es问题汇总--待完善
1. 查询某个索引库中数据总量
方式一:
CountRequest 鄙人喜欢这种方式
public long getTotalNum(String indexName) throws IOException {CountRequest countRequest = new CountRequest(indexName);// 如果需要,你可以在这里添加查询条件// countRequest.query(QueryBuilders.matchQuery("field_name", "value"));CountResponse countResponse = esHighLevelClient.count(countRequest, RequestOptions.DEFAULT);return countResponse.getCount();}
方式二:
SearchRequest 这种方式只能查询出10000条。
SearchRequest searchRequest = new SearchRequest();searchRequest.indices(index);SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();sourceBuilder.query(QueryBuilders.matchAllQuery());System.out.println("SDL语句:"sourceBuilder);searchRequest.source(sourceBuilder);SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);long value = response.getHits().getTotalHits().value;System.out.println("数据总量:"+value);
优化方式,设置trackTotalHits(true)则可以获取数据总量
sourceBuilder.trackTotalHits(true);
2. 分页问题
分页类型:
- 浅分页
- 深度分页
浅分页 from+size
适用场景:适用于数据量不大、实时性要求高的场景。
示例代码
SearchRequest searchRequest2 = new SearchRequest();searchRequest2.indices(index);SearchSourceBuilder sourceBuilder2 = new SearchSourceBuilder();for (int i = 1; i <= totalPage; i++) {//---------------from + sizesourceBuilder2.from((i - 1) * 300);System.out.println("起始索引是:"+(i - 1) * 300);sourceBuilder2.size(300);searchRequest2.source(sourceBuilder2);SearchResponse searchResponse = restHighLevelClient.search(searchRequest2, RequestOptions.DEFAULT);SearchHits hits = searchResponse.getHits();SearchHit[] hits1 = hits.getHits();System.out.println("xxxx");}System.out.println("完成");当起始索引+每页显示条数 from+size大于10000时,报错:
result window is too large, from + size must be less than or equal to
原因:
系统默认限制10000条。
系统为什么限制10000条?
es分页原理:
------比如,现在要from为990,size为10,es会从每个分片中拿到前1000条数据,假如这个索引现在有4个分片,那么就会拿到4000条数据,然后在内存中对这4000条数据进行排序,然后从这4000条文档中取出前10条数据,4000条数据的存储,排序等操作都是在内存中完成,非常耗费资源。
------如果分页再继续深入下去,比如from为9990,size为10,那么就会从每个分片中先拿到前10000条数据,4个分片就是40000条数据,这时就要把4万条数据在内存中存储、排序等。如果分页再继续深入下去,也就是(from+size)*分片数量越大 ,越消耗资源,而且是倍数增长。
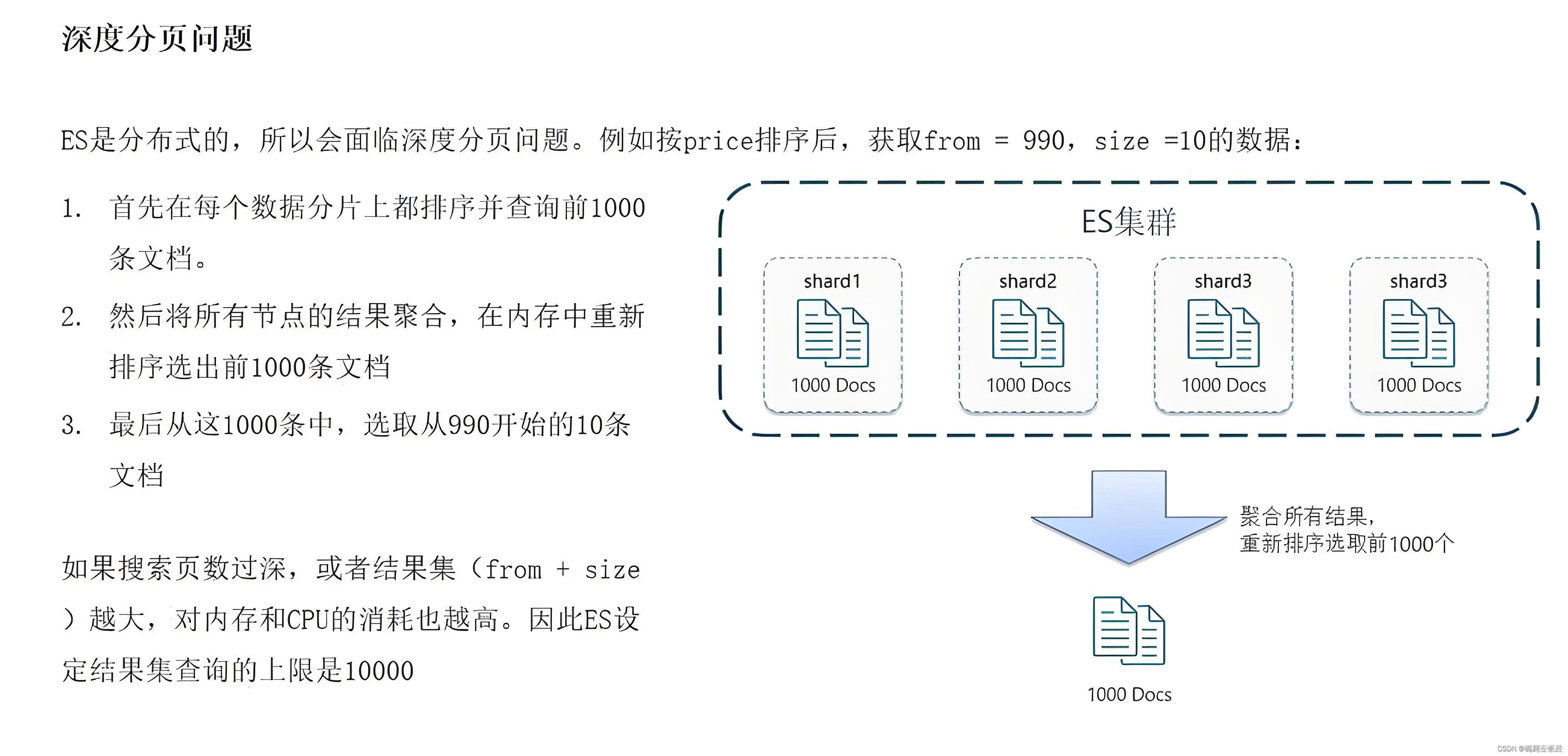
解决方案:
还是用from+size的方式进行分页,但是设置索引库index.max_result_window的值即可。
PUT yourindex/_settings
{"index.max_result_window": "1000000"
}
max_result_window 最大限制为 10亿
不推荐
参考:https://huaweicloud.csdn.net/637ee8fadf016f70ae4c9702.html
虽然这样设置在大数据量分页查询时能够解决result window is too large, from + size must be less than or equal to 这个问题,但是不推荐这样使用。
因为其会带来严重的后果,最常见的就是后期频繁的 OOM,而且很难发现原因。
看一下官方对该参数的解释:

ax_result_window本身是对JVM的一种保护机制,通过设定一个合理的阈值,避免初学者分页查询时由于单页数据过大而导致OOM。
在很多业务场景中经常需要查询10000条以后的数据,当遇到不能查询10000条以后的数据的问题之后,网上的很多答案会告诉你可以通过放开这个参数的限制,将其配置为100万,甚至1000万就行。
但是如果仅仅放开这个参数就行,那么这个参数限制的意义有何在呢?如果你不知道这个参数的意义,很可能导致的后果就是频繁的发生OOM而且很难找到原因
那么这个参数就完全不能动吗?当然不是,设置一个合理的参数阈值是需要通过你的各项指标参数来衡量确定的,比如你用户量、数据量、物理内存的大小、分片的数量等等。通过监控数据和分析各项指标从而确定一个最佳值,并非越大越好。
建议如果你不是对 ES 有足够的了解和使用经验,不要轻易修改max_result_window参数的阈值!
所以当数据量非常大时,分页就不要用form+size,推荐使用深度分页
深度分页 scroll
使用方式:
scroll 原理:
scroll 分页方式的原理与游标(cursor)类似。当你执行一个带有 scroll 参数的搜索查询时,Elasticsearch会为这次搜索创建一个快照(snapshot),并存储相关的搜索上下文(search context)。这个上下文包括查询本身、排序方式、聚合等所有与搜索相关的信息。
- 首次POST /_search/scroll请求会返回一部分结果(基于size参数)以及一个scroll_id。
- 使用这个scroll_id,你可以通过后续的POST /_search/scroll请求来获取更多的结果。
- scroll参数定义了在多长时间内可以保持scroll上下文有效。如果在这个时间内没有新的scroll请求,那么scroll上下文就会被删除,无法再获取更多结果。
使用RestHighLevelClient
适用场景:如日志导出、数据迁移等,当不适用于用户界面的分页。因为scroll获取的数据不是实时性的,而是保存快照那一刻的数据,也就意味着即使有新数据写入,也不会被包含在查询结果中。
// 初始化scroll搜索
POST /_search/scroll
{"size": 100, // 每次返回的文档数量"scroll": "1m", // 保持scroll上下文的活动时间,这里是1分钟"query": {"match_all": {} // 可替换为任何需要的查询条件}
}// 后续的scroll请求(在第一次请求返回后)
POST /_search/scroll
{"scroll": "1m", // 保持与第一次请求相同的scroll上下文时间"scroll_id": "你的scroll_id" // 第一次请求返回的scroll_id
}
public void TestScroll() throws IOException {SearchRequest searchRequest = new SearchRequest(index);//创建查询条件SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchAllQuery());// 设置每批获取的数量searchSourceBuilder.size(1000);searchRequest.source(searchSourceBuilder);// 设置滚动时间searchRequest.scroll(TimeValue.timeValueMinutes(5));SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);String scrollId = searchResponse.getScrollId();do {for (SearchHit hit : searchResponse.getHits().getHits()) {//TODO 处理搜索结果System.out.println(hit.getSourceAsMap());}// 使用当前的滚动ID进行下一个批次的搜索SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);scrollRequest.scroll(TimeValue.timeValueMinutes(5));scrollId = searchResponse.getScrollId();searchResponse = restHighLevelClient.scroll(scrollRequest, RequestOptions.DEFAULT);} while (searchResponse.getHits().getHits().length != 0);//清除Scroll请求状态ClearScrollRequest clearScrollRequest = new ClearScrollRequest();clearScrollRequest.addScrollId(scrollId);restHighLevelClient.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);}
深度分页 search_after
参考:https://blog.csdn.net/u011250186/article/details/125483759
原理
实现原理:
search_after 分页的方式是根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。
说明:
为了找到每一页最后一条数据,每个文档必须有一个全局唯一值,官方推荐使用 _uid 作为全局唯一值,其实使用业务层的 id 也可以。
说明:使用search_after查询需要将from设置为0或-1,当然也可以不写。
需要注意的是:
1)sort字段的选择
如果search_after中的关键字为***,那么***123的文档也会被搜索到,所以在选择search_after的排序字段时需要谨慎,可以使用比如文档的id或者时间戳等。另外,search_after并不是随机的查询某一页数据,而是并行的滚屏查询;search_after的查询顺序会在更新和删除时发生变化,也就是说支持实时的数据查询。
2)无法跳页请求
因为每一页的数据依赖于上一页最后一条数据,所以无法跳页请求。
public void TestSearchAfter() throws Exception {SearchRequest searchRequest = new SearchRequest();searchRequest.indices(index);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.from(0).size(1000);searchSourceBuilder.query(QueryBuilders.matchAllQuery());// 指定排序,并设置sort values为上一次查询的最后一条记录的sort valuessearchSourceBuilder.sort("_id", SortOrder.ASC);List<Map<String, Object>> mapList = new ArrayList<>();this.search(searchRequest,searchSourceBuilder,mapList, null);System.out.println(mapList.size());}private void search(SearchRequest searchRequest,SearchSourceBuilder searchSourceBuilder,List<Map<String, Object>> totalList, Object[] objects) throws Exception{if(Objects.nonNull(objects)){searchSourceBuilder.searchAfter(objects);}searchRequest.source(searchSourceBuilder);System.out.println(searchSourceBuilder);SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);SearchHit[] hits = searchResponse.getHits().getHits();if(Objects.nonNull(hits) && hits.length > 0){List<Map<String, Object>> collect = Arrays.stream(hits).map(SearchHit::getSourceAsMap).collect(Collectors.toList());//TODO 处理数据 ,可以不要 totalList参数 totalList.addAll(collect);search(searchRequest,searchSourceBuilder,totalList,hits[hits.length - 1].getSortValues());}}
相关文章:
es问题汇总--待完善
1. 查询某个索引库中数据总量 方式一: CountRequest 鄙人喜欢这种方式 public long getTotalNum(String indexName) throws IOException {CountRequest countRequest new CountRequest(indexName);// 如果需要,你可以在这里添加查询条件// countReques…...

