【机器学习】—机器学习和NLP预训练模型探索之旅
 目录
目录
一.预训练模型的基本概念
1.BERT模型
2 .GPT模型
二、预训练模型的应用
1.文本分类
使用BERT进行文本分类
2. 问答系统
使用BERT进行问答
三、预训练模型的优化
1.模型压缩
1.1 剪枝
权重剪枝
2.模型量化
2.1 定点量化
使用PyTorch进行定点量化
3. 知识蒸馏
3.1 知识蒸馏的基本原理
3.2 实例代码:使用知识蒸馏训练学生模型
四、结论
随着数据量的增加和计算能力的提升,机器学习和自然语言处理技术得到了飞速发展。预训练模型作为其中的重要组成部分,通过在大规模数据集上进行预训练,使得模型可以捕捉到丰富的语义信息,从而在下游任务中表现出色。
一.预训练模型的基本概念

预训练模型是一种在大规模数据集上预先训练好的模型,可以作为其他任务的基础。预训练模型的优势在于其能够利用大规模数据集中的知识,提高模型的泛化能力和准确性。常见的预训练模型包括BERT(Bidirectional Encoder Representations from Transformers)、GPT(Generative Pre-trained Transformer)等。
1.BERT模型
BERT是由Google提出的一种双向编码器表示模型。BERT通过在大规模文本数据上进行掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)的预训练,使得模型可以学习到深层次的语言表示。
2 .GPT模型
GPT由OpenAI提出,是一种基于Transformer的生成式预训练模型。GPT通过在大规模文本数据上进行自回归语言模型的预训练,使得模型可以生成连贯的文本。
二、预训练模型的应用
预训练模型在NLP领域有广泛的应用,包括但不限于文本分类、问答系统、机器翻译等。以下将介绍几个具体的应用实例。
1.文本分类
文本分类是将文本数据按照预定义的类别进行分类的任务。预训练模型可以通过在大规模文本数据上进行预训练,从而捕捉到丰富的语义信息,提高文本分类的准确性。
使用BERT进行文本分类
import torch
from transformers import BertTokenizer, BertForSequenceClassification
from torch.utils.data import DataLoader, Dataset
from sklearn.model_selection import train_test_split# 加载预训练的BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)# 定义数据集
class TextDataset(Dataset):def __init__(self, texts, labels, tokenizer, max_len):self.texts = textsself.labels = labelsself.tokenizer = tokenizerself.max_len = max_lendef __len__(self):return len(self.texts)def __getitem__(self, idx):text = self.texts[idx]label = self.labels[idx]encoding = self.tokenizer.encode_plus(text,add_special_tokens=True,max_length=self.max_len,return_token_type_ids=False,padding='max_length',return_attention_mask=True,return_tensors='pt',)return {'text': text,'input_ids': encoding['input_ids'].flatten(),'attention_mask': encoding['attention_mask'].flatten(),'label': torch.tensor(label, dtype=torch.long)}# 准备数据
texts = ["I love this!", "I hate this!"]
labels = [1, 0]
train_texts, val_texts, train_labels, val_labels = train_test_split(texts, labels, test_size=0.1)train_dataset = TextDataset(train_texts, train_labels, tokenizer, max_len=32)
val_dataset = TextDataset(val_texts, val_labels, tokenizer, max_len=32)train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=2, shuffle=False)# 训练模型
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)
for epoch in range(3):model.train()for batch in train_loader:optimizer.zero_grad()input_ids = batch['input_ids']attention_mask = batch['attention_mask']labels = batch['label']outputs = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)loss = outputs.lossloss.backward()optimizer.step()# 验证模型
model.eval()
correct = 0
total = 0
with torch.no_grad():for batch in val_loader:input_ids = batch['input_ids']attention_mask = batch['attention_mask']labels = batch['label']outputs = model(input_ids=input_ids, attention_mask=attention_mask)_, predicted = torch.max(outputs.logits, dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Validation Accuracy: {correct / total:.2f}')2. 问答系统
问答系统是从文本中自动提取答案的任务。预训练模型可以通过在大规模问答数据上进行预训练,从而提高答案的准确性和相关性。
使用BERT进行问答
from transformers import BertForQuestionAnswering# 加载预训练的BERT问答模型
model = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')# 输入问题和上下文
question = "What is the capital of France?"
context = "Paris is the capital of France."# 编码输入
inputs = tokenizer.encode_plus(question, context, return_tensors='pt')# 模型预测
outputs = model(**inputs)
