tomcat请求数据解析过程
前面提到tomcat请求处理的io交互过程,现在开始看下经过io交互后tomcat是怎么处理请求数据的。首先到AbstractProtocol.java中的process方法,注意这个方法是在tomcat线程池分配的线程调用的。生成用来对请求字节流数据进行解析的Http11Processor。
public SocketState process(SocketWrapperBase<S> wrapper, SocketEvent status) {......Processor processor = (Processor) wrapper.takeCurrentProcessor();......try {......if (processor == null) {processor = recycledProcessors.pop();......}if (processor == null) {processor = getProtocol().createProcessor();register(processor);......}do {state = processor.process(wrapper, status);......} while (state == SocketState.UPGRADING);}
//默认为 Http11Processor protected Processor createProcessor() {Http11Processor processor = new Http11Processor(this, adapter);return processor;}
然后在生成的Http11Processor的service方法中对请求字节流数据进行正式的解析。
- 请求行解析
请求行格式如GET / HTTP/1.1,首先跳过空行,然后读取请求方式,再读取请求url,之后解析协议版本,逻辑很清晰。注意这里是在fill(false)方法中读取nio的ByteBuffer的数据。
boolean parseRequestLine(boolean keptAlive, int connectionTimeout, int keepAliveTimeout) throws IOException {// check stateif (!parsingRequestLine) {return true;}//// Skipping blank lines// 跳过空行if (parsingRequestLinePhase < 2) {do {// Read new bytes if neededif (byteBuffer.position() >= byteBuffer.limit()) {if (keptAlive) {// Haven't read any request data yet so use the keep-alive// timeout.wrapper.setReadTimeout(keepAliveTimeout);}//读取nio中ByteBuffer中数据if (!fill(false)) {// A read is pending, so no longer in initial stateparsingRequestLinePhase = 1;return false;}// At least one byte of the request has been received.// Switch to the socket timeout.wrapper.setReadTimeout(connectionTimeout);}if (!keptAlive && byteBuffer.position() == 0 && byteBuffer.limit() >= CLIENT_PREFACE_START.length) {boolean prefaceMatch = true;for (int i = 0; i < CLIENT_PREFACE_START.length && prefaceMatch; i++) {if (CLIENT_PREFACE_START[i] != byteBuffer.get(i)) {prefaceMatch = false;}}if (prefaceMatch) {// HTTP/2 preface matchedparsingRequestLinePhase = -1;return false;}}// Set the start time once we start reading data (even if it is// just skipping blank lines)if (request.getStartTime() < 0) {request.setStartTime(System.currentTimeMillis());}chr = byteBuffer.get();} while (chr == Constants.CR || chr == Constants.LF);byteBuffer.position(byteBuffer.position() - 1);parsingRequestLineStart = byteBuffer.position();parsingRequestLinePhase = 2;}//解析请求方式if (parsingRequestLinePhase == 2) {//// Reading the method name// Method name is a token//boolean space = false;while (!space) {// Read new bytes if neededif (byteBuffer.position() >= byteBuffer.limit()) {if (!fill(false)) {return false;}}// Spec says method name is a token followed by a single SP but// also be tolerant of multiple SP and/or HT.int pos = byteBuffer.position();chr = byteBuffer.get();//http请求的开头字符为请求方式,以 空格(' ')或制表('\t')结尾if (chr == Constants.SP || chr == Constants.HT) {space = true;request.method().setBytes(byteBuffer.array(), parsingRequestLineStart,pos - parsingRequestLineStart);} else if (!HttpParser.isToken(chr)) {// Avoid unknown protocol triggering an additional errorrequest.protocol().setString(Constants.HTTP_11);String invalidMethodValue = parseInvalid(parsingRequestLineStart, byteBuffer);throw new IllegalArgumentException(sm.getString("iib.invalidmethod", invalidMethodValue));}}parsingRequestLinePhase = 3;}// 去除空字符if (parsingRequestLinePhase == 3) {// Spec says single SP but also be tolerant of multiple SP and/or HTboolean space = true;while (space) {// Read new bytes if neededif (byteBuffer.position() >= byteBuffer.limit()) {if (!fill(false)) {return false;}}chr = byteBuffer.get();if (chr != Constants.SP && chr != Constants.HT) {space = false;byteBuffer.position(byteBuffer.position() - 1);}}parsingRequestLineStart = byteBuffer.position();parsingRequestLinePhase = 4;}//解析urlif (parsingRequestLinePhase == 4) {// Mark the current buffer positionint end = 0;//// Reading the URI//boolean space = false;while (!space) {// Read new bytes if neededif (byteBuffer.position() >= byteBuffer.limit()) {if (!fill(false)) {return false;}}int pos = byteBuffer.position();prevChr = chr;chr = byteBuffer.get();if (prevChr == Constants.CR && chr != Constants.LF) {// CR not followed by LF so not an HTTP/0.9 request and// therefore invalid. Trigger error handling.