开源大模型与闭源大模型
概述
开源大模型和闭源大模型是两种常见的大模型类型,它们在以下方面存在差异:
-
开放性:
- 开源大模型:代码和模型结构是公开可用的,任何人都可以访问、修改和使用。
- 闭源大模型:模型的代码和结构是私有的,只能由特定的组织或个人使用。
-
可定制性:
- 开源大模型:由于其开放性,用户可以根据自己的需求进行定制和修改,以适应特定的应用场景。
- 闭源大模型:定制和修改的程度可能受到限制,因为模型的结构和实现细节可能不公开。
-
数据使用:
- 开源大模型:数据的使用通常是开放的,用户可以使用自己的数据进行训练和优化。
- 闭源大模型:数据的使用可能受到限制,可能需要使用特定的数据集或遵循特定的使用规则。
-
应用场景:
- 开源大模型:适用于需要灵活性、可定制性和广泛应用的场景,如研究、教育、开发等。
- 闭源大模型:适用于对性能、准确性和定制性有较高要求的场景,如企业内部应用、特定领域的解决方案等。
开源大模型的优点包括:
-
灵活性和可定制性,能够满足不同用户的需求。
-
促进技术的发展和创新,因为更多的人可以参与到模型的改进和优化中。
-
资源共享和协作,有利于推动整个行业的发展。
缺点可能包括:
- 质量和性能的不确定性,因为模型可能来自不同的来源和团队。
- 缺乏技术支持和维护,可能需要用户自己进行调试和优化。
闭源大模型的优点包括:
- 性能和质量的稳定性,经过严格的测试和优化。
- 提供专业的技术支持和维护。
- 更好地保护知识产权和商业机密。
缺点可能是:
- 定制性相对较低,可能无法完全满足某些特定需求。
- 开放性受限,可能对用户的参与和贡献有限。
应用场景方面,开源大模型适用于以下情况:
- 研究和开发,用于探索新的算法和技术。
- 教育和培训,提供开放的学习资源。
- 数据科学竞赛和项目,促进创新和竞争。
闭源大模型适用于以下情况:
- 企业内部应用,需要满足特定的业务需求和安全要求。
- 对性能和准确性要求较高的场景,如金融、医疗等领域。
- 特定领域的解决方案,如自然语言处理、计算机视觉等。
在实际应用中,选择开源大模型还是闭源大模型应根据具体需求、项目特点和团队资源来决定。有时,也可以结合使用开源和闭源模型,以充分发挥它们的优势。随着技术的发展和开放程度的提高,一些闭源大模型也可能逐渐开放或提供一定程度的定制化接口。
数据隐私
开源大模型和闭源大模型在数据隐私保护和用户数据安全方面存在一些差异。以下是对这些差异的详细讨论:
-
数据隐私保护的方式:
- 开源大模型:开源大模型的代码和数据通常是公开可用的,任何人都可以访问和审查模型的实现细节。为了保护数据隐私,开源大模型通常采用以下几种方式:
- 数据匿名化:在数据收集和预处理阶段,采用数据匿名化技术来隐藏敏感信息,如删除个人身份标识或使用假名代替真实姓名。
- 数据加密:对数据进行加密,确保只有授权人员能够解密和访问数据。
- 访问控制:实施访问控制机制,限制对数据的访问权限,只有经过授权的人员能够访问和使用数据。
- 安全审计:进行安全审计和监控,检测和防范潜在的安全威胁和数据泄露。
- 闭源大模型:闭源大模型的开发者通常拥有对数据的完全控制,数据的访问和使用受到严格的限制。为了保护数据隐私,闭源大模型可能采用以下方式:
- 数据隔离:将数据存储在安全的环境中,与其他数据隔离开来,减少数据泄露的风险。
- 访问权限管理:实施严格的访问权限控制,只有授权人员能够访问和使用数据。
- 数据加密:对数据进行加密,确保数据在传输和存储过程中的安全性。
- 安全评估和认证:进行安全评估和认证,确保模型和系统的安全性。
- 开源大模型:开源大模型的代码和数据通常是公开可用的,任何人都可以访问和审查模型的实现细节。为了保护数据隐私,开源大模型通常采用以下几种方式:
-
数据隐私保护的程度:
- 开源大模型:由于开源大模型的代码和数据是公开的,数据隐私保护的程度可能受到一定限制。虽然可以采取一些措施来保护数据隐私,但无法完全避免数据被潜在的攻击者获取和分析。开源大模型的开发者需要在保护数据隐私和促进模型的可访问性之间找到平衡。
- 闭源大模型:闭源大模型的数据访问和使用受到严格的限制,数据隐私保护的程度相对较高。开发者可以采取更高级的安全措施来保护数据,确保数据不被未经授权的人员访问和使用。闭源大模型的开发者对数据的控制也带来了一些潜在的问题,如用户对数据使用的透明度和控制程度较低。
-
用户数据安全的考虑:
- 开源大模型:开源大模型的用户在使用模型时需要注意数据的安全和隐私。他们应该确保自己的数据在上传和使用过程中得到适当的保护,并且了解模型的隐私政策和数据使用条款。用户还可以采取一些措施来增强数据的安全性,如使用强密码、定期备份数据等。
