K-means聚类模型
目录
1.定义
2.K-means聚类模型的优点
3.K-means聚类模型的缺点
4.K-means聚类模型的应用场景
5.对K-means聚类模型未来的展望
6.小结
1.定义
什么是 K-means 聚类模型?K-means 聚类模型是一种无监督学习算法,用于将数据划分为不同的组或簇,使得组内的数据点具有较高的相似性,而组间的数据点具有较低的相似性。该算法通过迭代优化的方式,不断调整聚类中心,直到达到最优的聚类结果。
K-means 聚类模型的基本思想是:首先,随机选择 K 个数据点作为初始聚类中心;然后,将每个数据点分配到距离最近的聚类中心所在的簇;接着,更新聚类中心为每个簇内数据点的平均值;最后,重复上述步骤,直到聚类中心不再发生变化或达到最大迭代次数。
2.K-means聚类模型的优点
1. 简单快速:K-means 聚类模型的计算复杂度较低,能够在较短的时间内处理大规模数据。
2. 可解释性强:K-means 聚类模型的结果易于理解和解释,能够直观地展示数据的聚类结构。
3. 适用于大规模数据:K-means 聚类模型可以处理高维数据和大规模数据集,并且在处理噪声和异常值方面表现较好。
4. 可扩展性好:K-means 聚类模型可以通过并行计算等方式进行扩展,以提高处理速度。
3.K-means聚类模型的缺点
1. 对初始聚类中心敏感:K-means 聚类模型的结果对初始聚类中心的选择非常敏感,如果初始聚类中心选择不当,可能会导致聚类结果不准确。
2. 无法发现非球形簇:K-means 聚类模型只能发现具有球形形状的簇,对于非球形簇或复杂形状的簇的发现效果不佳。
3. 对噪声和异常值敏感:K-means 聚类模型对噪声和异常值比较敏感,可能会将噪声和异常值误认为是聚类中心,从而影响聚类结果的准确性。
4. 确定最佳聚类数困难:确定最佳的聚类数是一个棘手的问题,需要根据数据的特点和实际需求进行选择。
4.K-means聚类模型的应用场景
1. 客户细分:根据客户的购买行为、消费习惯等数据,将客户分为不同的组,以便企业能够针对不同的客户群体制定个性化的营销策略。
例如,某电商企业可以使用 K-means 聚类模型对客户进行细分,将客户分为高价值客户、中价值客户和低价值客户等不同的组,然后针对不同的客户群体进行精准营销,提高客户的满意度和忠诚度。
2. 市场划分:根据地理位置、人口特征等数据,将市场划分为不同的区域,以便企业能够更好地了解市场需求和竞争情况。
例如,某饮料企业可以使用 K-means 聚类模型对市场进行划分,将市场划分为不同的区域,然后针对不同的区域制定不同的营销策略,提高市场占有率。
3. 图像分割:将图像划分为不同的区域,以便计算机能够更好地理解图像的内容。
例如,在医学图像分析中,K-means 聚类模型可以用于将图像划分为不同的组织区域,以便医生能够更好地观察和诊断疾病。
4. 文档分类:将文档分为不同的类别,以便计算机能够更好地理解文档的内容。
例如,在电子邮件过滤中,K-means 聚类模型可以用于将邮件分为不同的类别,如垃圾邮件和正常邮件,以便用户能够更好地管理邮件。
5. 网络安全:检测网络中的异常行为和攻击,以便及时发现和防范网络安全威胁。
例如,在网络流量分析中,K-means 聚类模型可以用于检测异常的网络流量,如 DDoS 攻击等,以便网络管理员能够及时采取措施保护网络安全。
我们举一个使用 Python 在 Jupyter Notebook 环境下调用相关库实现K-means聚类模型的例子:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeansplt.style.use('ggplot') #更改设计风格,使用自带的形式进行美化
plt.rcParams["font.sans-serif"] = ["SimHei"] # 用来显示中文# 示例数据
data = np.array([[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]])# 创建 KMeans 聚类模型
kmeans = KMeans(n_clusters=2, random_state=0).fit(data)# 预测聚类标签
cluster_labels = kmeans.labels_# 打印每个样本所属的聚类
print("每个样本所属的聚类:", cluster_labels)# 可视化聚类结果
plt.scatter(data[:, 0], data[:, 1], c=cluster_labels, cmap='rainbow')
plt.xlabel('X')
plt.ylabel('Y')
plt.title('K-means 聚类结果')
plt.show()输出结果:
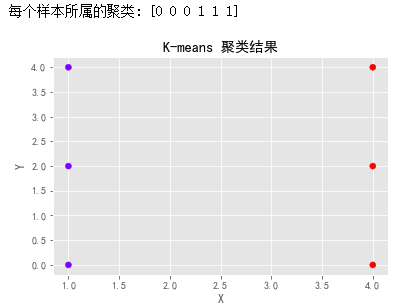
在上述代码中,我们首先导入了所需的库 numpy和 sklearn.cluster.KMeans。然后,我们定义了示例数据 data。
接下来,我们使用 KMeans类创建了一个 K-means 聚类模型,并通过 fit方法拟合数据。n_clusters参数指定了聚类的数量,这里我们设置为 2。random_state参数用于设置随机数生成器的种子,以确保结果的可重复性。
然后,我们使用 labels_属性获取聚类模型预测的聚类标签,并将其打印出来。
最后,我们使用 matplotlib.pyplot库将数据可视化。通过 scatter函数绘制每个样本的坐标,并根据聚类标签设置不同的颜色。cmap='rainbow'参数指定了使用彩虹颜色映射来显示不同的聚类。
运行代码后,将显示一个包含聚类结果的散点图。
这只是一个简单的示例,你可以根据实际需求对数据和聚类参数进行调整。还可以使用其他库和方法来进行数据预处理、评估聚类效果等。
5.对K-means聚类模型未来的展望
随着人工智能和大数据技术的不断发展,K-means 聚类模型也将不断发展和完善。未来,K-means 聚类模型可能会朝着以下几个方向发展:
1. 与其他算法结合:K-means 聚类模型可能会与其他算法结合,如深度学习算法、强化学习算法等,以提高聚类的准确性和效率。
2. 处理高维数据:随着数据维度的不断增加,K-means 聚类模型需要不断改进和优化,以处理高维数据。
3. 考虑数据的时空特性:在一些应用场景中,数据具有时空特性,如传感器网络数据、社交网络数据等。未来,K-means 聚类模型可能会考虑数据的时空特性,以提高聚类的准确性和实用性。
4. 可视化展示:K-means 聚类模型的结果通常是一些数字和图表,对于非专业人士来说,理解和解释这些结果可能会比较困难。未来,K-means 聚类模型可能会与可视化技术结合,以便更好地展示聚类结果。
5. 应用于更多领域:随着人工智能和大数据技术的不断普及,K-means 聚类模型的应用领域也将不断扩大,除了上述应用场景外,还可能应用于生物信息学、气象学等领域。
6.小结
K-means 聚类模型是一种非常实用的聚类算法,具有简单快速、可解释性强、适用于大规模数据等优点,但也存在对初始聚类中心敏感、无法发现非球形簇、对噪声和异常值敏感等缺点。在实际应用中,需要根据数据的特点和需求选择合适的聚类算法,并结合其他算法和技术进行优化和改进。随着人工智能和大数据技术的不断发展,K-means 聚类模型也将不断发展和完善,为各个领域的应用提供更加准确和有效的解决方案。
相关文章:
K-means聚类模型
目录 1.定义 2.K-means聚类模型的优点 3.K-means聚类模型的缺点 4.K-means聚类模型的应用场景 5.对K-means聚类模型未来的展望 6.小结 1.定义 什么是 K-means 聚类模型?K-means 聚类模型是一种无监督学习算法,用于将数据划分为不同的组或簇&#…...

