图像分类和文本分类(传统机器学习和深度学习)
1. 传统机器学习—决策树
1.1 图像分类代码
from sklearn import tree
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建决策树模型
clf = tree.DecisionTreeClassifier()# 训练模型
clf = clf.fit(X_train, y_train)# 预测新数据
predicted_class = clf.predict(X_test)# 打印预测结果
print(f"预测类别:{predicted_class}")# 可视化决策树
from sklearn.tree import export_graphviz
export_graphviz(clf, out_file="iris_tree.dot", feature_names=iris.feature_names, class_names=iris.target_names)
- 该代码首先加载了鸢尾花数据集,并将其划分为特征矩阵 X 和目标向量 y。
- 然后,使用
train_test_split函数将数据集划分为训练集和测试集。 - 接着,创建了一个决策树分类器模型,并使用训练数据对其进行训练。
- 最后,使用训练好的模型对测试数据进行预测,并打印预测结果。
- 此外,该代码还使用
export_graphviz函数将决策树可视化,并将其保存为iris_tree.dot文件。您可以使用 Graphviz 软件打开该文件,查看决策树的结构。
1.2 文本分类代码
from sklearn import tree
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer# 加载数据集
categories = ['alt.atheism', 'soc.religion.christian']
twenty_newsgroups = fetch_20newsgroups(subset='train', categories=categories)
X, y = twenty_newsgroups.data, twenty_newsgroups.target# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 特征提取
vectorizer = TfidfVectorizer()
X_train_vectorized = vectorizer.fit_transform(X_train)
X_test_vectorized = vectorizer.transform(X_test)# 创建决策树模型
clf = tree.DecisionTreeClassifier()# 训练模型
clf = clf.fit(X_train_vectorized, y_train)# 预测新数据
predicted_class = clf.predict(X_test_vectorized)# 打印预测结果
print(f"预测类别:{predicted_class}")# 可视化决策树
from sklearn.tree import export_graphviz
export_graphviz(clf, out_file="newsgroup_tree.dot", feature_names=vectorizer.get_feature_names(), class_names=categories)
- 该代码首先加载了 20 Newsgroups 数据集,并将其划分为训练集和测试集。
- 然后,使用
TfidfVectorizer对文本数据进行特征提取,将文本转换为词频-逆文档频率向量。 - 接着,创建了一个决策树分类器模型,并使用训练数据对其进行训练。
- 最后,使用训练好的模型对测试数据进行预测,并打印预测结果。
- 此外,该代码还使用
export_graphviz函数将决策树可视化,并将其保存为newsgroup_tree.dot文件。您可以使用 Graphviz 软件打开该文件,查看决策树的结构。
2. 深度学习
2.1 图像分类代码
import torch
from torchvision import datasets, transforms
from torch import nn, optim# 定义模型
class ImageClassifier(nn.Module):def __init__(self):super(ImageClassifier, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, 5)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.pool(nn.functional.relu(self.conv1(x)))x = self.pool(nn.functional.relu(self.conv2(x)))x = x.view(-1, 16 * 5 * 5)x = nn.functional.relu(self.fc1(x))x = nn.functional.relu(self.fc2(x))x = self.fc3(x)return x# 加载数据集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transforms.ToTensor())
