决策树与机器学习实战【代码为主】
文章目录
- 🛴🛴引言
- 🛴🛴决策树使用案例
- 🛴🛴`numpy`库生成模拟数据案例
- 🛴🛴决策树回归问题
- 🛴🛴决策树多分类问题
🛴🛴引言
决策树是一种经典的机器学习算法,在数据挖掘和预测分析中广泛应用。它是一种基于树结构进行决策的模型,可以用于分类和回归问题。
决策树的基本原理是通过对特征进行逐步划分,生成一棵树形结构,以实现对数据的分类或回归。从根节点开始,根据特征的不同取值,将数据划分到不同的子节点中。这个划分过程是基于一些衡量指标(例如信息增益、基尼系数等),目标是在每个节点上选择最佳的划分属性。
决策树的生成过程通常遵循下列步骤:
- 特征选择:从给定的特征集合中选择最佳的特征作为当前节点的划分属性。衡量指标常包括信息增益、基尼系数等。
- 树的构建:根据选择的划分属性,将数据集划分为多个子集,并生成相应的子节点。如果某个子集中的样本属于同一类别或达到终止条件,则将该节点标记为叶子节点。
- 递归过程:对于每个子节点,重复步骤1和步骤2,直到所有数据划分完毕或达到停止条件。
- 剪枝:为了避免过拟合,可以对生成的决策树进行剪枝。剪枝可以通过预剪枝和后剪枝两个方法实现,其中预剪枝是在生成树的过程中决定是否分裂节点,后剪枝是在生成树之后进行节点合并。
决策树的优点包括易于理解和解释、能够处理离散和连续特征、具有较好的可解释性等。此外,决策树还可以处理缺失值和异常值。

然而,决策树也有一些限制,包括容易过拟合、对特征空间划分较为敏感等。为了解决过拟合问题,可以通过剪枝、调整参数等方法进行优化。
在使用决策树时,需要注意以下几点:
- 特征选择:选择合适的特征作为划分属性对决策树的性能至关重要。
- 停止条件:设置递归停止的条件,防止过度拟合。常见的停止条件包括叶子节点中样本数量的最小值、树的最大深度、信息增益或基尼系数的阈值等。
- 数据预处理:决策树对数据的尺度不敏感,通常不需要进行归一化或标准化处理。
- 模型评估:决策树的常见评估指标包括准确率、精确率、召回率、F1分数等。
总之,决策树是一种直观且易于理解的机器学习模型,适用于一般的分类和回归问题。理解决策树的基本原理和构建过程,有助于更好地应用和解释该算法,为实际问题提供有效的预测和决策。

