爬虫实训案例:中国大学排名
近一个月左右的时间学习爬虫,在用所积累的知识爬取了《中国大学排名》这个网站,爬取的内容虽然只是可见的文本,但对于初学者来说是一个很好的练习。在爬取的过程中,通过请求数据、解析内容、提取文本、存储数据等几个重要的内容入手,不过在存储数据后的数据排版方面并不是很完善(优化),希望阅读本文章的学者大大给些存储后的数据排版方面的指点:中文对齐的问题
文章目录
- 前言🌟
- 一、🍉从网络上获取大学排名网页内容— getHTMLText()
- 二、🍉提取网页内容中信息到合适的数据结构— fillUnivList()
- 三、🍉将数据保存至电脑文件夹中— Store_as_file()
- 四、🍉主函数
- 总结🌟
前言🌟
本次案例主要涉及bs4库中的BeautifulSoup内容、requests的使用和存储数据等知识。

提示:以下是本篇文章正文内容,下面案例可供参考
一、🍉从网络上获取大学排名网页内容— getHTMLText()
- 爬取的网址:https://www.shanghairanking.cn/rankings/bcur/202411
- 判断是否可以爬取
在该网站的根目录下查看robots.txt文件是否可以爬取内容,这里显示没有搜索到该内容
3.利用request库爬取
def getHTMLText(url):try:r = requests.get(url, timeout=30)r.raise_for_status() # 判断请求是否成功:如果不是200,产生异常requests.HTTPErrorr.encoding = r.apparent_encoding # http header中猜测的响应内容编码方式 设置为 内容中分析出的响应内容编码方式(备选编码方式)return r.textexcept:return "请求失败"
二、🍉提取网页内容中信息到合适的数据结构— fillUnivList()
- 分析网页
我们要爬取的是”排名“,”学校名称“,”省市“,”类型“,”总分“,”办学层次“等信息,如图: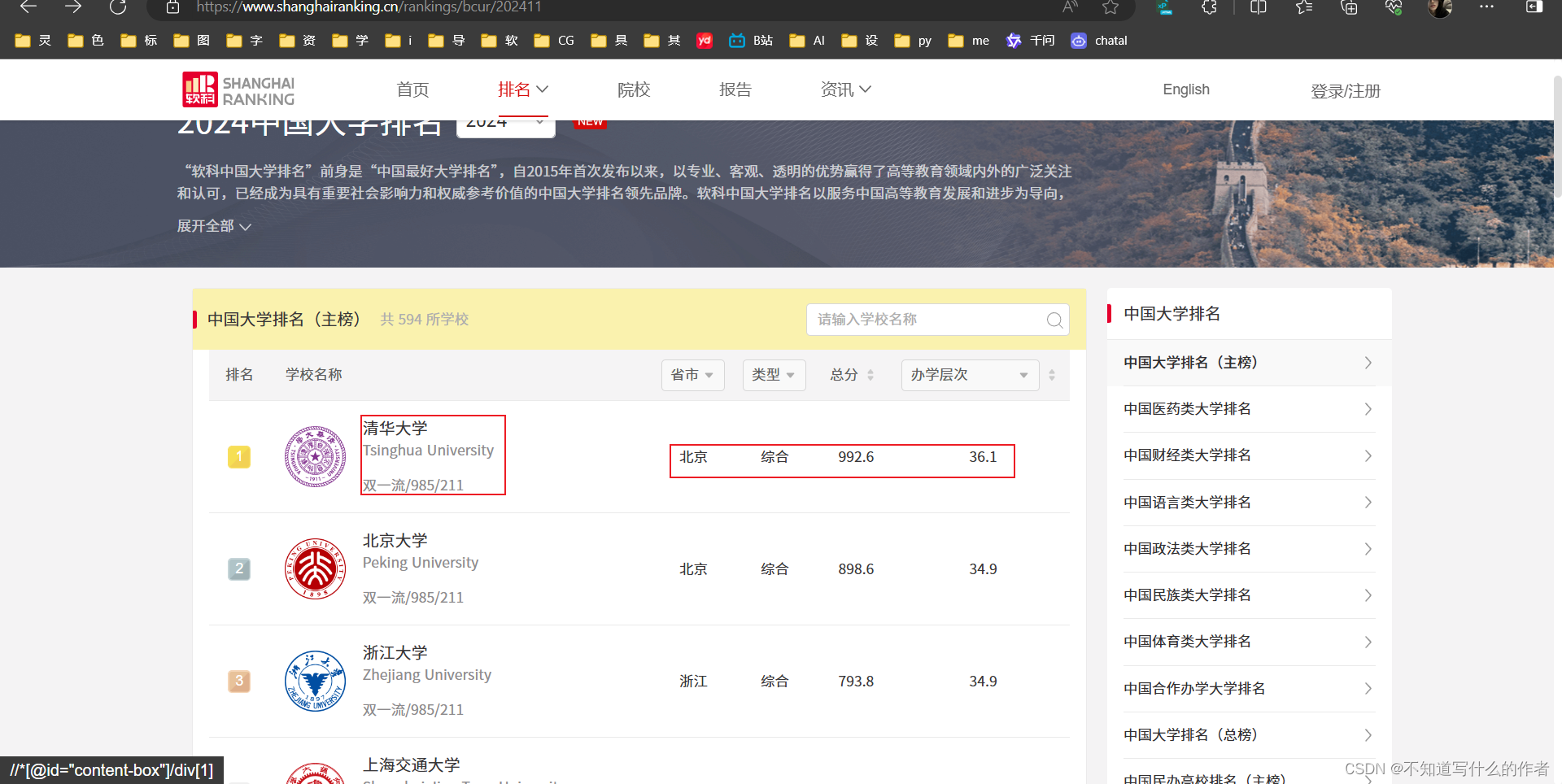
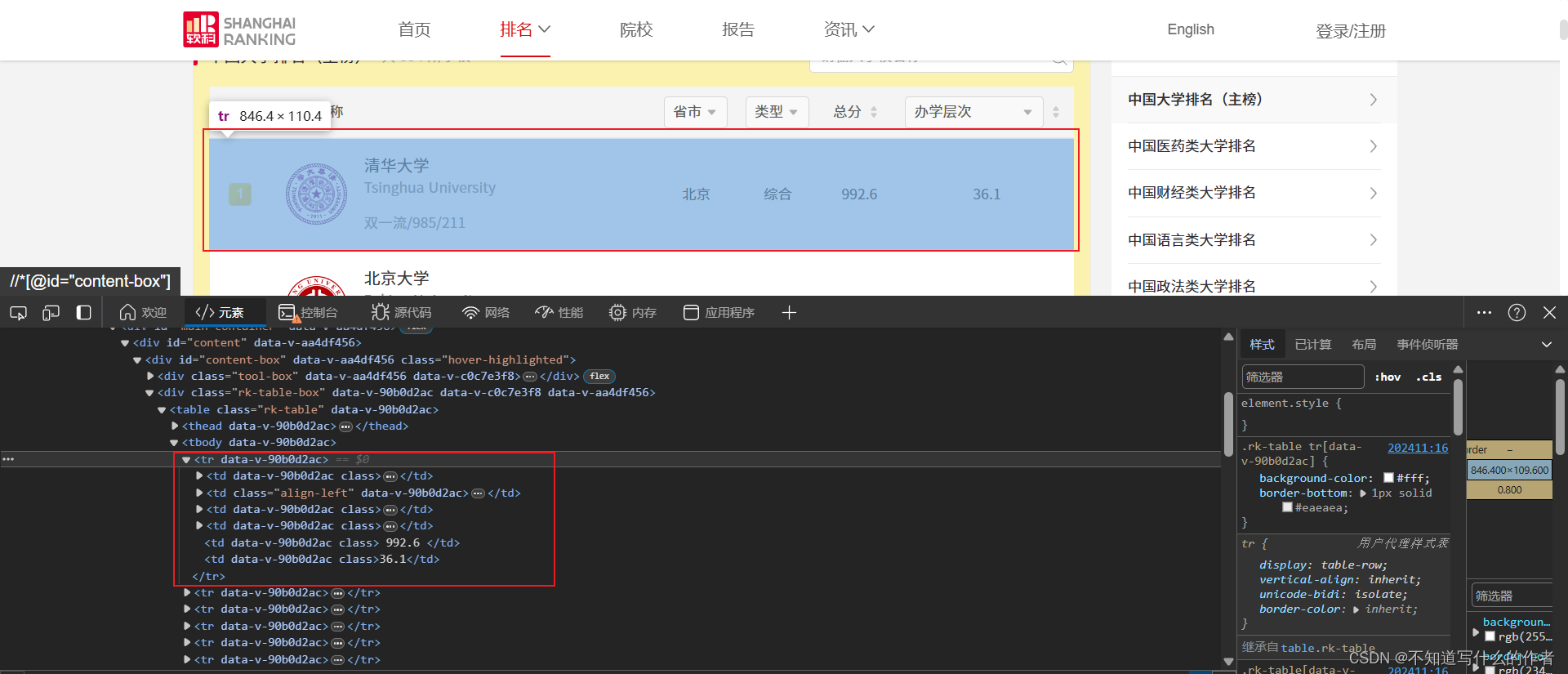
- 先是分析整体信息,需要爬取的文本信息都存放在
.html网页中的<tbody></tbody>中的<tr>标签下.
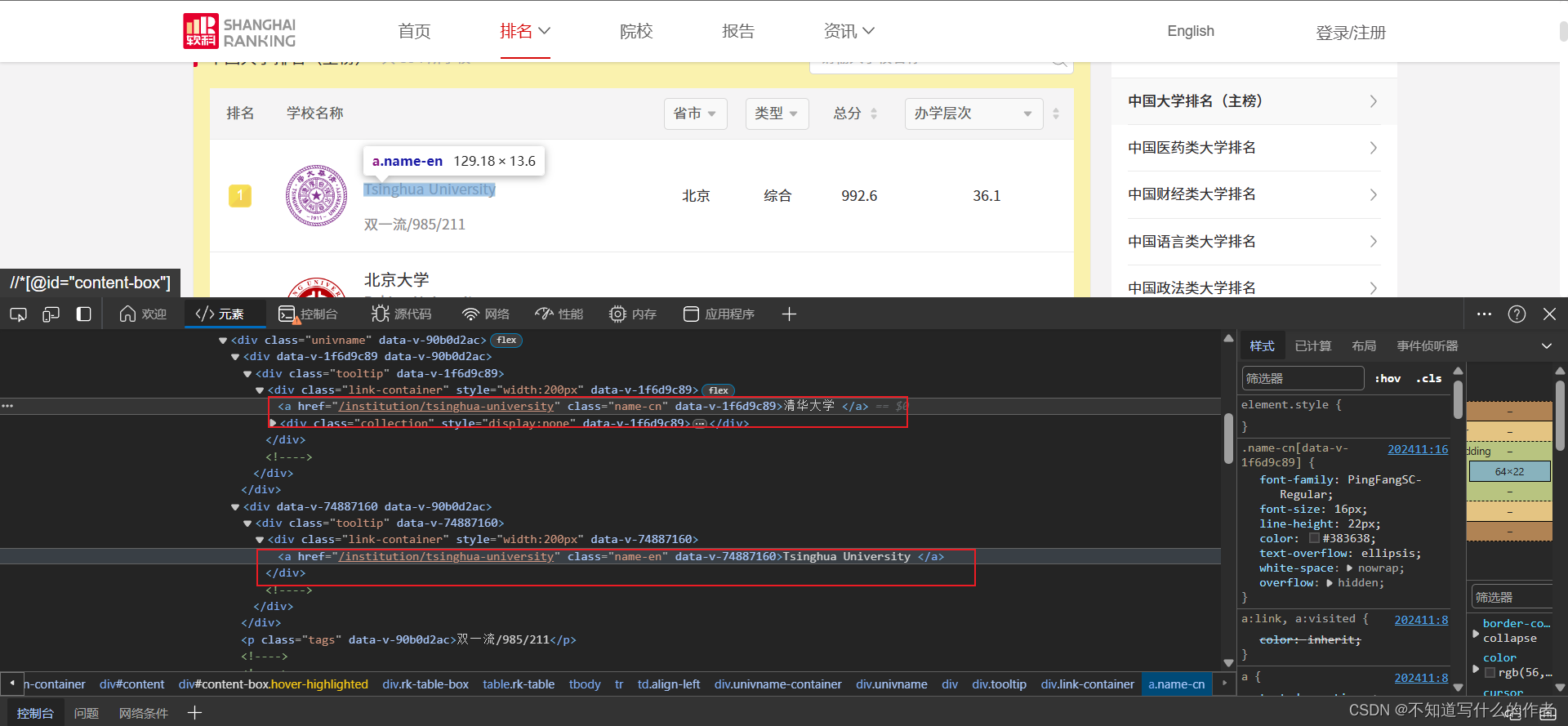
- ”学校名称”在
<div class="univname" data-v-90b0d2ac>标签下<a>标签中。
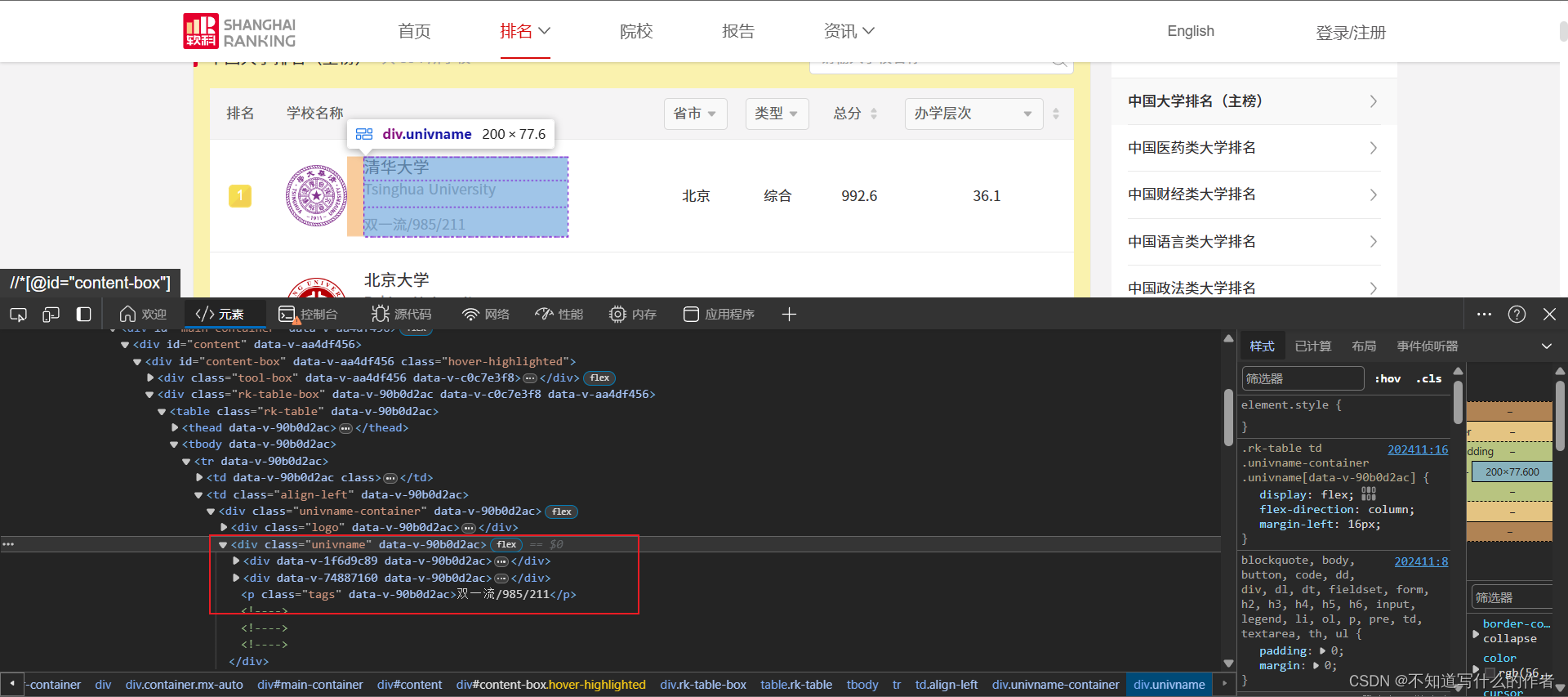
特征:<a>的父亲<div>标签的属性都是class="link-container"和style="width:200px
- 而”省市“,”类型“,”总分“,”办学层次“等,都是直接在
<tr>标签的子代中,所以可以直接获取相关数据存放至列表中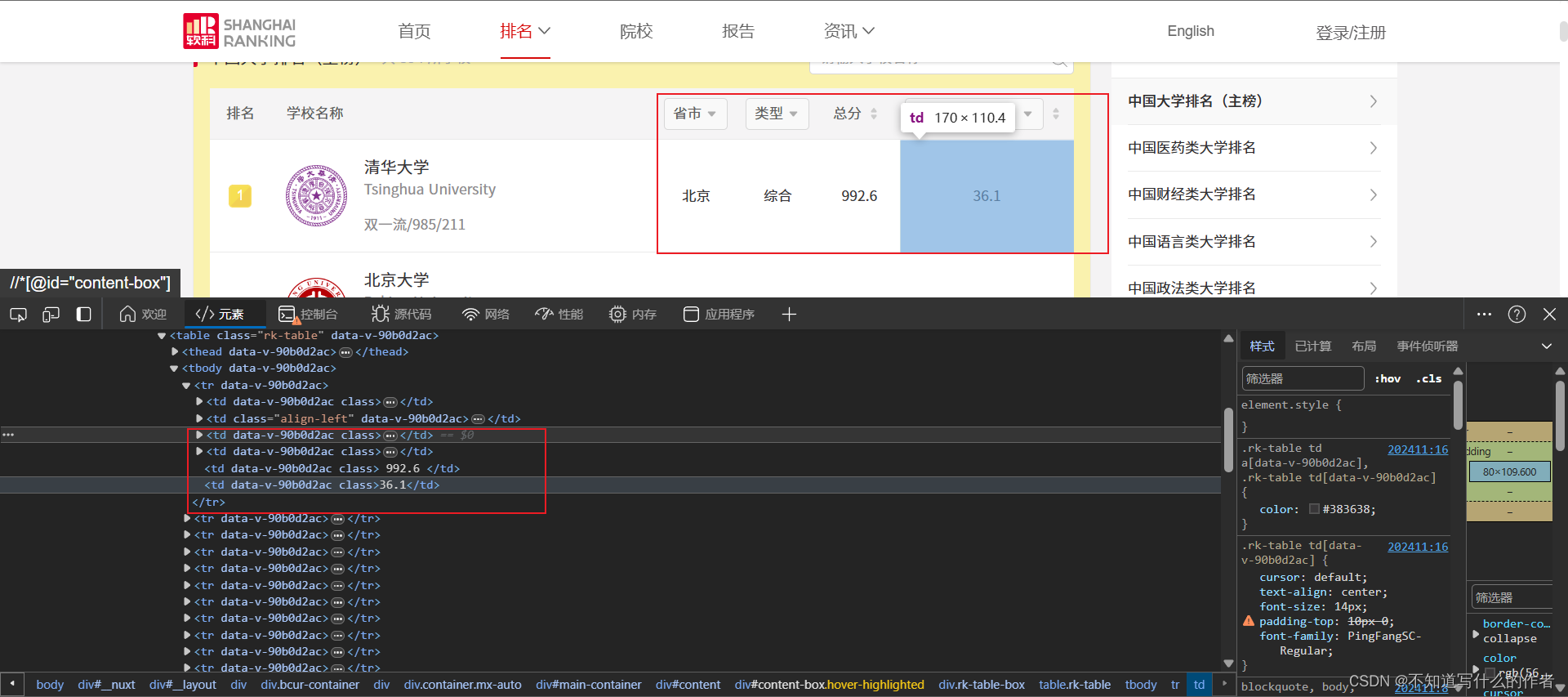
- 解析数据
获取主要爬取的数据,存放至列表中并返回