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transforms.ToTensor())# 创建数据加载器
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)# 定义模型、损失函数和优化器
model = ImageClassifier()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
for epoch in range(10):for i, (images, labels) in enumerate(train_loader):# 前向传播outputs = model(images)loss = criterion(outputs, labels)# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()# 打印训练信息if i % 100 == 0:print(f'Epoch: {epoch + 1}/{10}, Step: {i}/{len(train_loader)}, Loss: {loss.item():.4f}')# 测试模型
correct = 0
total = 0
with torch.no_grad():for images, labels in test_loader:outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Accuracy: {correct / total:.4f}')
- 首先,定义了一个图像分类模型
ImageClassifier,该模型包含三个卷积层、两个最大池化层、三个全连接层和一个 ReLU 激活函数。 - 然后,加载了 CIFAR10 数据集,并将其划分为训练集和测试集。
- 接着,创建了数据加载器,用于将数据分批加载到模型中。
- 然后,定义了模型、损失函数和优化器。
- 接下来,训练模型,并每隔 100 步打印训练信息。
- 最后,测试模型,并打印模型的准确率。
2.2 文本分类代码
import torch
from torchtext import data
from torchtext.vocab import GloVe
from torch import nn, optim# 定义模型
class TextClassifier(nn.Module):def __init__(self, vocab_size, embedding_dim, output_dim):super(TextClassifier, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, 128, batch_first=True)self.fc = nn.Linear(128, output_dim)def forward(self, text):embedded = self.embedding(text)output, (hidden, cell) = self.lstm(embedded)hidden = hidden[-1, :, :]output = self.fc(hidden)return output# 加载数据集
TEXT = data.Field(tokenize='spacy', include_lengths=True)
LABEL = data.LabelField(dtype=torch.long)
fields = [('text', TEXT), ('label', LABEL)]
train_data, test_data = data.TabularDataset.splits(path='./data', train='train.csv', test='test.csv', format='csv', fields=fields
)# 创建词向量
TEXT.build_vocab(train_data, vectors=GloVe(name='6B', dim=100))
LABEL.build_vocab(train_data)# 创建数据加载器
train_iterator, test_iterator = data.BucketIterator.splits((train_data, test_data), batch_size=64, device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
)# 定义模型、损失函数和优化器
model = TextClassifier(len(TEXT.vocab), 100, 2)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
