提取COCO 数据集的部分类
1.python提取COCO数据集中特定的类
安装pycocotools github地址:https://github.com/philferriere/cocoapi
pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
若报错,pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI

换成
pip install git+git://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
实在不行的话,手动下载
git clone https://github.com/pdollar/coco.git
cd coco/PythonAPI
python setup.py build_ext --inplace #安装到本地
python setup.py build_ext install # 安装到Python环境中
没有的库自己pip
注意skimage用pip install scikit-image -i https://pypi.tuna.tsinghua.edu.cn/simple
提取特定的类别如下:
# conding='utf-8'
from pycocotools.coco import COCO
import os
import shutil
from tqdm import tqdm
import skimage.io as io
import matplotlib.pyplot as plt
import cv2
from PIL import Image, ImageDraw#the path you want to save your results for coco to voc
savepath="/opt/10T/home/asc005/YangMingxiang/DenseCLIP_/data/COCO/" #save_path
img_dir=savepath+'images/'
anno_dir=savepath+'Annotations/'
# datasets_list=['train2014', 'val2014']
datasets_list=['train2017', 'val2017']classes_names = ['sheep'] #coco
#Store annotations and train2014/val2014/... in this folder
dataDir= '/opt/10T/home/asc005/YangMingxiang/DenseCLIP_/data/coco/' #origin cocoheadstr = """\
<annotation><folder>VOC</folder><filename>%s</filename><source><database>My Database</database><annotation>COCO</annotation><image>flickr</image><flickrid>NULL</flickrid></source><owner><flickrid>NULL</flickrid><name>company</name></owner><size><width>%d</width><height>%d</height><depth>%d</depth></size><segmented>0</segmented>
"""
objstr = """\<object><name>%s</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>%d</xmin><ymin>%d</ymin><xmax>%d</xmax><ymax>%d</ymax></bndbox></object>
"""tailstr = '''\
</annotation>
'''#if the dir is not exists,make it,else delete it
def mkr(path):if os.path.exists(path):shutil.rmtree(path)os.mkdir(path)else:os.mkdir(path)
mkr(img_dir)
mkr(anno_dir)
def id2name(coco):classes=dict()for cls in coco.dataset['categories']:classes[cls['id']]=cls['name']return classesdef write_xml(anno_path,head, objs, tail):f = open(anno_path, "w")f.write(head)for obj in objs:f.write(objstr%(obj[0],obj[1],obj[2],obj[3],obj[4]))f.write(tail)def save_annotations_and_imgs(coco,dataset,filename,objs):#eg:COCO_train2014_000000196610.jpg-->COCO_train2014_000000196610.xmlanno_path=anno_dir+filename[:-3]+'xml'img_path=dataDir+dataset+'/'+filenameprint(img_path)dst_imgpath=img_dir+filenameimg=cv2.imread(img_path)#if (img.shape[2] == 1):# print(filename + " not a RGB image")# returnshutil.copy(img_path, dst_imgpath)head=headstr % (filename, img.shape[1], img.shape[0], img.shape[2])tail = tailstrwrite_xml(anno_path,head, objs, tail)def showimg(coco,dataset,img,classes,cls_id,show=True):global dataDirI=Image.open('%s/%s/%s'%(dataDir,dataset,img['file_name']))annIds = coco.getAnnIds(imgIds=img['id'], catIds=cls_id, iscrowd=None)# print(annIds)anns = coco.loadAnns(annIds)# print(anns)# coco.showAnns(anns)objs = []for ann in anns:class_name=classes[ann['category_id']]if class_name in classes_names:print(class_name)if 'bbox' in ann:bbox=ann['bbox']xmin = int(bbox[0])ymin = int(bbox[1])xmax = int(bbox[2] + bbox[0])ymax = int(bbox[3] + bbox[1])obj = [class_name, xmin, ymin, xmax, ymax]objs.append(obj)draw = ImageDraw.Draw(I)draw.rectangle([xmin, ymin, xmax, ymax])if show:plt.figure()plt.axis('off')plt.imshow(I)plt.show()return objsfor dataset in datasets_list:#./COCO/annotations/instances_train2014.jsonannFile='{}/annotations/instances_{}.json'.format(dataDir,dataset)#COCO API for initializing annotated datacoco = COCO(annFile)#show all classes in cococlasses = id2name(coco)print(classes)#[1, 2, 3, 4, 6, 8]classes_ids = coco.getCatIds(catNms=classes_names)print(classes_ids)for cls in classes_names:#Get ID number of this classcls_id=coco.getCatIds(catNms=[cls])img_ids=coco.getImgIds(catIds=cls_id)print(cls,len(img_ids))# imgIds=img_ids[0:10]for imgId in tqdm(img_ids):img = coco.loadImgs(imgId)[0]filename = img['file_name']# print(filename)objs=showimg(coco, dataset, img, classes,classes_ids,show=False)print(objs)save_annotations_and_imgs(coco, dataset, filename, objs)然后就可以了