start_scores = outputs.start_logits
end_scores = outputs.end_logits# 获取答案的起始和结束位置
start_idx = torch.argmax(start_scores)
end_idx = torch.argmax(end_scores) + 1# 解码答案
answer = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens(inputs['input_ids'][0][start_idx:end_idx]))
print(f'Answer: {answer}')三、预训练模型的优化
在实际应用中,预训练模型的优化至关重要。常见的优化方法包括模型压缩、量化和蒸馏等。
1.模型压缩
模型压缩是通过减少模型参数数量和计算量来提高模型效率的方法。压缩后的模型不仅运行速度更快,还能减少存储空间和内存占用。常见的模型压缩技术包括剪枝、量化和知识蒸馏等。
1.1 剪枝
剪枝(Pruning)是一种通过删除模型中冗余或不重要的参数来减小模型大小的方法。剪枝可以在训练过程中或训练完成后进行。常见的剪枝方法包括:
- 权重剪枝(Weight Pruning):删除绝对值较小的权重,认为这些权重对模型输出影响不大。
- 结构剪枝(Structured Pruning):删除整个神经元或卷积核,减少模型的计算量和存储需求。
剪枝后的模型通常需要重新训练,以恢复或接近原始模型的性能。
权重剪枝
import torch
import torch.nn.utils.prune as prune# 定义一个简单的模型
class SimpleModel(torch.nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc = torch.nn.Linear(10, 10)def forward(self, x):return self.fc(x)model = SimpleModel()# 对模型的全连接层进行权重剪枝
prune.l1_unstructured(model.fc, name='weight', amount=0.5)# 查看剪枝后的权重
print(model.fc.weight)2.模型量化
模型量化是通过降低模型参数的精度来减少计算量的方法。量化通常通过将浮点数表示的权重和激活值转换为低精度表示(如8位整数)来实现。这可以显著减少模型的存储空间和计算开销,同时在硬件上加速模型推理。
2.1 定点量化
定点量化(Fixed-point Quantization)是将浮点数表示的权重和激活值转换为固定精度的整数表示。常见的定点量化包括8位整数量化(INT8),这种量化方法在不显著降低模型精度的情况下,可以大幅提升计算效率。
使用PyTorch进行定点量化
import torch
import torch.quantization# 加载预训练模型
model = SimpleModel()# 定义量化配置
model.qconfig = torch.quantization.get_default_qconfig('fbgemm')# 准备量化模型
model = torch.quantization.prepare(model, inplace=True)# 模拟量化后的推理过程
# 这里应该使用训练数据对模型进行微调,但为了简单起见,省略此步骤
model = torch.quantization.convert(model, inplace=True)# 查看量化后的模型
print(model)3. 知识蒸馏
知识蒸馏(Knowledge Distillation)是通过将大模型(教师模型,Teacher Model)的知识转移到小模型(学生模型,Student Model)的方法,从而提高小模型的性能和效率。知识蒸馏的核心思想是通过教师模型的软标签(soft labels)指导学生模型的训练。
3.1 知识蒸馏的基本原理
在知识蒸馏过程中,学生模型不仅学习训练数据的真实标签,还学习教师模型对训练数据的输出,即软标签。软标签包含了更多的信息,比如类别之间的相似性,使学生模型能够更好地泛化。
蒸馏损失函数通常由两部分组成:
- 交叉熵损失:衡量学生模型输出与真实标签之间的差异。
- 蒸馏损失:衡量学生模型输出与教师模型软标签之间的差异。
总体损失函数为这两部分的加权和。
3.2 实例代码:使用知识蒸馏训练学生模型
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset# 定义教师模型和学生模型
teacher_model = SimpleModel()
student_model = SimpleModel()# 加载示例数据
data = torch.randn(100, 10)
labels = torch.randint(0, 10, (100,))
dataset = TensorDataset(data, labels)
data_loader = DataLoader(dataset, batch_size=10, shuffle=True)# 定义蒸馏训练函数
def distillation_train(student_model, teacher_model, data_loader, optimizer, temperature=2.0, alpha=0.5):teacher_model.eval()student_model.train()for data, labels in data_loader:optimizer.zero_grad()# 教师模型输出with torch.no_grad():teacher_logits = teacher_model(data)# 学生模型输出student_logits = student_model(data)# 计算蒸馏损失loss_ce = F.cross_entropy(student_logits, labels)loss_kl = F.kl_div(F.log_softmax(student_logits / temperature, dim=1),F.softmax(teacher_logits / temperature, dim=1),reduction='batchmean') * (temperature ** 2)loss = alpha * loss_ce + (1.0 - alpha) * loss_klloss.backward()optimizer.step()# 定义优化器
optimizer = torch.optim.Adam(student_model.parameters(), lr=1e-3)# 进行蒸馏训练
for epoch in range(10):distillation_train(student_model, teacher_model, data_loader, optimizer)# 验证学生模型
student_model.eval()
correct = 0
total = 0
with torch.no_grad():for data, labels in data_loader:outputs = student_model(data)_, predicted = torch.max(outputs, dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Student Model Accuracy: {correct / total:.2f}')四、结论
预训练模型在机器学习和自然语言处理领域具有重要意义。通过在大规模数据集上进行预训练,模型可以捕捉到丰富的语义信息,从而在下游任务中表现出色。

