kafka 案例
kafka 案例
- 目录
- 概述
- 需求:
- 设计思路
- 实现思路分析
- 1.kafka案例_API 带回调函数的生产者
- 2.kafka案例_API生产者分区策略测试
- 3.kafka案例_自定义分区的生产者
- 4.kafka案例_API同步发送生产者
- 5.kafka案例_API简单消费者
- 5.kafka案例_API消费者重置offset
- 参考资料和推荐阅读
Survive by day and develop by night.
talk for import biz , show your perfect code,full busy,skip hardness,make a better result,wait for change,challenge Survive.
happy for hardess to solve denpendies.
目录
概述
需求:
设计思路
实现思路分析
1.kafka案例_API 带回调函数的生产者
以下是一个使用 Kafka 的 Java 生产者带回调函数的案例:
import org.apache.kafka.clients.producer.*;import java.util.Properties;public class ProducerExample {public static void main(String[] args) {Properties properties = new Properties();properties.put("bootstrap.servers", "localhost:9092");properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(properties);ProducerRecord<String, String> record = new ProducerRecord<>("topic-name", "key", "value");producer.send(record, new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (exception == null) {System.out.println("消息发送成功!");} else {System.out.println("消息发送失败:" + exception.getMessage());}}});producer.close();}
}
请注意替换 bootstrap.servers 的值为 Kafka 服务器的地址和端口,并替换 topic-name、key 和 value 分别为实际使用的主题、键和值。
在这个案例中,我们使用 KafkaProducer 类创建一个 Kafka 生产者。然后,通过创建一个 ProducerRecord 对象,我们指定了要发送到的主题、键和值。
然后,我们调用 producer.send() 方法来发送消息。此方法接受一个 Callback 参数,该参数用于在消息发送完成后执行回调函数。在回调函数中,我们可以检查发送结果并采取相应的操作。
最后,我们调用 producer.close() 方法来关闭生产者。
2.kafka案例_API生产者分区策略测试
在Kafka中,可以使用API生产者分区策略来决定将消息发送到哪个分区。以下是一个展示如何使用API生产者分区策略的示例代码。
首先,创建一个新的Java类,例如ProducerPartitionStrategyTest.java,并导入Kafka相关的依赖项。
import org.apache.kafka.clients.producer.*;import java.util.Properties;
接下来,定义一个自定义的Partitioner类,用于实现分区策略。在这个例子中,我们将根据消息的键来决定分区。如果键为偶数,则将消息发送到分区0;如果键为奇数,则将消息发送到分区1。
class CustomPartitioner implements Partitioner {@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {int numPartitions = cluster.partitionCountForTopic(topic);int partition = 0;try {int keyValue = Integer.parseInt(key.toString());if (keyValue % 2 == 0) {partition = 0;} else {partition = 1;}} catch (NumberFormatException e) {partition = Math.abs(key.hashCode() % numPartitions);}return partition;}@Overridepublic void close() {// 不做任何操作}@Overridepublic void configure(Map<String, ?> configs) {// 不做任何操作}
}
然后,在主方法中创建一个Producer并设置自定义分区策略。
public class ProducerPartitionStrategyTest {public static void main(String[] args) {// 配置Kafka生产者Properties properties = new Properties();properties.put("bootstrap.servers", "localhost:9092");properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("partitioner.class", "com.example.CustomPartitioner");// 创建Kafka生产者Producer<String, String> producer = new KafkaProducer<>(properties);// 发送消息for (int i = 0; i < 10; i++) {String key = String.valueOf(i);String value = "Message " + i;ProducerRecord<String, String> record = new ProducerRecord<>("topic", key, value);producer.send(record, new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (exception != null) {System.err.println("Error producing message: " + exception.getMessage());} else {System.out.println("Message sent to partition " + metadata.partition() + ", offset " + metadata.offset());}}});}// 关闭生产者producer.close();}
