YOLOv10详细解读 | 一文带你深入了解yolov10的创新点(附网络结构图 + 举例说明)
前言
Hello大家好,我是Snu77,继YOLOv9发布时间没有多久,YOLOv10就紧接着发布于2024.5.23号(不得不感叹YOLO系列的发展速度,但要纠正大家的观点就是不是最新的就一定最好)!
本文给大家带来的是YOLOv10的论文详细解读->论文名称为:YOLOv10: Real-Time End-to-End Object Detection(大家看着眼熟么,是不是和RT-DETR的《DETRs Beat YOLOs on Real-time Object Detection》比较像,从这个论文题目可以看到目前的创新方向都是往端到端和实时的方向去搞,在精度上的创新已经不是很大了!)
本文内含YOLOv10网络结构图 + 各个创新模块手撕结构图 + 举例讲解,相信阅读完本文一定能够让你有所收获~

论文地址:官方论文地址点击此处即可跳转
代码地址:官方代码地址点击此处即可跳转


摘要
过去几年中,由于YOLO在计算成本和检测性能之间的有效平衡,它已经成为实时目标检测领域的主要范式。研究人员探索了YOLO的架构设计、优化目标、数据增强策略等方面,取得了显著进展。然而,YOLO依赖于非极大值抑制(NMS)进行后处理,这阻碍了YOLO的端到端部署,并对推理延迟产生了不利影响。此外,YOLO的各种组件设计缺乏全面深入的检查,导致明显的计算冗余,限制了模型的能力。这导致了效率不佳,同时也有很大的性能提升潜力。在这项工作中,我们旨在从后处理和模型架构两方面进一步提升YOLO的性能-效率边界。为此,我们首先提出了一致的双重分配策略,用于YOLO的NMS-free训练,这同时带来了竞争力的性能和低推理延迟。此外,我们引入了整体效率-精度驱动的模型设计策略。我们从效率和精度的角度全面优化了YOLO的各个组件,大大减少了计算开销并增强了能力。我们的努力成果是一个新的YOLO系列,用于实时端到端目标检测,称为YOLOv10。大量实验表明,YOLOv10在各种模型规模上都达到了最先进的性能和效率。例如,在COCO数据集上,YOLOv10-S在相似AP的情况下比RT-DETR-R18快1.8倍,同时参数和FLOPs减少了2.8倍。与YOLOv9-C相比,YOLOv10-B在相同性能下的延迟减少了46%,参数减少了25%。
一、引言
实时目标检测一直是计算机视觉领域的研究重点,旨在以低延迟准确预测图像中物体的类别和位置。它被广泛应用于各种实际应用中,包括自动驾驶、机器人导航和物体跟踪等。近年来,研究人员集中精力设计基于CNN的目标检测器以实现实时检测。其中,YOLO由于其在性能和效率之间的平衡,越来越受欢迎。YOLO的检测流程由两个部分组成:模型前向过程和NMS后处理。然而,这两部分仍存在不足,导致准确性-延迟界限不理想。
段落总结:YOLOv10的主要创新点其实就是对取消后处理NMS,部分读者可能对NMS比较陌生,这里带大家简单学习下
NMS额外介绍
非极大值抑制(Non-Maximum Suppression, NMS)是一种常用的后处理技术,用于目标检测算法中以减少冗余检测框并确保检测结果的精确性。NMS的主要目标是在同一物体上保留一个最佳的检测框,同时抑制那些得分较低的重叠框。下面是NMS的工作原理和应用:
NMS的工作原理
- 检测框排序:首先,将所有检测框按照置信度(即检测得分)从高到低排序。
- 选择最高得分的检测框:选择得分最高的检测框作为当前的最佳检测结果。
- 计算重叠区域:对于剩余的所有检测框,计算它们与当前最佳检测框的重叠度(通常使用交并比,IoU,即Intersection over Union)。
- 抑制重叠框:将那些与当前最佳检测框的重叠度超过某一阈值的检测框抑制(即移除),因为它们很可能是对同一物体的重复检测。
- 重复步骤2-4:在剩余的检测框中,重复上述步骤,直到没有检测框剩余。
NMS的局限性
尽管NMS在实践中非常有效,但它也存在一些局限性,例如:
- 参数敏感性:NMS需要设置重叠度阈值,这个参数的选择对最终结果有很大影响,过高或过低的阈值都会影响检测效果(有的时候我们用Detect的时候进行推理会出现一个物体有多个检测框其实根据参数的设置也有一定的关系)。
- 速度影响:在大规模检测任务中,NMS的计算复杂度可能会影响整体的推理速度(这也是YOLOv10去掉NMS的主要原因,提高推理速度从而实现端到端)。
- 无法处理复杂场景:对于一些复杂场景,如拥挤的人群或密集的目标,NMS可能无法有效区分相邻的多个目标。
具体而言,YOLO在训练期间通常采用一对多的标签分配策略,其中一个真实物体对应多个正样本。尽管这种方法能获得更好的性能,但需要在推理过程中使用NMS选择最佳正预测,这减慢了推理速度,并使性能对NMS的超参数敏感,阻碍了YOLO的端到端部署。为解决这一问题,可以采用最近引入的端到端DETR架构。例如,RT-DETR通过高效的混合编码器和不确定性最小的查询选择(个人理解本质和NMS原理其实是相似的,不对欢迎评论区指正),推动DETR进入实时应用领域。然而,DETR的内在复杂性阻碍了其在准确性和速度之间达到最佳平衡。另一种方法是探索基于CNN的端到端检测,通常采用一对一的分配策略来抑制冗余预测,但通常会引入额外的推理开销或达不到理想的性能。
此外,模型架构设计仍是YOLO的一个基本挑战,对准确性和速度有重要影响。为了实现更高效和有效的模型架构,研究人员探索了不同的设计策略。提出了各种主要计算单元来增强特征提取能力,例如DarkNet、CSPNet、EfficientRep和ELAN等。为了增强多尺度特征融合,还探索了PAN、BiC、GD和RepGFPN等。此外,还研究了模型缩放策略和重新参数化技术。尽管这些努力取得了显著进展,但缺乏对YOLO各个组件的全面检查,导致YOLO内部存在相当大的计算冗余,导致参数利用效率低下和效率不佳。此外,结果模型能力也受到限制,留有很大的精度提升空间(其实YOLOv10目前的反馈大家精度其实都不是很好)。
在这项工作中,我们旨在解决这些问题,并进一步提升YOLO的准确性-速度界限。我们针对整个检测流程中的后处理和模型架构进行了改进。首先,通过引入一致的双重分配策略(这里说的双重分配策略其实就是指调用了两次V8的损失函数计算方法,然后进行了一个求和,具体代码大家可以在YOLOv10的项目文件的如下文件的最末尾看到'ultralytics/utils/loss.py',一下图片是我在代码中的截图并进行了标注大家感兴趣的可以自行找到代码中进行观看,但是具体的改进还是体现在检测头中!)
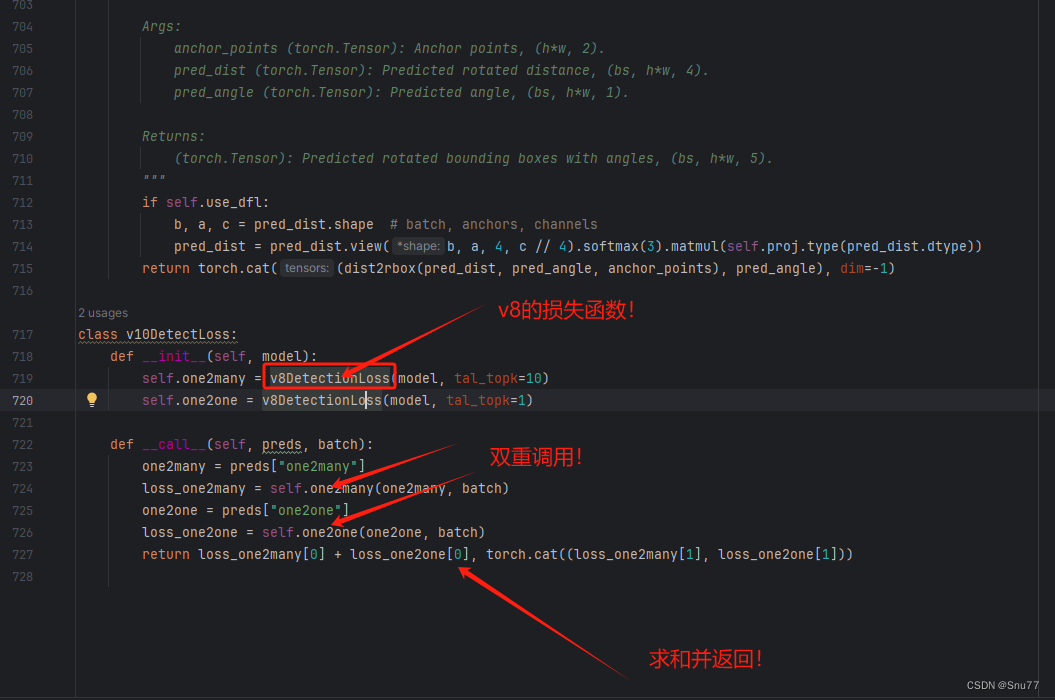
解决了后处理中的冗余预测问题,使YOLO在训练期间享有丰富而和谐的监督信号,同时在推理时无需NMS,从而实现高效的竞争性性能。其次,我们提出了整体效率-精度驱动的模型设计策略,通过对YOLO各组件进行全面检查,从效率和精度的角度优化模型架构。为提高效率,我们提出了轻量级分类头(Yaml文件中体现不出来,但是从代码上看只是重新布局了Conv的操作)、空间-通道分离下采样(SCDown)和基于秩的块设计(C2fUIB),以减少显著的计算冗余,实现更高效的架构。为提高精度,我们探索了大核卷积并提出了有效的部分自注意力模块,以增强模型能力,在低成本下实现性能改进(PSA)。