相关文章:
【机器学习】—机器学习和NLP预训练模型探索之旅
目录 一.预训练模型的基本概念 1.BERT模型 2 .GPT模型 二、预训练模型的应用 1.文本分类 使用BERT进行文本分类 2. 问答系统 使用BERT进行问答 三、预训练模型的优化 1.模型压缩 1.1 剪枝 权重剪枝 2.模型量化 2.1 定点量化 使用PyTorch进行定点量化 3. 知识蒸馏…...
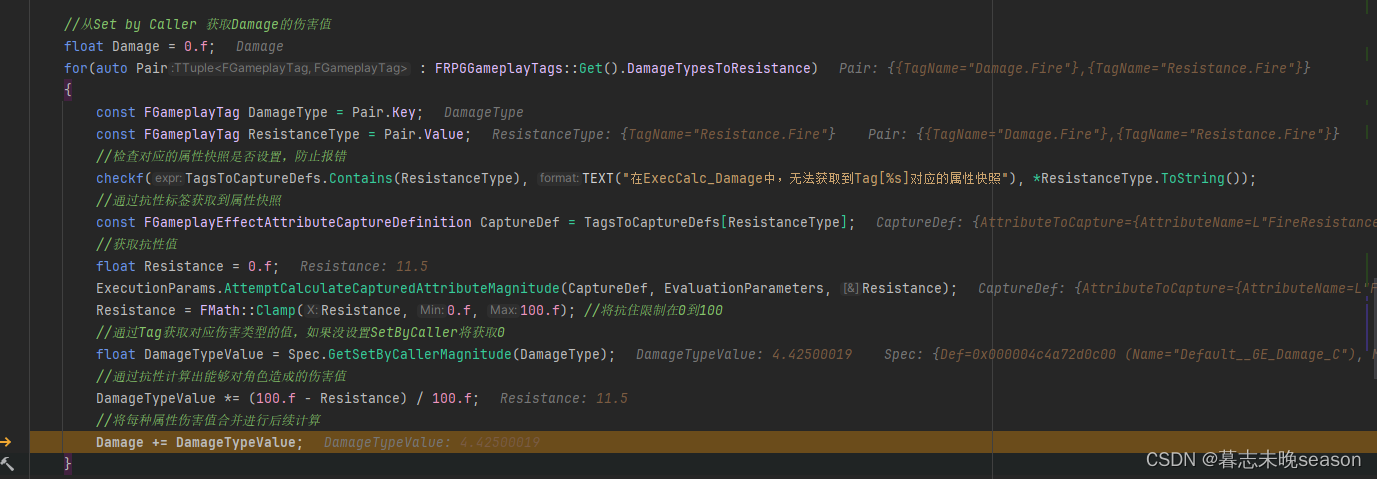
54. UE5 RPG 增加伤害类型
在正常的RPG游戏中,都存在一个类别就是属性伤害,比如,在一个游戏里面有一个火属性的技能,它造成的伤害就是火属性类型的,并且它还有可能有附加伤害,比如给予目标一个灼烧效果,每秒造成多少的火属…...