python 线性回归模型
教材链接-3.2. 线性回归的从零开始实现 c实现 该博客仅用于记录一下自己的代码,可与c实现作为对照 from d2l import torch as d2l import torch import random # nn是神经网络的缩写 from torch import nn from torch.utils import data# 加载训练数据 # 加载训…...
pcl::transformPointCloud()用法及注意事项
函数用法 #include <pcl/common/transforms.h> pcl::transformPointCloud(const pcl::PointCloud<PointT> &cloud_in, pcl::PointCloud<PointT> &cloud_out, const Eigen::Matrix4f &transform) 其中cloud_in, cloud_out的类型为pcl::PointClo…...

图像超分辨率重建相关概念、评价指标、数据集、模型
1、图像超分辨率概念 1.1 基本定义 超分辨率(Super-Resolution),简称超分(SR)。是指利用光学及其相关光学知识,根据已知图像信息恢复图像细节和其他数据信息的过程,简单来说就是增大图像的分辨…...

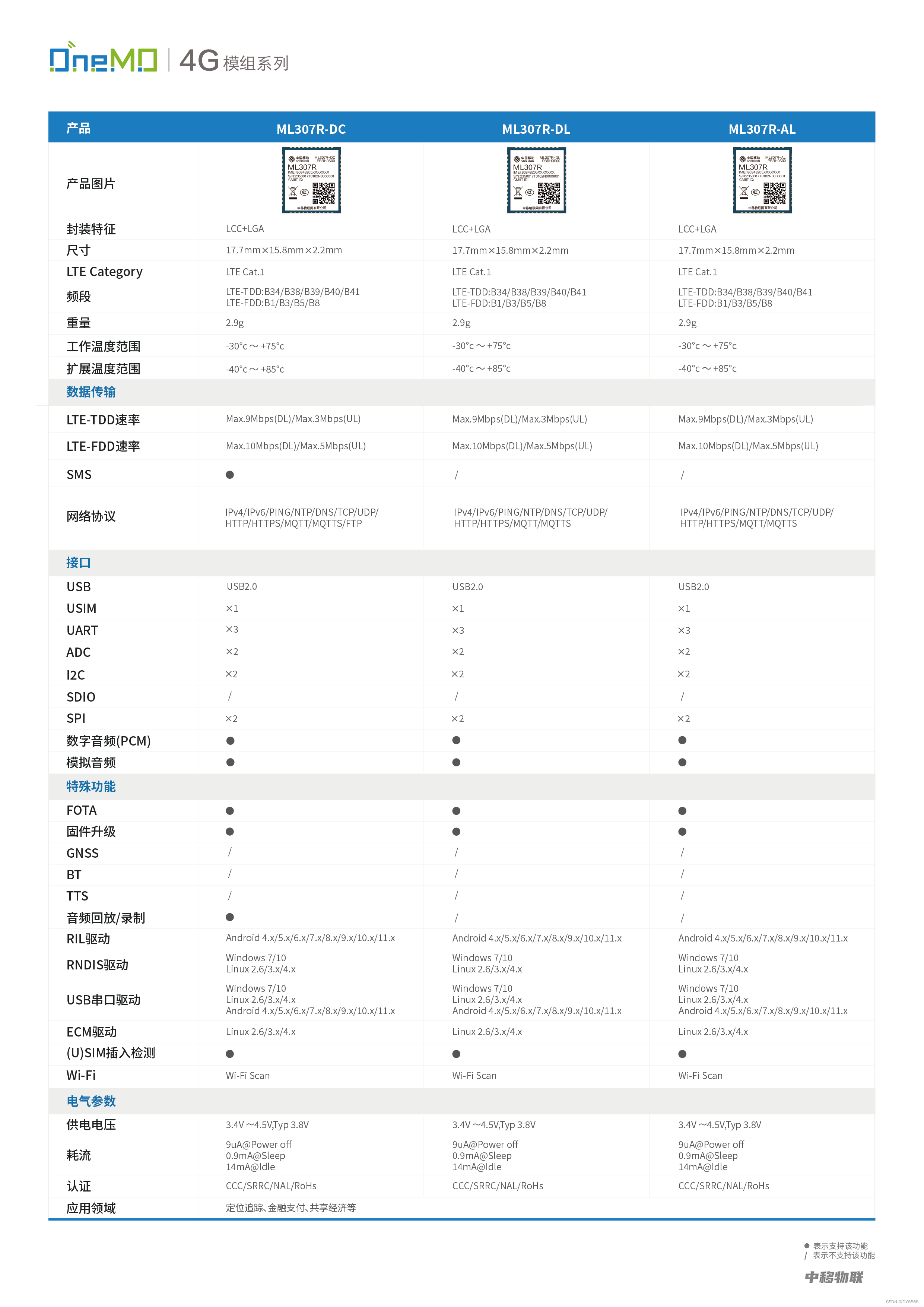
中移物联OneMO Cat.1模组推动联网POS规模应用
在第三方支付蓬勃发展和消费模式不断革新的时代背景下,新型联网POS终端以其智能化、便捷化的特点丰富人们生活便利度。在这一变革浪潮中,中移物联OneMO Cat.1模组ML307R凭借其卓越的性能和成本效益,成为推动联网POS规模应用的重要力量。 性能…...
二.常见算法--贪心算法
(1)单源点最短路径问题 问题描述: 给定一个图,任取其中一个节点为固定的起点,求从起点到任意节点的最短路径距离。 例如: 思路与关键点: 以下代码中涉及到宏INT_MAX,存在于<limits.h>中…...
LabVIEW高温往复摩擦测试系统中PID控制
在LabVIEW开发高温往复摩擦测试系统中实现PID控制,需要注意以下几个方面: 1. 系统建模与参数确定 物理模型建立: 首先,需要了解被控对象的物理特性,包括热惯性、摩擦系数等。这些特性决定了系统的响应速度和稳定性。实验数据获取…...

