Pytorch入门(7)—— 梯度累加(Gradient Accumulation)
1. 梯度累加
- 在训练大模型时,batch_size 最大值往往受限于显存容量上限,当模型非常大时,这个上限可能小到不可接受。梯度累加(Gradient Accumulation)是一个解决该问题的 trick
- 梯度累加的思想很简单,就是时间换空间。具体而言,我们不在每个 batch data 梯度计算后直接更新模型,而是多算几个 batch 后,使用这些 batch 的平均梯度更新模型,从而放大等效 batch_size。如下图所示

- 用公式表示:设 batch size 为 n n n,模型参数为 w \pmb{w} w,样本 i i i 的损失为 l i l_i li,则正常情况下 sgd 参数更新为
w ← w + α ∑ i = 1 n 1 n ∂ l i ∂ w \pmb{w} \leftarrow \pmb{w} + \alpha \sum_{i=1}^n\frac{1}{n}\frac{\partial l_i}{\partial \pmb{w}} w←w+αi=1∑nn1∂w∂li 使用梯度累加时,设累加步长为 m m m(即计算 m m m 个 batch 梯度后用梯度均值更新一次),sgd 更新如下
w ← w + α 1 m ∑ b = 1 m ∑ i = 1 n 1 n ∂ l b i ∂ w = w + α ∑ i = 1 m n 1 m n ∂ l i ∂ w \begin{aligned} \pmb{w} &\leftarrow \pmb{w} + \alpha \frac{1}{m} \sum_{b=1}^m \sum_{i=1}^n\frac{1}{n}\frac{\partial l_{bi}}{\partial \pmb{w}} \\ &= \pmb{w} + \alpha \sum_{i=1}^{mn}\frac{1}{mn} \frac{\partial l_i}{\partial \pmb{w}} \end{aligned} w←w+αm1b=1∑mi=1∑nn1∂w∂lbi=w+αi=1∑mnmn1∂w∂li 可见这等价于使用 batch_size = m n mn mn 进行训练
2. 在 pytorch 中实现梯度累加
2.1 伪代码
- pytorch 使用和 tensor 绑定的自动微分机制。每个 tensor 对象都有
.grad属性存储其中每个元素的梯度值,通过.requires_grad属性控制其是否参与梯度计算。训练模型时,一般通过对标量loss执行loss.backward()自动进行反向传播,以得到计算图中所有 tensor 的梯度。详见 PyTorch入门(2)—— 自动求梯度 - pytorch 中梯度
tensor.grad不会自动清零,而会在每次反向传播过程中自动累加,所以一般在反向传播前把梯度清零
这种设计对于实现梯度累加 trick 是很方便的,我们可以在 batch 计算过程中进行计数,仅在达到计数达到更新步长时进行一次参数更新并清零梯度,即for inputs, labels in data_loader:# forward pass preds = model(inputs)loss = criterion(preds, labels)# clear grad of last batch optimizer.zero_grad()# backward pass, calculate grad of batch dataloss.backward()# update modeloptimizer.step()# batch accumulation parameter accum_iter = 4 # loop through enumaretad batches for batch_idx, (inputs, labels) in enumerate(data_loader):# forward pass preds = model(inputs)loss = criterion(preds, labels)# scale the loss to the mean of the accumulated batch sizeloss = loss / accum_iter # backward passloss.backward()# weights updateif ((batch_idx + 1) % accum_iter == 0) or (batch_idx + 1 == len(data_loader)):optimizer.step()optimizer.zero_grad()
2.2 线性回归案例
- 下面使用来自 经典机器学习方法(1)—— 线性回归 的简单线性回归任务说明梯度累加的具体实现方法
本节代码直接从 jupyter notebook 复制而来,可能无法直接运行!
- 首先生成随机数据构造 dataset
import torch from IPython import display from matplotlib import pyplot as plt import numpy as np import random import torch.utils.data as Data import torch.nn as nn import torch.optim as optim# 生成样本 num_inputs = 2 num_examples = 1000 true_w = torch.Tensor([-2,3.4]).view(2,1) true_b = 4.2 batch_size = 10# 1000 个2特征样本,每个特征都服从 N(0,1) features = torch.randn(num_examples, num_inputs, dtype=torch.float32) # 生成真实标记 labels = torch.mm(features,true_w) + true_b labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float32)# 包装数据集,将训练数据的特征和标签组合 dataset = Data.TensorDataset(features, labels)- 不使用梯度累加技巧,batch size 设置为 40