// Avoid unknown protocol triggering an additional errorrequest.protocol().setString(Constants.HTTP_11);String invalidRequestTarget = parseInvalid(parsingRequestLineStart, byteBuffer);throw new IllegalArgumentException(sm.getString("iib.invalidRequestTarget", invalidRequestTarget));}if (chr == Constants.SP || chr == Constants.HT) {space = true;end = pos;} else if (chr == Constants.CR) {// HTTP/0.9 style request. CR is optional. LF is not.} else if (chr == Constants.LF) {// HTTP/0.9 style request// Stop this processing loopspace = true;// Set blank protocol (indicates HTTP/0.9)request.protocol().setString("");// Skip the protocol processingparsingRequestLinePhase = 7;if (prevChr == Constants.CR) {end = pos - 1;} else {end = pos;}} else if (chr == Constants.QUESTION && parsingRequestLineQPos == -1) {parsingRequestLineQPos = pos;} else if (parsingRequestLineQPos != -1 && !httpParser.isQueryRelaxed(chr)) {// Avoid unknown protocol triggering an additional errorrequest.protocol().setString(Constants.HTTP_11);// %nn decoding will be checked at the point of decodingString invalidRequestTarget = parseInvalid(parsingRequestLineStart, byteBuffer);throw new IllegalArgumentException(sm.getString("iib.invalidRequestTarget", invalidRequestTarget));} else if (httpParser.isNotRequestTargetRelaxed(chr)) {// Avoid unknown protocol triggering an additional errorrequest.protocol().setString(Constants.HTTP_11);// This is a general check that aims to catch problems early// Detailed checking of each part of the request target will// happen in Http11Processor#prepareRequest()String invalidRequestTarget = parseInvalid(parsingRequestLineStart, byteBuffer);throw new IllegalArgumentException(sm.getString("iib.invalidRequestTarget", invalidRequestTarget));}}if (parsingRequestLineQPos >= 0) {request.queryString().setBytes(byteBuffer.array(), parsingRequestLineQPos + 1,end - parsingRequestLineQPos - 1);request.requestURI().setBytes(byteBuffer.array(), parsingRequestLineStart,parsingRequestLineQPos - parsingRequestLineStart);} else {//把解析到的url记下来request.requestURI().setBytes(byteBuffer.array(), parsingRequestLineStart,end - parsingRequestLineStart);}// HTTP/0.9 processing jumps to stage 7.// Don't want to overwrite that here.if (parsingRequestLinePhase == 4) {parsingRequestLinePhase = 5;}}if (parsingRequestLinePhase == 5) {// Spec says single SP but also be tolerant of multiple and/or HTboolean space = true;while (space) {// Read new bytes if neededif (byteBuffer.position() >= byteBuffer.limit()) {if (!fill(false)) {return false;}}byte chr = byteBuffer.get();if (chr != Constants.SP && chr != Constants.HT) {space = false;byteBuffer.position(byteBuffer.position() - 1);}}parsingRequestLineStart = byteBuffer.position();parsingRequestLinePhase = 6;// Mark the current buffer positionend = 0;}//协议版本if (parsingRequestLinePhase == 6) {//// Reading the protocol// Protocol is always "HTTP/" DIGIT "." DIGIT//while (!parsingRequestLineEol) {// Read new bytes if neededif (byteBuffer.position() >= byteBuffer.limit()) {if (!fill(false)) {return false;}}int pos = byteBuffer.position();prevChr = chr;chr = byteBuffer.get();if (chr == Constants.CR) {// Possible end of request line. Need LF next else invalid.} else if (prevChr == Constants.CR && chr == Constants.LF) {// CRLF is the standard line terminatorend = pos - 1;parsingRequestLineEol = true;} else if (chr == Constants.LF) {// LF is an optional line terminatorend = pos;parsingRequestLineEol = true;} else if (prevChr == Constants.CR || !HttpParser.isHttpProtocol(chr)) {String invalidProtocol = parseInvalid(parsingRequestLineStart, byteBuffer);throw new IllegalArgumentException(sm.getString("iib.invalidHttpProtocol", invalidProtocol));}}if (end - parsingRequestLineStart > 0) {request.protocol().setBytes(byteBuffer.array(), parsingRequestLineStart, end - parsingRequestLineStart);parsingRequestLinePhase = 7;}// If no protocol is found, the ISE below will be triggered.}if (parsingRequestLinePhase == 7) {// Parsing is complete. Return and clean-up.parsingRequestLine = false;parsingRequestLinePhase = 0;parsingRequestLineEol = false;parsingRequestLineStart = 0;return true;}throw new IllegalStateException(sm.getString("iib.invalidPhase", Integer.valueOf(parsingRequestLinePhase)));}