def fillUnivList(ulist, html):soup = BeautifulSoup(html, 'html.parser') # 设置BeautifulSoup解析器为'html.parser'soup.prettify() # 整理解析的网页# 创建列表tds_name = []name_types = []tds_location = []tds_type = []tds_total = []tds_level = []try:# 遍历tbody的下行遍历for tr in soup.tbody.children:# 检测tr标签的类型的类型,如果tr标签的类型不是bs4库定义的tag类型,将过滤掉if isinstance(tr, bs4.element.Tag): # 检查变量tr是否为BeautifulSoup库中Tag类的实例的一个条件判断语句# tds=str(list(tr('td')[2])[0]).strip()# 学校名称td_name = tr('td')[1]td_div_names = td_name.find_all('div', attrs={"style": "width:200px", "class": "link-container"})for div_tag in td_div_names:# 另一种写法# name_part = div_tag.find('a').get_text(strip=True).split('\n', 1)[0]a = str(div_tag.find_all('a')[0].string).strip().split('\n')[0]tds_name.append(a)# 学校类型td_name_type = tr('td')[1] \.find_all('div', attrs={"class": "univname"})[0] \.find_all('p', attrs={"class": "tags"})[0].get_text(strip=True)# 位置td_location = tr('td')[2].get_text(strip=True)# 类型td_type = tr('td')[3].get_text(strip=True)# 总分td_total = tr('td')[4].get_text(strip=True)# 办学层次td_level = tr('td')[5].get_text(strip=True)# 将各个数据添加至列表name_types.append(td_name_type)tds_location.append(td_location)tds_type.append(td_type)tds_total.append(td_total)tds_level.append(td_level)# break# 中文名字列表name_cns = tds_name[::2]# 英文名字列表name_ens = tds_name[1::2]i=1# 遍历列表大学信息,存放至空列表university中,使用zip打包,zip打包后的数据是元组for