# 构造 DataLoader batch_size = 40 data_iter = Data.DataLoader(dataset, batch_size, shuffle=False) # shuffle=False 保证实验可比# 定义模型 net = nn.Sequential(nn.Linear(num_inputs, 1))# 初始化模型参数 nn.init.normal_(net[0].weight, mean=0, std=0) nn.init.constant_(net[0].bias, val=0)# 均方差损失函数 criterion = nn.MSELoss()# SGD优化器 optimizer = optim.SGD(net.parameters(), lr=0.01)# 模型训练 num_epochs = 3 for epoch in range(1, num_epochs + 1):epoch_loss = []for X, y in data_iter:# 正向传播,计算损失output = net(X) loss = criterion(output, y.view(-1, 1))# 梯度清零optimizer.zero_grad() # 计算各参数梯度loss.backward()#print('backward: ', net[0].weight.grad)# 更新模型optimizer.step()epoch_loss.append(loss.item()/batch_size)print(f'epoch {epoch}, loss: {np.mean(epoch_loss)}')''' epoch 1, loss: 0.5434057731628418 epoch 2, loss: 0.1914414196014404 epoch 3, loss: 0.06752514398097992 ''' - 使用梯度累加,batch size 设置为 10,步长设为 4,等效 batch size 为 40
# 构造 DataLoader batch_size = 10 accum_iter = 4 data_iter = Data.DataLoader(dataset, batch_size, shuffle=False) # shuffle=False 保证实验可比# 定义模型 net = nn.Sequential(nn.Linear(num_inputs, 1))# 初始化模型参数 nn.init.normal_(net[0].weight, mean=0, std=0) nn.init.constant_(net[0].bias, val=0)# 均方差损失 criterion = nn.MSELoss()# SGD优化器对象 optimizer = optim.SGD(net.parameters(), lr=0.01)# 模型训练 num_epochs = 3 for epoch in range(1, num_epochs + 1):epoch_loss = []for batch_idx, (X, y) in enumerate(data_iter):# 正向传播,计算损失output = net(X) loss = criterion(output, y.view(-1, 1)) loss = loss / accum_iter # 取各个累计batch的平均损失,从而在.backward()时得到平均梯度# 反向传播,梯度累计loss.backward()if ((batch_idx + 1) % accum_iter == 0) or (batch_idx + 1 == len(data_iter)):#print('backward: ', net[0].weight.grad)# 更新模型optimizer.step() # 梯度清零optimizer.zero_grad()epoch_loss.append(loss.item()/batch_size)print(f'epoch {epoch}, loss: {np.mean(epoch_loss)}') ''' epoch 1, loss: 0.5434057596921921 epoch 2, loss: 0.19144139245152472 epoch 3, loss: 0.06752512042224407 '''
- 不使用梯度累加技巧,batch size 设置为 40
- 可以观察到无论 epoch loss 还是
net[0].weight.grad都完全相同,说明梯度累加不影响计算结果
相关文章:
Pytorch入门(7)—— 梯度累加(Gradient Accumulation)
1. 梯度累加 在训练大模型时,batch_size 最大值往往受限于显存容量上限,当模型非常大时,这个上限可能小到不可接受。梯度累加(Gradient Accumulation)是一个解决该问题的 trick梯度累加的思想很简单,就是时…...
day12
第一题 本题我们可以使用以下方法: 方法一: 使用hash表<元素,出现次数>来统计字符串中不同元素分别出现的次数,当某一个元素的次数大于1时,返回false,如果每个元素的出现次数都为1,则返回…...

