力扣hot 100:49. 字母异位词分组(python C++)
目录
- 题目描述:
- 题解(python):(方法一:排序)
- 代码解析
- 代码运行解析
- 题解(C++):(方法一:排序)
- 代码解析&运行解析
原题目链接
题目描述:
示例 1:
输入: strs = [“eat”, “tea”, “tan”, “ate”, “nat”, “bat”]
输出: [[“bat”],[“nat”,“tan”],[“ate”,“eat”,“tea”]]
示例 2:
输入: strs = [“”]
输出: [[“”]]
示例 3:
输入: strs = [“a”]
输出: [[“a”]]
提示:
1 <= strs.length <= 104
0 <= strs[i].length <= 100
strs[i] 仅包含小写字母
题解(python):(方法一:排序)
class Solution:def groupAnagrams(self, strs: List[str]) -> List[List[str]]:mp = collections.defaultdict(list)for st in strs:key = "".join(sorted(st))mp[key].append(st)return list(mp.values())
代码解析
这段代码定义了一个名为 Solution 的类,类中包含一个名为 groupAnagrams 的方法。该方法用于将一组字符串按字母异位词(anagram)分组。以下是代码的逐行解析:
class Solution:def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
- 这段代码定义了一个类
Solution,类中包含一个方法groupAnagrams。这个方法接收一个参数strs,它是一个字符串列表(List[str]),返回值是一个列表,列表中的每个元素也是一个字符串列表(List[List[str]])。
mp = collections.defaultdict(list)
- 这里定义了一个名为
mp的变量,它是一个defaultdict(来自collections模块)。defaultdict是一种字典,它在引用的键不存在时会自动创建键,并将其值初始化为指定的默认值。在这个例子中,默认值是一个空列表。
for st in strs:key = "".join(sorted(st))mp[key].append(st)
- 这一段代码遍历输入的字符串列表
strs。- 对于每个字符串
st,通过sorted(st)对字符串的字符进行排序,得到一个排序后的字符列表。 - 然后通过
''.join(sorted(st))将排序后的字符列表重新组合成一个字符串key。 - 使用这个
key作为键,将原始字符串st添加到mp字典中对应的列表中。
- 对于每个字符串
return list(mp.values())
- 最后,将字典
mp中所有的值(即各个字母异位词分组的列表)转换为一个列表,并返回这个列表。
总结:
- 这个方法的主要作用是将输入的字符串列表按字母异位词分组。字母异位词是指由相同字母组成但顺序不同的字符串。
- 通过对每个字符串的字符进行排序,可以生成唯一的键(排序后的字符串),用这个键来将原始字符串分组。
例如,输入 ["eat", "tea", "tan", "ate", "nat", "bat"],该方法将返回 [['eat', 'tea', 'ate'], ['tan', 'nat'], ['bat']]。
代码运行解析
当然可以!我们来详细跟踪代码执行的每一步,以理解它是如何处理输入 ["eat", "tea", "tan", "ate", "nat", "bat"] 的。
import collectionsclass Solution:def groupAnagrams(self, strs: List[str]) -> List[List[str]]:mp = collections.defaultdict(list)
- 创建了一个
defaultdict,初始状态mp是空的:mp = {}。
for st in strs:key = "".join(sorted(st))mp[key].append(st)
遍历 strs 列表,并对每个字符串执行以下操作:
-
处理
st = "eat":sorted("eat")结果是['a', 'e', 't']key = "".join(['a', 'e', 't'])结果是"aet"mp["aet"].append("eat"),更新后的mp是:{'aet': ['eat']}
-
处理
st = "tea":sorted("tea")结果是['a', 'e', 't']key = "".join(['a', 'e', 't'])结果是"aet"mp["aet"].append("tea"),更新后的mp是:{'aet': ['eat', 'tea']}
-
处理
st = "tan":sorted("tan")结果是['a', 'n', 't']key = "".join(['a', 'n', 't'])结果是"ant"mp["ant"].append("tan"),更新后的mp是:{'aet': ['eat', 'tea'], 'ant': ['tan']}
-
处理
st = "ate":sorted("ate")结果是['a', 'e', 't']key = "".join(['a', 'e', 't'])结果是"aet"mp["aet"].append("ate"),更新后的mp是:{'aet': ['eat', 'tea', 'ate'], 'ant': ['tan']}
-
处理
st = "nat":sorted("nat")结果是['a', 'n', 't']key = "".join(['a', 'n', 't'])结果是"ant"mp["ant"].append("nat"),更新后的mp是:{'aet': ['eat', 'tea', 'ate'], 'ant': ['tan', 'nat']}
-
处理
st = "bat":sorted("bat")结果是['a', 'b', 't']key = "".join(['a', 'b', 't'])结果是"abt"mp["abt"].append("bat"),更新后的mp是:{'aet': ['eat', 'tea', 'ate'], 'ant': ['tan', 'nat'], 'abt': ['bat']}
return list(mp.values())
- 最终,将
mp的值转换为列表:list(mp.values())。 - 返回结果是
[['eat', 'tea', 'ate'], ['tan', 'nat'], ['bat']]。
综上,代码的每一步执行结果如下:
mp = {}(初始状态)mp = {'aet': ['eat']}mp = {'aet': ['eat', 'tea']}mp = {'aet': ['eat', 'tea'], 'ant': ['tan']}mp = {'aet': ['eat', 'tea', 'ate'], 'ant': ['tan']}mp = {'aet': ['eat', 'tea', 'ate'], 'ant': ['tan', 'nat']}mp = {'aet': ['eat', 'tea', 'ate'], 'ant': ['tan', 'nat'], 'abt': ['bat']}- 返回值:
[['eat', 'tea', 'ate'], ['tan', 'nat'], ['bat']]
题解(C++):(方法一:排序)
class Solution {
public:vector<vector<string>> groupAnagrams(vector<string>& strs) {unordered_map<string, vector<string>> mp;for (string& str:strs){string key = str;sort(key.begin(),key.end());mp[key].emplace_back(str);}vector<vector<string>> ans;for (auto it = mp.begin();it != mp.end(); ++ it){ans.emplace_back(it->second);}return ans;}
};
代码解析&运行解析
这段代码定义了一个名为 Solution 的类,类中包含一个名为 groupAnagrams 的方法。这个方法用于将一组字符串按字母异位词(anagram)分组。以下是代码的逐行解析:
class Solution {
public:vector<vector<string>> groupAnagrams(vector<string>& strs) {
- 这段代码定义了一个类
Solution,类中包含一个公有方法groupAnagrams。该方法接收一个引用参数strs,它是一个字符串的向量(vector<string>),返回值是一个二维字符串向量(vector<vector<string>>)。
unordered_map<string, vector<string>> mp;
- 这里定义了一个名为
mp的变量,它是一个unordered_map,键类型是string,值类型是vector<string>。这个哈希映射用于将排序后的字符串(作为键)映射到原始字符串列表(作为值)。
for (string& str: strs) {string key = str;sort(key.begin(), key.end());mp[key].emplace_back(str);}
- 这一段代码遍历输入的字符串向量
strs。- 对于每个字符串
str,将其复制到key中。 - 通过
sort(key.begin(), key.end())对key中的字符进行排序。 - 使用排序后的
key作为键,将原始字符串str添加到mp字典中对应的列表中。
- 对于每个字符串
vector<vector<string>> ans;
- 创建一个空的二维字符串向量
ans,用于存储结果。
for (auto it = mp.begin(); it != mp.end(); ++it) {ans.emplace_back(it->second);}
- 遍历
mp中的每一个键值对。- 对于每一个键值对,将值(即一个字符串列表)添加到
ans中。
- 对于每一个键值对,将值(即一个字符串列表)添加到
return ans;}
};
- 最后,返回
ans,它包含了按字母异位词分组的字符串列表。
总结:
- 这个方法的主要作用是将输入的字符串向量按字母异位词分组。字母异位词是指由相同字母组成但顺序不同的字符串。
- 通过对每个字符串的字符进行排序,可以生成唯一的键(排序后的字符串),用这个键来将原始字符串分组。
例如,输入 ["eat", "tea", "tan", "ate", "nat", "bat"],该方法将返回 [['eat', 'tea', 'ate'], ['tan', 'nat'], ['bat']]。
让我们详细跟踪代码执行的每一步,以理解它是如何处理输入 ["eat", "tea", "tan", "ate", "nat", "bat"] 的。
假设输入是 ["eat", "tea", "tan", "ate", "nat", "bat"],代码的每一步执行结果如下:
-
创建
mp:mp = {}(初始状态) -
处理
str = "eat":key = "eat"sort(key.begin(), key.end())结果是key = "aet"mp["aet"].emplace_back("eat"),更新后的mp是:{"aet": ["eat"]}
-
处理
str = "tea":key = "tea"sort(key.begin(), key.end())结果是key = "aet"mp["aet"].emplace_back("tea"),更新后的mp是:{"aet": ["eat", "tea"]}
-
处理
str = "tan":key = "tan"sort(key.begin(), key.end())结果是key = "ant"mp["ant"].emplace_back("tan"),更新后的mp是:{"aet": ["eat", "tea"], "ant": ["tan"]}
-
处理
str = "ate":key = "ate"sort(key.begin(), key.end())结果是key = "aet"mp["aet"].emplace_back("ate"),更新后的mp是:{"aet": ["eat", "tea", "ate"], "ant": ["tan"]}
-
处理
str = "nat":key = "nat"sort(key.begin(), key.end())结果是key = "ant"mp["ant"].emplace_back("nat"),更新后的mp是:{"aet": ["eat", "tea", "ate"], "ant": ["tan", "nat"]}
-
处理
str = "bat":key = "bat"sort(key.begin(), key.end())结果是key = "abt"mp["abt"].emplace_back("bat"),更新后的mp是:{"aet": ["eat", "tea", "ate"], "ant": ["tan", "nat"], "abt": ["bat"]}
遍历 mp,将每个值(字符串列表)添加到 ans 中:
ans = [["eat", "tea", "ate"], ["tan", "nat"], ["bat"]]
返回 ans,最终结果是:[['eat', 'tea', 'ate'], ['tan', 'nat'], ['bat']]。
相关文章:
)
力扣hot 100:49. 字母异位词分组(python C++)
目录 题目描述:题解(python):(方法一:排序)代码解析代码运行解析 题解(C):(方法一:排序)代码解析&运行解析 原题目链接…...

