生成式AI的GPU网络技术架构

生成式AI的GPU网络
引言:超大规模企业竞相部署拥有64K+ GPU的大型集群,以支撑各种生成式AI训练需求。尽管庞大Transformer模型与数据集需数千GPU,但实现GPU间任意非阻塞连接或显冗余。如何高效利用资源,成为业界关注焦点。
张量并行
流水线阶段的GEMM操作可跨多GPU分布。张量并行采用2D模型并行(流水线+张量),显著减少流水线深度,从而缩短训练时间。
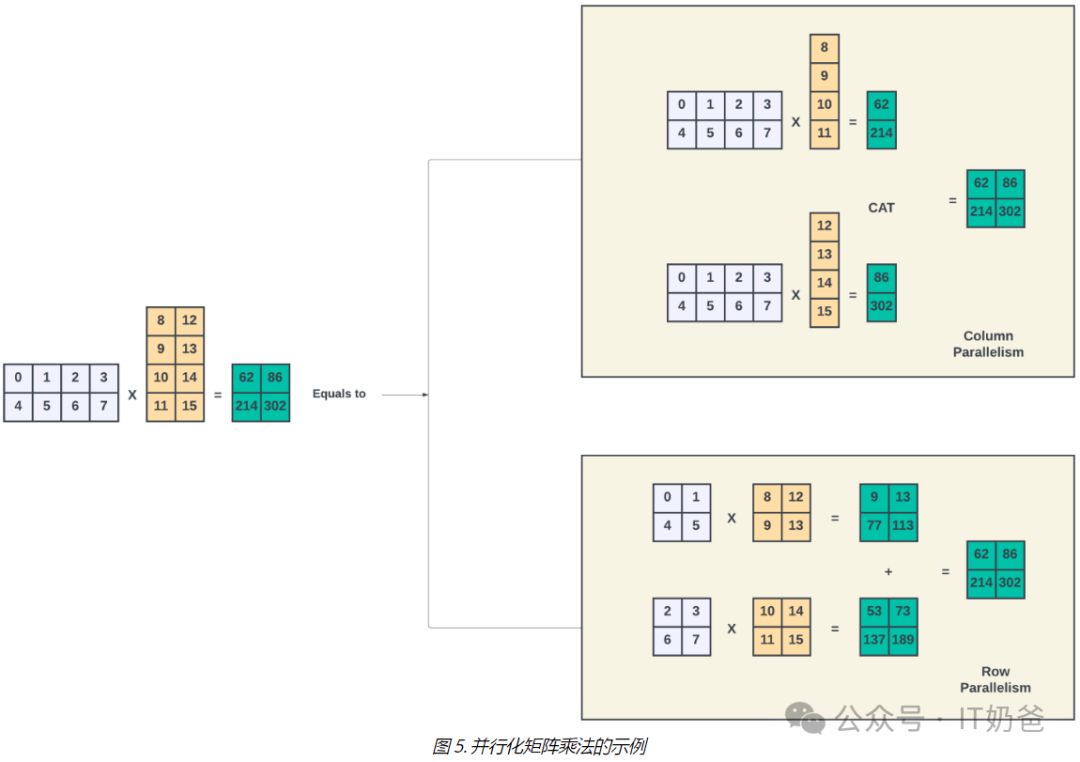
矩阵乘法并行化极为简便。输入矩阵(X)与权重矩阵(Y)相乘时,可轻松拆分为Nt个独立部分,如图5所示,Nt可设为2,显著提升计算效率。
通过张量并行技术,将Nt个部分矩阵乘法高效分配给Nt个离散GPU,需将输入X广播至所有GPU,确保高效并行处理。
GPU间协同工作,通过乘法运算获取结果Zt。张量并行GPU间需共享部分结果,通过列并行连接或行并行加法,汇总得出最终结果Z。这一成果将无缝衔接至后续计算流程,确保高效的数据处理与运算。
每个微批次的Nt GPU之间的all-to-all通信需要高带宽。通信的大小取决于微批次大小和隐藏层(矩阵乘法中使用的权重)的大小。由于高带宽要求,每个流水线中参与张量并行的 GPU 数量通常仅限于 GPU 服务器或节点内的 GPU 数量。这些服务器内 GPU 通过高速 NVlink 和 NVSwitches 连接。
回想一下,当两个 GPU 在服务器内时, H100服务器中的 GPU 到 GPU 带宽是它们在两个不同的服务器上时的 9 倍。
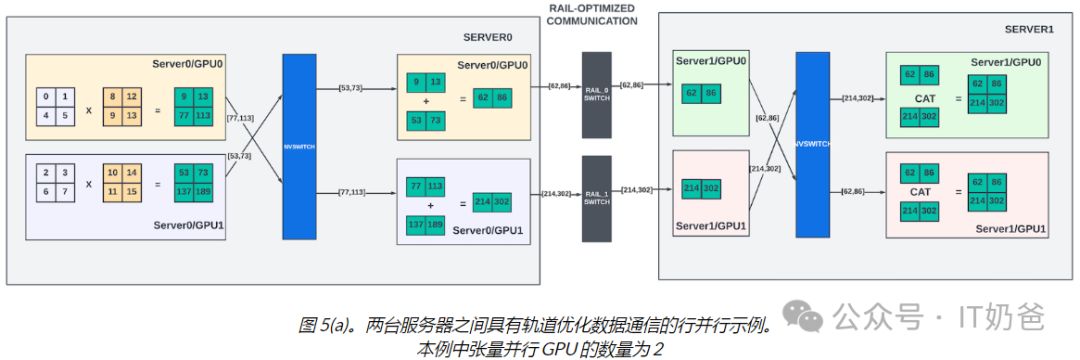
如图6所示,流水线阶段间的GPU交换中间结果时,相邻两个阶段的张量并行组需进行全对全(all-to-all)通信,确保数据高效传递,优化整体计算效率。
在上面的矩阵示例中,如果下一个流水线阶段的 GPU 位于不同的服务器中,Nvidia 不会将最终结果Z广播到下一个流水线阶段的所有张量并行组,而是提供像分散-聚集(scatter-gather)这样的集合,如 Megatron-LM 论文中所述。结果可以在发送端分成大小相等的块,每个 GPU 通过叶交换机将一个块发送到下一个流水线阶段中相同张量等级(轨道)的 GPU(图 5.a)。
