PyTorch学习笔记:新冠肺炎X光分类
前言
目的是要了解pytorch如何完成模型训练
https://github.com/TingsongYu/PyTorch-Tutorial-2nd参考的学习笔记
数据准备
由于本案例目的是pytorch流程学习,为了简化学习过程,数据仅选择了4张图片,分为2类,正常与新冠,训练集2张,
验证集2张。标签信息存储于TXT文件中。具体目录结构如下:
注意:
covid-19的图可以找到但是no-finding两张图没有找到
covid-19-1
covid-19-2
no-finding的图随便照两张看着正常的,别问我哪个是正常的,我也不知道(❍ᴥ❍ʋ),需要改名字为00001215_000.png,00001215_001.png
├─imgs
│ ├─covid-19
│ │ auntminnie-a-2020_01_28_23_51_6665_2020_01_28_Vietnam_coronavirus.jpeg
│ │ ryct.2020200028.fig1a.jpeg
│ │
│ └─no-finding
│ 00001215_000.png
│ 00001215_001.png
│
└─labelstrain.txtvalid.txt
创建标签文件:
创建 train.txt 和 valid.txt 文件,并填入图片路径和标签信息
- train.txt:
covid-19/auntminnie-a-2020_01_28_23_51_6665_2020_01_28_Vietnam_coronavirus.jpeg 1
no-finding/00001215_000.png 0- valid.txt:
covid-19/ryct.2020200028.fig1a.jpeg 1
no-finding/00001215_001.png 0
完整代码示例:
以下是准备数据集、定义模型和训练模型的完整代码示例:
import os
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F# 自定义数据集类
class COVID19Dataset(Dataset):def __init__(self, img_dir, label_file, transform=None):self.img_dir = img_dirself.transform = transformself.img_labels = []with open(label_file, 'r') as f:lines = f.readlines()for line in lines:self.img_labels.append(line.strip().split())def __len__(self):return len(self.img_labels)def __getitem__(self, idx):img_path, label = self.img_labels[idx]img_path = os.path.join(self.img_dir, img_path)image = Image.open(img_path).convert('RGB')label = int(label)if self.transform:image = self.transform(image)return image, label# 图像预处理
transform = transforms.Compose([transforms.Resize((8, 8)),transforms.ToTensor()
])# 创建数据集和数据加载器
train_dataset = COVID19Dataset(img_dir='imgs', label_file='labels/train.txt', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True)valid_dataset = COVID19Dataset(img_dir='imgs', label_file='labels/valid.txt', transform=transform)
valid_loader = DataLoader(valid_dataset, batch_size=2, shuffle=False)# 定义简单卷积神经网络
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(3, 1, kernel_size=3) # 输入通道为3(RGB),输出通道为1,卷积核大小为3x3self.fc1 = nn.Linear(1 * 6 * 6, 2) # 全连接层,输入大小为6*6*1,输出大小为2(2类)def forward(self, x):x = self.conv1(x)x = F.relu(x)x = x.view(-1, 1 * 6 * 6) # 展平操作x = self.fc1(x)return xmodel = SimpleCNN()# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练函数