基于这些方法,我们成功地实现了一个新的实时端到端检测器系列,即YOLOv10-N / S / M / B / L / X。标准目标检测基准(如COCO)上的广泛实验表明,YOLOv10在计算-精度权衡方面显著优于以前的最先进模型。例如,YOLOv10-S / X在相似性能下分别比RT-DETR-R18 / R101快1.8倍和1.3倍。与YOLOv9-C相比,YOLOv10-B在相同性能下延迟减少46%。此外,YOLOv10表现出高效的参数利用率。YOLOv10-L / X分别比YOLOv8-L / X高出0.3 AP和0.5 AP,参数减少1.8倍和2.3倍。YOLOv10-M在相似AP下分别比YOLOv9-M / YOLO-MS减少23%和31%的参数。
总结:通过改进后处理和模型架构,提升YOLO的准确性和速度,提出了YOLOv10。
创新点:
- 引入一致的双重分配策略,消除NMS依赖。
- 提出整体效率-精度驱动的模型设计策略,包括轻量级分类头、空间-通道分离下采样和基于秩的块设计。
实验结果:YOLOv10在多个基准测试中表现出色,显著优于之前的最先进模型。
二、相关工作
实时目标检测器: 实时目标检测旨在在低延迟下对物体进行分类和定位,这对于实际应用至关重要。过去几年中,大量的努力集中在开发高效的检测器上。特别是,YOLO系列脱颖而出,成为主流之一。YOLOv1、YOLOv2和YOLOv3识别出典型的检测架构,由三个部分组成,即骨干网、颈部和头部。YOLOv4和YOLOv5引入了CSPNet设计来替代DarkNet,同时结合了数据增强策略、增强的PAN和更多种类的模型规模等。YOLOv6为颈部和骨干网分别提出了BiC和SimCSPSPPF,并采用了锚辅助训练和自我蒸馏策略。YOLOv7引入了E-ELAN以实现丰富的梯度流路径,并探索了几种可训练的免费增益方法。YOLOv8提出了C2f构建块,以实现有效的特征提取和融合。Gold-YOLO提供了先进的GD机制,以提升多尺度特征融合能力。YOLOv9提出了GELAN来改进架构,并通过PGI增强训练过程。
端到端目标检测器:端到端目标检测作为一种范式转变,提供了简化的架构。DETR引入了变压器架构,并采用匈牙利损失(感兴趣的可以搜索一下匈牙利算法)来实现一对一匹配预测,从而消除了手工设计的组件和后处理。从那时起,各种DETR变体被提出以增强其性能和效率。Deformable-DETR利用多尺度可变形注意模块加速收敛速度。DINO将对比降噪、混合查询选择和向前两次查看方案集成到DETR中。RT-DETR进一步设计了高效的混合编码器,并提出了不确定性最小的查询选择,以提高准确性和延迟。另一种实现端到端目标检测的方法是基于CNN的检测器。可学习的NMS和关系网络提出了另一种网络,以去除检测器的重复预测。OneNet和DeFCN提出了一对一匹配策略,使端到端目标检测能够完全依靠卷积网络实现。FCOSpss引入了正样本选择器,以选择最佳样本进行预测。
总结:这部分介绍了实时目标检测器(特别是YOLO系列)的演变和端到端目标检测器的发展,强调了不同架构设计和优化策略在提高检测性能和效率方面的重要性。通过这些努力,研究人员不断推动目标检测技术的发展,以满足实际应用的需求,全是套话这段不是很重要。
三、方法
3.1 无NMS训练的一致双重分配
在训练过程中,YOLO通常使用TAL(标签分配策略)为每个实例分配多个正样本。一对多分配的采用提供了丰富的监督信号,有助于优化并实现优异的性能。然而,这需要YOLO依赖于NMS后处理,导致推理效率不佳。虽然先前的工作探索了一对一匹配(为每个实例分配一个正样本,避免NMS后处理。)以抑制冗余预测,但通常会引入额外的推理开销或导致次优性能。在这项工作中,我们提出了一种无NMS训练策略,通过双重标签分配和一致的匹配度量,实现了高效率和竞争性性能。
例子解释1
这里解释一下大家可能不懂的点,一对多分配策略的解释:
假设我们有一张图像,其中包含两个目标:一个狗和一个猫。每个目标都有一个对应的真实边界框。
标签分配:
- 在一对多分配策略下,对于每个真实边界框(例如,狗的边界框),会分配多个正样本。这些正样本是预测的边界框,它们与真实边界框的重叠度(通常用IoU表示)超过某个阈值。例如,对于狗的边界框,模型可能会生成10个候选边界框,其中有5个与真实边界框的IoU超过0.5,这5个候选边界框将被分配为正样本。
丰富的监督信号:
- 由于分配了多个正样本,模型在训练过程中能够从更多的边界框中学习到相关信息。这些正样本提供了丰富的监督信号,有助于模型更好地优化分类和定位能力。每个正样本都会计算一个损失(例如分类损失和定位损失),模型会根据这些损失来调整参数,从而提高检测精度。
依赖NMS后处理:
- 在推理阶段(即模型应用于新图像时,注意此处是在推理阶段!!!我注意到Github上有人对作者的计算量进行质疑说和论文中公布的参数量不一致,有人回复是说训练的时候没有用到NMS所以此处的计算量可以忽略不记,仅仅是在推理阶段生效 | 我理解的就是论文公布的计算量是在推理阶段的,我们实际训练的时候可能参数量要大一些,不知道对不对,如果不对欢迎大家在评论区指正!),由于一对多分配策略会产生多个重叠的正样本(即多个边界框可能检测到同一个目标),因此需要使用NMS(非极大值抑制)来选择最优的预测边界框。NMS会抑制重叠度高的非最佳边界框,只保留得分最高的边界框,以减少冗余检测。
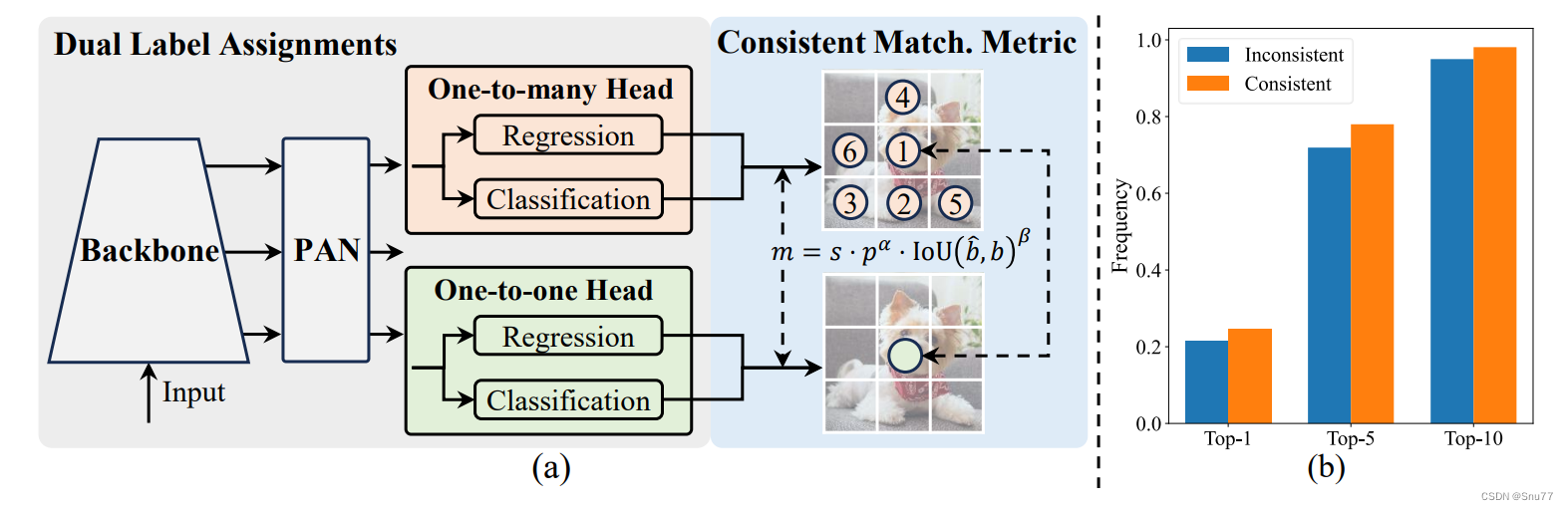 图片2描述:图展示了无NMS训练的一致双重分配策略以及YOLOv8-S模型在一对多结果中的一对一分配频率。
图片2描述:图展示了无NMS训练的一致双重分配策略以及YOLOv8-S模型在一对多结果中的一对一分配频率。
例子解释2
举例理解:大家看到这里可能还是晕头转向的对于这个一致双重分配策略不太理解,下面举个例子带大家理解下->
例子背景:
假设我们有一张包含三个目标(一个狗、一个猫和一个鸟)的图像。每个目标都有一个对应的真实边界框。在训练过程中,我们希望模型能够准确地预测这些边界框的位置和类别。一对多分配
在一对多分配策略中,模型会为每个真实边界框分配多个预测边界框作为正样本。假设对于狗的真实边界框,模型生成了10个候选边界框,其中有4个与真实边界框的IoU超过了设定的阈值(例如0.5),这4个边界框都会被视为正样本。这样做的目的是:
- 丰富监督信号:通过多个正样本,模型在训练过程中能够获得更多的反馈,帮助其更好地学习目标的特征。
- 优化效果更好:由于有更多的正样本参与优化,模型的性能通常会更好。
一对一分配(One-to-One Assignment)
在一对一分配策略中,每个真实边界框只分配一个预测边界框作为正样本。例如,对于狗的真实边界框,模型只选择与其IoU最高的一个预测边界框作为正样本。这种方法的优点是:
- 无需NMS后处理:因为每个目标只有一个正样本,避免了推理过程中使用非极大值抑制(NMS)来消除重复检测。
- 更高效的推理:省去了NMS步骤,推理速度更快。
一致双重分配策略(重点)
一致双重分配策略结合了一对多和一对一分配的优点,在训练和推理过程中分别使用这两种方法。1. 训练阶段:
- 一对多头:利用一对多分配策略,为每个真实边界框分配多个正样本,提供丰富的监督信号,帮助模型更好地学习。
- 一对一头:同时,利用一对一分配策略,为每个真实边界框分配一个正样本,确保训练过程中模型能够学会选择最佳的预测边界框。
2. 推理阶段:
- 在推理阶段,只使用一对一头进行预测,因为一对一分配确保每个目标只有一个正样本,避免了冗余预测和NMS后处理。
一致匹配度量(重点)
为了使两个分支在训练过程中保持一致,采用了一致的匹配度量。匹配度量用于评估预测边界框与真实边界框之间的一致性,公式为:
其中,
是分类得分,
和
分别是预测边界框和真实边界框,
表示空间先验,
和
是超参数。
通过一致的匹配度量,可以确保一对一头和一对多头在优化方向上的一致性,进一步提升模型的性能。
希望能通过这个例子帮助大家理解一下这个策略,如果不对欢迎评论区指正!
双重标签分配(论文翻译,具体上面已经用例子解释过了)
与一对多分配不同,一对一匹配仅为每个真实值分配一个预测,避免了NMS后处理。然而,这导致了弱监督,从而导致次优的准确性和收敛速度。幸运的是,这一缺陷可以通过一对多分配来弥补。为此,我们引入了YOLO的双重标签分配,结合了两种策略的优势。具体而言,如图2.(a)[前面展示过的图片]所示,我们为YOLO增加了另一个一对一头。它保留了与原始一对多分支相同的结构,并采用相同的优化目标,但利用一对一匹配获得标签分配。在训练过程中,两个头与模型一起联合优化,使骨干和颈部享有一对多分配提供的丰富监督。在推理过程中,我们丢弃一对多头,并利用一对一头进行预测,从而无需额外的推理成本即可实现YOLO的端到端部署。此外,在一对一匹配中,我们采用最高选择,取得了与匈牙利匹配相同的性能,但训练时间更少。
论文翻译(下面是论文中给出的例子):给定一个实例,我们将其与预测的最大IoU表示为u*,一对多和一对一匹配的最大分数分别表示为mo2m和mo2o。假设一对多分支产生了正样本Ω,一对一分支选择了度量为mo2o,i的第i个预测,我们可以推导出分类目标to2m,j = u · mo2m,j / mo2m ≤ u,对于j ∈ Ω 和to2o,i = u* · mo2o,i / mo2o = u,如[20, 59, 27, 64, 14]中所述的任务对齐损失。两个分支之间的监督差距可以通过不同分类目标的1-Wasserstein距离来推导,即 A = to2o,i − I(i ∈ Ω)to2m,i + \sum_{k∈Ω\{i}}to2m,k 我们可以观察到,随着to2m,i的增加,差距减小,即i在Ω中的排名越高。当to2m,i = u*时,差距达到最小,即i是Ω中的最佳正样本,如图2.(a)所示。为此,我们提出了一致的匹配度量,即αo2o = r · αo2m和βo2o = r · βo2m,这意味着mo2o = mr o2m。因此,一对多头的最佳正样本也是一对一头的最佳样本。这样,两个头可以一致和谐地优化。为简单起见,我们默认取r = 1,即αo2o = αo2m和βo2o = βo2m。为验证改进的监督对齐,我们统计了训练后在一对多结果中前1 / 5 / 10的一对一匹配对的数量。如图2.(b)所示,在一致的匹配度量下,对齐有所改进。关于数学证明的更全面理解,请参见附录。
3.2 整体效率-精度驱动的模型设计
除了后处理之外(本章节主要介绍的是一些结构性的创新,本章节附我个人手撕的各个结构图),YOLO模型的架构也在效率-精度权衡方面带来了巨大的挑战。尽管之前的工作探索了各种设计策略,但对YOLO各个组件的全面检查仍然缺乏。因此,模型架构表现出不可忽视的计算冗余和受限的能力,阻碍了其实现高效率和高性能的潜力。在这里,我们旨在从效率和精度的角度全面进行YOLO的模型设计。
效率驱动的模型设计
YOLO的组件包括干(stem)、下采样层、带有基本构建块的阶段和头部和主干部分计算成本较低,因此我们对其他三个部分进行效率驱动的模型设计。
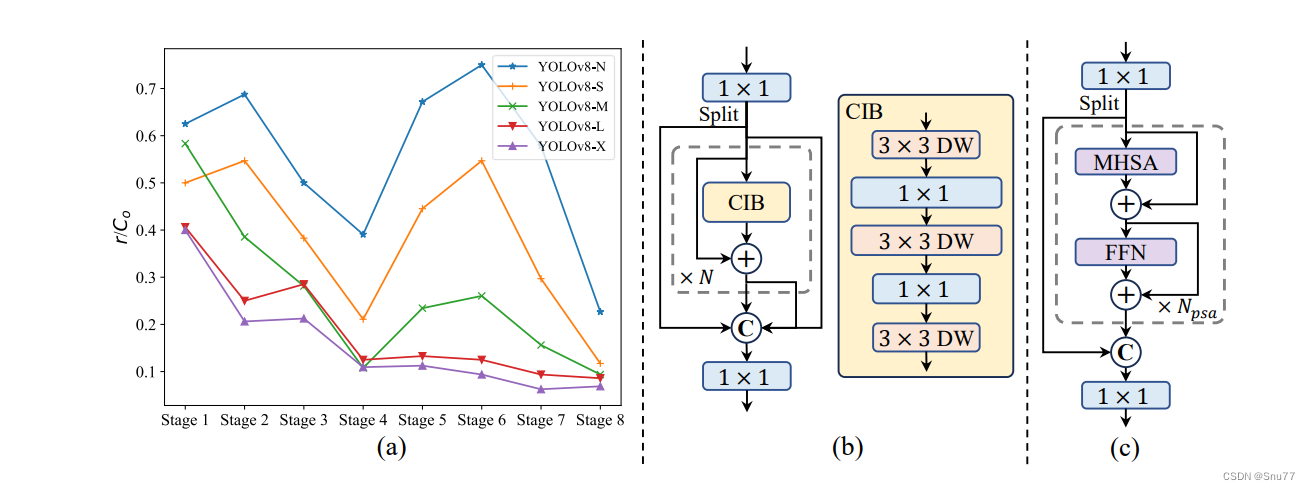
图3:说明
(a) YOLOv8各阶段和模型的内在秩
图3(a)展示了YOLOv8模型中骨干和颈部各阶段的内在秩。具体信息如下:
- 内在秩:内在秩是通过计算各阶段最后一个基本块的最后一个卷积的数值秩来确定的。数值秩表示超过某个阈值的奇异值数量。
- 归一化:数值秩
在y轴上归一化为
,其中
表示输出通道的数量,阈值默认设置为
,其中
是最大的奇异值。
- 观察结果:深层阶段和大型模型通常表现出较低的内在秩值,这表明这些阶段和模型存在较多的冗余。
图3(b) 紧凑倒置块(CIB)
图3(b)展示了紧凑倒置块(Compact Inverted Block, CIB)的结构:
- 组成部分:CIB采用廉价的深度卷积进行空间混合,并采用成本效益高的点卷积进行通道混合。
- 应用:CIB可以作为高效的基本构建块,例如嵌入ELAN结构中。
图3(c) 部分自注意力模块(PSA)
图3(c)展示了部分自注意力模块(Partial Self-Attention, PSA)的结构:
组成部分:PSA模块首先通过1×1卷积将特征均匀地划分为两部分。然后,只有一部分进入由多头自注意力模块(MHSA)和前馈网络(FFN)组成的NPSA块。最后,两部分特征被连接并通过1×1卷积融合(这就是指的是二次创新在MSHA上,也是我们大家发论文主要研究的方向)。
- 优化:在MHSA中,查询和键的维度设为值的一半,并将LayerNorm替换为BatchNorm以加快推理速度。
- 位置:PSA仅在分辨率最低的Stage 4之后放置,以避免自注意力的二次复杂性带来的过多开销。
通过这些模块的优化设计,YOLOv8模型在保持高性能的同时,实现了更高的效率和计算资源利用率。
1. 轻量级分类头
- YOLO中的分类头和回归头通常共享相同的架构。然而,它们在计算开销上表现出显著差异。例如,YOLOv8-S中的分类头(5.95G/1.51M)的FLOPs和参数数量分别是回归头(2.34G/0.64M)的2.5倍和2.4倍。然而,分析分类误差和回归误差的影响后,我们发现回归头对YOLO的性能更为重要。因此,我们可以减少分类头的开销而不显著影响性能。因此,我们采用了一个轻量级架构的分类头,它由两个核大小为3×3的深度可分离卷积和一个1×1卷积组成。
2. 空间-通道分离下采样
- YOLO通常利用带有步幅2的常规3×3标准卷积,同时实现空间下采样(从H×W到H/2×W/2)和通道变换(从C到2C)。这引入了不可忽视的计算成本
和参数数量
相反,我们提出分离空间减少和通道增加操作,进行更高效的下采样。具体而言,我们首先利用点卷积调整通道维度,然后利用深度卷积进行空间下采样。这将计算成本减少到
和参数数量减少到
。同时,这最大限度地保留了下采样过程中的信息,从而在减少延迟的同时实现竞争性性能。