🛴🛴决策树使用案例
以下是一个使用真实数据集的示例代码,数据类型是csv,文件名称是data.csv:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics
from matplotlib import pyplot as plt
from sklearn import tree# 读取数据集
data = pd.read_csv('data.csv')# 分割特征和目标变量
X = data.drop('target', axis=1)
y = data['target']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建并拟合决策树模型
model = DecisionTreeClassifier()
model.fit(X_train, y_train)# 使用模型进行预测
y_pred = model.predict(X_test)# 计算模型准确率
accuracy = metrics.accuracy_score(y_test, y_pred)
print('模型准确率:', accuracy)# 可视化决策树
fig = plt.figure(figsize=(10, 10))
_ = tree.plot_tree(model, feature_names=X.columns, class_names=['0', '1'], filled=True)
plt.show()
导入必要的库:
pandas用于数据分析和处理。DecisionTreeClassifier用于构建决策树模型。train_test_split用于将数据集划分为训练集和测试集。metrics提供了一些评估模型性能的方法。tree用于可视化决策树。
读取数据集:
- 使用
read_csv()函数读取名为data.csv的数据文件。
分割特征和目标变量:
- 使用
drop()函数从数据中移除目标变量,得到特征数据集X。- 将目标变量保存在
y中。
划分训练集和测试集:
- 使用
train_test_split()函数将数据集划分为训练集和测试集,其中测试集占比为0.2。
创建并拟合决策树模型:
- 创建
DecisionTreeClassifier类的实例作为模型。- 使用
fit()方法拟合模型,传入训练集的特征数据和目标变量。
使用模型进行预测:
- 调用已训练的模型的
predict()方法,传入测试集的特征数据,得到预测结果y_pred。
计算模型准确率:
- 使用
accuracy_score()函数计算模型在测试集上的准确率,传入真实的目标变量y_test和预测值y_pred。
可视化决策树:
- 创建一个图形对象
fig。- 使用
tree.plot_tree()方法绘制决策树,参数包括模型、特征名称和类别名称。- 使用
plt.show()方法显示绘制好的图形。
请确保在运行代码之前,将数据集文件
data.csv放在与代码文件相同的目录下。这段代码展示了如何使用决策树模型对真实数据集进行分类预测,并可视化决策树结构。希望这可以帮助您更好地理解决策树模型的应用。如有任何疑问,请随时提问。
🛴🛴numpy库生成模拟数据案例
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
from sklearn import metrics
from sklearn import tree# 生成特征数据
X = np.random.rand(100, 3) # 生成100个样本,每个样本有3个特征# 生成目标变量
y = np.random.choice([0, 1], size=100) # 生成100个目标变量,取值为0或1# 创建数据框
data = pd.DataFrame(X, columns=['feature1', 'feature2', 'feature3'])
data['target'] = y# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建并拟合决策树模型
model = DecisionTreeClassifier()
model.fit(X_train, y_train)# 使用模型进行预测
y_pred = model.predict(X_test)# 计算模型准确率
accuracy = metrics.accuracy_score(y_test, y_pred)
print('模型准确率:', accuracy)# 可视化决策树
fig = plt.figure(figsize=(10, 10))
_ = tree.plot_tree(model, feature_names=data.columns[:-1], class_names=['0', '1'], filled=True)
plt.show()
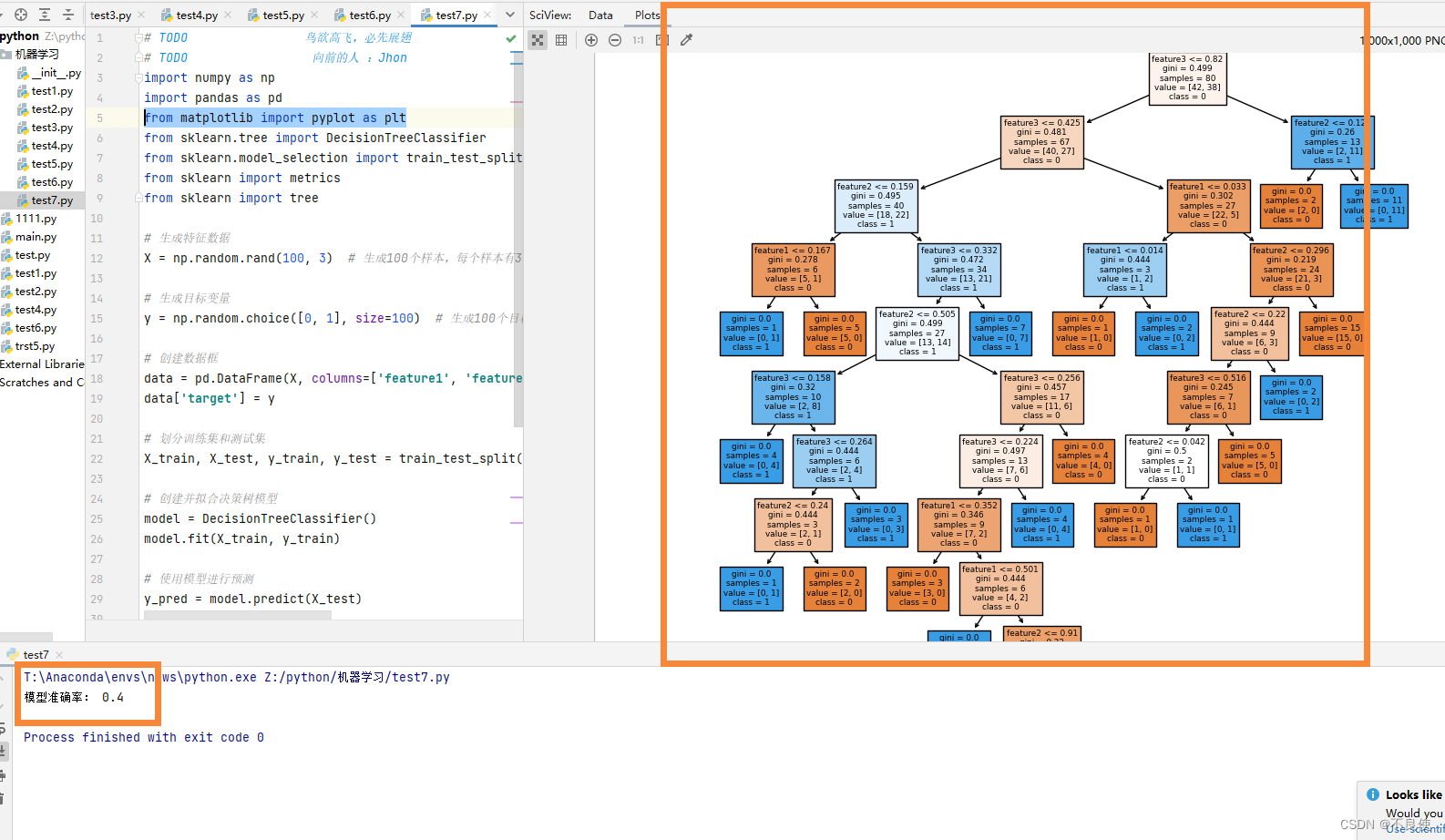