MySQL技术点合集
目录 1. MySQL目录 2. 验证是否首次登陆方法 3. 在Liunx中使用命令来输入sql语句方法 4. 获取修改密码 5. 关闭密码策略 6. 忘记MySQL密码找回 7. 旋转90度横向查看表 8. 添加一个远程连接的用户 1. MySQL目录 /usr/bin/mysql相关命令vim /etc/my.cnfmysql配置文件ls /…...

记录使用 Vue3 过程中的一些技术点
1、自定义组件,并使用 v-model 进行数据双向绑定。 简述: 自定义组件使用 v-model 进行传参时,遵循 Vue 3 的 v-model 机制。在 Vue 3 中,v-model 默认使用了 modelValue 作为 prop 名称,以及 update:modelValue 作为…...

6. C++通过fork的方式实现高性能网络服务器
我们上一节课写的tcp我们发现只有第一个与之连接的人才能收发信息。他又很多的不足 高性能网络服务器 通过fork实现高性能网络服务器 我们通过fork进行改装之后就可以成百上千的用户进行连接访问,对于每一个用户来说我们都fork一个子进程。让后让每一个子进程都是…...

直播美颜插件、美颜SDK详解:技术、功能与实现原理
今天,小编将详细解析直播美颜插件和美颜SDK的技术、功能以及实现原理。 一、美颜技术的背景与发展 1.1美颜技术的兴起 随着直播平台的普及,美颜SDK技术逐渐被集成到直播软件中,以满足用户对更美观、自然的直播效果的需求。 1.2美颜技术的…...

MyBatis入门(1)
目录 一、JDBC操作回顾 二、什么是MyBatis? 三、MyBatis入门 1、准备工作 (1)创建工程 (2)数据准备 2、配置数据库连接字符串 3、写持久层代码 4、单元测试 (1)使用IDEA自动成成测试类…...

打开服务器远程桌面连接不上,可能的原因及相应的解决策略
在解决远程桌面连接不上服务器的问题时,我们首先需要从专业的角度对可能的原因进行深入分析,并据此提出针对性的解决方案。以下是一些可能的原因及相应的解决策略: 一、网络连接问题 远程桌面连接需要稳定的网络支持,如果网络连接…...
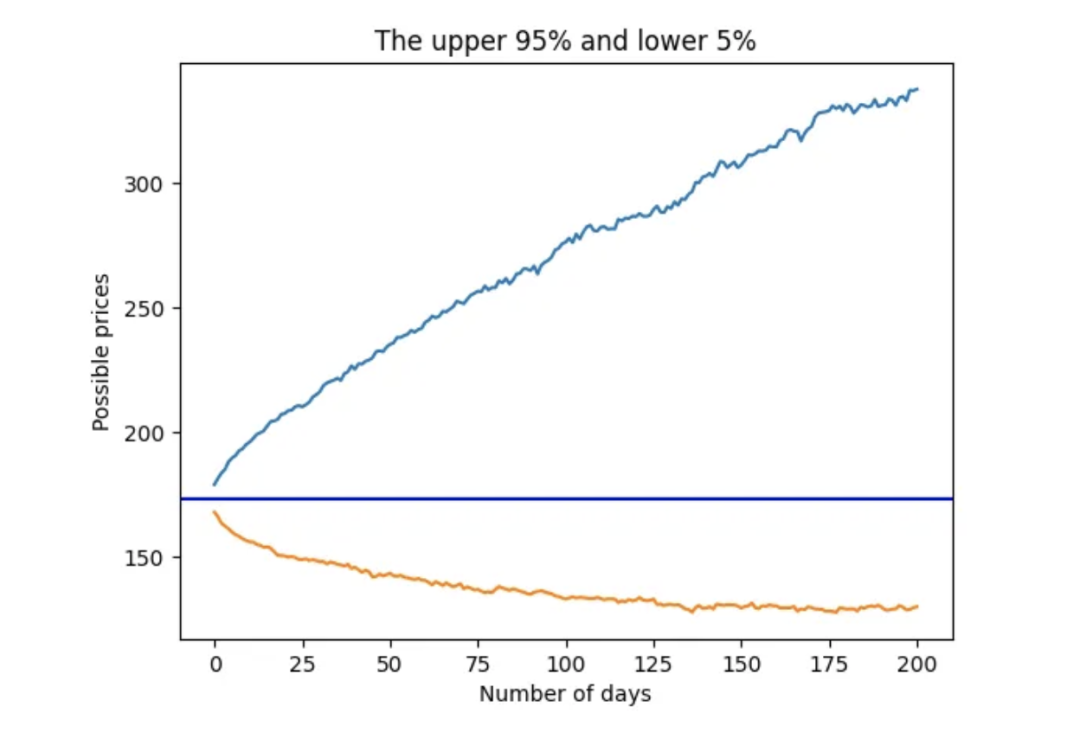
用于时间序列概率预测的蒙特卡洛模拟
大家好,蒙特卡洛模拟是一种广泛应用于各个领域的计算技术,它通过从概率分布中随机抽取大量样本,并对结果进行统计分析,从而模拟复杂系统的行为。这种技术具有很强的适用性,在金融建模、工程设计、物理模拟、运筹优化以…...