name_cn, name_en, name_type, location, type, total, level in \zip(name_cns, name_ens, name_types, tds_location, tds_type, tds_total, tds_level):university_data = {'序号':i,'学校名称': name_cn + " " + name_en + " " + name_type,'省市': location,'类型': type,'总分': total,'办学层次': level}i+=1ulist.append(university_data)return ulistexcept:return "爬取失败"
三、🍉将数据保存至电脑文件夹中— Store_as_file()
这里直接给出代码块,因为完全没有真的优化处理好爬取后的数据(还是很杂乱)
def Store_as_file(path,datas):# 打开文件准备写入with open(path, 'w', encoding='utf-8') as file:# 写入表头,方便阅读file.write("{:^10}\t{:<110}\t{:<10}\t{:<10}\t{:<10}\t{:>10}\n".format("序号","学校名称","省市","类型","总分","办学层次"))t="\t"*10# file.write(f"序号\t学校名称\t\t省市\t\t类型\t\t总分\t\t办学层次\n")# 遍历列表,将每个字典的内容写入文件for university in datas:# 使用制表符分隔各个字段,保证对齐line = "{序号:^10}\t{学校名称:<110}\t{省市:<10}\t{类型:<10}\t{总分:<10}\t{办学层次:>10}\n".format(**university)file.write(line)print(f"数据已成功保存至'{path}'")
四、🍉主函数
代码块:主函数的书写
def main():university = []num = int(input("请输入大学排名的年份:"))url=f"https://www.shanghairanking.cn/rankings/bcur/{num}11"html=getHTMLText(url)datas=fillUnivList(university,html)path=input("请输入存放内容的位置:")Store_as_file(path,datas)
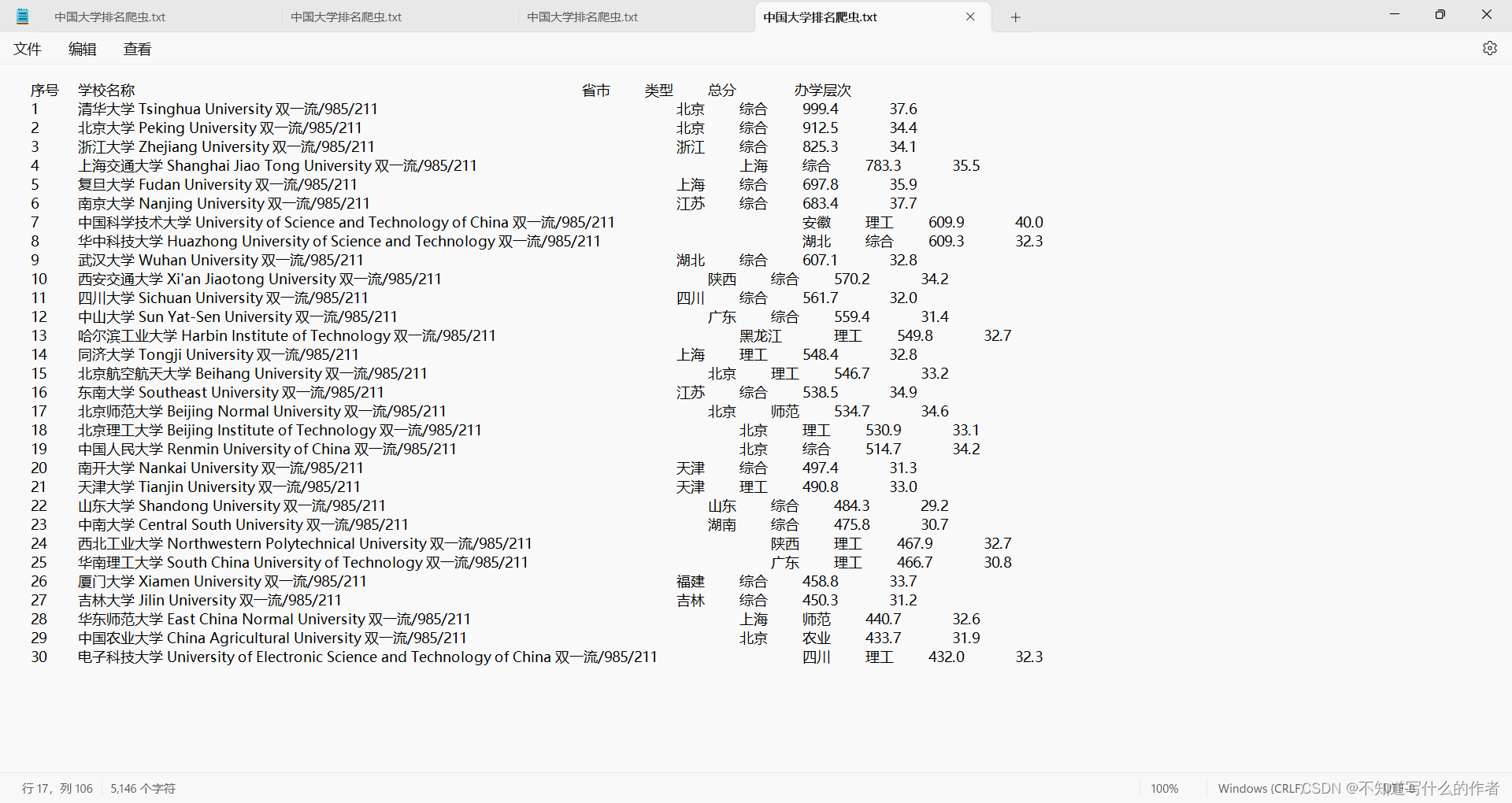
最终效果:当然,我是确实不知道怎么更改,还望读者帮忙提供点意见
总结🌟
总代码块:导入requests库和bs4库和bs4库中的BeautifulSoup
import requests
from bs4 import BeautifulSoup