for epoch in range(10):for i, batch in enumerate(train_iterator):# 前向传播text, text_lengths = batch.textoutputs = model(text)loss = criterion(outputs, batch.label)# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()# 打印训练信息if i % 100 == 0:print(f'Epoch: {epoch + 1}/{10}, Step: {i}/{len(train_iterator)}, Loss: {loss.item():.4f}')# 测试模型
correct = 0
total = 0
with torch.no_grad():for batch in test_iterator:text, text_lengths = batch.textoutputs = model(text)_, predicted = torch.max(outputs.data, 1)total += batch.label.size(0)correct += (predicted == batch.label).sum().item()print(f'Accuracy: {correct / total:.4f}')
- 首先,定义了一个文本分类模型
TextClassifier,该模型包含一个嵌入层、一个 LSTM 层和一个全连接层。 - 然后,加载了文本数据集,并将其划分为训练集和测试集。
- 接着,创建了词向量,用于将单词转换为向量。
- 然后,创建了数据加载器,用于将数据分批加载到模型中。
- 然后,定义了模型、损失函数和优化器。
- 接下来,训练模型,并每隔 100 步打印训练信息。
- 最后,测试模型,并打印模型的准确率。
3. 决策树介绍
3.1 决策树介绍
什么是决策树?
决策树是一种用于分类和回归任务的机器学习算法。它通过一系列规则将数据点分类到不同的类别中,就像树枝分叉一样。每个规则都基于一个特征,例如“颜色”或“尺寸”,每个分支都代表一个可能的特征值,例如“红色”或“大”。
决策树的结构类似于一棵倒置的树,其中:
- 根节点: 代表整个数据集。
- 内部节点: 代表一个特征,并根据特征值进行分支。
- 叶节点: 代表一个类别或预测结果。
决策树的学习过程
决策树的学习过程可以分为以下几个步骤:
- 特征选择: 选择最能区分不同类别的特征。
- 决策树构建: 根据选择的特征构建决策树,并递归地将数据点分配到不同的分支。
- 剪枝: 为了避免过拟合,可以剪枝去除一些不重要的分支。
决策树的优缺点
优点:
- 易于理解: 决策树的结构清晰,易于理解和解释。
- 无需数据预处理: 决策树可以处理各种类型的数据,无需进行数据预处理。
- 鲁棒性强: 决策树对缺失值和噪声数据具有较强的鲁棒性。
缺点:
- 容易过拟合: 决策树容易过拟合,尤其是在训练数据量较少的情况下。
- 对特征的顺序敏感: 决策树对特征的顺序敏感,不同的特征顺序可能导致不同的决策树结构。
决策树的应用
决策树在许多领域都有应用,例如:
- 分类: 识别客户的意图、预测客户的流失率、识别欺诈性交易。
- 回归: 预测房价、预测股票价格、预测天气变化。
- 规则提取: 提取可解释的规则,用于决策支持系统。
3.2 决策树使用例子
例子: 预测房价
假设我们有一组数据,包含以下特征:
- 房屋面积
- 房屋年代
- 房屋位置
- 房屋状况
我们的目标是预测每栋房子的价格。
步骤:
- 特征选择: 我们可以选择以下特征进行预测:
- 房屋面积
- 房屋年代
- 房屋位置
- 决策树构建: 我们可以使用决策树算法构建决策树,并根据特征值将数据点分配到不同的分支。
- 预测: 我们可以使用决策树预测每栋房子的价格。
示例代码:
from sklearn import tree
from sklearn.datasets import load_boston# 加载波士顿房价数据集
boston = load_boston()
X = boston.data
y = boston.target# 训练决策树模型
clf = tree.DecisionTreeRegressor()
clf = clf.fit(X, y)# 预测新数据
X_new = [[2500, 20, 1, 5]] # 房屋面积为 2500 平方英尺,房屋年代为 20 年,房屋位置为 1,房屋状况为 5
y_pred = clf.predict(X_new)# 打印预测结果
print("预测价格:", y_pred)
结果:
预测价格: [438436.11111111]
解释:
决策树模型预测该房屋的价格为 438,436.11 美元。
相关文章:
)
图像分类和文本分类(传统机器学习和深度学习)
1. 传统机器学习—决策树 1.1 图像分类代码 from sklearn import tree from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split# 加载数据集 iris load_iris() X, y iris.data, iris.target# 划分数据集 X_train, X_test, y_train,…...
基于SpringBoot和Hutool工具包实现的验证码案例
目录 验证码案例 1. 需求 2. 准备工作 3. 约定前后端交互接口 需求分析 接口定义 4. Hutool 工具介绍 5. 实现验证码 后端代码 前端代码 6. 运行测试 验证码案例 随着安全性的要求越来越高,目前项目中很多都会使用验证码,只要涉及到登录&…...