VScode解决报错“Remote-SSH XHR failed无法访问远程服务器“的方案
VScode解决报错"Remote-SSH XHR failed无法访问远程服务器"的方案 $ ls ~/.vscode-server/bin 2ccd690cbff1569e4a83d7c43d45101f817401dc稳定版下载链接:https://update.code.visualstudio.com/commit:COMMIT_ID/server-linux-x64/stable 内测版下载链接…...
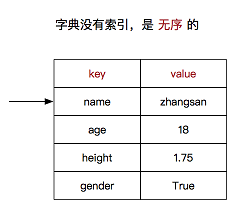
Python高级进阶--dict字典
dict字典⭐⭐ 1. 字典简介 dictionary(字典) 是 除列表以外 Python 之中 最灵活 的数据类型,类型为dict 字典同样可以用来存储多个数据字典使用键值对存储数据 2. 字典的定义 字典用{}定义键值对之间使用,分隔键和值之间使用:分隔 d {中…...
记忆力和人才测评,如何提升记忆力?
什么是记忆力? 如何通俗意义上的记忆力?我们可以把人的经历、经验理解成为一部纪录片,那么已经过去发生的事情,就是影片之前的情节,对于这些信息,在脑海里,人们会将其进行处理和组合ÿ…...

数据仓库建模
目录 数仓建模 为什么要对数据仓库进行分层 主题 主题的概念 维度建模: 模型的选择: 星形模式 雪花模型 星座模式 拉链表 维度表和事实表: 维度表 事实表 事实表设计规则 退化维度 事务事实表、周期快照事实表、累积快照事实…...

力扣:1738. 找出第 K 大的异或坐标值
1738. 找出第 K 大的异或坐标值 给你一个二维矩阵 matrix 和一个整数 k ,矩阵大小为 m x n 由非负整数组成。 矩阵中坐标 (a, b) 的 值 可由对所有满足 0 < i < a < m 且 0 < j < b < n 的元素 matrix[i][j](下标从 0 开始计数&…...

Keras深度学习框架第二十讲:使用KerasCV中的Stable Diffusion进行高性能图像生成
1、绪论 1.1 概念 为便于后文讨论,首先进行相关概念的陈述。 Stable Diffusion:Stable Diffusion 是一个在图像生成领域广泛使用的技术,尤其是用于文本到图像的转换。它基于扩散模型(Diffusion Models),这…...

C/C++ vector详解
要想了解STL,就必须会看: cplusplus.comhttps://legacy.cplusplus.com/ 官方内容全都是英文的,可以参考: C/C初始识https://blog.csdn.net/2301_77087344/article/details/138596294?spm1001.2014.3001.5501 vectorÿ…...