llama3 微调教程之 llama factory 的 安装部署与模型微调过程,模型量化和gguf转换。
本文记录了从环境部署到微调模型、效果测试的全过程,以及遇到几个常见问题的解决办法,亲测可用(The installed version of bitsandbytes was compiled without GPU support. NotImplementedError: Architecture ‘LlamaForCausalLM’ not sup…...

C++三剑客之std::any(二) : 源码剖析
目录 1.引言 2.std::any的存储分析 3._Any_big_RTTI与_Any_small_RTTI 4.std::any的构造函数 4.1.从std::any构造 4.2.可变参数模板构造函数 4.3.赋值构造与emplace函数 5.reset函数 6._Cast函数 7.make_any模版函数 8.std::any_cast函数 9.总结 1.引言 C三剑客之s…...
)
【C语言】8.C语言操作符详解(2)
文章目录 6.单⽬操作符7.逗号表达式8.下标访问[]、函数调⽤()8.1 [ ] 下标引⽤操作符8.2 函数调⽤操作符 9.结构成员访问操作符9.1 结构体9.1.1 结构的声明9.1.2 结构体变量的定义和初始化 9.2 结构成员访问操作符9.2.1 结构体成员的直接访问9.2.2 结构体成员的间接访问 6.单⽬…...

vivado 物理约束KEEP_HIERARCHY
KEEP_HIERARCHY Applied To Cells Constraint Values • TRUE • FALSE • YES • NO UCF Example INST u1 KEEP_HIERARCHY TRUE; XDC Example set_property DONT_TOUCH true [get_cells u1] IOB Applied To Cells Constraint Values IOB_XnYn UCF Examp…...

Linux 三十六章
🐶博主主页:ᰔᩚ. 一怀明月ꦿ ❤️🔥专栏系列:线性代数,C初学者入门训练,题解C,C的使用文章,「初学」C,linux 🔥座右铭:“不要…...

ntsd用法+安装包
ntsd是一个强大的进程终止软件,除了少数系统进程之外一律杀掉 用法 1.ntsd -c q -p 进程的pid 2.ntsd -c q -pn 进程名 记得解压到System32里面 当然,资源管理器的进程是可以杀的所以也可以让电脑黑屏 同样可以让电脑黑屏的还有taskkill /f /im 进程…...

Nacos 微服务管理
Nacos 本教程将为您提供Nacos的基本介绍,并带您完成Nacos的安装、服务注册与发现、配置管理等功能。在这个过程中,您将学到如何使用Nacos进行微服务管理。下方是官方文档: Nacos官方文档 1. Nacos 简介 Nacos(Naming and Confi…...
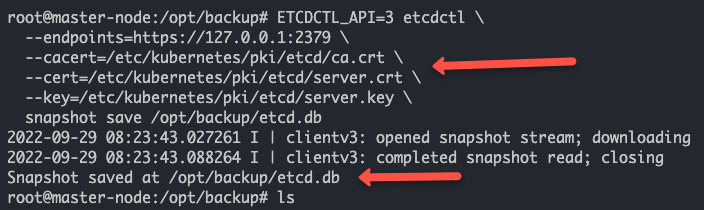
Kubernetes集群上的Etcd备份和恢复
在本教程中,您将学习如何在Kubernetes集群上使用etcd快照进行etcd备份和恢复。 在Kubernetes架构中,etcd是集群的重要组成部分。所有集群对象及其状态都存储在etcd中。为了更好地理解Kubernetes,有几点关于etcd的信息是您需要了解的。 它是…...
)
创建型模式 (Python版)
单例模式 懒汉式 class SingleTon:# 类属性_obj None # 用来存储对象# 创造对象def __new__(cls, *args, **kwargs):# 如果对象不存在,就创造一个对象if cls._obj is None:cls._obj super().__new__(cls, *args, *kwargs)# 返回对象return cls._objif __name__…...