def train(model, train_loader, criterion, optimizer, epoch):model.train()running_loss = 0.0for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()running_loss += loss.item()if batch_idx % 10 == 9:print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}] Loss: {running_loss / 10:.6f}')running_loss = 0.0# 验证函数
def validate(model, valid_loader, criterion):model.eval()validation_loss = 0.0correct = 0with torch.no_grad():for data, target in valid_loader:output = model(data)validation_loss += criterion(output, target).item()pred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()validation_loss /= len(valid_loader.dataset)print(f'\nValidation set: Average loss: {validation_loss:.4f}, Accuracy: {correct}/{len(valid_loader.dataset)} ({100. * correct / len(valid_loader.dataset):.0f}%)\n')# 训练和验证
for epoch in range(1, 11):train(model, train_loader, criterion, optimizer, epoch)validate(model, valid_loader, criterion)
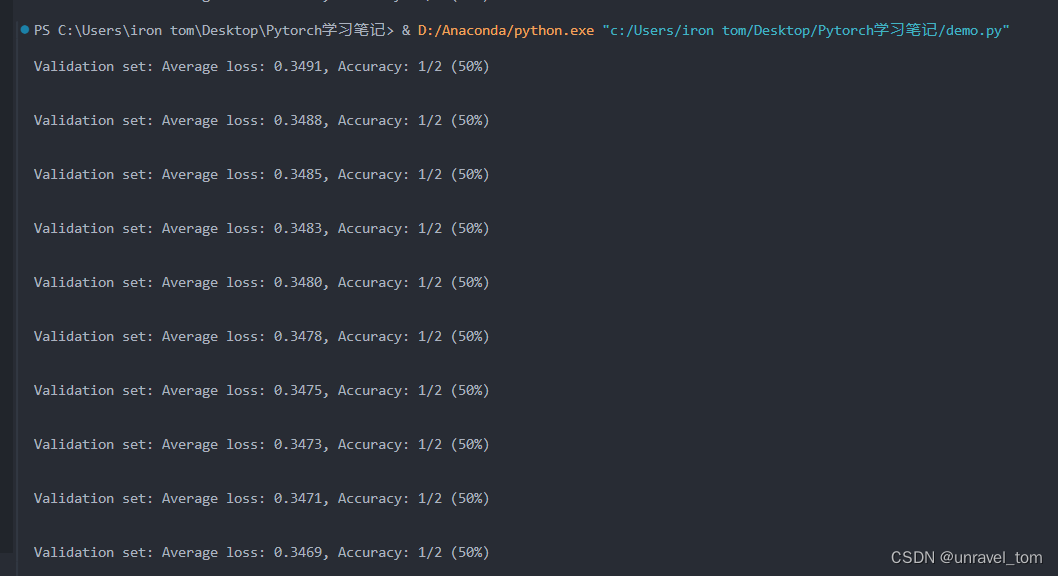
效果展示:
由于数据量少,随机性非常大,大家多运行几次,观察结果。不过本案例结果完全不重要!)可以观看Average loss变化,Accuracy由于训练数据过少几乎不会变化
知识点总结
1. 数据
- Q:要知道pytorch需要模型的格式
A:需要编写代码完成数据的读取,转换成模型能够读取的格式。在 PyTorch 中,读取数据通常通过自定义 Dataset 类和内置的 DataLoader 来实现。这种方法既灵活又高效,适用于各种类型的数据集。 - Q:自己如何编写Dataset?
A:编写一个自定义的 Dataset 类,需要继承 torch.utils.data.Dataset 并实现三个方法:__init__、__len__和__getitem__。
2. 模型
可参考:
从“卷积”、到“图像卷积操作”、再到“卷积神经网络”,“卷积”意义的3次改变_哔哩哔哩_bilibili
- Q: 卷积层,全连接层的作用是什么?
A: 卷积层提取特征,全连接层进行分类。- 卷积层:
- 卷积层的作用是提取输入图像的特征。
- 使用
3x3的卷积核进行卷积操作,可以捕捉到局部的空间特征。 - 卷积操作后的输出会产生一个新的特征图,这个特征图是卷积层提取到的特征表示。
- 全连接层:
- 全连接层的作用是将卷积层提取到的特征进行进一步的处理,最终输出分类结果。
- 在这个例子中,全连接层有两个神经元,分别输出两个分类的概率。
- 全连接层的输入被限制在
8x8,这意味着输入的特征图经过扁平化(flatten)后被映射到一个8x8的向量。
3. 优化
- Q:根据什么规则对模型的参数进行更新学习呢?
A:常用的方法:交叉熵损失函数(CrossEntropyLoss)、随机梯度下降法(SGD)和按固定步长下降学习率策略(StepLR)
4. 迭代
- Q:怎么进行模型迭代?
A: 有了模型参数更新的必备组件,接下来需要一遍又一遍地给模型喂数据,监控模型训练状态,这时候就需要for循环,不断地从dataloader里取出数据进行前向传播,反向传播,参数更新,观察loss、acc,周而复始。
总结
详细内容https://github.com/TingsongYu/PyTorch-Tutorial-2nd可查看,这是一篇读书笔记,与代码实现的分享。后续的笔记会以Q-A解决一些问题
相关文章:
PyTorch学习笔记:新冠肺炎X光分类
前言 目的是要了解pytorch如何完成模型训练 https://github.com/TingsongYu/PyTorch-Tutorial-2nd参考的学习笔记 数据准备 由于本案例目的是pytorch流程学习,为了简化学习过程,数据仅选择了4张图片,分为2类,正常与新冠…...
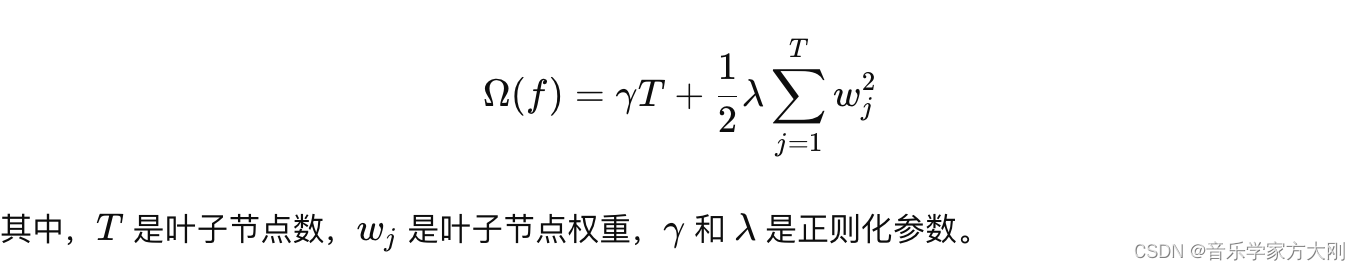
【Python】 XGBoost模型的使用案例及原理解析
原谅把你带走的雨天 在渐渐模糊的窗前 每个人最后都要说再见 原谅被你带走的永远 微笑着容易过一天 也许是我已经 老了一点 那些日子你会不会舍不得 思念就像关不紧的门 空气里有幸福的灰尘 否则为何闭上眼睛的时候 又全都想起了 谁都别说 让我一个人躲一躲 你的承诺 我竟然没怀…...

