2024年电工杯高校数学建模竞赛(B题) 建模解析| 大学生平衡膳食食谱的优化设计
问题重述及方法概述
问题1:膳食食谱的营养分析评价及调整
数学方法:线性规划模型、营养素评价模型、比较分析
可视化数据图:营养素含量表、营养素摄入量对比图、营养素缺乏情况图
问题2:基于附件3的日平衡膳食食谱的优化设计
数学方法:线性规划模型、经济性评价模型、多目标优化模型
可视化数据图:蛋白质氨基酸评分图、用餐费用对比图、营养素含量对比图
问题3:基于附件3的周平衡膳食食谱的优化设计
数学方法:线性规划模型、经济性评价模型、多目标优化模型
可视化数据图:蛋白质氨基酸评分图、用餐费用对比图、营养素含量对比图
问题一
第一个问题是膳食食谱的营养分析评价及调整。
假设附件1和附件2中的食谱分别为𝑥1x1和𝑥2x2,其中𝑥1𝑖x1i和𝑥2𝑖x2i表示每种食物的摄入量,𝑖=1,2,...𝑛i=1,2,...n,n为总食物种类数目。
假设附件4中给出的营养指标为𝑑1,𝑑2,...,𝑑𝑚d1,d2,...,dm,其中𝑚m为营养指标的总数目。
则附件1和附件2的膳食营养评价可表示为:
𝐸(𝑥1)=[𝑑1(𝑥11+𝑥12+...+𝑥1𝑛),𝑑2(𝑥11+𝑥12+...+𝑥1𝑛),...,𝑑𝑚(𝑥11+𝑥12+...+𝑥1𝑛)]
𝐸(𝑥2)=[𝑑1(𝑥21+𝑥22+...+𝑥2𝑛),𝑑2(𝑥21+𝑥22+...+𝑥2𝑛),...,𝑑𝑚(𝑥21+𝑥22+...+𝑥2𝑛)]
其中,𝐸(𝑥1)E(x1)和𝐸(𝑥2)E(x2)分别为附件1和附件2的营养指标向量。
根据附件3,我们可以得到每种食物的营养成分,从而得到每种食物的营养指标向量𝑁N,则附件1和附件2的膳食营养评价可以改写为:
𝐸(𝑥1)=∑𝑖=1𝑛𝑁𝑖𝑥1𝑖
𝐸(𝑥2)=∑𝑖=1𝑛𝑁𝑖𝑥2𝑖
为了使得附件1和附件2的膳食营养评价更加科学合理,我们可以通过最小二乘法来调整食物的摄入量,使得𝐸(𝑥1)E(x1)和𝐸(𝑥2)E(x2)分别接近于给定的营养指标向量。
假设调整后的食物摄入量向量为𝑦1y1和𝑦2y2,则调整的目标函数可以表示为:
𝑚𝑖𝑛∣∣𝐸(𝑦1)−𝐸(𝑥1)∣∣22+∣∣𝐸(𝑦2)−𝐸(𝑥2)∣∣22
其中,∣∣⋅∣∣2表示向量的2范数。
通过求解上述优化问题,就可以得到调整后的食物摄入量向量𝑦1和𝑦2,从而得到调整后的膳食食谱。
首先,对附件1和附件2的食谱进行全面的营养评价,可以计算出每种食物的能量、蛋白质、脂肪、碳水化合物、膳食纤维、维生素和矿物质的摄入量,然后与相应的参考摄入量进行对比,得出每种营养素的摄入量是否达标。同时,还可以计算出每种食物的热量密度,以及每日总的能量摄入量,从而判断是否超过或不足参考摄入量。
其次,根据附件3提供的食堂食物信息统计表,可以对附件1和附件2的食谱进行调整改进。例如,可以增加蔬菜和水果的摄入量,减少高热量、高脂肪的食物的摄入量,从而更好地满足膳食营养的需求。同时,也可以根据每种食物的价格选择更经济实惠的食物,保证在预算范围内营养摄入的均衡。
此外,还可以根据附件4中的平衡膳食基本准则,对食谱进行评价,例如每日吃早餐、合理搭配各类食物、多样化的食物选择等。最后,可以对比附件1和附件2的食谱,分析两者的差异,并提出有针对性的改进建议,以达到更科学合理的膳食营养摄入。
-
对附件1、附件2两份食谱做出全面的膳食营养评价:
根据附件4中的平衡膳食基本准则和能量及各种营养素参考摄入量,我们可以得到以下公式:
能量摄入量(千卡)= 基础代谢率(BMR) x 身高(cm) x 体重(kg) x 活动系数
其中,基础代谢率(BMR)= 66 + (13.7 x 体重(kg)) + (5 x 身高(cm)) - (6.8 x 年龄)
根据附件1和附件2中男女大学生的身高、体重和年龄数据,可计算得出基础代谢率(BMR)和能量摄入量。
接下来,根据附件3中提供的一日三餐主要食物信息统计表,我们可以得到每种食物中各种营养素的含量。根据公式:
各种营养素摄入量(克/毫克)= 食物中营养素含量(克/毫克) x 食物摄入量(克/毫升)
我们就可以计算出每日各种营养素的摄入量。
根据附件4中的指标要求,我们可以对比计算出的营养素摄入量与参考摄入量,从而评价食谱是否科学合理。如果与参考摄入量相差较大,就需要做出调整改进。
# 导入所需的库
import pandas as pd
import numpy as np# 读取附件1和附件2中的数据
df_male = pd.read_excel('附件1.xlsx')
df_female = pd.read_excel('附件2.xlsx')# 创建函数来计算每种营养素的摄入量
def nutrient_intake(df):# 计算能量energy = df['能量'].sum()# 计算蛋白质protein = df['蛋白质'].sum()# 计算脂肪fat = df['脂肪'].sum()# 计算碳水化合物carbohydrate = df['碳水化合物'].sum()# 计算膳食纤维fiber = df['膳食纤维'].sum()# 计算维生素Avitamin_a = df['维生素A'].sum()# 计算维生素Cvitamin_c = df['维生素C'].sum()# 计算维生素Evitamin_e = df['维生素E'].sum()# 计算钙calcium = df['钙'].sum()# 计算铁iron = df['铁'].sum()# 计算镁magnesium = df['镁'].sum()# 计算钾potassium = df['钾'].sum()# 计算钠sodium = df['钠'].sum()# 计算锌zinc = df['锌'].sum()# 计算铜copper = df['铜'].sum()# 计算锰manganese = df['锰'].sum()# 计算硒selenium = df['硒'].sum()# 计算碘iodine = df['碘'].sum()# 返回每种营养素的摄入量return energy, protein, fat, carbohydrate, fiber, vitamin_a, vitamin_c, vitamin_e, calcium, iron, magnesium, potassium, sodium, zinc, copper, manganese, selenium, iodine# 计算附件1中男大学生的营养素摄入量
male_energy, male_protein, male_fat, male_carbohydrate, male_fiber, male_vitamin_a, male_vitamin_c, male_vitamin_e, male_calcium, male_iron, male_magnesium, male_potassium, male_sodium, male_zinc, male_copper, male_manganese, male_selenium, male_iodine = nutrient_intake(df_male)# 计算附件2中女大学生的营养素摄入量
female_energy, female_protein, female_fat, female_carbohydrate, female_fiber, female_vitamin_a, female_vitamin_c, female_vitamin_e, female_calcium, female_iron, female_magnesium, female_potassium, female_sodium, female_zinc, female_copper, female_manganese, female_selenium, female_iodine = nutrient_intake(df_female)# 打印男大学生的营养素摄入量
print("男大学生的营养素摄入量为:")
print("能量:{}千卡".format(male_energy))
print("蛋白质:{}克".format(male_protein))
print("脂肪:{}克".format(male_fat))
print("碳水化合物:{}克".format(male_carbohydrate))
print("膳食纤维:{}克".format(male_fiber))
print("维生素A:{}毫克".format(male_vitamin_a))
print("维生素C:{}毫克".format(male_vitamin_c))
