纯干货分享 机器学习7大方面,30个硬核数据集
在刚刚开始学习算法的时候,大家有没有过这种感觉,最最重要的那必须是算法本身!
其实在一定程度上忽略了数据的重要性。
而事实上一定是,质量高的数据集可能是最重要的!
数据集在机器学习算法项目中具有非常关键的重要性,数据集的大小、质量的高低对整个项目的成功和模型性能的影响是至关重要的。
总结了6 方面:
1、决定模型性能:一个好的数据集可以让模型更准确,而低质量或小规模的数据集可能导致模型表现不佳。
2、特征选择和工程: 合适的特征选择和工程能够提高模型的泛化能力。
3、模型训练和评估: 好的数据集能够确保模型在不同数据上的泛化能力。
4、过拟合和欠拟合: 数据集的大小和质量可以影响模型的过拟合和欠拟合情况。较小的数据集更容易过拟合,而低质量数据可能导致欠拟合。
5、数据偏差: 数据集的不平衡分布或偏斜可能导致模型的偏差。
6、数据清洗和预处理: 数据集需要进行清洗和预处理,以处理缺失数据、异常值和重复数据。这是确保数据质量的重要步骤。
数据集是机器学习项目的基石。选择适当的数据集、数据清洗、特征工程和数据预处理等步骤都需要谨慎处理,以确保模型能够在实际应用中取得良好的效果。数据集的质量和数量都是决定模型成功的关键要素。
下面是涉及回归、分类、图像分类、文本情感分析、自然语言处理、自动驾驶和金融领域的30个常见机器学习数据集,以及每个数据集的介绍、获取链接和可能涉及到的算法。
回归问题
1、Boston Housing 数据集
-
介绍: 包含波士顿地区的住房价格数据。
-
获取方式: Scikit-learn内置数据集。
from sklearn.datasets import load_bostonboston = load_boston()# 特征矩阵
X = boston.data# 目标向量(房价)
y = boston.target-
涉及算法: 线性回归、岭回归、随机森林。
2、California Housing 数据集
-
介绍: 包含加利福尼亚州地区的住房价格数据。
-
获取方式: Scikit-learn内置数据集。
from sklearn.datasets import fetch_california_housing# 使用fetch_california_housing函数加载数据集
california_housing = fetch_california_housing()# 特征矩阵
X = california_housing.data# 目标向量(房屋价值的中位数)
y = california_housing.target-
涉及算法: 线性回归、决策树、支持向量机。
3、Diabetes 数据集
-
介绍: 包含糖尿病患者的医疗数据,用于预测糖尿病进展。
-
获取方式: Scikit-learn内置数据集。
from sklearn.datasets import load_diabetes# 使用load_diabetes函数加载数据集
diabetes = load_diabetes()# 特征矩阵
X = diabetes.data# 目标向量(糖尿病进展指数)
y = diabetes.target-
涉及算法: 线性回归、支持向量机、决策树。
4、Wine Quality 数据集
-
介绍: 包含红葡萄酒和白葡萄酒的化学分析数据,用于预测质量评分。
-
获取链接:https://archive.ics.uci.edu/ml/datasets/wine+quality
-
涉及算法: 线性回归、决策树、随机森林。
5、Airlines 数据集
-
介绍: 包含航班延误和性能数据。
-
获取链接:https://www.transtats.bts.gov/DL_SelectFields.asp
-
涉及算法: 线性回归、时间序列分析。
6、Energy Efficiency 数据集
-
介绍: 包含建筑能源效率的数据。
-
获取链接:https://archive.ics.uci.edu/ml/datasets/Energy+efficiency
-
涉及算法: 线性回归、岭回归、支持向量机。
7、Bike Sharing 数据集
-
介绍: 包含自行车租赁数据,涉及天气和日期信息。
-
获取链接: https://archive.ics.uci.edu/ml/datasets/Bike+Sharing+Dataset
-
涉及算法: 线性回归、决策树、随机森林。
8、Life Expectancy 数据集
-
介绍: 包含各国生活预期和卫生数据。
-
获取链接: https://www.kaggle.com/kumarajarshi/life-expectancy-who
-
涉及算法: 线性回归、决策树、随机森林。
9、NYC Yellow Taxi 数据集
-
介绍: 包含纽约市黄色出租车的行程数据。
-
获取链接: https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page
-
涉及算法: 时间序列分析、线性回归、岭回归。
10、Forest Fires 数据集
-
介绍: 包含葡萄牙森林火灾数据,用于预测火灾规模。
-
获取链接:https://archive.ics.uci.edu/ml/datasets/Forest+Fires
-
涉及算法:线性回归、决策树、随机森林。
分类问题
11、Iris 数据集
-
介绍: 包含三种不同种类的鸢尾花的测量数据。
-
获取方式: Scikit-learn内置数据集。
from sklearn.datasets import load_iris# 使用load_iris函数加载数据集
iris = load_iris()# 特征矩阵
X = iris.data# 目标向量(鸢尾花的类别)
y = iris.target-
涉及算法: 决策树、支持向量机、k-最近邻算法。
12、Breast Cancer 数据集
-
介绍: 用于分类乳腺肿瘤是否为恶性或良性。
-
获取链接:https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+%28Diagnostic%29