因此,如果每个流水线阶段有八个张量并行 GPU,数据通信量可以减少八分之一。使用此方案,在接收端,每个张量并行 GPU 都可以通过 NVlinks 执行所有聚集以获取所有块并计算最终结果Z,然后再将其用于进一步的矩阵乘法。
梯度聚合流量
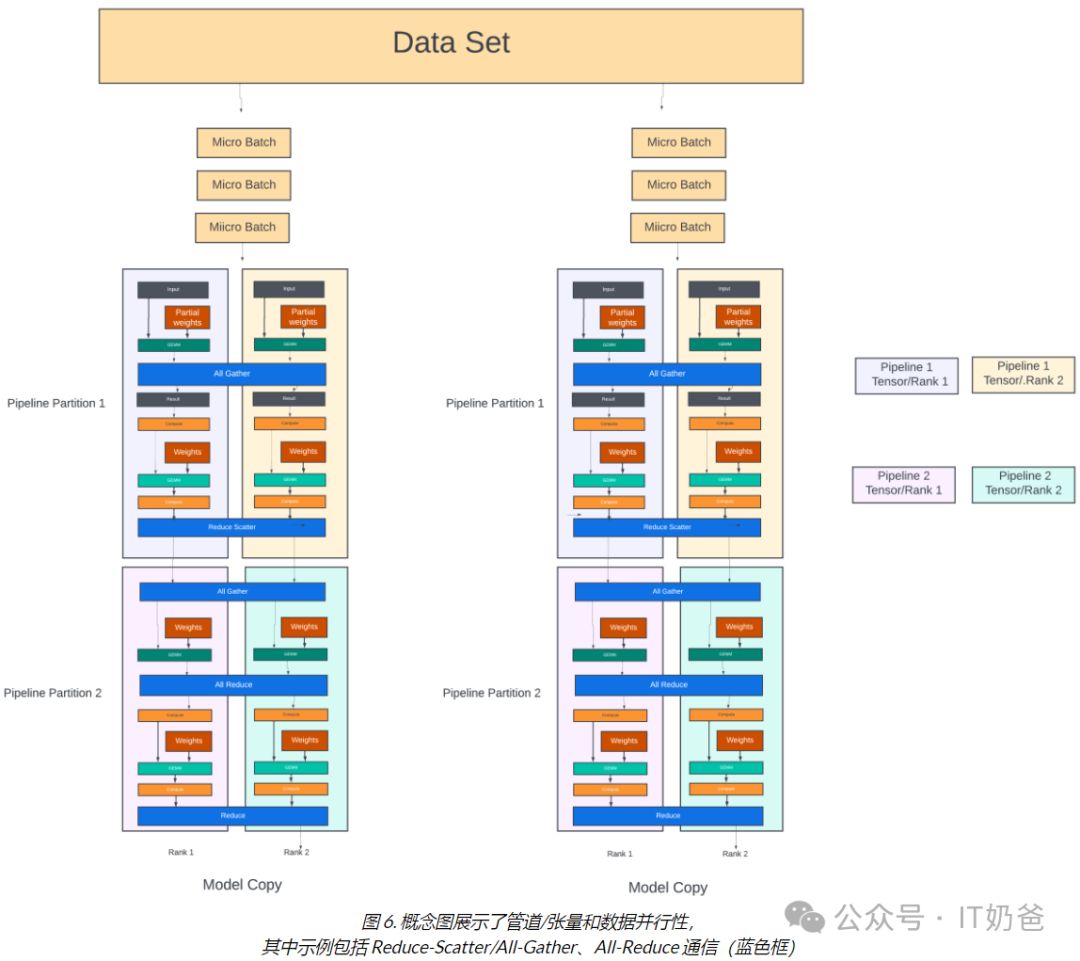
梯度聚合高效集成各模型副本参数梯度,实现全面优化。所有GPU协同工作,同rank/流水线内的GPU共同参与,确保每模型副本内Nm个GPU在每次迭代中并行执行Nm个梯度聚合线程,每线程含Nd个GPU,显著提升训练效率。
传统上,Ring-All-Reduce 方案以环形模式传递梯度,但速度受限。该方案下,每个GPU依次聚合从上一个GPU接收的梯度与本地计算的梯度,再发送给下一个GPU。这种顺序聚合与传播导致效率低下。为提升性能,需寻求更高效的梯度同步方法。
Nvidia创新推出双二叉树机制,实现梯度聚合的全带宽与对数延迟,大幅提升深度学习训练效率。如需深入了解此技术,请访问:[链接地址],获取详尽的论文解析。掌握前沿科技,引领深度学习新纪元。
二叉树梯度聚合中,各模型副本同阶段GPU形成树状结构。叶节点梯度上传至父节点,并与兄弟节点梯度相加。此过程递归进行,直至根节点完成梯度聚合,实现高效协同计算,优化模型训练效率。
根节点汇总所有梯度后,需逐层向下发送至树中所有节点,以更新模型参数的本地副本。梯度首先由根节点传递至其子节点,随后逐层下传,直至所有节点同步更新完毕。
在双二叉树方法中,使用跨数据并行组的同等级 GPU 构建两个二叉树。第一棵树的叶节点是另一棵树的中间节点。每棵树聚合一半的梯度。如论文所述,在双二叉树中,每个 GPU 最多可以有两个父 GPU 和两个子 GPU,并且性能(训练时间)远优于大型集群中的环形拓扑。对于大型集群,如果仅使用叶交换机即可访问子 GPU 和父 GPU,则部分梯度聚合可以使用叶交换机进行。但梯度聚合(或数据并行流量)还需要使用主干/聚合交换机来聚合所有无法通过叶交换机访问的数据并行 GPU 等级。