- 请求头解析
http请求头格式如name:value,解析先按行读取字符串,读取到":“则认为读到一个请求头,使用MimeHeaderField封装请求头字段,并返回当前请求头的value值到headerData.headerValue,再继续读取字节,读到”\r"为止,然后转换成字符串headerData.headerValue.setBytes(byteBuffer.array(), headerData.start,headerData.lastSignificantChar - headerData.start);保存到headerData.headerValue引用指向的MimeHeaderField对象。
private HeaderParseStatus parseHeader() throws IOException {// Read new bytes if neededif (byteBuffer.position() >= byteBuffer.limit()) {if (!fill(false)) {return HeaderParseStatus.NEED_MORE_DATA;}}prevChr = chr;chr = byteBuffer.get();if (chr == Constants.CR && prevChr != Constants.CR) {// Possible start of CRLF - process the next byte.} else if (chr == Constants.LF) {// CRLF or LF is an acceptable line terminatorreturn HeaderParseStatus.DONE;} else {if (prevChr == Constants.CR) {// Must have read two bytes (first was CR, second was not LF)byteBuffer.position(byteBuffer.position() - 2);} else {// Must have only read one bytebyteBuffer.position(byteBuffer.position() - 1);}break;}}if (headerParsePos == HeaderParsePosition.HEADER_START) {// Mark the current buffer positionheaderData.start = byteBuffer.position();headerData.lineStart = headerData.start;headerParsePos = HeaderParsePosition.HEADER_NAME;}//// Reading the header name// Header name is always US-ASCII//while (headerParsePos == HeaderParsePosition.HEADER_NAME) {// Read new bytes if neededif (byteBuffer.position() >= byteBuffer.limit()) {if (!fill(false)) { // parse headerreturn HeaderParseStatus.NEED_MORE_DATA;}}int pos = byteBuffer.position();chr = byteBuffer.get();if (chr == Constants.COLON) {if (headerData.start == pos) {// Zero length header name - not valid.// skipLine() will handle the errorreturn skipLine(false);}headerParsePos = HeaderParsePosition.HEADER_VALUE_START;headerData.headerValue = headers.addValue(byteBuffer.array(), headerData.start, pos - headerData.start);pos = byteBuffer.position();// Mark the current buffer positionheaderData.start = pos;headerData.realPos = pos;headerData.lastSignificantChar = pos;break;} else if (!HttpParser.isToken(chr)) {// Non-token characters are illegal in header names// Parsing continues so the error can be reported in contextheaderData.lastSignificantChar = pos;byteBuffer.position(byteBuffer.position() - 1);// skipLine() will handle the errorreturn skipLine(false);}// chr is next byte of header name. Convert to lowercase.if (chr >= Constants.A && chr <= Constants.Z) {byteBuffer.put(pos, (byte) (chr - Constants.LC_OFFSET));}}// Skip the line and ignore the headerif (headerParsePos == HeaderParsePosition.HEADER_SKIPLINE) {return skipLine(false);}//// Reading the header value (which can be spanned over multiple lines)//while (headerParsePos == HeaderParsePosition.HEADER_VALUE_START ||headerParsePos == HeaderParsePosition.HEADER_VALUE ||headerParsePos == HeaderParsePosition.HEADER_MULTI_LINE) {if (headerParsePos == HeaderParsePosition.HEADER_VALUE_START) {// Skipping spaceswhile (true) {// Read new bytes if neededif (byteBuffer.position() >= byteBuffer.limit()) {if (!fill(false)) {// parse header// HEADER_VALUE_STARTreturn HeaderParseStatus.NEED_MORE_DATA;}}chr = byteBuffer.get();if (chr != Constants.SP && chr != Constants.HT) {headerParsePos = HeaderParsePosition.HEADER_VALUE;byteBuffer.position(byteBuffer.position() - 1);// Avoids prevChr = chr at start of header value// parsing which causes problems when chr is CR// (in the case of an empty header value)chr = 0;break;}}}if (headerParsePos == HeaderParsePosition.HEADER_VALUE) {// Reading bytes until the end of the lineboolean eol = false;while (!eol) {// Read new bytes if neededif (byteBuffer.position() >= byteBuffer.limit()) {if (!fill(false)) {// parse header// HEADER_VALUEreturn HeaderParseStatus.NEED_MORE_DATA;}}prevChr = chr;chr = byteBuffer.get();if (chr == Constants.CR && prevChr != Constants.CR) {// CR is only permitted at the start of a CRLF sequence.