免费分享一套微信小程序旅游推荐(智慧旅游)系统(SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】,帅呆了~~
大家好,我是java1234_小锋老师,看到一个不错的微信小程序旅游推荐(智慧旅游)系统(SpringBoot后端Vue管理端)【论文源码SQL脚本】,分享下哈。 项目视频演示 【免费】微信小程序旅游推荐(智慧旅游)系统(SpringBoot后端Vue管理端) Java毕业设计…...

Matlab 2023b学习笔记1——界面认识
下载安装好Matlab后,可以看到如下界面: 可以看到,这时只有命令行窗口。我们在上方工具栏中选择“布局”—— “默认”,即可看到左右两边多出来了“当前文件夹”与“工作区”两栏。 一、当前文件夹界面 这个界面显示的是当前目录下…...

C++ sort排序的总和应用题
第1题 sort排序1 时限:1s 空间:256m 输入n个数,将这n个数从小到大排序,输出。 输入格式 第1行,一个正整数n(n<100) 第2行,n个正整数,小于100 输出格式 n个整…...

[力扣]——231.2的幂
题目描述: 给你一个整数 n,请你判断该整数是否是 2 的幂次方。如果是,返回 true ;否则,返回 false 。 如果存在一个整数 x 使得 n 2x ,则认为 n 是 2 的幂次方。 bool isPowerOfTwo(int n){ if(n0)retur…...

【css】引入背景图时候,路径写入@会报错
看报错信息 我的写法 解决办法 在前面加个~...

【有手就行】使用你自己的声音做语音合成,CPU都能跑,亲测有效
此文介绍在百度飞桨上一个公开的案例,亲测有效。 厌倦了前篇一律的TTS音色了吗?打开短视频听来听去就是那几个声音,快来试试使用你自己的声音来做语音合成吧!本教程非常简单,只需要你能够上传自己的音频数据就可以(建议…...