}
在以上示例中,我们首先配置了Kafka生产者的一些属性,例如Kafka服务器的地址、键和值的序列化程序以及分区策略。然后,我们创建了一个Kafka生产者,并使用自定义分区策略将消息发送到Kafka集群中。
在发送消息的循环中,我们创建了一个ProducerRecord对象,它包含要发送的消息的主题、键和值。然后,我们使用send()方法将消息发送到Kafka集群,并使用回调函数处理发送结果。
最后,我们关闭了生产者。
运行以上代码后,你将会看到消息被发送到正确的分区,并打印出消息的分区和偏移量的信息。
这就是一个简单的演示如何使用API生产者分区策略的例子。你可以根据自己的需求来实现自定义的分区策略,并将消息发送到合适的分区中。
3.kafka案例_自定义分区的生产者
自定义分区的生产者示例代码:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.Random;public class CustomPartitionProducer {public static void main(String[] args) {// Kafka 服务器地址String bootstrapServers = "localhost:9092";// 主题名称String topic = "custom-partition-topic";// 创建生产者配置Properties props = new Properties();props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 创建自定义分区器props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class.getName());// 创建生产者KafkaProducer<String, String> producer = new KafkaProducer<>(props);// 发送消息到自定义分区Random random = new Random();for (int i = 0; i < 10; i++) {String key = "key" + i;String value = "value" + i;producer.send(new ProducerRecord<>(topic, key, value));System.out.println("Sent message: key=" + key + ", value=" + value);}// 关闭生产者producer.close();}public static class CustomPartitioner implements org.apache.kafka.clients.producer.Partitioner {@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();// 这里自定义分区逻辑// 根据key的尾数来决定消息被发送到哪个分区int partition = Integer.parseInt(key.toString().substring(key.toString().length() - 1)) % numPartitions;System.out.println("Custom partitioner: topic=" + topic + ", key=" + key + ", partition=" + partition);return partition;}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}}
}
上面的代码示例首先创建一个自定义分区器CustomPartitioner,然后在生产者配置中指定该分区器类:
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class.getName());
在自定义分区器中,根据key的尾数来决定消息被发送到哪个分区:
int partition = Integer.parseInt(key.toString().substring(key.toString().length() - 1)) % numPartitions;
然后启动生产者,发送消息到指定的主题。每条消息的key都是以数字结尾的字符串,根据key的尾数来选择分区。输出中会打印出消息的详细信息,包括主题、key和分区信息。
4.kafka案例_API同步发送生产者
下面是使用Kafka客户端库进行API同步发送的一个示例:
import org.apache.kafka.clients.producer.*;import java.util.Properties;public class KafkaProducerExample {public static void main(String[] args) {String bootstrapServers = "localhost:9092";String topic = "test-topic";String key = "key1";String value = "value1";// 配置Kafka生产者Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 创建Kafka生产者实例Producer<String, String> producer = new KafkaProducer<>(props);// 创建消息实例ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);try {// 发送消息并等待返回结果RecordMetadata metadata = producer.send(record).get();System.out.println("消息发送成功,Topic: " + metadata.topic() +", Partition: " + metadata.partition() +", Offset: " + metadata.offset());} catch (Exception e) {System.out.println("消息发送失败:" + e.getMessage());} finally {// 关闭Kafka生产者producer.close();}}