// Possible start of CRLF - process the next byte.} else if (chr == Constants.LF) {// CRLF or LF is an acceptable line terminatoreol = true;} else if (prevChr == Constants.CR) {// Invalid value - also need to delete headerreturn skipLine(true);} else if (HttpParser.isControl(chr) && chr != Constants.HT) {// Invalid value - also need to delete headerreturn skipLine(true);} else if (chr == Constants.SP || chr == Constants.HT) {byteBuffer.put(headerData.realPos, chr);headerData.realPos++;} else {byteBuffer.put(headerData.realPos, chr);headerData.realPos++;headerData.lastSignificantChar = headerData.realPos;}}// Ignore whitespaces at the end of the lineheaderData.realPos = headerData.lastSignificantChar;// Checking the first character of the new line. If the character// is a LWS, then it's a multiline headerheaderParsePos = HeaderParsePosition.HEADER_MULTI_LINE;}// Read new bytes if neededif (byteBuffer.position() >= byteBuffer.limit()) {if (!fill(false)) {// parse header// HEADER_MULTI_LINEreturn HeaderParseStatus.NEED_MORE_DATA;}}byte peek = byteBuffer.get(byteBuffer.position());if (headerParsePos == HeaderParsePosition.HEADER_MULTI_LINE) {if (peek != Constants.SP && peek != Constants.HT) {headerParsePos = HeaderParsePosition.HEADER_START;break;} else {// Copying one extra space in the buffer (since there must// be at least one space inserted between the lines)byteBuffer.put(headerData.realPos, peek);headerData.realPos++;headerParsePos = HeaderParsePosition.HEADER_VALUE_START;}}}// Set the header valueheaderData.headerValue.setBytes(byteBuffer.array(), headerData.start,headerData.lastSignificantChar - headerData.start);headerData.recycle();return HeaderParseStatus.HAVE_MORE_HEADERS;}
- 请求体解析
请求体获取方式如下,从请求request中拿到BufferedReader,然后调用readLine就行。
BufferedReader reader = request.getReader();String line;while ((line=reader.readLine())!=null){System.out.println(line);}
tomcat会用CoyoteReader去封装内置的inputBuffer,生成BufferedReader。
public BufferedReader getReader() throws IOException {if (usingInputStream) {throw new IllegalStateException(sm.getString("coyoteRequest.getReader.ise"));}if (coyoteRequest.getCharacterEncoding() == null) {Context context = getContext();if (context != null) {String enc = context.getRequestCharacterEncoding();if (enc != null) {setCharacterEncoding(enc);}}}usingReader = true;inputBuffer.checkConverter();if (reader == null) {reader = new CoyoteReader(inputBuffer);}return reader;}
其实也很简答,就是到内置的缓冲区中读取数据,然后使用编码成字符串即可。
public String readLine() throws IOException {if (lineBuffer == null) {lineBuffer = new char[MAX_LINE_LENGTH];}String result = null;int pos = 0;int end = -1;int skip = -1;StringBuilder aggregator = null;while (end < 0) {mark(MAX_LINE_LENGTH);while ((pos < MAX_LINE_LENGTH) && (end < 0)) {int nRead = read(lineBuffer, pos, MAX_LINE_LENGTH - pos);if (nRead < 0) {if (pos == 0 && aggregator == null) {return null;}end = pos;skip = pos;}for (int i = pos; (i < (pos + nRead)) && (end < 0); i++) {if (lineBuffer[i] == LINE_SEP[0]) {end = i;skip = i + 1;char nextchar;if (i == (pos + nRead - 1)) {nextchar = (char) read();} else {nextchar = lineBuffer[i + 1];}if (nextchar == LINE_SEP[1]) {skip++;}} else if (lineBuffer[i] == LINE_SEP[1]) {end = i;skip = i + 1;}}if (nRead > 0) {pos += nRead;}}if (end < 0) {if (aggregator == null) {aggregator = new StringBuilder();}aggregator.append(lineBuffer);pos = 0;} else {reset();// No need to check return value. We know there are at least skip characters available.skip(skip);}}if (aggregator == null) {result = new String(lineBuffer, 0, end);} else {aggregator.append(lineBuffer, 0, end);result = aggregator.toString();}return result;}
相关文章:

tomcat请求数据解析过程
前面提到tomcat请求处理的io交互过程,现在开始看下经过io交互后tomcat是怎么处理请求数据的。首先到AbstractProtocol.java中的process方法,注意这个方法是在tomcat线程池分配的线程调用的。生成用来对请求字节流数据进行解析的Http11Processor。 public…...

《扑克牌游戏》
描述 有一个扑克牌游戏,游戏规则是不断地摸牌,尽可能地使手上的牌的点数接近于10,最完美的情况是总点数为10,不可以超过10,否则就爆了。输入10张牌的点数,(每张点数不超过10),请你输出用户应该抓…...

kali模块及字典介绍
1. 基本模块介绍 模块 类型 使用模式 功能 dmitry 信息收集 命令行 whois查询/子域名收集/端口扫描 dnmap 信息收集 命令行 用于组建分布式nmap,dnmap_server为服务端;dnmap_client为客户端 i…...

交换排序、归并排序、计数排序
冒泡排序: void BubbleSort(int* a, int n) {//第一层循环是趟数,第二层是交换for (int i 0; i < n-2; i){int flag 0;for (int j 0; j < n - 2 - i; j){if (a[j] > a[j 1]){swap(&a[j], &a[j 1]);flag 1;}}if (flag 0){break;…...

怎么查看 iOS ipa包 mobileprovision 改动
查看 iOS .ipa 包中的 .mobileprovision 文件(即配置文件或描述文件)的改动,可以通过以下步骤进行: 重命名 .ipa 文件:将 .ipa 文件扩展名改为 .zip。例如,如果文件名为 MyApp.ipa,则重命名为 M…...

【Unitydemo制作】音游制作—控制器与特效
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:就业…...

[程序员] 最近的感悟,错误处理占大头?
根据昨天分享的一个问题,想到的。 在代码里,异常处理的代码也算是占大头,扑面而来的就是发生错误时怎么处理的大片代码;而且出现问题的概率是绝对的占大头。所以,异常代码出现bug的概率也在不知不觉中增加!…...
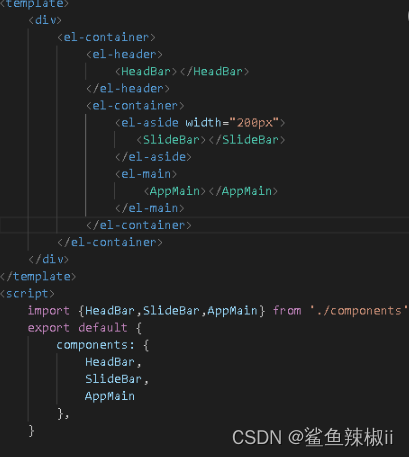
vue3(一) - 结构认识
通过之前博客应该已经完成了vue脚手架的认识和创建(地址),这节我们简单介绍一下需要使用的一些关键技术,后续在详细介绍 结构目录 创建脚手架时,我选择了TypeScript,store,route这三个选项 index.html入口 node_mo…...
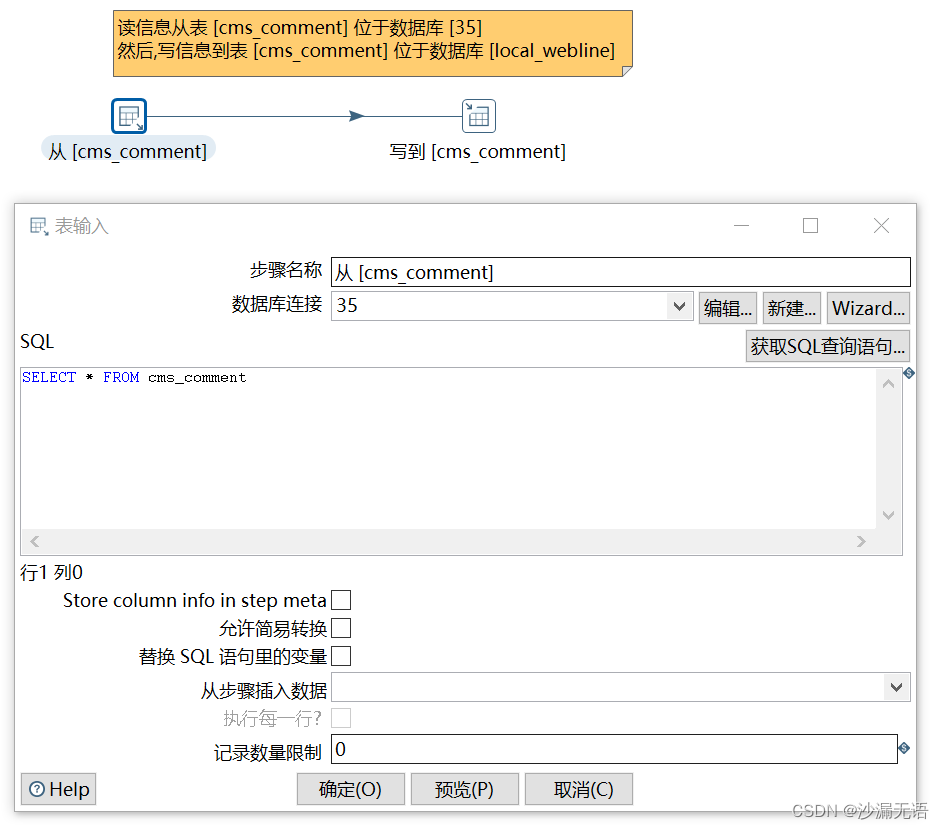
数据库迁移——kettle开发01
背景:数据库的多种多样,在搭建项目之初,并没有详细考虑到数据库的建设,当增加配置不能满足业务场景需要时,这时候考虑到使用更高性能的数据库,如将MySQL更换为oracle数据库。或者在搭建新项目时,…...