树形结构虽延迟低,但易在网络中产生2对1和1对2流量模式,可能引发短暂拥塞。相比之下,Ring-all-reduce的1对1流量模式更受超大规模网络运营商青睐,有效减少主干-叶子流量,保持网络高效流畅。
GPU 内存优化
GPU内存高效存储流水线/张量分区的参数、梯度、优化器状态、中间激活及输入数据,同时提供临时空间支持高效计算。
混合精度训练中,参数、梯度和优化器状态存储需求约(4*P + 12*P),采用Adam优化器时。对于拥有1万亿参数的模型,其存储空间需求高达24TB,展现了显著的存储挑战。
中间激活在反向传递中占用额外空间,与批大小和隐藏层大小成正比。通过重新计算激活,虽减少内存需求但增加计算量。对于输入激活,需1-2TB内存存储。然而,内存碎片等问题导致暂存空间增加和效率低下,需优化内存管理策略以提升性能。
GPT-4模型以1.5万亿参数傲视群雄,其32TB内存展现卓越性能,效率高达75%。若每个GPU拥有80GB容量,则400个GPU即可承载其一个模型副本,彰显强大算力。
针对Nd模型副本,优化内存的有效方法是仅在每个副本中存储部分参数、梯度和优化器状态。通过GPU间动态获取参数/状态,即“分片”技术,虽增加通信开销,但显著降低内存占用和所需GPU数量。微软研究显示,100B参数模型已通过分片优化。对于GPT-4等万亿参数模型,分片对GPU规模的影响尚待探究。
GPU-GPU 流量要点
- 流水线分区的张量并行GPU通信需高带宽,模型分区框架应优先保持其于同一服务器节点内,确保高效通信。
- 分散-聚集法大幅减少张量并行GPU在不同服务器间流水线阶段的通信量。通过轨道优化拓扑连接,GPU服务器实现高效流水线并行流量传输。特别地,各服务器中第N个GPU能经第N个叶交换机(轨道交换机)以无阻带宽互通,显著提升通信效率。
- 数据并行流量实现梯度聚合,通过所有并行组中的GPU间进行。这种分层树聚合形成了多种2对1或1对2的流量模式,传输量随GPU等级中存储参数量递增,高效处理大数据量。