男士内裤什么材质的好?推荐男士内裤的注意事项
天气已经逐渐热了起来,广大男士们在夏天难免会出一身的汗,不少男士朋友都觉得一些吸湿性、透气性不好的内裤会在夏天穿着很不适,想挑选一些比较适合夏天的男士内裤,但现在的男士内裤品牌和材质分类却比较多,看得大家眼…...

Python操作MySQL数据库的工具--sqlalchemy
文章目录 一、pymysql和sqlalchemy的区别二、sqlalchemy的详细使用1.安装库2.核心思想3.整体思路4.sqlalchemy需要连接数据库5.使用步骤1.手动提前创建数据库2.使用代码创建数据表3.用代码操作数据表3.1 增加数据3.2 查询数据3.3 删除数据3.4 修改数据 一、pymysql和sqlalchemy…...

【算法】排序
排序算法在信息学非常常用。Hello!大家好,我是学霸小羊,今天讲几个排序算法。 1.“打擂台”排序 思路:a[ i ]和a[ j ]打擂台(i<j)。 这个方法简单易懂,只需要看看需不需要交换。按从大到小…...
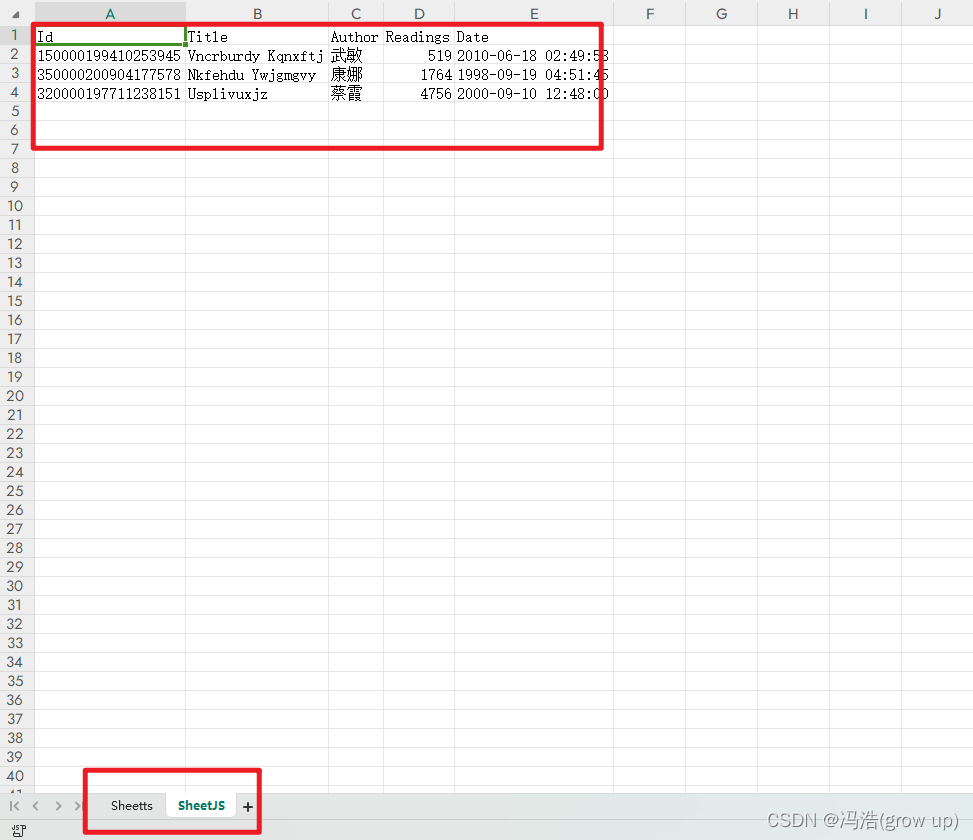
前端开发之xlsx的使用和实例,并导出多个sheet
前端开发之xlsx的使用和实例 前言效果图1、安装2、在页面中引用3、封装工具类(excel.js)4、在vue中使用 前言 在实现业务功能中导出是必不可少的功能,接下来为大家演示在导出xlsx的时候的操作 效果图 1、安装 npm install xlsx -S npm inst…...

创建数据库数据插入、更新与删除
创建数据库和创建表 一、实验目的 (1)熟悉和掌握数据库的创建和连接方法; (2)熟悉和掌握数据库表的建立、修改和删除; (3)加深对表的实体完整性、参照完整性和用户自定义完整性的…...

