【C++】——入门基础知识超详解

目录
编辑
1.C++关键字
2. 命名空间
2.1 命名空间定义
2.2 命名空间使用
命名空间的使用有三种方式:
注意事项
3. C++输入&输出
示例 1:基本输入输出
示例 2:读取多个值
示例 3:处理字符串输入
示例 4:读取整行字符串
示例 5:错误输出和日志输出
输入输出流的格式化
示例 6:设置小数位数
示例 7:对齐输出
综合示例:简单的交互程序
4.缺省参数
4.1 缺省参数概念
4.2 缺省参数分类
注意事项
5. 函数重载
5.1 函数重载概念
5.2 C++支持函数重载的原理 -- 名字修饰 (Name Mangling)
结论
6. 引用
6.1 引用概念
6.2 引用特性
1.引用在定义时必须初始化
2.一个变量可以有多个引用
3.引用一旦引用一个实体,再不能引用其他实体
6.3 常引用
6.4 使用场景
1.做参数
2.做返回值
6.5 传值、传引用效率比较
6.6 引用和指针的区别
7. 内联函数
7.1 概念
7.2 特性
以空间换时间:
编译器建议:
3.声明和定义不分离:
7.3 内联函数的使用建议
8. auto 关键字
8.1 类型别名思考
8.2 auto 简介
8.3 auto 的使用细则
1.auto 与指针和引用结合使用
2.在同一行定义多个变量
8.4 auto 不能推导的场景
1.auto 不能作为函数的参数
2.auto 不能直接用来声明数组
3.为了避免与 C++98 中的 auto 混淆,C++11 只保留了 auto 作为类型指示符的用法
4.auto 最常见的优势用法是与 C++11 提供的新式 for 循环和 lambda 表达式配合使用
9. 基于范围的 for 循环
9.1 范围 for 的语法
9.2 范围 for 的使用条件
循环迭代的范围必须是确定的
迭代的对象要实现 ++ 和 == 的操作
10. 指针空值 nullptr
10.1 C++98 中的指针空值
10.2 nullptr 简介
注意:
1.C++关键字
C++总计63个关键字,C语言32个关键字
ps:下面我们只是看一下C++有多少关键字,不对关键字进行具体的讲解。后面我们学到以后再
细讲。
2. 命名空间
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存
在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,
以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
#include <stdio.h>
#include <stdlib.h>
int rand = 10;
// C语言没办法解决类似这样的命名冲突问题,所以C++提出了namespace来解决
int main()
{
printf("%d\n", rand);
return 0;
}
// 编译后后报错:error C2365: “rand”: 重定义;以前的定义是“函数”2.1 命名空间定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}
中即为命名空间的成员。
// bit是命名空间的名字,一般开发中是用项目名字做命名空间名。
// 大家下去以后自己练习用自己名字缩写即可,如张三:zs// 1. 正常的命名空间定义
namespace bit
{// 命名空间中可以定义变量/函数/类型int rand = 10;int Add(int left, int right){return left + right;}struct Node{struct Node* next;int val;};
}// 2. 命名空间可以嵌套
// test.cpp
namespace N1
{int a;int b;int Add(int left, int right){return left + right;}namespace N2{int c;int d;int Sub(int left, int right){return left - right;}} // namespace N2
} // namespace N1// 3. 同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。
// ps:一个工程中的test.h和上面test.cpp中两个N1会被合并成一个
// test.h
namespace N1
{int Mul(int left, int right){return left * right;}
} // namespace N1
注意:一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中
2.2 命名空间使用
命名空间中成员该如何使用呢 比如:
#include <iostream> // 引入iostream以使用std::cout和std::endlnamespace bit
{// 命名空间中可以定义变量/函数/类型int a = 0;int b = 1;int Add(int left, int right){return left + right;}struct Node{struct Node* next;int val;};
}int main()
{// 使用命名空间中的变量需要加上命名空间前缀// 编译报错:error C2065: “a”: 未声明的标识符std::cout << bit::a << std::endl;return 0;
}
命名空间的使用有三种方式:
1.加命名空间名称及作用域限定符
这是最为明确的方式,通过加上命名空间名称和作用域限定符 :: 来访问命名空间中的成员。
#include <iostream>namespace bit {int a = 10;int b = 20;int Add(int left, int right) {return left + right;}
}int main() {// 使用命名空间名称及作用域限定符std::cout << "a: " << bit::a << std::endl;std::cout << "b: " << bit::b << std::endl;std::cout << "Add: " << bit::Add(3, 4) << std::endl;return 0;
}
2.使用using将命名空间中某个成员引入
使用 using 关键字可以将命名空间中的某个成员引入当前作用域,之后可以直接使用该成员。
#include <iostream>namespace bit {int a = 10;int b = 20;int Add(int left, int right) {return left + right;}
}int main() {// 使用using将命名空间中某个成员引入using bit::a;using bit::Add;std::cout << "a: " << a << std::endl;// 使用被引入的成员不需要加命名空间前缀std::cout << "Add: " << Add(3, 4) << std::endl;// 需要加命名空间前缀访问其他成员std::cout << "b: " << bit::b << std::endl;return 0;
}
3.使用using namespace 命名空间名称 引入
使用 using namespace 关键字可以将整个命名空间引入当前作用域,之后可以直接使用命名空间中的所有成员。
#include <iostream>namespace bit {int a = 10;int b = 20;int Add(int left, int right) {return left + right;}
}int main() {// 使用using将命名空间中某个成员引入using bit::a;using bit::Add;std::cout << "a: " << a << std::endl;// 使用被引入的成员不需要加命名空间前缀std::cout << "Add: " << Add(3, 4) << std::endl;// 需要加命名空间前缀访问其他成员std::cout << "b: " << bit::b << std::endl;return 0;
}
注意事项
- 加命名空间名称及作用域限定符:这种方式最为安全和明确,避免了命名冲突。
- 使用
using将命名空间中某个成员引入:适用于只需要频繁使用命名空间中的某几个成员的情况。 - 使用
using namespace引入整个命名空间:简单快捷,但容易引发命名冲突,尤其是在大型项目中使用多个命名空间时。
根据实际需要选择合适的方式使用命名空间,有助于代码的组织和可读性。
3. C++输入&输出
在C++中,标准输入和输出通过标准库 <iostream> 提供。常用的输入输出流对象包括:
