关于 Transformer 的11个常见面试题
Transformer 是如何工作的?
Transformer 是一种深度学习算法,特别适用于自然语言处理(NLP)任务,如语言翻译、语言生成和语言理解。它们能够处理长度可变的输入序列并捕捉长距离依赖关系,使其在理解和处理自然语言方面非常有效。
Transformer 通过使用多层自注意力机制和前馈层来处理输入序列并生成输出序列。自注意力层允许网络关注输入序列的不同部分并权衡其重要性,而前馈层则允许网络学习输入和输出序列之间的复杂关系。
Transformer 的应用
以下是一些 Transformer 的有趣应用:
-
自然语言处理: Transformer 广泛用于语言翻译、生成和理解。它们能够处理长度可变的输入序列并捕捉长距离依赖关系,使其在理解和处理自然语言方面非常有效。
-
文本摘要: Transformer 可以用来生成长文本(如新闻文章或研究论文)的简洁而连贯的摘要。这有助于从大量文本中快速提取关键信息。
-
图像和视频描述: Transformer 可以用来生成图像和视频的描述性字幕,使它们更容易被搜索和理解。这对于图像和视频标记或帮助视障人士非常有用。
-
语音识别: Transformer 可以用来理解和转录口语,使用户能够使用语音控制设备或访问信息。
-
聊天机器人和虚拟助手: Transformer 可以用来构建智能聊天机器人和虚拟助手,它们能够理解和响应自然语言查询和命令。
-
推荐系统: Transformer 可以用来构建推荐系统,根据用户的兴趣和过去的行为建议产品、文章或其他内容。
-
生成合成数据: Transformer 可以用来生成与真实数据难以区分的人工数据,使用生成对抗网络(GAN)等技术。这对于数据扩充或隐私保护数据生成任务非常有用。
宝典
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。
总结链接如下:
重磅消息!《大模型面试宝典》(2024版) 正式发布!
面试题
问题1: Transformer 的优势是什么?
Transformer 的优势包括:
- 高效处理输入序列: Transformer 能够处理长度可变的输入序列并捕捉长距离依赖关系,使其在理解和处理自然语言方面非常有效。
- 在各种任务上的良好表现: Transformer 在各种自然语言处理任务上取得了最先进的性能,包括语言翻译、语言生成和语言理解。
- 高度并行化: Transformer 可以在多个GPU上高效训练,这使得训练时间更快,并且能够处理大型数据集。
- 易于实现:与循环神经网络(RNN)等其他类型的深度学习算法相比, Transformer 相对简单易实现。
问题2: Transformer 的局限性是什么?
Transformer 的局限性包括:
- 对大量数据的依赖: Transformer 需要大量数据来实现良好的性能,这在数据稀缺或难以获取的情况下可能是一个挑战。
- 对初始化的敏感性: Transformer 对其权重和偏差的初始值敏感,这可能会影响最终性能。
- 难以解释: Transformer 是黑箱模型,因此很难理解它们是如何做出预测或决策的,这使得调试或解释其行为具有挑战性。
- 应用范围有限: Transformer 主要设计用于自然语言处理任务,可能在其他类型的任务(如计算机视觉或强化学习)上表现不佳。
问题3:什么是 Transformer 及其架构?它与传统神经网络有何不同?
Transformer 是一种神经网络架构,由Vaswani等人在2017年的论文“Attention Is All You Need”中提出。它基于自注意力机制,允许网络并行处理输入序列,而不是使用传统神经网络中的循环连接。 Transformer 在机器翻译、语言建模和语言生成等任务中表现非常出色。 Transformer 的架构包括一个编码器和一个解码器,分别由多个自注意力层和前馈神经网络层组成。编码器处理输入序列并生成一组上下文表示,然后传递给解码器生成输出序列。自注意力层允许网络在每一层考虑输入元素之间的关系,而不是像传统神经网络那样使用循环连接。
问题4: Transformer 是如何训练的?
Transformer 的训练过程与其他神经网络类似。训练过程包括为网络提供大量输入-输出对,并使用优化算法调整网络的权重和偏差,以最小化预测输出与真实输出之间的误差。优化算法通常是随机梯度下降(SGD)的变体,误差函数通常是均方误差(MSE)或交叉熵损失。
问题5: Transformer 中的自注意力机制是什么?
在 Transformer 中,自注意力机制用于计算每个输入元素相对于其他元素的重要性,并权衡每个元素对输出的贡献。这是通过首先使用一组可学习的权重将输入元素投射到更高维空间,然后计算投射元素的点积来完成的。然后通过softmax函数将点积转换为权重,这些权重反映了每个输入元素的重要性。最后,输入元素的加权和用于计算输出。
问题6:训练和实现 Transformer 时有哪些常见挑战,如何改进其性能?