【CTF Web】CTFShow web3 Writeup(SQL注入+PHP+UNION注入)
web3 1 管理员被狠狠的教育了,所以决定好好修复一番。这次没问题了。 解法 注意到: <!-- flag in id 1000 -->但是拦截很多种字符。 if(preg_match("/or|\-|\\|\*|\<|\>|\!|x|hex|\/i",$id)){die("id error"); }使用…...
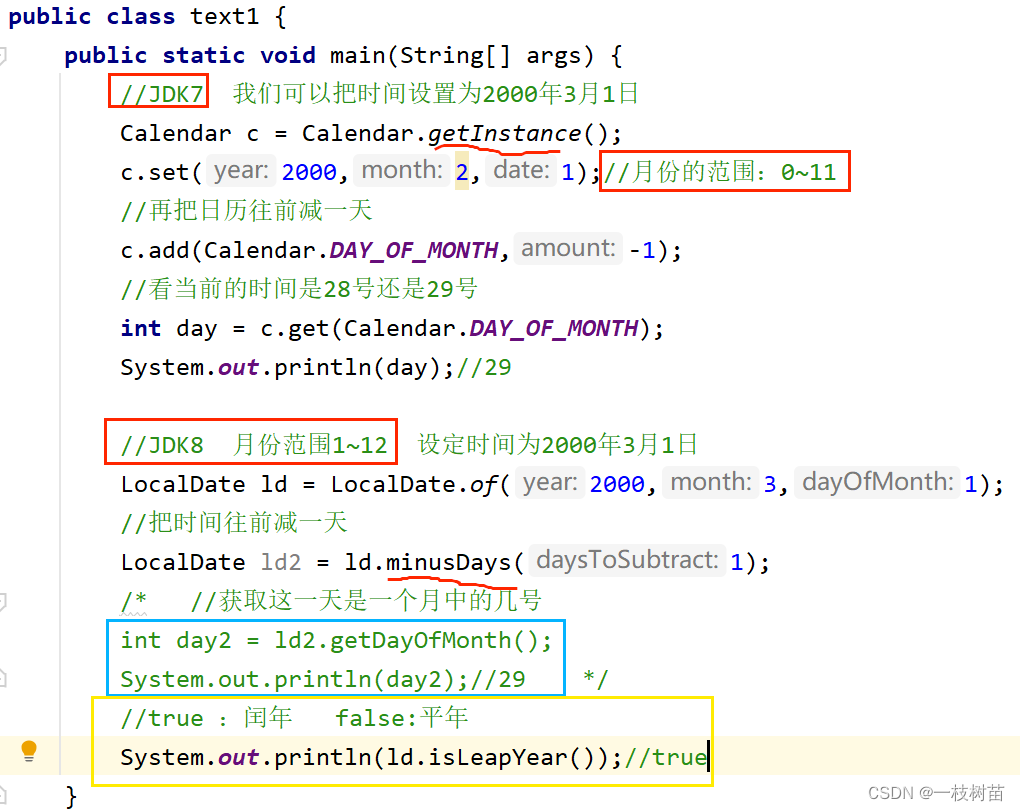
常见API(JDK7时间、JDK8时间、包装类、综合练习)
一、JDK7时间——Date 1、事件相关知识点 2、Date时间类 Data类是一个JDK写好的Javabean类,用来描述时间,精确到毫秒。 利用空参构造创建的对象,默认表示系统当前时间。 利用有参构造创建的对象,表示指定的时间。 练习——时间计…...
)
Docker数据卷(volume)
数据卷 数据卷是一个虚拟目录,是容器内目录与宿主机目录之间映射的桥梁。(容器内目录与宿主机目录对应的桥梁,修改宿主机对应的目录,docker会映射到容器内部,相当于修改了容器内的,反之也一样)数…...

30.哀家要长脑子了!---栈与队列
1.388. 文件的最长绝对路径 - 力扣(LeetCode) 其实看懂了就还好 用一个栈来保存所遍历过最大的文件的绝对路径的长度,栈顶元素是文件的长度,栈中元素的个数是该文件目录的深度,非栈顶元素就是当时目录的长度 检查此…...
多重继承引起的二义性问题和虚基类
多重继承容易引起的问题就是因为继承的成员同名而产生的二义性问题。 例:类A和类B中都有成员函数display和数据成员a,类C是类A和类B的直接派生类 情况一: class A {public:int a;void display(); }; class B {public:int a;void display; }; class C:…...