3. 基于秩的块设计
- YOLO通常为所有阶段使用相同的基本构建块,例如YOLOv8中的瓶颈块。为全面检查这种同质设计的冗余,我们利用内在秩分析各阶段的冗余。具体而言,我们计算每个阶段最后一个基本块的最后一个卷积的数值秩,表示超过阈值的奇异值数量。图3.(a)展示了YOLOv8的结果,表明深层阶段和大模型往往表现出更多冗余。此观察表明,简单地为所有阶段应用相同的块设计对于最佳的容量-效率权衡来说是次优的。为此,我们提出了一种基于秩的块设计方案,旨在通过紧凑的架构设计减少冗余阶段的复杂性。我们首先提出了一种紧凑的倒置块(CIB)结构,它采用廉价的深度卷积进行空间混合,并采用成本效益高的点卷积进行通道混合,如图3.(b)所示。它可以作为高效的基本构建块,例如嵌入ELAN结构中。然后,我们倡导一种基于秩的块分配策略,以在保持竞争性容量的同时实现最佳效率。具体而言,给定一个模型,我们按内在秩从低到高排序其所有阶段。我们进一步检查用CIB替换领先阶段的基本块的性能变化。如果与给定模型相比没有性能下降,我们继续替换下一个阶段,否则停止该过程。这样,我们可以在各个阶段和模型规模中实现自适应紧凑块设计,在不影响性能的情况下实现更高的效率。由于篇幅限制,算法细节请参见附录。

