【iceberg】数据湖与iceberg调研与实战
文章目录
- 一. 为什么现在要强调数据湖
- 1. 大数据架构发展历史
- 2. Lambda架构与kappa架构
- 3. 数据湖所具备的能力
- 二. iceberg是数据湖吗
- 1. iceberg的诞生
- 2. iceberg设计之table format
- 从如上iceberg的数据结构可以知道,iceberg在数据查询时,1.查找文件的时间复杂度至少是O(1),2. 加上列统计信息,能够很好的实现物理层面的文件裁剪。
- 3. iceberg 特性
- 4. 其他数据湖框架的对比
- 三. iceberg实战
- 1. 集成iceberg到flink
- 2. 管理iceberg元数据
- 2.1. java api管理iceberg的catalog
- 2.2. 通过flink sql操作iceberg的元数据
- 3. 通过flink将数据入湖--集成到chunjun
- 4. 通过flink 对数据湖进行数据分析--集成到chunjun
- 5. 小结
- 6. flink with iceberg 未来的规划
- 7. 接下来的探索
一. 为什么现在要强调数据湖
1. 大数据架构发展历史
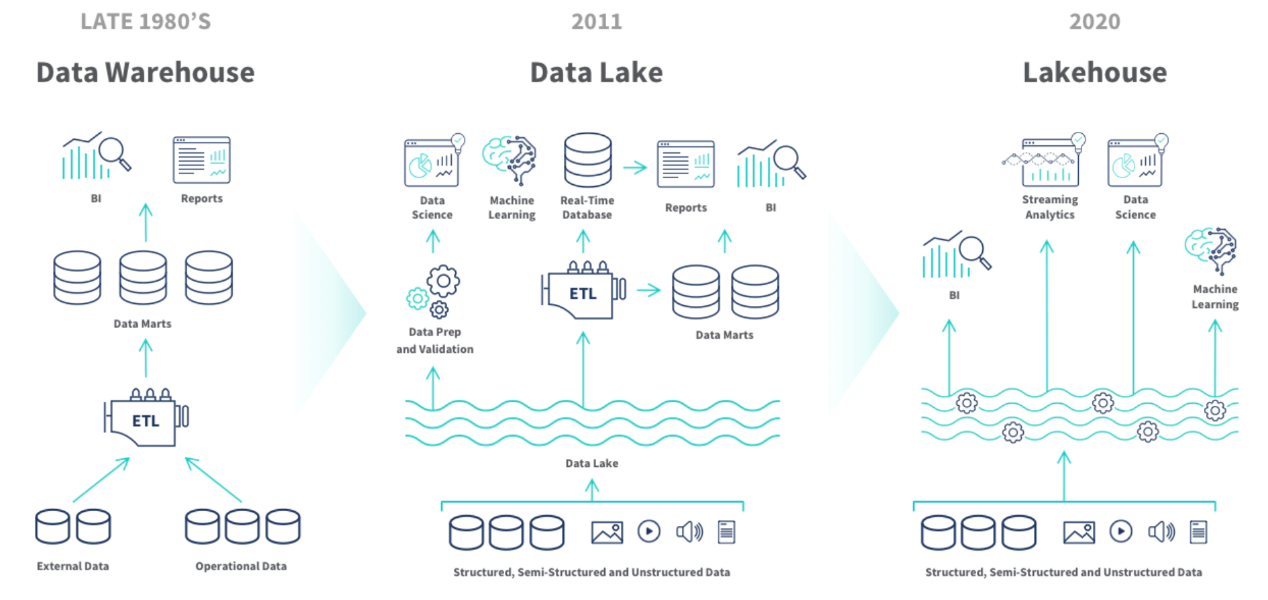
- 数据仓库:加载各个数据源到HIVE、HBASE等;
- 数据湖:数据入湖->再建仓(多中数据源)、或ETL;
- 湖仓一体:数据入湖、湖上建仓。离线实时数据使用同一批数据。
大数据整体的发展路径是:
向着统一存储、统一口径、一次性开发。
统一存储:只有一个存储,消除数据冗余,提高数据质量,更低的存储成本。
统一口径:离线、实时、ad-hoc、机器学习都可以使用同一个数据源,数据治理简单。
一次性开发:多次使用,节约计算成本。
注意:
缺点:将传统数据仓库迁移到湖仓的过程是耗时且昂贵的。
2. Lambda架构与kappa架构
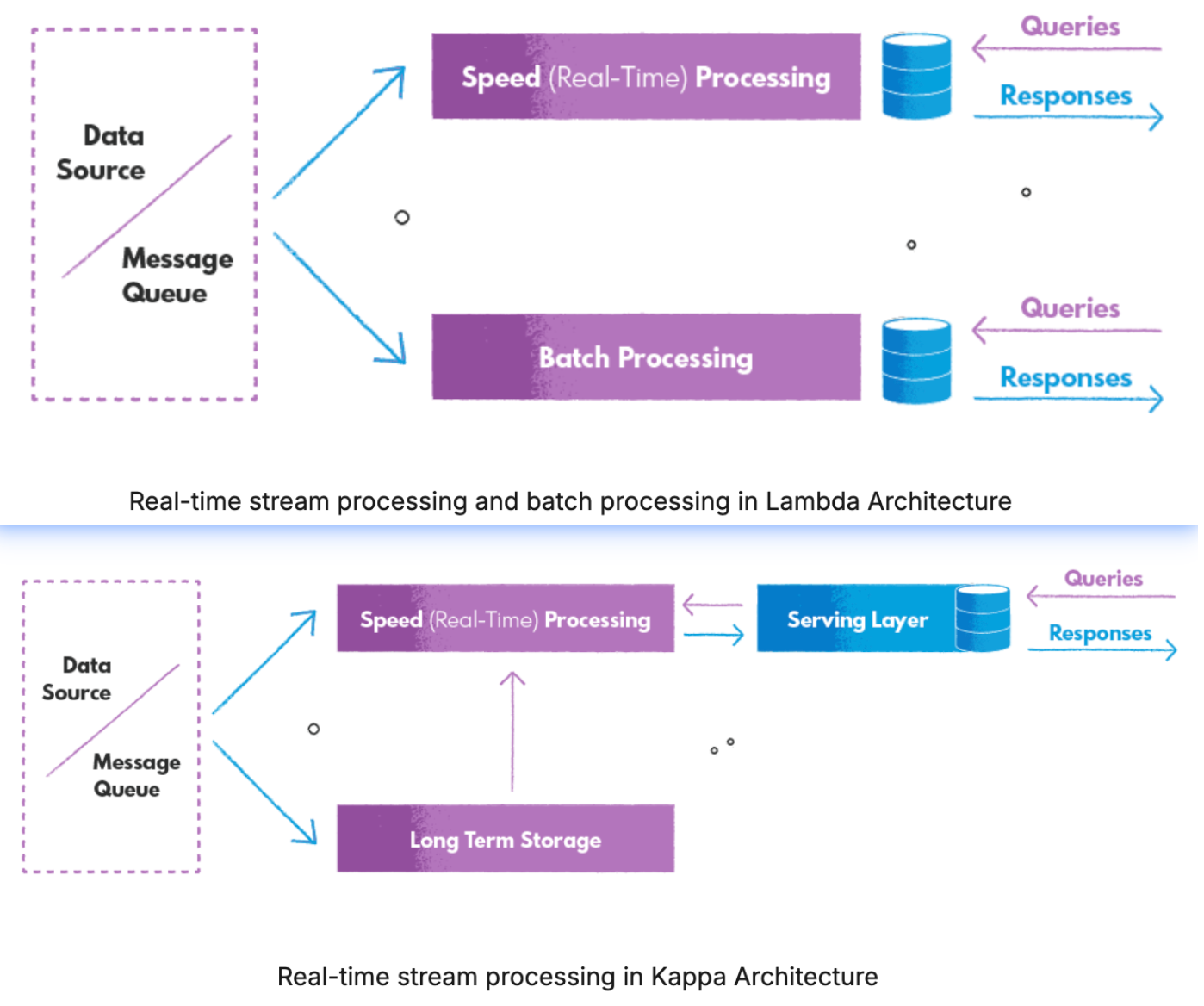