ciscn
ciscn Crypto部分复现 古典密码 先是埃特巴什密码(这个需要进行多次测试),然后base64,再栅栏即可 答案:flag{b2bb0873-8cae-4977-a6de-0e298f0744c3} _hash 题目: #!/usr/bin/python2 # Python 2.7 (6…...
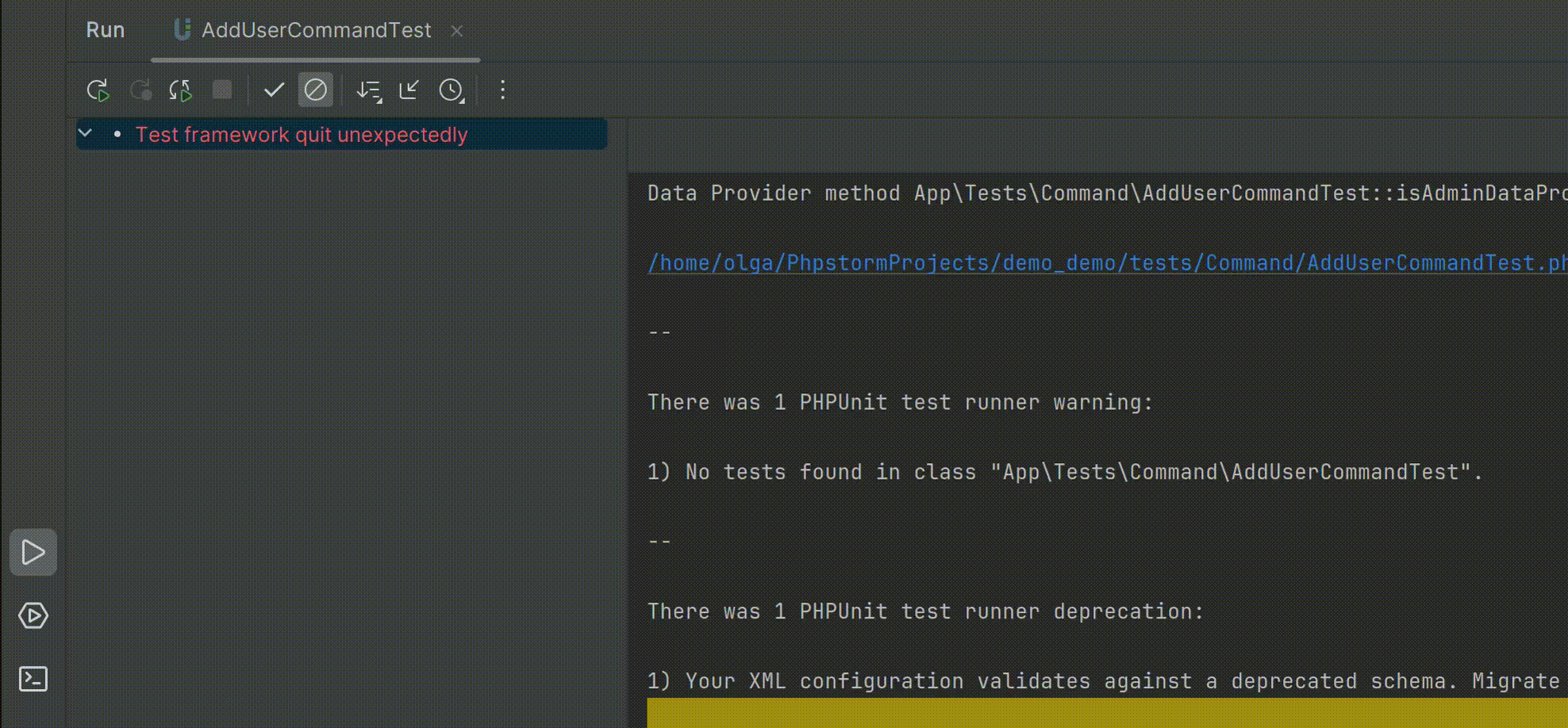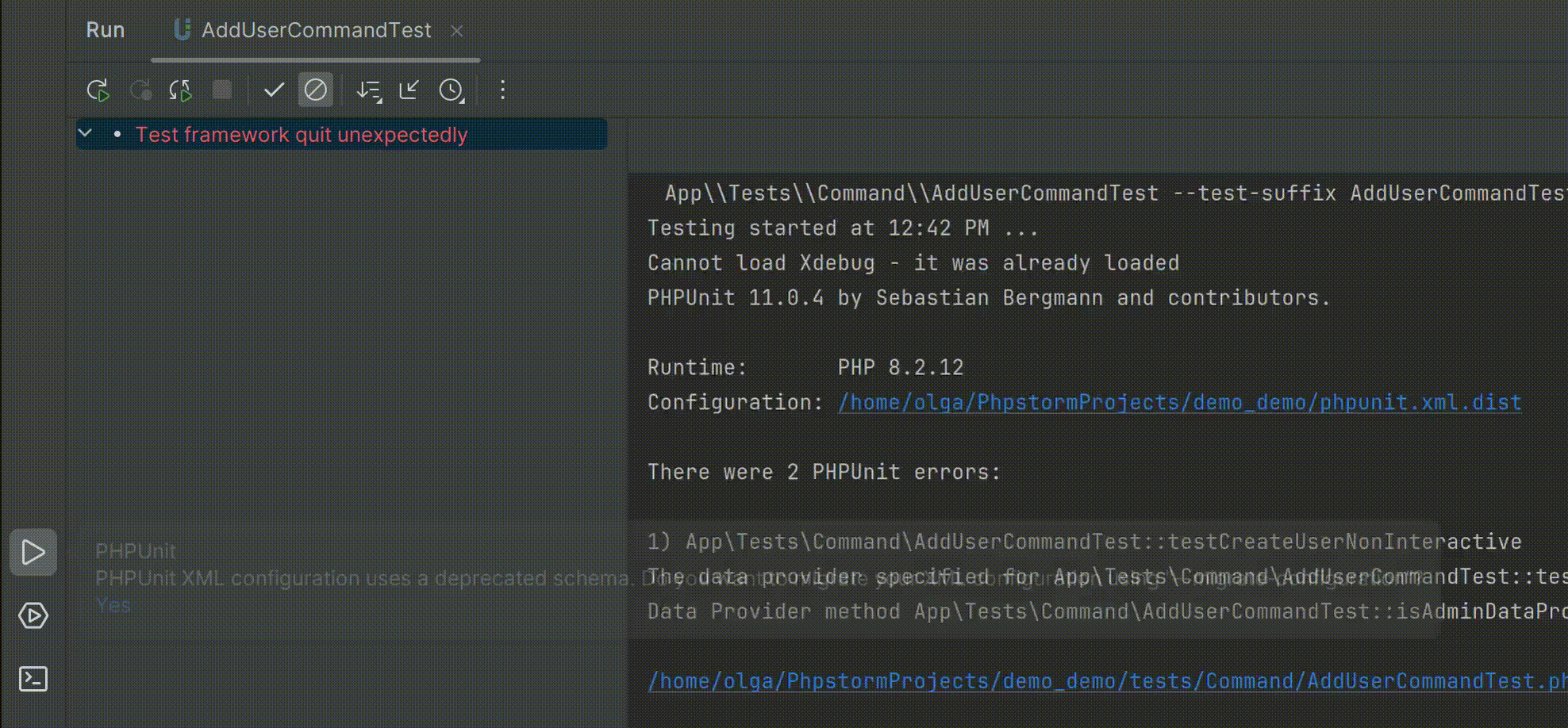