std::cin:标准输入流,用于从键盘读取输入。std::cout:标准输出流,用于向屏幕输出信息。std::cerr:标准错误流,用于向屏幕输出错误信息。std::clog:标准日志流,用于向屏幕输出日志信息。
以下是一些常见的输入和输出操作的示例。
示例 1:基本输入输出
#include <iostream>int main() {int number;std::cout << "请输入一个整数: "; // 输出提示信息std::cin >> number; // 从键盘读取输入到变量numberstd::cout << "您输入的整数是: " << number << std::endl; // 输出输入的值return 0;
}
std::cout使用<<操作符将字符串和变量输出到控制台。std::cin使用>>操作符从控制台读取输入到变量。
示例 2:读取多个值
#include <iostream>int main() {int a, b;std::cout << "请输入两个整数: ";std::cin >> a >> b;std::cout << "您输入的整数是: " << a << " 和 " << b << std::endl;return 0;
}
- 可以使用多个
>>操作符连续读取多个值。
示例 3:处理字符串输入
#include <iostream>
#include <string>int main() {std::string name;std::cout << "请输入您的姓名: ";std::cin >> name;std::cout << "您好, " << name << "!" << std::endl;return 0;
}- 对于单词输入,
std::cin可以直接读取到std::string变量中。
示例 4:读取整行字符串
#include <iostream>
#include <string>int main() {std::string line;std::cout << "请输入一行文字: ";std::getline(std::cin, line);std::cout << "您输入的是: " << line << std::endl;return 0;
}std::getline函数用于读取一整行输入,包括空格。
示例 5:错误输出和日志输出
#include <iostream>int main() {int a;std::cout << "请输入一个正整数: ";std::cin >> a;if (a <= 0) {std::cerr << "错误: 输入的不是正整数!" << std::endl;} else {std::clog << "输入的正整数是: " << a << std::endl;}return 0;
}std::cerr用于输出错误信息。std::clog用于输出日志信息。
输入输出流的格式化
C++ 提供了一些操作符和函数来格式化输入输出,例如控制小数位数、对齐等。
示例 6:设置小数位数
#include <iostream>
#include <iomanip> // 引入iomanip库int main() {double pi = 3.141592653589793;std::cout << "默认输出: " << pi << std::endl;std::cout << std::fixed << std::setprecision(2);std::cout << "设置两位小数: " << pi << std::endl;return 0;
}std::fixed和std::setprecision用于设置小数位数。
示例 7:对齐输出
#include <iostream>
#include <iomanip>int main() {std::cout << std::setw(10) << "列1" << std::setw(10) << "列2" << std::endl;std::cout << std::setw(10) << 123 << std::setw(10) << 456 << std::endl;std::cout << std::setw(10) << 78 << std::setw(10) << 91011 << std::endl;return 0;
}std::setw用于设置字段宽度,实现对齐输出。
综合示例:简单的交互程序
#include <iostream>
#include <string>int main() {std::string name;int age;double salary;std::cout << "请输入您的姓名: ";std::getline(std::cin, name);std::cout << "请输入您的年龄: ";std::cin >> age;std::cout << "请输入您的工资: ";std::cin >> salary;std::cout << std::fixed << std::setprecision(2);std::cout << "姓名: " << name << std::endl;std::cout << "年龄: " << age << " 岁" << std::endl;std::cout << "工资: $" << salary << std::endl;return 0;
}4.缺省参数
4.1 缺省参数概念
缺省参数是在声明或定义函数时为函数的参数指定一个默认值。在调用该函数时,如果没有传递相应的实参,则使用该参数的默认值,否则使用传递的实参。
例子:
#include <iostream>// 定义带缺省参数的函数
void PrintMessage(std::string message = "Hello, World!") {std::cout << message << std::endl;
}int main() {PrintMessage(); // 使用缺省参数,输出 "Hello, World!"PrintMessage("Hello, C++!"); // 使用指定的实参,输出 "Hello, C++!"return 0;
}
4.2 缺省参数分类
缺省参数可以分为全缺省参数和半缺省参数。
-
全缺省参数: 所有参数都有缺省值的函数。
例子:
#include <iostream>// 定义带全缺省参数的函数 void Display(int a = 1, int b = 2) {std::cout << "a = " << a << ", b = " << b << std::endl; }int main() {Display(); // 使用缺省参数,输出 "a = 1, b = 2"Display(5); // 第一个参数使用指定值,第二个参数使用缺省值,输出 "a = 5, b = 2"Display(3, 4); // 使用指定的实参,输出 "a = 3, b = 4"return 0; }2.半缺省参数: 部分参数有缺省值的函数。通常缺省参数应从右往左定义,即后面的参数有缺省值,前面的没有。
例子:
#include <iostream>// 定义带半缺省参数的函数 void Show(int a, int b = 10) {std::cout << "a = " << a << ", b = " << b << std::endl; }int main() {Show(5); // 第一个参数使用指定值,第二个参数使用缺省值,输出 "a = 5, b = 10"Show(3, 7); // 使用指定的实参,输出 "a = 3, b = 7"return 0; }注意事项
1.顺序:缺省参数必须从右向左依次定义,不能间隔定义。例如,void func(int a = 1, int b); 是不允许的,因为 b 没有缺省值,而 a 有。
// 错误示例:
void func(int a = 1, int b); // 不允许的,b 没有缺省值// 正确示例:
void func(int a, int b = 2); // 正确的,b 有缺省值
2.声明和定义:缺省参数只能在函数声明或定义中的一个地方出现,不能在两个地方都定义缺省值。
// 错误示例:
void func(int a = 1, int b = 2); // 在声明中定义了缺省参数void func(int a = 1, int b = 2) { // 在定义中又定义了缺省参数,这是错误的// function body
}// 正确示例:
void func(int a = 1, int b = 2); // 在声明中定义了缺省参数void func(int a, int b) { // 在定义中使用声明中的缺省参数// function body
}
3.缺省值必须是常量或全局变量:缺省值必须是一个常量或全局变量,不能是局部变量或表达式的结果。
const int default_value = 5;// 正确示例:
void func(int a, int b = default_value);// 错误示例:
void func(int a, int b = a + 1); // 不允许,缺省值不能是表达式的结果
4.C语言不支持缺省参数:缺省参数是C++的特性,C语言不支持缺省参数。
通过使用缺省参数,可以使函数调用更加简洁,避免在多次调用中重复传递相同的实参。
5. 函数重载
在自然语言中,一个词可以有多重含义,人们可以通过上下文来判断该词的真实含义,即该词被重载了。比如,关于体育项目的笑话:“乒乓球是‘谁也赢不了!’(我们赢不了对手),男足是‘谁也赢不了!’(我们赢不了对手)。”这展示了同一个表达可以有不同的解释。
同样地,在C++中,函数也可以重载。
5.1 函数重载概念
函数重载:是指在同一作用域中声明几个功能类似但参数不同的同名函数。这些同名函数的参数列表(参数个数、类型或类型顺序)不同。函数重载常用于处理实现功能类似但数据类型不同的问题。
例子:
#include <iostream>// 函数重载示例
void Print(int i) {std::cout << "整数: " << i << std::endl;
}void Print(double d) {std::cout << "双精度: " << d << std::endl;
}void Print(const std::string& s) {std::cout << "字符串: " << s << std::endl;
}int main() {Print(42); // 调用 Print(int)Print(3.14); // 调用 Print(double)Print("Hello!"); // 调用 Print(const std::string&)return 0;
}
5.2 C++支持函数重载的原理 -- 名字修饰 (Name Mangling)
为什么C++支持函数重载,而C语言不支持呢?这是因为C++使用了一种叫做名字修饰(Name Mangling)的技术。
在C/C++中,一个程序要运行,需要经历以下几个阶段:预处理、编译、汇编、链接。
-
实际项目通常由多个头文件和多个源文件构成。编译链接阶段,如果在
a.cpp中调用了b.cpp中定义的Add函数,编译后链接前,a.o的目标文件中没有Add的函数地址,因为Add定义在b.cpp中。所以链接阶段,链接器会到b.o的符号表中找到Add的地址,然后将它们链接到一起。 -
链接时,面对
Add函数,链接器会使用函数名修饰规则来找到函数。不同编译器有不同的函数名修饰规则。 -
由于 Windows 下 VS 的修饰规则过于复杂,而 Linux 下 G++ 的修饰规则简单易懂,我们使用 G++ 演示修饰后的名字。
-
在 G++ 中,函数名修饰后的名字是
_Z + 函数长度 + 函数名 + 类型首字母。
例子:
采用C语言编译器编译后:
// test.c
int Add(int a, int b) {return a + b;
}
编译后函数名未发生改变:
$ gcc -c test.c
$ nm test.o
0000000000000000 T Add
采用C++编译器编译后:
// test.cpp
int Add(int a, int b) {return a + b;
}
编译后函数名发生改变:
$ g++ -c test.cpp
$ nm test.o
0000000000000000 T _Z3Addii
通过名字修饰,C++ 可以区分同名函数,只要参数不同,修饰后的名字就不一样,支持函数重载。而C语言无法支持重载,因为同名函数无法区分。
结论
- C语言不支持函数重载,因为同名函数无法区分。
- C++支持函数重载,通过名字修饰技术将参数类型信息添加到函数名中,使得同名函数可以区分。
- 两个函数如果函数名和参数都相同,即使返回值不同,也不构成重载,因为编译器无法区分它们。
6. 引用
6.1 引用概念
引用是C++中一个重要的概念,它并不是定义一个新变量,而是给已经存在的变量取了一个别名。引用和被引用的变量共享同一块内存空间,因此引用不会占用额外的内存空间。
语法:
类型& 引用变量名 = 实体变量;
例子:
int a = 10;
int& ref = a; // ref 是 a 的引用
- 这里
ref是a的别名,通过ref可以操作a。
注意: 引用类型必须和引用实体是同种类型。
6.2 引用特性
-
1.引用在定义时必须初始化
int a = 10; int& ref = a; // 必须初始化 -
2.一个变量可以有多个引用
int a = 10; int& ref1 = a; int& ref2 = a; // a 有多个引用 -
3.引用一旦引用一个实体,再不能引用其他实体
int a = 10; int b = 20; int& ref = a; // ref = b; // 错误,ref 不能再引用 b,只能修改 a 的值 ref = b; // 这只是把 b 的值赋给 a,而不是让 ref 引用 b6.3 常引用
常引用(const reference)指向一个不能修改的变量,这样可以防止通过引用修改变量的值。
例子:
int a = 10; const int& ref = a; // ref 是常引用,不能通过 ref 修改 a 的值 // ref = 20; // 错误,不能修改6.4 使用场景
1.做参数
void printValue(const int& value) {std::cout << value << std::endl;
}int main() {int a = 10;printValue(a); // 传递引用return 0;
}
2.做返回值
int& getElement(int arr[], int index) {return arr[index];
}int main() {int arr[3] = {1, 2, 3};getElement(arr, 1) = 10; // 修改 arr[1] 的值std::cout << arr[1] << std::endl; // 输出 10return 0;
}
注意: 如果函数返回时,返回的对象还在作用域内(没有被销毁),则可以使用引用返回,否则必须使用传值返回。
6.5 传值、传引用效率比较
传值时,函数会传递实参的一份拷贝,这在处理大数据时效率低。传引用则直接操作实参,提高效率。
例子:
void printByValue(std::string s) {std::cout << s << std::endl;
}void printByReference(const std::string& s) {std::cout << s << std::endl;
}int main() {std::string str = "Hello, World!";printByValue(str); // 传值,效率低printByReference(str); // 传引用,效率高return 0;
}
6.6 引用和指针的区别
- 引用是变量的别名,指针存储变量的地址
int a = 10; int& ref = a; // 引用 int* ptr = &a; // 指针 - 引用在定义时必须初始化,指针可以不初始化
int a = 10; int& ref = a; // 必须初始化 int* ptr; // 可以不初始化 ptr = &a; // 之后再初始化 - 引用一旦初始化后不能再改变引用对象,指针可以随时指向其他对象
int a = 10; int b = 20; int& ref = a; // ref = b; // 错误,引用不能改变对象 int* ptr = &a; ptr = &b; // 可以改变指向 - 没有NULL引用,但有NULL指针
int* ptr = nullptr; // NULL指针 // int& ref = nullptr; // 错误,没有NULL引用 - sizeof引用和指针
int a = 10; int& ref = a; int* ptr = &a; std::cout << sizeof(ref) << std::endl; // 输出变量类型的大小 std::cout << sizeof(ptr) << std::endl; // 输出指针类型的大小(4或8字节) - 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
int a = 10; int& ref = a; ref++; // a 的值变为 11int arr[3] = {1, 2, 3}; int* ptr = arr; ptr++; // ptr 指向下一个元素 - 有多级指针,但没有多级引用
int a = 10; int* ptr = &a; int** pptr = &ptr; // 多级指针 // int&& ref = a; // 没有多级引用 - 访问实体方式不同
int a = 10; int& ref = a; int* ptr = &a;ref = 20; // 直接使用引用 *ptr = 20; // 显式解引用 - 引用比指针使用起来更安全
- 引用在初始化后不能变更,使得引用在使用上比指针更安全。