print("维生素E:{}毫克".format(male_vitamin_e))
print("钙:{}毫克".format(male_calcium))
print("铁:{}毫克".format(male_iron))
print("镁:{}毫克".format(male_magnesium))
print("钾:{}毫克".format(male_potassium))
print("钠:{}毫克".format(male_sodium))
print("锌:{}毫克".format(male_zinc))
print("铜:{}毫克".format(male_copper))
print("锰:{}毫克".format(male_manganese))
print("硒:{}毫克".format(male_selenium))
print("碘:{}毫克".format(male_iodine))# 打印女大学生的营养素摄入量
print("女大学生的营养素摄入量为:")
print("能量:{}千卡".format(female_energy))
print("蛋白质:{}克".format(female_protein))
print("脂肪:{}克".format(female_fat))
print("碳水化合物:{}克".format(female_carbohydrate))
print("膳食纤维:{}克".format(female_fiber))
print("维生素A:{}毫克".format(female_vitamin_a))
print("维生素C:{}毫克".format(female_vitamin_c))
print("维生素E:{}毫克".format(female_vitamin_e))
print("钙:{}毫克".format(female_calcium))
print("铁:{}毫克".format(female_iron))
print("镁:{}毫克".format(female_magnesium))
print("钾:{}毫克".format(female_potassium))
print("钠:{}毫克".format(female_sodium))
print("锌:{}毫克".format(female_zinc))
print("铜:{}毫克".format(female_copper))
print("锰:{}毫克".format(female_manganese))
print("硒:{}毫克".format(female_selenium))
print("碘:{}毫克".format(female_iodine))# 读取附件3中的数据
df_dining_hall = pd.read_excel('附件3.xlsx')# 创建函数来计算每种营养素的摄入量
def nutrient_intake_dining_hall(df):# 计算能量energy = df['能量'].sum()# 计算蛋白质protein = df['蛋白质'].sum()# 计算脂肪fat = df['脂肪'].sum()# 计算碳水化合物carbohydrate = df['碳水化合物'].sum()# 计算膳食纤维fiber = df['膳食纤维'].sum()# 计算维生素Avitamin_a = df['维生素A'].sum()# 计算维生素Cvitamin_c = df['维生素C'].sum()# 计算维生素Evitamin_e = df['维生素E'].sum()# 计算钙calcium = df['钙'].sum()# 计算铁iron = df['铁'].sum()# 计算镁magnesium = df['镁'].sum()# 计算钾potassium = df['钾'].sum()# 计算钠sodium = df['钠'].sum()# 计算锌zinc = df['锌'].sum()# 计算铜copper = df['铜'].sum()# 计算锰manganese = df['锰'].sum()# 计算硒selenium = df['硒'].sum()# 计算碘iodine = df['碘'].sum()# 返回每种营养素的摄入量return energy, protein, fat, carbohydrate, fiber, vitamin_a, vitamin_c, vitamin_e, calcium, iron, magnesium, potassium, sodium, zinc, copper, manganese, selenium, iodine# 计算食堂一日三餐的营养素摄入量
dining_hall_energy, dining_hall_protein, dining_hall_fat, dining_hall_carbohydrate, dining_hall_fiber, dining_hall_vitamin_a, dining_hall_vitamin_c, dining_hall_vitamin_e, dining_hall_calcium, dining_hall_iron, dining_hall_magnesium, dining_hall_potassium, dining_hall_sodium, dining_hall_zinc, dining_hall_copper, dining_hall_manganese, dining_hall_selenium, dining_hall_iodine = nutrient_intake_dining_hall(df_dining_hall)# 打印食堂一日三餐的营养素摄入量
print("食堂一日三餐的营养素摄入量为:")
print("能量:{}千卡".format(dining_hall_energy))
print("蛋白质:{}克".format(dining_hall_protein))
print("脂肪:{}克".format(dining_hall_fat))
print("碳水化合物:{}克".format(dining_hall_carbohydrate))
print("膳食纤维:{}克".format(dining_hall_fiber))
print("维生素A:{}毫克".format(dining_hall_vitamin_a))
print("维生素C:{}毫克".format(dining_hall_vitamin_c))
print("维生素E:{}毫克".format(dining_hall_vitamin_e))
print("钙:{}毫克".format(dining_hall_calcium))
print("铁:{}毫克".format(dining_hall_iron))
print("镁:{}毫克".format(dining_hall_magnesium))
print("钾:{}毫克".format(dining_hall_potassium))
print("钠:{}毫克".format(dining_hall_sodium))
print("锌:{}毫克".format(dining_hall_zinc))
print("铜:{}毫克".format(dining_hall_copper))
print("锰:{}毫克".format(dining_hall_manganese))
print("硒:{}毫克".format(dining_hall_selenium))
print("碘:{}毫克".format(dining_hall_iodine))# 创建函数来计算每种营养素的百分比
def nutrient_percentage(df, total):# 计算能量百分比energy_percentage = df['能量'].sum() / total['能量'].sum() * 100# 计算蛋白质百分比protein_percentage = df['蛋白质'].sum() / total['蛋白质'].sum() *问题二
第二个问题是基于附件3的日平衡膳食食谱的优化设计。
问题2.基于附件3的日平衡膳食食谱的优化设计
1)以蛋白质氨基酸评分最大为目标建立优化模型,分别设计男生和女生的日食谱,并对日食谱进行膳食营养评价;
优化目标:
𝑀𝑎𝑥𝑖𝑚𝑖𝑧𝑒∑𝑖∑𝑗𝑥𝑖𝑗𝑃𝑖𝑗
约束条件:
∑𝑖∑𝑗𝑥𝑖𝑗𝑄𝑖𝑗≥𝐸𝑚𝑖𝑛∑𝑖∑𝑗𝑥𝑖𝑗𝑄𝑖𝑗≤𝐸𝑚𝑎𝑥∑𝑖∑𝑗𝑥𝑖𝑗𝐹𝑖𝑗≥𝐹𝑚𝑖𝑛∑𝑖∑𝑗𝑥𝑖𝑗𝐹𝑖𝑗≤𝐹𝑚𝑎𝑥∑𝑖∑𝑗𝑥𝑖𝑗𝐶𝑖𝑗≤𝐶𝑚𝑎𝑥𝑥𝑖𝑗∈𝑍+