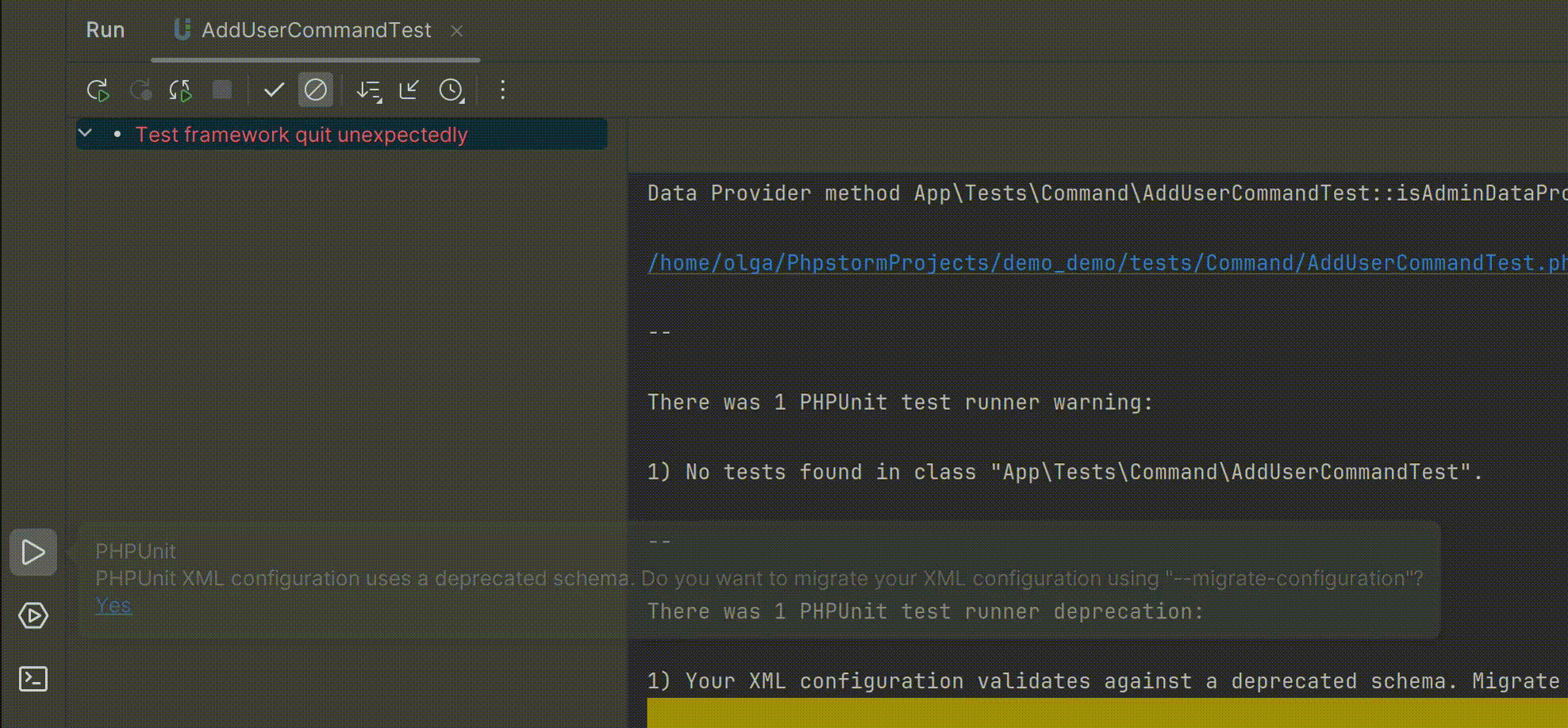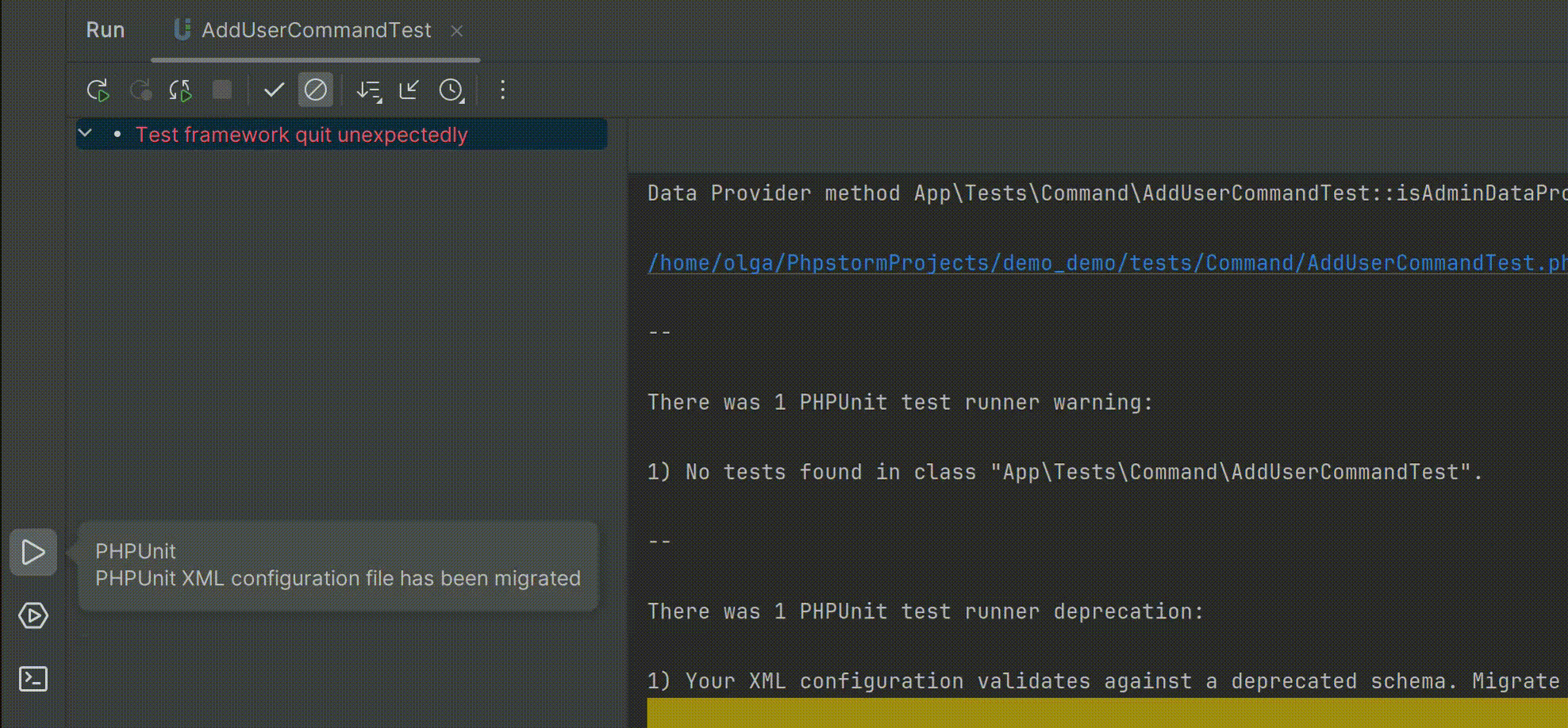
智能的PHP开发工具PhpStorm v2024.1全新发布——支持PHPUnit 11.0
PhpStorm是一个轻量级且便捷的PHP IDE,其旨在提高用户效率,可深刻理解用户的编码,提供智能代码补全,快速导航以及即时错误检查。可随时帮助用户对其编码进行调整,运行单元测试或者提供可视化debug功能。 立即获取PhpS…...
