深入理解数仓开发(一)数据技术篇之日志采集
前言
今天开始重新回顾电商数仓项目,结合《阿里巴巴大数据之路》和尚硅谷的《剑指大数据——企业级电商数据仓库项目实战 精华版》来进行第二次深入理解学习。之前第一次学习数仓,虽然尽量放慢速度力求深入理解,但是不可能一遍掌握,尤其是关于数仓建模,那需要实打实的经验!
好在最近发现了这两本好书,但是发现纸质版虽然很好,但是标注那么多零碎的知识点复习起来还是不够直观,所以这里用博客的形式把我第二遍学习中学到的东西记录下来(只针对我的问题)对于一些理论比如基础的工具使用,一些专业术语不多废话,最多一句带过。
两本书对整个数仓的开发步骤基本是一致的,所以学习的时候会结合着一起学,互相弥补各自的不足(《阿里巴巴大数据之路》理论非常丰富,《剑指大数据—企业级电商数仓实战》更加贴近实战)。
文章的结构我会按照《阿里巴巴大数据之路》来分层,每个章节总结到博客应该又是一篇万字长文。
1、📄日志采集
电商项目的日志采集主要分为两部分:浏览器(Web 端)和无线客户端(APP、小程序),阿里巴巴对于这两部分日志的采集方案分别为 Aplus.js(浏览器)和 UserTrack (APP)。
1.1、🌍浏览器的页面日志采集
浏览器页面的日志采集可以分为两类:
- 页面浏览日志
也就是一个网页被加载的次数,因为只有网页被加载成功时才会被记录为日志。页面浏览日志有两大基本指标:PV(页面浏览量)和 UV(用户访客数)。
- 页面交互日志
即捕获用户的行为操作,通过采集用户的行为数据,以便量化获知用户的兴趣点和体验优化点。
1.1.1、🌍浏览器的浏览日志采集流程
- 1️⃣用户在浏览器地址栏输入一个请求地址
- 2️⃣浏览器发送一个 http 请求
- 一个标准的 http 请求分为 3 部分:
- 请求行(请求方法、URL、http协议版本)
- 请求头(附加信息,比如 Cookie)
- 请求体(可选,一般为空)
- 一个标准的 http 请求分为 3 部分:
- 3️⃣服务器接收并响应请求
- 一个标标准的 http 相应也分为 3 部分:
- 状态行(状态码,比如 200)
- 响应头(附加信息,比如 Cookie)
- 响应体(非空,比如 json、html、image、text、mp4等)
- 一个标标准的 http 相应也分为 3 部分:
- 4️⃣浏览器接受响应内容并渲染
日志采集的动作发生在上面的第 4 步,也就是在浏览器解析响应的页面的时候。所以实现日志采集的思路就是:在 HTML 文档合适的位置插入一个日志采集节点(比如一段 js 脚本),当浏览器解析到这个节点的时候,将自动触发发送一个特定的 http 请求到日志采集服务器。
具体采集日志的过程如下:
- 1️⃣客户端日志采集
- 由植入到 HTML 文档中的一段 JS 脚本来执行,在执行时采集当前页面参数,浏览器行为的上下文信息(比如该页面的上一页)以及一些运行换信息(比如当前浏览器的版本、屏幕大小、操作系统信息)
- 具体的采集脚本可以是提前写入到 HTML 中,也可以是在返回响应时动态植入。
- 2️⃣客户端日志发送
- 采集脚本执行时,会向日志服务器发送起一个 http 请求,将采集到的日志发送到日志服务器。
- 采集到的日志信息一般以 URL 参数的形式放在 HTTP 请求行中。
- 3️⃣服务器端日志收集
- 日志服务器接收到客户端发来的日志请求后,一般会立即返回一个请求成功的响应,防止客户端页面长时间等待。
- 同时,日志服务器会把该日志的内容写入一个缓冲区内,完成对这条日志的收集。
- 4️⃣服务器端日志解析存档