7. 内联函数
7.1 概念
内联函数是使用 inline 关键字修饰的函数。在编译时,C++编译器会在调用内联函数的地方直接展开函数体,而不是进行正常的函数调用。这避免了函数调用时建立栈帧的开销,从而提升程序运行的效率。
例子:
#include <iostream>// 定义内联函数
inline int Add(int a, int b) {return a + b;
}int main() {int result = Add(3, 4); // 调用内联函数std::cout << "结果: " << result << std::endl;return 0;
}
7.2 特性
-
以空间换时间:
- 概念:内联函数用函数体替换函数调用,省去调用的开销,但会使目标文件变大。
- 缺点:目标文件变大,因为每次调用内联函数都会复制函数体。
- 优点:减少函数调用的开销,提高运行效率。
-
编译器建议:
例子:
inline void SmallFunction() {// 函数体很小,适合内联 }3.声明和定义不分离:
- 概念:
inline对编译器来说只是建议,不同编译器对inline的实现机制不同。 - 建议使用场景:将小规模、非递归、且频繁调用的函数使用
inline修饰。长函数或递归函数不适合使用inline,编译器可能会忽略inline。
- 概念:
概念:内联函数不建议将声明和定义分离,否则可能导致链接错误。
原因:内联函数在编译阶段展开,不会生成函数地址,链接阶段找不到函数地址会报错。
错误例子:
// header.h
inline int Add(int a, int b); // 声明// source.cpp
inline int Add(int a, int b) { // 定义return a + b;
}// main.cpp
#include "header.h"
int main() {Add(3, 4);return 0;
}
正确例子:
// header.h
inline int Add(int a, int b) {return a + b;
}// main.cpp
#include "header.h"
int main() {Add(3, 4);return 0;
}
7.3 内联函数的使用建议
- 内联函数适合用在短小且频繁调用的函数上,可以减少函数调用的开销。
- 不适合将大函数和递归函数设为内联,因为这会增加代码体积并可能导致编译器忽略
inline关键字。 - 内联函数通常在头文件中定义,因为内联函数在编译阶段展开,需要在每个调用的地方都能看到函数体。
8. auto 关键字
8.1 类型别名思考
随着程序的复杂度增加,程序中用到的类型也变得越来越复杂,导致以下问题:
- 类型难于拼写:例如,
std::map<std::string, std::string>::iterator是一个非常长的类型名,很容易写错。 - 含义不明确导致容易出错:复杂的类型名可能会导致理解上的混淆。
聪明的程序员想到,可以使用 typedef 给类型取别名,例如:
typedef std::map<std::string, std::string>::iterator MapIterator;
虽然 typedef 可以简化代码,但它也有一些缺点,尤其是当我们需要根据表达式的类型来声明变量时,可能并不容易知道表达式的类型。
8.2 auto 简介
在早期的 C/C++ 中,auto 表示局部变量的自动存储类型,但几乎没人使用它。
在 C++11 中,auto 被赋予了新的含义:它不再是存储类型指示符,而是类型指示符。使用 auto 声明的变量由编译器在编译期推导其实际类型。
注意: 使用 auto 定义变量时,必须对其进行初始化,以便编译器推导其实际类型。
例子:
#include <iostream>
#include <map>
#include <string>int main() {std::map<std::string, std::string> myMap;myMap["hello"] = "world";// 使用 auto 简化代码auto it = myMap.begin();std::cout << it->first << ": " << it->second << std::endl;return 0;
}
8.3 auto 的使用细则
1.auto 与指针和引用结合使用
用 auto 声明指针类型时,用 auto 和 auto* 没有区别,但用 auto 声明引用类型时必须加 &。
int a = 10;
auto ptr = &a; // ptr 是 int*
auto& ref = a; // ref 是 int&std::cout << *ptr << ", " << ref << std::endl;
2.在同一行定义多个变量
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将报错,因为编译器只对第一个变量进行类型推导。
auto x = 10, y = 20; // 正确,x 和 y 都是 int
// auto a = 10, b = 3.14; // 错误,a 是 int,b 是 double,类型不同
8.4 auto 不能推导的场景
1.auto 不能作为函数的参数
// void func(auto x); // 错误,不能使用 auto 作为函数参数
2.auto 不能直接用来声明数组
// auto arr[10]; // 错误,不能直接用 auto 声明数组
3.为了避免与 C++98 中的 auto 混淆,C++11 只保留了 auto 作为类型指示符的用法
4.auto 最常见的优势用法是与 C++11 提供的新式 for 循环和 lambda 表达式配合使用
std::vector<int> vec = {1, 2, 3, 4, 5};// 使用 auto 与新式 for 循环
for (auto& val : vec) {std::cout << val << " ";
}
std::cout << std::endl;
9. 基于范围的 for 循环
9.1 范围 for 的语法
在 C++98 中,如果要遍历一个数组,可以按照以下方式进行:
int arr[] = {1, 2, 3, 4, 5};
for (int i = 0; i < 5; ++i) {std::cout << arr[i] << std::endl;
}
C++11 引入了基于范围的 for 循环,使得遍历更加简单。for 循环后的括号由冒号 : 分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。
例子:
#include <iostream>
#include <vector>int main() {std::vector<int> vec = {1, 2, 3, 4, 5};// 基于范围的 for 循环for (const auto& val : vec) {std::cout << val << " ";}std::cout << std::endl;return 0;
}
注意: 可以用 continue 结束本次循环,用 break 跳出整个循环。
9.2 范围 for 的使用条件
-
循环迭代的范围必须是确定的
对于数组而言,就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供
begin和end的方法。 -
迭代的对象要实现
++和==的操作
10. 指针空值 nullptr
10.1 C++98 中的指针空值
在 C/C++ 中,如果一个指针没有合法的指向,我们通常会将其初始化为 NULL。
int* p = NULL; // 或者 int* p = 0;
但是 NULL 实际上是一个宏定义,通常被定义为 0 或 (void*)0,这可能导致一些问题。
例子:
void f(int);
void f(int*);f(NULL); // 编译器可能会选择 f(int) 而不是 f(int*)
10.2 nullptr 简介
C++11 引入了新的关键字 nullptr,专门表示空指针值,以解决 NULL 的问题。
例子:
10.2 nullptr 简介
C++11 引入了新的关键字 nullptr,专门表示空指针值,以解决 NULL 的问题。例子:注意:
- 使用
nullptr表示指针空值时,不需要包含头文件,因为nullptr是 C++11 引入的关键字。 - 在 C++11 中,
sizeof(nullptr)与sizeof((void*)0)所占的字节数相同。 - 为了提高代码的健壮性,建议在表示指针空值时使用
nullptr。
相关文章:
【C++】——入门基础知识超详解
目录 编辑 1.C关键字 2. 命名空间 2.1 命名空间定义 2.2 命名空间使用 命名空间的使用有三种方式: 注意事项 3. C输入&输出 示例 1:基本输入输出 示例 2:读取多个值 示例 3:处理字符串输入 示例 4:读…...