python-找出四位数中的玫瑰花数
【问题描述】玫瑰花数指一个n位数(n>4),其每位上的数字的n次幂之和等于本身。 请求出所有四位数中的玫瑰花数 【输入形式】 【输出形式】 【样例输入】 【样例输出】1634 8208 9474 【样例说明】 【评分标准】 完整代码如下: for n in ra…...

Linux-命令上
at是一次性的任务,crond是循环的定时任务 如果 cron.allow 文件存在,只有在文件中出现其登录名称的用户可以使用 crontab 命令。root 用户的登录名必须出现在 cron.allow 文件中,如果这个文件存在的话。系统管理员可以明确的停止一个用户&am…...
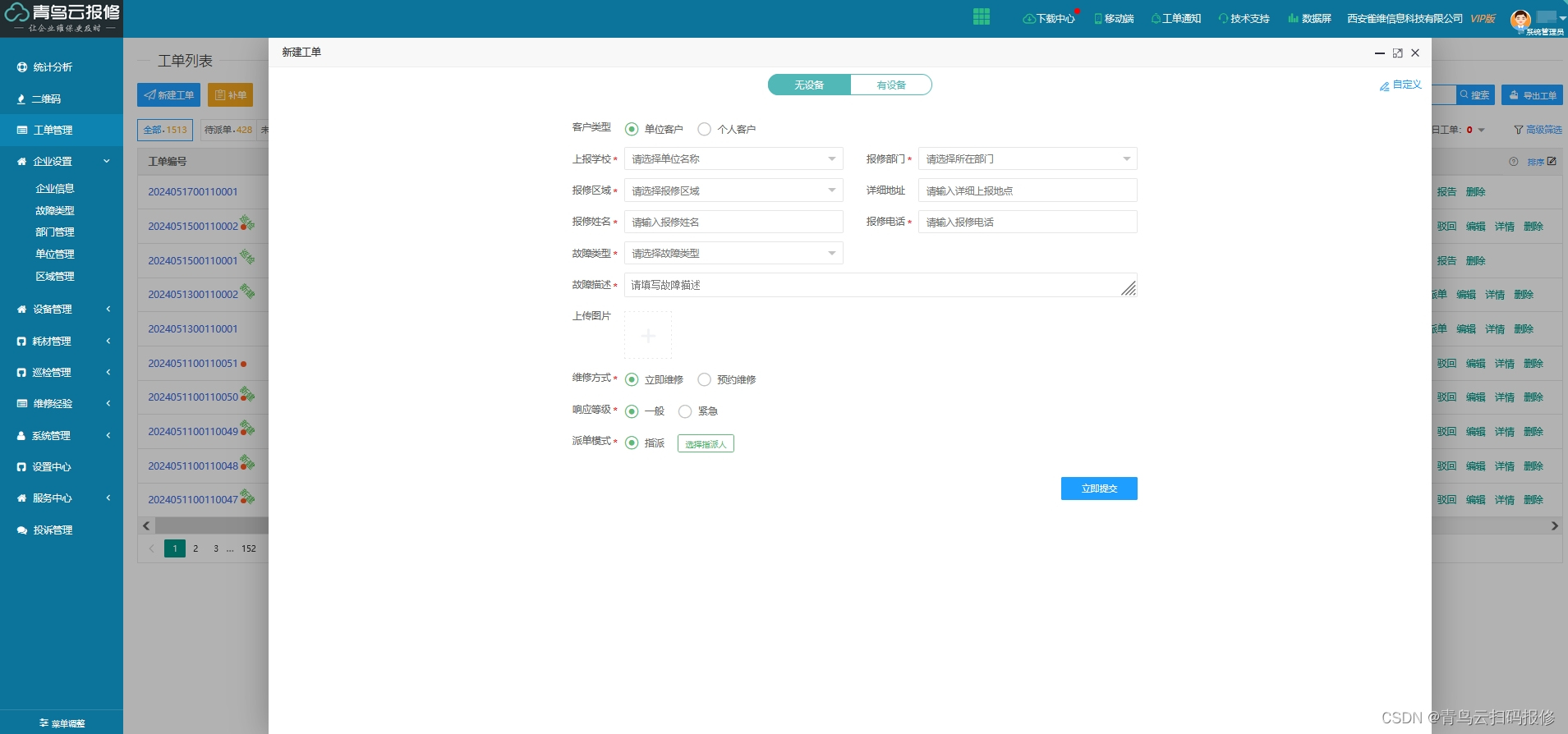
青鸟云报修系统:实现高效、便捷的维修申请处理
在日常生活和工作中,故障报修难免会遇到,售后报修服务则成为了解决问题的关键。纸质化售后报修维修申请单,作为报修流程中的重要一环,在一定程度上能够记录和追踪售后报修维修流程,但在实际操作过程中却存在着诸多弊端…...