}
这个示例使用了Kafka的Java客户端库,并创建了一个Kafka生产者实例。代码中设置了Kafka服务器的地址、要发送的主题、消息的键和值。还配置了键和值的序列化器为StringSerializer。
然后,创建了一个ProducerRecord实例来包装要发送的消息。通过调用producer.send(record).get()方法发送消息并等待返回结果。发送成功后,通过返回的RecordMetadata对象获取到消息的元数据,包括发送到的Topic、Partition和Offset。
最后,关闭Kafka生产者。
5.kafka案例_API简单消费者
以下是一个简单的Kafka案例,使用Kafka的Java API实现一个简单的消费者。
首先,需要安装Kafka并启动Kafka服务。然后,创建一个Kafka消费者来消费指定的主题。
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.util.Collections;
import java.util.Properties;public class SimpleConsumer {public static void main(String[] args) {// Kafka broker的地址String bootstrapServers = "localhost:9092";// 消费者组的IDString groupId = "test-group";// 要消费的主题String topic = "test-topic";// 创建Kafka消费者的配置Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 创建Kafka消费者Consumer<String, String> consumer = new KafkaConsumer<>(props);// 订阅主题consumer.subscribe(Collections.singletonList(topic));// 消费消息while (true) {ConsumerRecords<String, String> records = consumer.poll(1000);// 处理每条消息records.forEach(record -> {System.out.println("Received message: " + record.value());});}}
}
在这个例子中,首先定义了Kafka broker的地址、消费者组的ID和要消费的主题。然后,创建了一个Kafka消费者的配置,并设置了必要的属性。然后,创建了一个Kafka消费者,并使用subscribe()方法订阅了指定的主题。最后,使用poll()方法从Kafka集群拉取消息,并使用forEach()方法对每条消息进行处理。
运行这个消费者应用程序,它将开始消费指定主题的消息并打印出来。
注意:这只是一个简单的Kafka消费者示例,没有处理异常或实现自动提交偏移量。在实际应用中,需要根据具体需求添加更多的处理逻辑。
5.kafka案例_API消费者重置offset
要在Java中重置Kafka消费者的偏移量(offset),您可以使用以下代码片段:
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;import java.util.Arrays;
import java.util.Properties;public class ConsumerOffsetResetExample {public static void main(String[] args) {String topic = "your-topic";String bootstrapServers = "localhost:9092";String groupId = "your-group-id";// 创建Kafka消费者配置Properties properties = new Properties();properties.setProperty("bootstrap.servers", bootstrapServers);properties.setProperty("group.id", groupId);properties.setProperty("enable.auto.commit", "false"); // 禁用自动提交偏移量// 创建Kafka消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);// 订阅主题consumer.subscribe(Arrays.asList(topic));// 将偏移量重置到最早的可用位置consumer.seekToBeginning(consumer.assignment());// 或者将偏移量重置到最新的可用位置// consumer.seekToEnd(consumer.assignment());// 处理消息try {while (true) {// 拉取消息// ConsumerRecord<String, String> record = consumer.poll(Duration.ofMillis(100)).iterator().next();// 处理消息// ...// 手动提交偏移量// consumer.commitSync();}} finally {// 关闭Kafka消费者consumer.close();}}
}
在上面的代码中,我们使用seekToBeginning方法将偏移量重置为最早的可用位置。您还可以使用seekToEnd方法将偏移量重置为最新的可用位置。请根据您的需求选择适当的方法。
参考资料和推荐阅读
参考资料
官方文档
开源社区
博客文章
书籍推荐
- 暂无
欢迎阅读,各位老铁,如果对你有帮助,点个赞加个关注呗!同时,期望各位大佬的批评指正~,如果有兴趣,可以加文末的交流群,大家一起进步哈
相关文章:

kafka 案例
kafka 案例 目录概述需求: 设计思路实现思路分析1.kafka案例_API 带回调函数的生产者2.kafka案例_API生产者分区策略测试3.kafka案例_自定义分区的生产者4.kafka案例_API同步发送生产者5.kafka案例_API简单消费者5.kafka案例_API消费者重置offset 参考资料和推荐阅读…...

别被“涨价“带跑,性价比才是消费真理
文章来源:全食在线 “再不好好赚钱,连方便面也吃不起了。”这是昨天在热搜下,一位网友的留言。而热搜的内容,正是康师傅方便面即将涨价的消息。 01 传闻初现 昨天上午,朋友圈就有人放出康师傅方便面要涨价的消息&am…...

GEE深度学习——使用Tensorflow进行神经网络DNN土地分类
Tensorflow TensorFlow是一个开源的深度学习框架,由Google开发和维护。它提供了一个灵活的框架来构建和训练各种机器学习模型,尤其是深度神经网络模型。 TensorFlow的主要特点包括: 1. 它具有高度的灵活性,可以用于训练和部署各种类型的机器学习模型,包括分类、回归、聚…...
)
死锁示例(python、go)
Thread 1首先获取了资源A,然后尝试获取资源B,但此时资源B已经被Thread 2获取,因此Thread 1会一直等待。而Thread 2也类似,首先获取资源B,然后尝试获取资源A,但此时资源A已经被Thread 1获取,因此…...
)
Spring Cloud 面试题(五)
1. Eureka的自我保护模式是什么? Eureka的自我保护模式是一种应对网络异常的安全保护措施,旨在防止因网络分区或其他异常情况导致服务实例被错误地注销。当Eureka Server在短时间内丢失过多的客户端心跳时,会触发自我保护机制。以下是自我保…...
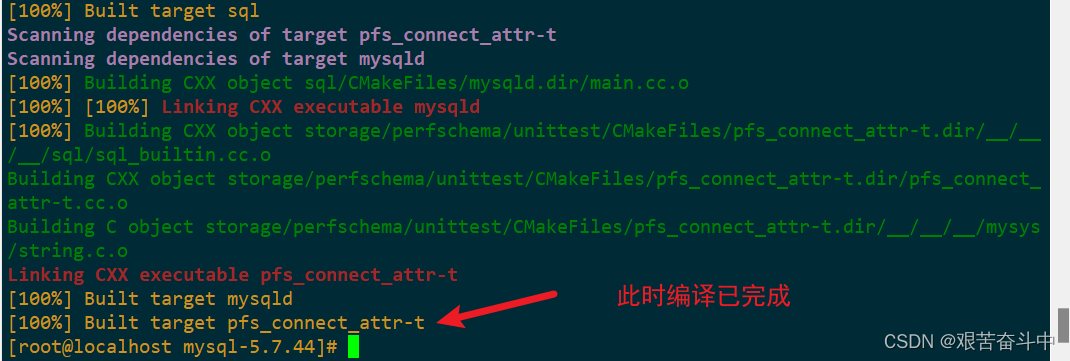
源码编译安装LAMP