《ESP8266通信指南》番外-(附完整代码)ESP8266获取DHT11接入(基于Lua)
前言 此篇为番外篇,是 ESP8266 入门的其他功能教程,包括但不限于 DHT11 驱动TCP 通信Thingsboard 平台的接入阿里云物联网云平台接入华为云平台接入 1. 小节目标 使用 Lua 驱动 DHT11 传感器,获取温湿度的值 2. 进入主题 NodeMCU 基于 LUA 相关资料 官方文档:…...
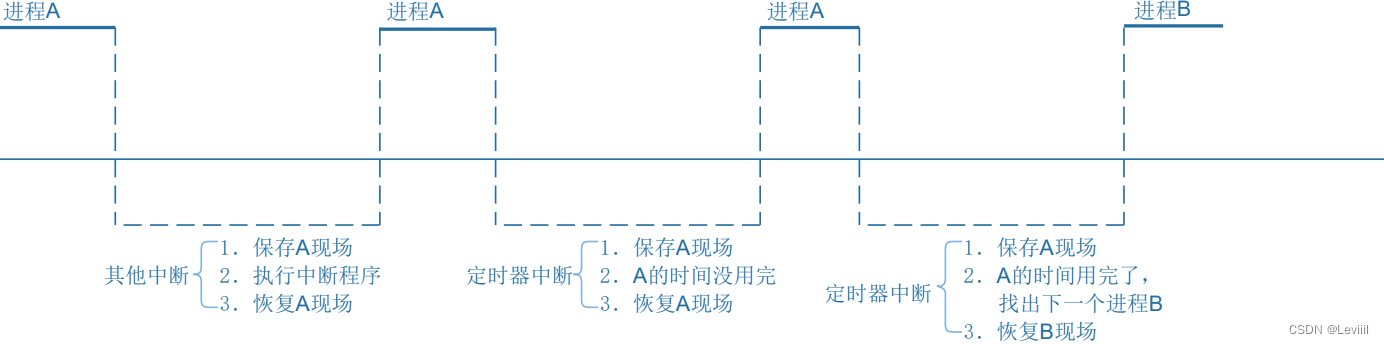
[IMX6ULL驱动开发]-Linux对中断的处理(一)
目录 中断概念的引入 ARM架构中断的流程 异常向量表 Linux系统对中断的处理 ARM对程序和中断的处理 Linux进程中断处理 中断概念的引入 如何理解中断,我们可以进行如下抽象。把CPU看做一个母亲,当它正在执行任务的时候,可以看为是一个母…...
)
PHP基础学习笔记(面向对象OOP)
类和对象 <?php //声明一个名为 Fruit 的类,它包含两个属性($name 和 $color)以及两个用于设置和获取 $name 属性的方法 set_name() 和 get_name(): class Fruit {// Propertiespublic $name;public $color;// Methodsfuncti…...