Python解析网页
目录 1、Beautiful Soup 2、解析数据 3、遍历文档树 4、搜索文档树 一、Beautiful Soup 1、什么是Beautiful Soup 定义:Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库. 功能:它能够通过你喜欢的转换器实现惯用的文档导航,查找,修…...

IDEA连接MySQL后如何管理数据库
上一节讲解了IDEA如何连接MySQL数据库管理系统,接下来我们就可以在IDEA里使用MySQL来管理数据库了。那么如果我们现在还没有创建需要的数据库怎么办?本节就来教大家如何在IDEA连接MySQL后管理数据库(创建/修改/删除数据库、创建/修改/删除表、插入/更新/…...

linux新机快速配置ssh
配置SSH以实现证书登录 要配置新的Linux机器以实现证书登录,您需要执行以下步骤: 安装SSH服务器: sudo apt-get install openssh-server修改SSH端口(可选): SSH配置文件(通常位于/etc/ssh/sshd…...
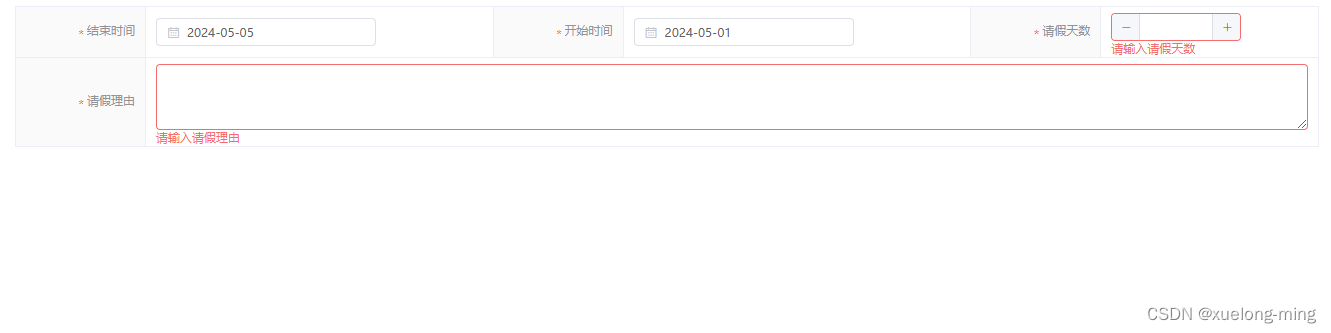
使用elementUI的form表单校验时,错误提示位置异常解决方法
问题 最近在做项目时遇到一个问题,使用elementUI的Descriptions 描述列表与form表单校验时,遇到校验信息显示的位置不对,效果如图: 期望显示在表格中。 效果 代码 html <el-form :model"form":rules"rules…...

Android面试题之Kotlin常见集合操作技巧
本文首发于公众号“AntDream”,欢迎微信搜索“AntDream”或扫描文章底部二维码关注,和我一起每天进步一点点 list 创建和修改 不可变list,listOf var list listOf("a","d","f") println(list.getOrElse(3){"Unkn…...
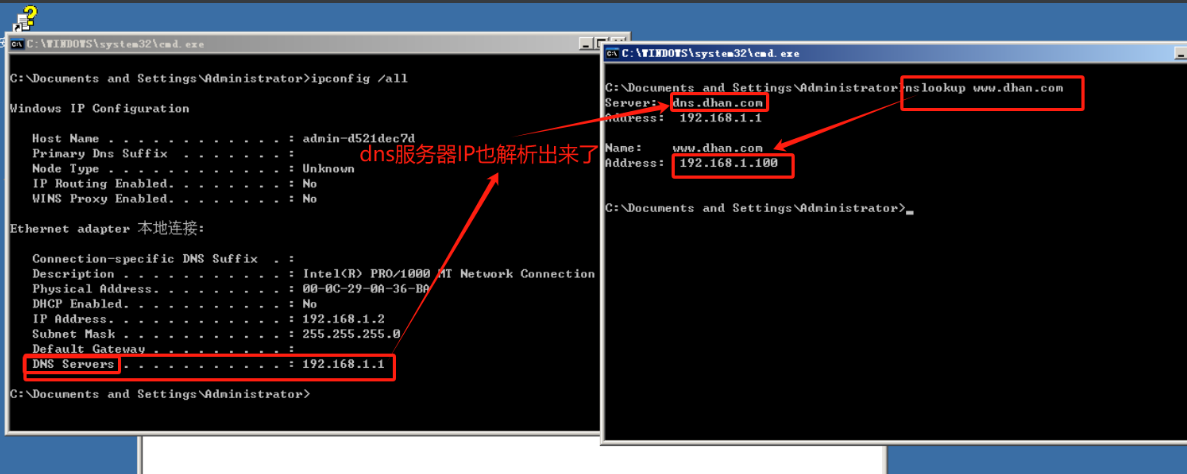
网络拓扑—DNS服务搭建
文章目录 DNS服务搭建网络拓扑配置网络DNSPC 安装DNS服务配置DNS服务创建正向查找区域创建反向查找区域创建子域名 PC机DNS域名解析 DNS服务搭建 网络拓扑 为了节省我的U盘空间,没有用路由器,所以搭建的环境只要在同网段即可。 //交换机不用考虑 DNS&a…...