训练和实现 Transformer 的常见挑战包括长训练时间、过拟合和缺乏可解释性。为了解决这些挑战,可以使用批量归一化、数据并行、模型并行、正则化技术(如权重衰减和dropout)、注意力可视化以及最先进的优化技术(如AdamW和Lookahead)等方法。为了提高 Transformer 的性能,可以使用更大且更多样化的数据集、调优超参数、使用预训练模型以及实施最先进的优化技术。
问题7:如何决定 Transformer 中的层数和注意力头的数量?
Transformer 中的层数和注意力头的数量会影响模型的性能和复杂性。一般来说,增加层数和注意力头数量可以提高模型性能,但也会增加计算成本和过拟合的风险。适当的层数和注意力头数量取决于具体任务和数据集,可能需要通过实验来确定最佳值。
问题8:如何处理 Transformer 中的不同长度的输入序列?
Transformer 可以通过填充(padding)来处理不同长度的输入序列,确保所有序列具有相同的长度。填充通常添加到较短序列的末尾,使其与最长的序列长度一致。 Transformer 然后可以并行处理所有序列,因为填充元素不会对输出产生影响。
问题9:如何处理 Transformer 中的缺失/损坏数据并解决过拟合问题?
可以使用插补和数据增强等技术处理 Transformer 中的缺失或损坏数据。在插补中,缺失值被替换为某种估计值,如可用数据的均值或中位数。在数据增强中,根据可用数据生成新的数据点,以帮助模型更好地泛化。正则化技术如权重衰减、dropout和早停可以用于解决 Transformer 中的过拟合问题。权重衰减涉及在损失函数中添加惩罚项,以防止权重过大,而dropout涉及在训练期间随机将部分权重设为零,以防止模型过度依赖于任何一个特征。早停则是在验证集性能开始恶化时停止训练,以防止模型过度拟合训练集。
问题10:如何微调预训练的 Transformer 以适应特定任务?
微调预训练的 Transformer 以适应特定任务涉及通过在该任务的标注数据集上训练网络来调整网络的权重和偏差。预训练模型作为起点,提供一组已经在大型数据集上训练过的初始权重和偏差,可以针对新任务进行微调。可以使用与训练传统 Transformer 相同的优化算法和技术来完成此过程。
问题11:如何确定 Transformer 的适当容量水平?
Transformer 的适当容量水平取决于任务的复杂性和数据集的大小。容量太低的模型可能会欠拟合数据,而容量太高的模型可能会过拟合数据。确定适当容量水平的一种方法是训练和评估具有不同层数和注意力头数量的多个模型,并选择在验证集上表现最佳的模型。
使用 Transformer 网络的技巧和最佳实践
以下是一些使用 Transformer 的技巧和最佳实践:
- 使用大量高质量数据: Transformer 需要大量数据进行训练,数据的质量也会显著影响模型性能。确保使用足够量的高质量数据来训练 Transformer 。
- 使用适当的评估指标:不同的任务和数据集需要不同的评估指标。确保为特定任务和数据集选择合适的评估指标。
- 微调预训练模型:预训练的 Transformer 模型可以提供良好的起点,并可以针对特定任务和数据集进行微调,这可以节省时间并提高性能。
- 监控训练和评估性能:在训练和评估过程中跟踪 Transformer 的性能,以识别任何问题或改进的空间。
- 使用适当的超参数:正确设置超参数(如学习率和层数)可以显著影响 Transformer 的性能。尝试不同的值,并使用交叉验证找到特定任务和数据集的最佳超参数。
- 使用正则化技术:正则化技术(如dropout和权重衰减)可以帮助防止过拟合并提高 Transformer 的泛化能力。
- 使用适当的硬件: Transformer 计算量大,确保使用合适的硬件(如GPU)来高效地训练和运行模型。
- 考虑使用迁移学习:迁移学习对于数据或资源有限的任务非常有用。可以使用预训练的 Transformer 模型,并针对特定任务进行微调,而不是从头开始训练模型。
- 使用多任务学习:多任务学习涉及训练单个模型同时执行多个任务。这对于相关任务共享信息非常有用。
- 跟踪最新发展: Transformer 领域不断发展,定期发布新的研究和进展。跟踪领域的最新进展,以确保使用最有效和最先进的方法。
结论
Transformer 是一种特别适用于自然语言处理任务的深度学习算法,如语言翻译、生成和理解。它们通过使用多层自注意力和前馈层来处理输入序列并生成输出序列。 Transformer 功能强大且灵活,可应用于各种自然语言处理任务。
Transformer 的主要优势包括处理长度可变的输入序列和捕捉长距离
依赖关系的能力,以及学习数据中复杂关系和模式的灵活性和强大功能。 Transformer 的某些局限性包括其大型和计算要求高,以及训练需要大量标注数据。训练和优化 Transformer 的技巧包括选择适当的模型架构、使用正确的预处理和数据增强技术以及使用合适的评估指标。 Transformer 领域的常见挑战包括需要更高效的模型、开发鲁棒的评估指标以及将领域知识整合到 Transformer 模型中。
相关文章:
关于 Transformer 的11个常见面试题
Transformer 是如何工作的? Transformer 是一种深度学习算法,特别适用于自然语言处理(NLP)任务,如语言翻译、语言生成和语言理解。它们能够处理长度可变的输入序列并捕捉长距离依赖关系,使其在理解和处理自…...