2. 将上面获取的数据集划分为训练集和测试集
#conding='utf-8'
import os
import random
from shutil import copy2# origin
image_original_path = "/opt/10T/home/asc005/YangMingxiang/DenseCLIP_/data/COCO/images"
label_original_path = "/opt/10T/home/asc005/YangMingxiang/DenseCLIP_/data/COCO/Annotations"# parent_path = os.path.dirname(os.getcwd())
# parent_path = "D:\\AI_Find"
# train_image_path = os.path.join(parent_path, "image_data/seed/train/images/")
# train_label_path = os.path.join(parent_path, "image_data/seed/train/labels/")
train_image_path = os.path.join("/opt/10T/home/asc005/YangMingxiang/DenseCLIP_/data/COCO/train2017")
train_label_path = os.path.join("/opt/10T/home/asc005/YangMingxiang/DenseCLIP_/data/COCO/annotations/train2017")
test_image_path = os.path.join("/opt/10T/home/asc005/YangMingxiang/DenseCLIP_/data/COCO/val2017")
test_label_path = os.path.join("/opt/10T/home/asc005/YangMingxiang/DenseCLIP_/data/COCO/annotations/val2017")# test_image_path = os.path.join(parent_path, 'image_data/seed/val/images/')
# test_label_path = os.path.join(parent_path, 'image_data/seed/val/labels/')def mkdir():if not os.path.exists(train_image_path):os.makedirs(train_image_path)if not os.path.exists(train_label_path):os.makedirs(train_label_path)if not os.path.exists(test_image_path):os.makedirs(test_image_path)if not os.path.exists(test_label_path):os.makedirs(test_label_path)def main():mkdir()all_image = os.listdir(image_original_path)for i in range(len(all_image)):num = random.randint(1,5)if num != 2:copy2(os.path.join(image_original_path, all_image[i]), train_image_path)train_index.append(i)else:copy2(os.path.join(image_original_path, all_image[i]), test_image_path)val_index.append(i)all_label = os.listdir(label_original_path)for i in train_index:copy2(os.path.join(label_original_path, all_label[i]), train_label_path)for i in val_index:copy2(os.path.join(label_original_path, all_label[i]), test_label_path)if __name__ == '__main__':train_index = []val_index = []main()3.将上一步提取的COCO 某一类 xml转为COCO标准的json文件:
# -*- coding: utf-8 -*-
# @Time : 2019/8/27 10:48
# @Author :Rock
# @File : voc2coco.py
# just for object detection
import xml.etree.ElementTree as ET
import os
import jsoncoco = dict()
coco['images'] = []
coco['type'] = 'instances'
coco['annotations'] = []
coco['categories'] = []category_set = dict()
image_set = set()category_item_id = 0
image_id = 0
annotation_id = 0def addCatItem(name):global category_item_idcategory_item = dict()category_item['supercategory'] = 'none'category_item_id += 1category_item['id'] = category_item_idcategory_item['name'] = namecoco['categories'].append(category_item)category_set[name] = category_item_idreturn category_item_iddef addImgItem(file_name, size):global image_idif file_name is None:raise Exception('Could not find filename tag in xml file.')if size['width'] is None:raise Exception('Could not find width tag in xml file.')if size['height'] is None:raise Exception('Could not find height tag in xml file.')img_id = "%04d" % image_idimage_id += 1image_item = dict()image_item['id'] = int(img_id)# image_item['id'] = image_idimage_item['file_name'] = file_nameimage_item['width'] = size['width']image_item['height'] = size['height']coco['images'].append(image_item)image_set.add(file_name)return