HashMap在Go与Java的底层实现与区别
在Java中
在Java中hash表的底层数据结构与扩容等已经是面试集合类问题中几乎必问的点了。网上有对源码的解析已经非常详细了我们这里还是说说其底层实现。
基础架构
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {private static final long serialVersionUID = 362498820763181265L;// 默认的初始容量是16static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;// 最大容量static final int MAXIMUM_CAPACITY = 1 << 30;// 默认的负载因子static final float DEFAULT_LOAD_FACTOR = 0.75f;// 当桶(bucket)上的结点数大于等于这个值时会转成红黑树static final int TREEIFY_THRESHOLD = 8;// 当桶(bucket)上的结点数小于等于这个值时树转链表static final int UNTREEIFY_THRESHOLD = 6;// 桶中结构转化为红黑树对应的table的最小容量static final int MIN_TREEIFY_CAPACITY = 64;// 存储元素的数组,总是2的幂次倍transient Node<k,v>[] table;// 一个包含了映射中所有键值对的集合视图transient Set<map.entry<k,v>> entrySet;// 存放元素的个数,注意这个不等于数组的长度。transient int size;// 每次扩容和更改map结构的计数器transient int modCount;// 阈值(容量*负载因子) 当实际大小超过阈值时,会进行扩容int threshold;// 负载因子final float loadFactor;
}本文所有Java代码均来自JavaGuide(HashMap 源码分析 | JavaGuide),这里主要就是定义一些必要的常量,被用于哈希表的创建参数,扩容参数等待。
然后就是hash表中的Node节点的数据结构,我们的k-v键值对就存储在一个Node类里面。在jdk1.7前其实与redis中的字典Dictionary数据结构中的hash表十分类似,即采用线性搜索和拉链法。在jdk1.8 及以后版本1中,添加了树化,即当节点数大于8就会将当前节点转化为红黑树,这样做的目的主要是为了增加搜索效率,红黑树的时间复杂度为O(log n)如果没有树化链表查询的时间复杂度为O(n) 。接下来就看看JavaGuide中给出的节点类:
链表节点:
// 继承自 Map.Entry<K,V>
static class Node<K,V> implements Map.Entry<K,V> {final int hash;// 哈希值,存放元素到hashmap中时用来与其他元素hash值比较final K key;//键V value;//值// 指向下一个节点Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public final K getKey() { return key; }public final V getValue() { return value; }public final String toString() { return key + "=" + value; }// 重写hashCode()方法public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}// 重写 equals() 方法public final boolean equals(Object o) {if (o == this)return true;if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>)o;if (Objects.equals(key, e.getKey()) &&Objects.equals(value, e.getValue()))return true;}return false;}
}树节点:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // 父TreeNode<K,V> left; // 左TreeNode<K,V> right; // 右TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red; // 判断颜色TreeNode(int hash, K key, V val, Node<K,V> next) {super(hash, key, val, next);}// 返回根节点final TreeNode<K,V> root() {for (TreeNode<K,V> r = this, p;;) {if ((p = r.parent) == null)return r;r = p;}resize()
然后我们来重点讲一讲resize()扩容这个方法。
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {// 超过最大值就不再扩充了,就只好随你碰撞去吧if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}// 没超过最大值,就扩充为原来的2倍else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in threshold// 创建对象时初始化容量大小放在threshold中,此时只需要将其作为新的数组容量newCap = oldThr;else {// signifies using defaults 无参构造函数创建的对象在这里计算容量和阈值newCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {// 创建时指定了初始化容量或者负载因子,在这里进行阈值初始化,// 或者扩容前的旧容量小于16,在这里计算新的resize上限float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {// 把每个bucket都移动到新的buckets中for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)// 只有一个节点,直接计算元素新的位置即可newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)// 将红黑树拆分成2棵子树,如果子树节点数小于等于 UNTREEIFY_THRESHOLD(默认为 6),则将子树转换为链表。// 如果子树节点数大于 UNTREEIFY_THRESHOLD,则保持子树的树结构。((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else {Node<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;// 原索引if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}// 原索引+oldCapelse {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);// 原索引放到bucket里if (loTail != null) {loTail.next = null;newTab[j] = loHead;}// 原索引+oldCap放到bucket里if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;
}在Java的hashmap中,在jdk1.8以后是通过负载因子的判断来选择是否进行resize()方法默认负载因子是0.75。如果存储数据与当前容量之比为0.75就会进行扩容。同时当我们存储数据过多时,无论我们的hash算法做了什么样的优化,一定还是会有hash冲突的存在,所以为了解决冲突,我们使用拉链法。在插入数据时,我们采用的方式是将已存在hashmap中的键值对的值与插入的值进行比较,如果二者相等就进行覆盖,如果二者不相等就使用尾加法加载链表尾部(在redis5中,使用的是equals()进行比较,因为redis存储的所有值都是String字符串。)。我们将一个拉链称之为一个哈希桶。但是我们试想如果一个桶的节点过于多了,那么我们查找时遍历起来是很花费时间的,在hashtable中使用的是线性搜索法加拉链法来解决这个问题的,但是如果我们一直盲目使用线性搜索法的话,(我们暂且将线性搜索法占据的hash表数组槽位与hash表当前容量的比值称为线性搜索负载因子)当线性搜索负载因子过大时,我们的hash表的查找效率会受到极大的影响。所有在jdk1.8后的树化则很好解决了这个问题,即当拉链上的节点树大于8时,会先对数组容量进行判断,如果小于64先扩容(hashmap扩容都为2倍扩容),否则进行拉链法。(为什么先扩容呢?因为hashmap的hash函数计算与容量有关所以扩容后会得到新的hash值,避免了hash冲突,相较于红黑树的遍历,我们肯定更优先考虑的是这种做法)
在Golang中
基础架构
type hmap struct {count intflags uint8B uint8noverflow uint16hash0 uint32buckets unsafe.Pointeroldbuckets unsafe.Pointernevacuate uintptrextra *mapextra
}type mapextra struct {overflow *[]*bmapoldoverflow *[]*bmapnextOverflow *bmap
}-
count 表示当前hash表中的元素。
-
B 表示当前hash表持有的 buckets (即桶数组)数量,由于hash表中桶数量都为2的倍数,所以该字段会存储对数。(这里和redis的hash表一样,在redis的rehash过程中,需要先创建一个2倍旧数组长度的新数组,然后进行hash桶迁移)。
-
oldbuckets是哈希表在扩容时用于保存之前buckets的字段,它的大小是当前buckets的一半。
在go的hashmap中,我们使用溢出桶来降低扩容频率,本质上就是预先分配几个数组空间用于存储超出容量的k-v