Netty: Netty中的组件
文章目录 一、EventLoop1、EventLoop2、EventLoopGroup(1)处理普通时间和定时任务(2)处理IO任务 二、Channel三、Future&Promise四、Handler&Pipeline五、ByteBuf 一、EventLoop 1、EventLoop EventLoop本质是一个单线程…...

Julia编程01:Julia语言介绍
在2020上半年,因为疫情无法返校,所以在家待了半年,期间学习一点了R语言、Python、Julia、linux和C语言,只是学习基础语法并没有项目练习,因此返校半年后差不多都不记得了,现在重新捡起Julia丰富下当时写的笔…...
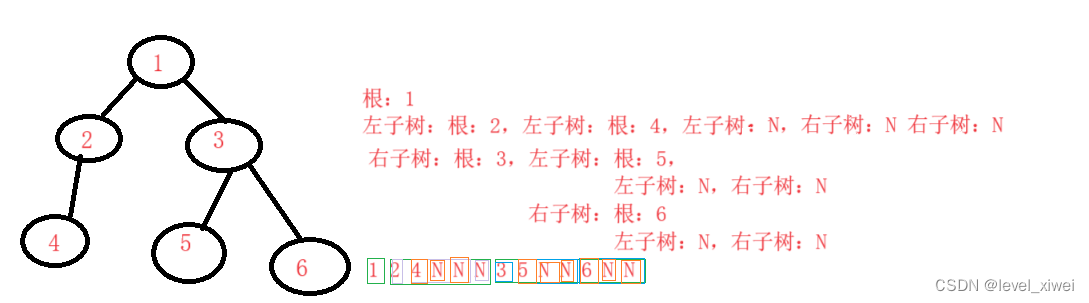
二叉树顺序结构及链式结构
一.二叉树的顺序结构 1.定义:使用数组存储数据,一般使用数组只适合表示完全二叉树,此时不会有空间的浪费 注:二叉树的顺序存储在逻辑上是一颗二叉树,但是在物理上是一个数组,此时需要程序员自己想清楚调整…...

【Python】pandas连续变量分箱
路过了学校花店 荒野到海边 有一种浪漫的爱 是浪费时间 徘徊到繁华世界 才发现你背影 平凡得特别 绕过了城外边界 还是没告别 爱错过了太久 反而错得完美无缺 幸福兜了一个圈 🎵 林宥嘉《兜圈》 import pandas as pd import numpy as np from sklearn.model_selecti…...

Qt 打卡小程序总结
1.Qt::Alignment(枚举类型)用于指定控件或文本的对齐方式 Qt::AlignLeft:左对齐。Qt::AlignRight:右对齐。Qt::AlignHCenter:水平居中对齐。Qt::AlignTop:顶部对齐。Qt::AlignBottom:底部对齐。…...