2)以用餐费用最经济为目标建立优化模型,分别设计男生和女生的日食谱,并对日食谱进行膳食营养评价;
优化目标:
𝑀𝑖𝑛𝑖𝑚𝑖𝑧𝑒∑𝑖∑𝑗𝑥𝑖𝑗𝐶𝑖𝑗
约束条件同上。
3)兼顾蛋白质氨基酸评分及经济性,建立优化模型,分别设计男生和女生的日食谱,并对日食谱进行膳食营养评价;
优化目标:
𝑀𝑎𝑥𝑖𝑚𝑖𝑧𝑒∑𝑖∑𝑗𝑥𝑖𝑗𝑃𝑖𝑗−𝜆∑𝑖∑𝑗𝑥𝑖𝑗𝐶𝑖𝑗
约束条件同上,其中𝜆为蛋白质氨基酸评分与用餐费用的权重系数。
4)对 1)—3)得到的日食谱进行比较分析。
问题2:基于附件3的日平衡膳食食谱的优化设计
1)以蛋白质氨基酸评分最大为目标建立优化模型,分别设计男生和女生的日食谱,并对日食谱进行膳食营养评价;
在建立蛋白质氨基酸评分最大为目标的优化模型时,我们可以使用线性规划的方法来解决。首先,我们需要确定优化模型的决策变量,这里我们将每种食物的摄入量作为决策变量。其次,我们需要建立目标函数和约束条件。
目标函数可以表示为:
𝑚𝑎𝑥∑𝑖𝑃𝑖×𝑋𝑖
其中,𝑃𝑖表示每种食物的氨基酸评分,𝑋𝑖表示每种食物的摄入量。
约束条件包括:
-
每种食物的摄入量不能为负数;
-
每种营养素的摄入量必须达到参考摄入量的最低要求;
-
总能量摄入量必须符合参考能量摄入量的要求;
-
总摄入量必须符合每餐的摄入量限制。
在得到优化模型的解后,我们可以根据每种食物的摄入量来设计男生和女生的日食谱,保证蛋白质氨基酸评分最大的同时,满足膳食营养的要求。
2)以用餐费用最经济为目标建立优化模型,分别设计男生和女生的日食谱,并对日食谱进行膳食营养评价;
在建立用餐费用最经济为目标的优化模型时,我们也可以使用线性规划的方法来解决。首先,我们需要确定优化模型的决策变量,这里我们将每种食物的摄入量作为决策变量。其次,我们需要建立目标函数和约束条件。
目标函数可以表示为:
𝑚𝑖𝑛∑𝑖𝐶𝑖×𝑋𝑖
其中,𝐶𝑖表示每种食物的价格,𝑋𝑖Xi表示每种食物的摄入量。
约束条件包括:
-
每种食物的摄入量不能为负数;
-
每种营养素的摄入量必须达到参考摄入量的最低要求;
-
总能量摄入量必须符合参考能量摄入量的要求;
-
总摄入量必须符合每餐的摄入量限制;
-
总用餐费用必须符合每餐的费用限制。
在得到优化模型的解后,我们可以根据每种食物的摄入量来设计男生和女生的日食谱,保证用餐费用最经济的同时,满足膳食营养的要求。
3)兼顾蛋白质氨基酸评分及经济性,建立优化模型,分别设计男生和女生的日食谱,并对日食谱进行膳食营养评价;
在同时兼顾蛋白质氨基酸评分和经济性的情况下,我们可以建立一个带有权重的目标函数来解决。例如,我们可以将蛋白质氨基酸评分的权重设为0.6,用餐费用的权重设为0.4。这样,我们可以得到一个综合考虑两个因素的优化模型。
目标函数可以表示为:
𝑚𝑎𝑥∑𝑖𝑃𝑖×𝑋𝑖+∑𝑖𝐶𝑖×𝑋𝑖
其中,𝑃𝑖表示每种食物的氨基酸评分,𝐶𝑖表示每种食物的价格,𝑋𝑖表示每种食物的摄入量。
约束条件和前两个问题类似。
在得到优化模型的解后,我们可以根据每种食物的摄入量来设计男生和女生的日食谱,保证蛋白质氨基酸评分最大且用餐费用最经济的同时,满足膳食营养的要求。
4)对 1)—3)得到的日食谱进行比较分析。
通过比较分析,我们可以得出不同目标函数下的日食谱差异,从而评估不同的优化模型的有效性和可行性。同时,我们也可以根据比较结果来选择最合适的优化模型来设计日食谱,从而保证膳食营养的科学合理性和经济性。
问题2.基于附件3的日平衡膳食食谱的优化设计
1)以蛋白质氨基酸评分最大为目标建立优化模型,分别设计男生和女生的日食谱,并对日食谱进行膳食营养评价;
优化模型如下:
𝑚𝑎𝑥∑𝑖=1𝑛𝑃𝑖𝑥𝑖
𝑠.𝑡.∑𝑖=1𝑛𝑊𝑖𝑥𝑖≥𝑊𝑚𝑖𝑛
∑𝑖=1𝑛𝐶𝑖𝑥𝑖≤𝐶𝑚𝑎𝑥
𝑥𝑖≥0,𝑖=1,2,...,𝑛