lambda架构:
- 复杂性:分为速度层批层;流批不同的技术,维护两套不同的代码库、工具,维护成本很高
- 流、批分离:处理相同数据出现不一致的结果;
- 延迟:流等批,增加延迟。(CDC可以解决)
kappa架构:流批一体(典型的kafka实时数仓)
- 数据回溯能力弱:面对更复杂的数据分析时,要将DWD和DWS层的数据写入到ClickHouse、ES、MySQL或者是Hive里做进一步分析,这无疑带来了链路的复杂性。
- OLAP分析能力弱:Kafka是一个顺序存储的系统,顺序存储系统是没有办法直接在其上进行OLAP分析的,例如谓词下推这类的优化策略,在顺序存储平台(Kafka)上实现是比较困难的事情。
- 数据时序性受到挑战:Kappa架构是严重依赖于消息队列的,我们知道消息队列本身的准确性严格依赖它上游数据的顺序,但是,消息队列的数据分层越多,发生乱序的可能性越大。
这里可以将kafka改为将starrocks或doris作为实时数仓的存储层以及olap分析层。
提供存储的同时,具备强大的olap分析,以及运行的实时性。
那么:
- 是否存在一种存储技术
既能够支持数据高效的回溯能力,支持数据的更新(ACID),又能够实现数据的批流读写,并且还能够实现分钟级到秒级的数据接入?
- 有没有这样一个架构
既能够满足实时性的需求,又能够满足离线计算的要求,而且还能够减轻开发运维的成本,解决通过消息队列方式构建的Kappa架构中遇到的痛点?
3. 数据湖所具备的能力
数据湖要具备的能力:
- 流批数据处理的统一与能力
- 数据入湖后,支持对数据的修正、数据质量管理的能力。
- 数据的一致性与正确性:ACID事务的能力,元数据的可拓展性。
- 计算引擎与存储引擎的解耦:这样数据湖中间件可以在多个地方应用,即在不同计算引擎(spark、flink、trino、hive、starrocks…)、存储引擎(hdfs、s3)上应用。
二. iceberg是数据湖吗
1. iceberg的诞生