-
涉及算法: 逻辑回归、支持向量机、决策树。
13、Wine 数据集
-
介绍: 包含三个不同种类的葡萄酒的化学分析数据。
-
获取链接:https://archive.ics.uci.edu/ml/datasets/wine
-
涉及算法: 主成分分析(PCA)、支持向量机、k-最近邻算法。
图像分类
14、MNIST 数据集
-
介绍: 包含手写数字图像数据集。
-
获取链接:http://yann.lecun.com/exdb/mnist/
-
涉及算法: 卷积神经网络(CNN)、深度学习。
15、CIFAR-10 数据集
-
介绍: 包含10个不同类别的小图像数据集。
-
获取链接: https://www.cs.toronto.edu/~kriz/cifar.html
-
涉及算法: 卷积神经网络(CNN)、深度学习。
16、ImageNet 数据集
-
介绍: 包含数百万张图像,涵盖数千个不同类别。
-
获取链接: http://www.image-net.org/
-
涉及算法: 卷积神经网络(CNN)、迁移学习。
17、Fashion MNIST 数据集
-
介绍: 与MNIST类似,但包含了10个不同种类的时尚物品的图像。
-
获取链接:https://github.com/zalandoresearch/fashion-mnist
-
涉及算法:卷积神经网络(CNN)、多层感知机(MLP)。
18、Dogs vs、Cats 数据集
-
介绍: 包含狗和猫的图像,用于图像分类任务。
-
获取链接:https://www.kaggle.com/c/dogs-vs-cats
-
涉及算法:卷积神经网络(CNN)、迁移学习。
文本情感分析
19、IMDb 电影评分数据集
-
介绍: 包含电影的评分和评论数据。
-
获取链接:https://www.imdb.com/interfaces/
-
涉及算法: 自然语言处理模型、推荐系统、情感分析。
20、Yelp 数据集
-
介绍: 包含用户对商家的评论和评分数据。
-
获取链接:https://www.yelp.com/dataset
-
涉及算法: 自然语言处理模型、推荐系统、卷积神经网络。
21、Amazon 评论数据集
-
介绍: 包含亚马逊产品的评论和评分数据。
-
获取链接:https://registry.opendata.aws/amazon-reviews/
-
涉及算法: 自然语言处理模型、推荐系统、情感分析。
22、Spam SMS 数据集
-
介绍: 包含垃圾短信和非垃圾短信的文本数据。
-
获取链接:https://www.kaggle.com/datasets/uciml/sms-spam-collection-dataset
-
涉及算法: 自然语言处理模型、朴素贝叶斯、支持向量机。
23、Twitter 情感分析数据集
-
介绍: 包含推文的情感分析数据。
-
获取链接:http://help.sentiment140.com/for-students
-
涉及算法: 自然语言处理模型、情感分析。
自然语言处理
24、Penn Treebank 数据集
-
介绍: 包含句子和标签,用于语法分析和自然语言处理任务。
-
获取链接:https://catalog.ldc.upenn.edu/LDC99T42
-
涉及算法: 循环神经网络(RNN)、长短时记忆网络(LSTM)。
25、Gutenberg 电子书数据集
-
介绍: 包含大量文学作品的文本数据,可用于文本分析和自然语言处理。
-
获取链接:http://www.gutenberg.org/
-
涉及算法: 文本分析、主题建模、情感分析。
26、20 Newsgroups 数据集
-
介绍: 包含新闻组文章的文本数据,用于文本分类和主题建模。
-
获取方式: Scikit-learn内置数据集。
from sklearn.datasets import fetch_20newsgroups# 使用fetch_20newsgroups函数加载数据集
newsgroups = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))# 文本数据
X = newsgroups.data# 目标向量(新闻组类别)
y = newsgroups.target-
涉及算法: 朴素贝叶斯、支持向量机、自然语言处理模型。
自动驾驶
27、Udacity Self-Driving Car 数据集
-
介绍: 包含来自Udacity自动驾驶汽车的传感器数据。
-
获取链接:https://github.com/udacity/self-driving-car
-
涉及算法: 深度学习、卷积神经网络、循环神经网络。
28、KITTI Vision Benchmark Suite 数据集
-
介绍: 包含来自自动驾驶测试车的图像、点云和GPS数据。
-
获取链接:http://www.cvlibs.net/datasets/kitti/
-
涉及算法: 计算机视觉、深度学习、激光雷达处理。
金融类
29、LendingClub 数据集
-
介绍: 包含借贷交易的数据,用于信用风险评估。
-
获取链接:https://www.kaggle.com/datasets/wordsforthewise/lending-club
-
涉及算法: 逻辑回归、随机森林、梯度提升。
30、NYC Taxi Trip 数据集
-
介绍: 包含纽约市出租车行程数据,用于预测乘客付费。
-
获取链接:https://www.kaggle.com/c/nyc-taxi-trip-duration
-
涉及算法: 回归分析、时间序列分析、深度学习。
最后
最后聊一聊,获取一些数据集可能需要注册或符合特定使用条件。此外,对于图像分类、文本情感分析和自然语言处理等任务,还可以使用深度学习技术,如卷积神经网络(CNN)、循环神经网络(RNN)和预训练模型(如BERT)。对于自动驾驶任务,需要结合计算机视觉和传感器数据处理。金融领域的数据集通常用于建立量化金融模型和风险分析。
相关文章:

纯干货分享 机器学习7大方面,30个硬核数据集
在刚刚开始学习算法的时候,大家有没有过这种感觉,最最重要的那必须是算法本身! 其实在一定程度上忽略了数据的重要性。 而事实上一定是,质量高的数据集可能是最重要的! 数据集在机器学习算法项目中具有非常关键的重…...

算法训练营day46
一、单词拆分 元素无重可复选 base case is.length return true,遍历到了最后, 因为ilen s.length,len初始值为1,那么i1 s.length,那么i s.lenth -1 也就是最后一个字符位置 dp(s,i)函数定义:返回 s[i…] 是否能够…...

推荐五个线上兼职,在家也能轻松日入百元,适合上班族和全职宝妈
在这个瞬息万变的时代,你是否也曾考虑过在繁忙的工作之外,寻找一份兼职副业来补贴家用,同时保持生活的多样性?别急,现在就让我为你揭秘五个可靠的日结线上兼职岗位,助你轻松迈向财务自由之路! 一…...
Python_文件操作_学习
目录 一、关于文件的打开和关闭 1. 文件的打开 2.文件的关闭 二、文件的读取 1. 文件的读_r 2. 使用readline 3.使用readlines 三、文件的写入 1. 文本的新建写入 2.文本的追加写入 四、文件的删除和重命名 1.文件的重命名 2.文件的删除 五、文件的定位读写 1.t…...

Leetcode 3154. Find Number of Ways to Reach the K-th Stair
Leetcode 3154. Find Number of Ways to Reach the K-th Stair 1. 解题思路2. 代码实现 题目链接:3154. Find Number of Ways to Reach the K-th Stair 1. 解题思路 这一题思路上就是一个动态规划,我们只需要确定一下运行的终止条件,然后写…...

Vue3/Vite引入EasyPlayer.js播放H265视频错误的问题
一、引入EasyPlayer.js github链接:GitHub - EasyDarwin/EasyPlayer.js: EasyPlayer.js H5播放器 将demo/html目录下的 EasyPlayer-element.min.js、EasyPlayer-lib.min.js、EasyPlayer.wasm、jquery.min.js 复制到vue3工程的public目录下,注意,vue3 vite的index.html文件…...