import bs4def getHTMLText(url):try:r = requests.get(url, timeout=30)r.raise_for_status() # 判断请求是否成功:如果不是200,产生异常requests.HTTPErrorr.encoding = r.apparent_encoding # http header中猜测的响应内容编码方式 设置为 内容中分析出的响应内容编码方式(备选编码方式)return r.textexcept:return "请求失败"def fillUnivList(ulist, html):soup = BeautifulSoup(html, 'html.parser') # 设置BeautifulSoup解析器为'html.parser'soup.prettify() # 整理解析的网页# 创建列表tds_name = []name_types = []tds_location = []tds_type = []tds_total = []tds_level = []try:# 遍历tbody的下行遍历for tr in soup.tbody.children:# 检测tr标签的类型的类型,如果tr标签的类型不是bs4库定义的tag类型,将过滤掉if isinstance(tr, bs4.element.Tag): # 检查变量tr是否为BeautifulSoup库中Tag类的实例的一个条件判断语句# tds=str(list(tr('td')[2])[0]).strip()# 学校名称td_name = tr('td')[1]td_div_names = td_name.find_all('div', attrs={"style": "width:200px", "class": "link-container"})for div_tag in td_div_names:# 另一种写法# name_part = div_tag.find('a').get_text(strip=True).split('\n', 1)[0]a = str(div_tag.find_all('a')[0].string).strip().split('\n')[0]tds_name.append(a)# 学校类型td_name_type = tr('td')[1] \.find_all('div', attrs={"class": "univname"})[0] \.find_all('p', attrs={"class": "tags"})[0].get_text(strip=True)# 位置td_location = tr('td')[2].get_text(strip=True)# 类型td_type = tr('td')[3].get_text(strip=True)# 总分td_total = tr('td')[4].get_text(strip=True)# 办学层次td_level = tr('td')[5].get_text(strip=True)# 将各个数据添加至列表name_types.append(td_name_type)tds_location.append(td_location)tds_type.append(td_type)tds_total.append(td_total)tds_level.append(td_level)# break# 