ChatGPT技术演进简介
chatGPT(chat generative pre-train transformer, 可以对话的预训练trasformer模型),讨论点: 1、chatGPT为什么突然火了 2、GPT 1.0、2.0、3.0、3.5 、4和4o区别和特性,在不同应用场景中如何选对模型 3、未…...

C语言 | Leetcode C语言题解之第114题二叉树展开为链表
题目: 题解: void flatten(struct TreeNode* root) {struct TreeNode* curr root;while (curr ! NULL) {if (curr->left ! NULL) {struct TreeNode* next curr->left;struct TreeNode* predecessor next;while (predecessor->right ! NULL)…...

Vue 子组件向父组件传值
1、使用自定义事件 ($emit) 这是Vue中最常用的子组件向父组件传递数据的方式。子组件通过触发一个自定义事件,并附加数据作为参数,父组件则监听这个事件并处理传递过来的数据。 子组件 (发送数据): <template><button click"…...
【前端笔记】Vue项目报错Error: Cannot find module ‘webpack/lib/RuleSet‘
网上搜了下发现原因不止一种,这里仅记录本人遇到的原因和解决办法,仅供参考 原因:因为某种原因导致本地package.json中vue/cli与全局vue/cli版本不同导致冲突。再次提示,这是本人遇到的,可能和大家有所不同,…...

edge浏览器的网页复制
一些网页往往禁止复制粘贴,本文方法如下: 网址最前面加上 read: (此方法适用于Microsoft Edge 浏览器)在此网站网址前加上read:进入阅读器模式即可...

