使用Python实现深度学习模型:自动编码器(Autoencoder)
自动编码器(Autoencoder)是一种无监督学习的神经网络模型,用于数据的降维和特征学习。它由编码器和解码器两个部分组成,通过将输入数据编码为低维表示,再从低维表示解码为原始数据来学习数据的特征表示。本教程将详细介绍如何使用Python和PyTorch库实现一个简单的自动编码器,并展示其在图像数据上的应用。
什么是自动编码器(Autoencoder)?
自动编码器是一种用于数据降维和特征提取的神经网络。它包括两个主要部分:
- 编码器(Encoder):将输入数据编码为低维的潜在表示(latent representation)。
- 解码器(Decoder):从低维的潜在表示重建输入数据。
通过训练自动编码器,使得输入数据和重建数据之间的误差最小化,从而实现数据的压缩和特征学习。
实现步骤
步骤 1:导入所需库
首先,我们需要导入所需的Python库:PyTorch用于构建和训练自动编码器模型,Matplotlib用于数据的可视化。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
步骤 2:准备数据
我们将使用MNIST数据集作为示例数据,MNIST是一个手写数字数据集,常用于图像处理的基准测试。
# 定义数据预处理
transform = transforms.Compose([transforms.ToTensor()])# 下载并加载训练数据
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
步骤 3:定义自动编码器模型
我们定义一个简单的自动编码器模型,包括编码器和解码器两个部分。
class Autoencoder(nn.Module):def __init__(self):super(Autoencoder, self).__init__()# 编码器self.encoder = nn.Sequential(nn.Linear(28 * 28, 128),nn.ReLU(),nn.Linear(128, 64),nn.ReLU(),nn.Linear(64, 32))# 解码器self.decoder = nn.Sequential(nn.Linear(32, 64),nn.ReLU(),nn.Linear(64, 128),nn.ReLU(),nn.Linear(128, 28 * 28),nn.Sigmoid())def forward(self, x):x = self.encoder(x)x = self.decoder(x)return x# 创建模型实例
model = Autoencoder()
步骤 4:定义损失函数和优化器
我们选择均方误差(MSE)损失函数作为模型训练的损失函数,并使用Adam优化器进行优化。
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
步骤 5:训练模型
我们使用定义的自动编码器模型对MNIST数据集进行训练。
num_epochs = 20for epoch in range(num_epochs):for data in train_loader:inputs, _ = datainputs = inputs.view(-1, 28 * 28) # 将图像展平为向量# 前向传播outputs = model(inputs)loss = criterion(outputs, inputs)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
步骤 6:可视化结果
训练完成后,我们可以使用训练好的自动编码器模型对测试数据进行编码和解码,并可视化重建结果。
# 加载测试数据
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=10, shuffle=False)# 获取一些测试数据
dataiter = iter(test_loader)
images, labels = dataiter.next()
images_flat = images.view(-1, 28 * 28)# 使用模型进行重建
outputs = model(images_flat)# 可视化原始图像和重建图像
fig, axes = plt.subplots(nrows=2, ncols=10, sharex=True, sharey=True, figsize=(20, 4))for images, row in zip([images, outputs], axes):for img, ax in zip(images, row):ax.imshow(img.view(28, 28).detach().numpy(), cmap='gray')ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)plt.show()
总结
通过本教程,你学会了如何使用Python和PyTorch库实现一个简单的自动编码器(Autoencoder),并在MNIST数据集上进行训练和测试。自动编码器是一种强大的工具,能够有效地进行数据降维和特征学习,广泛应用于图像处理、异常检测、数据去噪等领域。希望本教程能够帮助你理解自动编码器的基本原理和实现方法,并启发你在实际应用中使用自动编码器解决数据处理问题。
相关文章:
)
使用Python实现深度学习模型:自动编码器(Autoencoder)
自动编码器(Autoencoder)是一种无监督学习的神经网络模型,用于数据的降维和特征学习。它由编码器和解码器两个部分组成,通过将输入数据编码为低维表示,再从低维表示解码为原始数据来学习数据的特征表示。本教程将详细介…...