【收录 Hello 算法】9.4 小结
目录 9.4 小结 1. 重点回顾 2. Q & A 9.4 小结 1. 重点回顾 图由顶点和边组成,可以表示为一组顶点和一组边构成的集合。相较于线性关系(链表)和分治关系(树),网络关系(图&am…...

MYSQL数据库基础语法
目录 友情提醒第一章:数据库简述1)数据库简述2)常见的数据库软件3)MySQL数据库安装和连接4)SQL语句分类①DDL(Data Definition)②DML(Data Manipulation)③DQL࿰…...
)
R实验 参数检验(二)
实验目的:掌握正态分布和二项分布中,功效与样本容量之间的关系;学会利用R软件完成一个正态总体方差和两个正态总体方差比的区间估计和检验。 实验内容: (习题5.28)一种药物可治疗眼内高压,目的…...

【Linux】进程信号及相关函数/系统调用的简单认识与使用
文章目录 前言一、相关函数/系统调用1. signal2. kill3. abort (库函数)4. raise (库函数)5. alarm 前言 现实生活中, 存在着诸多信号, 比如红绿灯, 上下课铃声…我们在接收到信号时, 就会做出相应的动作. 对于进程也是如此的, 进程也会收到来自 OS 发出的信号, 根据信号的不同…...
什么是Spring Boot)
Spring (14)什么是Spring Boot
Spring Boot是一个开源的Java基础框架,旨在简化Spring应用的创建和开发过程。Spring Boot通过提供一套默认配置(convention over configuration),自动配置和启动器(starters)来减少开发者的开发工作量和配置…...

区间预测 | Matlab实现CNN-KDE卷积神经网络结合核密度估计多置信区间多变量回归区间预测
区间预测 | Matlab实现CNN-KDE卷积神经网络结合核密度估计多置信区间多变量回归区间预测 目录 区间预测 | Matlab实现CNN-KDE卷积神经网络结合核密度估计多置信区间多变量回归区间预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现CNN-KDE卷积神经网络结合…...

Java集合框架全景解读:从源码到实践精通指南
1. Java集合框架简介 在Java中,集合框架是用于存储和处理数据集合的一组类和接口。它提供了一系列的数据结构,比如列表(List)、集(Set)和映射(Map)。这些数据结构为开发者处理数据提…...

Python | Leetcode Python题解之第107题二叉树的层序遍历II
题目: 题解: class Solution:def levelOrderBottom(self, root: TreeNode) -> List[List[int]]:levelOrder list()if not root:return levelOrderq collections.deque([root])while q:level list()size len(q)for _ in range(size):node q.popl…...
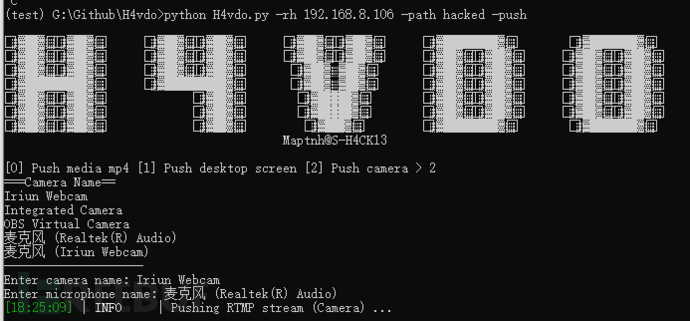
H4vdo 台湾APT-27视频投放工具
地址:https://github.com/MartinxMax/H4vdo 视频 关于 H4vdo RTMP lock 屏播放视频工具,可以向目标发送有效载荷,播放目标的屏幕内容。目标无法曹作计算机 使用方法 安装依赖 根据你的操作系统选择一个安装程序 RTMP 服务端 ./rtsp-simple-server.…...
FlashAttention 在昇腾NPU上到底快在哪?一次拆透 ops-transformer 的核心算子
这是一篇关于昇腾NPU上FlashAttention技术深度解析的CSDN博客文章。文章结合了您提供的网页信息(特别是ops-transformer仓库的上下文)以及深度学习算子优化的专业知识,旨在帮助开发者理解其原理、优势及在昇腾生态中的应用。 FlashAttention …...