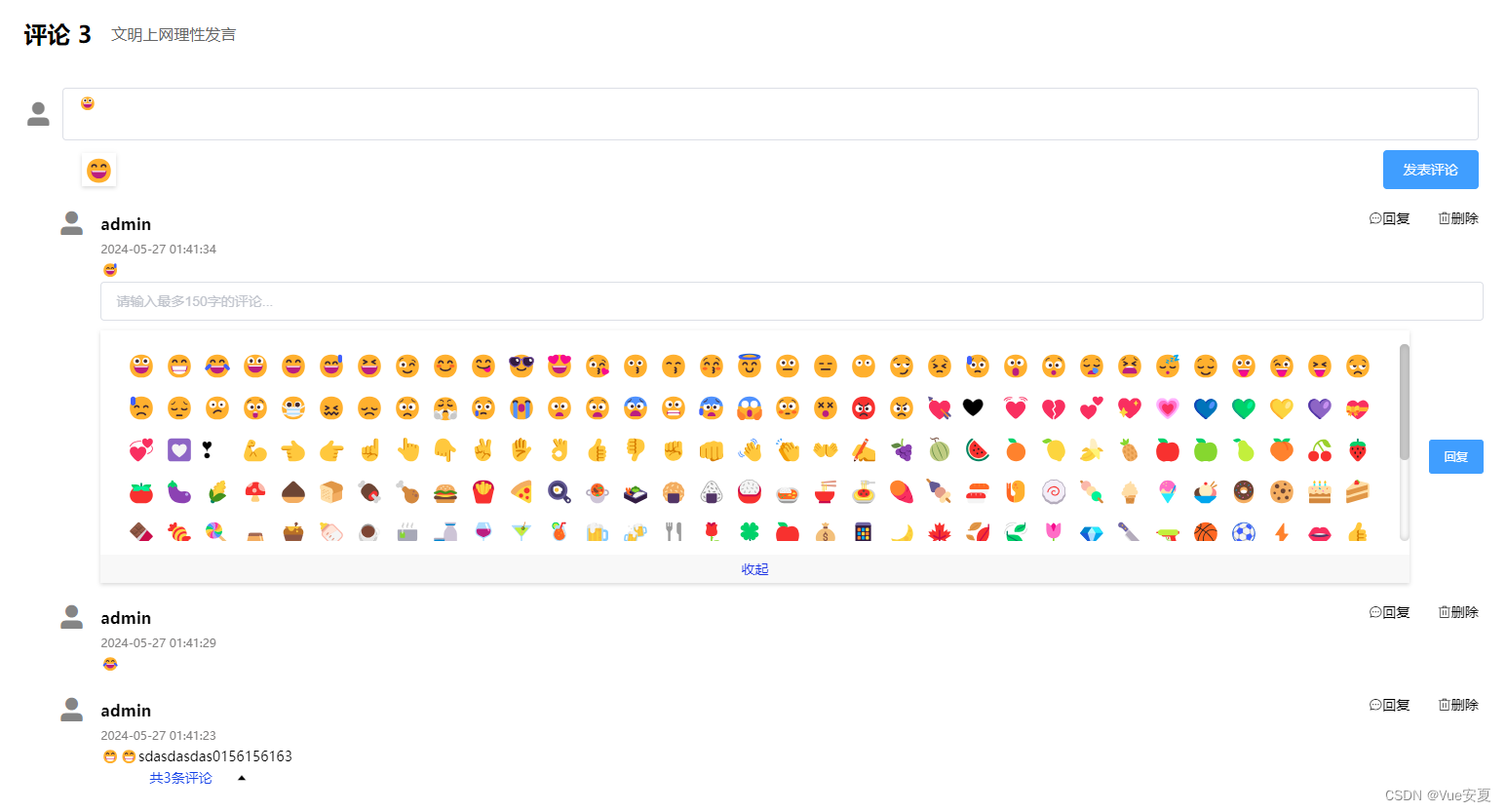
Vue2+Element 封装评论+表情功能
有需要的小伙伴直接拿代码即可,不需要下载依赖,目前是初始版本,后期会进行代码的优化。 评论组件如下: 创建 comment.vue 文件。 表情组件 VueEmoji.vue 在评论组件中使用。 <template><div class"comment"…...

