ClickHouse 24.4 版本发布说明

本文字数:13148;估计阅读时间:33 分钟
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发

新的一个月意味着新版本的发布!
发布概要
本次ClickHouse 24.4版本包含了13个新功能🎁、16个性能优化🛷、65个bug修复🐛
贡献者名单
和往常一样,我们向 24.4 版本中的所有新贡献者表示热烈欢迎!ClickHouse 的受欢迎程度在很大程度上归功于社区的努力。看到社区不断壮大总是令人感到骄傲。
以下是新贡献者的姓名:
Alexey Katsman、Anita Hammer、Arnaud Rocher、Chandre Van Der Westhuizen、Eduard Karacharov、Eliot Hautefeuille、Igor Markelov、Ilya Andreev、Jhonso7393、Joseph Redfern、Josh Rodriguez、Kirill、KrJin、Maciej Bak、Murat Khairulin、Paweł Kudzia、Tristan、dilet6298、loselarry
如果你想知道我们是如何生成这个列表的…… 点这里【https://gist.github.com/gingerwizard/5a9a87a39ba93b422d8640d811e269e9】。
递归CTE
由 Maksim Kita 贡献
SQL:1999引入了递归公共表达式(CTE)用于层次查询,从而将SQL扩展为图灵完备的编程语言。
至今,ClickHouse一直通过利用层次字典来支持层次查询。有了我们新的默认启用的查询分析和优化基础设施,我们终于有了引入了期待已久的强大功能,例如递归CTE。
ClickHouse的递归CTE采用标准的SQL:1999语法,并通过了递归CTE的所有PostgreSQL测试。此外,ClickHouse现在对递归CTE的支持甚至超过了PostgreSQL。在CTE的UNION ALL子句的底部,可以指定多个(任意复杂的)查询,可以多次引用CTE的基表等。
递归CTE可以优雅而简单地解决层次问题。例如,它们可以轻松回答层次数据模型(例如树和图)的可达性问题。
具体来说,递归CTE可以计算关系的传递闭包,这意味着它可以找出所有可能的间接连接。以伦敦地铁的站点连接为例,您可以想象到所有直接相连的地铁站:从牛津街到邦德街,从邦德街到大理石拱门,从大理石拱门到兰开斯特门,等等。这些连接的传递闭包则包含了这些站点之间所有可能的连接,例如:从牛津街到兰开斯特门,从牛津街到大理石拱门,等等。
为了演示这一点,我们使用了一个模拟伦敦地铁所有连接的数据集,其中每个条目表示两个直接相连的站点。然后,我们可以使用递归CTE来轻松回答这样的问题:
当从中央线的牛津街站出发时,我们最多可以在五次停靠内到达哪些站点?
我们用中央线站点地图的截图来进行可视化:

我们为存储伦敦地铁连接数据集创建了一个ClickHouse表:
CREATE OR REPLACE TABLE Connections (Station_1 String,Station_2 String,Line String,PRIMARY KEY(Line, Station_1, Station_2)
);值得注意的是,我们在上面的DDL语句中没有指定表引擎(这是自从ClickHouse 24.3之后才可能的),并且在列定义中使用了PRIMARY KEY语法(自从ClickHouse 23.7以来就可行了)。通过这样的设置,不仅我们的递归CTEs,连同我们的ClickHouse表DDL语法也符合SQL的标准。
我们利用url表函数和自动模式推断,直接将数据集加载到我们的表中:
INSERT INTO Connections
SELECT * FROM url('https://datasets-documentation.s3.eu-west-3.amazonaws.com/london_underground/london_connections.csv')加载后的数据如下所示:
SELECT*
FROM Connections
WHERE Line = 'Central Line'
ORDER BY Station_1, Station_2
LIMIT 10;┌─Station_1──────┬─Station_2────────┬─Line─────────┐1. │ Bank │ Liverpool Street │ Central Line │2. │ Bank │ St. Paul's │ Central Line │3. │ Barkingside │ Fairlop │ Central Line │4. │ Barkingside │ Newbury Park │ Central Line │5. │ Bethnal Green │ Liverpool Street │ Central Line │6. │ Bethnal Green │ Mile End │ Central Line │7. │ Bond Street │ Marble Arch │ Central Line │8. │ Bond Street │ Oxford Circus │ Central Line │9. │ Buckhurst Hill │ Loughton │ Central Line │
10. │ Buckhurst Hill │ Woodford │ Central Line │└────────────────┴──────────────────┴──────────────┘接着,我们使用递归CTE来回答上述问题:
WITH RECURSIVE Reachable_Stations AS
(SELECT Station_1, Station_2, Line, 1 AS stopsFROM ConnectionsWHERE Line = 'Central Line'AND Station_1 = 'Oxford Circus'UNION ALLSELECT rs.Station_1, c.Station_2, c.Line, rs.stops + 1 AS stopsFROM Reachable_Stations AS rs, Connections AS cWHERE rs.Line = c.LineAND rs.Station_2 = c.Station_1AND rs.stops < 5
)
SELECT DISTINCT (Station_1, Station_2, stops) AS connections
FROM Reachable_Stations
ORDER BY stops ASC;结果如下所示:
┌─connections────────────────────────────────┐1. │ ('Oxford Circus','Bond Street',1) │2. │ ('Oxford Circus','Tottenham Court Road',1) │3. │ ('Oxford Circus','Marble Arch',2) │4. │ ('Oxford Circus','Oxford Circus',2) │5. │ ('Oxford Circus','Holborn',2) │6. │ ('Oxford Circus','Bond Street',3) │7. │ ('Oxford Circus','Lancaster Gate',3) │8. │ ('Oxford Circus','Tottenham Court Road',3) │9. │ ('Oxford Circus','Chancery Lane',3) │
10. │ ('Oxford Circus','Marble Arch',4) │
11. │ ('Oxford Circus','Oxford Circus',4) │
12. │ ('Oxford Circus','Queensway',4) │
13. │ ('Oxford Circus','Holborn',4) │
14. │ ('Oxford Circus','St. Paul\'s',4) │
15. │ ('Oxford Circus','Bond Street',5) │
16. │ ('Oxford Circus','Lancaster Gate',5) │
17. │ ('Oxford Circus','Tottenham Court Road',5) │
18. │ ('Oxford Circus','Notting Hill Gate',5) │
19. │ ('Oxford Circus','Chancery Lane',5) │
20. │ ('Oxford Circus','Bank',5) │└────────────────────────────────────────────┘递归CTE具有简单的迭代执行逻辑,类似于递归的自我连接,一直连接下去,直到找不到新的连接伙伴或满足中止条件。因此,我们上面的CTE首先执行UNION ALL子句的顶部部分,查询我们的Connections表,找到所有直接连接到中央线上的牛津街站的站点。这将返回一个表,它绑定到Reachable_Stations标识符,并且看起来像这样:
Initial Reachable_Stations table content┌─Station_1─────┬─Station_2────────────┐│ Oxford Circus │ Bond Street ││ Oxford Circus │ Tottenham Court Road │└───────────────┴──────────────────────┘从现在开始,只有CTE的UNION ALL子句的底部部分将被执行(递归执行):
将Reachable_Stations与Connections表连接,找到那些在Connections表中的Station_1值与Reachable_Stations的Station_2值匹配的连接伙伴。
Connections table join partners┌─Station_1────────────┬─Station_2─────┐
│ Bond Street │ Marble Arch │
│ Bond Street │ Oxford Circus │
│ Tottenham Court Road │ Holborn │
│ Tottenham Court Road │ Oxford Circus │