【qt】标准项模型
标准项模型 一.使用标准型项模型1.应用场景2.界面拖放3.创建模型4.配套模型5.视图设置模型6.视图属性的设置 二.从文件中拿到数据1.文件对话框获取文件名2.创建文件对象并初始化3.打开文件对象4.创建文本流并初始化5.读取文本流6.关闭文件7.完整代码 三.为模型添加数据1.自定义…...
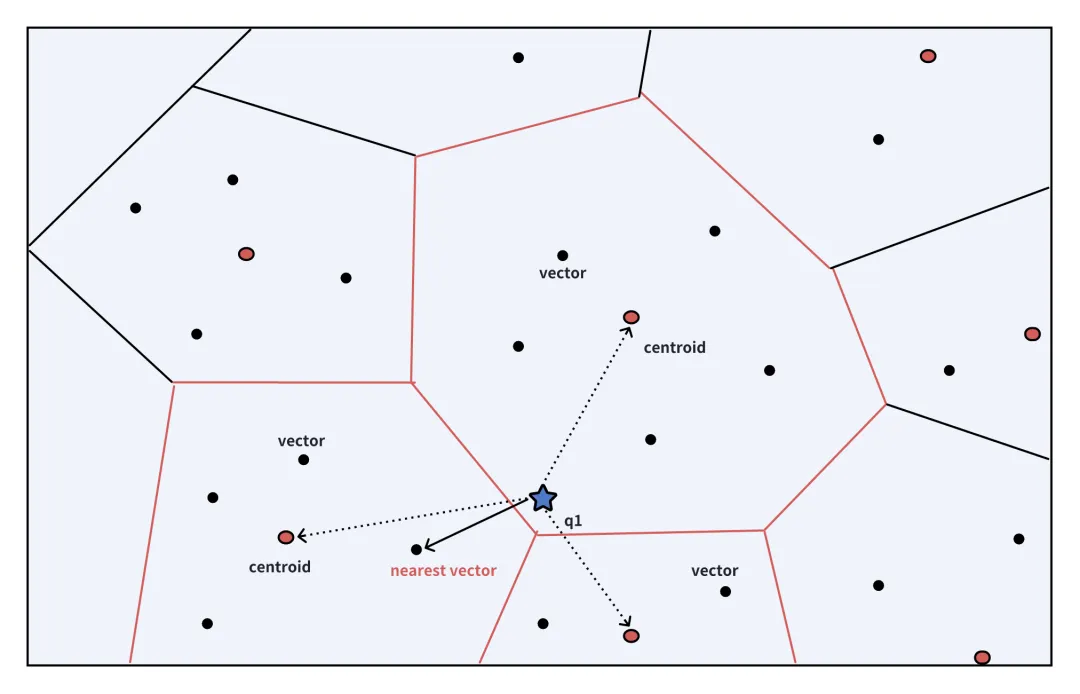
一文深度剖析 ColBERT
近年来,向量搜索领域经历了爆炸性增长,尤其是在大型语言模型(LLMs)问世后。学术界开始重点关注如何通过扩展训练数据、采用先进的训练方法和新的架构等方法来增强 embedding 向量模型。 在之前的文章中,我们已经深入探…...
css左右滚动互不影响
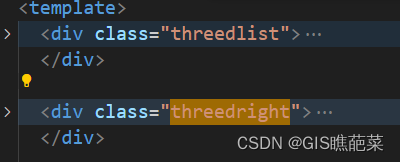
想实现左右都可以滚动,且互不影响。 只需要再左边的css里面 .threedlist {cursor: pointer;width: 280px;position: fixed;height: 100vh; /* 定义父容器高度 */overflow-y: auto; /* 只有在内容超过父容器高度时才出现滚动条 */} 如果想取消滚动条样式 .threedli…...

【linux-uboot移植-mmc及tftp启动-IMX6ULL】
目录 1. uboot简介2. 移植前的基本介绍:2.1 环境系统信息: 3. 初次编译4. 烧录编译的u-boot4.1 修改网络驱动 5. 通过命令启动linux内核5.1 通过命令手动启动mmc中的linux内核5.1.1 fatls mmc 1:15.1.2 fatload mmc 1:1 0x80800000 zImage5.1.3 fatload mmc 1:1 0x8…...
Python-温故知新
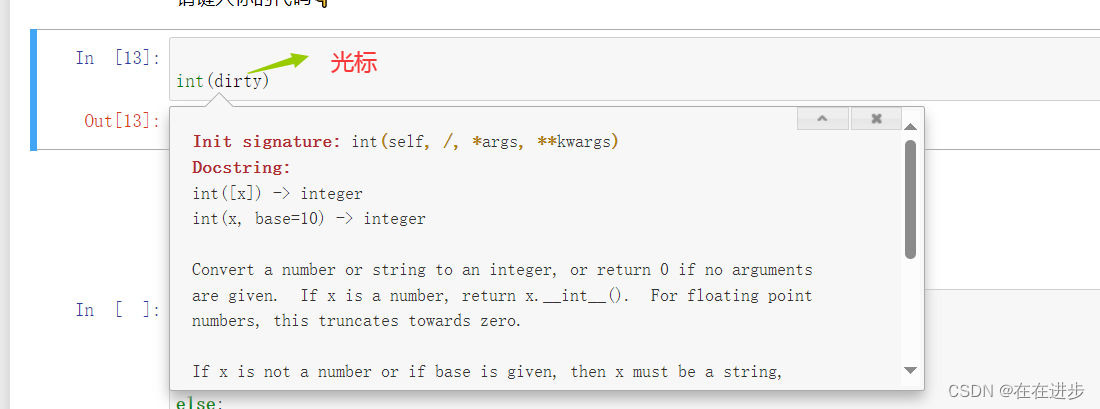
1快速打开.ipynb文件 安装好anaconda后,在需要打开notebook的文件夹中, shift键右键——打开powershell窗口——输入jupyter notebook 即可在该文件夹中打开notebook的页面: 2 快速查看函数用法 光标放在函数上——shift键tab 3......