使用libtorch加载YOLOv8生成的torchscript文件进行目标检测
在网上下载了60多幅包含西瓜和冬瓜的图像组成melon数据集,使用 LabelMe 工具进行标注,然后使用 labelme2yolov8 脚本将json文件转换成YOLOv8支持的.txt文件,并自动生成YOLOv8支持的目录结构,包括melon.yaml文件,其内容…...
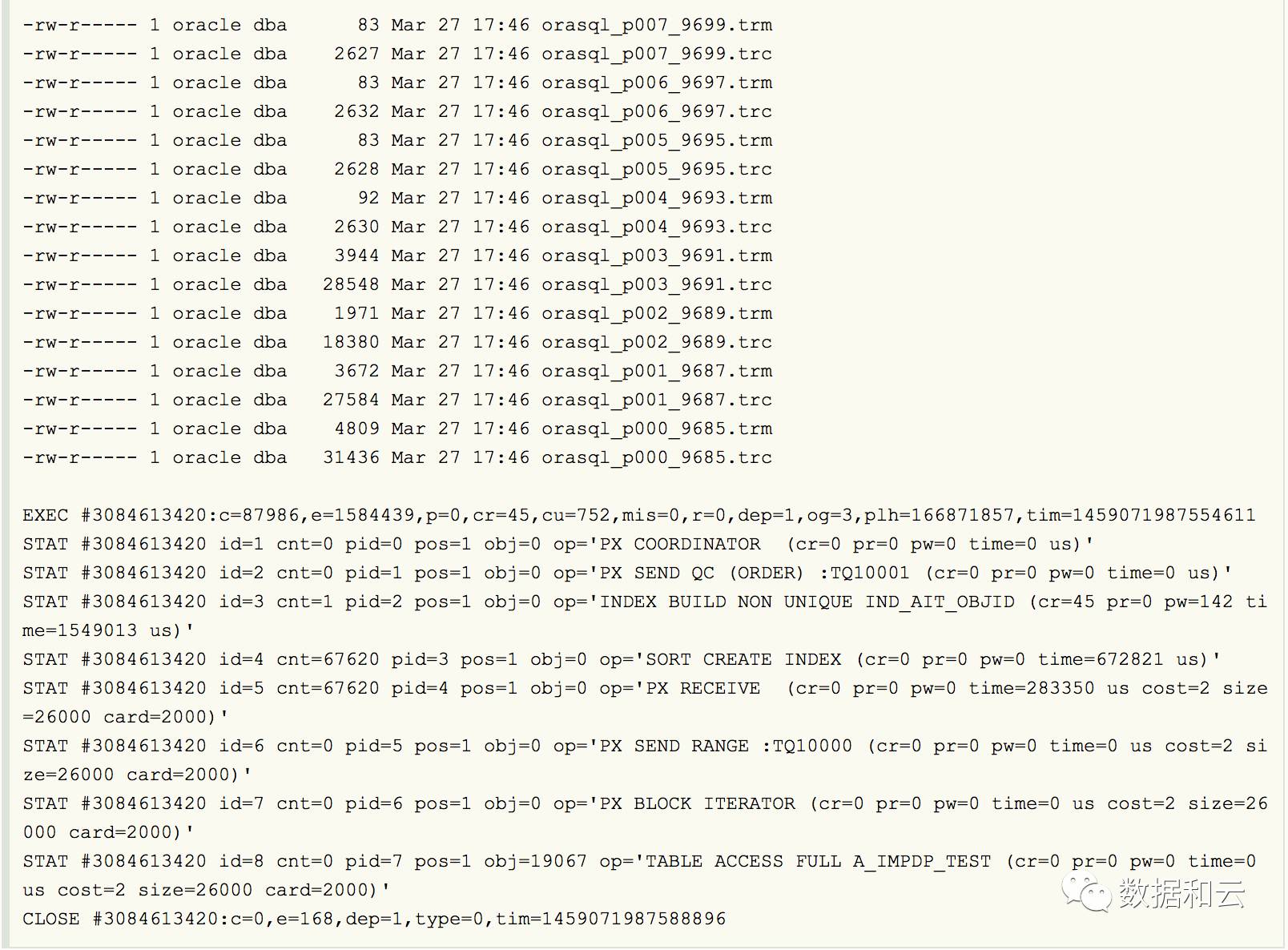
Oracle 并行和 session 数量的
这也就是为什么我们指定parallel为4,而实际并行度为8的原因。 insert create index,发现并行数都是加倍的 Indexes seem always created with parallel degree 1 during import as seen from a sqlfile. The sql file shows content like: CREATE INDE…...

