【大数据】MapReduce JAVA API编程实践及适用场景介绍

目录
1.前言
2.mapreduce编程示例
3.MapReduce适用场景
1.前言
本文是作者大数据系列专栏的其中一篇,前文我们依次聊了大数据的概论、分布式文件系统、分布式数据库、以及计算引擎mapreduce核心概念以及工作原理。
书接上文,本文将会继续聊一下mapreduce的编程实践以及mapreduce的适用场景。基于的Hadoop版本依然是前文的hadoop3.1.3。
2.mapreduce编程示例
本文依然以最经典的单词分词,即统计各个单词数量的业务场景为例。mapreduce其实就是编写map函数和reduce函数。map reduce的Java API中提供了map和reduce的标准接口,实现接口,编写自己的业务逻辑即可。
依赖:
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>3.1.3</version>
</dependency>map函数:
map阶段会从分布式文件系统HDFS中去读数据,读入的数据先进行分词,然后进行初步的统计。所以编写map函数要写的就是分词和统计:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.Text;public class MyMapper extends Mapper<Object, Text, Text, IntWritable> {private Text word = new Text();@Overrideprotected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, new IntWritable(1));}}
}key,是每条输入的键,默认情况下处理文本文件时通常是记录的偏移量,类型为Object(实践中常为LongWritable)。
context是输出。
在new StringTokenizer这一步,文本就会进行分词。
IntWritable是int的包装类,主要是为了赋予int类型可序列化的能力,毕竟要在网络中进行传输。
reduce函数:
reduce的shuffle是底层自动执行的,所以我们只需要编写好reduce函数即可:
reduce函数的输入就是shuffle后的<key,Iterable>,context是输出。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {int sum=0;for(IntWritable val:values){sum+=val.get();}context.write(key,new IntWritable(sum));}
}
main函数:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class MapReduceTest {public static void main(String[] args)throws Exception {Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://192.168.31.10:9000");conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");Job job = Job.getInstance(conf, "word count");job.setJarByClass(MapReduceTest.class); // 使用当前类的类加载器job.setMapperClass(MyMapper.class);job.setCombinerClass(MyReducer.class);job.setReducerClass(MyReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path("/user/hadoop/input/input1.txt"));FileOutputFormat.setOutputPath(job, new Path("/user/hadoop/output"));job.waitForCompletion(true);}