视频播放器-Kodi
一、前言 Kodi 是一款开源免费的多媒体播放软件。Kodi 是由非营利性技术联盟 Kodi 基金会开发的免费开源媒体播放器应用程序。 Kodi是一款免费和开源(遵循GPL协议)的多媒体播放器和娱乐中心软件,由XBMC基金会开发。Kodi的主要功能是管理和播…...
Helm安装kafka3.7.0无持久化(KRaft 模式集群)
文章目录 2.1 Chart包方式安装kafka集群 5.开始安装2.2 命令行方式安装kafka集群 搭建 Kafka-UI三、kafka集群测试3.1 方式一3.2 方式二 四、kafka集群扩容4.1 方式一4.2 方式二 五、kafka集群删除 参考文档 [Helm实践---安装kafka集群 - 知乎 (zhihu.com)](https://zhuanlan.…...
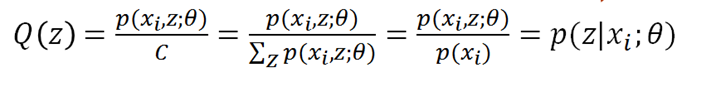
【机器学习】期望最大化(EM)算法
文章目录 一、极大似然估计1.1 基本原理1.2 举例说明 二、Jensen不等式三、EM算法3.1 隐变量 与 观测变量3.2 为什么要用EM3.3 引入Jensen不等式3.4 EM算法步骤3.5 EM算法总结 参考资料 EM是一种解决 存在隐含变量优化问题 的有效方法。EM的意思是“期望最大化(Exp…...

【Python】机器学习中的过采样和欠采样:处理不平衡数据集的关键技术
原谅把你带走的雨天 在渐渐模糊的窗前 每个人最后都要说再见 原谅被你带走的永远 微笑着容易过一天 也许是我已经 老了一点 那些日子你会不会舍不得 思念就像关不紧的门 空气里有幸福的灰尘 否则为何闭上眼睛的时候 又全都想起了 谁都别说 让我一个人躲一躲 你的承诺 我竟然没怀…...
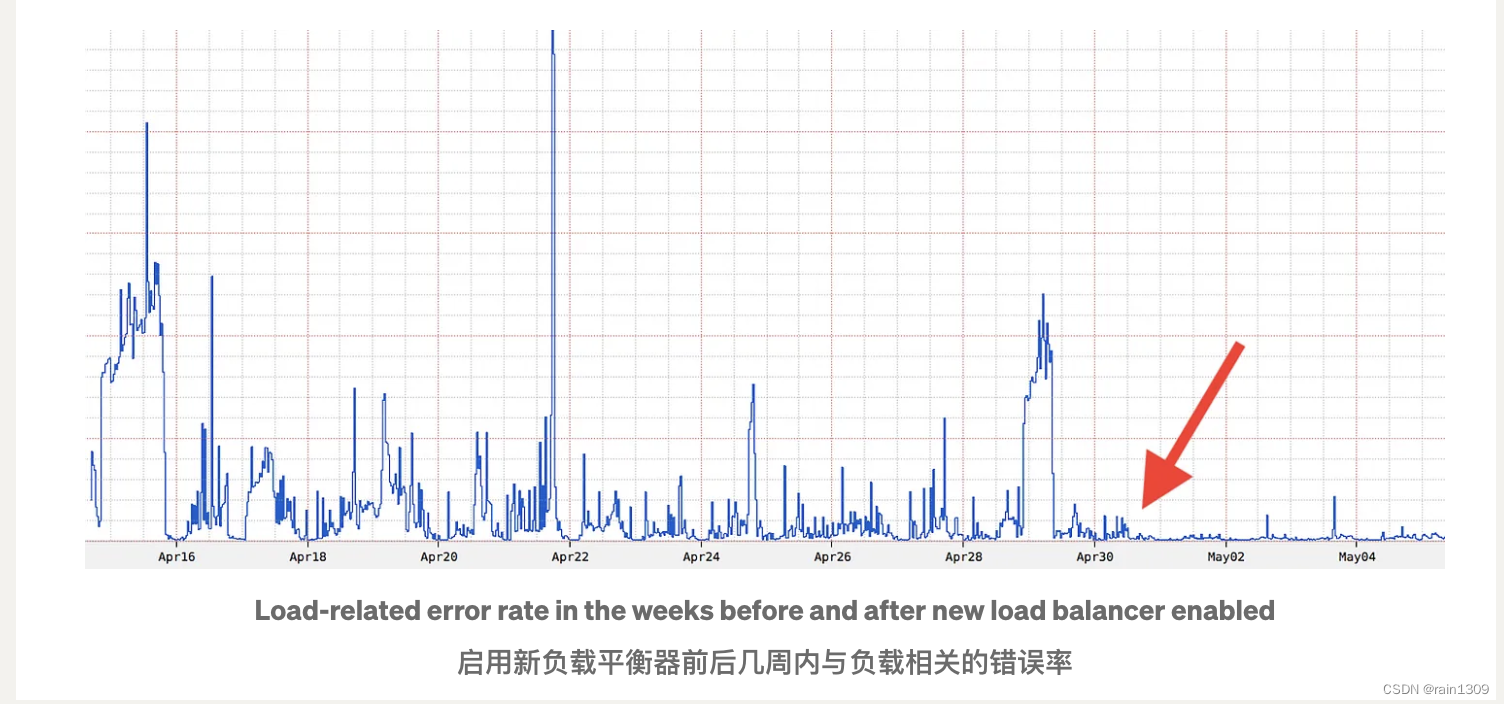
重新思考:Netflix 的边缘负载均衡
声明 本文是对Netflix 博客的翻译 前言 在先前关于Zuul 2开源的文章中,我们简要概述了近期在负载均衡方面的一些工作。在这篇文章中,我们将更详细地介绍这项工作的原因、方法和结果。 因此,我们开始从Zuul和其他团队那里学习&#…...