扩容方法
-
开放寻址法
-
其实就是线性搜索法。简而言之就是依次探测和比较数组中的元素以判断目标键值对是否存在于哈希表,当我们向当前哈希表写入新数据时,如果发生了冲突,就会将键值对写入下一个索引不为空的位置。开放寻址法中对性能影响最大的是装载因子,它是数组中元素数量与数组大小的比值。随着装 载因子的增加,线性探测的平均用时会逐渐增加,这会影响哈希表的读写性能。当装载率超过70% 之后,哈希表的性能就会急剧下降,而一旦装载率达到100%,整个哈希表就会完全失效,这时查找 和插入任意元素的时间复杂度都是
O(n),我们需要遍历数组中的全部元素,所以在实现哈希表时一 定要关注装载因子的变化。
-
-
拉链法
-
和jdk 1.7 一样,就不做过多解释。
-
在go中的k-v添加我们需要注意的是当插入的k-v小于25时会以如下方式插入:
hash := make(map[string]int, 3)
hash["1"] = 1
hash["2"] = 2
hash["3"] = 3如若大于25个,就会分别创建两个数组,分别存储k 和 v,然后以遍历形式插入。
言归正传,在go的hashmap中扩容条件为:装在因子超过6.5 || 哈希表使用太多溢出桶。
同时由于在go的hashmap的扩容不是原子性的所以需要判断以避免二次扩容(这和redis也一样,增删改查需要判断当前数据库的hash表是否在进行rehash)。
扩容数据结构
说了这么多,接下来我们就来重点介绍go的hashmap扩容的数据结构变化。runtime. evacuate会将一个旧桶中的数据分流到两个新桶,所以它会创建两个用于保存分配 上下文的runtime.evacDst结构体,这两个结构体分别指向了一个新桶。
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))newbit := h.noldbuckets()if !evacuated(b) {var xy [2]evacDstx := &xy[0]x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))x.k = add(unsafe.Pointer(x.b), dataOffset)x. v = add(x.k, bucketCnt*uintptr(t.keysize))y := &xy[1Jy. b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))y.k = add(unsafe.Pointer(y.b), dataOffset)y.v = add(y.k, bucketCnt*uintptr(t.keysize))
}go中的hashamp扩容分为等量扩容和翻倍扩容,如果是前者就只初始化一个桶,如果是翻倍扩容,就会初始化两个桶。会把一个链表数据分到新表两个位置,将8个节点分流到两个桶中(这里获取桶位置采用取模或者位运算来得到数据存储的桶位置),然后将k的指针指向两个桶位置。
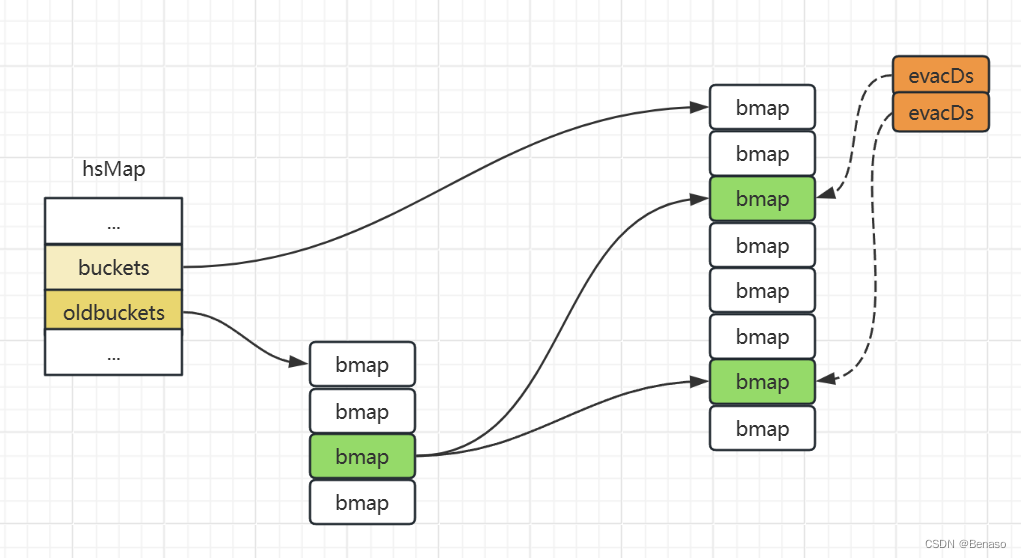
在数据查询时,会先判断是否在进行分流,如果在进行,就先会从旧桶中读取数据。相较于Java的hashmap它不会一次性将所有的元素重新哈希,而是在每次插入元素时,都会将一部分元素移动到新的桶中。这样可以避免一次性的大量计算,但可能会导致一段时间内的查询效率稍低。
相关文章:
HashMap在Go与Java的底层实现与区别
在Java中 在Java中hash表的底层数据结构与扩容等已经是面试集合类问题中几乎必问的点了。网上有对源码的解析已经非常详细了我们这里还是说说其底层实现。 基础架构 public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable,…...