Iceberg是一个面向海量数据分析场景的表格式(Table Format)。
该项目最初是由Netflix公司开发的,目的是解决他们使用巨大的PB级表的长期问题。它于2018年作为Apache孵化器项目开源,并于2020年5月19日从孵化器中毕业。
表格式(Table Format):是对元数据以及数据文件的一种组织方式,处于计算框架(Flink,Spark…)之下,数据文件之上。
我们先回到Netflix 的 Ryan Blue创建Iceberg的原因。
举个hive的窘境:hive表分区天改成小时。
需要如下操作:
- 不能在原表之上直接修改,只能新建一个按小时分区的表,
- 再把数据Insert到新的小时分区表。
- 因为分区字段修改,导致需要修改原表上层的应用的sql,即使通过Rename的命令把新表的名字改为原表。
以上操作上任何一步操作,都会冒着其他地方出现错误的风险。
所以数据的组织方式(表格式)是许多数据基础设施面临挫折和问题的共同原因。
[! Apache Iceberg设计的一个关键考虑是解决各种数据一致性和性能问题,这些问题是Hive在使用大数据时所面临的问题。]
- hive的table state存储在两个地方:分区存储在hive元数据、文件存储在文件系统。
- bucketing(分桶)是由hive的hash实现,(效率不高吗)
- 非 ACID 布局的
唯一原子操作是添加分区- 需要在文件系统中原子地移动对象 ing
- 需要dir_list来plan作业,这会导致 :
- 效率:O(n) 的列表调用,其中 n 是匹配分区的数量。
- 正确性:最终一致性会破坏正确性。
2. iceberg设计之table format
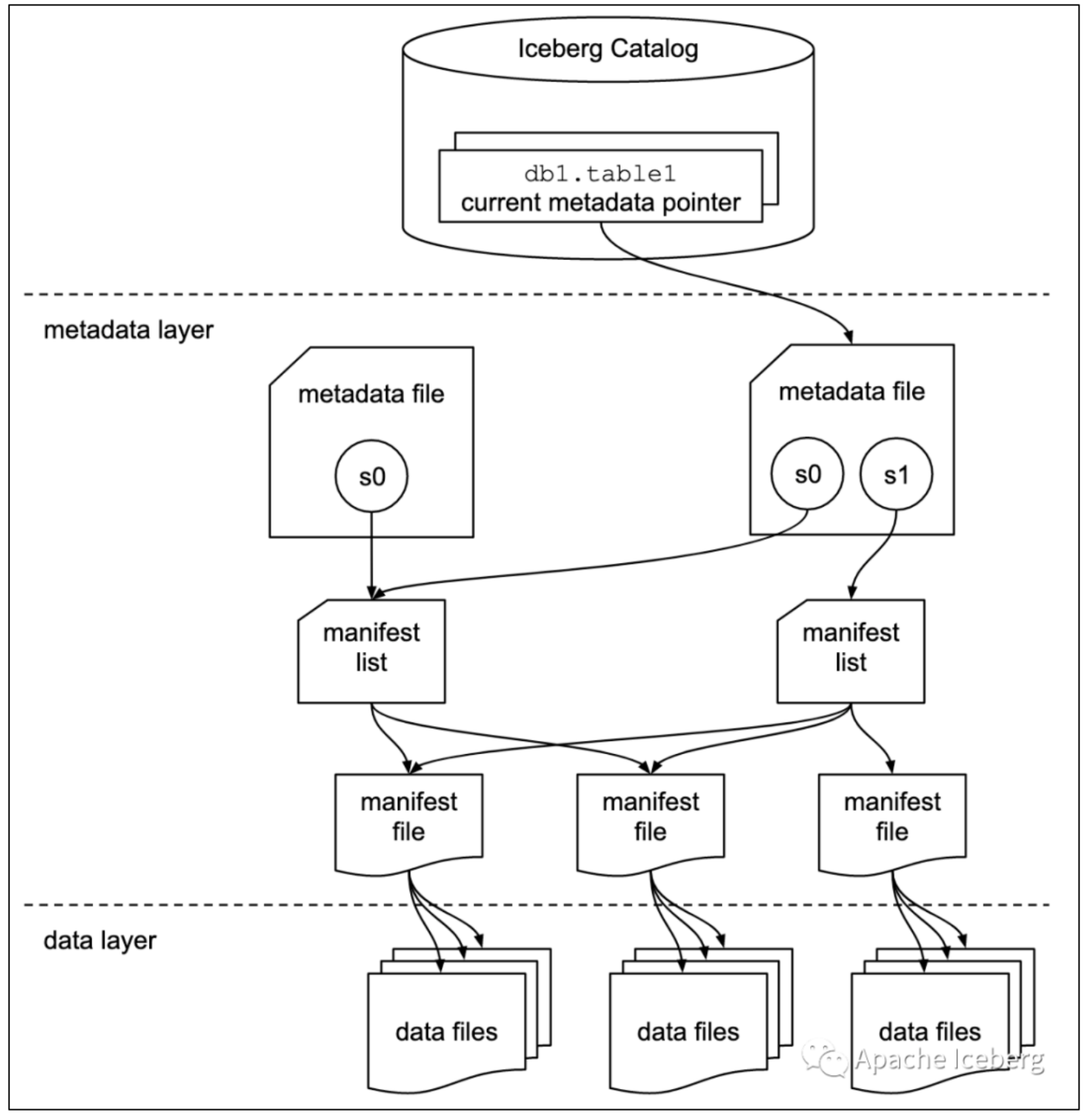
有关存储格式方面,Apache Iceberg 中的一些概念如下:
数据文件 data files
数据文件是Apache Iceberg表真实存储数据的文件,一般是在表的数据存储目录的data目录下,iceberg支持三种格式(parquet、avro、orc)的文件存储。
Iceberg每次更新会产生多个数据文件(data files)。
表快照 Snapshot
快照代表一张表在某个时刻下表的状态。每个快照里面会列出表在某个时刻的所有 data files 列表。
- data files是存储在不同的manifest files里面
- manifest files是存储在一个Manifest list文件里面
- 一个Manifest list文件代表一个Snapshot。
清单列表 Manifest list
manifest list是一个元数据文件,它列出构建表快照(Snapshot)的清单(Manifest file)。
- manifest list中记录了Manifest file列表,其中每个Manifest file信息占据一行。
- 每行中存储了
- Manifest file的路径、
- 数据文件(data files)的分区范围,
- 增加了几个数文件、删除了几个数据文件等信息,
这些信息可以用来在查询时提供过滤,加快速度。
清单文件 Manifest file
Manifest file也是一个元数据文件,
- 存储了数据文件(data files)的列表信息。
- 每行都是每个数据文件的详细描述,包括
- 数据文件的状态、文件路径、
- 分区信息、
- 列级别的统计信息(比如每列的最大最小值、空值数等)、
- 文件的大小以及文件里面数据行数等信息。
其中列级别的统计信息可以在扫描表数据时过滤掉不必要的文件。
从如上iceberg的数据结构可以知道,iceberg在数据查询时,1.查找文件的时间复杂度至少是O(1),2. 加上列统计信息,能够很好的实现物理层面的文件裁剪。
3. iceberg 特性
| 序号 | 特性 | 说明 |
|---|---|---|
| 1 | 统一存储 | 统一性:数据都统一存储到hdfs、s3中。 - 数据湖中可以存储结构化、半结构化、非结构化数据,我们可以通过iceberg来摄取这些数据。 - 但要注意:数据湖存储例如图片等非结构化数据并不是强项。 |
| 2 | 插件化 | 灵活性:Iceberg不和特定的数据存储、计算引擎绑定。常见数据存储(HDFS、S3…),计算引擎(Flink、Spark…)都可以接入Iceberg。 |
| 3 | 模式演化 | 演化能力:支持table、schema、Partition的添加、删除、更新或重命名,简化表修改成本。 |
| 4 | 隐藏分区 | 分区信息并不需要人工维护:会自动计算。 由于Iceberg的分区信息和表数据存储目录是独立的,使得Iceberg的表分区可以被修改,而且不涉及到数据迁移。 |
| 5 | Time Travel | 镜像数据查询:允许用户通过将表重置为之前某一时刻的状态来快速纠正问题。 |
| 6 | 乐观锁的并发支持 | 提供了多个程序并发写入的能力并且保证数据线性一致。 |
| 7 | 支持事务 | upsert与读写分离: - 提供事务(ACID)的机制,使其具备了upsert的能力并且使得边写边读成为可能,从而数据可以更快的被下游组件消费。 - 通过事务保证了下游组件只能消费已commit的数据,而不会读到部分甚至未提交的数据。 |
| 8 | 文件级数据剪裁 | 文件级谓词下推: - Iceberg的元数据里面提供了每个数据文件的一些统计信息,比如最大值,最小值,Count计数等等。 - 查询SQL的过滤条件除了常规的分区,列过滤,甚至可以下推到文件级别,大大加快了查询效率。 |
4. 其他数据湖框架的对比