这段代码生成了具有3个特征和一个目标变量的模拟数据,并使用决策树模型进行学习和预测。你可以调整生成数据的方式,修改特征数量、样本数量,以及目标变量的取值等。
导入必要的库:
numpy用于生成随机数组作为特征数据。pandas用于创建和处理数据框。DecisionTreeClassifier用于创建决策树模型。train_test_split用于将数据集划分为训练集和测试集。metrics提供了一些评估模型性能的方法。tree用于可视化决策树。
生成特征数据:
- 使用
numpy.random.rand()函数生成一个形状为(100, 3)的随机数组,表示100个样本,每个样本有3个特征。
生成目标变量:
- 使用
numpy.random.choice()函数生成一个长度为100的随机数组,随机选择值为0或1作为目标变量。
创建数据框:
- 使用
pandas.DataFrame()函数将特征数据X和目标变量y组合成一个数据框,特征列的名称为feature1、feature2、feature3,目标变量列的名称为target。
划分训练集和测试集:
- 使用
train_test_split()函数将数据集划分为训练集和测试集,其中测试集占比为0.2。
创建并拟合决策树模型:
- 创建
DecisionTreeClassifier类的实例作为模型。- 使用
fit()方法拟合模型,传入训练集的特征数据X_train和目标变量y_train。
使用模型进行预测:
- 调用已训练的模型的
predict()方法,传入测试集的特征数据X_test,得到预测结果y_pred。
计算模型准确率:
- 使用
accuracy_score()函数计算模型在测试集上的准确率,传入真实目标变量y_test和预测值y_pred。
可视化决策树:
- 创建一个图形对象
fig。- 使用
tree.plot_tree()方法绘制决策树,参数包括模型、特征名称和类别名称。- 使用
plt.show()方法显示绘制好的图形。
这段代码演示了如何使用决策树模型对生成的模拟数据进行分类预测,并可视化生成的决策树结构
🛴🛴决策树回归问题
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from matplotlib import pyplot as plt# 生成特征数据
X = np.random.rand(100, 1) # 生成100个样本,每个样本有1个特征# 生成目标变量
y = np.sin(2 * np.pi * X) + np.random.normal(0, 0.1, size=(100, 1)) # 生成目标变量,使用正弦函数,并添加噪声# 创建并拟合决策树回归模型
model = DecisionTreeRegressor()
model.fit(X, y)# 预测新数据
new_data = np.linspace(0, 1, 100).reshape(-1, 1)
prediction = model.predict(new_data)# 可视化结果
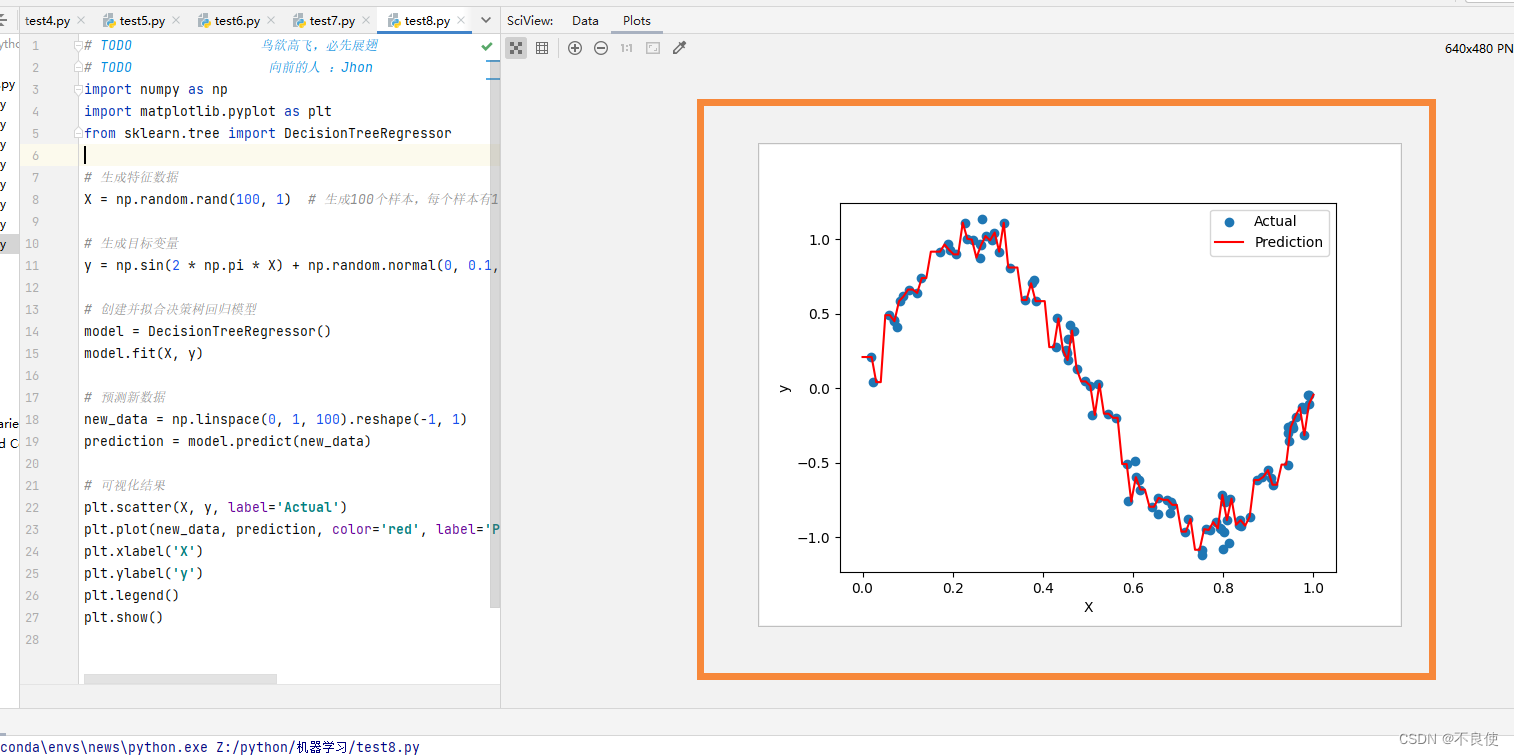
plt.scatter(X, y, label='Actual')
plt.plot(new_data, prediction, color='red', label='Prediction')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.show()