Java中print,println,printf的功能以及区别
在Java中,System.out.print, System.out.println, 和 System.out.printf 都是用于在控制台输出的方法,但它们在使用和功能上有所不同。 System.out.print: * 功能:将指定的内容输出到控制台,但不换行。 * 示例:Sy…...

vue3+electron+typescript 项目安装、打包、多平台踩坑记录
环境说明 这里的测试如果没有其他特别说明的,就是在win10/i7环境,64位 创建项目 vite官方是直接支持创建electron项目的,所以,这里就简单很多了。我们已经不需要向开始那样自己去慢慢搭建 yarn create vite这里使用yarn创建&a…...

实际案例分析
实际案例分析 一、数据准备与特征工程 1.1数据收集 在实际案例分析中,首先需要收集相关数据。数据来源可以包括公开数据集、企业内部数据、互联网爬虫抓取等。为了保证数据的质量和准确性,数据收集过程中需遵循以下原则: -针对性强&#…...
JAVA实现图书管理系统(初阶)
一.抽象出对象: 1.要有书架,图书,用户(包括普通用户,管理员用户)。根据这些我们可以建立几个包,来把繁杂的代码分开,再通过一个类来把这些,对象整合起来实现系统。说到整合…...
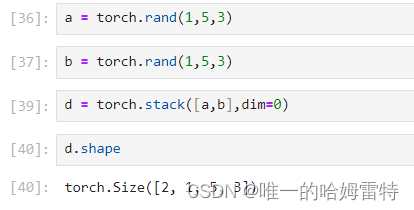
【Torch学习笔记】
作者:zjk 和 的区别是逐元素相乘,是矩阵相乘 cat stack 的区别 cat stack 是用于沿新维度将多个张量堆叠在一起的函数。它要求所有输入张量具有相同的形状,并在指定的新维度上进行堆叠。...

LeetCode算法题:42. 接雨水(Java)
题目描述 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 示例 1: 输入:height [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3…...
LINGO:存贮问题
存贮模型中的基本概念 模型: 基本要素: (1)需求率:单位时间内对某种物品的需求量,用D表示。 (2)订货批量:一次订货中,包含某种货物的数量,用 Q表…...