- iceberg不支持自动文件合并,历史数据也需要自己手动清洗
- 文件格式支持的最多:parquet、avro、orc
- 存储引擎支持hdfs、S3
- 不支持索引
三. iceberg实战
1. 集成iceberg到flink
iceberg独立于计算引擎和存储引擎
...
# 1.16 or above has a regression in loading external jar via -j option.
# See FLINK-30035 for details.
put iceberg-flink-runtime-1.16-1.5.2.jar in flink/lib dir./bin/sql-client.sh embedded shell
2. 管理iceberg元数据
https://iceberg.apache.org/docs/latest/java-api-quickstart/
2.1. java api管理iceberg的catalog
使用iceberg native api去管理iceberg的catalog
/*** 数据湖元数据操作*/
public interface DatalakeMetaAPI {// Catalog操作<A> A createCatalog();void dropCatalog(String catalogName);Catalog getCatalog(String catalogName);// Namespace操作:就是数据库void createNamespace(String namespaceName);void dropNamespace(String namespaceName);Namespace getNamespace(String namespaceName);List<Namespace> getAllNamespaces();// Table操作Table createTable();void dropTable(String namespaceName, String tableName);Table alterTable(String catalogName, String namespaceName, String tableName);List<TableIdentifier> getAllTables(String namespaceName);<T> T setConf();
}
/*** hadoopCatalog的实现方法*/
public class IcebergMetaAPI implements DatalakeMetaAPI {private HadoopCatalog hadoopCatalog;private String warehousePath;public IcebergMetaAPI(String warehousePath) {Configuration hadoopConf = setConf();hadoopCatalog = new HadoopCatalog(hadoopConf, warehousePath);}@Overridepublic HadoopCatalog createCatalog() {Configuration hadoopConf = setConf();return new HadoopCatalog(hadoopConf, warehousePath);}@Overridepublic void dropCatalog(String catalogName) {}@Overridepublic Catalog getCatalog(String catalogName) {return null;}@Overridepublic void createNamespace(String namespaceName) {hadoopCatalog.createNamespace(Namespace.of(namespaceName));System.out.println("创建Namespace成功");}@Overridepublic void dropNamespace(String namespaceName) {hadoopCatalog.dropNamespace(Namespace.of(namespaceName));System.out.println("删除Namespace成功");}@Overridepublic Namespace getNamespace(String namespaceName) {if (hadoopCatalog.namespaceExists(Namespace.of(namespaceName))) {// todo:是否正确return hadoopCatalog.listNamespaces(Namespace.of(namespaceName)).get(0);}return Namespace.empty();}@Overridepublic List<Namespace> getAllNamespaces() {return hadoopCatalog.listNamespaces();}@Overridepublic Table createTable() {TableIdentifier spaceAndTableName = TableIdentifier.of("logging", "logs2");/** typeid是需要的, 从其他模式格式(如Spark、Avro和Parquet)进行转换时,将自动分配新的ID */Schema schema = new Schema(Types.NestedField.required(1, "level", Types.StringType.get()),Types.NestedField.required(2, "event_time", Types.TimestampType.withZone()),Types.NestedField.required(3, "message", Types.StringType.get()),Types.NestedField.optional(4, "call_stack",Types.ListType.ofRequired(5, Types.StringType.get())));/*** 分区规范描述了Iceberg如何将记录分组成数据文件。分区规范是使用构建器为表的模式创建的。** <p>以下是按照日志事件的时间戳的小时和日志级别进行分区:*/PartitionSpec partition = PartitionSpec.builderFor(schema).hour("event_time").identity("level").build();// namespace就是数据库Table table = hadoopCatalog.createTable(spaceAndTableName, schema, partition);System.out.println("创建表" + table + "成功");return table;}@Overridepublic void dropTable(String namespaceName, String tableName) {hadoopCatalog.dropTable(TableIdentifier.of("namespaceName", "tableName"));}@Overridepublic Table alterTable(String catalogName, String namespaceName, String tableName) {//todo:修改表操作return null;}@Overridepublic List<TableIdentifier> getAllTables(String namespaceName) {return hadoopCatalog.listTables(Namespace.of(namespaceName));}@Overridepublic Configuration setConf() {Configuration configuration = new Configuration();configuration.set("fs.defaultFS", "hdfs://localhost:9000");// configuration.addResource(new// Path("/Users/lianggao/MyWorkSpace/001-360/001project-360/datalake-metadata-api/datalake-metadata-iceberg/src/main/resources/core-site.xml"));// configuration.addResource(new// Path("/Users/lianggao/MyWorkSpace/001-360/001project-360/datalake-metadata-api/datalake-metadata-iceberg/src/main/resources/hdfs-site.xml"));// configuration.addResource(new// Path("/usr/hdp/current/hive-client/conf/hdfs-site.xml"));configuration.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");// configuration.setBoolean("fs.hdfs.impl.disable.cache", true);// configuration.set("hadoop.job.ugi", "logsget");// UserGroupInformation.setConfiguration(configuration);// try {// Subject subject = new Subject();// subject.getPrincipals().add(new UserPrincipal("logsget"));// UserGroupInformation.loginUserFromSubject(null);// } catch (IOException e) {// e.printStackTrace();// }return configuration;}
}
2.2. 通过flink sql操作iceberg的元数据
本文采用的是flink client sql (在flink standalone集群)去提交iceberg表相关操作,如下创建catalog,我们看到创建的catalog持久化到了s3存储中。
表操作
# 创建catalog
CREATE CATALOG hadoop_catalog WITH ( 'type'='iceberg', 'catalog-type'='hadoop', 'warehouse'='hdfs://iceberg1v.middle.bjmd.qihoo.net:9000/warehouse/iceberg-hadoop', 'property-version'='1' );# 使用catalog
use catalog hadoop_catalog;# 创建表,默认数据库为default