- 闭源大模型:闭源大模型的用户通常对数据的安全和隐私有更高的信心,因为数据的访问和使用受到更严格的控制。用户仍然需要关注模型的安全性和数据的备份,以防止潜在的数据丢失或泄露。
-
法律和合规性要求:
- 开源大模型:开源大模型的开发者需要遵守相关的开源许可证规定,确保在使用开源代码和数据时遵循许可协议。根据不同的地区和行业,还可能存在特定的法律和合规性要求,如数据保护法规、隐私法规等,开源大模型的开发者需要确保其模型符合这些要求。
- 闭源大模型:闭源大模型的开发者需要建立自己的法律和合规体系,确保模型的开发和使用符合法律法规的要求。需要制定隐私政策和数据使用条款,明确用户的数据权利和义务,并采取相应的安全措施来保护用户数据。
-
透明度和可解释性:
- 开源大模型:由于开源大模型的代码是公开的,用户可以更好地理解模型的工作原理和决策过程,提高透明度和可解释性。有助于用户对模型的输出有更多的信任,并发现潜在的偏差或问题。
- 闭源大模型:由于闭源大模型的实现细节是保密的,用户对模型的工作原理和决策过程了解较少,透明度和可解释性相对较低。可能导致用户对模型的信任度降低,特别是在涉及关键决策的应用场景中。
开源大模型和闭源大模型在数据隐私保护和用户数据安全方面存在差异。开源大模型提供了更大的灵活性和可定制性,但数据隐私保护的程度可能较低;闭源大模型提供了更高的数据隐私保护,但用户对数据的透明度和控制程度可能受限。在实际应用中,选择使用哪种类型的大模型应根据具体需求、数据的敏感性、安全要求和法律合规性等因素进行综合考虑。无论是开源大模型还是闭源大模型,都需要采取适当的安全措施来保护用户数据的安全和隐私。最终的目标是在保护数据隐私的前提下,实现大模型的广泛应用和价值。
商业应用
在商业应用领域,开源大模型和闭源大模型各有其优劣势。以下是对这两种模式的详细探讨,涵盖其在商业化过程中可能遇到的各方面问题和机会。
开源大模型
优势
-
透明度和可控性
开源大模型的代码和架构细节是公开的,企业可以了解其内部工作机制。透明度保障了系统的安全性,并允许企业在出现问题时迅速定位和解决问题。 -
成本效益
开源大模型通常可以免费使用或者成本较低,企业可以根据需要自行部署和维护。降低了初期的投入成本,而且只需为自己特定的需求付费,比如云计算资源和专门的技术支持。 -
创新和社区支持
开源模型通过丰富的社区贡献可以不断改进和优化,吸引全球开发者共同参与。企业可以从这些新功能和改进中受益,加速创新周期。 -
灵活性和定制化
企业可以根据自身的特殊需求定制模型,无需受限于供应商预设的功能。开源许可允许修改源代码,在需要特定调整和优化时尤为重要。
劣势
-
技术门槛
使用开源大模型通常需要具备高水平的技术能力和知识,企业需要拥有一支经验丰富的技术团队来配置、优化和维护系统。 -
维护和支持
与闭源模型相比,开源模型缺乏官方的长期技术支持。虽然社区提供了帮助,但在遇到复杂或重大的技术问题时,可能无法及时获得有效解决方案。 -
责任和风险
开源软件的安全性和可靠性并不总是得到充分验证,由于源代码公开,容易成为攻击目标。企业需要进一步进行安全审查和风险管理。
闭源大模型
优势
-
易用性和便捷性
闭源大模型通常打包完整,用户体验友好,有专门的技术支持和培训,降低了企业的技术门槛,企业可以更快地实现业务目标。 -
可靠性和稳定性
闭源大模型由专业团队开发和维护,经过严格的测试和验证,通常具有高稳定性和高可靠性,适合企业重要的生产环境。 -
安全与合规
闭源供应商通常提供保障性的安全措施和合规策略,有助于企业满足法律和监管要求。企业可以依赖供应商提供的安全更新和支持。 -
专业支持和服务
闭源模型供应商通常会提供专门的客户支持和服务,包括技术协助、定制开发、性能优化等。企业可以享受到及时和高效的服务,降低运营风险。
劣势
-
成本高昂
商业闭源模型通常伴随着高额的许可证费用和服务费。对于预算有限的中小企业,高昂的费用可能会成为重大负担。 -
依赖性和锁定效应
企业一旦选择某个闭源模型,就会对供应商产生很高的依赖性,切换成本高昂。一旦供应商停止支持或改变策略,企业可能面临业务中断或需要重新部署其他模型的风险。 -
定制化受限
闭源模型的功能和特性由供应商决定,企业不能随意修改源代码,只能在已有框架内进行有限的调整。可能限制企业的创新能力和业务灵活性。 -
数据隐私担忧
使用闭源模型时,企业的数据经常需要上传至供应商平台进行处理,可能引发数据隐私和安全问题,尤其是在涉及敏感数据和严格隐私法规的情况下。
结论
在商业应用领域,开源大模型和闭源大模型各具优劣,企业需要根据自身的需求、资源和战略目标进行选择。