Android 版本与 API level 以及 NDK 版本对应
采用 Android studio 开发 Android app 的时候,需要选择支持的最低 API Level 和使用的 NDK 版本,对应开发 app 的最低 SDK 版本: 在 app 的 build.gradle 文件里,对应于代码如下: 目前各版本的占有率情况如下…...

护网经验面试题目原版
文章目录 一、护网项目经验1.项目经验**Hvv的分组和流程**有没有遇到过有意思的逻辑漏洞?有没有自己开发过武器/工具?有做过代码审计吗?有0day吗有cve/cnvd吗?有src排名吗?有没有写过技战法有钓鱼经历吗?具…...

64_《智能体微服务架构企业级实战教程》授权与认证之授权认证集成测试
前言 配套视频教程: 在 Bilibili课堂、CSDN课程、51CTO学堂 同步发售,提供:源码+部署脚本+文档。 bilibili课堂视频教程:智能体微服务架构企业级实战教程_哔哩哔哩_bilibili CSDN课程视频教程:智能体微服务架构企业级实战教程_在线视频教程-CSDN程序员研修院 51CTO学堂…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

Python PIL 画矩形框
基础代码 from PIL import Image, ImageDraw# 打开图片 img Image.open(your_image.jpg)# 创建绘图对象 draw ImageDraw.Draw(img)# 矩形坐标 (x1, y1, x2, y2) coords (23, 21, 69, 76)# 画矩形框(红色,线宽2) draw.rectangle(coords, ou…...
)
毕业设计 yolov11骨折检测医疗辅助系统(源码+论文)
文章目录 0 前言1 项目运行效果2 课题背景2.1 研究背景2.2 国内外研究现状2.3 研究意义 3 设计框架(骨折检测系统设计框架说明)3.1. 系统架构图3.2. 技术选型3.2.1 核心组件3.2.2 辅助工具 3.3. 核心模块设计3.3.1 YOLO模型训练模块训练流程图关键伪代码…...

WarcraftHelper:让魔兽争霸3在现代电脑上完美运行的关键插件
WarcraftHelper:让魔兽争霸3在现代电脑上完美运行的关键插件 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为《魔兽争霸3》这…...

3分钟快速上手:bilibili-parse视频解析API终极指南
3分钟快速上手:bilibili-parse视频解析API终极指南 【免费下载链接】bilibili-parse bilibili Video API 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-parse bilibili-parse是一款高效专业的B站视频解析工具,为开发者和内容创作者提供…...

3步快速恢复加密压缩包密码:ArchivePasswordTestTool终极指南
3步快速恢复加密压缩包密码:ArchivePasswordTestTool终极指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 面对遗忘的加密压…...

Windows上直接安装APK文件:告别模拟器的轻量级安卓应用安装方案
Windows上直接安装APK文件:告别模拟器的轻量级安卓应用安装方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为笨重的安卓模拟器烦恼吗?…...
)
别再死记硬背公式了!用UE5的Lerp节点玩转材质混合(附灰度图实战案例)
别再死记硬背公式了!用UE5的Lerp节点玩转材质混合(附灰度图实战案例)在游戏开发中,材质混合是创造丰富视觉效果的关键技术。对于Unreal Engine 5的初学者来说,LinearInterpolate(简称Lerp)节点可…...

收藏|2026 新版大模型入行指南!风口红利期程序员小白均可入局
2026年人工智能行业发展势头迅猛,已然迈入全民争相布局的高速发展阶段。多模态技术持续更新升级,大模型各类商业化项目不断落地投产,市场专业人才缺口不断拉大,对应岗位薪酬待遇也迎来大幅上涨。 不管是毫无技术基础、打算从零起步…...