1.LAMP介绍 LAMP架构是目前成熟的企业网站应用模式之一,指的是协同工作的一整套系统和相关软件,能够提供动态Web站点服务及其应用开发环境。LAMP是一个缩写词,具体包括Linux操作系统、Apache网站服务器、MySQL数据库服务器、PHP(…...
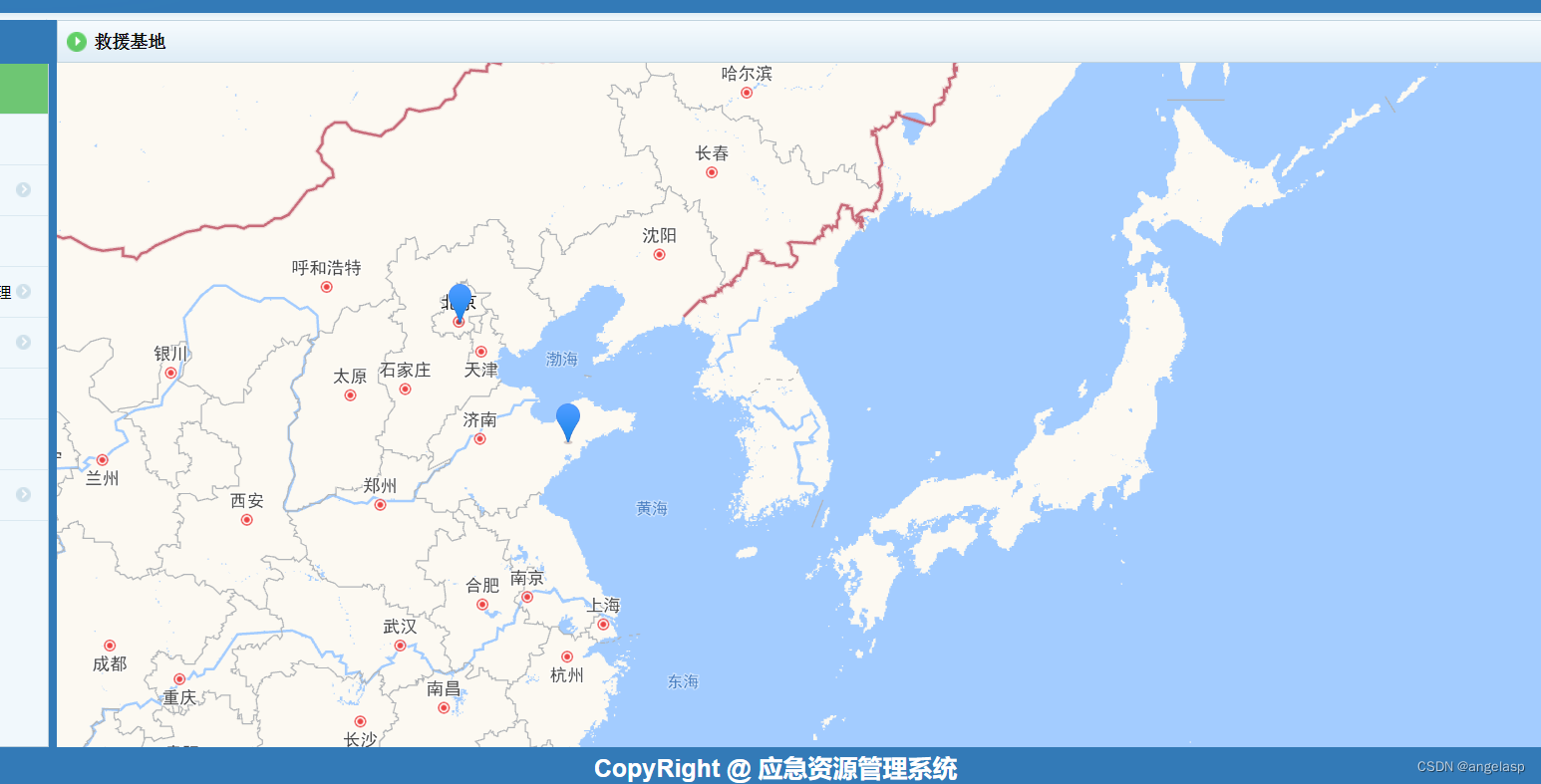
html5网页-浏览器中实现高德地图定位功能
介绍 HTML5是当前Web开发中最常用的技术之一,而地图应用又是其中一个非常常见的需求。高德地图是国内最受欢迎的地图服务提供商之一,他们提供了一系列的API,方便开发者在自己的网站或应用中集成地图功能。 接下来我们如何使用HTML5浏览器和高…...
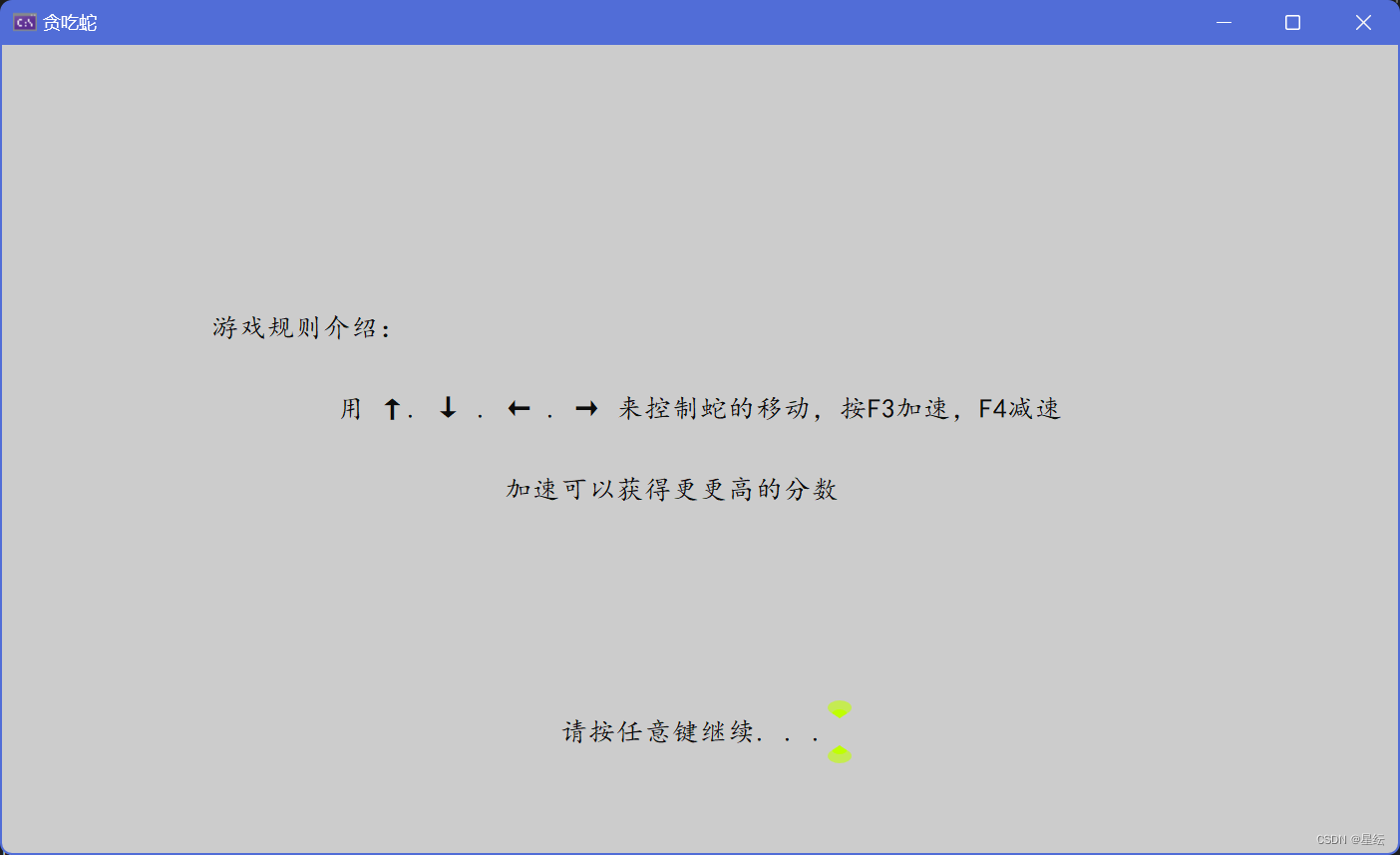
C从零开始实现贪吃蛇大作战
个人主页:星纭-CSDN博客 系列文章专栏 : C语言 踏上取经路,比抵达灵山更重要!一起努力一起进步! 有关Win32API的知识点在上一篇文章: 目录 一.地图 1.控制台基本介绍 2.宽字符 1.本地化 2.类项 3.setlocale函…...