- 日志缓冲区中的日志会被顺序读出并解析,解析出的数据会被转存到标准的日志文件,而且如果有实时分析需求的话会被注入到实时消息通道供其它后端程序读取并加工。
经过格式化的日志,为后面日志的加工和计算得以顺利进行打下了基础。
1.1.2、🌍页面的交互日志采集
PV 日志解决了页面流量和流量来源统计的问题,但是随着业务的发展,仅了解用户访问的页面和路径,已经远远不能满足用户细分研究的需求。很多场景下更需要了解用户访问某个页面时的互动行为数据(比如鼠标焦点的变化)。所以这些行为无法通过常规的 PV 日志采集方法解决。
交互日志采集和浏览日志采集完全不同,交互日志千变万化,呈现出高度自定义的业务特征,但是阿里巴巴有自己的一套专门用来采集交互日志的技术方案(也叫“黄金令箭”)。这里丢这个技术不多介绍,毕竟书里也没有过多透露关于这个技术的细节,大概流程就是:
- 1️⃣业务方(比如程序员)通过这套系统(“黄金令箭”)将具体的业务场景下的交互采集点注册到系统当中,系统会自动生成与之对应的交互日志采集模板。
- 2️⃣业务方将采集模板植入到目标页面,并将采集代码与需要监测的交互行为进行绑定。
- 3️⃣当用户在页面交互触发制定行为时,采集代码会被触发执行并通过 HTTP 请求发送到日志服务器。
- 4️⃣日志服务器接收到日志后将数据进行转存。
之后,业务方就可以对这部分行为数据根据业务需求进行解析处理,并可以与浏览数据进关联运算。
1.1.3、🌍页面日志的服务器端清洗和预处理
经过上面采集处理后的数据一般并不会直接提供给下游使用,基于下面的 4 个原因,在时效性宽松的情况下还需要对数据进行一些离线预处理。
- 1️⃣识别流量攻击,网络爬虫和流量作弊
- 2️⃣数据项补正
- 对日志中一些公共并且重要的字段取值归一(将数据特征缩放到一个特定的范围当中,比如 [ 0,1 ] ,以消除不同量纲和量纲单位对数据分析结果的影响)、标准化处理或反向补正(根据新日志对旧日志中的个别数据项做回补,比如用户登录后,对用户登录之前的页面做身份信息的回补)。
- 3️⃣无效数据剔除
- 采集到的数据难免会存在一些无意义的数据(比如因为业务变更、采集配置不当或者冗余的数据),会消耗存储和算力。所以需要定时检查采集配置并按照配置对无效数据进行剔除。
- 4️⃣ 日志隔离分发
- 考虑到数据安全,一般会对一些日志进入到公共环境之前做隔离。
至此,页面日志(浏览日志和行为日志)的采集流程就算完成了,此时的日志已经具备了结构化或半结构的特征,可以被关系型数据库装载和使用了(Hive 当然也可以)。
1.2、📲客户端的日志采集
移动端的数据采集一方面是为了服务于开发者,帮助他们进行一些数据分析(设备信息、用户行为信息);另一方面是为了对 APP 进行不断的优化,提升用户体验。
浏览器的网页日志是使用 JS 脚本来采集的,而这里的移动客户端的日志采集使用采集SDK 来完成。移动端的日志采集根据不同的用户行为分为不同的事件,常用的包括页面事件(页面浏览)和控件点击事件(页面交互)等。
阿里巴巴对于移动端的日志采集使用的是 UserTrack (简称 UT)。
1.2.1、📲页面事件
每条页面事件日志记录三类信息:
- 设备和用户基本信息
- 被访问页面的信息(比如商品id、所属店铺)
- 访问的基本路径(页面来源、来源的来源)
对于页面事件,有的采集 SDK 选择在页面创建时就发送日志。而阿里巴巴的 UT ,它提供了两个接口,分别在页面展现和页面退出时调用。当进入该店铺详情页时,调用页面展现的接口,该接口会记录一些页面进入时的状态信息,但是不发送日志。当从该店铺详情页离开时(比如退出手机淘宝,或者返回上一页),这是才会调用页面退出接口,该接口会发送日志。