《微服务王国的守护者:Spring Cloud Dubbo的奇幻冒险》
5. 经典问题与解决方案 5.3 服务追踪与链路监控 在微服务架构的广袤宇宙中,服务间的调用关系错综复杂,如同一张庞大的星系网络。当一个请求穿越这个星系,经过多个服务节点时,如何追踪它的路径,如何监控整个链路的健康…...
npm 使用)
(九)npm 使用
视频链接:尚硅谷2024最新版微信小程序 文章目录 使用 npm 包自定义构建 npmVant Weapp 组件库的使用Vant Weapp 组件样式覆盖使用 npm 包 目前小程序已经支持使用 npm 安装第三方包,因为 node_modules 目录中的包不会参与小程序项目的编译、上传和打包, 因此在小程序项目中要…...
Thinkphp5内核宠物领养平台H5源码
源码介绍 Thinkphp5内核流浪猫流浪狗宠物领养平台H5源码 可封装APP,适合做猫狗宠物类的发信息发布,当然懂的修改一下,做其他信息发布也是可以的。 源码预览 源码下载 https://download.csdn.net/download/huayula/89361685...
一、Elasticsearch介绍与部署
目录 一、什么是Elasticsearch 二、安装Elasticsearch 三、配置es 四、启动es 1、下载安装elasticsearch的插件head 2、在浏览器,加载扩展程序 3、运行扩展程序 4、输入es地址就可以了 五、Elasticsearch 创建、查看、删除索引、创建、查看、修改、删除文档…...
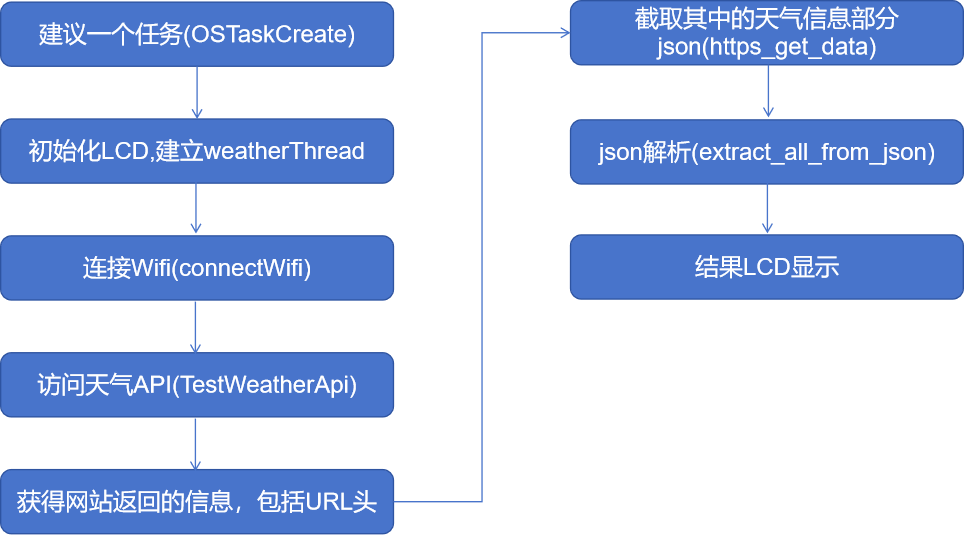
NL6621 实现获取天气情况
一、主要完成的工作 1、建立TASK INT32 main(VOID) {/* system Init */SystemInit();OSTaskCreate(TestAppMain, NULL, &sAppStartTaskStack[NST_APP_START_TASK_STK_SIZE -1], NST_APP_TASK_START_PRIO); OSStart();return 1; } 2、application test task VOID TestAp…...

SpringCloud配置文件bootrap
解决方案: 情况一、SpringBoot 版本 小于 2.4.0 版本,添加以下依赖 <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-context</artifactId> </dependency> 情况二、SpringBoot…...

经典面试题:进程、线程、协程开销问题,为什么进程切换的开销比线程的大?
上下文切换的过程? 上下文切换是操作系统在将CPU从一个进程切换到另一个进程时所执行的过程。它涉及保存当前执行进程的状态并加载下一个将要执行的进程的状态。下面是上下文切换的详细过程: 保存当前进程的上下文: 当操作系统决定切换到另…...

鸿蒙 DevEco Studio 3.1 Release 下载sdk报错的解决办法
鸿蒙 解决下载SDK报错的解决方法 最近在学习鸿蒙开发,以后也会记录一些关于鸿蒙相关的问题和解决方法,希望能帮助到大家。 总的来说一般有下面这样的报错 报错一: Components to install: - ArkTS 3.2.12.5 - System-image-phone 3.1.0.3…...