元组的创建和删除
目录 使用赋值运算符直接创建元组 创建空元组 创建数值元组 删除元组 自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 元组(tuple)是Python中另一个重要的序列结构&#…...

CSS3用户界面
用户界面 appearance appearance 属性用于控制元素是否采用用户代理(浏览器)的默认样式(外观) element {appearance: auto | none;}auto(默认):元素采用浏览器提供的默认样式。none:元素不采用任何默认样式,显示为“裸”元素,通常表现为无特定样式的简单框。input[…...

STL源码刨析:序列式容器之vector
目录 1.序列式容器和关联式容器 2.vector的定义和结构 3.vector的构造函数和析构函数的实现 4.vector的数据结构以及实现源码 5.vector的元素操作 前言 本系列将重点对STL中的容器进行讲解,而在容器的分类中,我们将容器分为序列式容器和关联式容器。本章…...

Flutter 中的 AbsorbPointer 小部件:全面指南
Flutter 中的 AbsorbPointer 小部件:全面指南 在Flutter中,AbsorbPointer是一个特殊的小部件,用于吸收(或“吞噬”)所有传递到其子组件的指针事件(如触摸或鼠标点击)。这在某些情况下非常有用&…...

Web开发学习总结
学习路线 Web 全球广域网,也称为万维网(www World Wide Web),能够通过浏览器访问的网站 初识Web前端 Web标准也称为网页标准,由一系列的标准组成,大部分由W3C(World Wide Web Consortium,万维网联盟)负责制定。三个组…...

springboot相关知识集锦----1
一、springboot是什么? springboot是一个用于构建基于spring框架的独立应用程序的框架。它采用自动配置的原则,以减少开发人员在搭建应用方面的时间和精力。同时提升系统的可维护性和可扩展性。 二、springboot的优点 约定优于配置 版本锁定…...
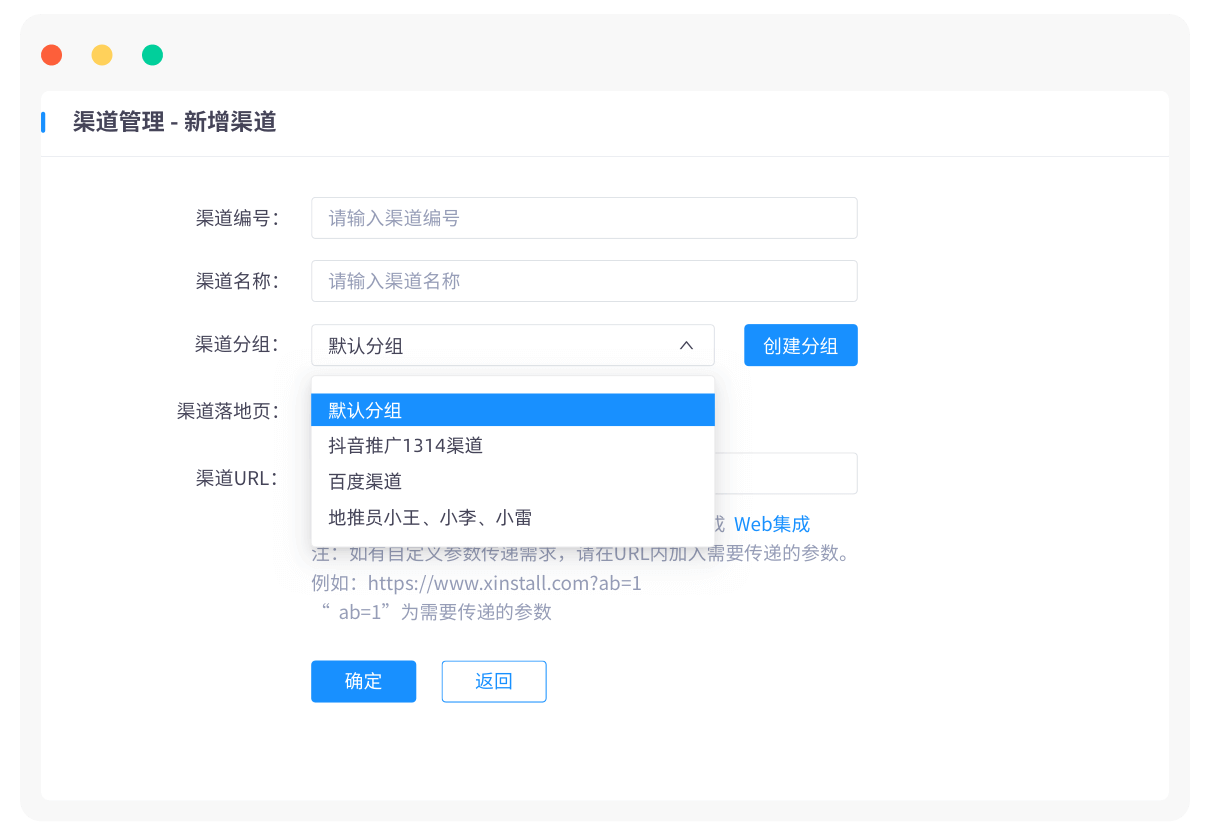
App推广新境界:Xinstall助你轻松突破运营痛点,实现用户快速增长!
在移动互联网时代,App已经成为企业营销不可或缺的一部分。然而,如何有效地推广App,吸引并留住用户,成为了众多企业面临的难题。今天,我们将为您揭秘一款神奇的App推广工具——Xinstall,它将助您轻松突破运营…...
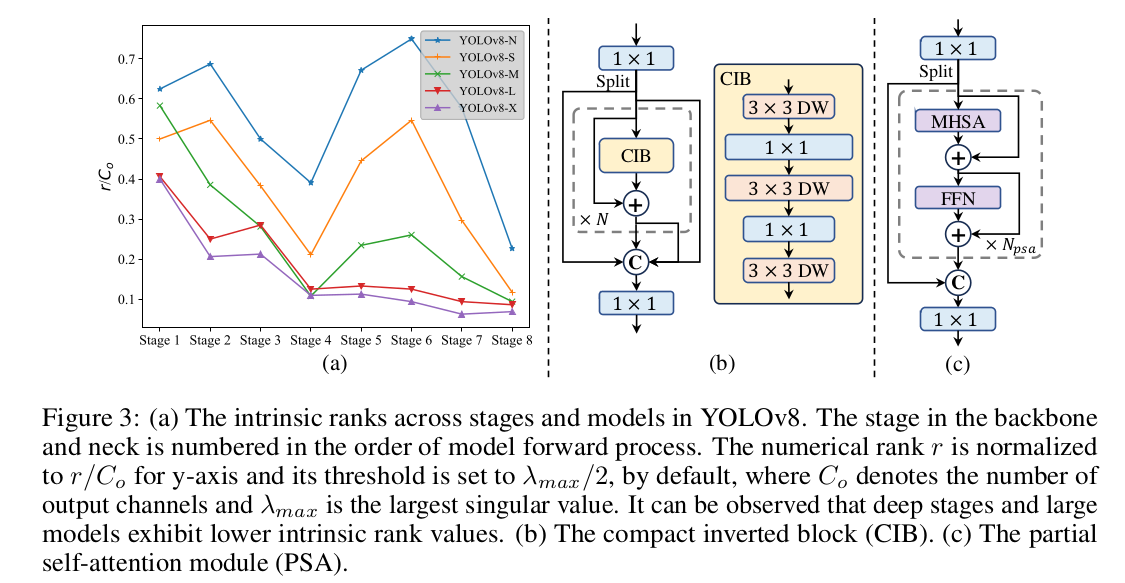
YOLOv10 论文学习
论文链接:https://arxiv.org/pdf/2405.14458 代码链接:https://github.com/THU-MIG/yolov10 解决了什么问题? 实时目标检测是计算机视觉领域的研究焦点,目的是以较低的延迟准确地预测图像中各物体的类别和坐标。它广泛应用于自动…...
[Spring Boot]baomidou 多数据源
文章目录 简述本文涉及代码已开源 项目配置pom引入baomidouyml增加dynamic配置启动类增加注解配置结束 业务调用注解DS()TransactionalDSTransactional自定义数据源注解MySQL2 测试调用查询接口单数据源事务测试多数据源事务如果依然使用Transactional会怎样?测试正…...