OS多核多线程锁记录笔记
自旋锁作用 自旋锁的是为了保护两个核上的公共资源,也就是全局变量,只有在一方也就是一个核抢到了自选锁,才能对公共资源进行操作修改,当然还有其他形似的锁如互斥锁,这里不比较两者的区别,以前没有深入的去…...

nginx做TCP代理
要实现TCP代理,可以使用Nginx的stream模块。stream模块允许Nginx作为一个转发代理来处理TCP流量,包括TCP代理、负载均衡和SSL终止等功能。 以下是配置Nginx实现TCP代理的基本步骤: 在Nginx配置文件中添加stream块,并在该块中配置…...

python 异常处理 try
异常 我们常见的代码错误后 会出现此类异常 SyntaxError:语法错误 AttributeError:属性错误 IndexError:索引错误 TypeError:类型错误 NameError:变量名不存在错误 KeyError:映射中不存在的关键字…...

月入10万+管道收益,揭秘旅游卡运营的5个阶段!
网上的项目众多,只要用心,便能发现不少商机。在互联网上运营,关键在于理解项目的底层逻辑。今天,我们来揭秘旅游卡项目,如何做到月入10万。 1、先赚成本 开始项目时,首要任务是回本。不要急于求成&#x…...
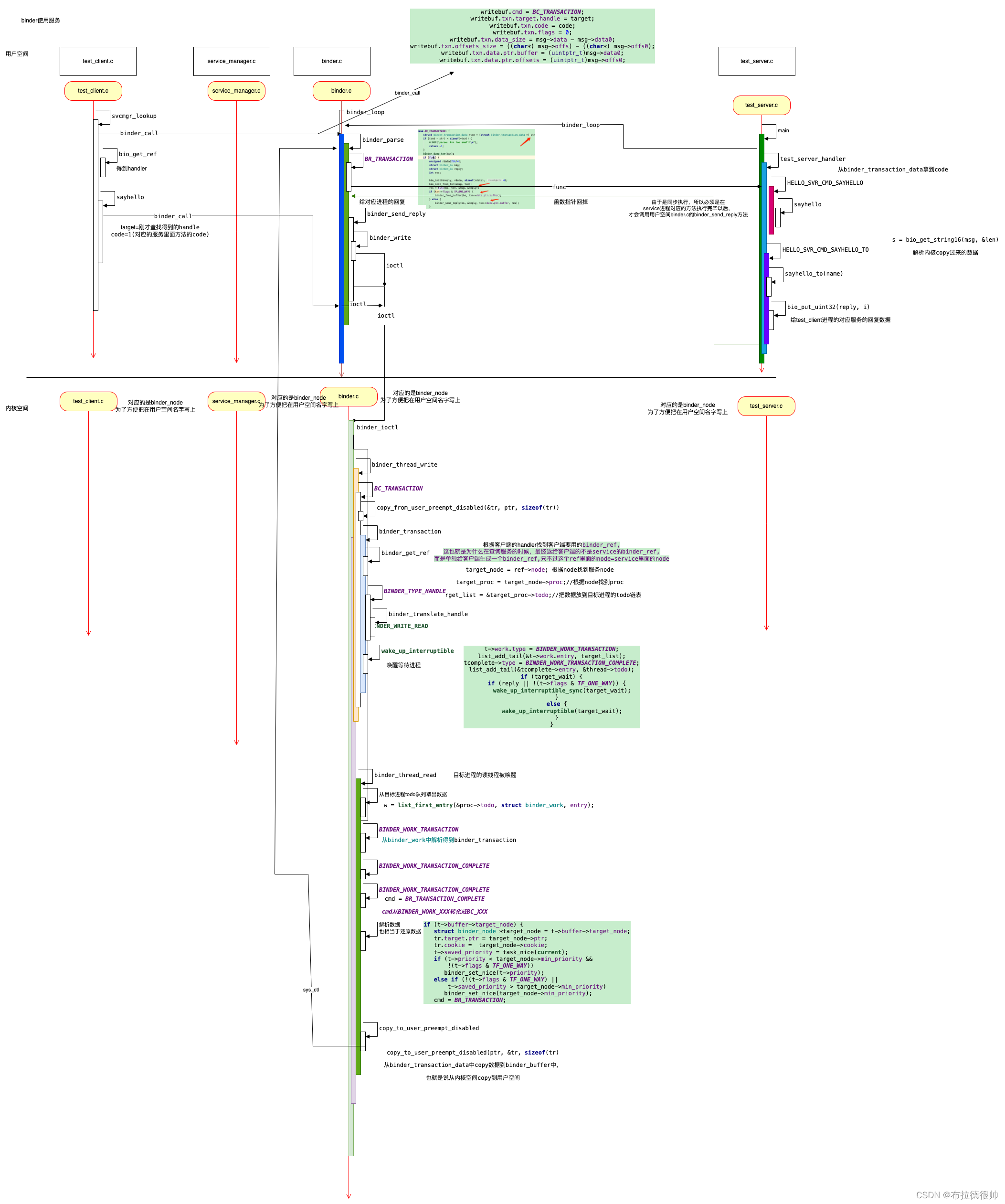
android_binder源码分析之_binder驱动使用服务
一,binder驱动源码分析,使用服务过程 uint32_t svcmgr_lookup(struct binder_state *bs, uint32_t target, const char *name) {uint32_t handle;unsigned iodata[512/4];struct binder_io msg, reply;bio_init(&msg, iodata, sizeof(iodata), 4);b…...