开源大模型适合具备技术能力的企业,尤其是那些希望保持自主权、降低成本并具备强大的定制化需求的公司。通过利用开源社区的力量,企业可以迅速创新并适应变化的市场需求。也要求企业具备足够的技术人才和资源来处理相关的技术挑战和维护问题。
闭源大模型则适合希望快速部署、追求高稳定性和可靠性的企业,尤其是那些愿意为便捷性、安全性和专业支持付出较高费用的公司。企业可以依赖供应商提供的全面服务,降低内部技术压力,但同时也需要考虑潜在的数据隐私风险和供应商锁定效应。
企业在选择开源或闭源大模型时,应综合考虑业务需求、技术能力、成本预算、数据安全和长期战略,找到最适合自己的方案,从而在竞争激烈的市场中立于不败之地。
社区参与
开源大模型和闭源大模型在社区参与与合作方面有显著区别,对人工智能(AI)行业的发展产生了深远影响。以下是对这两种模式在社区参与与合作方面的详细比较,以及对行业发展的推动作用的探讨。
开源大模型与社区参与
开源大模型是指源代码公开的AI模型,任何人都可以访问、使用、修改和分发。这种模式在社区参与和合作方面具有以下特点:
-
开放透明性:
- 代码透明:开源模型的所有代码和训练数据集都向公众开放。有助于社区成员理解模型的工作原理、发现潜在的问题并提出改进意见。
- 公开研究:研究人员可以公开分享他们的研究成果,包括模型架构、训练方法和性能评估。促进了知识的自由流通和技术的快速发展。
-
广泛的社区支持:
- 多样化贡献:开源模型允许来自世界各地的开发者和研究人员参与其中,他们可以提出改进建议、提交代码补丁或开发新功能。有助于模型的快速迭代和优化。
- 合作与交流:开源社区为开发者提供了一个交流和合作的平台,例如GitHub、论坛和邮件列表。社区成员可以分享经验、互相帮助,解决技术难题。
-
创新与实验:
- 自由创新:开源模式鼓励开发者在现有模型的基础上进行创新和实验。他们可以自由修改模型以适应特定应用场景,甚至可以衍生出新的模型和算法。
- 快速原型开发:开发者可以基于开源模型快速开发出原型,并在实际应用中验证其效果。加速了AI技术从研究到实际应用的转化过程。
闭源大模型与社区参与
闭源大模型是指那些源代码未公开,通常由大型科技公司或研究机构开发和维护的AI模型。在社区参与和合作方面的特点如下:
-
有限的透明性:
- 代码封闭:闭源模型的源代码和训练数据集通常不向公众开放。限制了外部研究人员对模型内部机制的理解和改进。
- 信息保密:闭源模式下,公司的研究成果和技术细节通常保密,只发布有限的性能指标和应用示例。可能会导致技术创新的滞后。
-
受限的社区支持:
- 内部团队为主:闭源模型的开发和维护主要由公司内部的团队完成,外部开发者的参与机会较少。可能限制了模型的多样化发展。
- 有限的合作平台:尽管一些公司会通过学术会议、研讨会和合作项目与外部研究机构合作,但通常受限于特定领域和项目。
-
创新受限:
- 创新受控:闭源模式下,创新主要由公司内部主导,外部开发者难以在现有模型的基础上进行自由创新。创新的速度和广度可能受到限制。
- 技术垄断:一些大型公司可能通过闭源模式实现技术垄断,限制了其他企业和开发者的创新机会,可能导致市场竞争的不公平。
对行业发展的推动作用
-
开源大模型的推动作用:
- 促进技术普及:开源大模型的自由使用和修改权限有助于AI技术的普及,使得更多的开发者和企业能够利用先进的AI技术,推动整个行业的发展。
- 加速创新:开源模式鼓励广泛的合作和快速的技术迭代,促进了新技术和新应用的不断涌现。开源社区的活跃度直接推动了AI领域的技术进步。
- 教育和人才培养:开源模型为教育和培训提供了丰富的资源,使得更多的学生和研究人员能够接触和学习最新的AI技术,培养了大量的AI人才。
-
闭源大模型的推动作用:
- 资源集中:闭源模式下,公司可以集中资源进行高效的研发和技术攻关,开发出高性能和高质量的AI模型。通常在商业应用中表现出色。
- 商业竞争力:闭源模型通常伴随着商业化应用,能够为企业带来直接的经济收益,推动公司进一步投入AI研发,形成良性循环。
- 专有技术保护:闭源模式保护了公司的知识产权和技术秘密,防止竞争对手复制和模仿,保障了企业的市场竞争力。
结论
开源大模型和闭源大模型在社区参与与合作方面各有优劣。开源大模型通过广泛的社区参与、自由的创新和快速的技术迭代,推动了AI技术的普及和发展。闭源大模型通过集中的资源投入和高效的研发,推动了高性能AI模型的商业化应用。两者的互补和共存,形成了AI行业发展的双轮驱动,共同推动了技术进步和应用落地。
相关文章:
开源大模型与闭源大模型
概述 开源大模型和闭源大模型是两种常见的大模型类型,它们在以下方面存在差异: 开放性: 开源大模型:代码和模型结构是公开可用的,任何人都可以访问、修改和使用。闭源大模型:模型的代码和结构是私有的&…...