搜维尔科技:使用Haption Virtuose 6D 力反馈通过机器人和虚拟现实完成远程操作项目
使用Haption Virtuose 6D 力反馈通过机器人和虚拟现实完成远程操作项目 搜维尔科技:使用Haption Virtuose 6D 力反馈通过机器人和虚拟现实完成远程操作项目...
)
【Python】WHEELTEC GPS G60主代码读取传感器数据代码(Windows系统)
【Python】WHEELTEC惯导IMU主代码读取传感器数据代码 Windows系统,直接输入串口号即可 读取设备的移动速度(km/h) 注:该GPS传感器需要在室外条件运行,室内可能接收不到信号。 # coding: utf-8 # last modified:202310…...

【Vue】Vue2与Vue3的区别
目录 响应式系统组合式API更小的体积编译优化新的生命周期钩子更好的性能组件结构与模板TeleportFragments 静态节点标记异步组件Slots的改进更好的TypeScript支持Composition API的引入 响应式系统 Vue2使用Object.defineProperty来实现响应式系统,这意味着只有预…...

马斯克的 xAI 帝国!60亿融资背后的超级布局?
在全球科技竞技场,每个重大融资事件都是对行业格局的一次重塑。近日,埃隆马斯克的人工智能初创企业 xAI 成功完成了一轮规模空前的融资——60亿美元,此举无疑在业界投下了一枚震撼弹,标志着 AI 领域内一场新的竞赛拉开了序幕。 …...

互联网医院开发:引领智慧医疗新时代
随着科技的迅猛发展和互联网的普及,传统医疗模式正在迎来一场深刻的变革。互联网医院的崛起,打破了时间和空间的限制,为患者和医疗机构带来了更加便捷、高效、安全的医疗服务体验。本文将从技术角度深入探讨互联网医院的开发,包括…...

民国漫画杂志《时代漫画》第18期.PDF