除了页面展现和退出这两个基础接口外,UT 还提供了页面扩展信息的接口,在页面离开前,该接口会给页面添加一些扩展信息,比如店铺ID、店铺类别(天猫/淘宝)等。
上面的三个接口必须配合使用,其中页面展现和退出必须成对使用,而页面扩展接口必须在这两个接口使用的前提下使用。
日志发送的时机:
对于网页浏览日志,基本都是页面加载之后,当浏览器解析到相关的日志发送JS脚本就会自动执行发送。而对于移动端日志发送,则是在页面离开后发送,因为移动端可以对页面停留时长进行一个准确的计算。
用户行为路径还原:
在很多场景下需要采集更多的信息来减少计算分析的成本,UT 针对这种情况提功力透传参数的功能。所谓透传参数就是把当前页面的某些信息传递到下一个或者下下一个页面的日志中。比如我搜索 "手机" 之后给我推荐了很多商品,我点进去一个商品之后,我的搜索词也应该被记录到该商品日志当中去。
1.2.2、📲控件点击和其它事件
和网页交互日志一样,交互类行为呈现出高度自定义的业务特征。对于控件点击事件,它首先也会记录基本的设备和用户信息,此外,它还会记录页面名称、控件名称、控件的业务参数等。
除此之外,UT 还提供了一些默认的日志采集方法,比如自动捕获应用崩溃,应用的退出、页面的前后台切换等。
1.2.3、📲特殊场景
日志聚合:
上面所有的场景(页面事件和交互事件)都是一个行为产生一条日志,比如一次浏览、一次点击。对于用户量很大的公司,为了平衡日志的大小,减少流量消耗、日志服务器的压力、网络传输压力等,采集 SDK 提供了聚合功能。对于一下曝光或者性能技术类的日志,可以选择对这类日志进行一个聚合,以减少对日志采集服务器的请求量,适当减小日志的大小。比如对于曝光日志,手机一次滚动屏幕可能会触发几十个商品的曝光,我们总不可能让它生成几十个曝光日志,所以采集 SDK 提供了本地聚合的功能,在客户端对这类日志进行聚合,然后再去发送到日志采集服务器。
1.2.4、📲设备标识
这里简单介绍,设备标识用来标识用户的唯一性。对于 UV 指标,可以通过用户 ID 来进行唯一标识,但是很多网页或软件并不要求用户必须登录,所以就难以标识日志的来源。对于这种情况 PC 端可以通过 Cookie 来解决,但是移动端就难以解决了。
对于单APP的公司,设备标识并不是非要攻克的难题,但是对于阿里巴巴有大量APP的大公司,唯一标识就必须解决。阿里巴巴使用的是 UTDID ,它是通过特定的算法来生成的,大部分情况下可以唯一标识一个设备。
1.2.5、📲日志传输
移动端的日志传输一般先存储在客户端本地,然后伺机上传(启动后、使用过程中 、切换后台时)。触发上传日志的时机并不是单纯依靠间隔时间,还要结合日志的大小以及上传时网络的耗时不断调整上传机制。
移动端上传日志是向日志服务器发送 POST 请求,当天的日志会被存储到当天的日志文件中。
之后当这些日志需要被下游使用时,一般会把日志放到消息队列(比如 Kafka ,阿里巴巴用的是 TimeTunel)供下游消费者(比如 Hadoop 等,阿里巴巴用的是 MaxCompute)消费。
总结
日志采集这一部分主要是《阿里巴巴大数据之路》中专门拎出来讲,学完之后确实对数据采集的过程有了更深刻的印象和理解。
相关文章:
数据技术篇之日志采集)
深入理解数仓开发(一)数据技术篇之日志采集
前言 今天开始重新回顾电商数仓项目,结合《阿里巴巴大数据之路》和尚硅谷的《剑指大数据——企业级电商数据仓库项目实战 精华版》来进行第二次深入理解学习。之前第一次学习数仓,虽然尽量放慢速度力求深入理解,但是不可能一遍掌握࿰…...