-
导入必要的库:
numpy用于生成随机数和数学计算。matplotlib.pyplot用于绘制图形。DecisionTreeRegressor用于创建决策树回归模型。
-
生成特征数据:
- 使用
numpy.random.rand()生成一个形状为(100, 1)的随机数组,表示100个样本,每个样本有1个特征。
- 使用
-
生成目标变量:
- 使用正弦函数
np.sin()生成目标变量y,并添加服从正态分布的噪声np.random.normal()。
- 使用正弦函数
4- 创建并拟合决策树回归模型:
- 创建
DecisionTreeRegressor类的实例作为回归模型。 - 使用
fit()方法拟合模型,传入特征数据X和目标变量y。
- 预测新数据:
- 生成一组新的特征数据
new_data,使用np.linspace()生成0到1之间的等差数列。 - 使用已训练的模型的
predict()方法对新数据进行回归预测,得到预测结果prediction。
- 生成一组新的特征数据
- 可视化结果:
- 使用
plt.scatter()绘制原始数据散点图。 - 使用
plt.plot()绘制预测结果曲线。 - 设置横轴和纵轴标签。
- 使用
plt.legend()显示图例。 - 使用
plt.show()显示图形。
- 使用
该代码演示了如何使用决策树回归模型来解决回归问题,并使用可视化方式展示预测结果。
🛴🛴决策树多分类问题
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from matplotlib import pyplot as plt# 生成特征数据
X = np.random.rand(100, 2) # 生成100个样本,每个样本有2个特征# 生成目标变量
y = np.random.randint(0, 3, size=100) # 生成目标变量,取值为0、1、2# 创建并拟合决策树分类模型
model = DecisionTreeClassifier()
model.fit(X, y)# 预测新数据
new_data = np.random.rand(10, 2) # 生成10个新数据样本
prediction = model.predict(new_data)print('预测结果:', prediction)
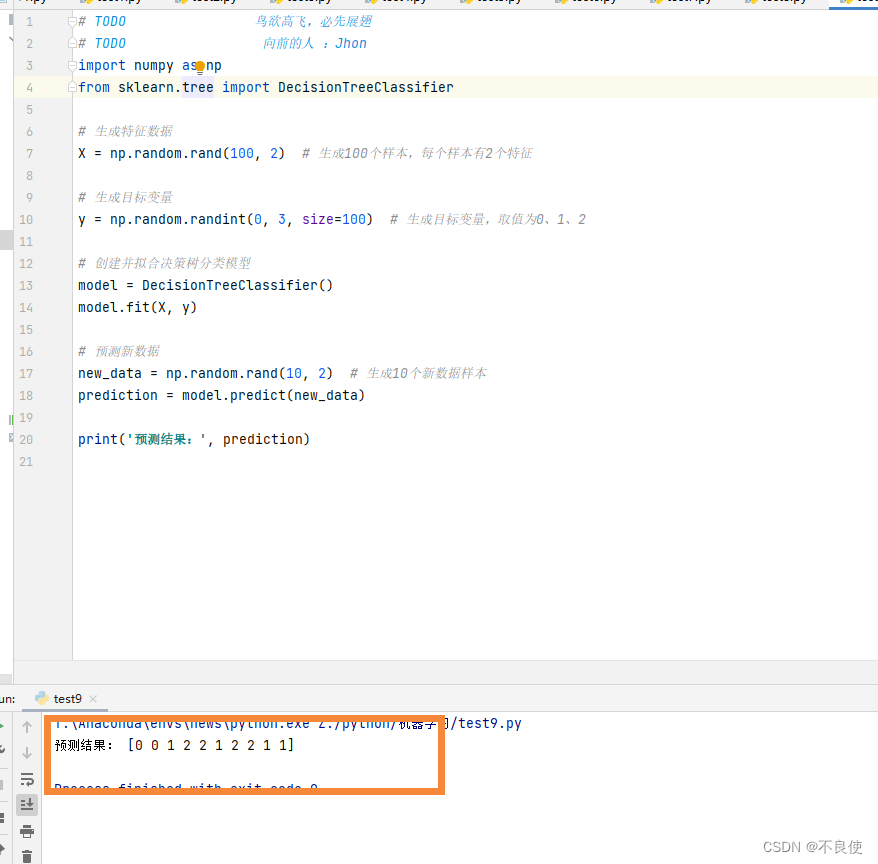
- 导入必要的库:
numpy用于生成随机数组。DecisionTreeClassifier用于创建决策树分类模型。
- 生成特征数据:
- 使用
numpy.random.rand()生成一个形状为(100, 2)的随机数组,表示有100个样本,每个样本有2个特征。
- 使用
- 生成目标变量:
- 使用
numpy.random.randint()生成一个长度为100的随机数组,取值范围为0到2,表示3个分类。
- 使用
- 创建并拟合决策树分类模型:
- 创建
DecisionTreeClassifier类的实例作为分类模型。 - 使用
fit()方法拟合模型,传入特征数据X和目标变量`
- 创建