python+selenium - UI自动框架之封装查找元素
单一的元素定位方法不能满足所有元素的定位,可以根据每个元素的特点来找到合适的方法,可以参考下图的方法: elementFind.py from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_con…...
java 拦截器-用户无操作超时退出利用Redis
1、授权过滤,只要实现AuthConfigAdapter接口 2、利用Redis token超时时间,用户访问后台续时 效果 Component public class AuthFilter implements Filter {private static Logger logger LoggerFactory.getLogger(AuthFilter.class);Autowiredprivat…...

民国漫画杂志《时代漫画》第16期.PDF
时代漫画16.PDF: https://url03.ctfile.com/f/1779803-1248612470-6a05f0?p9586 (访问密码: 9586) 《时代漫画》的杂志在1934年诞生了,截止1937年6月战争来临被迫停刊共发行了39期。 ps:资源来源网络!...

线程池以及日志类的实现
目录 线程池: 日志类: 可变参数以及相关函数 1.va_list 2. va_start 3. va_end 日志Log类 线程池 线程池: 是一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着 监督管理者分配可并发执行…...

基于长短期记忆网络 LSTM 的送餐时间预测
前言 系列专栏:【深度学习:算法项目实战】✨︎ 涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对…...

K-means聚类算法详细介绍
目录 🍉简介 🍈K-means聚类模型详解 🍈K-means聚类的基本原理 🍈K-means聚类的算法步骤 🍈K-means聚类的优缺点 🍍优点 🍍缺点 🍈K-means聚类的应用场景 🍈K-mea…...
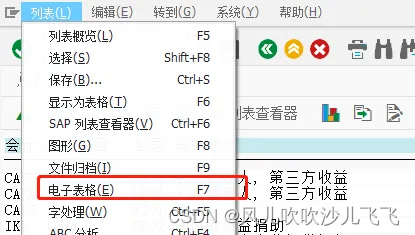
SAP FS00如何导出会计总账科目表
输入T-code : S_ALR_87012333 根据‘FS00’中找到的总账科目,进行筛选执行 点击左上角的列表菜单,选择‘电子表格’导出即可...