Edge浏览器:重新定义现代网页浏览
引言 - Edge的起源与重生 Edge浏览器,作为Microsoft Windows标志性的互联网窗口,源起于1995年的Internet Explorer。在网络发展的浪潮中,IE曾是无可争议的霸主,但随着技术革新与用户需求的演变,它面临的竞争日益激烈。…...

HDFS,HBase,MySQL,Elasticsearch ,MongoDB分别适合存储什么特征的数据?
HDFS(Hadoop Distributed File System)通常用于存储大规模数据,适合存储结构化和非结构化数据,例如文本文件、日志数据、图像和视频等。 HBase是基于Hadoop的分布式数据库,适合存储大量非结构化和半结构化的数据&…...

ArcGIS中离线发布路径分析服务,并实现小车根据路径进行运动
ArcGIS中离线发布路径分析服务,您可以按照以下步骤操作: 准备ArcMap项目: 打开ArcMap并加载包含网络分析图层的项目。在ArcMap中,使用 Network Analyst Toolbar 或 Catalog 创建网络数据集(Network Dataset)…...

时政|医疗结果互认
背景(存在的问题) 看同一种病,换一家医院甚至换一个院区、换一个科室,检查检验还得再来一遍,费钱又费时。开展检查检验结果互认,可以明显减轻患者就医负担。患者不用做重复检查,也可节约就医时…...
华为OD机试【找出通过车辆最多颜色】(java)(100分)
1、题目描述 在一个狭小的路口,每秒只能通过一辆车,假设车辆的颜色只有 3 种,找出 N 秒内经过的最多颜色的车辆数量。 三种颜色编号为0 ,1 ,2。 2、输入描述 第一行输入的是通过的车辆颜色信息[0,1,1,2] ࿰…...

hyperf 多对多关联模型
这里使用到三张表,一张是用户(users),一张是角色(roles),一张是用户角色关联表(users_roles), 首先创建用户模型、角色模型 php bin/hyperf.php gen:model users php bin/hyperf.php gen:model rolesusers…...
)
每日力扣刷题day03(从零开始版)
文章目录 2024.5.24(5题)2828.判别首字母缩略词题解一题解二 1365.有多少小于当前数字的数字题解一题解二题解三 2469.温度转换题解一题解二 1502.判断能否形成等差数列题解一题解二 2351.第一个出现两次的字母题解一题解二 2024.5.24(5题&am…...

误差反向传播简介与实现
误差反向传播 导语计算图反向传播链式法则 反向传播结构加法节点乘法节点 实现简单层加法乘法 激活函数层实现ReLUSigmoid Affine/Softmax层实现Affine基础版批版本 Softmax-with-Loss 误差反向传播实现梯度确认总结参考文献 导语 书上在前一章介绍了随机梯度下降法进行参数与…...
ATmega328P加硬件看门狗MAX824L看门狗
void Reversewdt(){ //硬件喂狗,11PIN接MAX824L芯片WDIif (digitalRead(11) HIGH) {digitalWrite(11, LOW); //低电平} else {digitalWrite(11, HIGH); //高电平 }loop增加喂狗调用 void loop() { …… Reversewdt();//喂狗 }...

【Redis】 String类型的内部编码与使用环境
文章目录 🍃前言🌴内部编码🎄典型使用场景🚩缓存功能🚩计数(Counter)功能🚩共享会话(Session)🚩验证码功能 ⭕总结 🍃前言 本篇文章重…...

HarmonyOS interface router scale pageTransition SlideEffect.Left ArkTS ArkUI
🎬️create Component export default struct TitleBar {build(){Row(){Text(transition).fontSize(30fp).fontColor(Color.White)}.width(100%).height(8%).backgroundColor(#4169E1).padding({left:10})}}🎞️interface export interface IList{ti…...
Go语言(Golang)的开发框架
在Go语言(Golang)的开发中,有多种开发框架可供选择,它们各自具有不同的特点和优势。以下是一些流行的Go语言开发框架,选择Go语言的开发框架时,需要考虑项目需求、团队熟悉度、社区支持、框架性能和可维护性…...
)
Python入门第三课——Python 数据类型(详细)
文章回顾 Python入门第一课——Python起步安装、Sublime Text安装教程,环境配置Python入门第二课——Python的变量和简单数据类型 目录 文章回顾前言一、Python的详细数据类型二、各种数据类型和使用方法1.Number(数字)2、String(…...

html入门
<!DOCTYPE html><!--每个文件都要加上这个,是html文件的主题--> <html><!--查不多就是c预言的main函数,从头括到尾部--><head><meta http-equiv"Content-Type" content"text/html;charsetutf-8" /…...

蓝桥杯杨辉三角
PREV-282 杨辉三角形【第十二届】【蓝桥杯省赛】【B组】 (二分查找 递推): 解析: 1.杨辉三角具有对称性: 2.杨辉三角具有一定规律 通过观察发现,第一次出现的地方一定在左部靠右的位置,所以从…...