时代漫画18.PDF: https://url03.ctfile.com/f/1779803-1248612707-27e56b?p9586 (访问密码: 9586) 《时代漫画》的杂志在1934年诞生了,截止1937年6月战争来临被迫停刊共发行了39期。 ps:资源来源网络!...

java.lang.NumberFormatException: For input string:
创建SpringBoot,Mybatis的项目时候,Service层调用Mapper层时候爆出了一个错误 发现报错是一个类型转换错误,经过排查后发现是因为mapper接收的实体类中没有写空参构造...
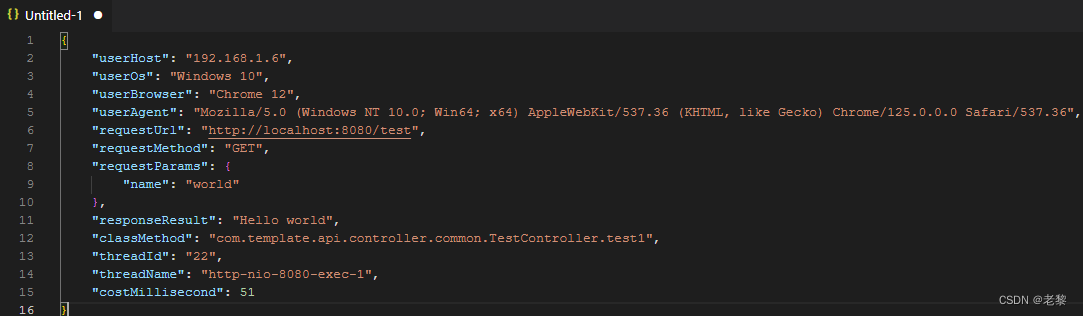
从零开始搭建Springboot项目脚手架4:保存操作日志
目的:通过AOP切面,统一记录接口的访问日志 1、加maven依赖 2、 增加日志类RequestLog 3、 配置AOP切面,把请求前的request、返回的response一起记录 package com.template.common.config;import cn.hutool.core.util.ArrayUtil; import cn.hu…...
)
持续总结中!2024年面试必问 20 道 Rocket MQ面试题(一)
一、请简述什么是RocketMQ? RocketMQ是一个开源的消息中间件,由阿里巴巴团队开发,主要设计用于分布式系统中的异步通信、应用解耦、流量削峰和消息持久化。它支持高吞吐量、高可用性、可扩展性和容错性,是构建大规模实时消息处理…...
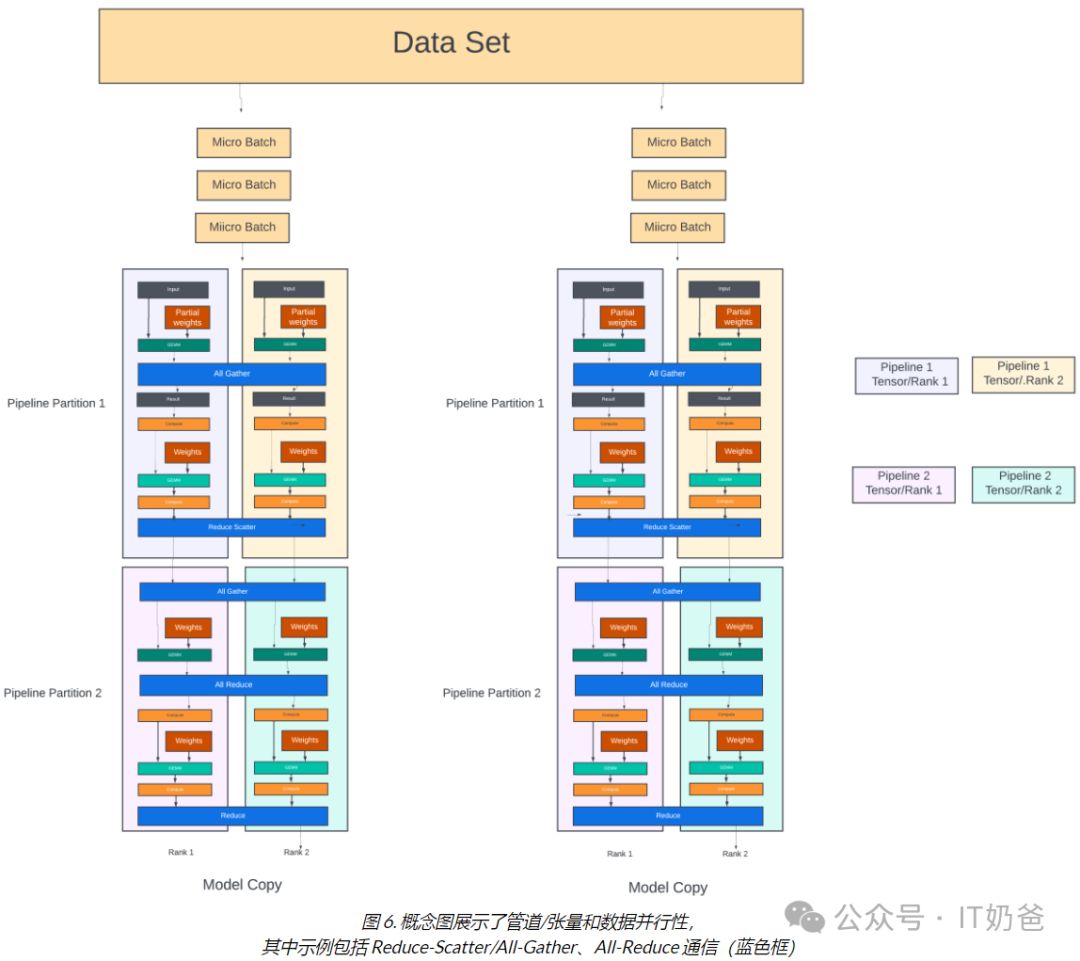
生成式AI的GPU网络技术架构
生成式AI的GPU网络 引言:超大规模企业竞相部署拥有64K GPU的大型集群,以支撑各种生成式AI训练需求。尽管庞大Transformer模型与数据集需数千GPU,但实现GPU间任意非阻塞连接或显冗余。如何高效利用资源,成为业界关注焦点。 张量并…...