【波点音乐看广告】
import uiautomator2 as u2 import time from datetime import datetime import xml.etree.ElementTree as ET import re import os 连接设备 d u2.connect() os.system(‘adb shell chmod 775 /data/local/tmp/atx-agent’) os.system(‘adb shell /data/local/tmp/atx-age…...
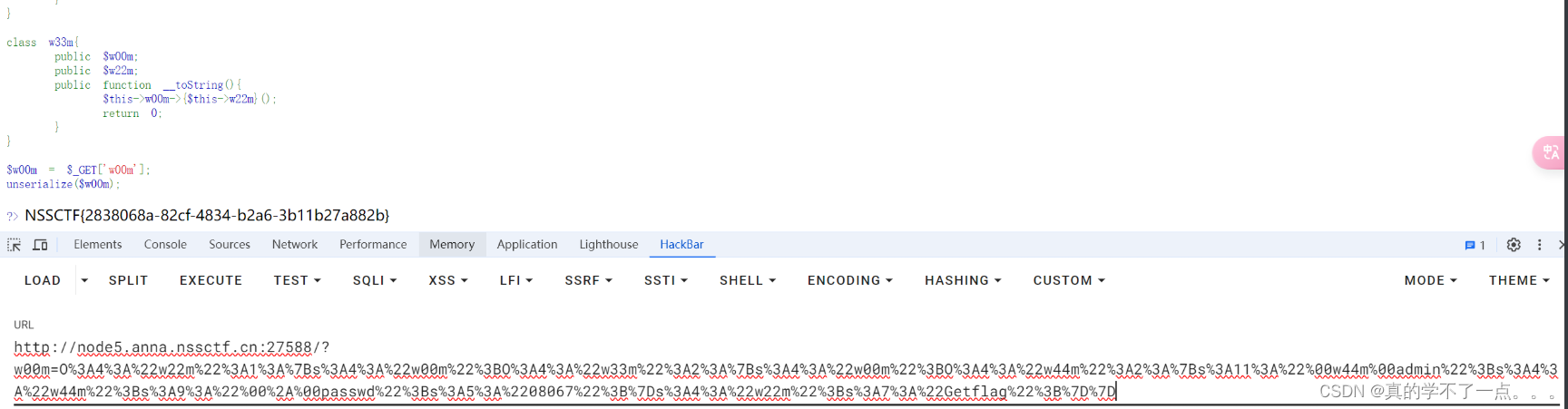
[SWPUCTF 2021 新生赛]pop