CREATE TABLE `sample` (city_name STRING ,category_name STRING,province_name STRING,order_amount_daily_category_city decimal(20,2)
);# 插入数据
INSERT INTO `sample` VALUES (1, 'a');# 创建带有主键的表
CREATE TABLE `sample5` (`id` INT UNIQUE COMMENT 'unique id',`data` STRING NOT NULL,PRIMARY KEY(`id`) NOT ENFORCED
) with (
'format-version'='2',
'write.upsert.enabled'='true'
);注意:flink sql只允许修改表的属性,并不支持对于列、分区的修改。
官网: https://iceberg.apache.org/docs/nightly/flink/
查找表的相关元数据
-- 表历史
SELECT * FROM spotify$history;--
SELECT * FROM spotify$metadata_log_entries;-- snapshots
SELECT * FROM spotify$snapshots;产品结合:我们运行的flink是在 yarn 下运行的,交互慢,费资源,所以不推荐使用flink对catalog进行管理,而是使用native api管理。
3. 通过flink将数据入湖–集成到chunjun
自己搭建的集群与现有系统部环境暂不统一,使用系统部的hadoop作为数据湖的存储
Flink SQL> CREATE CATALOG hadoop_catalog WITH ( 'type'='iceberg', 'catalog-type'='hadoop', 'warehouse'='hdfs://iceberg1v.middle.bjmd.qihoo.net:9000/warehouse/iceberg-hadoop',
'property-version'='1' );[ERROR] Could not execute SQL statement. Reason:
java.io.IOException: ViewFs: Cannot initialize: Empty Mount table in config for viewfs://iceberg1v.middle.bjmd.qihoo.net:9000/
Flink SQL> CREATE CATALOG hadoop_catalog WITH ( 'type'='iceberg', 'catalog-type'='hadoop', 'warehouse'='hdfs://namenode.dfs.shbt.qihoo.net:9000/home/logsget/warehouse/iceberg-hadoop', 'property-version'='1' );
[INFO] Execute statement succeed.Flink SQL> use catalog hadoop_catalog;
[INFO] Execute statement succeed.Flink SQL> CREATE TABLE `sample` (city_name STRING , category_name STRING, province_name STRING, order_amount_daily_category_city decimal(20,2));
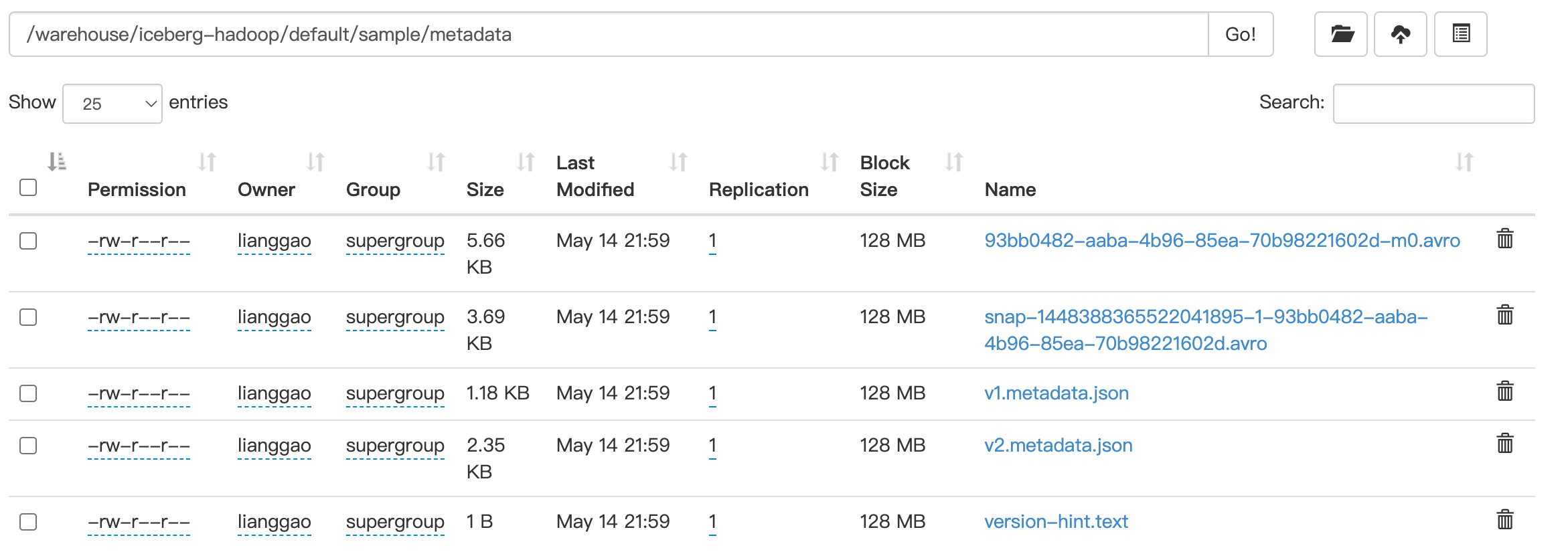
2024-05-17 00:47:21,945 WARN org.apache.hadoop.hdfs.DFSClient [] - Cannot remove /home/logsget/warehouse/iceberg-hadoop/default/sample/metadata/version-hint.text: No such file or directory.
[INFO] Execute statement succeed.
CREATE CATALOG hadoop_catalog WITH ( 'type'='iceberg', 'catalog-type'='hadoop', 'warehouse'='hdfs://namenode.dfs.shbt.qihoo.net:9000/home/logsget/warehouse/iceberg-hadoop', 'property-version'='1' );--use catalog hadoop_catalog;CREATE TABLE `aaa_b` (
city_name STRING , category_name STRING, province_name STRING, order_amount_daily_category_city decimal(20,2)
)
WITH ('password' = 'a87fc6992a96de56','connector' = 'starrocks-x','sink.max-retries' = '3','schema-name' = 'dp_test','sink.buffer-flush.interval-ms' = '5000','fe-nodes' = 'db01.doris.shyc2.qihoo.net:8030','table-name' = 'ads_product_citycategoryamount_di','url' = 'jdbc:mysql://10.192.197.134:9030/dp_test?useUnicode=true&characterEncoding=utf-8&useSSL=false&connectTimeout=3000&useUnicode=true&characterEncoding=utf8&useSSL=false&rewriteBatchedStatements=true&&serverTimezone=Asia/Shanghai&sessionVariables=query_timeout=86400','username' = 'dfs_shbt_logsget'
);insert into hadoop_catalog.`default`.sample select * from aaa_b;/data01/chunjun-master-dev/bin/run-ri-test.sh /data01/chunjun-master-dev/conf/ice-w.sql \
offline logsget '' '' 3 '' '' '' '' '' logsget 1 '' '' '' '' '' \
radar_1_2187_9270_4058632_test '' '' '' local
4. 通过flink 对数据湖进行数据分析–集成到chunjun
CREATE CATALOG hadoop_catalog WITH ( 'type'='iceberg', 'catalog-type'='hadoop', 'warehouse'='hdfs://namenode.dfs.shbt.qihoo.net:9000/home/logsget/warehouse/iceberg-hadoop', 'property-version'='1' );--use catalog hadoop_catalog;CREATE TABLE `aaa_b` (
city_name STRING , category_name STRING, province_name STRING, order_amount_daily_category_city decimal(20,2)
)
WITH ('connector' = 'print'
);insert into aaa_b select * from hadoop_catalog.`default`.sample ;/data01/chunjun-master-dev/bin/run-ri-test.sh /data01/chunjun-master-dev/conf/ice-w.sql \offline logsget '' '' 3 '' '' '' '' '' logsget 1 '' '' '' '' '' \radar_1_2187_9270_4058632_test '' '' '' local
5. 小结
虽然iceberg当初是为了解决hive表格式的问题,但实际上iceberg的种种能力,使得他配得上作为数据湖中间件,这里再回顾下iceberg的能力:
- 流批数据处理的统一与能力
- 数据入湖后,支持对数据的修正、数据质量管理的能力。
- 数据的一致性与正确性:ACID事务的能力,元数据的可拓展性。
- 计算引擎与存储引擎的解耦:这样数据湖中间件可以在多个地方应用,即在不同计算引擎(spark、flink、trino、hive、starrocks…)、存储引擎(hdfs、s3)上应用。
我们可以借助iceberg搭建存储统一、计算口径统一的数据湖仓。
具体地,我们可以
- 使用iceberg native api进行元数据管理;
- 使用flink进行数据入湖;湖仓建设;
- 使用flink、spark、trino、hive等进行数据分析。
6. flink with iceberg 未来的规划
There are some features that are do not yet supported in the current Flink Iceberg integration work:
- Don’t support creating iceberg table with hidden partitioning. Discussion in flink mail list.
- Don’t support creating iceberg table with computed column.
- Don’t support creating iceberg table with watermark.
- Don’t support adding columns, removing columns, renaming columns, changing columns. FLINK-19062 is tracking this.
7. 接下来的探索
- iceberg数据入湖的事务能力验证
- iceberg修改表结构对任务的影响
- iceberg批数据分批写完,下游数据立马能消费的验证,以及相关原理
- iceberg数据合并的逻辑验证。
- iceberg处理非结构数据与半结构数据的实践
相关文章:
【iceberg】数据湖与iceberg调研与实战
文章目录 一. 为什么现在要强调数据湖1. 大数据架构发展历史2. Lambda架构与kappa架构3. 数据湖所具备的能力 二. iceberg是数据湖吗1. iceberg的诞生2. iceberg设计之table format从如上iceberg的数据结构可以知道,iceberg在数据查询时,1.查找文件的时间…...
xrdp多用户多控制界面远程控制
1、无桌面安装桌面(原本有ubuntu桌面的可以直接跳过这一步) Gnome 与 xfce 相比,xfce 由于其轻巧,它可以安装在低端台式机上。Xfce 优雅的外观,增强了用户体验,它对用户非常友好,性能优于其他桌…...

