Keras深度学习框架第二十九讲:在自定义训练循环中应用KerasTuner超参数优化
1、简介
在KerasTuner中,HyperModel类提供了一种方便的方式来在可重用对象中定义搜索空间。你可以通过重写HyperModel.build()方法来定义和进行模型的超参数调优。为了对训练过程进行超参数调优(例如,通过选择适当的批处理大小、训练轮数或数据增强设置),程序员可以重写HyperModel.fit()方法,在该方法中你可以访问:
- hp对象,它是keras_tuner.HyperParameters的一个实例
- 由HyperModel.build()构建的模型
在“开始使用KerasTuner”一文的“调整模型训练”部分中给出了一个基本示例。
2、自定义训练循环的超参数调优
本文将通过重写HyperModel.fit()方法来子类化HyperModel类,并编写一个自定义训练循环。如果你想了解如何使用Keras编写一个自定义训练循环,可以参考指南《从零开始编写训练循环》。
首先,我们导入所需的库,并为训练和验证创建数据集。在这里,我们仅使用随机数据作为演示目的。
import keras_tuner
import tensorflow as tf
import keras
import numpy as npx_train = np.random.rand(1000, 28, 28, 1)
y_train = np.random.randint(0, 10, (1000, 1))
x_val = np.random.rand(1000, 28, 28, 1)
y_val = np.random.randint(0, 10, (1000, 1))
接着,我们将HyperModel类子类化为MyHyperModel。在MyHyperModel.build()中,我们构建一个简单的Keras模型来进行10个不同类别的图像分类。MyHyperModel.fit()接受几个参数,其签名如下所示:
def fit(self, hp, model, x, y, validation_data, callbacks=None, **kwargs):
hp 参数用于定义超参数。
model 参数是由 MyHyperModel.build() 返回的模型。
x, y, 和 validation_data 都是自定义参数。稍后我们将通过调用 tuner.search(x=x, y=y, validation_data=(x_val, y_val)) 来传递我们的数据给它们。你可以定义任意数量的这些参数并给它们自定义的名称。
callbacks 参数原本是为了与 model.fit() 一起使用的。KerasTuner 在其中放置了一些有用的 Keras 回调,例如,在模型最佳轮次时保存模型的回调。
在自定义训练循环中,我们将手动调用这些回调。但在调用它们之前,我们需要使用以下代码将我们的模型分配给它们,以便它们可以访问模型以进行保存。
for callback in callbacks:callback.model = model
在这个例子中,我们只调用了回调的 on_epoch_end() 方法来帮助我们保存模型的最佳状态。如果需要,你也可以调用其他回调方法。如果你不需要保存模型,那么你就不需要使用回调。
在自定义训练循环中,我们将通过将NumPy数据包装成tf.data.Dataset来调优数据集的批处理大小。请注意,你也可以在这里调优任何预处理步骤。此外,我们还调优了优化器的学习率。
我们将使用验证损失作为模型的评估指标。为了计算平均验证损失,我们将使用keras.metrics.Mean(),它在批次之间平均验证损失。我们需要返回验证损失,以便Tuner可以记录它。
class MyHyperModel(keras_tuner.HyperModel):def build(self, hp):"""Builds a convolutional model."""inputs = keras.Input(shape=(28, 28, 1))x = keras.layers.Flatten()(inputs)x = keras.layers.Dense(units=hp.Choice("units", [32, 64, 128]), activation="relu")(x)outputs = keras.layers.Dense(10)(x)return keras.Model(inputs=inputs, outputs=outputs)def fit(self, hp, model, x, y, validation_data, callbacks=None, **kwargs):# Convert the datasets to tf.data.Dataset.batch_size = hp.Int("batch_size", 32, 128, step=32, default=64)train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(batch_size)validation_data = tf.data.Dataset.from_tensor_slices(validation_data).batch(batch_size)# Define the optimizer.optimizer = keras.optimizers.Adam(hp.Float("learning_rate", 1e-4, 1e-2, sampling="log", default=1e-3))loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True)# The metric to track validation loss.epoch_loss_metric = keras.metrics.Mean()# Function to run the train step.