通过这种整体效率-精度驱动的模型设计策略,我们可以显著提高YOLO模型的性能和效率,使其在各种应用场景中表现出色。
3.3 精度驱动的模型设计
我们进一步探索大核卷积和自注意力机制,旨在以最小的成本提升性能。
(1) 大核卷积
采用大核深度卷积是一种有效的方法,可以扩大感受野并增强模型的能力。然而,在所有阶段简单地使用它们可能会导致以下问题:
- 浅层特征污染:在浅层特征中使用大核卷积可能会影响检测小物体的效果。
- 高分辨率阶段的I/O开销和延迟:在高分辨率阶段使用大核卷积会显著增加I/O开销和延迟。
因此,我们建议在深层阶段的紧凑倒置块(CIB)中使用大核深度卷积。具体来说,我们将CIB中第二个3×3深度卷积的核大小增加到7×7。此外,我们采用结构重新参数化技术,在不增加推理开销的情况下引入另一个3×3深度卷积分支,以缓解优化问题。随着模型规模的增加,其感受野自然扩展,大核卷积的好处减少。因此,我们仅在小模型规模中采用大核卷积。
(2) 部分自注意力(PSA)
自注意力在各种视觉任务中得到了广泛应用,因为它具有显著的全局建模能力。然而,自注意力机制表现出较高的计算复杂度和内存占用。为了解决这个问题,鉴于注意力头冗余的普遍存在,我们提出了一种高效的部分自注意力(PSA)模块设计,如图3(c)所示。
具体来说,我们通过1×1卷积将特征均匀地划分为两部分。然后,我们仅将其中一部分输入到由多头自注意力模块(MHSA)和前馈网络(FFN)组成的NPSA块中。两部分特征随后被连接并通过1×1卷积融合。此外,我们遵循将MHSA中查询和键的维度分配为值的一半,并将LayerNorm替换为BatchNorm以加快推理速度。
PSA仅在分辨率最低的Stage 4之后放置,以避免自注意力二次复杂性带来的过多开销。通过这种方式,可以在低计算成本下将全局表示学习能力引入YOLO模型,从而增强模型能力并提高性能。
通过这些精度驱动的设计,我们能够在不显著增加计算成本的情况下提升YOLO模型的性能。