CentOS 7安装alertmanager
说明:本文介绍如何在CentOS 7安装alertmanager; Step1:下载安装包 访问Github仓库,下载对应版本的alertmanager安装包 https://github.com/prometheus/alertmanager/releases 如何查看自己系统的信息,可参考下图中的…...
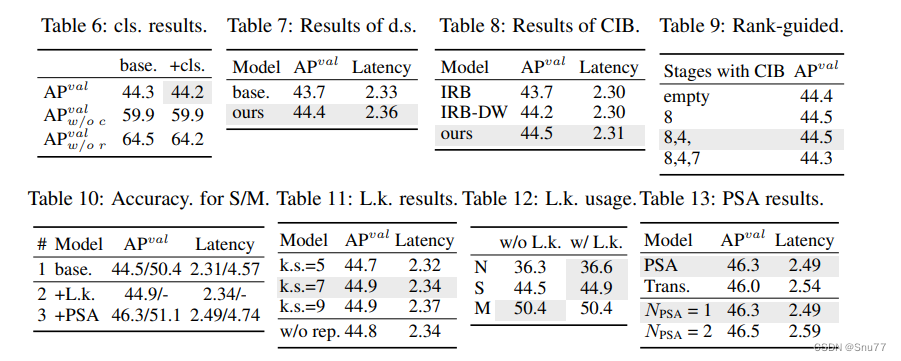
YOLOv10详细解读 | 一文带你深入了解yolov10的创新点(附网络结构图 + 举例说明)
前言 Hello大家好,我是Snu77,继YOLOv9发布时间没有多久,YOLOv10就紧接着发布于2024.5.23号(不得不感叹YOLO系列的发展速度,但要纠正大家的观点就是不是最新的就一定最好)! 本文给大家带来的是…...

【openlayers系统学习】3.5colormap详解(颜色映射)
五、colormap详解(颜色映射) colormap 包是一个很好的实用程序库,用于创建颜色图。该库已作为项目的依赖项添加(1.7美化(设置style))。要导入它,请编辑 main.js 以包含以下行…...
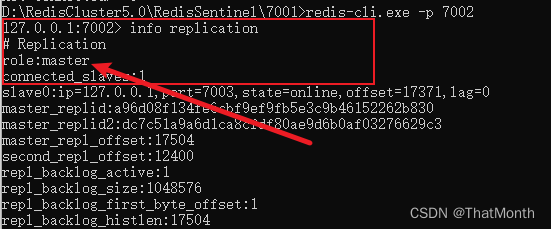
Redis教程(十五):Redis的哨兵模式搭建
一、搭建Redis一主二从 分别复制三份Redis工作文件夹,里面内容一致 接着修改7002的配置文件,【redis.windows-service.conf】 port 7002 改成 port 7002 slaveof 127.0.0.1 7001 7003也同样修改 port 7003 slaveof 127.0.0.1 7001 这样就指定了700…...

【C语言】8.C语言操作符详解(3)
文章目录 10.操作符的属性:优先级、结合性10.1 优先级10.2 结合性 11.表达式求值11.1 整型提升11.2 算术转换11.3 问题表达式解析11.3.1 表达式111.3.2 表达式211.3.3 表达式311.3.4 表达式411.3.5 表达式5: 11.4 总结 10.操作符的属性:优先级、结合性 …...