数据结构--树与二叉树--编程实现以孩子兄弟链表为存储结构递归求树的深度
数据结构–树与二叉树–编程实现以孩子兄弟链表为存储结构递归求树的深度 题目: 编程实现以孩子兄弟链表为存储结构,递归求树的深度。 ps:题目来源2025王道数据结构 思路: 从根结点开始 结点 N 的高度 max{N 孩子树的高度 1, N兄弟树的…...
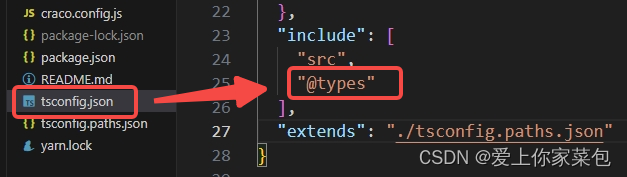
Property xxx does not exist on type ‘Window typeof globalThis‘ 解决方法
问题现象 出现以上typescript警告,是因为代码使用了window的非标准属性,即原生 window 对象上不存在该属性。 解决办法 在项目 根目录 或者 src目录 下新建 xxx.d.ts 文件,然后进行对该 属性 进行声明即可。 注意:假如xxx.d.ts文…...

BOM..
区别:...

rust的版本问题,安装问题,下载问题
rust的版本、安装、下载问题 rust版本问题, 在使用rust的时候,应用rust的包,有时候包的使用和rust版本有关系。 error: failed to run custom build command for pear_codegen v0.1.2 Caused by: process didnt exit successfully: D:\rus…...

SDUT 链表9-------7-9 sdut-C语言实验-约瑟夫问题
7-9 sdut-C语言实验-约瑟夫问题 分数 20 全屏浏览 切换布局 作者 马新娟 单位 山东理工大学 n个人想玩残酷的死亡游戏,游戏规则如下: n个人进行编号,分别从1到n,排成一个圈,顺时针从1开始数到m,数到m的…...

Anthropic绘制出了大型语言模型的思维图:大型语言模型到底是如何工作
今天,我们报告了在理解人工智能模型的内部运作方面取得的重大进展。我们已经确定了如何在 Claude Sonnet(我们部署的大型语言模型之一)中表示数百万个概念。这是对现代生产级大型语言模型的首次详细了解。这种可解释性的发现将来可以帮助我们…...