└──────────────────────┴───────────────┘通过UNION ALL子句,这些连接伙伴被添加到Reachable_Stations表中,标记了递归CTE的第一次迭代的完成。在接下来的迭代中,我们执行CTE的UNION ALL子句的底部部分,继续将Reachable_Stations与Connections表连接,以识别(并添加到Reachable_Stations中)所有在Connections表中的Station_1值与Reachable_Stations的Station_2值匹配的新连接伙伴。这些迭代将持续进行,直到找不到新的连接伙伴或满足停止条件。在我们的查询中,我们使用一个停靠计数器来在达到从起始站点允许的停靠数时中止CTE的迭代循环。
需要注意的是,结果中将牛津街站列为从牛津街站到达的站点,分别需要2和4次停靠。这在理论上是正确的,但并不是非常实际,这是因为我们的查询不考虑任何方向或循环。我们把这留给读者作为一个有趣的练习。
作为一个附加问题,我们感兴趣的是从中央线的牛津街站到达斯特拉特福站需要多少次停靠。我们再次用中央线地图来可视化这个问题:
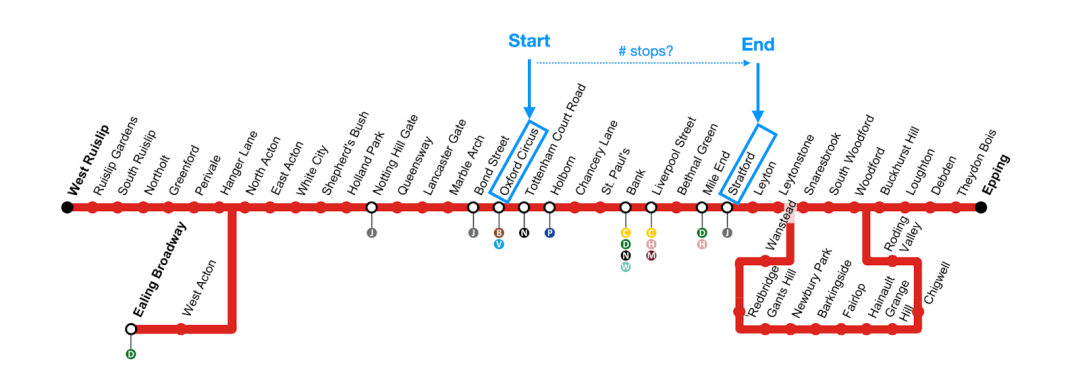
为此,我们只需修改递归CTE的中止条件(一旦添加了具有Stratford作为目标站点的连接伙伴到CTE表中,就停止CTE的连接迭代):
WITH RECURSIVE Reachable_Stations AS
(SELECT Station_1, Station_2, Line, 1 AS stopsFROM ConnectionsWHERE Line = 'Central Line'AND Station_1 = 'Oxford Circus'UNION ALLSELECT rs.Station_1 c.Station_2, c.Line, rs.stops + 1 AS stopsFROM Reachable_Stations AS rs, Connections AS cWHERE rs.Line = c.LineAND rs.Station_2 = c.Station_1AND 'Stratford' NOT IN (SELECT Station_2 FROM Reachable_Stations)
)
SELECT max(stops) as stops
FROM Reachable_Stations;结果显示,从牛津街站到达斯特拉特福站需要9次停靠,与上述中央线地图计划相匹配。
┌─stops─┐
1. │ 9 │└───────┘递归CTE可以轻松回答关于这个数据集的更有趣的问题。例如,原始版本数据集中的相对连接时间可以用来找出从牛津街站到希思罗机场站的最快连接(跨越地铁线)。敬请期待在单独的后续文章中解决这个问题。
QUALIFY
由 Maksim Kita 贡献
这个版本新增的另一个功能是QUALIFY子句,它允许我们根据窗口函数的值进行筛选。
我们将通过窗口函数 - 排名示例来演示如何使用它。数据集包含假设的足球运动员及其薪水。我们可以像这样将其导入到ClickHouse中:
CREATE TABLE salaries ORDER BY team AS
FROM url('https://raw.githubusercontent.com/ClickHouse/examples/main/LearnClickHouseWithMark/WindowFunctions-Aggregation/data/salaries.csv')
SELECT * EXCEPT (weeklySalary), weeklySalary AS salary
SETTINGS schema_inference_make_columns_nullable=0;让我们快速查看薪水表中的数据:
SELECT * FROM salaries LIMIT 5; ┌─team──────────────┬─player───────────┬─position─┬─salary─┐
1. │ Aaronbury Seekers │ David Morton │ D │ 63014 │
2. │ Aaronbury Seekers │ Edwin Houston │ D │ 51751 │
3. │ Aaronbury Seekers │ Stephen Griffith │ M │ 181825 │
4. │ Aaronbury Seekers │ Douglas Clay │ F │ 73436 │
5. │ Aaronbury Seekers │ Joel Mendoza │ D │ 257848 │└───────────────────┴──────────────────┴──────────┴────────┘接下来,让我们计算每个球员所在位置的薪水排名。即,他们相对于在同一位置上踢球的人来说薪水有多少?
SELECT player, team, position AS pos, salary,rank() OVER (PARTITION BY position ORDER BY salary DESC) AS posRank
FROM salaries
ORDER BY salary DESC
LIMIT 5 ┌─player──────────┬─team────────────────────┬─pos─┬─salary─┬─posRank─┐
1. │ Robert Griffin │ North Pamela Trojans │ GK │ 399999 │ 1 │
2. │ Scott Chavez │ Maryhaven Generals │ M │ 399998 │ 1 │
3. │ Dan Conner │ Michaelborough Rogues │ M │ 399998 │ 1 │
4. │ Nathan Thompson │ Jimmyville Legionnaires │ D │ 399998 │ 1 │
5. │ Benjamin Cline │ Stephaniemouth Trojans │ D │ 399998 │ 1 │└─────────────────┴─────────────────────────┴─────┴────────┴─────────┘假设我们想要通过位置排名(posRank)来筛选出薪水最高的前3名球员。我们可能会尝试添加一个WHERE子句来实现这一目标:
SELECT player, team, position AS pos, salary,rank() OVER (PARTITION BY position ORDER BY salary DESC) AS posRank
FROM salaries
WHERE posRank <= 3
ORDER BY salary DESC
LIMIT 5Received exception:
Code: 184. DB::Exception: Window function rank() OVER (PARTITION BY position ORDER BY salary DESC) AS posRank is found in WHERE in query. (ILLEGAL_AGGREGATION)但由于WHERE子句在窗口函数评估之前运行,这样是行不通的。在24.4版本发布之前,我们可以通过引入CTE来绕过这个问题:
WITH salaryRankings AS(SELECT player, if(length(team) <=25, team, concat(substring(team, 5), 1, '...')) AS team, position AS pos, salary,rank() OVER (PARTITION BY position ORDER BY salary DESC) AS posRankFROM salariesORDER BY salary DESC)
SELECT *
FROM salaryRankings