- 集群GPU的数据/张量及模型并行划分后,每次训练迭代均重复通信模式。次优分区导致的拥塞、长尾延迟等问题会在迭代中累积,影响作业完成时间。
- 分片参数于所有数据并行GPU上,可大幅减少集群GPU数量,虽增数据并行通信,但显著缩小集群规模,提升效率。
状态空间/划分方法
决定张量、管道和数据并行 GPU 的最佳组合的状态空间很大,并且取决于许多因素。
- GPU组过多导致梯度聚合通信量剧增,影响迭代效率,流水线停顿降低GPU利用率。针对特定批次大小,过多数据并行组会缩减小批次和微批次大小,进而无法充分利用GPU计算资源,因为计算量与微批次大小直接相关。优化并行组配置,提高GPU资源利用率至关重要。
- 增大微批量(Bu)数量可显著减少流水线刷新停滞影响,但同时微批量大小会相应减小,可能引发GPU计算利用率不足。在优化时需权衡两者,确保高效利用资源。
- 当张量并行组GPU超过8个时,需依赖低带宽连接与叶交换机传输高带宽流量,导致性能瓶颈。为避免此问题,多数模型分区方法均致力于将GPU数量控制在每台服务器的可用范围内。
- Nvidia的Super POD震撼发布,搭载高达256个GPU,通过NV交换机GH200的层次结构高效互联。此系统强大到支持超过八个张量并行GPU,引领计算性能新纪元。
- 模型状态分片虽使GPU间通信量增1.5倍,但显著减少所需GPU总数,整体优化训练时间与成本,提升效率。
高效利用GPU集群是一大挑战,手动划分模型至多GPU以满足内存限制并最大化计算能力极为困难。Nvidia的开源框架(Alpa/Ray)能自动执行状态空间搜索,并考虑集群拓扑,实现智能优化。
NVIDIA Collective Communications Library(NCCL)针对特定集体操作,构建了高效跨GPU和节点的环或树结构,旨在减少争用、最大化吞吐量。其拓扑和通信模式专为集体操作优化,确保计算性能卓越。
服务器间流量
训练期间,服务器间流量利用GPU Direct RDMA技术,高效传输数据(中间结果、梯度等)于不同GPU内存间。GPU Direct RDMA是RDMA技术的进阶版,突破性地实现了GPU内存与远程设备间的直接数据交换,无需主机CPU介入,极大提升了数据传输效率。