Mybatis-Plus笔记
1.MP基础 1.1 MP常见注解 TableName(“指定表明”) TableName("tb_user") // 指定表名 Data NoArgsConstructor AllArgsConstructor Builder public class User {private Long id;private String userName;private String password;private String name;private I…...
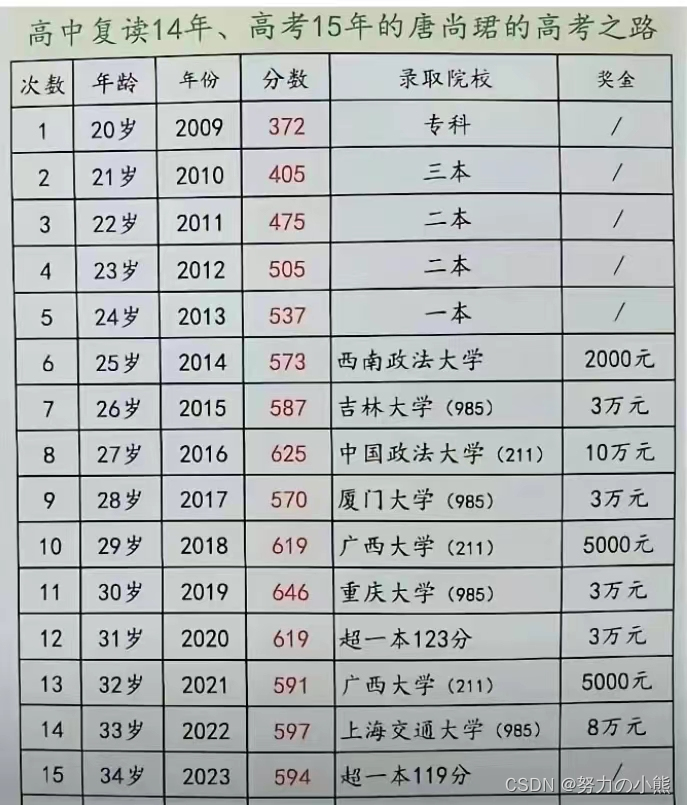
“高考钉子户”唐尚珺决定再战2024年高考
“高考钉子户”唐尚珺决定在2024年再次参加高考,这个选择确实很特别也很有趣。十几年连续参加高考,他已经积累了大量的备考经验和应试技巧。这样的经验对于高考辅导机构来说无疑是非常宝贵的资源,他如果选择去辅导机构当老师,应该…...

Hive安装教程
前置条件:hadoop&mysql docker容器安装mysql-CSDN博客 以下的/opt/bigdata目录根据自己实际情况更改 1.上传hive包并解压 tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /opt/bigdata/ 2.修改路径 mv /opt/bigdata/apache-hive-3.1.3-bin/ hive cd /opt/bigdata/hive/…...
使用Python Tkinter创建GUI应用程序
大家好,当我们谈及使用Python Tkinter创建GUI应用程序时,我们涉及的不仅是技术和代码,更是关于创造力和用户体验的故事。Tkinter作为Python标准库中最常用的GUI工具包,提供了丰富的功能和灵活的接口,让开发者能够轻松地…...