WHERE posRank <= 3 ┌─player────────────┬─team────────────────────┬─pos─┬─salary─┬─posRank─┐1. │ Robert Griffin │ North Pamela Trojans │ GK │ 399999 │ 1 │2. │ Scott Chavez │ Maryhaven Generals │ M │ 399998 │ 1 │3. │ Dan Conner │ Michaelborough Rogue... │ M │ 399998 │ 1 │4. │ Benjamin Cline │ Stephaniemouth Troja... │ D │ 399998 │ 1 │5. │ Nathan Thompson │ Jimmyville Legionnai... │ D │ 399998 │ 1 │6. │ William Rubio │ Nobleview Sages │ M │ 399997 │ 3 │7. │ Juan Bird │ North Krystal Knight... │ GK │ 399986 │ 2 │8. │ John Lewis │ Andreaberg Necromanc... │ D │ 399985 │ 3 │9. │ Michael Holloway │ Alyssaborough Sages │ GK │ 399984 │ 3 │
10. │ Larry Buchanan │ Eddieshire Discovere... │ F │ 399973 │ 1 │
11. │ Alexis Valenzuela │ Aaronport Crusaders │ F │ 399972 │ 2 │
12. │ Mark Villegas │ East Michaelborough ... │ F │ 399972 │ 2 │└───────────────────┴─────────────────────────┴─────┴────────┴─────────┘尽管这个查询是有效的,但它相当繁琐。现在有了QUALIFY子句,我们可以在不需要引入CTE的情况下筛选数据,如下所示:
SELECT player, team, position AS pos, salary,rank() OVER (PARTITION BY position ORDER BY salary DESC) AS posRank
FROM salaries
QUALIFY posRank <= 3
ORDER BY salary DESC;接着,我们将得到和以前相同的结果。
Join 的性能提升
由 Maksim Kita 贡献
此外,针对某些特定的JOIN使用情况,还进行了一些性能改进。
首先是谓词下推的改进,即分析器确定筛选条件可以应用于JOIN的两侧时的优化。
让我们通过一个示例来说明,我们使用The OpenSky数据集,该数据集包含2019年至2021年的航空数据。我们想要获取经过旧金山的十次航班的列表,可以使用以下查询来实现:
SELECTl.origin,r.destination AS dest,firstseen,lastseen
FROM opensky AS l
INNER JOIN opensky AS r ON l.destination = r.origin
WHERE notEmpty(l.origin) AND notEmpty(r.destination) AND (r.origin = 'KSFO')
LIMIT 10
SETTINGS optimize_move_to_prewhere = 0为了避免ClickHouse执行另一项优化,我们禁用了optimize_move_to_prewhere,这样我们就能看到JOIN改进带来的好处。如果我们在24.3上运行此查询,结果将如下所示:
┌─origin─┬─dest─┬───────────firstseen─┬────────────lastseen─┐1. │ 00WA │ 00CL │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │2. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │3. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │4. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │5. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │6. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │7. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │8. │ 00WA │ YSSY │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │9. │ 00WA │ YSSY │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │
10. │ 00WA │ YSSY │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │└────────┴──────┴─────────────────────┴─────────────────────┘10 rows in set. Elapsed: 0.656 sec. Processed 15.59 million rows, 451.90 MB (23.75 million rows/s., 688.34 MB/s.)
Peak memory usage: 62.79 MiB.让我们看看 24.4 的表现:
┌─origin─┬─dest─┬───────────firstseen─┬────────────lastseen─┐1. │ 00WA │ 00CL │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │2. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │3. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │4. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │5. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │6. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │7. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │8. │ 00WA │ YSSY │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │9. │ 00WA │ YSSY │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │
10. │ 00WA │ YSSY │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │└────────┴──────┴─────────────────────┴─────────────────────┘10 rows in set. Elapsed: 0.079 sec.查询速度提升了约8倍。如果我们通过SELECT *返回所有列,那么在24.3中,此查询所花费的时间会增加到超过4秒,在24.4中则为0.4秒,这是一个10倍的改进。