四、实验
4.1 实现细节
我们选择YOLOv8作为基线模型,因为它在延迟和准确性之间具有良好的平衡,并且提供了各种模型尺寸。我们采用一致的双重分配策略进行无NMS训练,并基于此进行整体效率-精度驱动的模型设计,从而开发了YOLOv10模型。YOLOv10具有与YOLOv8相同的变体,即N / S / M / L / X。此外,我们通过简单地增加YOLOv10-M的宽度缩放因子,派生出一个新的变体YOLOv10-B。我们在COCO数据集上验证了所提出的检测器,并在相同的从头训练设置下进行验证。此外,所有模型的延迟测试都在T4 GPU上使用TensorRT FP16进行,遵循相关研究的方法。
4.2 与最先进方法的比较
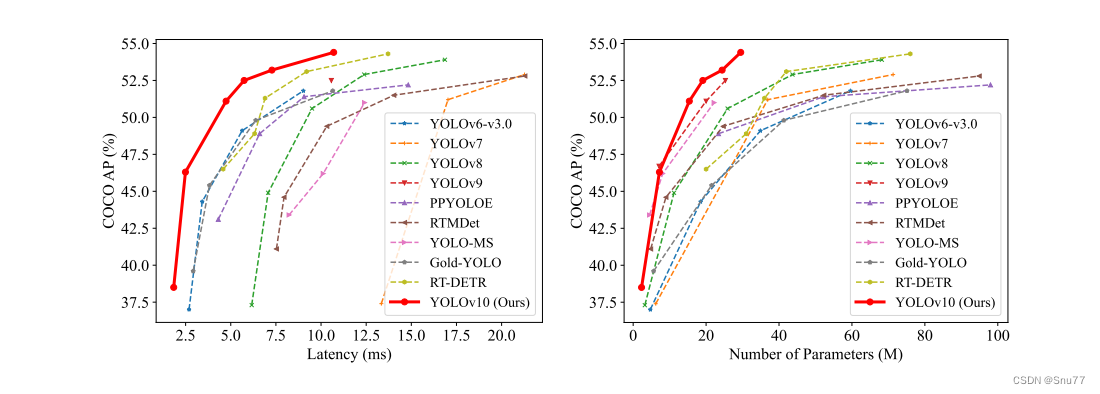
如表1所示,我们的YOLOv10在各种模型规模上实现了最先进的性能和端到端延迟。我们首先将YOLOv10与我们的基线模型YOLOv8进行比较。在N / S / M / L / X五种变体上,YOLOv10分别实现了1.2% / 1.4% / 0.5% / 0.3% / 0.5%的AP提升,同时参数减少了28% / 36% / 41% / 44% / 57%,计算量减少了23% / 24% / 25% / 27% / 38%,延迟降低了70% / 65% / 50% / 41% / 37%。
与其他YOLO模型相比,YOLOv10在准确性和计算成本之间也表现出更优的权衡。具体来说,对于轻量级和小型模型,YOLOv10-N / S比YOLOv6-3.0-N / S分别高出1.5 AP和2.0 AP。
表1中列出了与最先进方法的比较。延迟是使用官方预训练模型测量的。Latencyf表示模型在没有后处理时前向过程的延迟。†表示YOLOv10使用原始一对多训练并采用NMS的结果。为了公平比较,所有结果均未使用诸如知识蒸馏或PGI等额外的高级训练技术。
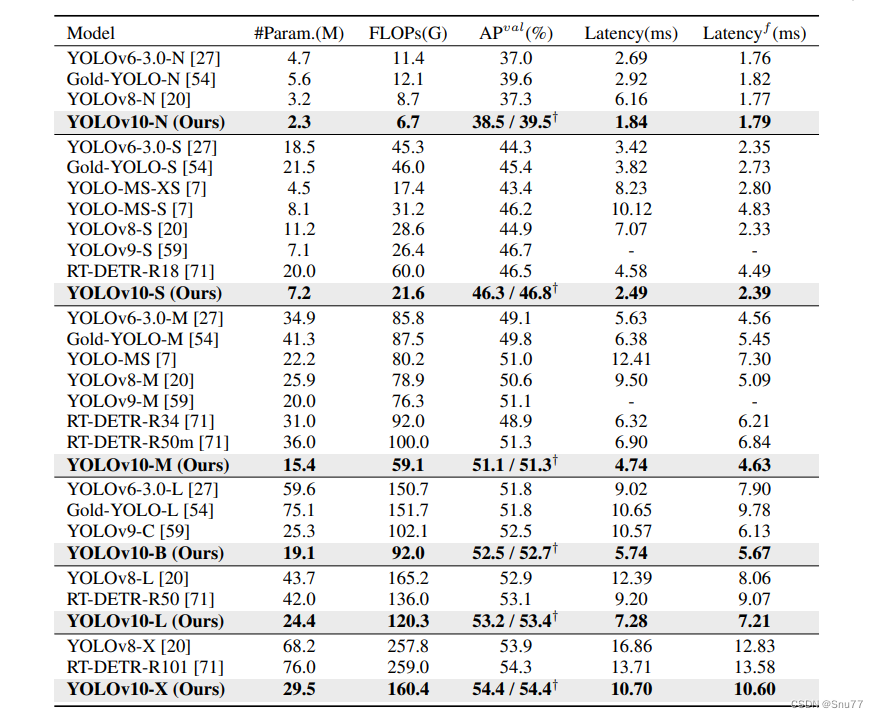
相比于AP,YOLOv10在参数量和计算量上分别减少了51% / 61%。对于中等规模的模型,YOLOv10-B / M相较于YOLOv9-C / YOLO-MS,在相同或更好的性能下分别减少了46% / 62%的延迟。对于大型模型,相较于Gold-YOLO-L,我们的YOLOv10-L减少了68%的参数量和32%的延迟,同时显著提升了1.4%的AP。此外,与RT-DETR相比,YOLOv10在性能和延迟上均有显著提升。值得注意的是,YOLOv10-S / X在类似性能下推理速度分别比RT-DETR-R18 / R101快1.8倍和1.3倍。这些结果充分证明了YOLOv10作为实时端到端检测器的优越性。
我们还使用原始的一对多训练方法将YOLOv10与其他YOLO模型进行比较。在这种情况下,我们考虑了模型前向过程的性能和延迟(Latencyf),如[56, 20, 54]所示。表1显示,YOLOv10在不同模型规模上也表现出最先进的性能和效率,表明我们的架构设计具有有效性。
4.3 模型分析
消融研究。我们在表2中展示了基于YOLOv10-S和YOLOv10-M的消融结果。可以观察到,我们的无NMS训练通过一致的双重分配显著减少了YOLOv10-S的端到端延迟4.63毫秒,同时保持了44.3%的竞争性性能。此外,我们的效率驱动模型设计减少了11.8M参数和20.8 GFLOPs,同时对于YOLOv10-M的延迟减少了0.65毫秒,充分展示了其有效性。更进一步,我们的精度驱动模型设计对于YOLOv10-S和YOLOv10-M分别取得了1.8 AP和0.7 AP的显著提升,延迟仅增加了0.18毫秒和0.17毫秒,这很好地展示了其优越性。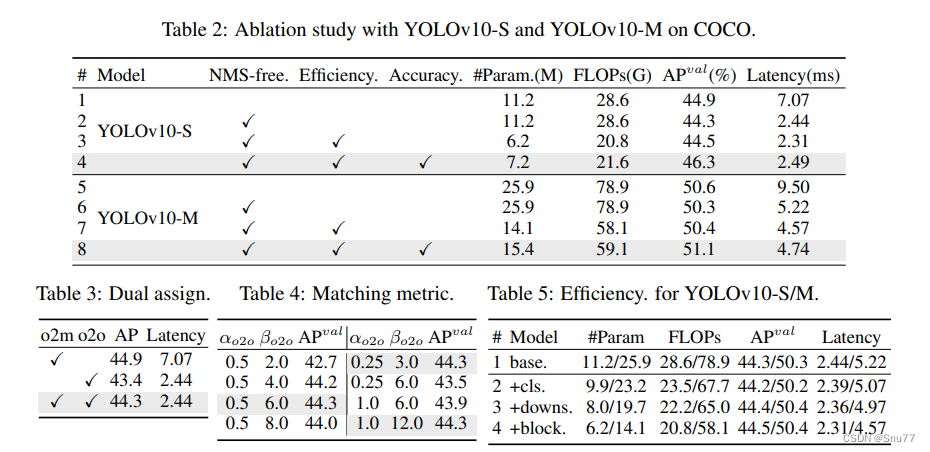
无NMS训练的分析
- 双重标签分配。我们为无NMS的YOLO模型引入了双重标签分配,这在训练过程中可以带来一对多(o2m)分支的丰富监督,并在推理过程中带来一对一(o2o)分支的高效率。我们基于YOLOv8-S(表2中的#1)验证了它的优势。具体而言,我们分别引入了仅用o2m分支和仅用o2o分支进行训练的基线。正如表3所示,我们的双重标签分配在AP-延迟权衡上实现了最佳表现。
- 一致的匹配度量。我们引入一致的匹配度量,使一对一头与一对多头更加协调。我们基于YOLOv8-S(表2中的#1),在不同的αo2o和βo2o下验证了其优势。正如表4所示,所提出的一致匹配度量(即αo2o=r · αo2m和βo2o=r · βo2m)可以实现最佳性能,其中一对多头中的αo2m=0.5和βo2m=6.0 [20]。这种改进可归因于监督差距的减少(方程(2)),从而在两个分支之间提供了更好的监督对齐。此外,所提出的一致匹配度量消除了对耗时的超参数调优的需求,这在实际场景中具有吸引力。
效率驱动模型设计的分析。我们基于YOLOv10-S/M逐步引入效率驱动设计元素进行实验。我们的基线是没有效率-准确性驱动模型设计的YOLOv10-S/M模型(表2中的#2/#6)。如表5所示,每个设计组件,包括轻量化分类头、空间-通道解耦下采样和排序引导块设计,都有助于减少参数数量、FLOPs和延迟。重要的是,这些改进是在保持竞争性能的情况下实现的。
- 轻量化分类头。我们基于表5中的YOLOv10-S的#1和#2,分析了预测类别和定位错误对性能的影响,如[6]。具体而言,我们通过一对一分配将预测与实例匹配。然后,我们用实例标签替换预测的类别得分,得到没有分类错误的APval w/o c。同样,我们用实例的定位替换预测的定位,得到没有回归错误的APval w/o r。如表6所示,APval w/o r远高于APval w/o c,表明消除回归错误带来了更大的改进。因此,性能瓶颈更多地在于回归任务。因此,采用轻量化分类头可以在不影响性能的情况下提高效率。
- 空间-通道解耦下采样。我们为提高效率对下采样操作进行了解耦,其中通过逐点卷积(PW)首先增加通道维度,然后通过深度卷积(DW)减少分辨率,以最大限度地保留信息。我们基于表5中的YOLOv10-S,将其与通过DW进行空间缩减,然后通过PW进行通道调整的基线方法进行了比较。如表7所示,我们的下采样策略通过减少下采样过程中信息损失,实现了0.7%的AP提升。
紧凑的倒置块(CIB)。我们引入CIB作为紧凑的基本构建块。我们基于表5中的YOLOv10-S验证了其有效性。具体而言,我们引入了倒置残差块[46](IRB)作为基线,如表8所示,基线达到了次优的43.7% AP。然后,我们在其后添加了一个3×3的深度卷积(DW),称为“IRB-DW”,这
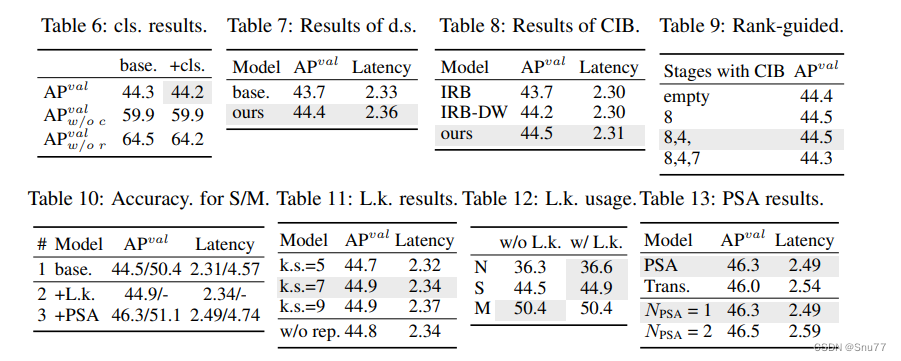
带来了0.5%的AP提升。与“IRB-DW”相比,我们的CIB通过在前面添加另一个DW(开销最小)进一步实现了0.3%的AP提升,表明其优越性。排序引导的块设计。我们引入排序引导的块设计,自适应地整合紧凑块设计,以提高模型效率。我们基于表5中的YOLOv10-S验证了它的优势。根据固有排序按升序排序的阶段为阶段8-4-7-3-5-1-6-2,如图3.(a)所示。正如表9所示,当逐步用高效的CIB替换每个阶段的瓶颈块时,我们观察到从阶段7开始的性能下降。在具有较低固有排序和更多冗余的阶段8和4中,我们可以采用高效块设计而不影响性能。这些结果表明,排序引导的块设计可以作为提高模型效率的有效策略。
精度驱动模型设计的分析。我们展示了基于YOLOv10-S/M逐步整合精度驱动设计元素的结果。我们的基线是在整合了效率驱动设计后的YOLOv10-S/M模型(表2中的#3/#7)。如表10所示,采用大核卷积和PSA模块分别为YOLOv10-S带来了0.4% AP和1.4% AP的显著性能提升,而延迟增加分别只有0.03毫秒和0.15毫秒。注意,对于YOLOv10-M没有采用大核卷积(见表12)。
- 大核卷积。我们首先基于表10中的YOLOv10-S的#2研究了不同核大小的影响。如表11所示,随着核大小的增加,性能提高并在7×7核大小附近趋于平稳,表明了大感受野的益处。此外,在训练过程中移除重参数化分支会导致0.1%的AP下降,显示了其在优化中的有效性。此外,我们基于YOLOv10-N / S / M研究了大核卷积在不同模型规模上的效果。如表12所示,对于大模型(即YOLOv10-M)没有带来改进,这是由于其固有的广泛感受野。因此,我们只在小模型(即YOLOv10-N / S)中采用大核卷积。
- 部分自注意力(PSA)。我们引入PSA,通过以最低成本结合全局建模能力来提高性能。我们首先基于表10中的YOLOv10-S的#3验证了其有效性。具体而言,我们引入了变压器块,即MHSA后接FFN,作为基线,称为“Trans.”。如表13所示,与之相比,PSA带来了0.3%的AP提升,同时延迟减少了0.05毫秒。性能提升可能归因于在自注意力中通过减少注意力头的冗余缓解了优化问题[62, 9]。此外,我们研究了不同NPSA的影响。如表13所示,将NPSA增加到2可获得0.2%的AP提升,但延迟增加了0.1毫秒。因此,我们默认将NPSA设置为1,以在保持高效率的同时增强模型能力。
五、结论
在本文中,我们针对YOLOs的整个检测流程中的后处理和模型架构进行了研究。对于后处理,我们提出了一致的双重分配用于无NMS训练,实现了高效的端到端检测。对于模型架构,我们引入了整体的效率-准确性驱动模型设计策略,改善了性能-效率的权衡。这些改进带来了我们新的实时端到端目标检测器YOLOv10。大量实验表明,YOLOv10在性能和延迟方面均达到了最先进的水平,相比其他高级检测器,充分展示了其优越性。
温馨提示
在末尾再给大家说一下,YOLO系列目前发展的比较快,大家可能会感到很迷茫不知道如何选择模型来作为改进的基准,其实不管是最近新出的YOLOv9还是v10其实目前来看都不适用于改进,v9的原因在v9的专栏已经介绍过了,v10主要原因还是小作坊出的(不算是正统像V5和V8)其次就是论文还没有被收录目前来看V10的论文中我阅读过程中甚至能够发现到错误的地方,所以如果你是短期内急着毕业那么V8和RT-DETR应该是目前最好的选择,如果你还不急着产出一些成果那么V10和V9也是可以入手看一看的,以上内容都是我个人见解仅供参考!
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv10改进有效涨点专栏,本专栏目前为新开的,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏目录:YOLOv10改进有效专栏 | 持续复现前沿机制
相关文章:
YOLOv10详细解读 | 一文带你深入了解yolov10的创新点(附网络结构图 + 举例说明)
前言 Hello大家好,我是Snu77,继YOLOv9发布时间没有多久,YOLOv10就紧接着发布于2024.5.23号(不得不感叹YOLO系列的发展速度,但要纠正大家的观点就是不是最新的就一定最好)! 本文给大家带来的是…...