}
3.MapReduce适用场景
mapreduce适用于哪些场景?之前聊了那么多,似乎MapReduce也就只能统计一下数量?其实不是这样的,MapReduce能用来实现一切代数关系运算,即:选择、投影、并、交、差、连接,也就是对应关系型数据库的全部操作。
以连接为例:
在存数据的时候通过一个外键来预留好关联点。map和reduce函数都是我们手动定义的,map阶段我们完全可以把外键作为key,这样在reduce的shuffle阶段数据自然就会通过外键这个key聚合在一起。
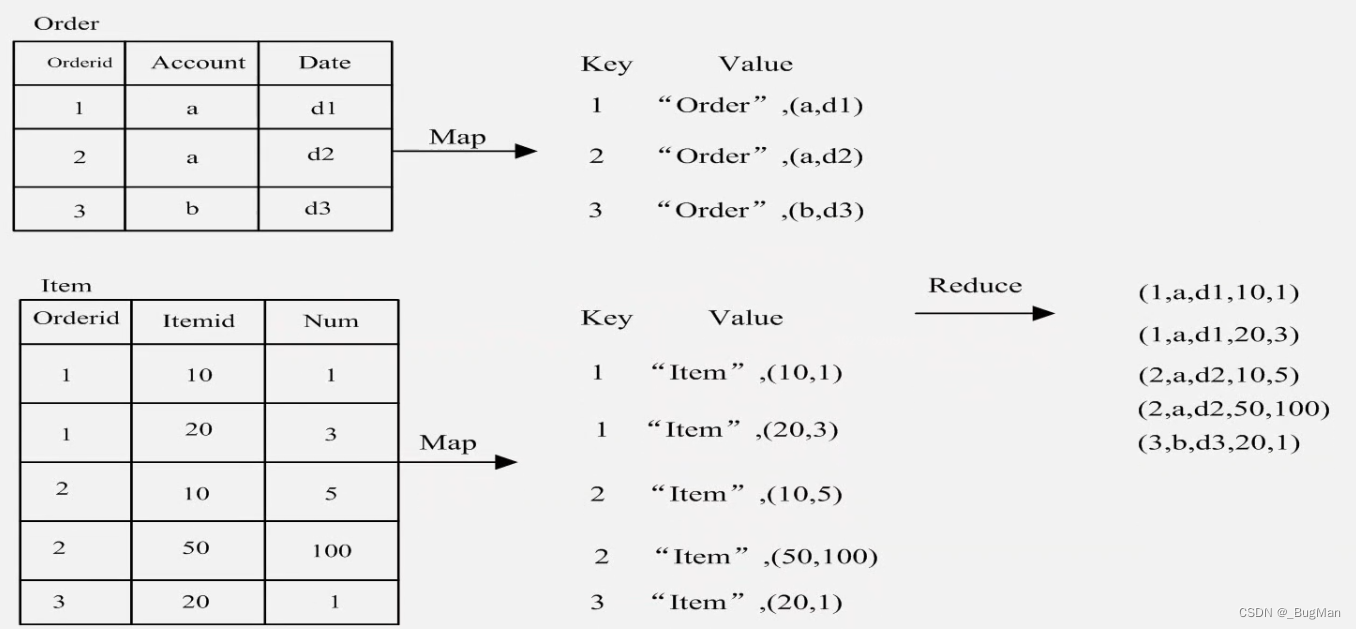
ok,我们知道了MapReduce能将数据关联在一起,那么MapReduce能做的事情可就太多了。回想一下类比我们在用关系型数据库时,想对数据进行统计分析,是不是其实就是将数据连接聚合在一起。所以我们说MapReduce可以完成一切对于数据的关系运算,也就是完成一切对于数据的计算任务。
下面举几个具体在行业内落地的应用场景:
1.搜索引擎的网页索引:
网页爬虫抓取大量网页内容。
Map阶段:解析每个网页,提取关键词,生成键值对(关键词, 网页URL)。
Reduce阶段:对关键词进行聚合,生成倒排索引,即每个关键词对应一组包含该关键词的网页列表。
2.用户行为分析:
收集用户在网站上的浏览、点击、购买等行为数据。
Map阶段:将每个事件转化为键值对(用户ID, 行为详情)。
Reduce阶段:按用户ID聚合,统计用户的总访问次数、购买行为、最常访问的页面等。
3.广告效果评估:
分析广告展示、点击和转化数据。
Map阶段:处理广告日志,产生(广告ID, 展示次数/点击次数/转化次数)键值对。
Reduce阶段:计算每个广告的CTR(点击率)和ROI(投资回报率)。
4.社交网络分析:
计算用户之间的关系,如好友数、影响力等。
Map阶段:遍历用户关系数据,输出(用户A, 用户B)键值对表示A关注B。
Reduce阶段:对每个用户进行聚合,计算其关注者和被关注者的数量。
5.新闻热点检测:
分析新闻标题和内容,找出热门话题。
Map阶段:将每条新闻转化为(关键词, 新闻ID)键值对。
Reduce阶段:对关键词进行聚合,统计出现频率,找出出现最多的关键词。
6.图像处理:
大规模图像分类或标签生成。
Map阶段:对每张图片进行预处理,生成特征向量和对应的图像ID。
Reduce阶段:使用机器学习模型对特征向量进行分类或聚类。
7.金融领域:
信用评分模型的训练。
Map阶段:处理个人信用记录,形成(用户ID, 信用特征)键值对。
Reduce阶段:用这些特征训练模型,预测用户违约概率。
8.基因组学研究:
对大规模基因序列进行比对和变异检测。
Map阶段:将基因序列片段与参考基因组进行比对,输出匹配位置。
Reduce阶段:整合比对结果,确定变异位点。
相关文章:
【大数据】MapReduce JAVA API编程实践及适用场景介绍
目录 1.前言 2.mapreduce编程示例 3.MapReduce适用场景 1.前言 本文是作者大数据系列专栏的其中一篇,前文我们依次聊了大数据的概论、分布式文件系统、分布式数据库、以及计算引擎mapreduce核心概念以及工作原理。 书接上文,本文将会继续聊一下mapr…...
)
图像分类和文本分类(传统机器学习和深度学习)
1. 传统机器学习—决策树 1.1 图像分类代码 from sklearn import tree from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split# 加载数据集 iris load_iris() X, y iris.data, iris.target# 划分数据集 X_train, X_test, y_train,…...
基于SpringBoot和Hutool工具包实现的验证码案例
目录 验证码案例 1. 需求 2. 准备工作 3. 约定前后端交互接口 需求分析 接口定义 4. Hutool 工具介绍 5. 实现验证码 后端代码 前端代码 6. 运行测试 验证码案例 随着安全性的要求越来越高,目前项目中很多都会使用验证码,只要涉及到登录&…...