国内外相机在LabVIEW图像处理的对比
概述 本文对比国内外相机在LabVIEW进行图像处理的区别,探讨各自的特点。国内相机如大恒和海康威视,具有较高性价比和本地化支持;国外品牌如Basler和FLIR则以高性能和稳定性著称。两者在驱动兼容性、图像质量和技术支持方面各有优势。 详细对…...

第四十五天 | 322.零钱兑换
题目:322.零钱兑换 尝试解答: 1.确定dp[j]含义:装满容量为j的背包所需要放的硬币个数为dp[j]; 2.动态转移方程:dp[j] dp[j - coins[i]] 1; 3.遍历顺序:本题应该为组合类题目,不考虑装入的顺序&#x…...

3D 生成重建011-LucidDreamer 优化SDS过平滑结果的一种探索
3D 生成重建011-LucidDreamer 优化SDS过平滑结果的一种探索 文章目录 0论文工作1论文方法2 效果 0论文工作 文本到3D生成的最新进展标志着生成模型的一个重要里程碑,为在各种现实场景中创建富有想象力的3D资产打开了新的可能性。虽然最近在文本到3D生成方面的进展…...

ES6 笔记04
01 异步函数的使用 es6推出了一种按照顺序执行的异步函数的方法 async 异步函数 async异步函数可以解决promise封装异步代码,调用时一直then链式编程时比较麻烦的问题 定义异步函数: async function 函数名(){ await 表达式1或者函数的调用1 await 表达式2或者函数的调用2 ...…...
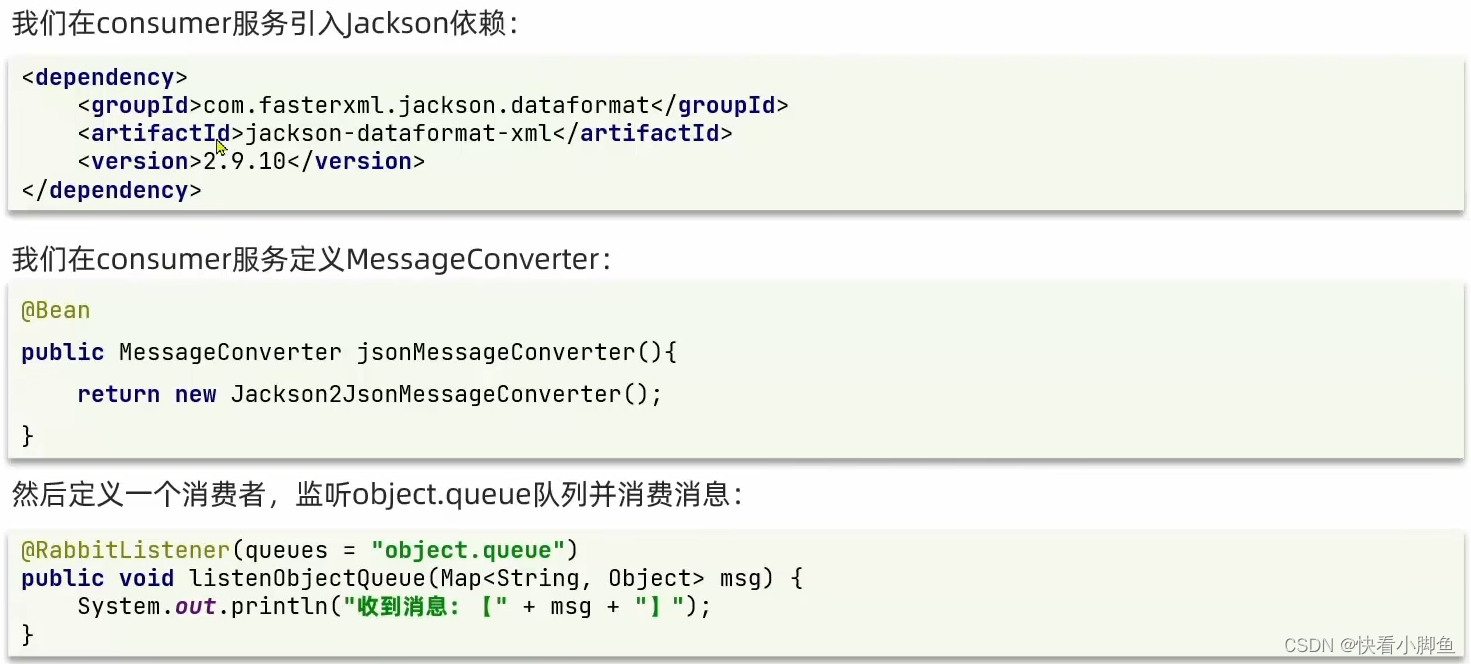
中间件-------RabbitMQ
同步和异步 异步调用 MQ MQ优势:①服务解耦 ②异步调用 ③流量削峰 结构 消息模型 RabbitMQ入门案例,实现消息发送和消息接收 生产者: public class PublisherTest {Testpublic void testSendMessage() throws IOException, TimeoutExce…...

flink Data Source数据源
flink Data Source数据源 Source 并行度 非并行:并行度只能为1 并行 基于集合的Source fromElements package com.pxj.sx.flink; import org.apache.flink.configuration.Configuration; import org.apache.flink.configuration.RestOptions; import org.ap…...