【openlayers系统学习】3.5colormap详解(颜色映射)
五、colormap详解(颜色映射) colormap 包是一个很好的实用程序库,用于创建颜色图。该库已作为项目的依赖项添加(1.7美化(设置style))。要导入它,请编辑 main.js 以包含以下行…...
Redis教程(十五):Redis的哨兵模式搭建
一、搭建Redis一主二从 分别复制三份Redis工作文件夹,里面内容一致 接着修改7002的配置文件,【redis.windows-service.conf】 port 7002 改成 port 7002 slaveof 127.0.0.1 7001 7003也同样修改 port 7003 slaveof 127.0.0.1 7001 这样就指定了700…...

【C语言】8.C语言操作符详解(3)
文章目录 10.操作符的属性:优先级、结合性10.1 优先级10.2 结合性 11.表达式求值11.1 整型提升11.2 算术转换11.3 问题表达式解析11.3.1 表达式111.3.2 表达式211.3.3 表达式311.3.4 表达式411.3.5 表达式5: 11.4 总结 10.操作符的属性:优先级、结合性 …...

离线初始化k8s
导出和导入所有必要的 Kubernetes 镜像,使用阿里云作为源。 在能访问外网的机器上拉取镜像 首先,在有外网访问的机器上运行以下命令来拉取所有 Kubernetes v1.29.5 版本需要的镜像: kubeadm config images pull --image-repository regist…...
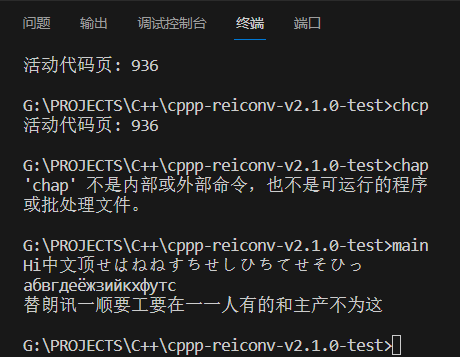
C++字符编码 cppp-reiconv库使用详解
经常写一些控制台小程序,常常会遇到输出中文乱码的问题,在windwos下可以使用MultiByteToWideChar转换字符编码,但跨平台就需要cppp-reiconv这样的第三方字符编码处理库,且开源。 一、下载cppp-reiconv库的源码和静/动态库 GitHu…...
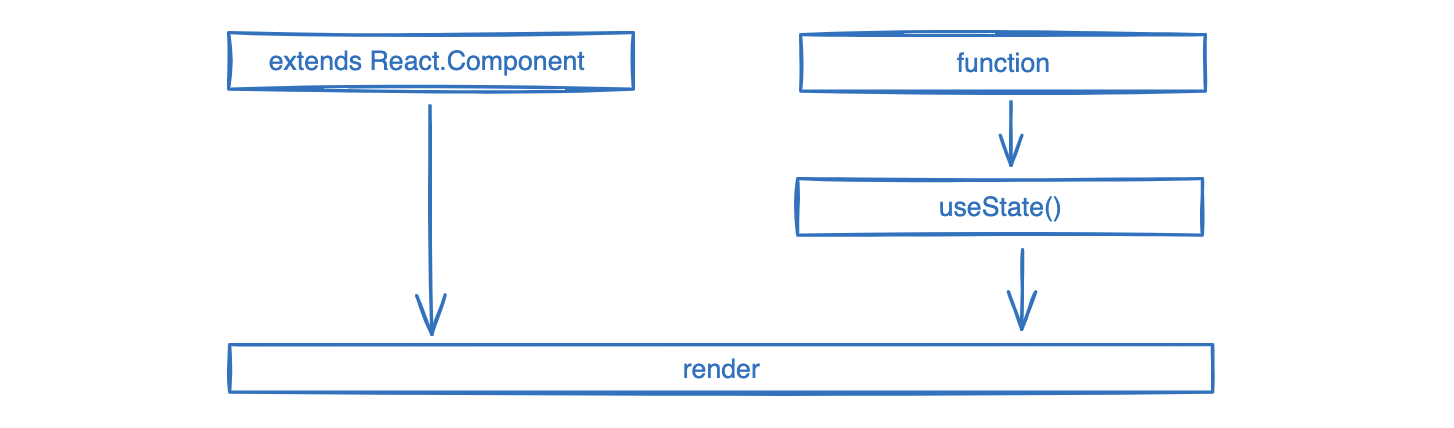
通过继承React.Component创建React组件-5
在React中,V16版本之前有三种方式创建组件(createClass() 被删除了),之后只有两种方式创建组件。这两种方式的组件创建方式效果基本相同,但还是有一些区别,这两种方法在体如下: 本节先了解下用extnds Reac…...
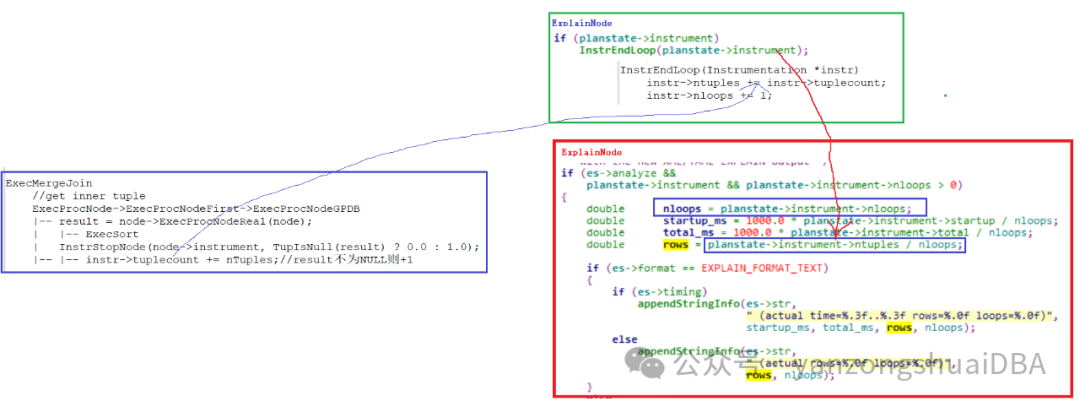
PgSQL内核机制 - 算子执行统计元组个数
PgSQL内核机制 - 算子执行统计元组个数 我们在执行explain analyze观察执行计划执行情况时,时常通过每个算子实际执行结果来分析SQL的执行,其中有一项“rows XXX”表示执行的行数(这里姑且先认为是执行的真实行数)。但有些场景下…...