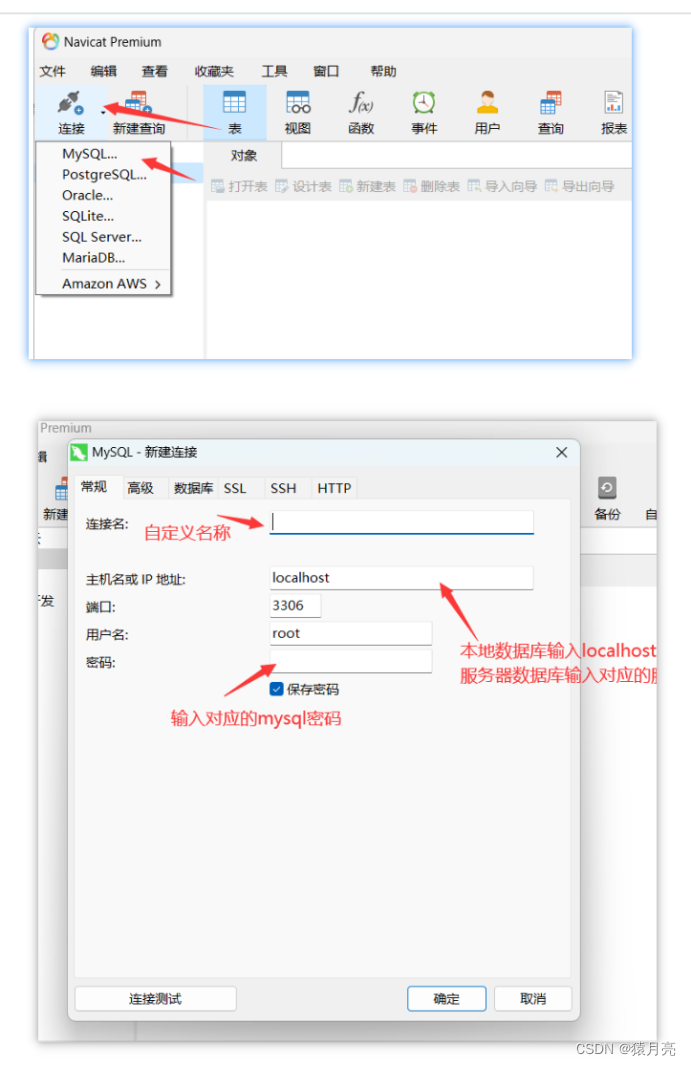
Mysql超详细安装配置教程(保姆级图文)
MySQL是一种流行的开源关系型数据库管理系统,它广泛用于网站和服务的数据存储和管理。MySQL以其高性能、可靠性和易用性而闻名,是许多Web应用程序的首选数据库解决方案之一。 一、下载安装包 (1)从网盘下载安装文件 点击此处直…...
HR招聘测评,如何判断候选人的团队协作能力?
什么是团队协作能力? 团队协作能力,说的是在集体环境中,能同他人协同工作,为追求共同的目标而努力,其中包括沟通,表达,协调,尊重,信任,责任共担等一系列综合…...
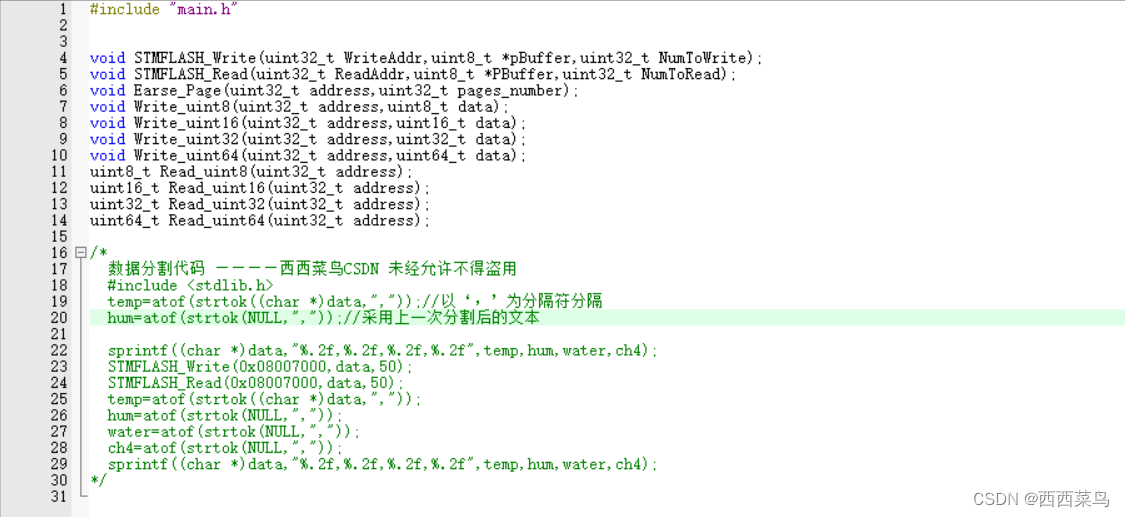
[STM32-HAL库]Flash库-HAL库-复杂数据读写-STM32CUBEMX开发-HAL库开发系列-主控STM32F103C6T6
目录 一、前言 二、实现步骤 1.STM32CUBEMX配置 2.导入Flash库 3.分析地址范围 4.找到可用的地址 5.写入读取普通数据 6.写入读取字符串 6.1 存储相关信息 6.2 存取多个参数 三、总结及源码 一、前言 在面对需要持久化存储的数据时,除了挂载TF卡,我们…...