@tf.functiondef run_train_step(images, labels):with tf.GradientTape() as tape:logits = model(images)loss = loss_fn(labels, logits)# Add any regularization losses.if model.losses:loss += tf.math.add_n(model.losses)gradients = tape.gradient(loss, model.trainable_variables)optimizer.apply_gradients(zip(gradients, model.trainable_variables))# Function to run the validation step.@tf.functiondef run_val_step(images, labels):logits = model(images)loss = loss_fn(labels, logits)# Update the metric.epoch_loss_metric.update_state(loss)# Assign the model to the callbacks.for callback in callbacks:callback.set_model(model)# Record the best validation loss valuebest_epoch_loss = float("inf")# The custom training loop.for epoch in range(2):print(f"Epoch: {epoch}")# Iterate the training data to run the training step.for images, labels in train_ds:run_train_step(images, labels)# Iterate the validation data to run the validation step.for images, labels in validation_data:run_val_step(images, labels)# Calling the callbacks after epoch.epoch_loss = float(epoch_loss_metric.result().numpy())for callback in callbacks:# The "my_metric" is the objective passed to the tuner.callback.on_epoch_end(epoch, logs={"my_metric": epoch_loss})epoch_loss_metric.reset_state()print(f"Epoch loss: {epoch_loss}")best_epoch_loss = min(best_epoch_loss, epoch_loss)# Return the evaluation metric value.return best_epoch_loss
现在,我们可以初始化Tuner了。在这里,我们使用Objective("my_metric", "min")作为需要最小化的指标。目标名称应该与你在传递给回调的on_epoch_end()方法的日志中使用的键一致。回调需要使用日志中的这个值来找到最佳的epoch以保存模型的检查点。
换句话说,当你自定义训练循环并决定在每个epoch结束时记录一些指标时,你需要确保你传递给on_epoch_end()方法的日志中包含一个键(例如"my_metric"),该键与你在Tuner中定义的Objective的名称相匹配。这样,Tuner就可以使用这个指标来跟踪模型性能的变化,并决定何时保存最佳的模型检查点。
在上面的例子中,如果我们在每个epoch结束时计算了验证损失,并将其作为"val_loss"键传递给on_epoch_end()方法,那么我们需要在初始化Tuner时使用Objective("val_loss", "min"),因为我们的目标是找到具有最小验证损失的epoch。
tuner = keras_tuner.RandomSearch(objective=keras_tuner.Objective("my_metric", "min"),max_trials=2,hypermodel=MyHyperModel(),directory="results",project_name="custom_training",overwrite=True,
)
我们通过将我们在MyHyperModel.fit()方法的签名中定义的参数传递给tuner.search()来开始搜索。
tuner.search(x=x_train, y=y_train, validation_data=(x_val, y_val))