常见的魔术方法 魔术方法__construct() 类的构造函数,在对象实例化时调用 __destruct() 类的析构函数,在对象被销毁时被调用 __call() 在对象中调用一个不可访问的对象时被调用,比如一个对象被调用时,里面没有程序想调用的属性 …...
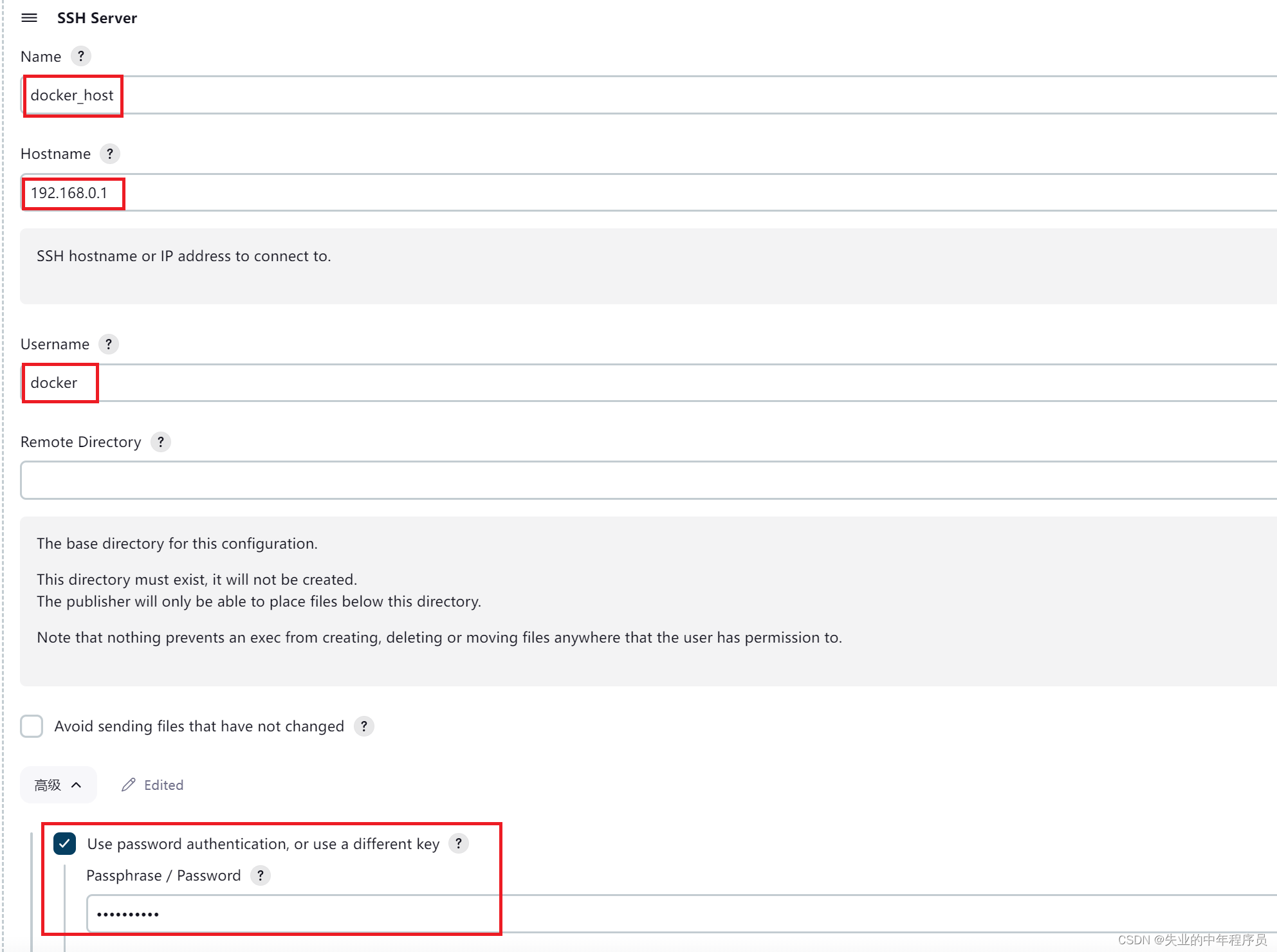
【DevOps】Jenkins + Dockerfile自动部署Maven(SpringBoot)项目
环境 docker_host192.168.0.1jenkins_host192.168.0.2 jenkins_host构建完成后把jar发布到docker_host,再通过dockerfile自动构建镜像,运行镜像 1 Jenkins安装 AWS EC2安装Jenkins:AWS EC2 JDK11 Jenkins-CSDN博客 AWS EC2上Docker安装…...