相关文章:
决策树与机器学习实战【代码为主】
文章目录 🛴🛴引言🛴🛴决策树使用案例🛴🛴numpy库生成模拟数据案例🛴🛴决策树回归问题🛴🛴决策树多分类问题 🛴🛴引言 决策树是一种经…...
从感知机到神经网络
感知机 一、感知机是什么二、用感知机搭建简单逻辑电路2.1 与门2.2 与非门2.3 或门 三、感知机的局限性3.1 异或门3.2 线性和非线性 四、多层感知机4.1 已有门电路的组合4.2 Python异或门的实现 五、感知机模型5.1 感知机模型5.2 感知机损失函数5.3 感知机学习算法 六、感知机原…...

【HMGD】STM32/GD32 I2C DMA 主从通信
STM32 I2C配置 主机配置 主机只要配置速度就行 从机配置 从机配置相同速度,可以设置第二地址 因为我的板子上面已经有了上拉电阻,所以可以直接通信 STM32 I2C DMA 定长主从通信代码示例 int state 0; static uint8_t I2C_recvBuf[10] {0}; stat…...
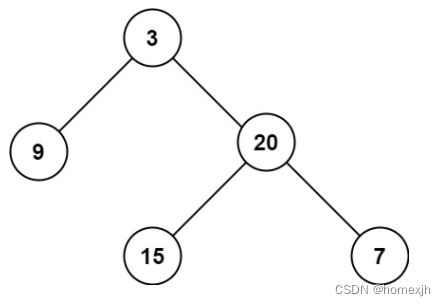
leecode 226 翻转二叉树、101 对称二叉树、104 二叉树的最大深度
leecode 226 翻转二叉树、101 对称二叉树、104 二叉树的最大深度 leecode 226 翻转二叉树 题目链接 :https://leetcode.cn/problems/invert-binary-tree/description/ 题目 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。…...

Redux基础
简介 状态管理工具,集中式管理react、vue、angular等应用中多个组件的状态,是一个库,使用之后可以清晰的知道应用里发生了什么以及数据是如何修改,如何更新的 在项目中添加 Redux 并不是必须的,根据项目需求选择是否引入 Redux 三个原则 …...

国外目标公司的任何一个联系人也许都有意义
我们说跟进一个项目,最好能够联系上拥有决策权的人,不然中间隔着几重关系,所有的更新都需要层层审批申报,特别麻烦,总是要等,也许等到最后就是一场空。如果能够直接和老板或者是拍板的人沟通,则…...