网络工程师练习题
网络工程师 随着company1网站访问量的不断增加,公司为company1设立了多台服务器。下面是不同用户ping网站www.company1.com后返回的IP地址及响应状况,如图8.58所示。从图8.58可以看出,域名www.company1.com对应了多个IP地址,说明在图8.59所示的NDS属性中启用了循环功能。在…...
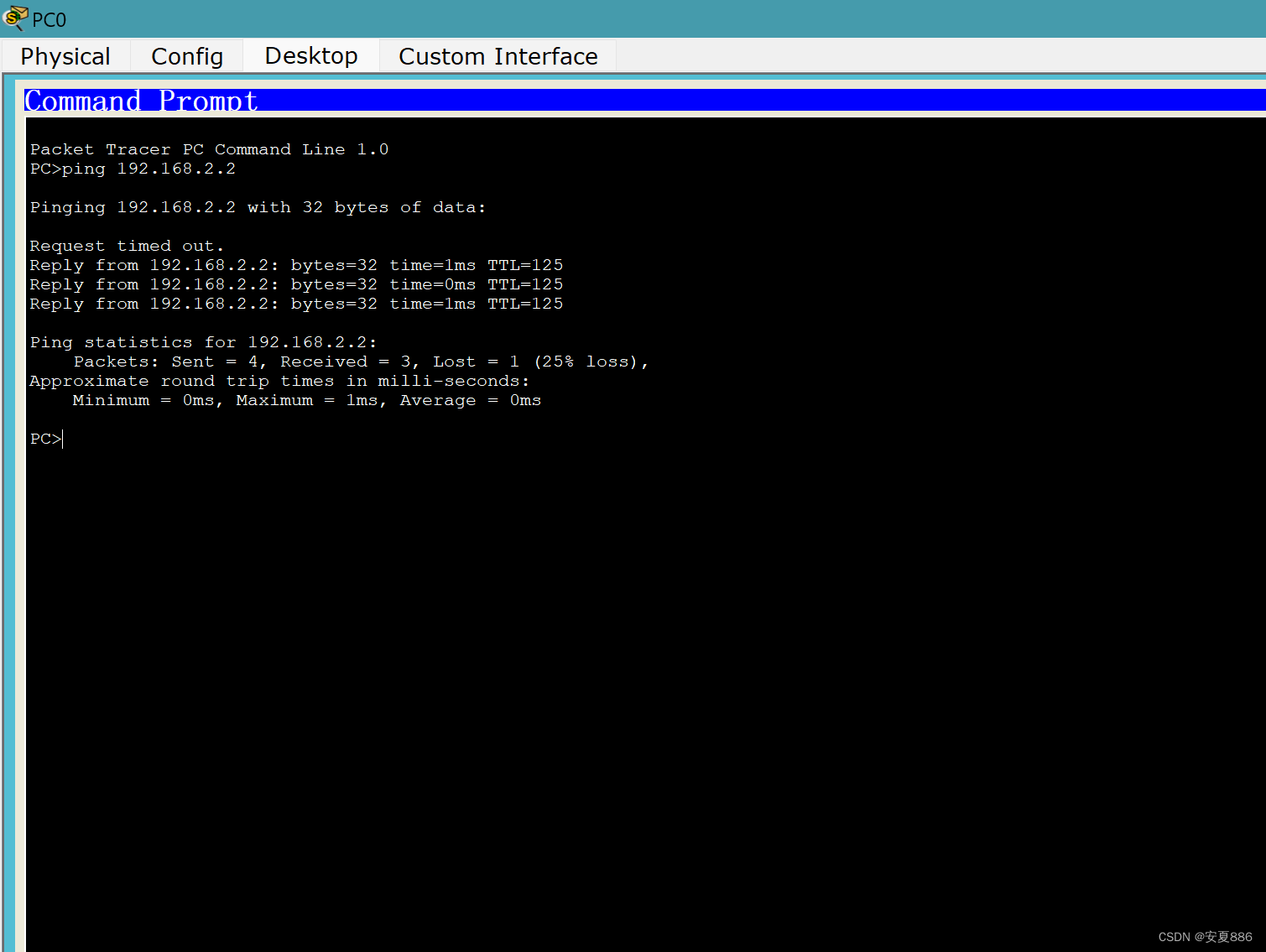
思科模拟器--03.RIP协议路由--24.5.17
1.首先,先创建两个个人电脑:PC0和PC1和三个路由器:R1,R2和R3. (诀窍:建议用文本框标注一下重要简短的内容; 目的:降低失误概率,提高成功率!) 第0步:(个人电脑的IP,子网掩码和默认网关配置) 接着,可以先将个人电脑的IP和网关先配置一下…...

当实时互动遇上新硬件:GIAC 全球互联网架构大会「新硬件」专题论坛