【C++】——入门基础知识超详解
目录 编辑 1.C关键字 2. 命名空间 2.1 命名空间定义 2.2 命名空间使用 命名空间的使用有三种方式: 注意事项 3. C输入&输出 示例 1:基本输入输出 示例 2:读取多个值 示例 3:处理字符串输入 示例 4:读…...

ChatGPT技术演进简介
chatGPT(chat generative pre-train transformer, 可以对话的预训练trasformer模型),讨论点: 1、chatGPT为什么突然火了 2、GPT 1.0、2.0、3.0、3.5 、4和4o区别和特性,在不同应用场景中如何选对模型 3、未…...

C语言 | Leetcode C语言题解之第114题二叉树展开为链表
题目: 题解: void flatten(struct TreeNode* root) {struct TreeNode* curr root;while (curr ! NULL) {if (curr->left ! NULL) {struct TreeNode* next curr->left;struct TreeNode* predecessor next;while (predecessor->right ! NULL)…...

Vue 子组件向父组件传值
1、使用自定义事件 ($emit) 这是Vue中最常用的子组件向父组件传递数据的方式。子组件通过触发一个自定义事件,并附加数据作为参数,父组件则监听这个事件并处理传递过来的数据。 子组件 (发送数据): <template><button click"…...
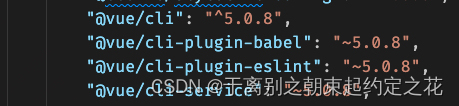
【前端笔记】Vue项目报错Error: Cannot find module ‘webpack/lib/RuleSet‘
网上搜了下发现原因不止一种,这里仅记录本人遇到的原因和解决办法,仅供参考 原因:因为某种原因导致本地package.json中vue/cli与全局vue/cli版本不同导致冲突。再次提示,这是本人遇到的,可能和大家有所不同,…...

edge浏览器的网页复制
一些网页往往禁止复制粘贴,本文方法如下: 网址最前面加上 read: (此方法适用于Microsoft Edge 浏览器)在此网站网址前加上read:进入阅读器模式即可...