【k8s】存储 pvc 参数列表
相关文章: 【K8s】初识PV和PVC 【k8s】存储 pv 参数列表 【k8s】存储 pvc 参数列表 1. pv概述 2. 参数列表 [rootpaas-controller-3:/home/ubuntu]$ kubectl explain pvc.spec KIND: PersistentVolumeClaim VERSION: v1RESOURCE: spec <Object>DESCRI…...

数据集007:垃圾分类数据集(含数据集下载链接)
数据集简介 本数据拥有 训练集:43685张; 验证集:5363张; 测试集:5363张; 总类别数:158类。 部分代码: 定义数据集 class MyDataset(Dataset):def __init__(self, modetrain, …...
Spring常用注解(超全面)
官网:核心技术SPRINGDOC.CN 提供 Spring 官方文档的翻译服务,可以方便您快速阅读中文版官方文档。https://springdoc.cn/spring/core.html#beans-standard-annotations 1,包扫描组件标注注解 Component:泛指各种组件 Controller、…...

HQL面试题练习 —— 合并活动日期
目录 1 题目2 建表语句3 题解 1 题目 已知有表记录了每个大厅的活动开始日期和结束日期,每个大厅可以有多个活动。请编写一个SQL查询合并在同一个大厅举行的所有重叠的活动,如果两个活动至少有一天相同,那他们就是重叠的,请将他们…...

基于SVm和随机森林算法模型的中国黄金价格预测分析与研究
摘要 本研究基于回归模型,运用支持向量机(SVM)、决策树和随机森林算法,对中国黄金价格进行预测分析。通过历史黄金价格数据的分析和特征工程,建立了相应的预测模型,并利用SVM、决策树和随机森林算法进行训…...

Host头攻击-使用反向代理服务器或负载均衡器来传递路由信息
反向代理服务器的作用 安全性:反向代理服务器位于Web服务器之前,可以隐藏实际Web服务器的身份和地址,从而增加安全性。它还可以对客户端请求进行过滤和检查,以防止潜在的攻击。负载均衡:反向代理服务器可以将客户端请…...

Office技巧速成:3个让效率翻倍的实用方法
表格操作总出错怎么办众多人于运用Excel开展数据处理工作之际,时常会被合并单元格以及公式报错等情形搞得疲惫不堪,焦头烂额。实际上,要是认真细细探究一番,便会发觉,大部分这类问题均是起因于对 Excel 基本功能欠缺熟…...

UCD9081 GUI实战:电源时序管理与故障记录配置详解
1. 项目概述:为什么我们需要一个智能的电源监控与序列管理器?在复杂的多轨电源系统设计中,比如服务器主板、通信基站或者高端测试仪器,工程师们常常面临一个共同的挑战:如何确保十几路甚至几十路电源在上电、下电以及运…...

还在熬夜起草各类通知?2026便捷AI办公好物,轻松写完正式公文
作为一名在行政岗摸爬滚打五年的职场人,我每天的工作不是泡在各类会议里,就是埋头起草通知、整理纪要。相信不少行政、文秘岗位的朋友都和我有一样的困扰:公司部门多、会议密,每周光是例会、项目协调会、临时部署会就要开三四场&a…...

Linux grep 文本过滤与正则实战——日志筛选、文本匹配神器
前言grep 是 Linux 最核心的文本搜索、日志过滤命令,排查报错、筛选日志、过滤配置、批量匹配全部靠它。本文从基础用法到正则实战,全覆盖工作高频场景,看完彻底掌握 grep。一、grep 核心作用从文件/管道流中匹配包含指定关键词的行ÿ…...

3步搞定显卡风扇异常:用FanControl彻底解决NVIDIA风扇噪音和转速问题
3步搞定显卡风扇异常:用FanControl彻底解决NVIDIA风扇噪音和转速问题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitH…...

2026年腾讯云OpenClaw/Hermes Agent配置Token Plan集成流程详解
2026年腾讯云OpenClaw/Hermes Agent配置Token Plan集成流程详解。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...
)
【独家实测】ChatGPT-4 Turbo vs GPT-3.5 Turbo单位token成本对比:附Python自动核算脚本(限免24h)
更多请点击: https://codechina.net 第一章:ChatGPT API价格计算的底层逻辑与成本认知 ChatGPT API 的计费并非基于会话时长或请求次数,而是严格依据模型实际处理的 token 数量——包括输入(prompt)和输出(…...

CANN/pypto copysign函数API文档
# pypto.copysign 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A…...

10个sd-webui-regional-prompter实用技巧:从基础分割到高级2D区域配置
10个sd-webui-regional-prompter实用技巧:从基础分割到高级2D区域配置 【免费下载链接】sd-webui-regional-prompter set prompt to divided region 项目地址: https://gitcode.com/gh_mirrors/sd/sd-webui-regional-prompter sd-webui-regional-prompter是一…...

Cortex-R52学习:时钟和复位
文章目录1. 时钟和时钟使能2. 复位信号3. 复位相关信号1. 时钟和时钟使能 Cortex-R52处理器采用单一时钟驱动其所有触发器和存储器。包括复位输入在内的多种输入信号均配有同步逻辑,允许它们以异步于处理器时钟的方式工作。大多数总线都配有使能输入,使…...