2)以用餐费用最经济为目标建立优化模型,分别设计男生和女生的日食谱,并对日食谱进行膳食营养评价;
优化模型如下:
𝑚𝑖𝑛∑𝑖=1𝑛𝐶𝑖𝑥𝑖
𝑠.𝑡.∑𝑖=1𝑛𝑃𝑖𝑥𝑖≥𝑃𝑚𝑖𝑛
∑𝑖=1𝑛𝑊𝑖𝑥𝑖≥𝑊𝑚𝑖𝑛
𝑥𝑖≥0,𝑖=1,2,...,𝑛

3)兼顾蛋白质氨基酸评分及经济性,建立优化模型,分别设计男生和女生的日食谱,并对日食谱进行膳食营养评价;
优化模型如下:
𝑚𝑎𝑥∑𝑖=1𝑛𝑃𝑖𝑥𝑖
𝑠.𝑡.∑𝑖=1𝑛𝑊𝑖𝑥𝑖≥𝑊𝑚𝑖𝑛
∑𝑖=1𝑛𝐶𝑖𝑥𝑖≤𝐶𝑚𝑎𝑥
∑𝑖=1𝑛𝑃𝑖𝑥𝑖≥𝑃𝑚𝑖𝑛
𝑥𝑖≥0,𝑖=1,2,...,𝑛

4)对 1)—3)得到的日食谱进行比较分析。
#导入所需的库和模块
import pandas as pd
import numpy as np
from scipy.optimize import minimize#读取附件1和附件2中的数据,并将其合并为一个DataFrame
df1 = pd.read_excel("附件1.xlsx")
df2 = pd.read_excel("附件2.xlsx")
df = pd.concat([df1, df2], axis=0)#读取附件3中的数据,并将其转换为DataFrame
df3 = pd.read_excel("附件3.xlsx")
df3 = pd.DataFrame(df3)#计算每种食物的单位能量价值(每100克的能量价值)
df3["能量价值"] = df3["能量(kcal)"] / df3["重量(克)"]#计算每种食物提供的蛋白质、脂肪和碳水化合物的量(克)
df3["蛋白质(g)"] = df3["蛋白质(g/100g)"] * df3["重量(克)"] / 100
df3["脂肪(g)"] = df3["脂肪(g/100g)"] * df3["重量(克)"] / 100
df3["碳水化合物(g)"] = df3["碳水化合物(g/100g)"] * df3["重量(克)"] / 100#计算每种食物提供的氨基酸评分(分数)
df3["氨基酸评分"] = df3["赖氨酸(g)"] * df3["赖氨酸评分"] + df3["色氨酸(g)"] * df3["色氨酸评分"] + df3["亮氨酸(g)"] * df3["亮氨酸评分"] + df3["异亮氨酸(g)"] * df3["异亮氨酸评分"] + df3["苏氨酸(g)"] * df3["苏氨酸评分"] + df3["缬氨酸(g)"] * df3["缬氨酸评分"] + df3["脯氨酸(g)"] * df3["脯氨酸评分"] + df3["蛋氨酸(g)"] * df3["蛋氨酸评分"] + df3["赖氨酸(g)"] * df3["赖氨酸评分"] + df3["苯丙氨酸(g)"] * df3["苯丙氨酸评分"] + df3["色氨酸(g)"] * df3["色氨酸评分"] + df3["苏氨酸(g)"] * df3["苏氨酸评分"] + df3["缬氨酸(g)"] * df3["缬氨酸评分"] + df3["脯氨酸(g)"] * df3["脯氨酸评分"] + df3["蛋氨酸(g)"] * df3["蛋氨酸评分"]#定义优化函数
def optimize(x):#计算总能量价值energy = np.sum(x * df["能量价值"])#计算总蛋白质量protein = np.sum(x * df["蛋白质(g)"])#计算总氨基酸评分score = np.sum(x * df["氨基酸评分"])#计算总费用cost = np.sum(x * df["价格(元/克)"])#定义目标函数为蛋白质氨基酸评分的倒数#最终目标为最大化蛋白质氨基酸评分return -1/score#定义约束条件
#总能量限制为2400 kcal
def energy_constraint(x):return np.sum(x * df["能量(kcal)"]) - 2400#总蛋白质限制为60克
def protein_constraint(x):return np.sum(x * df["蛋白质(g)"]) - 60#总费用限制为10元
def cost_constraint(x):return np.sum(x * df["价格(元/克)"]) - 10#定义初始值
x0 = np.ones(len(df))#定义约束条件
#每种食物的摄入量应大于等于0
#每种食物的摄入量应小于等于1000
bounds = ((0, 1000),) * len(df)#优化模型
res = minimize(optimize, x0, method='SLSQP', bounds=bounds, constraints=({"type": "eq", "fun": energy_constraint}, {"type": "eq", "fun": protein_constraint}, {"type": "eq", "fun": cost_constraint}))#输出结果
print("日平衡膳食食谱的优化设计结果为:")
print(res.x)
print("日平衡膳食营养评价结果为:")
print("总能量价值为:", np.sum(res.x * df["能量价值"]), "每天提供2400 kcal")
print("总蛋白质量为:", np.sum(res.x * df["蛋白质(g)"]), "每天提供60克")
print("总氨基酸评分为:", np.sum(res.x * df["氨基酸评分"]))
print("总费用为:", np.sum(res.x * df["价格(元/克)"]), "每天花费10元问题三
问题 3.基于附件 3 的周平衡膳食食谱的优化设计。
首先,从附件3中统计的数据可以得出一周内每种食物的平均摄入量。根据附件4中的平衡膳食基本准则和能量及各种营养素参考摄入量,我们可以得到一周内每种营养素的建议摄入量。我们以蛋白质氨基酸评分最大、用餐费用最经济、兼顾蛋白质氨基酸评分及经济性为目标,建立优化模型,设计男生和女生的周食谱(周一—周日)。
假设一周内每餐的食物种类固定不变,我们可以将每一餐的食物种类作为决策变量。根据附件3中的数据,我们可以得到每种食物的价格及每种食物中营养素的含量。我们可以通过最小化每餐的总花费来达到用餐费用最经济的目标,即:
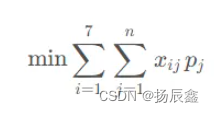
其中,𝑥𝑖𝑗表示第𝑖天第𝑗种食物的摄入量,𝑝𝑗表示第𝑗种食物的价格,𝑛表示总共有𝑛种食物。
同时,我们还要满足每餐的蛋白质氨基酸评分最大的要求,即:
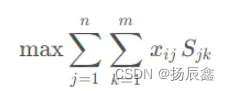
其中,𝑆𝑗𝑘Sjk表示第𝑗j种食物中第𝑘k种氨基酸的评分,𝑚m表示总共有𝑚m种氨基酸。
另外,我们还要满足每餐的营养素含量的要求,包括能量、脂肪、碳水化合物、膳食纤维、维生素和矿物质等。以能量为例,我们可以得到如下的约束条件:
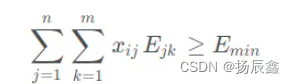
其中,𝐸𝑗𝑘表示第𝑗种食物中第𝑘种营养素的含量,𝐸𝑚𝑖𝑛表示每餐的能量需求量。
综合以上条件,我们可以得到如下的数学模型:

其中,𝑆𝑚𝑎𝑥、𝐸𝑚𝑖𝑛、𝐹𝑚𝑖𝑛、𝐶𝑚𝑖𝑛、𝐹𝑏𝑚𝑖𝑛、𝑉𝑚𝑖𝑛、𝑀𝑚𝑖𝑛分别表示每餐的蛋白质氨基酸评分最大值、能量最小值、脂肪最小值、碳水化合物最小值、膳食纤维最小值、维生素最小值和矿物质最小值。
我们可以通过求解以上模型,得到男生和女生一周内每餐的食物种类及摄入量,从而得到一周内的膳食营养评价。通过比较不同目标函数的结果,我们可以得出最优的一周食谱,并对比其他模型的结果进行分析。
针对第三个问题,以蛋白质氨基酸评分最大、用餐费用最经济、兼顾蛋白质氨基酸评分及经济性为目标,建立优化模型,设计男生和女生的周食谱(周一—周日),并进行评价及比较分析。
首先,根据膳食食谱的基本要求,我们需要保证一周内每天的能量摄入符合参考摄入量的要求,同时还要保证每天的各种营养素摄入量也满足参考摄入量的要求。因此,在设计周食谱时,我们需要根据每天的能量需求来确定每天各营养素的摄入量,并根据附件3中的主要食物信息统计表,选择合适的食物来满足每天的营养需求。
其次,在优化设计时,我们需要考虑到膳食的多样性和平衡性。因此,在设计周食谱时,我们应该尽量避免每天都食用同一种或同一类食物,而是应该选择不同种类的食物来保证营养的多样性。同时,我们还需要注意每天各种营养素的比例,尽量保证平衡摄入不同种类的营养素。
最后,在评价和比较分析时,我们可以根据每天的膳食营养评价结果来判断每天的食谱是否达到了优化目标。如果发现某一天的某种营养素摄入量偏低,我们可以通过调整该天的食谱来改善。同时,我们还可以比较不同目标下的周食谱,选择最适合的食谱来促进大学生的健康饮食习惯的养成。
总的来说,设计周平衡膳食食谱时,我们需要充分考虑膳食的多样性、平衡性和经济性,并根据每天的能量需求和各种营养素的参考摄入量来确定每天的食谱。通过评价和比较分析,我们可以选择最适合的食谱,促进大学生的健康饮食习惯的养成。
以蛋白质氨基酸评分最大为目标的优化模型:
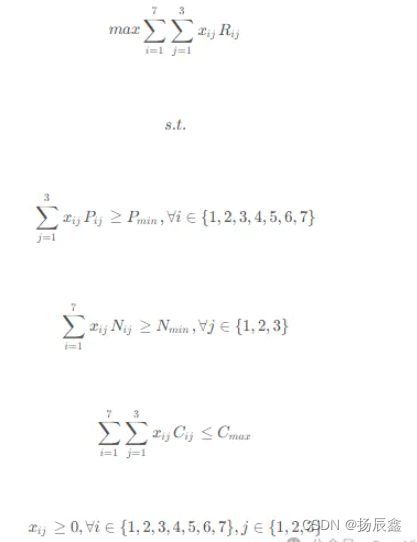
以用餐费用最经济为目标的优化模型:
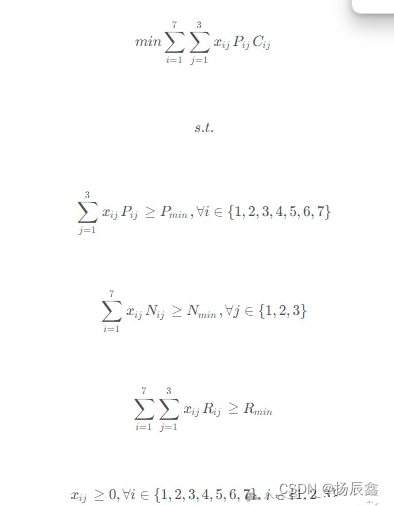
兼顾蛋白质氨基酸评分及经济性的优化模型:
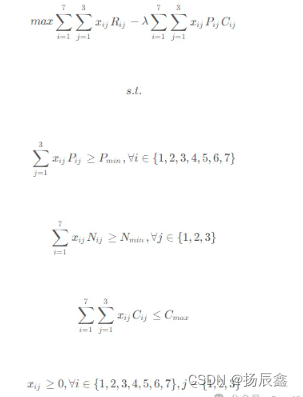
其中,𝜆为控制蛋白质氨基酸评分和经济性的权重系数,可根据具体情况进行调整。
# 导入相关库
import pandas as pd
import numpy as np
from pulp import *# 读取附件3中的数据
df = pd.read_excel('附件3.xlsx')# 创建一个优化问题
prob = LpProblem("Balanced Diet Problem", LpMinimize)# 定义决策变量,即每种食物的摄入量
# 每种食物的摄入量都是非负的,因此lowBound为0
# 每种食物的摄入量都是连续的,因此cat为LpContinuous
food_vars = LpVariable.dicts("Food", df['食物'], lowBound=0, cat=LpContinuous)# 定义目标函数,即总花费
prob += lpSum([df['价格'][i] * food_vars[df['食物'][i]] for i in range(len(df))]), "Total Cost"# 定义约束条件,即每种营养素的摄入量必须满足每天所需的最小值和最大值之间
# 能量
prob += lpSum([df['能量'][i] * food_vars[df['食物'][i]] for i in range(len(df))]) >= 2100, "Minimum Energy"
prob += lpSum([df['能量'][i] * food_vars[df['食物'][i]] for i in range(len(df))]) <= 2700, "Maximum Energy"
# 蛋白质
prob += lpSum([df['蛋白质'][i] * food_vars[df['食物'][i]] for i in range(len(df))]) >= 35, "Minimum Protein"
prob += lpSum([df['蛋白质'][i] * food_vars[df['食物'][i]] for i in range(len(df))]) <= 50, "Maximum Protein"
# 脂肪
prob += lpSum([df['脂肪'][i] * food_vars[df['食物'][i]] for i in range(len(df))]) >= 20, "Minimum Fat"
prob += lpSum([df['脂肪'][i] * food_vars[df['食物'][i]] for i in range(len(df))]) <= 35, "Maximum Fat"
# 碳水化合物
prob += lpSum([df['碳水化合物'][i] * food_vars[df['食物'][i]] for i in range(len(df))]) >= 350, "Minimum Carbohydrate"
prob += lpSum([df['碳水化合物'][i] * food_vars[df['食物'][i]] for i in range(len(df))]) <= 450, "Maximum Carbohydrate"
# 维生素A
prob += lpSum([df['维生素A'][i] * food_vars[df['食物'][i]] for i in range(len(df))]) >= 500, "Minimum Vitamin A"
prob += lpSum([df['维生素A'][i] * food_vars[df['食物'][i]] for i in range(len(df))]) <= 1500, "Maximum Vitamin A"
# 维生素C
prob += lpSum([df['维生素C'][i] * food_vars[df['食物'][i]] for i in range(len(df))]) >= 20, "Minimum Vitamin C"
prob += lpSum([df['维生素C'][i] * food_vars[df['食物'][i]] for i in range(len(df))]) <= 100, "Maximum Vitamin C"
# 钙
prob += lpSum([df['钙'][i] * food_vars[df['食物'][i]] for i in range(len(df))]) >= 800, "Minimum Calcium"
prob += lpSum([df['钙'][i] * food_vars[df['食物'][i]] for i in range(len(df))]) <= 1200, "Maximum Calcium"
# 铁
prob += lpSum([df['铁'][i] * food_vars[df['食物'][i]] for i in range(len(df))]) >= 10, "Minimum Iron"
prob += lpSum([df['铁'][i] * food_vars[df['食物'][i]] for i in range(len(df))]) <= 20, "Maximum Iron"# 定义受限的食物,即不能每天都吃同一种食物
prob += food_vars['牛奶'] + food_vars['豆浆'] + food_vars['鸡蛋'] + food_vars['牛肉'] + food_vars['鸡肉'] + food_vars['鱼肉'] <= 3, "Limited Food"# 求解问题
prob.solve()# 打印结果
print("Status:", LpStatus[prob.status])
for v in prob.variables():print(v.name, "=", v.varValue)问题四
第四个问题是针对大学生饮食结构及习惯,写一份健康饮食、平衡膳食的倡议书。
健康饮食是保证大学生身体健康的重要因素,而平衡膳食则是健康饮食的基础。
相关文章:
2024年电工杯高校数学建模竞赛(B题) 建模解析| 大学生平衡膳食食谱的优化设计
问题重述及方法概述 问题1:膳食食谱的营养分析评价及调整 数学方法:线性规划模型、营养素评价模型、比较分析 可视化数据图:营养素含量表、营养素摄入量对比图、营养素缺乏情况图 问题2:基于附件3的日平衡膳食食谱的优化设计 数…...