python-找出四位数中的玫瑰花数
【问题描述】玫瑰花数指一个n位数(n>4),其每位上的数字的n次幂之和等于本身。 请求出所有四位数中的玫瑰花数 【输入形式】 【输出形式】 【样例输入】 【样例输出】1634 8208 9474 【样例说明】 【评分标准】 完整代码如下: for n in ra…...

Linux-命令上
at是一次性的任务,crond是循环的定时任务 如果 cron.allow 文件存在,只有在文件中出现其登录名称的用户可以使用 crontab 命令。root 用户的登录名必须出现在 cron.allow 文件中,如果这个文件存在的话。系统管理员可以明确的停止一个用户&am…...
青鸟云报修系统:实现高效、便捷的维修申请处理
在日常生活和工作中,故障报修难免会遇到,售后报修服务则成为了解决问题的关键。纸质化售后报修维修申请单,作为报修流程中的重要一环,在一定程度上能够记录和追踪售后报修维修流程,但在实际操作过程中却存在着诸多弊端…...

Python解析网页
目录 1、Beautiful Soup 2、解析数据 3、遍历文档树 4、搜索文档树 一、Beautiful Soup 1、什么是Beautiful Soup 定义:Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库. 功能:它能够通过你喜欢的转换器实现惯用的文档导航,查找,修…...

IDEA连接MySQL后如何管理数据库
上一节讲解了IDEA如何连接MySQL数据库管理系统,接下来我们就可以在IDEA里使用MySQL来管理数据库了。那么如果我们现在还没有创建需要的数据库怎么办?本节就来教大家如何在IDEA连接MySQL后管理数据库(创建/修改/删除数据库、创建/修改/删除表、插入/更新/…...

linux新机快速配置ssh
配置SSH以实现证书登录 要配置新的Linux机器以实现证书登录,您需要执行以下步骤: 安装SSH服务器: sudo apt-get install openssh-server修改SSH端口(可选): SSH配置文件(通常位于/etc/ssh/sshd…...
使用elementUI的form表单校验时,错误提示位置异常解决方法
问题 最近在做项目时遇到一个问题,使用elementUI的Descriptions 描述列表与form表单校验时,遇到校验信息显示的位置不对,效果如图: 期望显示在表格中。 效果 代码 html <el-form :model"form":rules"rules…...

Android面试题之Kotlin常见集合操作技巧
本文首发于公众号“AntDream”,欢迎微信搜索“AntDream”或扫描文章底部二维码关注,和我一起每天进步一点点 list 创建和修改 不可变list,listOf var list listOf("a","d","f") println(list.getOrElse(3){"Unkn…...
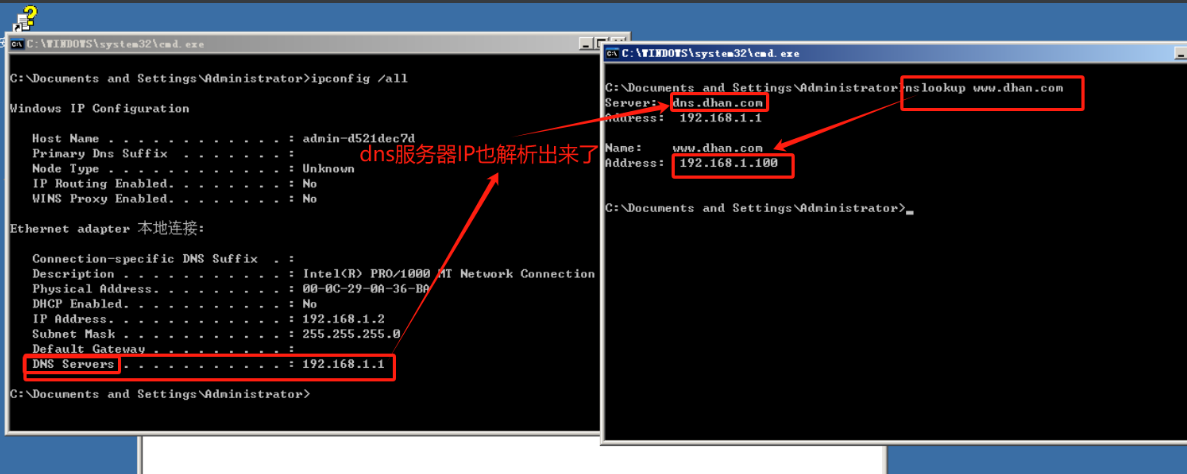
网络拓扑—DNS服务搭建
文章目录 DNS服务搭建网络拓扑配置网络DNSPC 安装DNS服务配置DNS服务创建正向查找区域创建反向查找区域创建子域名 PC机DNS域名解析 DNS服务搭建 网络拓扑 为了节省我的U盘空间,没有用路由器,所以搭建的环境只要在同网段即可。 //交换机不用考虑 DNS&a…...