git会忽略我们工作改动中的大小写
在我们日常git工作中,我们对于文件名字的大小写修改正常是不会被git记录的 这是因为默认情况下git是不区分大小写的 这会导致一个问题,由于我们修改了文件名字的大小写,而对于文件之间相互依赖的导入代码没有对应修改 如果我们此时本地推送…...

SSL 自定义证书创建过程
1、生成自签名根证书和私钥 1.1 生成根证书 1.1.1生成根证书私钥 首先,生成一个自签名的根证书和私钥。这个根证书将作为信任锚(Trust Anchor),客户端会信任由这个根证书签署的所有证书。 openssl genrsa -out rootCA.key 204…...

javaSwing飞机订票系统
摘要 Java swing实现的飞机票预定系统,系统数据库原本采用的是Oracle,我又改了一个mysql版本的,所以这套系统有两个版本,一个是mysql数据库版的,一个是Oracle数据库版 一. 已经完成的功能 : …...
)
赶紧收藏!2024 年最常见 20道 Redis面试题(四)
上一篇地址:赶紧收藏!2024 年最常见 20道 Redis面试题(三)-CSDN博客 七、Pipeline有什么好处,为什么要用pipeline? Redis Pipeline 是一种批量执行命令的技术,它允许客户端一次性发送多个命令…...
虚拟列表 vue-virtual-scroller 的使用
npm 详情:vue-virtual-scroller - npm (npmjs.com) 这里我使用的是RecycleScroller。 App.vue <template><RecycleScrollerclass"scroller":items"items":item-size"54"v-slot"{ item }"><list-item :it…...