今年,被广泛预见为 AI 技术关键转折点的年份,生成式 AI 热度不断攀升,应用落地加速深化。在这个过程中,为了适应日益复杂的业务需求,背后的架构也将迎来新一轮的革新。 而在这场技术变革的浪潮中,GIAC 全球…...
)
赶紧收藏!2024 年最常见 20道 Redis面试题(三)
上一篇地址:赶紧收藏!2024 年最常见 20道 Redis面试题(二)-CSDN博客 五、Redis的持久化机制是什么? Redis 是一个高性能的键值存储系统,支持多种类型的数据结构,如字符串、哈希、列表、集合、…...
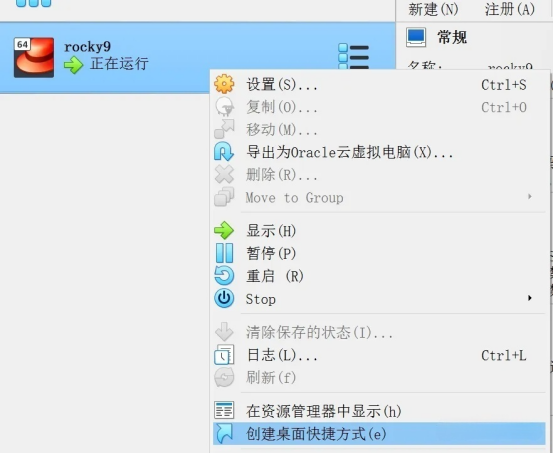
VMware 和 VirtualBox开机自启指定虚拟机详细教程
VMware上虚拟机随宿主机开机自启 1. 设置自动启动虚拟机 网上教程旧版的,界面和新版有所差异。17版本设置如下:VMware Workstation工作台 -> 文件 -> 配置自动启动虚拟机 -> 按顺序选择需要启动的虚拟机 VMWare17配置自动启动虚拟机提示&…...