image_iddef addAnnoItem(object_name, image_id, category_id, bbox):global annotation_idannotation_item = dict()annotation_item['segmentation'] = []seg = []# bbox[] is x,y,w,h# left_topseg.append(bbox[0])seg.append(bbox[1])# left_bottomseg.append(bbox[0])seg.append(bbox[1] + bbox[3])# right_bottomseg.append(bbox[0] + bbox[2])seg.append(bbox[1] + bbox[3])# right_topseg.append(bbox[0] + bbox[2])seg.append(bbox[1])annotation_item['segmentation'].append(seg)annotation_item['area'] = bbox[2] * bbox[3]annotation_item['iscrowd'] = 0annotation_item['ignore'] = 0annotation_item['image_id'] = image_idannotation_item['bbox'] = bboxannotation_item['category_id'] = category_idannotation_id += 1annotation_item['id'] = annotation_idcoco['annotations'].append(annotation_item)def parseXmlFiles(xml_path):for f in os.listdir(xml_path):if not f.endswith('.xml'):continuebndbox = dict()size = dict()current_image_id = Nonecurrent_category_id = Nonefile_name = Nonesize['width'] = Nonesize['height'] = Nonesize['depth'] = Nonexml_file = os.path.join(xml_path, f)# print(xml_file)tree = ET.parse(xml_file)root = tree.getroot()if root.tag != 'annotation':raise Exception('pascal voc xml root element should be annotation, rather than {}'.format(root.tag))# elem is <folder>, <filename>, <size>, <object>for elem in root:current_parent = elem.tagcurrent_sub = Noneobject_name = Noneif elem.tag == 'folder':continueif elem.tag == 'filename':file_name = elem.textif file_name in category_set:raise Exception('file_name duplicated')# add img item only after parse <size> tagelif current_image_id is None and file_name is not None and size['width'] is not None:if file_name not in image_set:current_image_id = addImgItem(file_name, size)# print('add image with {} and {}'.format(file_name, size))else:raise Exception('duplicated image: {}'.format(file_name))# subelem is <width>, <height>, <depth>, <name>, <bndbox>for subelem in elem:bndbox['xmin'] = Nonebndbox['xmax'] = Nonebndbox['ymin'] = Nonebndbox['ymax'] = Nonecurrent_sub = subelem.tagif current_parent == 'object' and subelem.tag == 'name':object_name = subelem.textif object_name not in category_set:current_category_id = addCatItem(object_name)else:current_category_id = category_set[object_name]elif current_parent == 'size':if size[subelem.tag] is not None:raise Exception('xml structure broken at size tag.')size[subelem.tag] = int(subelem.text)# option is <xmin>, <ymin>, <xmax>, <ymax>, when subelem is <bndbox>for option in subelem:if current_sub == 'bndbox':if bndbox[option.tag] is not None:raise Exception('xml structure corrupted at bndbox tag.')bndbox[option.tag] = int(option.text)# only after parse the <object> tagif bndbox['xmin'] is not None:if object_name is None:raise Exception('xml structure broken at bndbox tag')if current_image_id is None:raise Exception('xml structure broken at bndbox tag')if current_category_id is None:raise Exception('xml structure broken at bndbox tag')bbox = []# xbbox.append(bndbox['xmin'])# ybbox.append(bndbox['ymin'])# wbbox.append(bndbox['xmax'] - bndbox['xmin'])# hbbox.append(bndbox['ymax'] - bndbox['ymin'])# print('add annotation with {},{},{},{}'.format(object_name, current_image_id, current_category_id,# bbox))addAnnoItem(object_name, current_image_id, current_category_id, bbox)if __name__ == '__main__':#修改这里的两个地址,一个是xml文件的父目录;一个是生成的json文件的绝对路径xml_path = r'G:\dataset\COCO\person\coco_val2014\annotations\\'json_file = r'G:\dataset\COCO\person\coco_val2014\instances_val2014.json'parseXmlFiles(xml_path)json.dump(coco, open(json_file, 'w'))相关文章:

提取COCO 数据集的部分类
1.python提取COCO数据集中特定的类 安装pycocotools github地址:https://github.com/philferriere/cocoapi pip install githttps://github.com/philferriere/cocoapi.git#subdirectoryPythonAPI若报错,pip install githttps://github.com/philferriere…...

高刚性滚柱直线导轨有哪些优势?
滚柱导轨是机械传动系统中用于支持和引导滑块或导轨的装置,承载能力较高、刚性强及高精度等特点。特别适用于大负载和高刚性的工业设备,如机床、数控机床等设备,这些优势使其在工业生产和机械设备中得到了广泛的应用。 1、高精度:…...
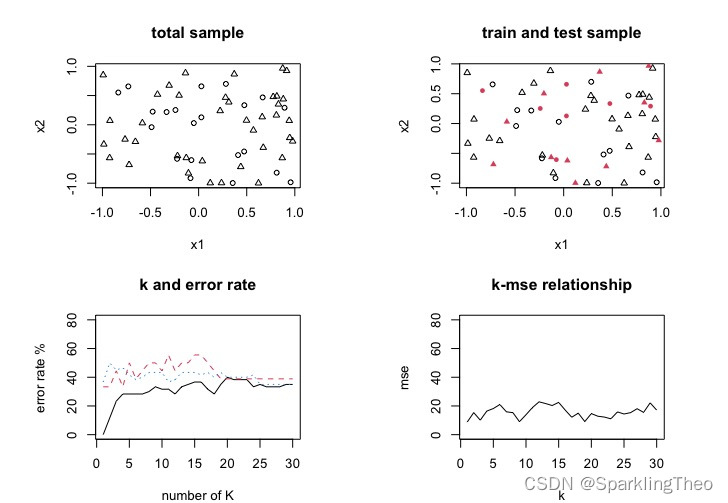
KNN及降维预处理方法LDA|PCA|MDS
文章目录 基本原理模型介绍模型分析 python代码实现降维处理维数灾难 curse of dimensionality线性变换 Linear TransformationLDA - 线性判别分析LDA python 实现PCA - 主成分分析PCA最近重构性PCA最大可分性PCA求解及说明PCA python实现 多维缩放 Multiple Dimensional Scali…...

论文精读-SwinIR Image Restoration Using Swin Transformer
论文精读-SwinIR: Image Restoration Using Swin Transformer SwinIR:使用 Swin Transformer进行图像恢复 参数量:SR 11.8M、JPEG压缩伪影 11.5M、去噪 12.0M 优点:1、提出了新的网络结构。它采用分块设计。包括浅层特征提取:cnn提取&#…...

解释Spring Bean的生命周期
Spring Bean的生命周期涉及到Bean的创建、配置、使用和销毁的各个阶段。理解这个生命周期对于编写高效的Spring应用和充分利用框架的功能非常重要。下面是Spring Bean生命周期的主要步骤: 1. 实例化Bean Spring容器首先将使用Bean的定义(无论是XML、注…...
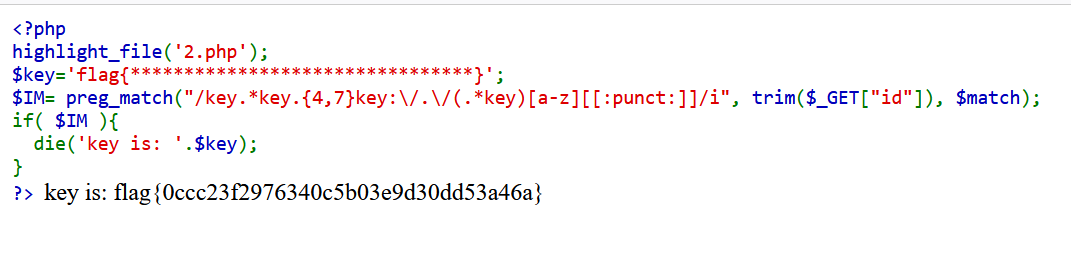
CTF网络安全大赛web题目:字符?正则?
题目来源于:bugku 题目难度:难 题目描 述: 字符?正则? 题目htmnl源代码: <code><span style"color: #000000"> <span style"color: #0000BB"><?php <br />highl…...
Linux——Docker容器虚拟化平台
安装docker 安装 Docker | Docker 从入门到实践https://vuepress.mirror.docker-practice.com/install/ 不需要设置防火墙 docker命令说明 docker images #查看所有本地主机的镜像 docker search 镜像名 #搜索镜像 docker pull 镜像名 [标签] #下载镜像&…...