ROS参数服务器
一、介绍 参数服务器是用于存储和检索参数的分布式多机器人配置系统,它允许节点动态地获取参数值。 在ROS中,参数服务器是一种用于存储和检索参数的分布式多机器人配置系统。它允许节点动态地获取参数值,并提供了一种方便的方式来管理和共享配…...

QCC---DFU升级变更设备名和地址
QCC---DFU升级变更设备名和地址 这个很多人碰到这个疑问,升级了改不了设备名和地址 /******************************************************************************* Copyright (c) 2018 Qualcomm Technologies International, Ltd. FILE NAME sink_dfu_ps.c DESCRIPT…...

[力扣题解] 695. 岛屿的最大面积
题目:695. 岛屿的最大面积 思路 代码 深度优先搜索 // 深度搜索 class Solution { private:int area_max 0;int dir[4][2] {{0, 1}, {0, -1}, {1, 0}, {-1, 0}};void dfs(vector<vector<int>>& grid, vector<vector<bool>>& …...

AI模型发展路径探析:开源与闭源,何者更胜一筹?
AI模型发展路径探析:开源与闭源,何者更胜一筹? 在当今快速发展的人工智能领域,AI模型成为推动技术创新和应用落地的关键。而评价一个AI模型“好不好”“有没有发展”,往往会引向一个重要话题:开源与闭源这…...

concurrency 并行编程
Goroutine go语言的魅力所在,高并发。 线程是操作系统调度的一种执行路径,用于在处理器执行我们在函数中编写的代码。一个进程从一个线程开始,即主线程,当该线程终止时,进程终止。这是因为主线程是应用程序的原点。然后…...

JavaScript如何让一个按钮的点击事件在完成之前禁用
在JavaScript中,要禁用一个按钮的点击事件直到某个操作完成,你可以将其点击事件用匿名函数的方式书写。 你可以将其在点击函数内设置为null来禁用按钮。 <button id"butto_n">点击抽奖</button><script>butto_n.onclick bu…...

透视App投放效果,Xinstall助力精准分析,让每一分投入都物超所值!
在移动互联网时代,App的推广与投放成为了每一个开发者和广告主必须面对的问题。然而,如何精准地掌握投放效果,让每一分投入都物超所值,却是一个令人头疼的难题。今天,我们就来谈谈如何通过Xinstall这个专业的App全渠道…...

【Linux杂货铺】进程通信
目录 🌈 前言🌈 📁 通信概念 📁 通信发展阶段 📁 通信方式 📁 管道(匿名管道) 📂 接口 编辑📂 使用fork来共享通道 📂 管道读写规则 &…...
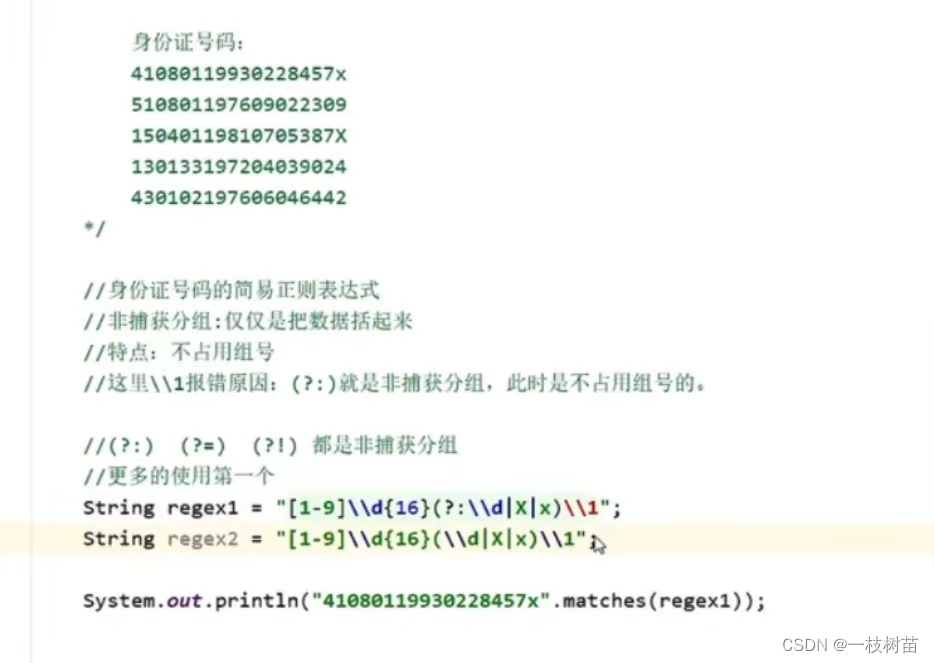
常用API(正则表达式、爬取、捕获分组和非捕获分组 )
1、正则表达式 练习——先爽一下正则表达式 正则表达式可以校验字符串是否满足一定的规则,并用来校验数据格式的合法性。 需求:假如现在要求校验一个qq号码是否正确。 规则:6位及20位之内,0不能在开头,必须全部是数字…...
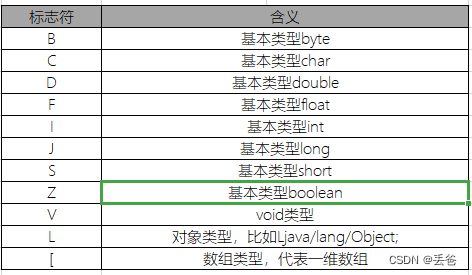
JVM学习-Class文件结构②
访问标识(access_flag) 在常量池后,紧跟着访问标记,标记使用两个字节表示,用于识别一些类或接口层次的访问信息,包括这个Class是类还是接口,是否定义为public类型,是否定义为abstract类型,如果…...