离线初始化k8s
导出和导入所有必要的 Kubernetes 镜像,使用阿里云作为源。 在能访问外网的机器上拉取镜像 首先,在有外网访问的机器上运行以下命令来拉取所有 Kubernetes v1.29.5 版本需要的镜像: kubeadm config images pull --image-repository regist…...
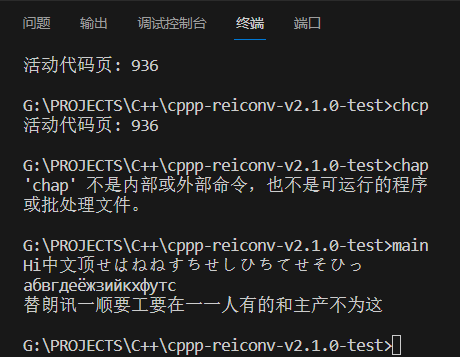
C++字符编码 cppp-reiconv库使用详解
经常写一些控制台小程序,常常会遇到输出中文乱码的问题,在windwos下可以使用MultiByteToWideChar转换字符编码,但跨平台就需要cppp-reiconv这样的第三方字符编码处理库,且开源。 一、下载cppp-reiconv库的源码和静/动态库 GitHu…...
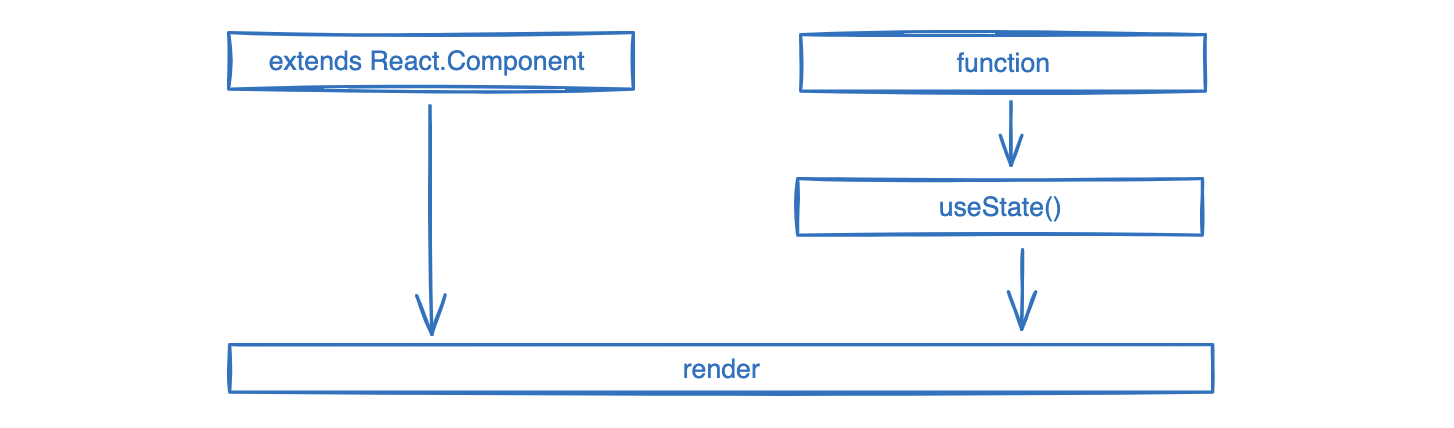
通过继承React.Component创建React组件-5
在React中,V16版本之前有三种方式创建组件(createClass() 被删除了),之后只有两种方式创建组件。这两种方式的组件创建方式效果基本相同,但还是有一些区别,这两种方法在体如下: 本节先了解下用extnds Reac…...
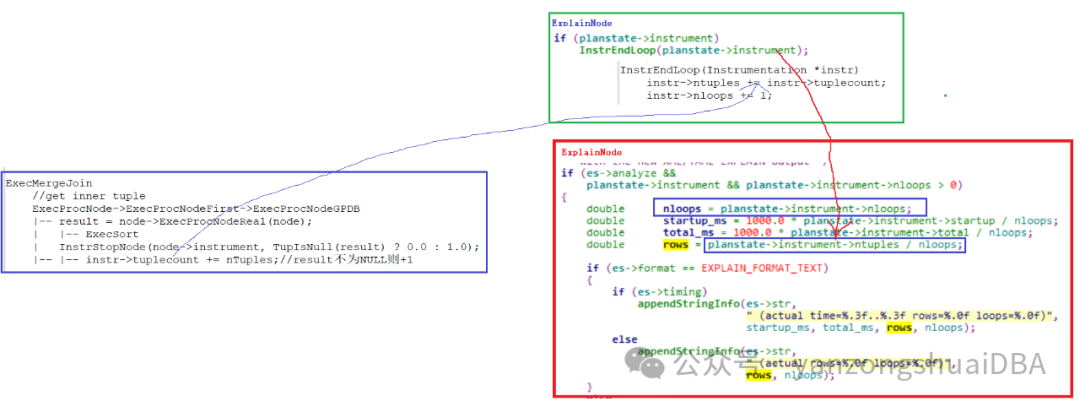
PgSQL内核机制 - 算子执行统计元组个数
PgSQL内核机制 - 算子执行统计元组个数 我们在执行explain analyze观察执行计划执行情况时,时常通过每个算子实际执行结果来分析SQL的执行,其中有一项“rows XXX”表示执行的行数(这里姑且先认为是执行的真实行数)。但有些场景下…...