以太网广泛普及,交换机/路由器生态系统丰富,超大规模企业和公共数据中心纷纷投资构建以太网架构。其中,RoCEv2(基于融合以太网/IP的RDMA)承载服务器间流量,其交换/路由方式与常规IP流量无异,为数据中心带来高效、稳定的网络体验。
RDMA 写入涉及以下步骤
优化后内容:在GPU/流间建立队列对(QP),通过带外通信共享QP信息,整个训练期间仅需一次设置,高效便捷。
2 - 将 QP 转换为准备状态以发送/接收交易
3 - 准备 RDMA 进行写入(发送方/接收方内存地址、传输大小)
RDMA网络接口卡(NIC)在发送服务器上接管,从特定GPU内存中读取数据,并高效地通过网络传输至目标服务器。其独特地利用GPU结构的MTU大小,将数据传输优化为网络上的多个高效事务。
QP中,每个RDMA操作(写入/读取/发送/接收)均由发送方分配唯一序列号,确保接收方精准检测丢失操作。传统RDMA NIC中,数据包不重排,序列号缺失即触发接收方暂停接收,并请求发送方从断点重传全部数据包,即回退N次重传。此法效率低下,既耗带宽又增延迟。
一些 NIC 支持选择性 NACK,它们请求仅重新传输丢失的数据包。一些 NIC(如 Nvidia 的 ConnectX NIC)允许网络对数据包进行重新排序(有限重新排序)。在此模式下,NIC 将操作无序(OOO)直接写入 GPU 内存,而不会触发向发送方的重新传输。NIC 内部的硬件可以使用位图跟踪最多 N 个操作(N 对应于带宽延迟乘积或 RTT),并按顺序将元数据传送给 GPU。此机制巧妙地使用 GPU 内存来存储 OOO 数据包,并且可以在不占用 NIC 内存空间的情况下实现。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
相关文章:
生成式AI的GPU网络技术架构
生成式AI的GPU网络 引言:超大规模企业竞相部署拥有64K GPU的大型集群,以支撑各种生成式AI训练需求。尽管庞大Transformer模型与数据集需数千GPU,但实现GPU间任意非阻塞连接或显冗余。如何高效利用资源,成为业界关注焦点。 张量并…...