让我们来看看为什么查询更快。其中两行很关键:
INNER JOIN opensky AS r ON l.destination = r.origin
WHERE notEmpty(l.origin) AND notEmpty(r.destination) AND (r.origin = 'KSFO')我们WHERE子句的最后一个条件是r.origin = 'KSFO'。在上一行中,我们指定只有当l.destination = r.origin时才进行连接,这意味着l.destination也必须是'KSFO'。24.4版本中的分析器知道这一点,因此可以更早地过滤掉很多行。
换句话说,在24.4中,我们的WHERE子句实际上是这样的
INNER JOIN opensky AS r ON l.destination = r.origin
WHERE notEmpty(l.origin) AND notEmpty(r.destination)
AND (r.origin = 'KSFO') AND (l.destination = 'KSFO')第二个改进是,如果JOIN后的谓词过滤掉任何未连接的行,分析器现在会自动将OUTER JOIN转换为INNER JOIN。
举个例子,假设我们最初编写了一个查询来查找旧金山和纽约之间的航班,捕捉直达航班和有中转的航班。
SELECTl.origin,l.destination,r.destination,registration,l.callsign,r.callsign
FROM opensky AS l
LEFT JOIN opensky AS r ON l.destination = r.origin
WHERE notEmpty(l.destination)
AND (l.origin = 'KSFO')
AND (r.destination = 'KJFK')
LIMIT 10后来我们添加了一个额外的过滤器,只返回r.callsign = 'AAL1424'的行。
SELECTl.origin,l.destination AS leftDest,r.destination AS rightDest,registration AS reg,l.callsign,r.callsign
FROM opensky AS l
LEFT JOIN opensky AS r ON l.destination = r.origin
WHERE notEmpty(l.destination)
AND (l.origin = 'KSFO')
AND (r.destination = 'KJFK')
AND (r.callsign = 'AAL1424')
LIMIT 10
SETTINGS optimize_move_to_prewhere = 0由于现在要求JOIN右侧的callsign列具有值,LEFT JOIN可以转换为INNER JOIN。让我们来看看在24.3和24.4中查询性能的变化。
24.3
┌─origin─┬─leftDest─┬─rightDest─┬─reg────┬─callsign─┬─r.callsign─┐1. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │2. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │3. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │4. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │5. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │6. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │7. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │8. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │9. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │
10. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │└────────┴──────────┴───────────┴────────┴──────────┴────────────┘10 rows in set. Elapsed: 1.937 sec. Processed 63.98 million rows, 2.52 GB (33.03 million rows/s., 1.30 GB/s.)
Peak memory usage: 2.84 GiB.24.4
┌─origin─┬─leftDest─┬─rightDest─┬─reg────┬─callsign─┬─r.callsign─┐1. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │2. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │3. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │4. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │5. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │6. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │7. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │8. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │9. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │
10. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │└────────┴──────────┴───────────┴────────┴──────────┴────────────┘10 rows in set. Elapsed: 0.762 sec. Processed 23.22 million rows, 939.75 MB (30.47 million rows/s., 1.23 GB/s.)
Peak memory usage: 9.00 MiB.在24.4中,查询速度快了将近三倍。
如果您想了解JOIN性能改进是如何实现的,请阅读Maksim Kita的博客文章,他详细解释了所有内容。
关于24.4版本的内容就介绍到这里。我们邀请您参加5月30日举行的24.5版本发布会。请确保注册,这样您就能收到Zoom网络研讨会的所有详情。【https://clickhouse.com/company/events/v24-5-community-release-call】
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求
相关文章:
ClickHouse 24.4 版本发布说明
本文字数:13148;估计阅读时间:33 分钟 审校:庄晓东(魏庄) 本文在公众号【ClickHouseInc】首发 新的一个月意味着新版本的发布! 发布概要 本次ClickHouse 24.4版本包含了13个新功能🎁…...