中文名字列表name_cns = tds_name[::2]# 英文名字列表name_ens = tds_name[1::2]i=1# 遍历列表大学信息,存放至空列表university中,使用zip打包,zip打包后的数据是元组for name_cn, name_en, name_type, location, type, total, level in \zip(name_cns, name_ens, name_types, tds_location, tds_type, tds_total, tds_level):university_data = {'序号':i,'学校名称': name_cn + " " + name_en + " " + name_type,'省市': location,'类型': type,'总分': total,'办学层次': level}i+=1ulist.append(university_data)return ulistexcept:return "爬取失败"def Store_as_file(path,datas):# 打开文件准备写入with open(path, 'w', encoding='utf-8') as file:# 写入表头,方便阅读file.write("{:^10}\t{:<110}\t{:<10}\t{:<10}\t{:<10}\t{:>10}\n".format("序号","学校名称","省市","类型","总分","办学层次"))t="\t"*10# file.write(f"序号\t学校名称\t\t省市\t\t类型\t\t总分\t\t办学层次\n")# 遍历列表,将每个字典的内容写入文件for university in datas:# 使用制表符分隔各个字段,保证对齐line = "{序号:^10}\t{学校名称:<110}\t{省市:<10}\t{类型:<10}\t{总分:<10}\t{办学层次:>10}\n".format(**university)file.write(line)print(f"数据已成功保存至'{path}'")def main():university = []num = int(input("请输入大学排名的年份:"))url=f"https://www.shanghairanking.cn/rankings/bcur/{num}11"html=getHTMLText(url)datas=fillUnivList(university,html)path=input("请输入存放内容的位置:")Store_as_file(path,datas)if __name__ == '__main__':main()
最后还是想哆嗦一下,希望读者大大,和爬虫感兴趣的多找我讨论讨论,给出点建议和学习上的交流👑👑 👏👏
相关文章:
爬虫实训案例:中国大学排名
近一个月左右的时间学习爬虫,在用所积累的知识爬取了《中国大学排名》这个网站,爬取的内容虽然只是可见的文本,但对于初学者来说是一个很好的练习。在爬取的过程中,通过请求数据、解析内容、提取文本、存储数据等几个重要的内容入…...