视频播放器-Kodi
一、前言 Kodi 是一款开源免费的多媒体播放软件。Kodi 是由非营利性技术联盟 Kodi 基金会开发的免费开源媒体播放器应用程序。 Kodi是一款免费和开源(遵循GPL协议)的多媒体播放器和娱乐中心软件,由XBMC基金会开发。Kodi的主要功能是管理和播…...
Helm安装kafka3.7.0无持久化(KRaft 模式集群)
文章目录 2.1 Chart包方式安装kafka集群 5.开始安装2.2 命令行方式安装kafka集群 搭建 Kafka-UI三、kafka集群测试3.1 方式一3.2 方式二 四、kafka集群扩容4.1 方式一4.2 方式二 五、kafka集群删除 参考文档 [Helm实践---安装kafka集群 - 知乎 (zhihu.com)](https://zhuanlan.…...
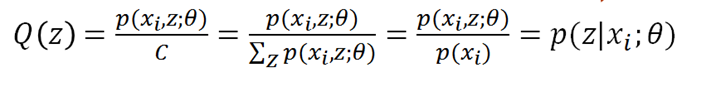
【机器学习】期望最大化(EM)算法
文章目录 一、极大似然估计1.1 基本原理1.2 举例说明 二、Jensen不等式三、EM算法3.1 隐变量 与 观测变量3.2 为什么要用EM3.3 引入Jensen不等式3.4 EM算法步骤3.5 EM算法总结 参考资料 EM是一种解决 存在隐含变量优化问题 的有效方法。EM的意思是“期望最大化(Exp…...

【Python】机器学习中的过采样和欠采样:处理不平衡数据集的关键技术
原谅把你带走的雨天 在渐渐模糊的窗前 每个人最后都要说再见 原谅被你带走的永远 微笑着容易过一天 也许是我已经 老了一点 那些日子你会不会舍不得 思念就像关不紧的门 空气里有幸福的灰尘 否则为何闭上眼睛的时候 又全都想起了 谁都别说 让我一个人躲一躲 你的承诺 我竟然没怀…...
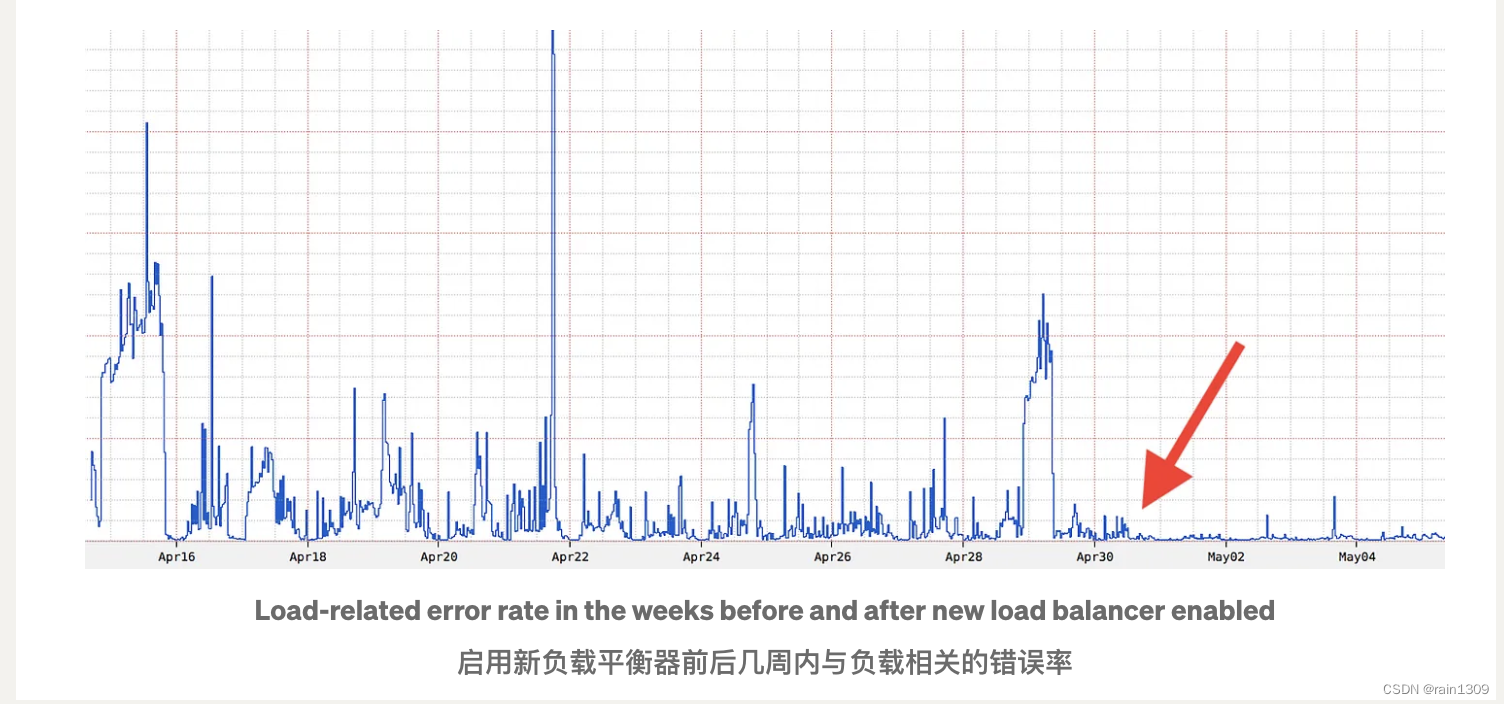
重新思考:Netflix 的边缘负载均衡
声明 本文是对Netflix 博客的翻译 前言 在先前关于Zuul 2开源的文章中,我们简要概述了近期在负载均衡方面的一些工作。在这篇文章中,我们将更详细地介绍这项工作的原因、方法和结果。 因此,我们开始从Zuul和其他团队那里学习&#…...