note-网络是怎样连接的2 协议栈和网卡
助记提要 协议栈的结构协议栈创建连接的实际过程协议栈发送数据包的2个判断依据TCP确认数据收到的原理断开连接的过程路由表和ARPMAC地址的分配MAC模块的工作通过电信号读取数据的原理网卡和协议栈接收包的过程ICMPUDP协议的适用场景 2章 用电信号传输TCP/IP数据 探索协议栈和…...

ros学习之路径规划
一、全局路径规划中的地图 1、栅格地图(Grid Map)2、概率图(Cost Map)3、特征地图(Feature Map4、拓扑地图(Topological Map) 二、全局路径规划算法 1、Dijkstra 算法 2、最佳路径优先搜索算…...

Qt 顺序容器的详细介绍
一.顺序容器介绍 Qt 中的顺序容器包括 QVector、QList、QLinkedList 和 QStack。这些容器都提供了类似于 C STL 中的容器的功能,但是在 Qt 中提供了更多的功能和接口。 二.具体介绍 1.QVector QVector:是一个动态数组,可以在其末尾快速插入…...
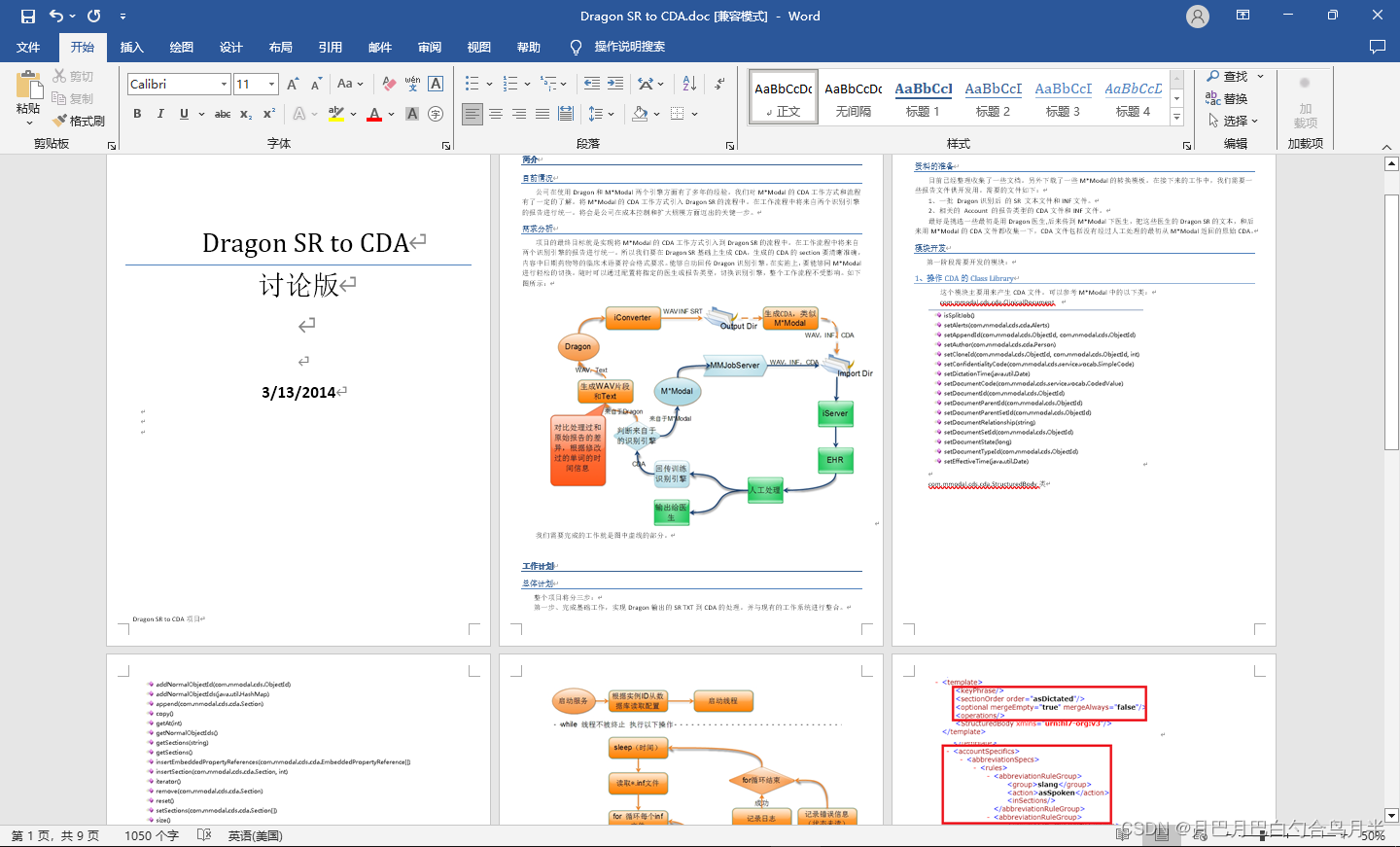
基于语音识别的智能电子病历(三)之 M*Modal
讨论“基于语音识别的智能电子病历”,就绕不开 Nuance 和 M*Modal。这2个公司长时间的占据第一和第二的位置。下面介绍一下M*Modal。 这是2019年的一个新闻“专业医疗软件提供商3M公司为自己购买了一份圣诞礼物,即M*Modal IP LLC的医疗技术业务…...