Transformer详解(3)-多头自注意力机制
attention multi-head attention pytorch代码实现 import math import torch from torch import nn import torch.nn.functional as Fclass MultiHeadAttention(nn.Module):def __init__(self, heads8, d_model128, droput0.1):super().__init__()self.d_model d_model # 12…...

运用HTML、CSS设计Web网页——“西式甜品网”图例及代码
目录 一、效果展示图 二、设计分析 1.整体效果分析 2.头部header模块效果分析 3.导航及banner模块效果分析 4.分类classify模块效果分析 5.产品展示show模块效果分析 6.版权banquan模块效果分析 三、HTML、CSS代码分模块展示 1. 头部header模块代码 2.导航及bann…...

大语言模型是通用人工智能的实现路径吗?【文末有福利】
相关说明 这篇文章的大部分内容参考自我的新书《解构大语言模型:从线性回归到通用人工智能》,欢迎有兴趣的读者多多支持。 关于大语言模型的内容,推荐参考这个专栏。 内容大纲 相关说明一、哲学与人工智能二、内容简介三、书籍简介与福利粉…...

c语言——宏offsetof
1.介绍 !!! offsetof 是一个宏 2.使用举例 结构体章节的计算结构体占多少字节需要先掌握(本人博客结构体篇章中已经讲解过) 计算结构体中某变量相对于首地址的偏移,并给出说明 首先,结构体首个…...

C#串口通信-串口相关参数介绍
串口通讯(Serial Communication),是指外设和计算机间,通过数据信号线、地线等,按位进行传输数据的一种双向通讯方式。 串口是一种接口标准,它规定了接口的电气标准,没有规定接口插件电缆以及使用的通信协议,…...

节省时间与精力:用BAT文件和任务计划器自动执行重复任务
文章目录 1.BAT文件详解2. 经典BAT文件及使用场景3. 使用方法4. 如何设置BAT文件为定时任务5. 实例应用:自动清理临时文件 BAT文件,也就是批处理文件,是一种在Windows操作系统中自动执行一系列命令的文本文件。这些文件的扩展名为 .bat。通过…...

一年前的Java作业,模拟游戏玩家战斗
说明:一年前写的作业,感觉挺有意思的,将源码分享给大家。 刚开始看题也觉得很难,不过写着写着思路更加清晰,发现也没有想象中的那么难。 一、作业题目描述: 题目:模拟游戏玩家战斗 1.1 基础功…...

C++ 学习 关于引用
🙋本文主要讲讲C的引用 是基础入门篇~ 本文是阅读C Primer 第五版的笔记 🌈 关于引用 几个比较重要的点 🌿引用相当于为一个已经存在的对象所起的另外一个名字 🌞 定义引用时,程序把引用和它的初始值绑定(b…...
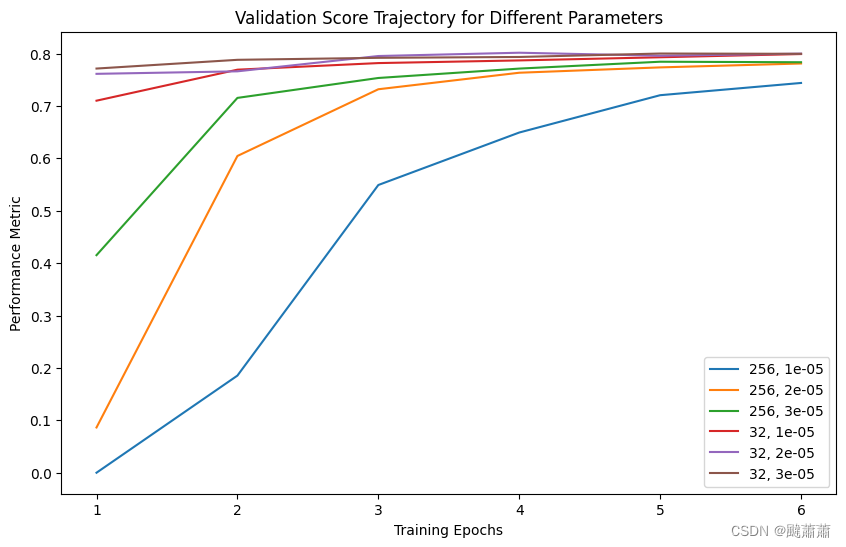
BERT ner 微调参数的选择
针对批大小和学习率的组合进行收敛速度测试,结论: 相同轮数的条件下,batchsize-32 相比 batchsize-256 的迭代步数越多,收敛更快批越大的话,学习率可以相对设得大一点 画图代码(deepseek生成)…...