Mybatis-Plus笔记
1.MP基础 1.1 MP常见注解 TableName(“指定表明”) TableName("tb_user") // 指定表名 Data NoArgsConstructor AllArgsConstructor Builder public class User {private Long id;private String userName;private String password;private String name;private I…...
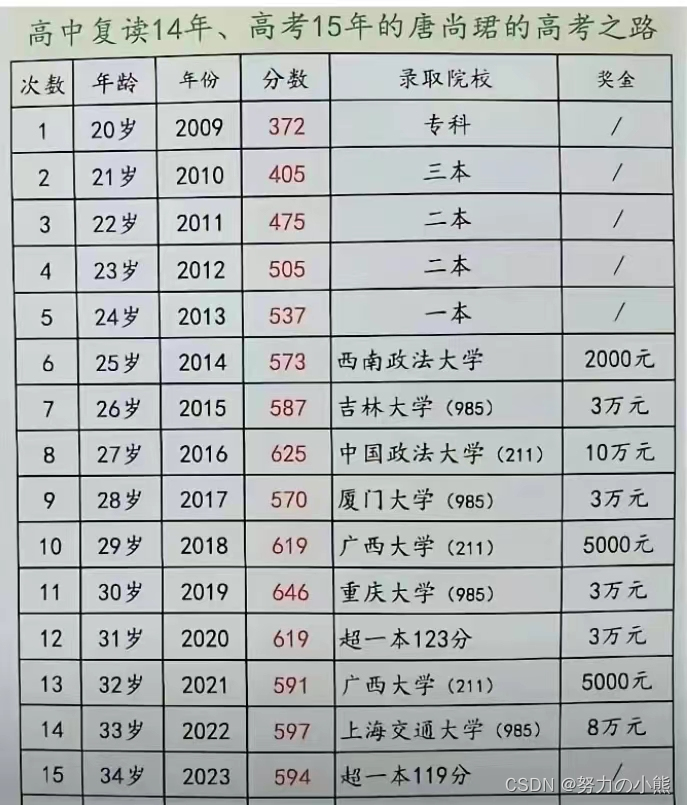
“高考钉子户”唐尚珺决定再战2024年高考
“高考钉子户”唐尚珺决定在2024年再次参加高考,这个选择确实很特别也很有趣。十几年连续参加高考,他已经积累了大量的备考经验和应试技巧。这样的经验对于高考辅导机构来说无疑是非常宝贵的资源,他如果选择去辅导机构当老师,应该…...

Hive安装教程
前置条件:hadoop&mysql docker容器安装mysql-CSDN博客 以下的/opt/bigdata目录根据自己实际情况更改 1.上传hive包并解压 tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /opt/bigdata/ 2.修改路径 mv /opt/bigdata/apache-hive-3.1.3-bin/ hive cd /opt/bigdata/hive/…...
使用Python Tkinter创建GUI应用程序
大家好,当我们谈及使用Python Tkinter创建GUI应用程序时,我们涉及的不仅是技术和代码,更是关于创造力和用户体验的故事。Tkinter作为Python标准库中最常用的GUI工具包,提供了丰富的功能和灵活的接口,让开发者能够轻松地…...