static-php-cli与Swoole集成:构建高性能微服务应用的最佳实践
static-php-cli与Swoole集成:构建高性能微服务应用的最佳实践 【免费下载链接】static-php-cli Build standalone portable PHP binaries on Linux, macOS, Windows, with PHP project together, with popular extensions included. 项目地址: https://gitcode.co…...

kafka安装与可视化工具offset explore连接操作说明
1.1 环境前置要求 本地部署 Kafka 4.0 极简,无复杂依赖,只需满足 1 个核心条件: 本地已安装 JDK 17 及以上版本(推荐 JDK 17),并配置好 Java 环境变量(能在命令行执行 java -version 和 javac -…...

Unity IL2CPP逆向实战:用frida-il2cpp-bridge穿透三重运行时屏障
1. 这不是“又一个 Frida 教程”,而是 Unity 逆向现场的生存手册 你刚在某款热门 Unity 游戏里发现一个可疑的加密逻辑,想确认它是否调用了 UnityEngine.PlayerPrefs.SetString 存储敏感 token;或者你在调试一款国产工具类 App,…...

C语言内联函数与宏的深度解析:性能、安全与工程实践
1. 项目概述:为什么我们需要关注内联与宏?在C语言的日常开发中,尤其是性能敏感或嵌入式领域的项目里,我们经常面临一个选择:为了实现一个简单的、频繁调用的功能,是写一个函数,还是用一个宏来搞…...

向量化智能矩阵系统的语义坍塌:当10万条内容同时找“相似“,为什么你的数据库扛不住?
摘要:智能矩阵系统从"关键词匹配"进化到"语义匹配"之后,遇到了一个被严重低估的性能瓶颈——向量检索的语义坍塌。本文从向量数据库原理、ANN近似最近邻算法、HNSW图索引、向量量化技术四个底层技术出发,拆解向量化智能矩…...

高性价比塑料链板输送机厂家排行适配指南
随着2026年《工业输送设备安全生产通用规范》正式落地,国内输送设备行业的准入门槛和生产标准迎来新一轮调整,新规对各领域使用的输送设备提出了更明确的合规要求,也给中小企业选购设备提供了清晰的参考标准。2026年输送设备安全生产新规核心…...

2026 网络安全渗透测试行业报告|机遇与前景
随着数字化转型的深入和网络威胁的日益复杂化,网络安全渗透测试行业在2025年迎来了前所未有的发展机遇与挑战。本文基于最新行业数据、招聘趋势与技术演进,全面剖析当前渗透测试行业的市场规模、人才供需、薪资水平、技术变革及未来发展方向,…...

读《AI时代成为行业精英的融合型学习法》
这段时间看了日本科普作家竹内熏写的《AI时代成为行业精英的融合型学习法》一书,想说说自己的体会。这是一本很薄的书,一共100来页,个人觉得,在现在这个什么都不会的小白也能用AI写出几万字文章的时代,这本书可以算得上…...

Django-tenants安全最佳实践:数据隔离与权限控制终极指南
Django-tenants安全最佳实践:数据隔离与权限控制终极指南 【免费下载链接】django-tenants Django tenants using PostgreSQL Schemas 项目地址: https://gitcode.com/gh_mirrors/dj/django-tenants 在构建SaaS应用时,数据隔离与权限控制是确保多…...