旅游卡在哪里拿货?千益畅行旅游卡源头
旅游卡是一种便捷的旅行工具,它可以提供多种优惠和特惠,让人们在旅行中更加省钱、省心。那么,在千益畅行旅游卡这里,我们该如何拿到这张神奇的旅游卡呢? 首先,千益畅行旅游卡作为一款专为旅行爱好者打造的…...

代码随想录算法训练营第四十一天| 509. 斐波那契数 、70. 爬楼梯 、746. 使用最小花费爬楼梯
509. 斐波那契数 题目链接:509. 斐波那契数 文档讲解:代码随想录/斐波那契数 视频讲解:视频讲解-斐波那契数 状态:已完成(1遍) 解题过程 看到题目的第一想法 虽然看了卡哥的动态规划五部曲,…...
Ribbon负载均衡(自己总结的)
文章目录 Ribbon负载均衡负载均衡解决的问题不要把Ribbon负载均衡和Eureka-Server服务器集群搞混了Ribbon负载均衡代码怎么写ribbon负载均衡依赖是怎么引入的? Ribbon负载均衡 负载均衡解决的问题 首先Ribbon负载均衡配合Eureka注册中心一块使用。 在SpringCloud…...

Leetcode 力扣92. 反转链表 II (抖音号:708231408)
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。 示例 1: 输入:head [1,2,3,4,5], left 2, right 4 输出:[1,4,3,2…...

OSI七层模型和TCP/IP四层模型的区别
OSI七层模型 1.物理层(Physical Layer) 实现相邻节点之间比特流的透明传输,尽可能屏蔽传输介质带来的差异。典型设备:集线器(Hub)。 2.数据链路层(Data Link Layer) 将网络层传下来…...