前端基础入门三大核心之HTML篇:深入理解重绘与重排 —— 概念、区别与实战演练
前端基础入门三大核心之HTML篇:深入理解重绘与重排 —— 概念、区别与实战演练 HTML渲染基础回顾重绘与重排的概念重绘(Repaint)重排(Reflow) 区别与影响实战示例:优化策略与代码演示示例1:避免…...

【C/C++笔试练习】TCP、IP广播、ARP协议、IP路由器、MAC协议、三次握手、TCP/IP、子网划分年、会抽奖、抄送列表
文章目录 C/C笔试练习选择部分(1)TCP(2)IP广播(3)ARP协议(4)IP路由器(5)MAC协议(6)三次握手(7)TCP/IP…...

线程的概念和控制
文章目录 线程概念线程的优点线程的缺点线程异常线程用途理解虚拟地址 线程控制线程的创建线程终止线程等待线程分离封装线程库 线程概念 什么是线程? 在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是“一…...

PHS树脂(聚对羟基苯乙烯)为KrF光刻胶专用树脂 本土企业具备百公斤级别量产能力
PHS树脂(聚对羟基苯乙烯)为KrF光刻胶专用树脂 本土企业具备百公斤级别量产能力 PHS树脂又称聚对羟基苯乙烯树脂、聚羟基苯乙烯树脂,指以对羟基苯乙烯作为基材制成的光刻胶树脂。与其他光刻胶树脂相比,PHS树脂具有极佳热稳定性、化…...

Python 机器学习 基础 之 数据表示与特征工程 【单变量非线性变换 / 自动化特征选择/利用专家知识】的简单说明
Python 机器学习 基础 之 数据表示与特征工程 【单变量非线性变换 / 自动化特征选择/利用专家知识】的简单说明 目录 Python 机器学习 基础 之 数据表示与特征工程 【单变量非线性变换 / 自动化特征选择/利用专家知识】的简单说明 一、简单介绍 二、单变量非线性变换 三、自…...

uniapp-自定义navigationBar
封装导航栏自定义组件 创建 nav-bar.vue <script setup>import {onReady} from dcloudio/uni-appimport {ref} from vue;const propsdefineProps([navBackgroundColor])const statusBarHeight ref()const navHeight ref()onReady(() > {uni.getSystemInfo({success…...

多式联运奇迹:探索 GPT-4o 的尖端功能
取得的显着进展的DigiOps与人工智能已经标志着重要的里程碑,随着时间的推移塑造了人工智能系统的能力。从早期基于规则系统的出现机器学习和深入学习,人工智能已经发展得更加先进和通用。 生成式预训练 Transformer (GPT) by OpenAI 已特别值得注意。每…...

前端 CSS 经典:好看的标题动画
前言:好看的标题动画实现。 效果: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0" /><…...