配置yum源
以下是在 Linux 系统中配置新的 yum 源的一般步骤和命令示例(以 CentOS 系统为例): 备份原有 yum 源配置文件:mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak 创建新的 yum 源配置文件(…...
数据技术篇之数据同步)
深入理解数仓开发(二)数据技术篇之数据同步
1、数据同步 数据同步我们之前在数仓当中使用了多种工具,比如使用 Flume 将日志文件从服务器采集到 Kafka,再通过 Flume 将 Kafka 中的数据采集到 HDFS。使用 MaxWell 实时监听 MySQL 的 binlog 日志,并将采集到的变更日志(json 格…...
—— 类与对象(二))
C++语言学习(六)—— 类与对象(二)
目录 一、对象数组 二、对象指针 三、this 指针 四、类类型作为参数类型的三种形式 4.1 对象本身作为参数 4.2 对象指针作为参数 4.3 对象引用作为参数 五、静态成员 5.1 静态数据成员 5.2 静态成员函数 六、友元机制 6.1 友元函数 6.2 友元类 七、类的组合 八、…...

3d选择模型后不能旋转什么原因?怎么解决?---模大狮模型网
在3D建模和渲染的过程中,旋转模型是常见的操作。然而,有时在选择了模型后,却发现无法进行旋转,这可能会让许多用户感到困扰。本文将探讨3D选择模型后不能旋转的可能原因,并提供相应的解决方法。 一、3D选择模型后不能旋…...

从入门到精通:详解Linux环境基础开发工具的使用
前言 在这篇文章中,我将深入学习和理解Linux环境基础开发工具的使用。无论你是初学者还是有一定经验的开发者,相信这篇文章都会对你有所帮助。我们将详细讲解软件包管理器、编辑器、编译器、调试器、自动化构建工具以及版本控制工具的使用。 Linux软件…...
安装 node)
linux(centos 7)安装 node
linux(centos 7)安装 node 下载对应版本&安装解压配置环境变量使配置文件生效验证是否安装成功附加 目前node最新版本是 node-v22.0.0 官网下载地址:https://registry.npmmirror.com/binary.html?pathnode/latest-v22.x/node-v22.0.0-li…...

C++之第九课
课程列表 今天,我们要学习一种结构:循环结构。 循环的方法有3种。 今天先将第1种for学了: int a;//循环变量 int b; for(a1;a<10;a){//像if那样“打包”cout<<a<<" ";b; } 当然,也可以这样写&#…...

618精选编程书单推荐:优质知识提升你的代码力
前言 在这个快速发展的技术时代,不断学习和提升自己的编程技能是每位程序员的必修课。今天,我为大家精心挑选了一系列编程技术书籍,它们将是你技术成长道路上的宝贵财富。 文章目录 前言编程之路:为何阅读书籍是不可或缺的书籍的…...

使用httpx异步获取高校招生信息:一步到位的代理配置教程
概述 随着2024年中国高考的临近,考生和家长对高校招生信息的需求日益增加。了解各高校的专业、课程设置和录取标准对于高考志愿填报至关重要。通过爬虫技术,可以高效地从各高校官网获取这些关键信息。然而,面对大量的请求和反爬机制的挑战&a…...