Ubuntu/Linux 安装Paraview
文章目录 0. 卸载已有ParaView1. 安装ParaView1.1 下载后安装 2.进入opt文件夹改名3. 更改启动项4. 创建硬链接5. 添加桌面启动方式6. 即可使用 0. 卸载已有ParaView YUT 1. 安装ParaView https://www.paraview.org/ 1.1 下载后安装 找到下载的文件夹,文件夹内…...

内存泄漏及其解决方法
1. 系统崩溃前的现象 垃圾回收时间延长:从原本的约10ms增长至50ms,Full GC时间也由0.5s增加至4-5s。Full GC频率增加:最短间隔可缩短至1分钟内发生一次。年老代内存持续增长:即使经过Full GC,年老代内存未见明显释放。…...

Java进阶学习笔记13——抽象类
认识抽象类: 当我们在做子类共性功能抽取的时候,有些方法在父类中并没有具体的体现,这个时候就需要抽象类了。在Java中,一个没有方法体的方法应该定义为抽象方法,而类中如果有抽象方法,该类就定义为抽象类…...

【Docker学习】深入研究命令docker exec
使用docker的过程中,我们会有多重情况需要访问容器。比如希望直接进入MySql容器执行命令,或是希望查看容器环境,进行某些操作或访问。这时就会用到这个命令:docker exec。 命令: docker container exec 描述&#x…...

C语言中的文件操作
前言 嗨,我是firdawn,在本章中我们将介绍,文件的概念,文件的打开和关闭,在篇末我们将介绍文件缓冲区的作用,下面是本章的思维导图,接下来,让我们开始今天的学习吧! 一…...

python使用xlrd读取excel的时候把字符串读成了数字
xlrd 是一个 Python 库,用于读取 Excel 文件(.xls 和 .xlsx,但 .xlsx 需要 openpyxl 或 xlrd 的较新版本)。然而,xlrd 在读取 Excel 文件时通常会将单元格的内容按其原始数据类型(如字符串、数字、日期等&a…...
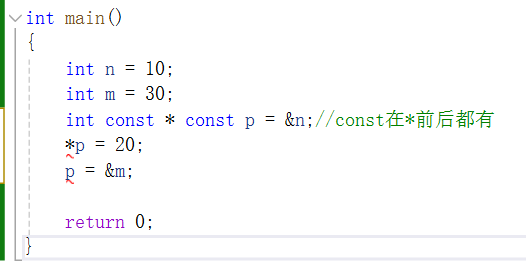
【C语言】走进指针世界(下卷)
前言 在“走进指针世界(上卷)”中,我们已经说过:什么是指针、内存和地址,指针的使用、声明、初始化,取地址运算符、解引用运算符以及这两者关系,还有指针赋值。 在正式使用指针进行各种代码的…...

【Spring】SSM整合_入门代码实现
1. Maven依赖 在pom.xml中添加SSM框架的依赖 <!-- Spring Core --> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> <version>5.3.x</version> </dependency>…...
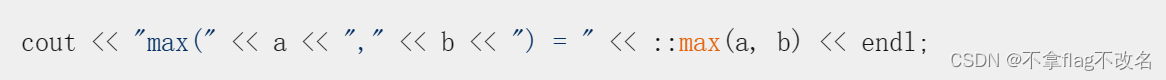
C++代码错误解决1(函数模板)
1、代码如下 //示例函数模板的使用 #include <iostream> #include <string> using namespace std; template <typename T>//函数模板 T max(T a,T b) {return a>b?a:b; } int main() {int a,b;cout<<"input two integers to a&b:"…...
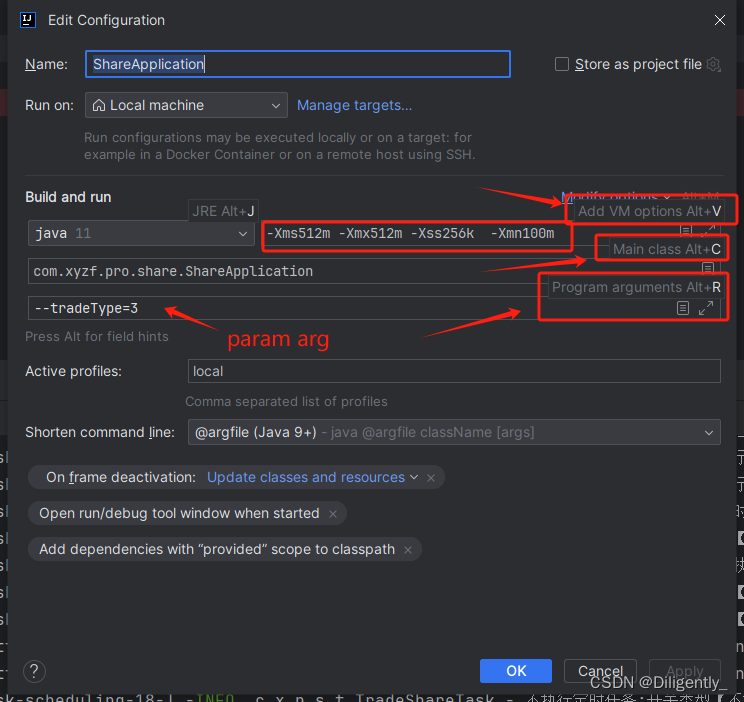
idea configuration 配置 方便本地启动环境切换
idea 再项目启动的时候避免切换环境导致上线的时候出现环境配置问题 可以再idea 的 configuration 中配置项目的 vm options 虚拟机的内容占用 -Xmx256m -Xms256m -Xmn100m -Xss256k program arguments properties 文件中需要修改的配置参数 active profiles 指定启动的本…...

win10配置wsl的深度学习环境
# 1、一步完成wsl:开启虚拟机、linux子系统、并下载ubuntu # 官方文档: https://learn.microsoft.com/zh-cn/windows/wsl/install wsl --install# 2、打开windows terminal,选ubuntu交互环境 # 第一次需要配置用户名和密码 # 接下来正常使用即可# 3、cud…...
如何处理时间序列的缺失数据
您是否应该删除、插入或估算? 世界上没有完美的数据集。每个数据科学家在数据探索过程中都会有这样的感觉: df.info()看到类似这样的内容: 大多数 ML 模型无法处理 NaN 或空值,因此如果您的特征或目标包含这些值,则在…...

小米MIMO最新邀请码
欢迎使用,各得10元体验金...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...

解密高校教师必会的Gemini 3.1 Pro五大科研隐藏技能:从论文评估到创新点锁定
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 科研路上,有人发完顶刊顺利晋升,有人还在为创新点抓耳挠腮。 大多数教…...

CausalVLR基准测试报告:在IU X-Ray和MIMIC-CXR数据集上的性能分析
CausalVLR基准测试报告:在IU X-Ray和MIMIC-CXR数据集上的性能分析 【免费下载链接】CausalVLR CausalVLR: A Toolbox and Benchmark for Vision-Language Causal Reasoning (多模态因果推理开源框架) 项目地址: https://gitcode.com/gh_mirrors/ca/CausalVLR …...

独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目 对于独立开发者或小型团队而言,启动一个集成…...

别再只比参数了!从插件生态到中文优化,聊聊ChatGPT和文心一言的“隐形”差异
超越参数之争:ChatGPT与文心一言的生态与本土化实战解析 当技术评测文章还在反复比较模型参数量与发布时间时,真正影响日常工作效率的往往是那些未被量化的"软实力"。本文将从插件生态构建与中文场景优化两个维度,带您重新认识这两…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...

Claude Code用户告别封号与Token焦虑,无缝切换至Taotoken平台
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code用户告别封号与Token焦虑,无缝切换至Taotoken平台 对于依赖Claude Code进行编程辅助的开发者而言ÿ…...

Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验
Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为在Windows电脑上无法直接安装安卓应用而烦…...