因为本地证书太旧或不全导致的 HTTPS 访问失败问题20240520
因为本地证书太旧或不全导致的 HTTPS 访问失败问题 在生产环境中,我们经常需要使用 curl 命令来测试和调试 HTTPS URL。然而,最近我遇到了一个棘手的问题:在测试环境中使用 curl 可以正常访问某个 URL,但在生产环境中却遇到了 SS…...

Lua获取表的长度
1.代码 -- 创建一个表并添加一些元素 local myTable {10, 20, 30, 40}-- 打印表的长度 print(#myTable) -- 输出 4,因为表中有 4 个元素-- 使用 # 来遍历表中的所有元素 for i 1, #myTable doprint(myTable[i]) end -- 这将依次打印 10, 20, 30, 40...

python九九乘法表的打印思考及实现
新书上架~👇全国包邮奥~ python实用小工具开发教程http://pythontoolsteach.com/3 欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 目录 一、问题引入 九九乘法表的显示需求 二、问题分析 嵌套循环的概念 屏幕宽度与换行的考虑…...

2.Spring中用到的设计模式
Spring框架中使用了多种设计模式来构建其强大且灵活的功能,这里举例说明Spring中的一些功能使用到的设计模式。 工厂模式:Spring容器本质是一个大工厂,使用工厂模式通过BeanFactory和ApplicationContext这两个核心接口来创建和管理bean对象。…...
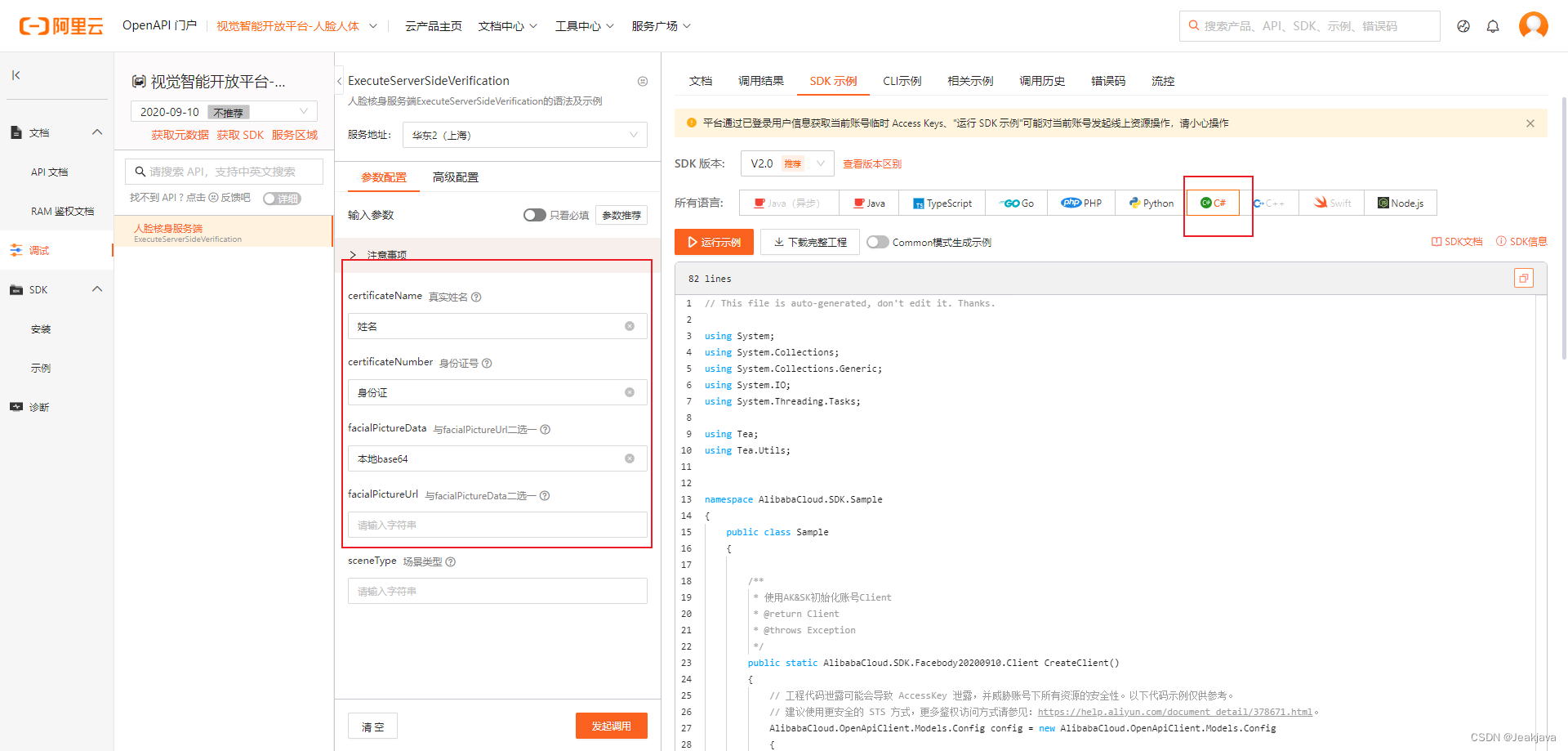
.NET调用阿里云人脸核身服务端 (ExecuteServerSideVerification)简易流程保姆级教学
需要注意的是,以下内容仅限基础调用 功能说明 该功能是输入核验人的姓名和身份证以及人脸照片,去阿里库里面匹配,3个信息是否一致,一致则验证通过,需要注意的是,人脸有遮挡,或者刘海࿰…...
]C语言堆排序技术详解)
[大师C语言(第十二篇)]C语言堆排序技术详解
引言 堆排序(Heap Sort)是一种基于比较的排序算法,它利用堆这种数据结构的特点来进行排序。堆是一种近似完全二叉树的结构,并同时满足堆积的性质:即子节点的键值或索引总是小于(或者大于)它的父…...