旅游卡在哪里拿货?千益畅行旅游卡源头
旅游卡是一种便捷的旅行工具,它可以提供多种优惠和特惠,让人们在旅行中更加省钱、省心。那么,在千益畅行旅游卡这里,我们该如何拿到这张神奇的旅游卡呢? 首先,千益畅行旅游卡作为一款专为旅行爱好者打造的…...

代码随想录算法训练营第四十一天| 509. 斐波那契数 、70. 爬楼梯 、746. 使用最小花费爬楼梯
509. 斐波那契数 题目链接:509. 斐波那契数 文档讲解:代码随想录/斐波那契数 视频讲解:视频讲解-斐波那契数 状态:已完成(1遍) 解题过程 看到题目的第一想法 虽然看了卡哥的动态规划五部曲,…...
Ribbon负载均衡(自己总结的)
文章目录 Ribbon负载均衡负载均衡解决的问题不要把Ribbon负载均衡和Eureka-Server服务器集群搞混了Ribbon负载均衡代码怎么写ribbon负载均衡依赖是怎么引入的? Ribbon负载均衡 负载均衡解决的问题 首先Ribbon负载均衡配合Eureka注册中心一块使用。 在SpringCloud…...

Leetcode 力扣92. 反转链表 II (抖音号:708231408)
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。 示例 1: 输入:head [1,2,3,4,5], left 2, right 4 输出:[1,4,3,2…...

OSI七层模型和TCP/IP四层模型的区别
OSI七层模型 1.物理层(Physical Layer) 实现相邻节点之间比特流的透明传输,尽可能屏蔽传输介质带来的差异。典型设备:集线器(Hub)。 2.数据链路层(Data Link Layer) 将网络层传下来…...

在虚拟机上安装MySQL和Hive
在虚拟机上安装MySQL和Hive的步骤如下。这里将分别针对MySQL和Hive的安装进行说明。 MySQL安装步骤 1. 准备工作 下载MySQL安装包,选择与你虚拟机操作系统版本相匹配的MySQL版本,例如MySQL 8.0.35。 2. 卸载旧版本(如果已安装)…...

Vue 2 和 Vue 3 中同步和异步
Vue 2 和 Vue 3 中同步和异步 Vue 2 同步和异步 同步更新 (Synchronous Updates) Vue 2 在数据更新后会进行同步渲染更新,但为了性能优化,Vue 会在内部队列中异步地进行 DOM 更新。这意味着数据变化会立即被捕捉到,但实际的 DOM 更新会被推迟到下一个事件循环队列中。new V…...
ssm150旅游网站的设计与实现+jsp
旅游网站设计与实现 摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本旅游网站就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞…...

【加密与解密(第四版)】第十四章笔记
第十四章 漏洞分析技术 14.1 软件漏洞原理 缓冲区溢出漏洞:栈溢出 堆溢出、整型溢出(存储溢出、计算溢出、符号问题) UAF(Use-After-Free)漏洞 14.2 ShellCode 功能模块:下载执行、捆绑、反弹shell 14.3 …...
鸿蒙系统和安卓系统通过termux搭建Linux系统—Centos
目录 1. 前言 2. 效果图展示 3. 安装termux 4. 安装Centos系统 4.1 更换源 4.2 拉取镜像 4.3 启动centos 5.结尾 1. 前言 大家好,我是jiaoxingk 今天这篇文章让你能够在手机或者平板上使用Linux-Centos系统 让你随时随地都能操作命令行进行装13 2. 效果图展示…...
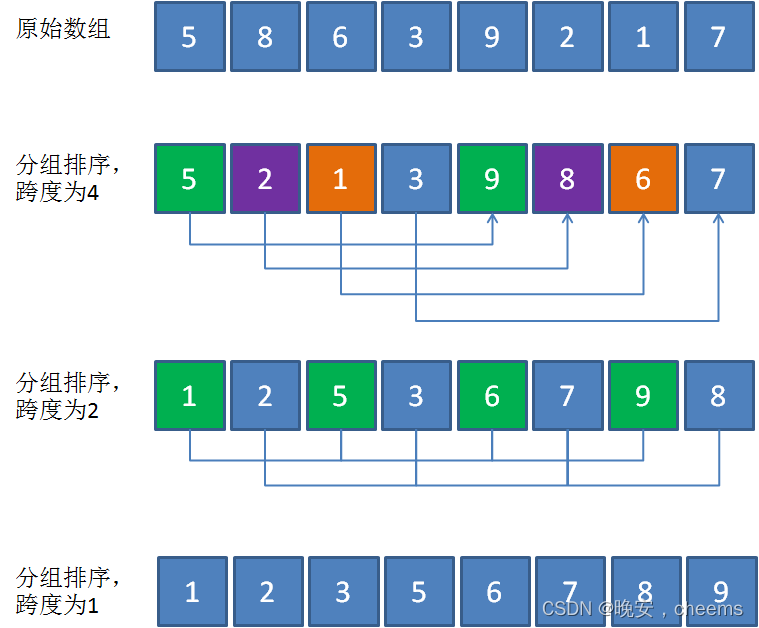
数据结构的希尔排序(c语言版)
一.希尔排序的概念 1.希尔排序的基本思想 希尔排序是一种基于插入排序算法的优化排序方法。它的基本思想如下: 选择一个增量序列 t1,t2,......,tk,其中 ti > tj, 当 i < j,并且 tk 1。 按增量序列个数k&#…...