【活动】开源与闭源大模型:探索未来趋势的双轨道路
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 开源与闭源大模型:探索未来趋势的双轨道路引言一、开源大模型&#…...
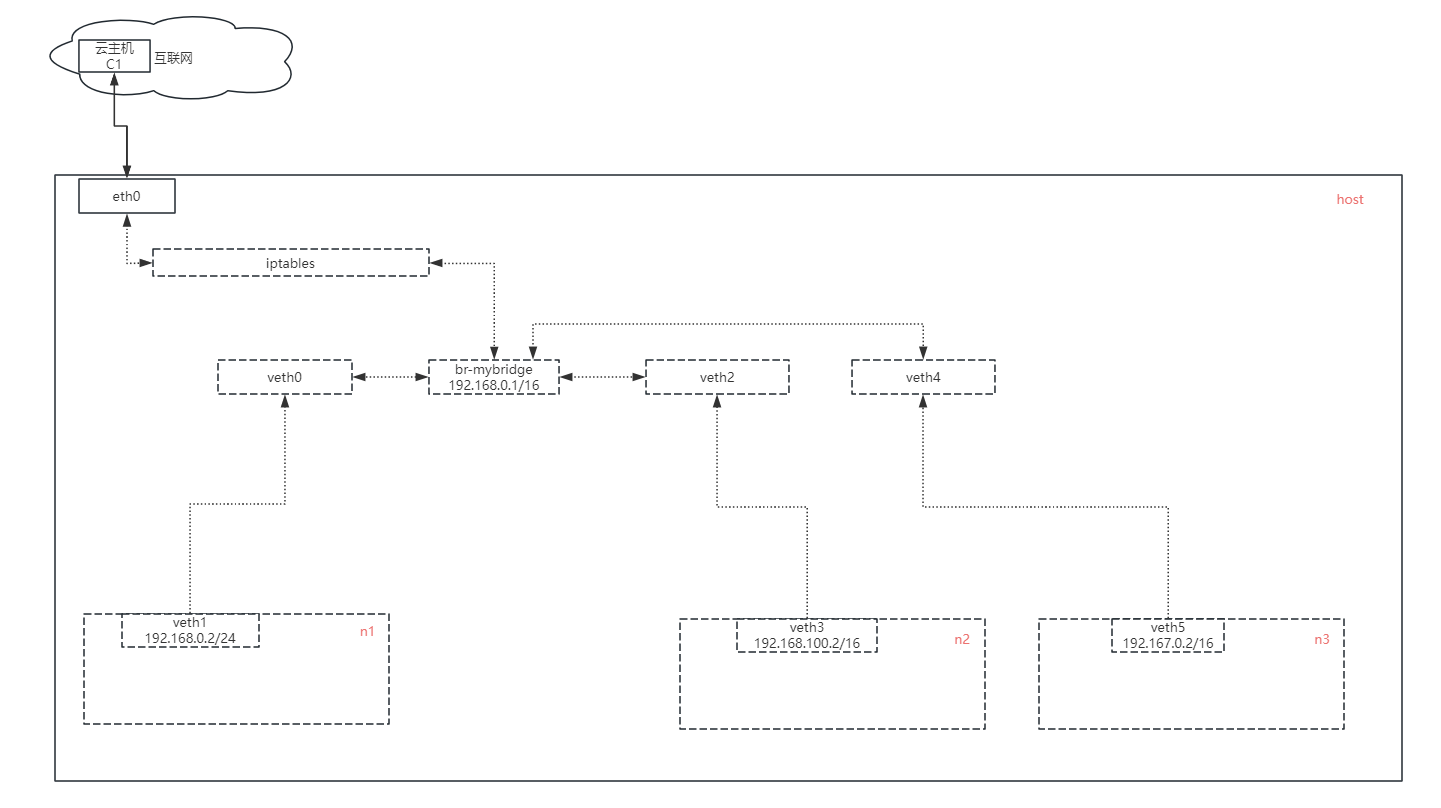
虚拟局域网(VLAN)
关键词:veth、vlan、bridge、iptables、nat、tcpdump、icmp、cidr、arp、路由表、计算机网络协议栈 前言 在过去的几十年里,互联网发展得非常快。许多新兴技术迅速崛起,也有不少曾经的主流技术被淘汰。然而,有些技术因为其基础性…...