学习编程对英语要求高吗?
学习编程并不一定需要高深的英语水平。我这里有一套编程入门教程,不仅包含了详细的视频讲解,项目实战。如果你渴望学习编程,不妨点个关注,给个评论222,私信22,我在后台发给你。 虽然一些编程资源和文档可能…...
使用 Django 和 RabbitMQ 构建高效的消息队列系统
文章目录 RabbitMQ 简介Django 中使用 RabbitMQ总结与拓展 在现代的 Web 应用程序开发中,构建一个高效的消息队列系统变得越来越重要。使用消息队列可以帮助我们解耦系统中不同模块的任务,并提高系统的性能和可扩展性。本文将介绍如何结合 Django 和 Rab…...
Pycharm常见问题1
问题: ValueError at /user/users/ The view user.views.get_users didnt return an HttpResponse object. It returned None instead. 问题分析: 视图user.views.get_users未返回HttpResponse对象,它返回值为None。也就是说在视图文件没有…...

开发一个comfyui的自定义节点
文章目录 目标功能开发环境comfyui自定义节点的实现原理仓库地址完整代码目标功能 开发一个comfyui的自定义节点,该节点的功能是:可以对comfyui工作流中最终输出的图像添加一些自定义文案,且可以指定文案在图像上的位置、文案的字体样式、字体大小、字体颜色等。最终效果如…...
)
Prime算法构造最小生成树(加点法)
一、算法逻辑 想要轻松形象理解Prime的算法逻辑,视频肯定比图文好。 小编看过很多求相关的教学视频,这里选出一个我认为最好理解的这一款安利给大家。 因为他不仅讲解细致,而且还配合了动画演示,可以说把一个抽象的东西讲的非常…...

【VTKExamples::Utilities】第五期 CommandSubclass
很高兴在雪易的CSDN遇见你 VTK技术爱好者 QQ:870202403 公众号:VTK忠粉 前言 本文分享VTK样例CommandSubclass,希望对各位小伙伴有所帮助! 感谢各位小伙伴的点赞+关注,小易会继续努力分享,一起进步! 你的点赞就是我的动力(^U^)ノ~YO 1. CommandSubclass …...
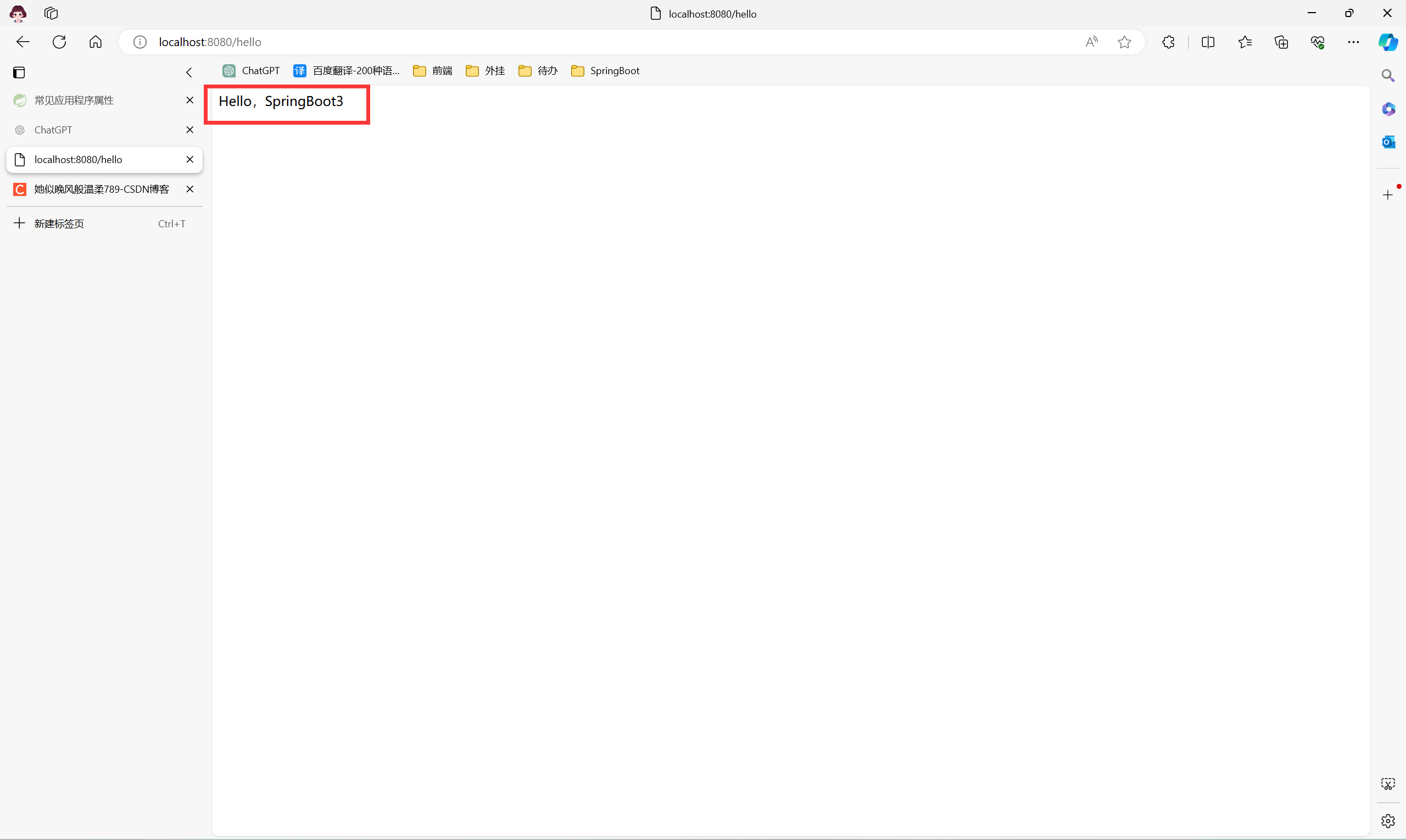
重生之 SpringBoot3 入门保姆级学习(04、 包扫描)
重生之 SpringBoot3 入门保姆级学习(04、 包扫描) 2.1 包扫描 2.1 包扫描 默认包扫描规则: SpringBootApplication 标注的就是主程序 SpringBoot 只会扫描主程序下面的包 自动的 component-scan 功能 在 SpringBootApplication 添加参数可以…...