Ubuntu/Linux 安装Paraview
文章目录 0. 卸载已有ParaView1. 安装ParaView1.1 下载后安装 2.进入opt文件夹改名3. 更改启动项4. 创建硬链接5. 添加桌面启动方式6. 即可使用 0. 卸载已有ParaView YUT 1. 安装ParaView https://www.paraview.org/ 1.1 下载后安装 找到下载的文件夹,文件夹内…...

内存泄漏及其解决方法
1. 系统崩溃前的现象 垃圾回收时间延长:从原本的约10ms增长至50ms,Full GC时间也由0.5s增加至4-5s。Full GC频率增加:最短间隔可缩短至1分钟内发生一次。年老代内存持续增长:即使经过Full GC,年老代内存未见明显释放。…...

Java进阶学习笔记13——抽象类
认识抽象类: 当我们在做子类共性功能抽取的时候,有些方法在父类中并没有具体的体现,这个时候就需要抽象类了。在Java中,一个没有方法体的方法应该定义为抽象方法,而类中如果有抽象方法,该类就定义为抽象类…...

【Docker学习】深入研究命令docker exec
使用docker的过程中,我们会有多重情况需要访问容器。比如希望直接进入MySql容器执行命令,或是希望查看容器环境,进行某些操作或访问。这时就会用到这个命令:docker exec。 命令: docker container exec 描述&#x…...

C语言中的文件操作
前言 嗨,我是firdawn,在本章中我们将介绍,文件的概念,文件的打开和关闭,在篇末我们将介绍文件缓冲区的作用,下面是本章的思维导图,接下来,让我们开始今天的学习吧! 一…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

Hindsight测试策略:单元测试、集成测试和端到端测试
Hindsight测试策略:单元测试、集成测试和端到端测试 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight作为一款专注于Agent Memory的开源项目,其可…...

Matlab,plot绘图如何添加边框
matlab生成的图——编辑(E)——坐标区属性(A)——框样式——Box,勾选效果:...

因果推断与机器学习融合:量化分析社会运动中镇压与抗议的动态关系
1. 项目概述:当数据科学遇见社会运动如果你研究过社会运动,尤其是那些看似突然爆发、席卷全国的抗议浪潮,你可能会被一个核心问题困扰:国家机器的镇压,究竟是浇灭火焰的冷水,还是火上浇油的催化剂ÿ…...
)
ArduPilot飞行模式实战:从代码角度看Stabilize、Acro、Loiter模式如何切换(附避坑指南)
ArduPilot飞行模式深度解析:从状态机到实战避坑指南 在开源飞控领域,ArduPilot以其强大的飞行模式系统著称。不同于普通用户只需了解模式功能,开发者更需要掌握模式切换的底层机制——这直接关系到飞行安全与二次开发效率。本文将带您深入Sta…...

第2章 谁在危险中——被AI替代的五类程序员
第2章 谁在危险中——被AI替代的五类程序员 核心问题:哪些程序员最容易被AI替代?背后的原因是什么? 2.1 问题定义:一场正在发生的结构性塌陷 2.1.1 数据不会说谎 2026年1月12日,Ravio发布了一份让整个科技圈沉默的报告:过去一年,初级开发者岗位招聘量暴跌73%。 不是…...

告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南
告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南你是否已经厌倦了Windows系统越来越慢的启动速度、频繁的后台更新和资源占用?当你的电脑开始频繁卡顿,或许该考虑给系统来一次"减负"了。Kubuntu 22.04 L…...

Unity中实现深度遮挡:LingBot-Depth实战接入与优化
1. 这不是“加个插件就完事”的AR效果——为什么LingBot-Depth在Unity里值得专门写一篇实战教程你肯定见过那种AR应用:虚拟椅子摆在真实地板上,但当你绕到椅子后面,它依然完整显示,完全无视身后那堵真实的墙;或者一只3…...
3步高效解决TranslucentTB任务栏透明化难题:完整配置指南
3步高效解决TranslucentTB任务栏透明化难题:完整配置指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否厌倦了Window…...

从零开始的Linux#2 vim编辑器
介绍vi\vim是Linux中最经典的文本编辑器,vim是vi的全面升级版本,我们后面只用vim通过vim编辑器编辑文件,需要使用命令vim 文件路径如果文件路径表示的文件不存在,那么此命令会用于编辑新文件;如果存在则编辑已有文件模…...