UABEA:Unity跨平台资源编辑与二进制解析工具深度指南
1. 为什么Unity开发者在2024年仍要为资源编辑发愁——UABEA不是另一个UI工具,而是解耦工作流的手术刀“UABEA:终极跨平台Unity游戏资源编辑器完全指南”这个标题里,“终极”二字不是营销话术,而是对当前Unity资源编辑生态痛点的精…...

Unity AI工作流:一句话生成可运行小游戏
1. 这不是“AI写代码”,而是用AI重构游戏开发工作流你有没有试过在Unity里搭一个最简单的飞行小游戏?比如让一只牛马角色在空中左右移动、避开障碍物、收集金币——传统做法是:新建场景、拖入Sprite、挂上Rigidbody2D、写Move脚本、写碰撞检测…...

淘金币自动化脚本:解放双手的淘宝任务终极解决方案
淘金币自动化脚本:解放双手的淘宝任务终极解决方案 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 在当今快…...

Qt应用AES/RSA加密监控:Frida+对象生命周期追踪框架
1. 这不是“又一个 Frida 教程”,而是一套可复用的逆向监控工程框架你有没有遇到过这样的场景:在分析一款 Qt 桌面客户端时,发现它用 AES 加密了用户登录凭证,用 RSA 加密了设备指纹,但所有加解密逻辑都藏在QByteArray…...

量子机器学习模型安全:反向工程威胁与防御策略解析
1. 量子机器学习模型的反向工程:安全威胁与防御策略量子计算与机器学习的结合,正以前所未有的方式重塑我们处理复杂问题的能力。作为一名长期关注量子算法与信息安全交叉领域的研究者,我亲眼见证了量子机器学习从理论构想走向实际应用的飞速发…...

终极解决方案:Applite如何彻底改变macOS应用管理体验
终极解决方案:Applite如何彻底改变macOS应用管理体验 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为复杂的命令行操作而烦恼吗?Applite是一款专…...

解密Lua字节码反编译:unluac架构深度解析与实战指南
解密Lua字节码反编译:unluac架构深度解析与实战指南 【免费下载链接】unluac fork from http://hg.code.sf.net/p/unluac/hgcode 项目地址: https://gitcode.com/gh_mirrors/un/unluac 在Lua生态系统中,字节码反编译技术对于逆向工程、代码审计和…...

为 Hermes Agent 配置自定义模型供应商指向 Taotoken
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为 Hermes Agent 配置自定义模型供应商指向 Taotoken Hermes Agent 是一款功能强大的 AI 智能体开发框架,它支持通过自…...

Gemini从部署到退役的全周期价值追踪:3类企业实测数据揭示87%团队忽略的关键衰减点
更多请点击: https://kaifayun.com 第一章:Gemini从部署到退役的全周期价值追踪:3类企业实测数据揭示87%团队忽略的关键衰减点 在真实生产环境中,Gemini模型的价值并非随部署即达峰值,而是呈现典型的“倒U型衰减曲线”…...

开发者在进行多轮对话应用测试时如何利用Taotoken快速切换模型对比
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发者在进行多轮对话应用测试时如何利用Taotoken快速切换模型对比 在开发基于大语言模型的多轮对话应用时,评估不同模…...