绿联NAS DXP系列发布:内网穿透技术在私有云的应用分析
5月23日,绿联科技举行了“新一代存储方式未来已来”发布会,发布了绿联NAS私有云DXP系列(包括两盘位到八盘位的九款新品)以及由绿联科技自研的全新NAS系统UGOS Pro。此次绿联发布的DXP系列九款产品,共有两盘位、四盘位、…...
)
别再死磕欧拉角了!用MATLAB的quaternion函数搞定机器人/无人机姿态解算(附完整代码)
四元数实战指南:用MATLAB彻底解决机器人姿态解算难题 刚接手无人机飞控项目时,我被欧拉角的万向节死锁问题折磨得焦头烂额——明明理论计算没问题,实际飞行时却总出现诡异的姿态跳变。直到改用四元数方案,这些问题才迎刃而解。本文…...

【GitHub项目推荐--video-use:用自然语言剪辑视频,Claude Code 的“AI 剪辑师”】⭐⭐⭐
GitHub 地址:https://github.com/browser-use/video-use 简介 video-use 是 browser-use 团队开源的一款“对话式视频编辑”技能。它的理念极其简单:把原始素材扔进文件夹,用自然语言告诉 Claude Code(或 Codex、Hermes 等 Age…...

Python零基础入门AI绘画:FLUX.1-Krea-Extracted-LoRA快速上手教程
Python零基础入门AI绘画:FLUX.1-Krea-Extracted-LoRA快速上手教程 1. 前言:为什么选择这个教程? 如果你对AI绘画感兴趣但被复杂的代码吓退,这个教程就是为你准备的。不需要任何编程基础,我们将从最基础的Python安装开…...

Qwen3-ASR语音识别快速部署:5步教程,轻松实现语音转文字
Qwen3-ASR语音识别快速部署:5步教程,轻松实现语音转文字 1. 准备工作:了解你的语音识别助手 在开始部署之前,让我们先认识一下Qwen3-ASR这个强大的语音识别工具。它能做什么?简单来说,它能把你说的任何话…...

ARIMA模型持久化:原理、工具与实践指南
1. 项目概述:ARIMA模型持久化的核心价值在时间序列分析领域,ARIMA(自回归综合移动平均)模型因其出色的预测能力被广泛应用于金融、气象、供应链管理等场景。但许多实践者常忽视一个关键环节——如何将训练好的模型持久化保存。模型…...
)
保姆级教程:在Windows 11上从零搭建Mask2Former环境(含Visual Studio 2022和CUDA 11.8避坑指南)
从零开始在Windows 11上搭建Mask2Former环境:避坑指南与实战验证 对于刚接触计算机视觉的开发者来说,环境搭建往往是第一个拦路虎。特别是在Windows系统上,从CUDA版本冲突到编译器缺失,每一步都可能遇到意想不到的问题。本文将手…...

STEP3-VL-10B部署与调用全攻略:WebUI交互和cURL API调用示例
STEP3-VL-10B部署与调用全攻略:WebUI交互和cURL API调用示例 1. 引言:为什么选择STEP3-VL-10B? STEP3-VL-10B是阶跃星辰推出的轻量级多模态模型,虽然只有10B参数,但在多项基准测试中表现优异。对于开发者而言&#x…...
)
第41篇:图像分割技术解析——像素级的视觉理解(原理解析)
文章目录现象引入:为什么模型能“抠图”?提出问题:图像分割的三大核心挑战原理剖析:从全卷积网络(FCN)到编码器-解码器结构1. 全卷积网络(FCN):扔掉全连接层,…...
)
别再死记公式了!用奇偶模分析法手把手拆解平行耦合微带线(附Python仿真验证)
奇偶模分析法:像庖丁解牛一样拆解平行耦合微带线 记得刚入行射频设计时,面对平行耦合微带线的网络参量分析,那些复杂的矩阵公式让我头疼不已。直到导师告诉我:"别急着背公式,先理解奇偶模分析法的精髓——它就像庖…...

如何高效使用Locale Emulator:Windows区域模拟的完整指南
如何高效使用Locale Emulator:Windows区域模拟的完整指南 【免费下载链接】Locale-Emulator Yet Another System Region and Language Simulator 项目地址: https://gitcode.com/gh_mirrors/lo/Locale-Emulator 你是否曾经因为日文游戏显示乱码而烦恼&#x…...