C++ IO流
C标准IO流 使用cout进行标准输出,即数据从内存流向控制台(显示器)使用cin进行标准输入,即数据通过键盘输入到程序中使用cerr进行标准错误的输出使用clog进行日志的输出 C文件IO流 文件流对象 ofstream:只写 ofstream 是 C 中用于输出文件…...

debian nginx upsync consul 实现动态负载
1. consul 安装 wget -O- https://apt.releases.hashicorp.com/gpg | sudo gpg --dearmor -o /usr/share/keyrings/hashicorp-archive-keyring.gpg echo "deb [signed-by/usr/share/keyrings/hashicorp-archive-keyring.gpg] https://apt.releases.hashicorp.com $(lsb_r…...

前端基础入门三大核心之HTML篇 —— 同源策略的深度解析与安全实践
前端基础入门三大核心之HTML篇 —— 同源策略的深度解析与安全实践 一、同源策略:定义与起源1.1 定义浅析1.2 何为“源”?1.3 起源与意义 二、同源策略的运作机制2.1 限制范围2.2 安全边界 三、跨越同源的挑战与对策3.1 JSONP3.2 CORS3.3 postMessage 四…...

go 微服务框架 kratos 日志库使用方法及原理探究
一、Kratos 日志设计理念 kratos 日志库相关的官方文档:日志 | Kratos Kratos的日志库主要有如下特性: Logger用于对接各种日志库或日志平台,可以用现成的或者自己实现Helper是在您的项目代码中实际需要调用的,用于在业务代码里…...

VC++位移操作>>和<<以及逻辑驱动器插拔产生的掩码dbv.dbcv_unitmask进行分析的相关代码
VC位移操作>>和<<以及逻辑驱动器插拔产生的掩码dbv.dbcv_unitmask进行分析的相关代码 一、VC位移操作符<<和>>1、右位移操作符 >>:2、左位移操作符 <<: 二、逻辑驱动器插拔产生的掩码 dbv.dbcv_unitmask 进行分析的…...

查看gpu
## 查看gpu信息 if_cuda torch.cuda.is_available() print("if_cuda",if_cuda)gpu_count torch.cuda.device_count() print("gpu_count",gpu_count)...

CSS与表格设计
在网页设计中,表格是一种不可或缺的元素,用于展示和组织数据。虽然HTML提供了基本的表格结构,但通过CSS(层叠样式表)的应用,我们可以极大地提升表格的外观和用户体验。本文将探讨如何利用CSS来设计既美观又…...