Activity启动流程要点
一、Activity启动流程 Activity的启动流程一般是通过调用startActivity或者是startActivityForResult来开始的startActivity内部也是通过调用startActivityForResult来启动Activity,只不过传递的requestCode小于0Activity的启动流程涉及到多个进程之间的通讯这里主…...

lua 计算第几周
需求 计算当前赛季的开始和结束日期,2024年1月1日周一是第1周的开始,每两周是一个赛季。 lua代码 没有处理时区问题 local const 24 * 60 * 60 --一整天的时间戳 local server_time 1716595200--todo:修改服务器时间 local date os.date("*t…...
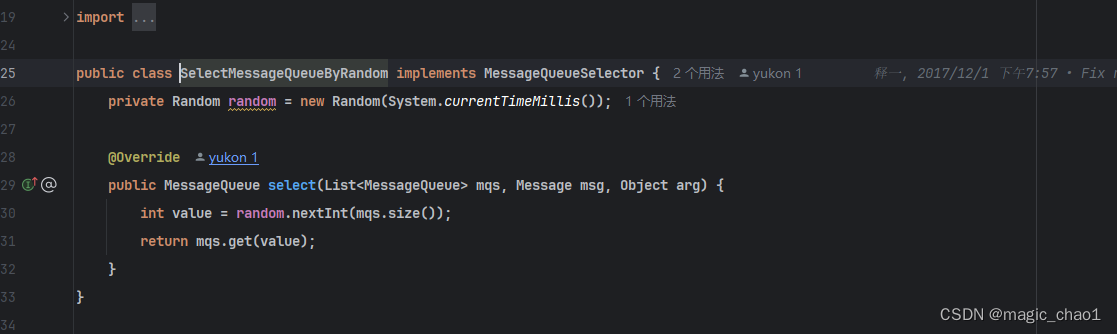
负载均衡策略
...

海外网红营销新趋势:“快闪式”营销如何迅速提升品牌曝光度
在当今数字化时代,海外网红营销已成为品牌迅速触达全球消费者、提升品牌曝光度和刺激销售的重要手段。其中,“快闪式”营销以其独特的时效性、创意性和互动性,成为品牌与海外网红合作的新趋势。本文Nox聚星将和大家探讨如何利用海外网红的影响…...

速看!打造专属数字化能力模型的七大关键!
在数字化浪潮中,企业如何打造适应自身发展的数字化能力模型?这是许多企业面临的重要课题。今天,通过众多企业使用蚓链数字化生态解决方案实践总结,为大家分享至关重要的七大经验,助你开启数字化转型之旅! 1…...

青蛙跳台阶问题
本期介绍🍖 主要介绍:青蛙跳台阶问题,青蛙跳台阶与斐波那契数列的关系👀。 文章目录 1. 题目2. 递归解题思路3. 迭代解题思路 1. 题目 从前有一只青蛙他想跳台阶,有n级台阶,青蛙一次可以跳1级台阶ÿ…...