数据库连接项目
MySQL...

MySQL--InnoDB体系结构
目录 一、物理存储结构 二、表空间 1.数据表空间介绍 2.数据表空间迁移 3.共享表空间 4.临时表空间 5.undo表空间 三、InnoDB内存结构 1.innodb_buffer_pool 2.innodb_log_buffer 四、InnoDB 8.0结构图例 五、InnoDB重要参数 1.redo log刷新磁盘策略 2.刷盘方式&…...

CPU架构启发的智能仓储布局优化实践
1. 仓库布局优化的核心挑战与创新机遇在物流仓储领域,拣货环节通常占据运营成本的55%-65%,而其中约50%的时间消耗在无效行走路径上。传统矩形仓库布局虽然易于规划和施工,但其正交的通道设计导致拣货员需要频繁进行90度转向,这种&…...

巨量投放总结
巨量商务管理平台 : https://business.oceanengine.com 巨量广告投放平台: https://ad.oceanengine.com 商务管理平台 账户 广告组 计划 广告投放平台 层级关系: 广告组 -> 计划 -> 创意 对应FB: 系列 - > 广告组 -> 广告...

交流电机驱动器的三种控制模式:前沿切相、后沿切相与同步模式详解
1. 项目概述:一个能玩出花的交流电机驱动器在汽车改装、工业控制或者一些创客项目里,驱动一个交流电机听起来简单,但想让它听话地变速、正反转,甚至实现软启动和精确同步,往往就得搬出笨重又昂贵的工业变频器。今天分享…...

Taotoken的审计日志功能为企业API安全与合规管理提供支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的审计日志功能为企业API安全与合规管理提供支持 当企业决定将大模型能力集成到内部业务流程中时,IT管理员和安…...

HoRain云--CLAUDE.md 使用指南
🎬 HoRain云小助手:个人主页 🔥 个人专栏: 《Linux 系列教程》《c语言教程》 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!…...
)
实战对比:用直方图均衡化与CLAHE拯救你的背光/过曝照片(附Python完整代码)
拯救逆光废片:直方图均衡化与CLAHE的实战效果对比每次旅行回来整理照片时,总会有几张因为光线问题几乎要删除的废片——要么是逆光下的人脸黑得看不清五官,要么是天空过曝失去所有云层细节。这些照片往往记录着重要时刻,直接删除实…...

终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生
终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为经…...
)
别再瞎拖拽了!Unity Prefab从创建到批量修改的保姆级工作流(含变体与嵌套实战)
Unity Prefab高效工作流:从创建到批量修改的实战指南在Unity项目开发中,Prefab(预制体)是最基础也最强大的工具之一。但很多开发者,尤其是初学者,往往停留在简单的"拖拽-修改"阶段,没…...

终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题
终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否也经历过这样的…...

树莓派Zero离线语音交互实战:TTS与STT引擎部署与优化
1. 项目概述:为什么选择树莓派 Zero 来实现语音功能?如果你玩过 Arduino、ESP32 这类微控制器,也接触过树莓派 4B 这样的单板电脑,那你大概能理解那种“选择困难症”:微控制器实时性强、功耗低,但算力有限&…...