最后,我们可以检索结果。
在Keras Tuner中,一旦tuner.search()方法执行完毕,你就可以从Tuner对象中检索最佳模型、最佳超参数配置以及搜索结果的历史记录。这些结果可以帮助你理解模型性能如何随着超参数的变化而变化,并为你提供最佳的模型配置以进行进一步的应用或部署。
通常,你可以使用tuner.get_best_models()来获取一个或多个最佳模型,使用tuner.get_best_hyperparameters()来获取最佳超参数配置,以及使用tuner.results_summary()来查看搜索结果的摘要。
best_hps = tuner.get_best_hyperparameters()[0]
print(best_hps.values)best_model = tuner.get_best_models()[0]
best_model.summary()
3、总结
使用Keras Tuner进行自定义训练循环超参数调优的过程可以大致分为以下几个步骤:
3.1. 安装Keras Tuner
首先,确保你已经安装了Keras Tuner库。可以使用pip进行安装:
pip install keras-tuner
3.2. 定义继承自keras_tuner.HyperModel的类
你需要定义一个继承自keras_tuner.HyperModel的类,并在其中定义build和fit方法。
build方法:用于定义模型的架构,并使用hp参数设置超参数的搜索空间。fit方法:用于模型的训练过程,它接受hp参数以及训练数据和其他必要的参数。
import tensorflow as tf
from tensorflow.keras import layers
from keras_tuner import HyperModelclass MyHyperModel(HyperModel):def build(self, hp):model = tf.keras.Sequential()# 示例:定义含可调参数的全连接层hp_units = hp.Int('units', min_value=32, max_value=512, step=32)model.add(layers.Dense(units=hp_units, activation='relu'))# ... 其他层 ...model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])return modeldef fit(self, hp, x_train, y_train, **kwargs):model = self.build(hp)model.fit(x_train, y_train, epochs=10, **kwargs)# 假设这里只进行一轮训练作为示例,实际中可能需要多轮return {'loss': model.evaluate(x_train, y_train)[0], 'accuracy': model.evaluate(x_train, y_train)[1]}
3.3. 准备数据和回调
准备好你的训练数据和验证数据,以及可能需要的回调函数(如模型保存、早停等)。
3.4. 使用Tuner进行搜索
实例化你的Tuner类(如RandomSearch、Hyperband等),并传入你的HyperModel、数据以及搜索的目标(如最小化验证损失)。
from keras_tuner import RandomSearchtuner = RandomSearch(MyHyperModel(),objective='val_loss',max_trials=10, # 搜索的最大试验次数executions_per_trial=3, # 每个试验的重复次数directory='my_dir', # 结果保存目录project_name='my_project'
)tuner.search(x_train, y_train,validation_data=(x_val, y_val),epochs=10, # 注意这里的epochs仅用于fit方法中的一轮训练callbacks=[...]) # 可能的回调,如ModelCheckpoint
3.5. 检索结果
搜索完成后,你可以从Tuner对象中检索最佳模型、最佳超参数配置以及搜索结果的历史记录。
best_hps = tuner.get_best_hyperparameters(num_trials=1)[0]
print(f'Best hyperparameters: {best_hps.values}')best_model = tuner.get_best_models(num_models=1)[0]
# 使用best_model进行预测或进一步评估
3.6. 可视化结果
Keras Tuner提供了丰富的可视化支持,你可以使用TensorBoard等工具来查看搜索过程的详细结果。
使用Keras Tuner进行自定义训练循环的超参数调优涉及安装Keras Tuner库,定义继承自HyperModel的类并实现其build和fit方法,准备训练数据和验证数据以及可能的回调。随后,实例化Tuner类并传入定义的HyperModel和数据,开始搜索最佳超参数组合。搜索完成后,可以通过Tuner的接口检索到最佳的超参数和模型。整个调优过程中需要注意设置合理的搜索空间、试验次数,并使用独立的验证集来评估模型性能,最后可以利用可视化工具查看调优结果。
相关文章:

Keras深度学习框架第二十九讲:在自定义训练循环中应用KerasTuner超参数优化
1、简介 在KerasTuner中,HyperModel类提供了一种方便的方式来在可重用对象中定义搜索空间。你可以通过重写HyperModel.build()方法来定义和进行模型的超参数调优。为了对训练过程进行超参数调优(例如,通过选择适当的批处理大小、训练轮数或数…...

手机App收集个人信息,用户是否有权拒绝?
其实过度收集个人信息这件事,在APP上随处可见,泛滥成灾。 前两天有个不疼不痒的小软件“小鸡词典”,因为收集个人信息受到了处罚。 小鸡词典因划分为工具类APP过度收集隐私(手机号、地理位置定位)、不同意政策不能用…...

云下到云上,丽迅物流如何实现数据库降本50% | OceanBase案例
在2024年3月20日的首场OceanBase数据库城市行活动中,专注于物流及供应链解决方案的丽迅物流的架构师阳磊,围绕“OB Cloud在丽迅物流的实践”这一主题,进行了精彩的演讲。本文为此次演讲的内容回顾。 在丽迅物流(Lesoon Logistics…...

STM32无源蜂鸣器播放音乐
开发板:野火霸天虎V2 单片机:STM32F407ZGT6 开发软件:MDKSTM32CubeMX 文章目录 前言一、找一篇音乐的简谱二、确定音调三、确定节拍四、使用STM32CubeMX生成初始化代码五、代码分析 前言 本实验使用的是低电平触发的无源蜂鸣器 无源蜂鸣器是…...

【云原生】kubernetes中的认证、权限设置---RBAC授权原理分析与应用实战
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

【Python设计模式04】策略模式
策略模式(Strategy Pattern)是一种行为型设计模式,它定义了一系列算法,并将每个算法封装起来,使它们可以互相替换。策略模式让算法的变化不会影响使用算法的客户端,使得算法可以独立于客户端的变化而变化。…...

私域用户画像分析:你必须知道的3个关键点!
在互联网时代的变革中,私域流量成为越来越多企业的关注焦点。而了解私域用户画像是建立精准营销策略的关键一步。 今天,就给大家分享私域用户画像分析的三个关键点,让大家都能更好地进行用户画像分析。 1、市场需求 理解市场需求是把握用户…...
【MATLAB源码-第74期】基于matlab的OFDM-IM索引调制系统不同频偏误码率对比,对比OFDM系统。
操作环境: MATLAB 2022a 1、算法描述 OFDM-IM索引调制技术是一种新型的无线通信技术,它将正交频分复用(OFDM)和索引调制(IM)相结合,以提高频谱效率和系统容量。OFDM-IM索引调制技术的基本思想…...

优于其他超导量子比特数千倍!猫态量子比特实现超过十秒的受控比特翻转时间
内容来源:量子前哨(ID:Qforepost) 文丨娴睿/慕一 排版丨沛贤 深度好文:2000字丨8分钟阅读 摘要:量子计算公司Alice & Bob和QUANTIC团队(国立巴黎高等矿业学院PSL分校、巴黎高等师范学院和…...
QtXlsx库编译使用
文章目录 一、前言二、Windows编译使用2.1 用法①:QtXlsx作为Qt的附加模块2.1.1 检验是否安装Perl2.1.2 下载并解压QtXlsx源码2.1.3 MinGW 64-bit安装模块2.1.4 测试 2.2 用法②:直接使用源码 三、Linus编译使用3.1、安装Qt5开发软件包:qtbas…...