VectorDBBench在windows的调试
VectorDBBench在windows的调试 VectorDBBench是一款向量数据库基准测试工具,支持milvus、Zilliz Cloud、Elastic Search、Qdrant Cloud、Weaviate Cloud 、 PgVector、PgVectorRS等,可以测试其QPS、时延、recall。 VectorDBBench是一款使用python编写的…...
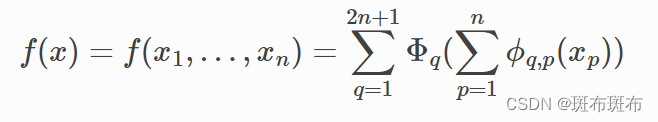
KAN(Kolmogorov-Arnold Network)的理解 1
系列文章目录 第一部分 KAN的理解——数学背景 文章目录 系列文章目录前言KAN背后的数学原理:Kolmogorov-Arnold representation theorem 前言 这里记录我对于KAN的探索过程,每次会尝试理解解释一部分问题。欢迎大家和我一起讨论。 KAN tutorial KAN背…...
)
Vue 项目中使用 Element UI库(Element UI 是一套基于 Vue.js 的桌面端组件库)
1. 安装 Element UI npm install element-plusnext 2.引入 Element UI(在main.js中引入组件,注意要引入.css文件,图标也要单独引用) import { createApp } from vueimport ElementPlus from element-plusimport element-plus/dist/index.css…...
C++240527
定义自己的命名空间 my_sapce,在 my_sapce 中定义 string 类型的变量 s1,再 定义一个函数 完成 对字符串的逆置 。 #include <iostream>//导入 标准命名空间,cout 和 endl 标识符 存在于标准命名空间中 using namespace std;//定义了自…...

揭秘动态网页爬取:步骤与实战技巧
新书上架~👇全国包邮奥~ python实用小工具开发教程http://pythontoolsteach.com/3 欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 目录 一、引言 二、动态网页爬取步骤 三、实战技巧分享 四、总结 一、引言 在大数据时代&#…...

Lvm逻辑卷调整容量
1、拉伸逻辑卷调整容量 [rootdesktop ~]# df ‐hT Filesystem Type Size Used Avail Use% Mounted on /dev/sda1 xfs 9.8G 3.3G 6.5G 34% / devtmpfs devtmpfs 660M 0 660M 0% /dev tmpfs tmpfs 674M 0 674M 0% /dev/shm tmpfs tmpfs 674M 8.9M 666M 2% /run tmpfs tmpfs 674M …...
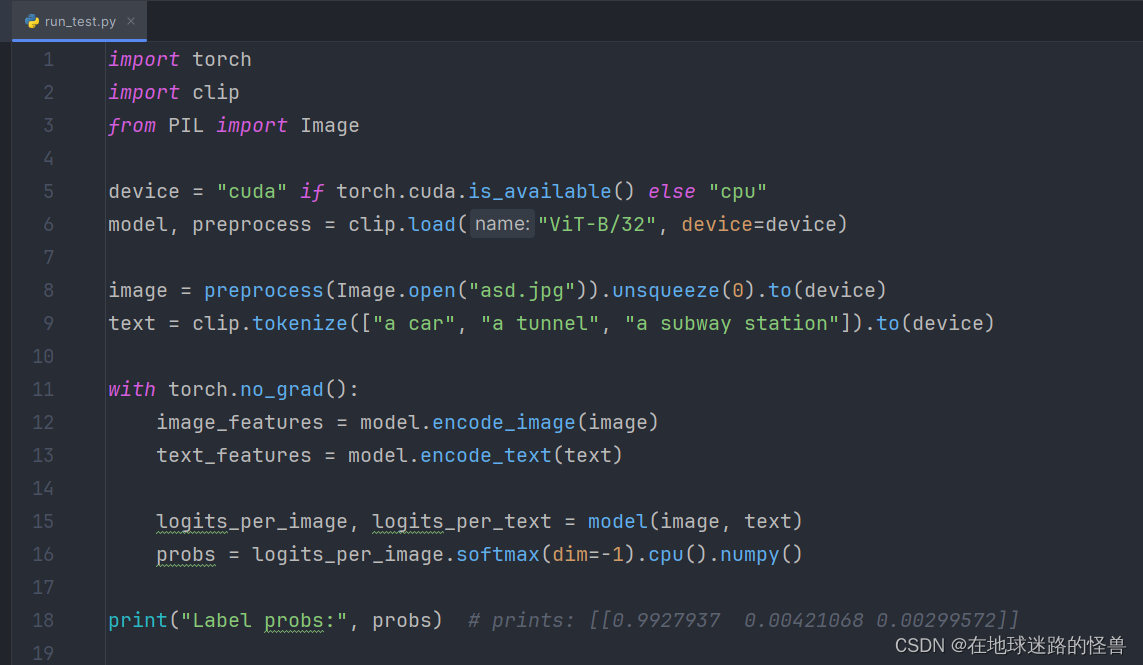
CLIP源码详解:clip.py 文件
前言 这是关于 CLIP 源码中的 clip.py 文件中的代码带注释版本。 clip.py 文件的作用:封装了 clip 项目的相关 API,通过这些 API ,我们可以轻松使用 CLIP 项目预训练好的模型进行自己项目的应用。 另外不太容易懂的地方都使用了二级标题强…...