内网穿透--Frp-简易型(速成)-上线
免责声明:本文仅做技术交流与学习... 目录 frp项目介绍: 一图通解: 编辑 1-下载frp 2-服务端(server)开启frp口 3-kali客户端(client)连接frp服务器 4-kali生成马子 5-kali监听 6-马子执行-->成功上线 frp项目介绍: GitHub - fatedier/frp: A fast reverse proxy…...

Python库之Scrapy的简介、安装、使用方法详细攻略
Python库之Scrapy的简介、安装、使用方法详细攻略 简介 Scrapy是一个快速的、高层次的web抓取和web抓取框架,用于抓取网站数据并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、信息处理或存储历史数据,以及各种其他用途。 …...
 —— STM32的SPI外设)
STM32单片机学习(28) —— STM32的SPI外设
文章目录概述SPI通信的移位机制(以bit为单位)SPI外设框图第一部分:数据通路SPI通信的数据帧格式SPI外设移位机制(以字节为单位)第二部分:主机时钟生成器SPI通信时钟频率与传输速率第三部分:主从…...
)
告别网盘客户端!用Alist+RaiDrive把百度云盘变成电脑本地文件夹(保姆级图文教程)
用AlistRaiDrive实现网盘本地化管理的终极方案 你是否厌倦了电脑上安装多个网盘客户端,不仅占用系统资源,操作还繁琐割裂?每次上传下载文件都要在不同客户端间切换,效率低下。现在,通过Alist和RaiDrive的组合…...
)
手把手教你为WCH CH582移植CherryUSB主机栈(基于RT-Thread,含中断优化)
基于RT-Thread的WCH CH582 USB主机协议栈深度移植指南在嵌入式开发领域,USB主机功能的实现往往意味着设备能够直接连接各类USB外设,从简单的键盘鼠标到复杂的存储设备。对于使用WCH CH582这类RISC-V内核MCU的开发者而言,原厂SDK提供的USB主机…...

别再死记硬背Payload了!我用XSS-Game靶场,带你拆解18种过滤规则背后的绕过逻辑
从XSS-Game靶场实战中掌握18种过滤规则的逆向思维在网络安全领域,跨站脚本攻击(XSS)始终是Web应用面临的主要威胁之一。许多开发者虽然了解XSS的基本概念,但当面对各种复杂的过滤规则时,往往不知如何系统分析并构造有效…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

孤舟笔记 互联网常用框架篇三 Dubbo是如何动态感知服务下线的?注册中心和服务端双保险
文章目录先说结论机制一:注册中心通知机制二:心跳检测机制三:连接事件感知机制四:定时拉取四种机制的协作回答技巧与点评加分回答面试官点评个人网站微服务环境下,服务实例随时可能上下线——重启、扩容、宕机……调用…...

TorchDynamo与TorchInductor:PyTorch编译器生态的完整解析
TorchDynamo与TorchInductor:PyTorch编译器生态的完整解析 【免费下载链接】torchdynamo A Python-level JIT compiler designed to make unmodified PyTorch programs faster. 项目地址: https://gitcode.com/gh_mirrors/to/torchdynamo TorchDynamo 是一个…...

企业云盘签章技术方案:从数字签名原理到工程落地
背景 电子签章在企业云盘中的落地,不只是一个"上传盖章图片"的功能实现。本质上,它是一套涉及数字签名、PKI基础设施、文档完整性校验的综合性技术方案。本文从技术选型角度,说清楚企业云盘内置签章需要解决哪些问题、主流实现方案…...
)
紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本+修复模板)
更多请点击: https://intelliparadigm.com 第一章:紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本修复模板) 近期在多轮生产级代码审计中发现,DeepSeek-R1(v2.5&#x…...

【DeepSeek漏洞扫描辅助实战指南】:20年安全专家亲授3大避坑法则与5步提效流程
更多请点击: https://intelliparadigm.com 第一章:DeepSeek漏洞扫描辅助的核心价值与适用边界 DeepSeek漏洞扫描辅助并非通用型渗透测试引擎,而是一个聚焦于大语言模型(LLM)应用层安全的轻量级分析工具。其核心价值在…...