【MySQL精通之路】系统变量-持久化系统变量
MySQL服务器维护用于配置其操作的系统变量。 系统变量可以具有影响整个服务器操作的全局值,也可以具有影响当前会话的会话值,或者两者兼而有之。 许多系统变量是动态的,可以在运行时使用SET语句进行更改,以影响当前服务器实例的…...

fdk-aac将aac格式转为pcm数据
int sampleRate 44100; // 采样率int sampleSizeInBits 16; // 采样位数,通常是16int channels 2; // 通道数,单声道为1,立体声为2FILE *m_fd NULL;FILE *m_fd2 NULL;HANDLE_AACDECODER decoder aacDecoder_Open(TT_MP4_ADTS, 1);if (!…...

【C语言深度解剖】(15):动态内存管理和柔性数组
🤡博客主页:醉竺 🥰本文专栏:《C语言深度解剖》 😻欢迎关注:感谢大家的点赞评论关注,祝您学有所成! ✨✨💜💛想要学习更多C语言深度解剖点击专栏链接查看&…...

力扣每日一题 5/25
题目: 给你一个下标从 0 开始、长度为 n 的整数数组 nums ,以及整数 indexDifference 和整数 valueDifference 。 你的任务是从范围 [0, n - 1] 内找出 2 个满足下述所有条件的下标 i 和 j : abs(i - j) > indexDifference 且abs(nums…...

隧道裂缝剥落病害AI识别系统
我国现有公路隧道超2.5万座,总里程超2.8万公里,其中运营超过15年的老旧隧道占比达35%。据交通运输部2025年统计,年均因隧道结构病害导致的交通中断超1200次,直接经济损失超45亿元。传统检测模式暴露四大核心痛点:检测周…...

DMA-330地址空间限制与扩展方案解析
1. DMA-330地址空间限制解析DMA-330作为Arm CoreLink系列中的直接内存访问控制器,其物理寻址能力直接由AxADDR信号宽度决定。这个32位地址总线宽度意味着它原生仅支持4GB(2^32字节)的物理地址空间访问。在实际嵌入式系统设计中,这…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...

2026 西安 AI 问答曝光搭建技术解析:GEO 知识图谱 + 深度测评
随着大语言模型技术的快速普及,AI 搜索已经成为用户获取企业信息、商家服务的核心入口。根据中国互联网信息中心 2026 年发布的《中国人工智能搜索发展报告》显示,2025 年国内 AI 搜索用户规模突破 8.2 亿,日均搜索请求超过 20 亿次ÿ…...

2605.VGGT-Omega 论文解读: 3D重建的Scaling Law, Register Attention效率革命 | Oxford+Meta CVPR26 Oral
VGGT-Omega: Scaling Feed-Forward 3D Reconstruction Jianyuan Wang, Minghao Chen, Shangzhan Zhang, Nikita Karaev, Johannes Schonberger, et al. Visual Geometry Group, Oxford Meta AI | CVPR 2026 Oral | arXiv 2605.15195 Paper | Project Page 一句话总结 VGGT-Om…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

三十岁想从零转行现实吗?带你分辨真正有前景的好工作
我是29岁那年,完成从转行裸辞副业的职业转型。 如果你把职业生涯看成是从现在开始30岁,到你退休那年,中间这么漫长的30年,那么30岁转行完全来得及…...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...

3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程
3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&a…...
运营管理与服务保障平台建设方案)
低空旅游观光与低空通勤(eVTOL)运营管理与服务保障平台建设方案
本方案旨在为eVTOL载具构建集运营管理、空中交通管制、安全保障与乘客服务于一体的数字化平台。通过微服务架构、5G-A融合感知、空域网格化与零信任安全等核心技术,解决高密度飞行中的资源调度与安全冲突问题。目标实现毫秒级冲突解算与15分钟内快速周转,…...