使用 RT 矩阵进行 3D 点云变换详解(基于 PCL 和 Eigen 库)
在 3D 点云处理中,RT 矩阵是一个常用的工具,用于对点云进行旋转和平移操作。本文将详细介绍 RT 矩阵的概念,并通过一个示例程序演示如何基于 PCL 和 Eigen 库将一帧点云进行矩阵变换再输出。 本教程的示例代码和点云数据可在 GitHub 下载。 什…...

CTFHUB技能树——SSRF(二)
目录 上传文件 FastCGI协议 Redis协议 上传文件 题目描述:这次需要上传一个文件到flag.php了.祝你好运 index.php与上题一样,使用POST请求的方法向flag.php传递参数 //flag.php页面源码 <?phperror_reporting(0);if($_SERVER["REMOTE_ADDR&…...

Vue3实现简单的瀑布流效果,可抽离成组件直接使用
先来看下效果图: 瀑布流中的内容可进行自定义,这里的示例图是通过不同背景颜色的展示进行区分,每个瀑布流中添加了自定义图片和文字描述。 实现方式: 1.建立子组件(可单独抽离)写出瀑布流的样式 文件名为…...

【已解决】C#如何消除Halcon上一次显示窗口的涂层
前言 在通过C#进行封装Halcon的时候发现一个问题,就是如果我重新去标定一个图像的时候不能把上一次的清掉,然后之前的会覆盖掉原来的,这个确实是这样,但是如果说现在的图像面积比之前的小的那么就没有任何效果显示,因…...

如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了
如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了 【免费下载链接】deberta-v3-base-zeroshot-v2.0 项目地址: https://ai.gitcode.com/hf_mirrors/NingBo_Ascend/deberta-v3-base-zeroshot-v2.0 deberta-v3-base-zeroshot-v2.0是一款基…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

ARMv8 HFGITR_EL2寄存器解析与虚拟化指令陷阱控制
1. AArch64 HFGITR_EL2寄存器架构解析HFGITR_EL2(Hypervisor Fine-Grained Instruction Trap Register)是ARMv8架构中专门用于指令级陷阱控制的系统寄存器,属于虚拟化扩展的重要组成部分。这个64位寄存器通过位映射机制实现对特定AArch64指令…...

【DeepSeek开源协议识别权威指南】:20年合规专家亲授3大协议陷阱与5步精准识别法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开源协议识别的底层逻辑与合规价值 DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)虽以“开源”名义发布,但其实际许可状态需通过结构化协议解析才能准确…...

METSO A413248自动化系统
METSO A413248 自动化系统模块产品特点: 品牌归属:芬兰METSO(美卓)工业自动化系统原装备件。 产品类型:工业级自动化控制模块/接口模块。 核心功能:用于控制信号处理、数据采集及系统集成。 系统兼容&am…...

第三卷第4章:原型模式设计思想
第三卷第4章:原型模式设计思想 目录介绍 01.案例引入与思考 1.1 痛点场景 1.2 它哪里不舒服 1.3 引出本篇主角 02.原型模式介绍 2.1 原型模式由来 2.2 原型模式定义...

Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南
Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南 【免费下载链接】Graphin 🌌 A React toolkit for graph visualization based on G6. 项目地址: https://gitcode.com/gh_mirrors/gr/Graphin 在当今数据驱动的时代,图可视化…...

从《吃豆人》到开放世界:聊聊Unity Navigation里Agent Radius和Cost的那些‘潜规则’
从《吃豆人》到开放世界:Unity Navigation中Agent Radius与Cost的隐藏逻辑1980年诞生的《吃豆人》用简单的迷宫路径定义了早期游戏AI的移动规则——幽灵们沿着固定路线巡逻,遇到转角时随机选择方向。这种设计在当时堪称革命性,但以今天的标准…...

Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验
Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为在Windows电脑上无法直接安装安卓应用而烦…...

还在手动触发Lindy子任务?这6个隐藏API+3个低代码集成技巧,今天就能上线全自动流水线
更多请点击: https://kaifayun.com 第一章:Lindy多步骤任务自动化的价值与演进路径 Lindy效应指出,一项技术的预期剩余寿命与其当前已存在时间正相关;在自动化领域,Lindy原则催生了对“经久验证、语义稳定、可组合性强…...