理解Apache Storm的实际用途和应用场景
学习目标: 理解Apache Storm的实际用途和应用场景 学习内容: 1. 实时数据处理和分析 1.1 实时日志分析 公司可以使用Storm来实时处理和分析服务器日志。例如,电商网站可以实时监控用户行为日志,以检测异常活动(如DD…...
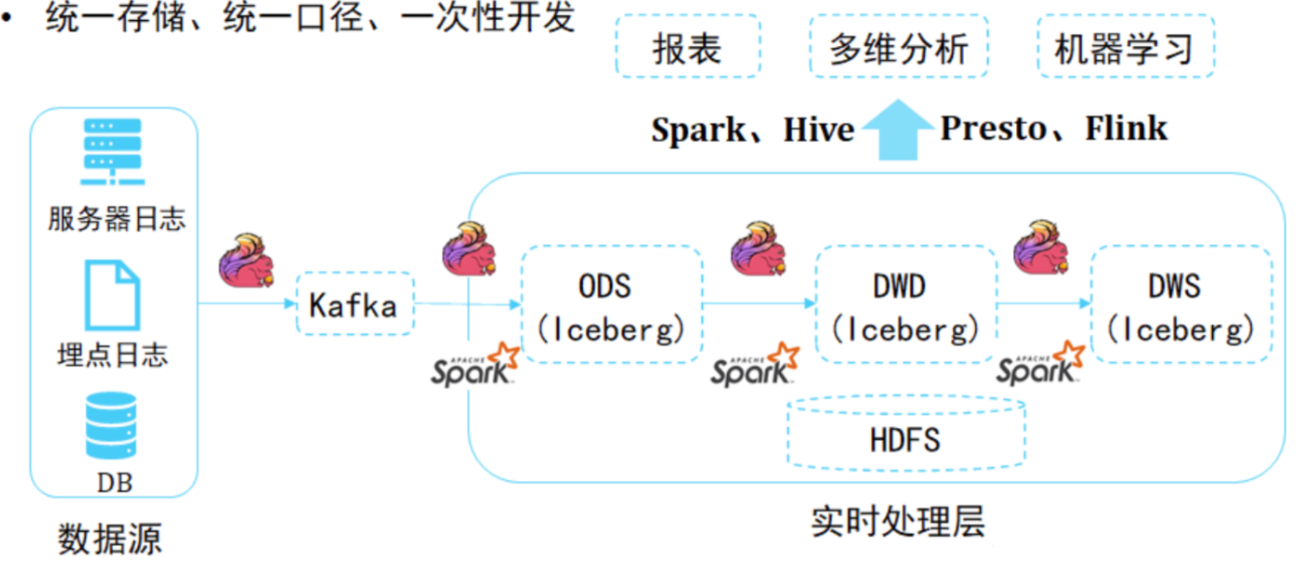
【iceberg】数据湖与iceberg调研与实战
文章目录 一. 为什么现在要强调数据湖1. 大数据架构发展历史2. Lambda架构与kappa架构3. 数据湖所具备的能力 二. iceberg是数据湖吗1. iceberg的诞生2. iceberg设计之table format从如上iceberg的数据结构可以知道,iceberg在数据查询时,1.查找文件的时间…...
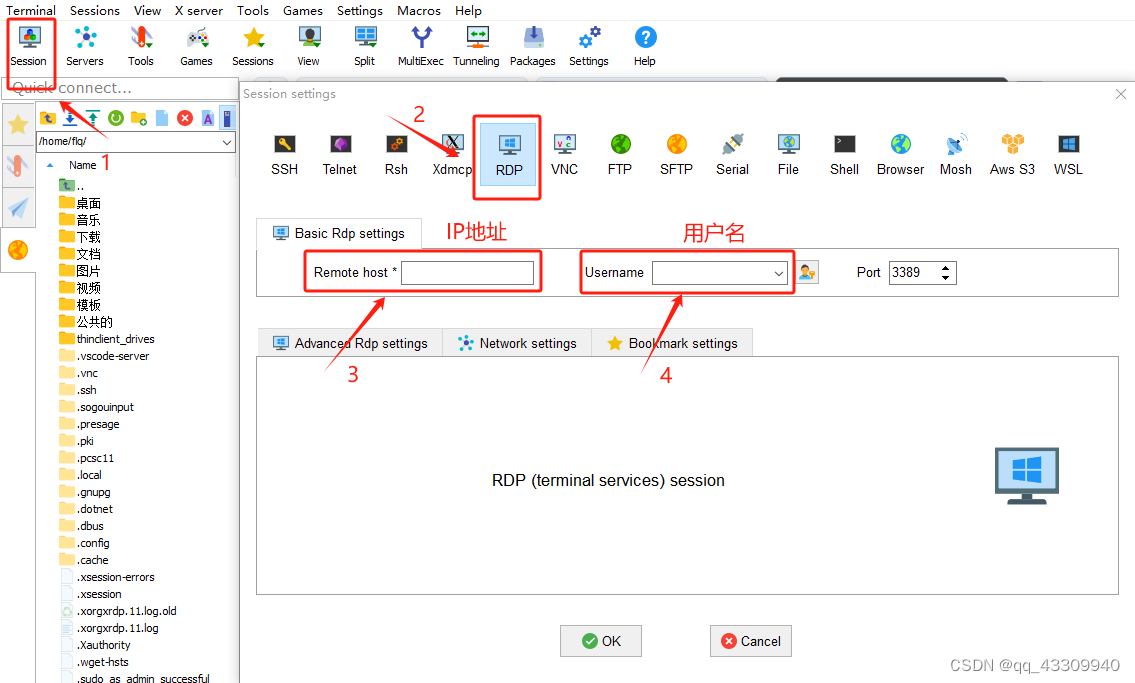
xrdp多用户多控制界面远程控制
1、无桌面安装桌面(原本有ubuntu桌面的可以直接跳过这一步) Gnome 与 xfce 相比,xfce 由于其轻巧,它可以安装在低端台式机上。Xfce 优雅的外观,增强了用户体验,它对用户非常友好,性能优于其他桌…...