LeetCode题练习与总结:二叉树的层序遍历Ⅱ--107
一、题目描述 给你二叉树的根节点 root ,返回其节点值 自底向上的层序遍历 。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历) 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[…...
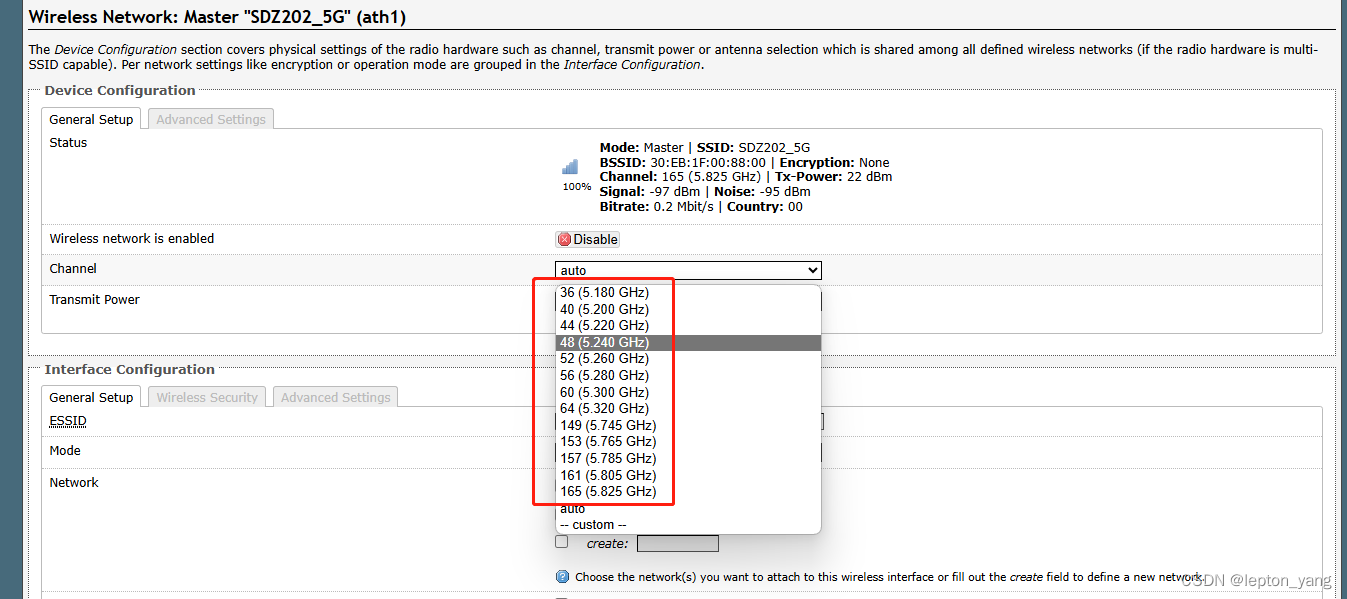
WIFI国家码设置的影响
记录下工作中关于国家码设置对WIFI的影响,以SKYLAB的SKW99和SDZ202模组为例进行说明。对应到日常,就是我们经常提及手机是“美版”“港版”等,它们的wifi国家码是不同的,各版本在wifi使用中遇到的各种情况与下面所述是吻合的。 现…...

2024年软考高项-信息系统管理师介绍-备考-考试内容-通过攻略
介绍 以下是计算机软件考试的资格设置,本文说的是高级资格中的信息系统项目管理师(简称"高项"),是比较热门和好考的选择,与中级的"系统集成项目管理工程师"有大部分的知识重叠交叉,中级考了"系统集成项…...

Python知识点复习
文章目录 Input & OutputVariables & Data typesPython字符串重复(字符串乘法)字符串和数字连接在一起print时,要强制类型转换int为str用input()得到的用户输入,是str类型,如果要以int形式计算的话,…...
GeoScene产品学习视频收集
1、易智瑞运营的极思课堂https://www.geosceneonline.cn/learn/library 2、历年易智瑞技术公开课视频资料 链接:技术公开课-易智瑞信息技术有限公司,GIS/地理信息系统,空间分析-制图-位置智能-地图 3、一些关于GeoScene系列产品和技术操作的视…...

51单片机的最小系统详解
51单片机的最小系统详解 1. 引言 在嵌入式系统中,51单片机被广泛应用于各种小型控制器和嵌入式开发板中。相信很多人都接触过51单片机,但是对于51单片机的最小系统却了解得不够深入。本文将从振荡电路、电源模块、复位电路、LED指示灯和调试接口五个方面详细介绍51单片机的…...

路径规划搜路算法有哪些?
路径规划搜索算法是帮助移动机器人或自动化系统在环境中从起点导航至终点的计算方法。以下是一些常见的路径规划搜索算法: Dijkstra算法:一种经典的最短路径搜索算法,适用于没有负权边的图。 A*算法:一种启发式搜索算法ÿ…...

Hadoop学习之hdfs的操作
Hadoop学习之hdfs的操作 1.将HDFS中的文件复制到本地 package com.shujia.hdfs;import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.junit.After; import org.junit.Before; import org.j…...

DBAPI怎么进行数据格式转换
DBAPI如何进行数据格式的转换 假设现在有个API,根据学生id查询学生信息,访问API查看数据格式如下 {"data":[{"name":"Michale","phone_number":null,"id":77,"age":55}],"msg"…...