amtlib.dll打不开怎么办?一键修复丢失amtlib.dll方法
电脑丢失amtlib.dll文件是什么情况?出现amtlib.dll打不开怎么办?这样的情况有什么解决方法呢?今天就和大家聊聊amtlib.dll文件同时教大家一键修复丢失amtlib.dll方法?一起来看看amtlib.dll文件丢失会有哪些方法修复? a…...

【退役之重学Java】关于 volatile 关键字
一、是什么 volatile 是Java中的关键字,用于声明变量,具有两个主要特性使其特殊。 二、两个特性 首先,如果有一个volatile变量,任何线程都无法将其缓存在计算机的缓存中。访问始终从主内存中进行。其次,如果volatile变…...
“大数据建模、分析、挖掘技术应用研修班”的通知!
随着2015年9月国务院发布了《关于印发促进大数据发展行动纲要的通知》,各类型数据呈现出了指数级增长,数据成了每个组织的命脉。今天所产生的数据比过去几年所产生的数据大好几个数量级,企业有了能够轻松访问和分析数据以提高性能的新机会&am…...

Uniapp自定义默认返回按钮回退页面
//自定义后退时的操作onBackPress() {this.back1();return true;}, methods: { //跳转到 tabBar 页面,并关闭其他所有非 tabBar 页面back1() {uni.switchTab({url: /pages/mangement/mangement});},//关闭所有页面,打开到应用内的某个页面。back1() {uni…...
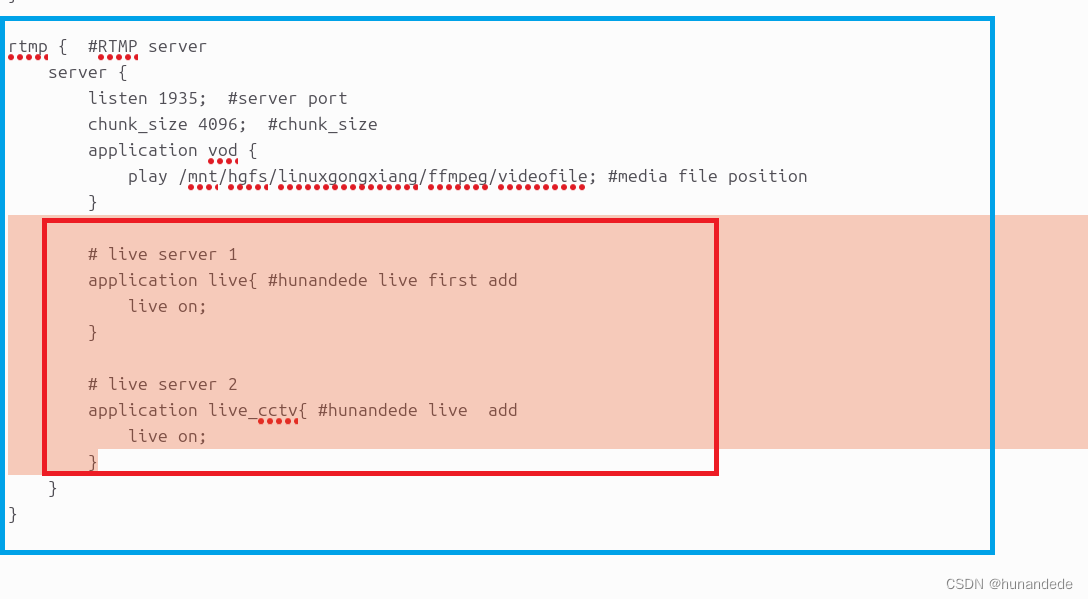
音视频开发5 补充 - Nginx搭建rtmp流媒体服务器,目的是让ffmpeg 可以直播推流
直播推流 ffmpeg -re -i out.mp4 -c copy flv rtmp://server/live/streamName -re, 表示按时间戳读取文件 参考: Nginx 搭建 rtmp 流媒体服务器 (Ubuntu 16.04) https://www.jianshu.com/p/16741e363a77 第一步 准备工作 安装nginx需要的依赖包 打开 ubutun 终端…...