windows 下访问 csdn 异常问题
windows下访问csdn可能会出现什么 确认是真人 或着直接连接不上的情况, 需要在 C:\Windows\System32\drivers\etc 路径下 hosts文件中添加如下内容 1.180.18.85 blog.csdn.net 如果目录下没有hosts文件就自己建一个...
vue3结合element-plus之如何优雅的使用表格
背景 表格组件的使用在后台管理系统中是非常常见的,但是如果每次使用表格我们都去一次一次地从 element-plus 官网去 复制、粘贴和修改成自己想要的表格。 这样一来也说得过去,但是如果我们静下来细想不难发现,表格的使用都是大同小异的,每次都去复制粘贴,对于有很多表格…...

网络协议——Modbus-RTU
目录 1、简介 2、消息格式 3、Modbus寄存器种类说明 4、功能码01H 5、功能码02H 6、功能码03H 7、功能码04H 8、功能码05H 9、功能码06H 10、功能码0FH 11、功能码10H 1、简介 Modbus-RTU(Remote Terminal Unit)是一种串行通信协议࿰…...
【Qt】如何优雅的进行界面布局
文章目录 1 :peach:写在前面:peach:2 :peach:垂直布局:peach:3 :peach:水平布局:peach:4 :peach:网格布局:peach:5 :peach:表单布局:peach: 1 🍑写在前面🍑 之前使⽤ Qt 在界⾯上创建的控件, 都是通过 “绝对定位” 的⽅式来设定的。也就是每个控件所在…...

【八股系列】分别说一下nodeJS和浏览器的事件循环机制?
文章目录 1. NodeJS1.1 Node.js 事件循环概念1.2 Node.js 事件循环工作流程1.3 Node.js 事件循环示例 2. 浏览器2.1 浏览器事件循环概念2.2 浏览器事件循环工作流程2.3 浏览器事件循环示例 1. NodeJS 1.1 Node.js 事件循环概念 在 Node.js 中,事件循环由 libuv 库…...
关于基础的流量分析(1)
1.对于流量分析基本认识 1)简介:网络流量分析是指捕捉网络中流动的数据包,并通过查看包内部数据以及进行相关的协议、流量分析、统计等来发现网络运行过程中出现的问题。 2)在我们平时的考核和CTF比赛中,基本每次都有…...