Oracle JSON 函数详解与实战
Oracle 数据库提供了丰富的 JSON 函数集,使得开发者可以高效地处理 JSON 数据。本文将详细介绍这些函数,包括它们的语法、使用场景、具体示例,以及在实际项目中的应用。 文章目录 JSON_VALUE语法参数说明示例 JSON_QUERY语法示例 JSON_TABLE语…...

矢量图转换实战指南:5步实现PNG到SVG的无损升级方案
矢量图转换实战指南:5步实现PNG到SVG的无损升级方案 【免费下载链接】vectorizer Potrace based multi-colored raster to vector tracer. Inputs PNG/JPG returns SVG 项目地址: https://gitcode.com/gh_mirrors/ve/vectorizer 在数字设计领域,你…...

如何快速掌握开源笔记工具:Xournal++ 终极使用指南
如何快速掌握开源笔记工具:Xournal 终极使用指南 【免费下载链接】xournalpp Xournal is a handwriting notetaking software with PDF annotation support. Written in C with GTK3, supporting Linux (e.g. Ubuntu, Debian, Arch, SUSE), macOS and Windows 10. S…...

零基础入门ModTheSpire:5分钟学会《杀戮尖塔》模组加载神器
零基础入门ModTheSpire:5分钟学会《杀戮尖塔》模组加载神器 【免费下载链接】ModTheSpire External mod loader for Slay The Spire 项目地址: https://gitcode.com/gh_mirrors/mo/ModTheSpire 想要为《杀戮尖塔》注入全新活力,但担心破坏原版游戏…...

终极指南:如何使用qmc-decoder快速解密QQ音乐加密音频文件
终极指南:如何使用qmc-decoder快速解密QQ音乐加密音频文件 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾经从QQ音乐下载了心爱的歌曲,却发…...

RePKG架构深度解析:解密Wallpaper Engine资源处理的核心技术
RePKG架构深度解析:解密Wallpaper Engine资源处理的核心技术 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 在数字内容创作领域,资源打包与纹理处理是图形应…...

Windows远程桌面免费解锁指南:家庭版也能享受多用户并发连接
Windows远程桌面免费解锁指南:家庭版也能享受多用户并发连接 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 你是否曾经因为Windows家庭版无法使用远程桌面而烦恼?或者需要多人同时访问同一…...

JMeter TPS真相:业务吞吐量 vs 采样均值的全栈解剖
1. 为什么TPS不是“点一下就出来的数字”,而是压测成败的命门刚接手公司电商大促前的压测任务时,我盯着JMeter报告里那个醒目的TPS(Transactions Per Second)数值,心里还觉得挺踏实——毕竟它看起来比“线程数”“响应…...

范畴论视角下的机器学习系统:从代数结构到工程实践
1. 机器学习系统:从孤立元素到结构化网络的视角转变我们每天都在和数据、算法、模型打交道。数据清洗、特征工程、模型训练、评估部署,这些环节构成了一个典型的机器学习项目流程。长久以来,我们习惯于将这些元素视为独立的、线性的步骤&…...

在线机器学习在时序异常检测中的应用:OML-AD原理与工程实践
1. 项目概述:当异常检测遇上实时数据流在运维监控、金融风控或物联网传感器分析中,我们常常需要盯着一条条不断涌出的时间序列数据,从中揪出那些“不对劲”的点——也就是异常。传统的玩法,比如训练一个SARIMA或者Prophet模型&…...

机器学习势函数与反向蒙特卡洛在GeO2玻璃中程有序结构解析中的对比研究
1. 项目概述:当机器学习势函数遇上反向蒙特卡洛在材料模拟的世界里,我们常常面临一个两难选择:是相信基于物理化学原理构建的“经验”模型,还是完全服从实验数据的“拟合”结果?这个问题在网络形成玻璃,比如…...