小猫咪的奇幻冒险:一个简单的Python小游戏
新书上架~👇全国包邮奥~ python实用小工具开发教程http://pythontoolsteach.com/3 欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 目录 一、游戏简介与演示 二、游戏开发与运行 1. 环境搭建 2. 代码解析 3. 加速机制 三、游戏…...

专注于运动控制芯片、运动控制产品研发、生产与销售为一体的技术型芯片代理商、方案商——青牛科技
深圳市青牛科技实业有限公司,是专注于运 动控制芯片、运动控制产品研发、生产与销售为一体的技术型 芯片代理商、方案商。现今代理了国产品牌GLOBALCHIP,芯谷,矽普,TOPPOWER等品牌。其中代理品牌TOPPOWER为电源模块,他们公司通过了…...
【C++】继承(二)深入理解继承:派生类默认成员函数与友元、静态成员的奥秘
目录 派生类的默认成员函数①派生类的构造函数②派生类的拷贝构造函数③派生类的赋值构造④派生类的析构函数 继承与友元继承与静态成员 前言 我们在上一章讲解了: 继承三部曲,本篇基于上次的基础继续深入了解继承的相关知识,欢迎大家和我一起学习继承 派…...

【MATLAB源码-第214期】基于matlab的遗传算法GA最短路径路由优化算法仿真。
操作环境: MATLAB 2022a 1、算法描述 在现代网络通信和路径规划领域,最短路径路由优化算法是一项关键技术。它涉及在给定的网络拓扑中寻找从源点到目标点的最短或成本最低的路径。近年来,遗传算法(GA)因其出色的全局…...
顺序栈 链式栈)
数据结构(四)顺序栈 链式栈
一、概念 栈是一种先进后出的数据结构。FILO(firt in late out) 逻辑结构:线性结构 二、存储结构: (一) 顺序存储 顺序栈 基于一个数组配合一个栈顶"指针(数组下标)–top" 顺序栈的本质就是对…...

【linux】g++/gcc编译器
目录 背景知识 gcc如何完成 预处理(进行宏替换) 编译(生成汇编) 汇编(生成机器可识别代码) 链接(生成可执行文件或库文件) 在这里涉及到一个重要的概念:函数库 函数库一般分为静态库和动态库两…...

VBA批量合并带有图片、表格与文本框的Word
本文介绍基于VBA语言,对大量含有图片、文本框与表格的Word文档加以批量自动合并,并在每一次合并时添加分页符的方法。 在我们之前的文章基于Python中docx与docxcompose批量合并多个Word文档文件并逐一添加分页符(https://blog.csdn.net/zhebu…...
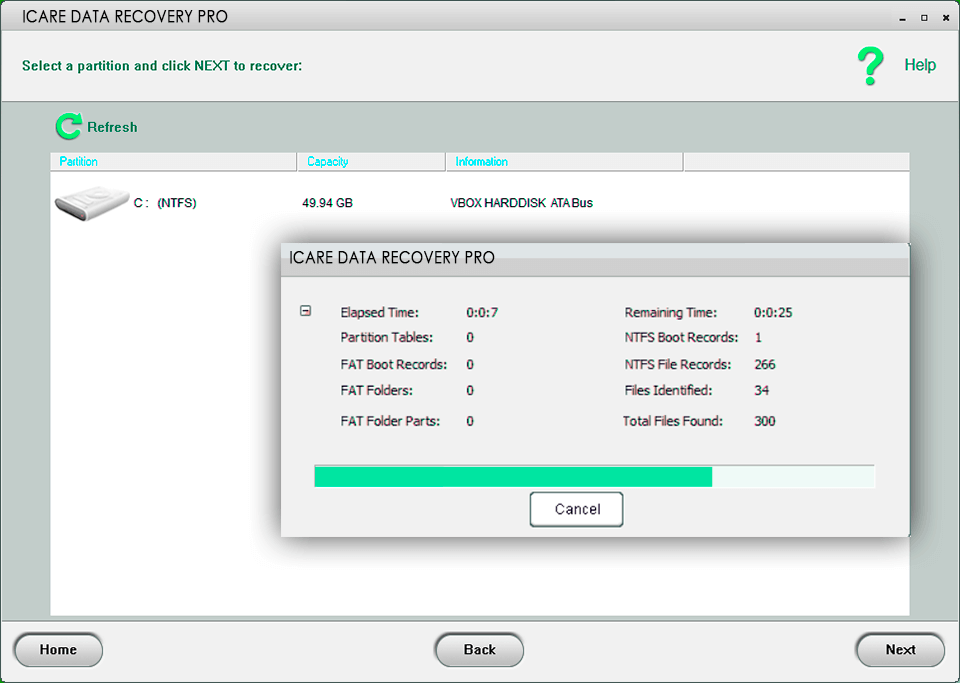
市面上前 11 名的 Android 数据恢复软件
Android数据恢复软件是恢复无意中删除的文件或文件夹的必要工具。该软件还将帮助您恢复丢失或损坏的信息。本文介绍提供数据备份和磁盘克隆选项的程序,这些选项有助于在Android设备上恢复文件的过程。 如果您正在寻找一种有效的方法来恢复图像,文档&…...

【数据结构与算法 | 基础篇】数组模拟栈
1. 前言 前文我们刚提及了如何用单向链表来模拟栈. 我们还可以用数组来模拟栈.使用栈顶指针top来进行栈顶的操作. 2. 数组模拟栈 (1). 栈接口 public interface stack<E> {//压栈boolean push(E value);//弹栈, 栈非空返回栈顶元素E pop();//返回栈顶元素, 但不弹栈E…...

css卡片横线100%宽度
所需样式: 横线不用border, 用单独一个div, 这样就不会影响父组件的padding <div class"pumpDetailView"><div class"pump_title_name"><span>{{ pumpInfo.pointname }}</span><divclass"point_state":style"…...