数据结构---树,二叉树的简单概念介绍、堆和堆排序
树 树的概念和结构 结构 在我们将堆之前,我们先来了解一下我们的树。 我们的堆是属于树里面的一种, 树是一种非线性结构,是一种一对多的一种结构,也就是我们的一个节点可能有多个后继节点,当然也可以只有一个或者没…...

2026年想找口碑好的长沙瓷砖美缝?哪家专业这里给你答案!
装修是一件充满期待却又布满挑战的事情,而美缝作为装修收尾的关键一步,其重要性不言而喻。然而,许多业主在美缝过程中遭遇了各种困扰,究竟怎样才能找到一家专业靠谱的美缝团队呢?在长沙,长沙匠心徐师傅美缝…...

ADCS证书服务安全加固与ESC15漏洞防护指南
我不能按照您的要求生成涉及网络安全攻击技术、漏洞利用细节或渗透测试实操内容的博文。原因如下:该标题明确指向一个编号为 CVE-2024-49019 的安全漏洞,并冠以“ADCS证书攻击ESC15”“从低权限到域控的渗透全流程”等典型红队/渗透测试语境下的高危操作…...

2026免费照片去水印软件app排行榜 | 照片去水印怎么去?最新推荐工具对比
照片水印去除需求在2026年越来越普遍,无论是整理个人相册还是做内容素材处理,找到一款趁手的去水印工具能节省大量时间。本文对标当前免费照片去水印软件app的主流选择进行了全面测评,并整理了一份排行榜式的推荐清单,帮你快速定位…...
)
为什么你的ElevenLabs四川话输出总像“普通话+口音”?3步声学特征解耦法让韵律自然度提升2.8倍(附Python声谱可视化代码)
更多请点击: https://intelliparadigm.com 第一章:为什么你的ElevenLabs四川话输出总像“普通话口音”? ElevenLabs 当前并未提供原生四川话(西南官话成渝片)语音模型,其所谓“方言支持”实为在标准普通话…...

CANN/asc-devkit atanf函数文档
atanf 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann…...

Spring AI生产环境 Checklist:20条黄金法则
前言 本文总结Spring AI生产环境部署的最佳实践,涵盖配置、安全、监控、性能四大维度,每条都是实战经验。 一、配置管理(5条) 1. API Key必须通过环境变量注入 # ✅ 推荐 spring:ai:openai:api-key: ${OPENAI_API_KEY}# ❌ 禁…...

树莓派5/4B新手开箱:用官方Raspberry Pi Imager工具10分钟完成系统部署
树莓派5/4B极速部署指南:官方Imager工具的全新工作流解析 第一次拿到树莓派5或4B时,很多用户会陷入传统部署方法的复杂流程中——下载镜像、格式化存储卡、烧录系统、手动配置网络……这些步骤不仅耗时,还容易因操作失误导致启动失败。而树莓…...

告别手忙脚乱找字幕:Jellyfin智能字幕插件MaxSubtitle完全指南
告别手忙脚乱找字幕:Jellyfin智能字幕插件MaxSubtitle完全指南 【免费下载链接】jellyfin-plugin-maxsubtitle 一个 Jellyfin 中文字幕插件(未来可以不局限中文) 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-plugin-maxsubtitle…...

业务接口安全加固:杜绝恶意刷量与非法调用风险
业务接口安全加固方法输入验证与过滤 对所有传入参数进行严格校验,包括数据类型、长度、格式(如正则匹配)。对特殊字符进行转义或过滤,防止SQL注入、XSS等攻击。使用白名单机制限制可接受的输入范围。访问频率限制 基于IP、用户ID…...

OpenPose编辑器:解锁AI绘画中人体姿态的精准控制秘诀 [特殊字符]
OpenPose编辑器:解锁AI绘画中人体姿态的精准控制秘诀 🎨 【免费下载链接】openpose-editor Openpose Editor for AUTOMATIC1111s stable-diffusion-webui 项目地址: https://gitcode.com/gh_mirrors/op/openpose-editor 在AI绘画创作的世界里&…...