XLASSO:高维稀疏建模在极端事件尾部预测中的原理与实践
1. 项目概述:当极端事件遇见高维稀疏性在金融风险管理、气候极端事件预测或是网络流量异常检测中,我们常常面临一个共同的挑战:如何基于有限的历史极端观测数据,对未来可能发生的、更为罕见的“黑天鹅”事件做出可靠预测ÿ…...

Burp Suite企业级部署:从单机工具到安全团队基础设施
1. 为什么企业级Burp Suite部署不是“装个软件就完事”?很多人第一次接触Burp Suite,是在渗透测试入门课上——下载社区版、双击安装、抓个百度登录包,三分钟上手。但当我接手某金融客户内部红队平台建设时,发现他们把Burp当Chrom…...

别再只用XGBoost了!用Python手把手教你玩转Stacking和Blending模型融合
别再只用XGBoost了!用Python手把手教你玩转Stacking和Blending模型融合当你在Kaggle竞赛中反复调整XGBoost参数却始终无法突破0.01的AUC提升,或者在业务场景中发现单一模型对某些特殊样本总是预测失误时,或许该换个思路了——就像交响乐团需要…...
)
逆向分析第一步:手把手教你搭建WinDbg+VMware双机调试环境(含问题排查)
逆向工程实战:从零构建WinDbg与VMware双机调试环境调试器与虚拟机的组合是安全研究人员分析软件行为、挖掘漏洞的必备工具链。想象一下,当你需要观察一个可疑驱动程序如何与操作系统内核交互,或是追踪某个恶意样本在系统底层的活动轨迹时&…...

机器学习预测器评估随机数生成器最小熵:原理、实现与对比分析
1. 项目概述:当机器学习遇上随机性评估在信息安全领域,随机数生成器的质量是基石。无论是生成加密密钥、初始化向量,还是为各类协议提供随机性,其输出的不可预测性直接决定了整个系统的安全强度。我们如何量化这种“不可预测性”&…...

【稻米计数】基于matlab形态学稻米计数【含Matlab源码 15562期】
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

卖切削液怎么找客户?下游工厂在哪里
卖切削液找客户,本质是找用切削液的下游工厂,核心难点是拿到这些下游厂的名单和联系人。切削液不像消费品,它的消耗量和工厂的机床数量、加工班次直接挂钩——有金属切削车间的工厂才是真客户,没有机加工产线的工厂对你毫无意义。…...

基于注意力机制的科学数据压缩:层次化架构与误差边界保证
1. 项目概述:当科学计算遇上注意力机制在计算流体动力学、气候模拟、高能物理这些前沿科学领域,每一次仿真实验都可能产生TB甚至PB级别的数据。这些数据并非杂乱无章,它们通常诞生于高度结构化的多维网格之上,每个网格点承载着一个…...

鼎讯Smart-E3:为交通大动脉的通信“血管”提供专业测试方案
在铁路、高速公路等交通基础设施中,光纤网络如同神经系统,承载着指挥调度、安全监控等关键数据。一旦出现故障,如何快速、精准地定位问题,是保障交通大动脉畅通的核心。鼎讯Smart-E3光时域反射仪,作为一款集多种功能于…...

利用Taotoken模型广场为不同业务场景选择性价比最优的大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为不同业务场景选择性价比最优的大模型 在将大模型能力集成到实际业务的过程中,开发者常常面临一…...