网络七层模型与云计算中的网络服务
网络七层模型,也称为OSI(Open System Interconnection)模型,是由国际标准化组织(ISO)制定的一个概念性框架,用于描述网络通信过程中信息是如何被封装、传输和解封装的。这一模型将复杂的网络通信…...

word一按空格就换行怎么办?word文本之间添加空格就换行怎么办?
如上图,无法在Connection和con之间添加空格,一按空格就会自动换行。 第一步:选中文本,打开段落。 第二步:点击中文版式,勾选允许西文在单词中间换行。 确定之后就解决一按空格就自动换行啦!...

Python 遍历字典的方法,你都掌握了吗
Python中的字典是一种非常灵活的数据结构,它允许通过键来存储和访问值。在处理字典时,经常需要遍历字典中的元素,以下是几种常见的遍历字典的方法。 1. 使用 for 循环直接遍历字典的键 字典的键是唯一的,可以直接通过 for 循环来…...
MySQL 8.4.0 LTS 变更解析:I_S 表、权限、关键字和客户端
↑ 关注“少安事务所”公众号,欢迎⭐收藏,不错过精彩内容~ MySQL 8.4.0 LTS 已经发布 ,作为发版模型变更后的第一个长期支持版本,注定要承担未来生产环境的重任,那么这个版本都有哪些新特性、变更,接下来少…...
LeetCode 124 —— 二叉树中的最大路径和
阅读目录 1. 题目2. 解题思路3. 代码实现 1. 题目 2. 解题思路 二叉树的问题首先我们要想想是否能用递归来解决,本题也不例外,而递归的关键是找到子问题。 我们首先来看看一棵最简单的树,也就是示例 1。这样的一棵树总共有六条路径…...

美甲店会员预约系统管理小程序的作用是什么
女性爱美体现在方方面面,美丽好看的指甲也不能少,市场中美甲店、小摊不少,也跑出了不少连锁品牌,70后到00后,每个层级都有不少潜在客户,商家需要获取和完善转化路径,不断提高品牌影响力与自身内…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...

对比按量计费与Token Plan套餐的实际成本差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按量计费与Token Plan套餐的实际成本差异 在构建和运营基于大模型的应用时,成本控制是一个核心的工程考量。Taotok…...

在数据预处理与分析流水线中集成大模型API进行智能标注与摘要
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在数据预处理与分析流水线中集成大模型API进行智能标注与摘要 对于数据工程师而言,处理海量非结构化文本数据是一项常见…...

前馈补偿技术:用数字预失真驯服放大器非线性失真
1. 项目概述:用前馈补偿驯服放大器失真在音频发烧友和硬件工程师的圈子里,追求“高保真”几乎是一种信仰。我们总希望从扬声器里传出的声音,是录音现场或音乐制作人意图的完美复刻,纤毫毕现,不带一丝杂质。然而&#x…...

为Claude Code配置Taotoken解决账号封禁与Token不足难题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken解决账号封禁与Token不足难题 对于依赖Claude Code进行日常编程辅助的开发者而言,直接使用官…...

Unity场景交互动画工程化实践:触发、动画、物理与渲染四层协同
1. 这不是“加个动画”那么简单:为什么90%的Unity场景交互动画最终显得廉价又生硬? “用 Unity 打造超酷场景交互动画”——这句话在B站、知乎和独立游戏开发群里的出现频率,大概和“三分钟学会Python”差不多。但真正跑完一个完整流程、让玩…...

京东自动购物系统:高效补货监控与智能下单终极指南
京东自动购物系统:高效补货监控与智能下单终极指南 【免费下载链接】Jd-Auto-Shopping 京东商品补货监控及自动下单 项目地址: https://gitcode.com/gh_mirrors/jd/Jd-Auto-Shopping 在电商购物场景中,错过心仪商品的补货时机是每个消费者都可能遇…...

2026年降AI工具处理速度横评:五款主流工具一万字论文处理时长完整数据报告
2026年降AI工具处理速度横评:五款主流工具一万字论文处理时长完整数据报告 拿同一篇论文,用三款工具分别处理,记录了完整检测数据。 结论先说:嘎嘎降AI(www.aigcleaner.com)效果最稳,价格也最…...