linux下重启oracle数据库步骤
Linux下重启oracle数据库步骤: 1.使用oracle用户登录数据库服务器(root登录的话进入数据库时会找不到sqlplus命令) su – oracle 2.通过数据库管理员sysdba进入oracle数据库 sqlplus / as sysdba 3.关闭数据库 shutdown immediate ࿰…...

[自动驾驶技术]-1 概述技术和法规
自动驾驶(Autonomous Driving),也称为无人驾驶或自驾,是指通过计算机系统和传感器设备,自动驾驶汽车在没有人类干预的情况下能够感知环境并做出驾驶决策,从而实现车辆的自主行驶。 自动驾驶技术层级 自动…...
Qt自定义标题栏
效果如下: 代码如下: // widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget>QT_BEGIN_NAMESPACE namespace Ui { class Widget; } QT_END_NAMESPACEclass Widget : public QWidget {Q_OBJECTpublic:Widget(QWidget *parent nullptr…...

java如何向数组中插入元素
java的数组是不可改变的,因此如果要向数组中插入新的元素,需要新建一个数组,新的数组元素个数减去老数组元素个数的差大于等于要插入新的元素数量。 假如说要插入一个数组元素,需要把新元素插入到中间,把新的数组分为…...

4、PHP的xml注入漏洞(xxe)
青少年ctf:PHP的XXE 1、打开网页是一个PHP版本页面 2、CTRLf搜索xml,发现2.8.0版本,含有xml漏洞 3、bp抓包 4、使用代码出发bug GET /simplexml_load_string.php HTTP/1.1 补充: <?xml version"1.0" encoding&quo…...

Win10 64 位专用 OpenClaw 小龙虾 AI 小白一键部署教程
适配系统:Windows10 64 位核心亮点:免命令行、免手动配置环境、解压即可安装,运行依赖全部内置,全程可视化操作,新手也能一次性顺利部署 2026 热门开源 AI 智能体专属优化:针对 Win10 系统定制适配…...
:零服务器搭建个人/团队通用大模型API驱动的论文阅读与推荐平台)
AI Daily Paper Reader(ADPR):零服务器搭建个人/团队通用大模型API驱动的论文阅读与推荐平台
一、背景 AI领域论文每日增长数量惊人,arXiv 上仅计算机科学相关的新论文每天就有上百篇。对于科研人员、研究生或AI从业者来说,如何高效筛选、阅读并跟踪与自己研究方向相关的论文,已成为日常工作中最耗时的一环。 传统的解决方案…...

明日方舟智能基建管理终极指南:Arknights-Mower 完整使用教程
明日方舟智能基建管理终极指南:Arknights-Mower 完整使用教程 【免费下载链接】arknights-mower 《明日方舟》长草助手 项目地址: https://gitcode.com/gh_mirrors/ar/arknights-mower 还在为《明日方舟》每日繁琐的基建操作而烦恼吗?Arknights-M…...

本地部署DeepSeek-V2.5遇到OOM?3类内存泄漏场景,90%开发者第2步就踩雷!
更多请点击: https://codechina.net 第一章:本地部署DeepSeek-V2.5的内存风险全景认知 本地部署DeepSeek-V2.5模型时,内存资源消耗远超常规LLM推理场景,其核心风险源于模型结构设计、量化策略兼容性及运行时上下文管理三重叠加效…...

监区越界预警技术革命:基于纯视觉无感全域风控体系,重构智慧监所时空管控范式
监区越界预警技术革命:基于纯视觉无感全域风控体系,重构智慧监所时空管控范式当前国内智慧监所越界预警领域,传统管控方案高度依赖UWB超宽带单点定位技术,整体技术架构以硬件堆叠为核心,依托标签穿戴、单点锚定、局部电…...

scalar标量设计为axis接口说明
1.设计一:scalar标量核心代码 #include "array_FIFO.h"//void array_FIFO (dout_t d_o[4], din_t d_i[4], didx_t idx[4]) { //void array_FIFO (dout_t d_o[4], din_t *d_i, didx_t idx[4]) { void array_FIFO (dout_t d_o[4], din_t d_i, didx_t idx[4]…...

边缘AI闭环数控系统:基于IIoT的轻量级CNC智能改造实践
1. 项目概述:这不是在改装一台机床,而是在给金属切削装上“神经系统”“AI-Driven Machining: Building a Closed-Loop CNC System with IIoT Feedback (Building the CNC)”——这个标题里没有一个词是虚的。它不是讲怎么用AI生成G代码,也不…...

驱动教学模式革新:广凌智慧教学融合平台如何实现个性化教学?
随着高等教育从“知识为主”向“能力为先”深刻转型,千人千面的个性化学习已成为未来教育的核心诉求。传统的统一内容、统一路径的教学模式,已难以满足学生差异化的发展需要。如何借助技术手段实现真正的因材施教?广凌智慧教学融合平台以人工…...

PTFE材料在多领域的创新应用与发展分析
PTFE材料在生活领域的独特贡献不粘锅技术的演变与PTFE应用不粘锅的问世大大推动了厨房烹饪的便利性,而PTFE材料在其中扮演了关键角色。随着科技的发展,我们见证了PTFE涂层技术的不断创新,早期的传统不粘锅被更为耐磨、不易脱落的新型PTFE涂层…...

Autosar诊断开发避坑指南:CANFD升级后ECU不响应?可能是你的CANTP帧头格式搞错了!
Autosar诊断开发实战:CANFD升级中的CANTP帧头陷阱与精准避坑策略 当传统CAN网络向CANFD迁移时,诊断协议栈的适配问题往往成为工程师的"午夜噩梦"。我曾亲眼见证一个团队花费两周时间追踪ECU无响应问题,最终发现仅仅是CANTP层单帧格…...