使用 RT 矩阵进行 3D 点云变换详解(基于 PCL 和 Eigen 库)
在 3D 点云处理中,RT 矩阵是一个常用的工具,用于对点云进行旋转和平移操作。本文将详细介绍 RT 矩阵的概念,并通过一个示例程序演示如何基于 PCL 和 Eigen 库将一帧点云进行矩阵变换再输出。 本教程的示例代码和点云数据可在 GitHub 下载。 什…...

CTFHUB技能树——SSRF(二)
目录 上传文件 FastCGI协议 Redis协议 上传文件 题目描述:这次需要上传一个文件到flag.php了.祝你好运 index.php与上题一样,使用POST请求的方法向flag.php传递参数 //flag.php页面源码 <?phperror_reporting(0);if($_SERVER["REMOTE_ADDR&…...

Vue3实现简单的瀑布流效果,可抽离成组件直接使用
先来看下效果图: 瀑布流中的内容可进行自定义,这里的示例图是通过不同背景颜色的展示进行区分,每个瀑布流中添加了自定义图片和文字描述。 实现方式: 1.建立子组件(可单独抽离)写出瀑布流的样式 文件名为…...

【已解决】C#如何消除Halcon上一次显示窗口的涂层
前言 在通过C#进行封装Halcon的时候发现一个问题,就是如果我重新去标定一个图像的时候不能把上一次的清掉,然后之前的会覆盖掉原来的,这个确实是这样,但是如果说现在的图像面积比之前的小的那么就没有任何效果显示,因…...
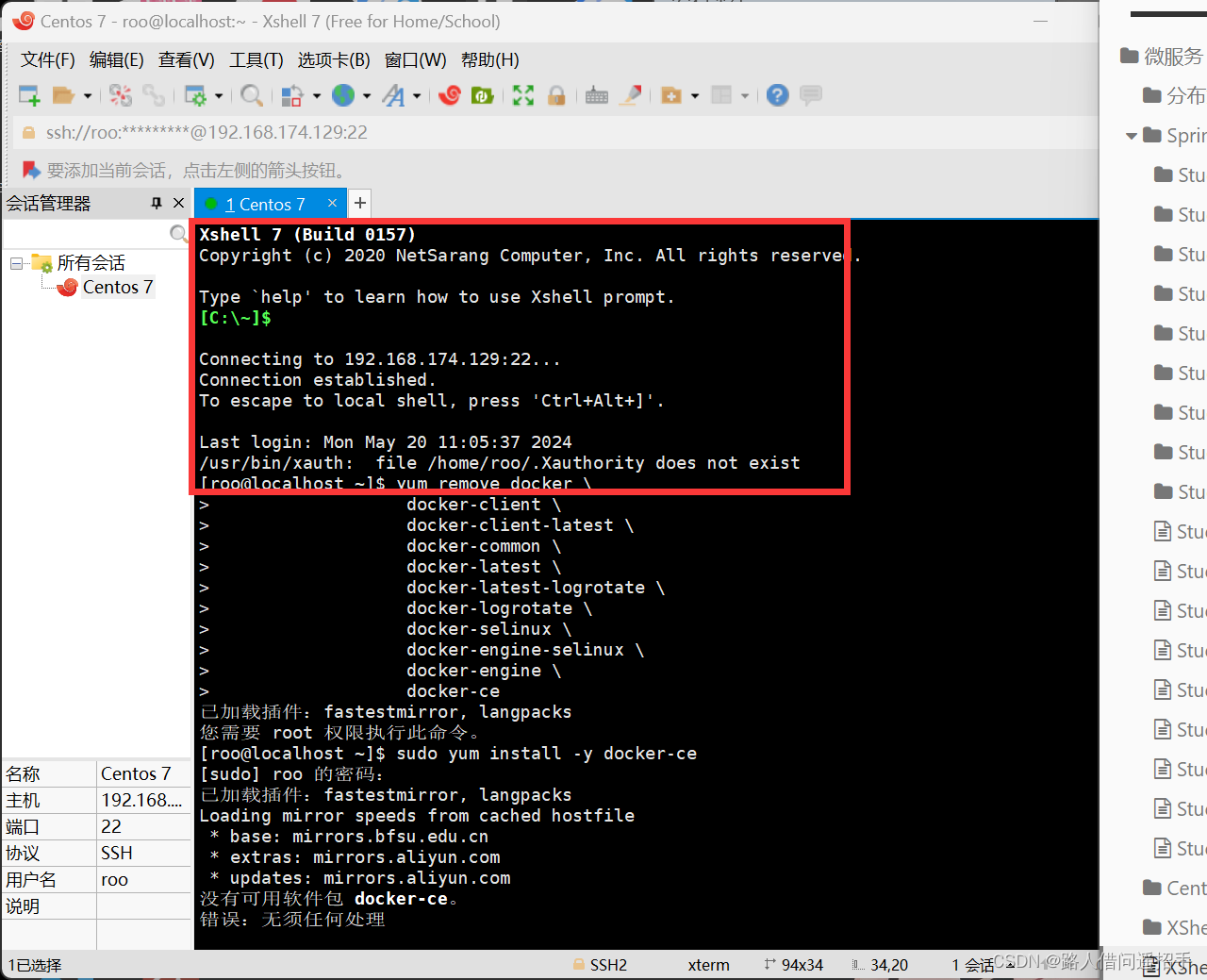
XShell-连接-Centos 7
XShell 连接Centos 7 一.准备 安装XShell XShell下载地址: 在虚拟机上安装Centos 7,具体操作自行学习 二.Centos 7的准备 1.网络适配器修改为NAT 2.获取IP 输入命令: ip addr我的Centos 7对外IP为192.168.174.129 三.XShell连接Cento…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南
#身份证OCR, #OCR接口, #API接入, #Python示例, #Java示例, #PHP示例, #踩坑指南, #石榴智能, #实名认证, #图片识别 身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南 作者:石榴智能技术团队 一、前言 身份证OCR识别已经不是什…...