QGIS开发笔记(二):Windows安装版二次开发环境搭建(上):安装OSGeo4W运行依赖其Qt的基础环境Demo
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/139136356 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...

设计一套Kafka到RocketMQ的双写+双读技术方案,实现无缝迁移!
设计一套Kafka到RocketMQ的双写双读技术方案,实现无缝迁移! 1、背景2、方案3、具体逻辑 1、背景 假设你们公司本来线上的MQ用的主要是Kafka,现在要从Kafka迁移到RocketMQ去,那么这个迁移的过程应该怎么做呢?应该采用什…...
)
Mysql下Limit注入方法(此方法仅适用于5.0.0<mysql<5.6.6的版本)
SQL语句类似下面这样:(此方法仅适用于5.0.0<mysql<5.6.6的版本) SELECT field FROM table WHERE id > 0 ORDER BY id LIMIT (注入点) 问题的关键在于,语句中有 order by 关键字,mysql…...

【Java EE】IPv6
IPv6引言IPv6 地址表示IPv6 地址类型地址范围详解多播地址结构IPv6 与 IPv4 的主要区别IPv6 首部格式扩展首部IPv6 地址配置方式无状态地址自动配置(SLAAC)有状态配置(DHCPv6)手动配置邻居发现协议(NDP)IPv…...

如何免费将PPTX转换为HTML?探索纯JavaScript解决方案的完整指南
如何免费将PPTX转换为HTML?探索纯JavaScript解决方案的完整指南 【免费下载链接】PPTX2HTML Convert pptx file to HTML by using pure javascript 项目地址: https://gitcode.com/gh_mirrors/pp/PPTX2HTML 在数字化办公时代,PPTX2HTML作为一款纯…...
)
【DeepSeek本地部署终极指南】:20年AI工程师亲测的5步零失败落地法(含GPU资源优化秘籍)
更多请点击: https://codechina.net 第一章:DeepSeek本地部署的底层逻辑与价值重定义 DeepSeek系列大模型的本地化部署,本质上是对AI能力所有权、数据主权与计算自主权的三重回归。它并非简单地将远程API替换为本地服务,而是重构…...

机器学习海气耦合模型Ola:解耦训练与滞后集合预报实战
1. 项目概述:当机器学习遇见海气耦合在气候预测这个领域里摸爬滚打了十几年,我见过太多复杂的物理模型和让人头大的耦合方案。传统的海气耦合模型,比如那些基于物理方程组的数值模式,虽然机理清晰,但计算成本高得吓人&…...

2026照片去水印免费软件app详细教程:保姆级指南,一看就会
你是不是也遇到过这些尴尬时刻——辛辛苦苦刷到一张绝美壁纸,保存下来却发现右下角赫然挂着平台水印,当头像嫌脏、做素材嫌low;想从自己发的抖音视频里截一张封面图,结果水印刚好糊在脸上;又或者,老板甩过来…...

Taotoken在多模型API聚合中的稳定性与低延迟体验观测
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken在多模型API聚合中的稳定性与低延迟体验观测 在项目开发中,尤其是那些重度依赖大模型能力的应用,A…...
)
AI开发~OpenAI专家之路:构建企业级AI应用(第三部分·上)
第七部分:LLM应用测试与评估——确保质量的关键7.1 为什么需要测试LLM应用?大白话解释: 想象你开了一家餐厅,请了一位大厨(AI模型)来做菜。但是这位大厨有个特点——每次做出来的菜味道可能不太一样。有时候…...
)
毕业设计 深度学习yolo11电动车骑行规范识别系统(源码+论文)
文章目录0 前言1 项目运行效果2 课题背景2.1. 城市交通发展现状2.2. 电动车交通安全问题2.2.1 事故频发现状2.2.2 监管难点分析2.3. 技术发展背景2.3.1 计算机视觉技术进步2.3.2 智能交通系统发展2.4. 项目研究意义4.1 理论价值2.4.2 实践价值2.5. 国内外研究现状2.5.1 国际研究…...

如何永久解锁Cursor Pro功能:面向开发者的完整解决方案
如何永久解锁Cursor Pro功能:面向开发者的完整解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tr…...

Taotoken控制台用量看板提供的洞察与规划价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken控制台用量看板提供的洞察与规划价值 对于依赖大模型API进行开发的项目团队而言,成本与用量的不透明常常是管理…...