Vue项目打包优化(element+echarts+vue使用cdn)
如何打包查看所有资源大小? 使用插件:webpack-bundle-analyzer 效果图: 安装webpack-bundle-analyzer 第一步,终端执行 npm instatll webpack-bundle-analyzer --save-dev第二步,vue.config.js配置 module.export…...

【ARM 嵌入式 C 入门及渐进 6.1 -- ARMv8 C 内嵌汇编写系统寄存器的函数实现】
请阅读【嵌入式开发学习必备专栏】 文章目录 ARMv8 C 内嵌汇编写系统寄存器 ARMv8 C 内嵌汇编写系统寄存器 在ARMv8架构下,使用C语言结合内嵌汇编实现将一个值写入特定系统寄存器的函数可以按照下面的方法进行。 下面这个示例展示了如何将一个uint64_t类型的值写入…...
ESP32基础应用之使用手机浏览器作为客户端与ESP32作为服务器进行通信
文章目录 1 准备2 移植2.1 softAP工程移植到simple工程中2.2 移植注意事项 3 验证 1 准备 参考工程 Espressif\frameworks\esp-idf-v5.2.1\examples\wifi\getting_started\softAP softAP工程演示将ESP32作为AP,即热点,使手机等终端可以连接参考工程 Esp…...
【课后练习分享】Java用户注册界面设计和求三角形面积的图形界面程序
目录 java编程题(每日一练): 问题一的答案代码如下: 问题一的运行截图如下: 问题二的答案代码如下: 问题二的运行截图如下: java编程题(每日一练): 1.…...
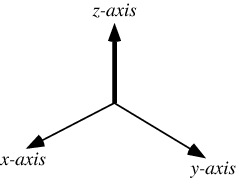
三维空间坐标系变换(旋转平移)
在探究三维空间下的变换前,首先研究二位空间,因为比较直观,再推广到三维空间。 首先应该清楚的一点是:旋转、平移对于坐标系下的点以及坐标系本身而言都是相对的(运动的相对性)。 例如: X O Y …...

从零打造会“看”的电子眼:Teensy与OLED的嵌入式图形与传感器实践
1. 项目概述:打造一个会“看”的电子生命体几年前,我第一次在创客社区看到“Uncanny Eyes”项目时就被深深吸引了。一个微小的OLED屏幕,在代码驱动下,竟然能呈现出如此逼真、灵动的眼球运动,那种介于生命与机械之间的诡…...

药物发现自动化:FEP计算工作流引擎faah的设计原理与实战
1. 项目概述:一个面向药物发现的自动化工作流引擎 最近在药物研发的自动化工具领域,一个名为 kiron0/faah 的项目引起了我的注意。这并非一个简单的脚本集合,而是一个设计精巧、旨在为药物发现中的自由能微扰计算提供端到端自动化解决方案的…...

Go语言实现Hermes引擎:高性能JavaScript字节码虚拟机解析与实践
1. 项目概述:一个Go语言实现的Hermes引擎最近在折腾一些需要高性能模板渲染的后端服务,偶然间在GitHub上发现了LAI-755/hermes-go这个项目。简单来说,这是一个用纯Go语言实现的Hermes引擎。如果你对前端生态熟悉,可能听说过Hermes…...

基于树莓派与QT Py的本地化物联网红外遥控器DIY指南
1. 项目概述与核心价值想没想过,把家里那堆遥控器——电视的、机顶盒的、空调的、音响的——统统集成到一个你手机能打开的网页里?而且这个控制中心完全在你家局域网里运行,不依赖任何云服务,不用担心厂商倒闭后设备变砖。今天分享…...

从零解析开源API网关fiGate:架构设计与生产实践
1. 项目概述:从零解析一个开源API网关最近在梳理团队内部微服务治理方案时,我又重新审视了市面上各类API网关的实现。除了大家耳熟能详的Kong、APISIX、Tyk这些“明星产品”,其实在GitHub的海洋里,还藏着不少设计精巧、思路独特的…...

5分钟快速上手:Windows虚拟显示器终极指南,轻松实现多屏扩展
5分钟快速上手:Windows虚拟显示器终极指南,轻松实现多屏扩展 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 还在为单显示器工作效率低下而烦恼吗…...
)
Midjourney Ash印相参数白皮书(含Adobe RGB/ProPhoto RGB双色域适配矩阵及ICC Profile嵌入规范)
更多请点击: https://intelliparadigm.com 第一章:Midjourney Ash印相技术演进与核心定位 Midjourney Ash印相(Ash Toning)并非传统暗房化学工艺的简单复刻,而是基于生成式AI图像合成模型的一套语义化风格映射机制。它…...

基于Python与Playwright的招聘信息自动化聚合与智能筛选工具实践
1. 项目概述:一个面向求职者的自动化信息聚合与投递工具最近在和一些做开发的朋友聊天,发现大家普遍有个痛点:找工作太费时间了。每天要在几个招聘App之间来回切换,重复筛选岗位、刷新列表、投递简历,机械性的操作占据…...

子高斯随机变量与深度学习异常检测原理
1. 子高斯随机变量基础解析子高斯随机变量是概率论中一类具有特殊尾部性质的分布。简单来说,一个随机变量X如果满足存在常数σ>0,使得对于所有λ∈R都有E[exp(λX)] ≤ exp(λσ/2),那么我们就称X是σ-子高斯的。这类分布的关键特征是它们…...

边缘计算赋能工业智能化:重大危险源监测+产线控制+视觉分析一体化解决方案
在工业 4.0 与智能制造深度融合的今天,工业现场产生的数据量呈指数级增长。传统的 "云端集中式" 数据处理架构在面对毫秒级实时控制、海量视觉数据传输、高危场景 724 小时不间断监测等需求时,逐渐暴露出延迟高、带宽成本大、网络依赖强、数据…...