linux日常运维2
下载linux离线安装包---- 利用 Downloadonly 插件下载 RPM 软件包及其所有依赖包 1. 先找个可以上网的linux操作系统,这里是以centos7操作系统为例,如果要使用centos6就先安装一个centos6的系统,然后让他可以上网,后面步骤如下 a.…...
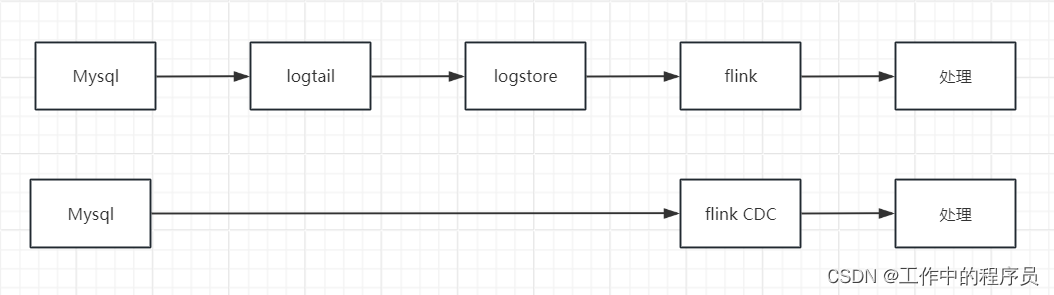
flink cdc mysql整理与总结
文章目录 一、业务中常见的需要数据同步的场景CDC是什么FlinkCDC是什么CDC原理为什么是FlinkCDC业务场景flink cdc对应flink的版本 二、模拟案例1.阿里云flink sql2.开源flink sql(单机模式)flink 安装安装mysql3.flink datastream 三、总结 提示:以下是本篇文章正文…...

超新星遗迹光学辐射特征的主控因素:环境密度与磁场影响的统计诊断
1. 项目概述:当超新星遗迹的“指纹”遇上统计学的“放大镜”在宇宙这个宏大的实验室里,超新星遗迹(Supernova Remnant, SNR)扮演着能量“搅拌器”和物质“回收站”的双重角色。一颗大质量恒星走到生命尽头,…...
)
别再手动标注了!:2026年唯一支持零样本Schema自演化+跨源实体对齐的3款工具深度拆解(含API调用成本对比)
更多请点击: https://kaifayun.com 第一章:别再手动标注了!:2026年唯一支持零样本Schema自演化跨源实体对齐的3款工具深度拆解(含API调用成本对比) 当企业每天接入17类异构数据源(CRM、IoT边缘…...

Telnet与SSH协议本质区别:从TCP连接到会话安全的底层解析
1. 为什么今天还在聊Telnet和SSH?一个被低估的“连接底层”分水岭 很多人以为Telnet和SSH只是“老古董协议”和“新标准协议”的简单替换关系,甚至觉得“现在谁还用Telnet?直接上SSH不就完了?”——这种认知在日常运维中看似无害&…...

分布式机器学习中的精度与效率权衡:从近似计算到自动驾驶实践
1. 项目概述:当“算得准”遇上“算得快”在分布式机器学习的世界里,我们每天都在面对一个看似简单、实则深刻的抉择:是要一个“算得准”但慢吞吞的模型,还是要一个“算得快”但偶尔会出点小错的系统?这个抉择ÿ…...

用格拉姆矩阵特征值调整替代SVD,高效求解带正交约束的优化问题
1. 项目概述与核心问题在机器学习和数值优化的世界里,我们经常遇到一个经典难题:如何在一个带约束的复杂空间里,找到那个“最好”的解。这就像在一个布满规则的迷宫里寻找宝藏,你不能横冲直撞,必须遵守墙壁(…...
)
用Python复现电池寿命预测论文:从数据清洗到模型调优的完整实战(附代码)
用Python实战电池寿命预测:从特征工程到模型优化的全流程解析在新能源与储能技术快速发展的今天,锂离子电池的健康状态(SOH)预测已成为工业界和学术界共同关注的核心课题。不同于传统实验室环境下耗时数月的电池老化测试ÿ…...

dos系统时代
1、蒂姆帕特森 是 “洁净室”方法吗 还是IBM 一、帕特森开发86-DOS:不是“洁净室”,而是“直接参考” 帕特森在1980年开发86-DOS(最初叫QDOS)时,并没有采用“洁净室”这种规避侵权的合法逆向工程方法。 实际上&…...

AI赋能工程教育:构建个性化、多元化与伦理驱动的学习生态
1. 项目概述:当工程教育遇见AI,我们到底在谈论什么?最近几年,AI这个词快被说烂了。从ChatGPT的横空出世,到各类生成式AI工具的遍地开花,似乎每个行业都在讨论如何“被赋能”。工程教育这个领域也不例外&…...

云服务器Nginx静态网站首屏慢的四层根因与优化方案
1. 为什么明明用了Nginx,静态网站首屏加载却要3秒以上?你有没有遇到过这种情况:在云服务器上用Nginx部署了一个纯HTMLCSSJS的静态站点,连数据库都不用,理论上应该毫秒级响应——结果打开首页,F12 Network面…...
)
别再只盯着MSE了!用Python实战对比5大回归评估指标(附避坑指南)
别再只盯着MSE了!用Python实战对比5大回归评估指标(附避坑指南)当你的回归模型在测试集上表现不佳时,第一个浮现在脑海的问题往往是:"该用哪个指标来评估才最合理?"这个问题远比想象中复杂——我…...