阴影映射(线段树)
实时阴影是电子游戏中最为重要的画面效果之一。在计算机图形学中,通常使用阴影映射方法来实现实时阴影。 游戏开发部正在开发一款 2D 游戏,同时希望能够在 2D 游戏中模仿 3D 游戏的光影效果,请帮帮游戏开发部! 给定 x-y 平面上的…...
Docker 容器间通讯
1、虚拟ip/访问 同一网络 安装docker时,docker会默认创建一个内部的桥接网络docker0,每创建一个容器分配一个虚拟网卡,容器之间(包括宿主机)可以根据分配的ip互相访问(ps:其他主机(包括其他主机的容器)无法ping通docker容器ip无法访问&#…...

C语言章节学习归纳--数据类型、运算符与表达式
3.1 C语言的数据类型(理解) 首先,对变量的定义可以包括三个方面: 数据类型 存储类型 作用域 所谓数据类型是按被定义变量的性质,表示形式,占据存储空间的多少,构造特点来划分的。在C语言中&…...
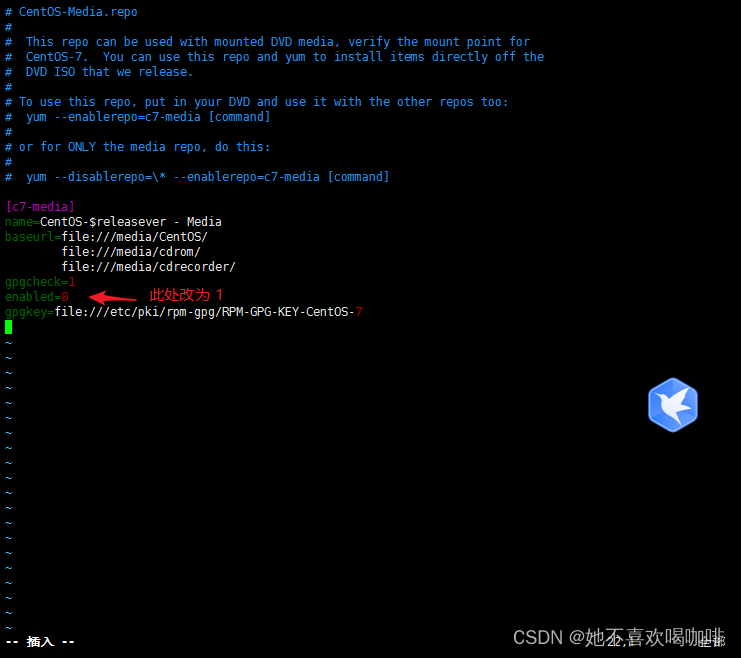
Centos 7.9 使用 iso 搭建本地 YUM 源
Centos 7.9 使用 iso 搭建本地 YUM 源 1 建立挂载点 [rootlocalhost ~]# mkdir -p /media/cdrom/ 2 创建光盘存储路径 [rootlocalhost ~]# mkdir -p /mnt/cdrom/ 3 上传 CentOS-7-x86_64-Everything-2207-02.iso 到 光盘存储路径 [rootlocalhost ~]# ls /mnt/cdrom/ CentOS-…...

NFT Insider #131:Mocaverse NFT市值破3.5万ETH,The Sandbox 参加NFCsummit
引言:NFT Insider由NFT收藏组织WHALE Members(https://twitter.com/WHALEMembers)、BeepCrypto (https://twitter.com/beep_crypto)联合出品,浓缩每周NFT新闻,为大家带来关于NFT最全面、最新鲜、…...

BatBot智慧能源管理平台,更加有效地管理能源
随着能源消耗的不断增加,能源管理已成为全球面临的重要问题。BatBot智慧能源管理作为一种的能源管理技术,促进企业在用能效率及管理有着巨大的提升。 BatBot智慧能源管理是一种基于人工智能技术的能源管理系统,通过智能分析和优化能源使用&…...

医院预约挂号系统微信小程序APP
医院预约挂号小程序,前端后台(后台 java spring boot mysql) 医院预约挂号系统具体功能介绍:展示医院信息、可以注册和登录, 预约挂号(包含各个科室的预约,可以预约每个各个医生)&…...

【代码随想录 二叉树】二叉树前序、中序、后序遍历的迭代遍历
文章目录 1. 二叉树前序遍历(迭代法)2. 二叉树后序遍历(迭代法)3. 二叉树中序遍历(迭代法) 1. 二叉树前序遍历(迭代法) 题目连接 🍎因为处理顺序和访问顺序是一致的。所…...