在虚拟机上安装MySQL和Hive
在虚拟机上安装MySQL和Hive的步骤如下。这里将分别针对MySQL和Hive的安装进行说明。 MySQL安装步骤 1. 准备工作 下载MySQL安装包,选择与你虚拟机操作系统版本相匹配的MySQL版本,例如MySQL 8.0.35。 2. 卸载旧版本(如果已安装)…...

Vue 2 和 Vue 3 中同步和异步
Vue 2 和 Vue 3 中同步和异步 Vue 2 同步和异步 同步更新 (Synchronous Updates) Vue 2 在数据更新后会进行同步渲染更新,但为了性能优化,Vue 会在内部队列中异步地进行 DOM 更新。这意味着数据变化会立即被捕捉到,但实际的 DOM 更新会被推迟到下一个事件循环队列中。new V…...
ssm150旅游网站的设计与实现+jsp
旅游网站设计与实现 摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本旅游网站就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞…...

【加密与解密(第四版)】第十四章笔记
第十四章 漏洞分析技术 14.1 软件漏洞原理 缓冲区溢出漏洞:栈溢出 堆溢出、整型溢出(存储溢出、计算溢出、符号问题) UAF(Use-After-Free)漏洞 14.2 ShellCode 功能模块:下载执行、捆绑、反弹shell 14.3 …...

别再被Linux的free命令骗了!手把手教你读懂‘可用内存’available的真实含义
别再被Linux的free命令骗了!手把手教你读懂‘可用内存’available的真实含义 每次在终端输入free -h,看到那一行数字跳动时,你是否也曾经盯着"free"列那个可怜的小数值心跳加速?别急,你可能正在经历一场Linu…...
)
K3s离线安装保姆级避坑指南:从镜像准备到集群验证(含Harbor私有仓库配置)
K3s离线安装全流程实战:从私有仓库搭建到集群高可用 在金融、军工、政务等对网络安全要求极高的领域,离线环境部署Kubernetes集群已成为刚需。作为轻量级Kubernetes发行版,K3s凭借其小于50MB的二进制体积和内置组件简化设计,成为隔…...

CANN/asc-devkit Tiling模板参数选择宏
ASCENDC_TPL_SEL_PARAM 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://…...
)
用GEE和Landsat 8数据,5步搞定城市生态健康“体检报告”(附完整代码)
城市生态健康体检实战:用GEE和Landsat 8生成可视化评估报告 城市规划师和环保工作者常常需要快速评估城市生态状况,但传统方法耗时费力。Google Earth Engine(GEE)平台结合Landsat 8数据,为我们提供了一种高效解决方案…...

CANN/Ascend C数学函数floorf
floorf 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/can…...

终极指南:在Linux系统上安装与优化Realtek RTL8125 2.5GbE网卡驱动
终极指南:在Linux系统上安装与优化Realtek RTL8125 2.5GbE网卡驱动 【免费下载链接】realtek-r8125-dkms A DKMS package for easy use of Realtek r8125 driver, which supports 2.5 GbE. 项目地址: https://gitcode.com/gh_mirrors/re/realtek-r8125-dkms …...

CANN/asc-devkit协作组shfl函数
shfl 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann/…...

3分钟掌握UnityPackage Extractor:无需Unity轻松提取资源包
3分钟掌握UnityPackage Extractor:无需Unity轻松提取资源包 【免费下载链接】unitypackage_extractor Extract a .unitypackage, with or without Python 项目地址: https://gitcode.com/gh_mirrors/un/unitypackage_extractor 你是否曾因需要查看Unity资源包…...

seo优化具体需要做什么?老站长每天必做的4件日常工作
早上8点15分,启动电脑,打开百度统计与Google Search Console后台。接手一个上线刚满两周的新域名,查看昨日的独立访客(UV)和页面浏览量(PV)数字。B2B机械设备类的展示型网站,前30天的自然搜索点击量极少数能突破100次。每天只发企…...

无参考视频质量评估:AI如何在没有标准答案时评判视频画质
1. 项目概述:当AI成为视频的“质检员”在视频内容爆炸式增长的今天,我们每天都会接触到海量的视频流——从手机随手拍的短视频,到专业制作的影视剧,再到监控摄像头24小时不间断的记录。你有没有想过,这些视频的“画质”…...