别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单
别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单当你花了三天三夜精心雕琢的Blender模型,导入Unity后却变成了一团旋转错乱、贴图闪烁的"抽象艺术",那种崩溃感每个3D开发者都懂。本文将用实战经验帮你建立一…...

亚马逊卖家公开信息数据提取:反爬攻防战与 Python 批量采集实战
摘要: 批量获取亚马逊(Amazon)第三方卖家的商业名称、信用代码和注册地址等信息,对于跨境 B2B 拓客和供应链分析具有重要意义。然而,亚马逊的 Cloudflare 盾和 Robot 验证码构成了极高的反爬门槛。本文将深度解析亚马逊…...

新手村任务:成为一个架构师需要哪些装备?
新手村任务:成为一个架构师需要哪些装备? 一、前言 如果你刚入行不久,想成为一名架构师,那这篇文章就是为你写的。 我们把成为架构师比作一个RPG游戏,你是主角,需要收集各种装备、刷经验、升级技能。 新手村的第一个任务就是:了解你需要哪些装备。 二、架构师技能树…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...

同步带装配工艺要点与损伤防控策略
一、引言在工业精密传动系统中,盖茨同步带凭借高精度、高效率、无滑差的优势,成为自动化设备、精密机床、输送产线的核心传动部件。多数企业在运维中,普遍将同步带异常磨损、断齿、断带等故障归咎于工况恶劣或产品质量问题,却忽略…...
)
别再瞎拖拽了!Unity Prefab从创建到批量修改的保姆级工作流(含变体与嵌套实战)
Unity Prefab高效工作流:从创建到批量修改的实战指南在Unity项目开发中,Prefab(预制体)是最基础也最强大的工具之一。但很多开发者,尤其是初学者,往往停留在简单的"拖拽-修改"阶段,没…...