使用Node.js搭建服务器
使用Node.js搭建服务器 1.安装Node.js和npm 安装教程自行搜索(好多),建议Node.js直接安装在C盘 注意镜像的设置:npm install -g cnpm --registryhttps://registry.npm.taobao.org 注意版本检查: //以下是我使用的版…...

网络编程——多进程的服务器
多进程的网络服务器 多进程的网络服务器是一种使用多个进程来处理并发网络请求的服务器架构。在这种架构中,服务器在接收到客户端连接请求后,会创建一个新的子进程来处理该请求,从而允许服务器同时处理多个客户端连接。多进程服务器通常用于…...

代码随想录算法训练营第二十一天| 530. 二叉搜索树的最小绝对差、501. 二叉搜索树中的众数、236. 二叉树的最近公共祖先
[LeetCode] 530. 二叉搜索树的最小绝对差 [LeetCode] 530. 二叉搜索树的最小绝对差 文章解释 [LeetCode] 530. 二叉搜索树的最小绝对差 视频解释 题目: 给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。 差值是一个正数,其…...

【面试】JDK和JVM是什么关系?
目录 1. JDK2. JVM3. 关系 1. JDK 1.Java Development Kit,java开发工具包。2.提供了java应用程序开发所需的所有工具和API。3.JDK包含了JRE(Java Runtime Environment),即Java运行环境,以及编译Java源代码的编译器(j…...
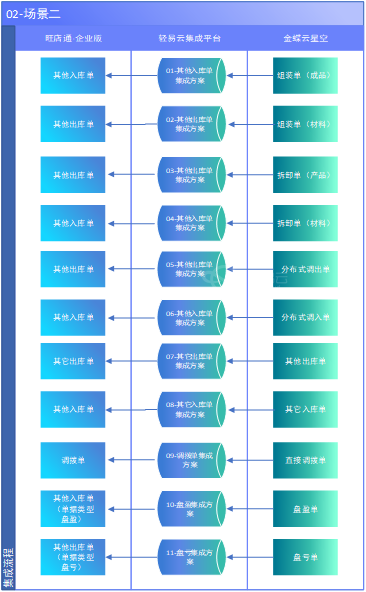
旺店通与金蝶云星空 就应该这样集成打通
在当今数字化商业环境中,企业需要高效、灵活的系统来支持其业务运营。旺店通和金蝶云星空作为两个领先的企业管理解决方案,它们的集成能够为企业带来无缝的业务流程和数据一致性。本文将详细介绍旺店通与金蝶云星空的全场景集成方案,包括主数…...
linux开发之设备树
设备树的基本概念 1.什么是设备树?为什么叫设备树呢? 设备树是描述硬件的文本文件,因为语法结构像树一样。所以叫设备树。 2.基本名词解释 <1>DT:Device Tree //设备树 <2>FDT:Flattened Device Tree //开放设备树,起源于0penFirmware(0F…...

