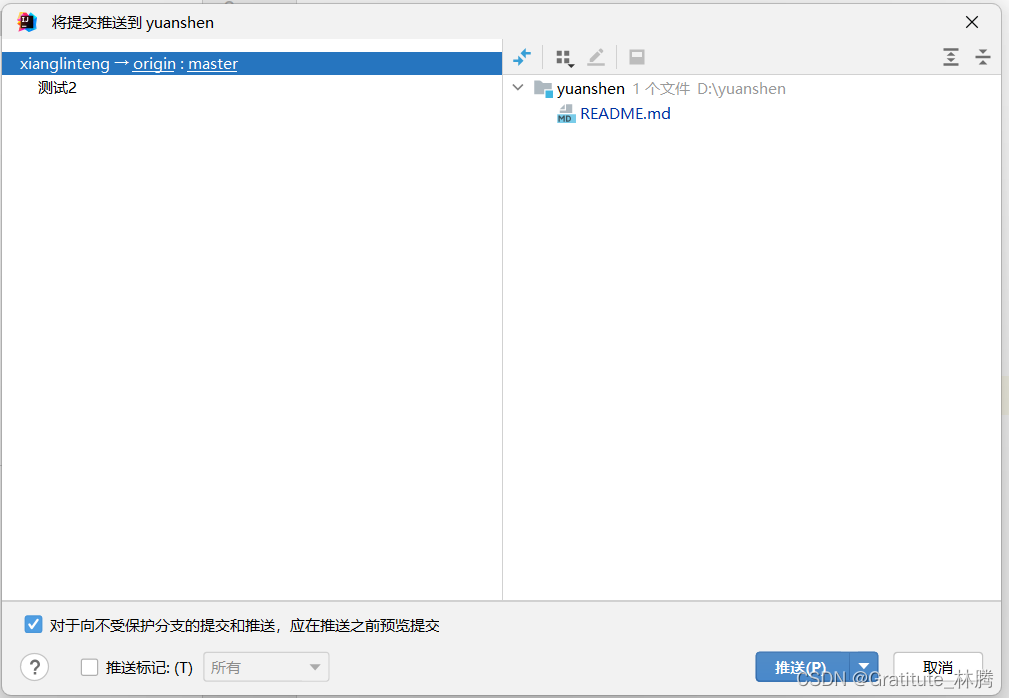
idea使用gitee基本操作流程
1.首先,每次要写代码前,先切换到自己负责的分支 点击签出。 然后拉取一次远程master分支,保证得到的是最新的代码。 写完代码后,在左侧栏有提交按钮。 点击后,选择更新的文件,输入描述内容(必填…...

Docker容器里面有什么东西?
2024年5月15日,周三下午 Docker 容器内部包含了一个运行的应用程序及其依赖环境。当你创建一个 Docker 容器时,你可以指定容器应该运行哪个镜像。这个镜像是由一系列层组成的,每一层包含了一些文件和目录。当你运行这个镜像时,Doc…...

vue基础+高级用法
一、vue基础用法 mvvm的了解/认知 语义化模板mvc - model view controllermvvm - model view view-model vue是如何利用mvvm思想进行开发 双向数据绑定 花括号,构建了数据与视图的双向绑定通过视图绑定事件,来处理数据 生命周期-vue示例 建立&…...

鸿蒙应用布局ArkUI【基础运用案例】
布局基础运用案例 平级导航的复合网格视图 平级导航的复合网格视图常出现在同时展示多种不同内容的界面。 例如,市场类应用作为典型的平级导航,其首页不同板块采用了不同布局能力。 标题栏与搜索栏:因元素单一、位置固定在顶部,…...
GD32F103RCT6/GD32F303RCT6-UCOSIII底层移植(1)工程建立
本文章基于兆易创新GD32 MCU所提供的2.2.4版本库函数开发 后续项目主要在下面该专栏中发布: 手把手教你嵌入式国产化_不及你的温柔的博客-CSDN博客 感兴趣的点个关注收藏一下吧! 电机驱动开发可以跳转: 手把手教你嵌入式国产化-实战项目-无刷电机驱动&am…...