Error:(6, 43) java: 程序包org.springframework.data.redis.core不存在
目录 一、在做SpringBoot整合Redis的项目时,报错: 二、尝试 三、解决办法 一、在做SpringBoot整合Redis的项目时,报错: 二、尝试 给依赖加版本号,并且把版本换了个遍,也不行,也去update过ma…...
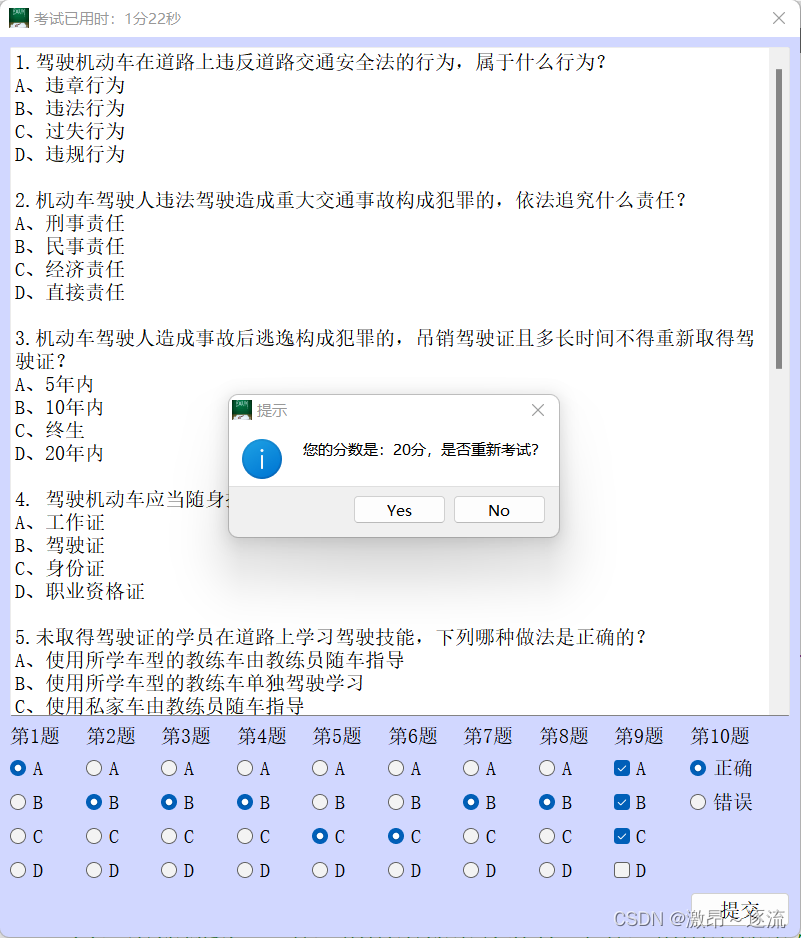
Qt 科目一考试系统(有源码)
项目源码和资源:科目一考试系统: qt实现科目一考试系统 一.项目概述 该项目是一个基于Qt框架开发的在线考试系统,主要实现了考试题目的随机抽取、考试时间限制、成绩统计等功能。用户可以通过界面操作进行考试,并查看自己的考试成绩。 二.技…...

在 Visual Studio 2022 (VS2022) 中删除 Git 分支的步骤如下
git branch -r PS \MauiApp1> git push origin --delete “20240523备份” git push origin --delete “20240523备份”...

玩转OpenHarmony智能家居:如何实现开发版“碰一碰”设备控制
一、简介 “碰一碰”设备控制,依托NFC短距通信协议,通过碰一碰的交互方式,将OpenAtom OpenHarmony(简称“OpenHarmony”)标准系统设备和全场景设备连接起来,解决了应用与设备之间接续慢、传输难的问题&…...

从游戏存档黑盒到透明编辑:uesave工具实战指南
从游戏存档黑盒到透明编辑:uesave工具实战指南 【免费下载链接】uesave Rust library and CLI to read and write Unreal Engine save files 项目地址: https://gitcode.com/gh_mirrors/ue/uesave 你是否曾经面对游戏存档文件感到束手无策?那些神…...

3步解锁Beyond Compare 5专业版:Python密钥生成器终极指南
3步解锁Beyond Compare 5专业版:Python密钥生成器终极指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 还在为Beyond Compare 5的30天试用期而烦恼吗?想免费使用这款强…...

新手入门使用 Python 快速接入 Taotoken 调用大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手入门使用 Python 快速接入 Taotoken 调用大模型 对于刚开始接触大模型 API 调用的开发者而言,如何快速、正确地接入…...

CRMEB 让您的在线商城更智能:最新商品模块更新亮点一览!
为了让广大电商商家更好地管理商品、提升用户的购物体验和满意度,近日,CRMEB标准版商城系统再度发力,对商品模块进行了全面升级,新增一系列功能,期待帮助企业商家更好地管理商品,提升用户购物体验ÿ…...
》控制范围(监控过程组)知识结构+10道真题)
软考高级《信息系统项目管理师教程(第4版)》控制范围(监控过程组)知识结构+10道真题
《信息系统项目管理师教程(第4版)》控制范围(监控过程组)知识结构+10道真题 一、控制范围 核心知识结构(第4版官方标准版) 1. 过程核心定义(必考,监控过程组重点) 控制范围属于范围管理、监控过程组,是范围管理的第六个过程,衔接确认范围与项目收尾,与实施整体变…...

Python代码性能优化实战:从循环到并发的全方位加速技巧
1. 项目概述:为什么你的Python代码总是“慢半拍”?干了这么多年开发,我见过太多同事和学员写的Python代码,功能上没问题,逻辑也清晰,但就是跑起来“慢半拍”。尤其是在处理数据清洗、批量文件操作或者实现一…...

RK3562核心板在工业物联网与边缘AI中的实战应用解析
1. 项目概述:为什么RK3562核心板值得关注?最近在为一个工业网关项目选型,市面上主流的ARM核心板看了个遍,从全志到瑞芯微,从低功耗到高性能。当拿到迅为电子这款基于RK3562的核心板规格书时,我的第一反应是…...

本地 AI 编码助手从 0 配起来:先选模型,再接 Ollama、VS Code、Claude Code 和 Codex
配本地 AI 编码助手,我现在最不建议的做法,就是打开 Ollama 以后直接搜一个最大模型下载。 这条路我踩过。 模型能跑起来,不代表能写代码。能写一个函数,不代表能进项目改文件。能在终端里回一句话,也不代表 Claude …...

如何做好费用率数据分析?巧用费用率研判企业盈利现状
企业经营发展过程中,盈利水平高低直接决定长远发展实力,而费用率数据是看透企业真实盈利水平最直观、最核心的指标。很多经营者在日常管理中,往往只看重账面营收的增长,却忽略了费用率数据的深层分析与解读,最终出现营…...

写给前端的 CAAN-pyasc:昇腾Python Ascend C绑定到底是啥?
写给前端的 CAAN-pyasc:昇腾Python Ascend C绑定到底是啥? 之前有兄弟问我:“哥,我想在 Python 里直接写 Ascend C 算子,不想写 C,咋搞?” 好问题。今天一次说清楚。 pyasc 是啥? py…...