DQL(数据查询)
目录 1. DQL概念 2. DQL - 编写顺序 3. 基础查询 3.1 查询多个字段 3.2 字段设置别名 3.3 去除重复记录 3.4 案例 4. 条件查询 4.1 语法 4.2 条件 4.3 案例: 5. 聚合函数 5.1 常见的聚合函数: 5.2 语法 5.3 案例: 6. 分组查…...
)
LeetCode 2951.找出峰值:模拟(遍历)
【LetMeFly】2951.找出峰值:模拟(遍历) 力扣题目链接:https://leetcode.cn/problems/find-the-peaks/ 给你一个下标从 0 开始的数组 mountain 。你的任务是找出数组 mountain 中的所有 峰值。 以数组形式返回给定数组中 峰值 的…...
)
A/B测试还在用t检验?DeepSeek团队淘汰传统方法的4个关键转折点(含贝叶斯动态决策引擎实测对比)
更多请点击: https://intelliparadigm.com 第一章:A/B测试范式迁移的必然性 传统A/B测试长期依赖静态流量分配、固定实验周期与人工决策闭环,在现代高并发、多场景、实时反馈的业务系统中正面临三重结构性失配:实验吞吐量低、决策…...

OpenVAS部署避坑指南:从Kali的`apt-get install gvm`到官方OVA镜像,我踩过的那些雷
OpenVAS部署避坑指南:从Kali的apt-get install gvm到官方OVA镜像实战复盘 1. 为什么OpenVAS部署总让人头疼? 三年前我第一次接触漏洞扫描工具时,OpenVAS的安装过程就给我留下了深刻印象。当时按照某技术论坛的教程,在Kali Linux…...

实战揭秘:Obsidian加州海岸主题如何将macOS美学融入笔记生产力革命
实战揭秘:Obsidian加州海岸主题如何将macOS美学融入笔记生产力革命 【免费下载链接】obsidian-california-coast-theme A minimalist obsidian theme inspired by macOS Big Sur 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-california-coast-theme …...

ARM裸机开发:从异常处理到协作式调度器的实战指南
1. 项目概述:从“异常”切入,理解ARM裸机开发的本质如果你刚开始接触ARM嵌入式开发,可能会觉得“异常”这个词有点吓人,听起来像是程序出了什么大问题。但恰恰相反,在ARM裸机开发的世界里,“异常”是系统与…...

中间件简单题目教学
题目1:环境搭建与简单模式使用 Docker 启动 RabbitMQ 4.x 容器,用户 guest,密码 123456,映射管理端口 15672。编写 Java 原生生产者,向队列 test_queue 发送消息 "Hello Exam"。编写 Java 原生消费者&#x…...

论文查重,重复率高该怎么办?
论文查重高,先别急着想“有没有捷径”。先判断你高到什么程度。10%-20%超线一点:最好处理 这种通常不是“论文废了”,而是局部重复。最常见:文献综述太像参考文献原话理论定义直接搬对策建议全是“加强XX、完善XX、建立XX”方法部…...

bili2text终极指南:一键将B站视频转换为高质量文字稿的免费工具
bili2text终极指南:一键将B站视频转换为高质量文字稿的免费工具 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾经为了整理B站视频中的精…...
)
Git提交者信息填错了?别慌,手把手教你用config命令修正(全局/本地/取消设置全攻略)
Git提交者信息填错了?别慌,手把手教你用config命令修正(全局/本地/取消设置全攻略) 刚提交完代码到Git仓库,突然发现用户名和邮箱填错了?别担心,这种情况几乎每个开发者都遇到过。提交者信息错误…...

3分钟掌握FlicFlac:高效音频格式转换工具完全指南
3分钟掌握FlicFlac:高效音频格式转换工具完全指南 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 在数字音频处理领域,格式兼容性…...

2026实测:专业降AI率软件选这款就对了
2026 年降 AIGC 工具已经从“机械式语义调整”进化为多维度智能优化系统,核心评估指标涵盖 AI 痕迹去除精准度、学术表达一致性、格式结构完整性、长段落逻辑稳定性、内容改写适配性以及高校检测合规性。本次测评覆盖 5 款主流工具,测试场景包括中英文论…...