【亲测免费】 DXF轨迹图转G代码工具:高效、精准的数控编程利器
DXF轨迹图转G代码工具:高效、精准的数控编程利器 【下载地址】DXF轨迹图转G代码工具介绍 DXF轨迹图转G代码工具介绍本仓库提供了一个资源文件,用于将DXF格式的轨迹图转换为G代码 项目地址: https://gitcode.com/open-source-toolkit/528cd 项目介…...

从决策树到XGBoost:核心原理、目标函数与工程优化全解析
1. 从“头发长短”到“预测房价”:决策树的灵魂与回归树的诞生很多朋友第一次接触XGBoost,或者更广义的树模型时,都会被一堆公式和术语劝退。什么信息增益、基尼系数、正则项、二阶泰勒展开……看几篇博客,感觉每篇都在自说自话&a…...

告别混乱!Flink指标报告选型指南:Graphite、InfluxDB、Prometheus、StatsD到底怎么选?
Flink监控体系选型实战:Graphite、InfluxDB、Prometheus与StatsD深度对比 当Flink集群从测试环境走向生产环境时,监控指标的可视化与分析能力直接关系到系统的稳定性和运维效率。面对Graphite、InfluxDB、Prometheus和StatsD这四种主流指标报告方案&…...

Sparrow比特币钱包:终极桌面安全钱包完全指南
Sparrow比特币钱包:终极桌面安全钱包完全指南 【免费下载链接】sparrow Desktop Bitcoin Wallet focused on security and privacy. Free and open source. 项目地址: https://gitcode.com/gh_mirrors/sparr/sparrow Sparrow比特币钱包是一款专注于安全与隐私…...

如何用Python+Perplexity API实时监控招聘动态,提前48小时锁定新岗?——资深猎头不愿透露的自动化情报系统
更多请点击: https://codechina.net 第一章:Perplexity招聘信息搜索 Perplexity AI 作为一家快速发展的生成式人工智能公司,其招聘动态常通过官方渠道及技术社区实时更新。掌握高效、精准的招聘信息检索方法,是开发者与研究人员了…...

3分钟快速上手:FanControl风扇控制软件的终极静音散热方案
3分钟快速上手:FanControl风扇控制软件的终极静音散热方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

图像采集卡与相机内置采集:架构差异、性能对比与选型指南
1. 项目概述:从“外挂”到“内置”的采集路径之争在视觉系统集成或工业检测项目里,选型阶段总会遇到一个基础但关键的问题:图像采集卡和相机内置的采集功能,到底该用哪个?这可不是一个简单的“哪个更好”的问题&#x…...

NewJob智能求职插件:如何用三色标签系统提升80%投递效率的完整指南
NewJob智能求职插件:如何用三色标签系统提升80%投递效率的完整指南 【免费下载链接】NewJob 一眼看出该职位最后修改时间,绿色为2周之内,暗橙色为1.5个月之内,红色为1.5个月以上 项目地址: https://gitcode.com/GitHub_Trending…...

从静态地图到动态避障:图解ROS中global_costmap与local_costmap如何协同工作
从静态地图到动态避障:图解ROS中global_costmap与local_costmap如何协同工作 在机器人自主导航领域,理解代价地图的工作原理是构建可靠导航系统的关键。想象一下,当人类在陌生城市中导航时,我们会同时参考静态的城市地图和实时观察…...

单片机代码优化实战:从数据类型到算法与数据结构的效率提升
1. 项目概述:为什么单片机代码需要“斤斤计较”?如果你是从PC端或者服务器端开发转过来的朋友,第一次接触单片机编程,可能会觉得处处掣肘。在PC上,我们习惯了动辄几个G的内存,上百G的硬盘,CPU频…...