回溯大法总结
前言 本篇博客将分两步来进行,首先谈谈我对回溯法的理解,然后通过若干道题来进行讲解,最后总结 对回溯法的理解 回溯法可以看做蛮力法的升级版,它在解决问题时的每一步都尝试所有可能的选项,最终找出所以可行的方案…...

基于Android Studio图书管理,图书借阅系统
目录 项目介绍 图片展示 运行环境 获取方式 项目介绍 用户 书架:搜索书籍,查看书籍,借阅书籍,收藏书籍,借阅书籍必须在一个月之内还书; 我的:可以修改密码,退出登录ÿ…...

SCSS 基本使用详解
一、引言 SCSS 是 Sass(Syntactically Awesome Stylesheets)的其中一种语法,是一种预处理器脚本语言,能够扩展 CSS 的功能,使其更加强大和高效。SCSS 保留了 CSS 的原有语法,同时增加了变量、嵌套规则、混…...
10.3.k8s的附加组件-图形化管理工具dashboard
目录 一、dashboard介绍 二、部署安装dashboard组件 1.下载dashboard本地文件 2.修改nodeport的端口范围 3.创建和查看dashboard 4.电脑浏览器访问测试 5.token登录方式登录dashboard 5.1.查看dashboard的token 5.2.继续查看用户token的secrets资源详细信息 5.3.复制…...

癫痫手术精准定位:基于脑电信号昼夜节律与多生物标志物的机器学习分析框架
1. 项目概述:当机器学习遇见脑电信号,如何让癫痫手术更精准?作为一名长期耕耘在生物医学信号处理与机器学习交叉领域的工程师,我常常思考如何将算法模型从实验室的“玩具”变成临床医生手中可靠的“手术刀”。癫痫,这个…...

WPF虚拟桌宠组件:可嵌入、高性能、工程化UI生命体
1. 这不是“桌面宠物”,而是一个可嵌入的WPF UI组件化生命体你可能在Windows XP时代见过那只晃着尾巴、偶尔打哈欠的3D小猫,也可能在Win10系统托盘里点开过一个会眨眼的像素狐狸——但那些是独立进程、是系统级小工具、是“看一眼就关掉”的轻量娱乐。而…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...

Codex使用API Key授权无法使用插件?
小伙伴们,大家好,我是小溪,见字如面。对于没有ChatGPT账号的小伙伴来说,虽然可以通过API Key授权的方式使用Codex桌面端,但是会有一些限制。比如无法使用插件功能,无法使用Codex移动端进行远程控制等。为了…...

告别Postman!用APIfox搞定接口测试+自动化,这份保姆级教程带你从环境配置到报告生成
从Postman到APIfox:接口测试自动化的高效迁移指南如果你还在为接口测试中的重复劳动和多环境切换头疼,是时候考虑从Postman迁移到APIfox了。作为一名经历过这个转型过程的开发者,我想分享一些实战经验,帮助你平滑过渡并最大化利用…...

Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题
Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常遇到C盘爆红、…...

树莓派工业GPIO接口板:电气隔离与电平转换实战指南
1. 项目概述:为什么需要一块工业级GPIO接口板?如果你用树莓派做过一些硬件项目,尤其是涉及到控制继电器、电机或者连接工业设备(比如PLC、变频器)时,大概率踩过这样的坑:直接用树莓派的GPIO引脚…...

模拟电路实现自主循线机器人:无MCU的硬件逻辑设计
1. 项目概述:用最纯粹的模拟电路,造一台会“思考”的机器人每次看到那些在赛道上灵巧穿梭的循线小车,你是不是也手痒,想自己动手做一个?但一听到“单片机”、“编程”、“Arduino”这些词,又觉得门槛太高&a…...

数字合成器d-FORMANT:从模拟经典到数字复刻的工程实践
1. 项目概述:从模拟经典到数字复刻如果你对合成器稍有了解,或者对电子音乐制作背后的硬件感兴趣,那么“FORMANT”这个名字你一定不陌生。它最初是上世纪70年代由《Elektor》杂志发布的一款模拟单音合成器,以其清晰的模块化设计和出…...

【国家级攻防演练级建议】:DeepSeek私有化部署中4类隐蔽后门植入路径与实时检测方案
更多请点击: https://kaifayun.com 第一章:DeepSeek私有化部署中隐蔽后门植入的攻防对抗本质 在私有化场景下,DeepSeek模型的部署链路常跨越镜像构建、权重加载、推理服务启动及API网关接入等多个环节。攻击者可利用构建上下文污染、依赖包劫…...