git会忽略我们工作改动中的大小写
在我们日常git工作中,我们对于文件名字的大小写修改正常是不会被git记录的 这是因为默认情况下git是不区分大小写的 这会导致一个问题,由于我们修改了文件名字的大小写,而对于文件之间相互依赖的导入代码没有对应修改 如果我们此时本地推送…...

跨平台鼠标控制库ez-cursor-free:原理、实现与自动化实战
1. 项目概述与核心价值如果你是一名开发者,尤其是经常需要处理跨平台UI自动化、游戏脚本或者桌面应用交互的开发者,那么你一定对“鼠标控制”这个基础但又充满细节的环节感到过头疼。不同的操作系统(Windows, macOS, Linux)提供了…...

嵌入式事件驱动框架Curtroller:模块化设计提升开发效率
1. 项目概述与核心价值最近在嵌入式开发社区里,一个名为“Curtroller”的项目引起了我的注意。这个项目由开发者KenWuqianghao在GitHub上开源,名字本身就是一个巧妙的组合——“Curt”(可能是“Current”电流的缩写或“Control”控制的变体&a…...

DeepLake:AI原生数据湖统一管理多模态数据与向量嵌入
1. 项目概述:当数据湖遇上AI向量化如果你正在构建一个AI应用,无论是RAG检索增强生成系统、多模态模型训练,还是复杂的语义搜索,数据管理环节的复杂性往往会让你头疼不已。传统的文件系统、数据库,甚至是对象存储&#…...

MCP-Commander:让AI助手操作本地文件与命令行的智能接口
1. 项目概述:一个连接思维与执行的智能接口最近在折腾AI工作流的时候,发现了一个挺有意思的项目,叫nmindz/mcp-commander。乍一看这个名字,可能有点摸不着头脑,但如果你正在尝试让大型语言模型(LLM…...

Golioth Firmware SDK:物联网设备连接与管理的开源解决方案
1. 项目概述:Golioth Firmware SDK 是什么?如果你正在开发物联网设备,尤其是那些需要稳定连接到云端、进行远程管理、固件更新和数据同步的设备,那么你一定对“设备管理”和“连接复杂性”这两个词深有体会。自己从头搭建一套稳定…...


【作品集】OpenClaw-AgentOps企业级多智能体贵金属交易分析平台
项目名称:OpenClaw-AgentOps 企业级多智能体贵金属交易分析平台 展示方式:保留原有项目架构图,同时加入系统真实页面切片,用“设计图 实物图”的方式完整展示项目。1. 项目一句话介绍OpenClaw-AgentOps 是一个面向贵金属交易研究…...

树莓派BlueZ源码编译安装与蓝牙协议栈深度配置指南
1. 项目概述与背景 如果你手头有一块树莓派,并且想用它来玩点物联网或者智能硬件项目,蓝牙功能几乎是绕不开的一环。无论是连接一个BLE温湿度传感器读取数据,还是控制一个蓝牙音箱,底层都需要一个稳定、功能完整的蓝牙协议栈来支…...

在视频剪辑工作流中集成Taotoken大模型以辅助创意构思
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在视频剪辑工作流中集成Taotoken大模型以辅助创意构思 视频创作的前期策划阶段,尤其是分镜头脚本构思和文案草稿撰写&a…...

Arduino程序心脏:从setup初始化到loop循环的实战解析
1. Arduino程序的双引擎:setup与loop初探 第一次接触Arduino编程时,很多人会被它独特的程序结构所吸引。与传统编程不同,Arduino程序没有复杂的main函数入口,而是由两个看似简单的函数构成整个程序的骨架——这就是setup()和loop(…...