使用Java Stream API的map方法将包含Long类型ID的流转换为String数组
在这个例子中,idList是一个包含Long类型ID的列表。我们使用stream()方法创建一个流,然后应用map(String::valueOf)方法将Long类型的ID转换为String类型。最后,我们使用toArray(String[]::new)方法将流中的元素收集到一个新的String[]数组中。…...

centos 安装nginx 并配置https ssl
进入你要安装的目录 一般是/usr/local/ wget https://nginx.org/download/nginx-1.24.0.tar.gz解压安装包:使用以下命令解压下载的Nginx安装包: tar -zxvf nginx-1.24.0.tar.gz在编译和安装Nginx之前,确保您的系统上已安装了必要的编译工具和…...

Jenkins 自动化部署
Post Steps部分 Exec cmmand cd /data/build/test-admin/ rm -f app.jar rm -f Dockerfile cp target/app.jar ./ cp docker/Dockerfile ./docker build -t test-admin . docker tag test-admin 192.168.1.100/test/test-admin:1.2-SNAPSHOT docker push 192.168.1.100/test/…...

Vue3拖拽缩放组件:如何用5分钟为你的应用添加专业级交互体验
Vue3拖拽缩放组件:如何用5分钟为你的应用添加专业级交互体验 【免费下载链接】vue3-draggable-resizable [Vue3 组件] 用于拖拽调整位置和大小的的组件,同时支持元素吸附对齐,实时参考线。 项目地址: https://gitcode.com/gh_mirrors/vu/vu…...

如何高效下载QQ音乐资源:5个简单步骤掌握res-downloader嗅探技术
如何高效下载QQ音乐资源:5个简单步骤掌握res-downloader嗅探技术 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

AI学习者的进度同步协议:Newsletter如何重构自学路径
1. 这不是一份普通 newsletter:它是一份 AI 学习者的“进度同步协议”“Learn AI Together — Towards AI Community Newsletter #14”——看到这个标题,别急着划走。它既不是某家大厂的公关通稿,也不是知识付费平台的引流钩子,更…...
为9.2%)
2026-2032期间,全球半导体设备零部件PVD和ALD熔射服务市场年复合增长率(CAGR)为9.2%
QYResearch调研显示,2025年全球半导体设备零部件PVD和ALD熔射服务市场规模大约为0.58亿美元,预计2032年将达到1.07亿美元,2026-2032期间年复合增长率(CAGR)为9.2%。行业竞争格局与细分市场市场分析全球半导体设备零部件…...

Office技巧速成:3个让效率翻倍的实用方法
表格操作总出错怎么办众多人于运用Excel开展数据处理工作之际,时常会被合并单元格以及公式报错等情形搞得疲惫不堪,焦头烂额。实际上,要是认真细细探究一番,便会发觉,大部分这类问题均是起因于对 Excel 基本功能欠缺熟…...

WarcraftHelper:5分钟解决魔兽争霸III现代兼容性问题的终极指南
WarcraftHelper:5分钟解决魔兽争霸III现代兼容性问题的终极指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典魔兽争霸III在W…...

Rufus技术演进:从Windows 7告别到现代USB启动盘工具的重构之路
Rufus技术演进:从Windows 7告别到现代USB启动盘工具的重构之路 【免费下载链接】rufus The Reliable USB Formatting Utility 项目地址: https://gitcode.com/GitHub_Trending/ru/rufus 在开源工具生态中,技术栈的更新换代往往伴随着兼容性的艰难…...

VHDL代码智能解析:基于大模型的硬件设计辅助实践
1. 项目背景与核心挑战在当今高性能处理器设计领域,VHDL作为硬件描述语言(HDL)的重要成员,因其严格的类型检查和结构化语法特性,被广泛应用于航空航天、汽车电子等关键行业。然而,随着芯片设计复杂度呈指数级增长,设计…...

用随机森林实现手写大写字母识别的完整实践
1. 项目概述:用随机森林搞定手写信件识别,这事儿比你想象中更接地气 “How To Perform Letter Recognition in Python Using Random Forest Classifier”——这个标题乍看像教科书里的章节名,但实际拆开来看,它直指一个非常典型、…...

全栈开发的核心技能:掌握这4个技术,成为全栈工程师
对于很多深耕测试领域多年的软件测试从业者来说,“转全栈开发”早已不是一个陌生的方向——无论是为了突破职业瓶颈,还是为了打通测试到开发的链路,提升自己的端到端交付能力,抑或是拓展职业选择的边界,全栈工程师都是…...